Datamigrering, ETL och belastning för Teradata-migreringar
Den här artikeln är del två i en serie i sju delar som ger vägledning om hur du migrerar från Teradata till Azure Synapse Analytics. Fokus för den här artikeln är metodtips för ETL- och belastningsmigrering.
Överväganden vid datamigrering
Inledande beslut om datamigrering från Teradata
När du migrerar ett Teradata-informationslager måste du ställa några grundläggande datarelaterade frågor. Exempel:
Ska oanvända tabellstrukturer migreras?
Vilken är den bästa migreringsmetoden för att minimera risker och användarpåverkan?
När du migrerar data marts: förblir fysisk eller virtuell?
I nästa avsnitt beskrivs dessa punkter inom ramen för migreringen från Teradata.
Migrera oanvända tabeller?
Tips
I äldre system är det inte ovanligt att tabeller blir redundanta över tid – de behöver inte migreras i de flesta fall.
Det är logiskt att bara migrera tabeller som används i det befintliga systemet. Tabeller som inte är aktiva kan arkiveras i stället för att migreras, så att data är tillgängliga om det behövs i framtiden. Det är bäst att använda systemmetadata och loggfiler i stället för dokumentation för att avgöra vilka tabeller som används, eftersom dokumentationen kan vara inaktuell.
Om det är aktiverat innehåller Teradata-systemkatalogtabeller och loggar information som kan avgöra när en viss tabell senast användes, vilket i sin tur kan användas för att avgöra om en tabell är en kandidat för migrering.
Här är en exempelfråga om DBC.Tables som anger datumet för senaste åtkomst och senaste ändring:
SELECT TableName, CreatorName, CreateTimeStamp, LastAlterName,
LastAlterTimeStamp, AccessCount, LastAccessTimeStamp
FROM DBC.Tables t
WHERE DataBaseName = 'databasename'
Om loggning är aktiverat och logghistoriken är tillgänglig är annan information, till exempel SQL-frågetext, tillgänglig i tabellen DBQLogTbl och associerade loggningstabeller. Mer information finns i Teradata-logghistorik.
Vilken är den bästa migreringsmetoden för att minimera risker och påverkan på användare?
Den här frågan uppstår ofta eftersom företag kanske vill minska effekten av ändringar på datalagrets datamodell för att förbättra flexibiliteten. Företag ser ofta en möjlighet att modernisera eller transformera sina data ytterligare under en ETL-migrering. Den här metoden medför en högre risk eftersom den ändrar flera faktorer samtidigt, vilket gör det svårt att jämföra resultatet av det gamla systemet jämfört med det nya. Att göra ändringar i datamodellen här kan också påverka överordnade eller underordnade ETL-jobb till andra system. På grund av den risken är det bättre att designa om på den här skalan efter migreringen av informationslagret.
Även om en datamodell avsiktligt ändras som en del av den övergripande migreringen är det bra att migrera den befintliga modellen i befintligt läge för att Azure Synapse i stället för att göra någon omkonstruktion på den nya plattformen. Den här metoden minimerar effekten på befintliga produktionssystem, samtidigt som du drar nytta av prestanda och elastisk skalbarhet för Azure-plattformen för enstaka omkonstruktionsuppgifter.
När du migrerar från Teradata bör du överväga att skapa en Teradata-miljö på en virtuell dator i Azure som en språngbräda i migreringsprocessen.
Tips
Migrera den befintliga modellen som den är till en början, även om en ändring av datamodellen planeras i framtiden.
Använda en Teradata-instans för virtuell dator som en del av en migrering
En valfri metod för att migrera från en lokal Teradata-miljö är att använda Azure-miljön för att skapa en Teradata-instans på en virtuell dator i Azure, som är samordnad med målmiljön Azure Synapse. Detta är möjligt eftersom Azure tillhandahåller billig molnlagring och elastisk skalbarhet.
Med den här metoden kan standardverktyg för Teradata, till exempel Teradata Parallel Data Transporter eller datareplikeringsverktyg från tredje part, till exempel Attunity Replicate, användas för att effektivt flytta delmängden av Teradata-tabeller som måste migreras till den virtuella datorinstansen. Sedan kan alla migreringsuppgifter utföras i Azure-miljön. Den här metoden har flera fördelar:
Efter den första replikeringen av data påverkar migreringsuppgifter inte källsystemet.
Azure-miljön har välbekanta Teradata-gränssnitt, verktyg och verktyg.
Azure-miljön ger tillgänglighet för nätverksbandbredd mellan det lokala källsystemet och molnmålsystemet.
Verktyg som Azure Data Factory kan effektivt anropa verktyg som Teradata Parallel Transporter för att migrera data snabbt och enkelt.
Migreringsprocessen samordnas och kontrolleras helt i Azure-miljön.
När du migrerar data marts: förblir fysisk eller virtuell?
Tips
Virtualisering av data marts kan spara på lagrings- och bearbetningsresurser.
I äldre Teradata-informationslagermiljöer är det vanligt att skapa flera data marts som är strukturerade för att ge bra prestanda för ad hoc-självbetjäningsfrågor och rapporter för en viss avdelning eller affärsfunktion i en organisation. Därför består ett dataarkiv vanligtvis av en delmängd av informationslagret och innehåller aggregerade versioner av data i ett formulär som gör det möjligt för användare att enkelt köra frågor mot dessa data med snabba svarstider via användarvänliga frågeverktyg som Microsoft Power BI, Tableau eller MicroStrategy. Det här formuläret är vanligtvis en dimensionsdatamodell. En användning av data marts är att exponera data i en användbar form, även om den underliggande lagerdatamodellen är något annat, till exempel ett datavalv.
Du kan använda separata data marts för enskilda affärsenheter i en organisation för att implementera robusta datasäkerhetssystem, genom att endast tillåta användare att komma åt specifika data marts som är relevanta för dem, och eliminera, dölja eller anonymisera känsliga data.
Om dessa data marts implementeras som fysiska tabeller behöver de ytterligare lagringsresurser för att lagra dem och ytterligare bearbetning för att skapa och uppdatera dem regelbundet. Dessutom är data i mars bara lika uppdaterade som den senaste uppdateringsåtgärden, och kan därför vara olämpliga för mycket volatila datainstrumentpaneler.
Tips
Prestanda och skalbarhet för Azure Synapse möjliggör virtualisering utan att offra prestanda.
Med tillkomsten av relativt billiga skalbara MPP-arkitekturer, till exempel Azure Synapse och de inneboende prestandaegenskaperna för sådana arkitekturer, kan det vara så att du kan tillhandahålla data mart-funktioner utan att behöva instansiera marten som en uppsättning fysiska tabeller. Detta uppnås genom att effektivt virtualisera dataarkivet via SQL-vyer till huvudinformationslagret eller via ett virtualiseringslager med funktioner som vyer i Azure eller visualiseringsprodukter från Microsoft-partner. Den här metoden förenklar eller eliminerar behovet av ytterligare lagrings- och aggregeringsbearbetning och minskar det totala antalet databasobjekt som ska migreras.
Det finns en annan potentiell fördel med den här metoden. Genom att implementera aggregerings- och kopplingslogik i ett virtualiseringslager, och presentera externa rapporteringsverktyg via en virtualiserad vy, "pushas den bearbetning som krävs för att skapa dessa vyer" till informationslagret, vilket vanligtvis är det bästa stället att köra kopplingar, aggregeringar och andra relaterade åtgärder på stora datavolymer.
De främsta drivkrafterna för att välja en implementering av en virtuell data mart framför en fysisk data mart är:
Mer smidighet: en virtuell data mart är enklare att ändra än fysiska tabeller och associerade ETL-processer.
Lägre total ägandekostnad: En virtualiserad implementering kräver färre datalager och kopior av data.
Eliminering av ETL-jobb för att migrera och förenkla informationslagerarkitekturen i en virtualiserad miljö.
Prestanda: Även om fysiska data marts historiskt sett har varit mer högpresterande implementerar virtualiseringsprodukter nu intelligenta cachelagringstekniker för att minimera.
Datamigrering från Teradata
Förstå dina data
En del av migreringsplaneringen är att i detalj förstå mängden data som behöver migreras eftersom det kan påverka beslut om migreringsmetoden. Använd systemmetadata för att fastställa det fysiska utrymme som tas upp av "rådata" i tabellerna som ska migreras. I det här sammanhanget innebär "rådata" mängden utrymme som används av dataraderna i en tabell, exklusive omkostnader som index och komprimering. Detta gäller särskilt för de största faktatabellerna eftersom dessa vanligtvis utgör mer än 95 % av data.
Du kan få ett korrekt tal för mängden data som ska migreras för en viss tabell genom att extrahera ett representativt urval av data, till exempel en miljon rader, till en okomprimerad avgränsad platt ASCII-datafil. Använd sedan filens storlek för att få en genomsnittlig rådatastorlek per rad i tabellen. Multiplicera slutligen den genomsnittliga storleken med det totala antalet rader i den fullständiga tabellen för att ge en rådatastorlek för tabellen. Använd den rådatastorleken i planeringen.
Överväganden vid ETL-migrering
Inledande beslut om Teradata ETL-migrering
Tips
Planera metoden för ETL-migrering i förväg och utnyttja Azure-anläggningar där det är lämpligt.
För ETL/ELT-bearbetning kan äldre Teradata-informationslager använda specialbyggda skript med Teradata-verktyg som BTEQ och Teradata Parallel Transporter (TPT) eller ETL-verktyg från tredje part, till exempel Informatica eller Ab Initio. Ibland använder Teradata-informationslager en kombination av ETL- och ELT-metoder som har utvecklats över tid. När du planerar en migrering till Azure Synapse måste du fastställa det bästa sättet att implementera den nödvändiga ETL/ELT-bearbetningen i den nya miljön samtidigt som kostnaden och risken minimeras. Mer information om ETL- och ELT-bearbetning finns i designmetoden ELT vs ETL.
I följande avsnitt beskrivs migreringsalternativ och rekommendationer för olika användningsfall. Det här flödesschemat sammanfattar en metod:
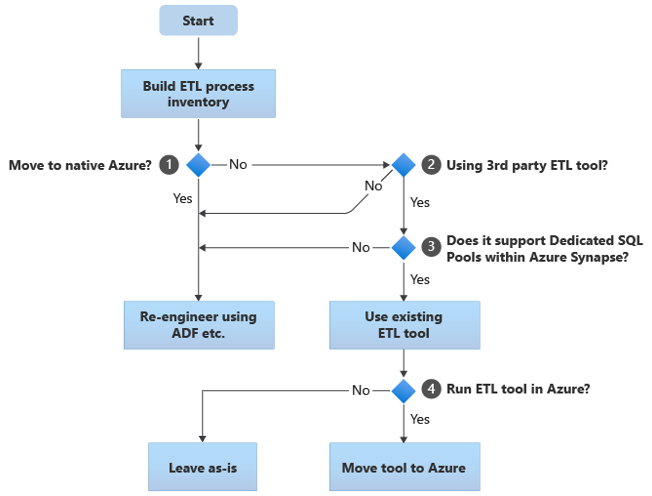
Det första steget är alltid att skapa en inventering av ETL/ELT-processer som måste migreras. Precis som med andra steg är det möjligt att de "inbyggda" Azure-standardfunktionerna gör det onödigt att migrera vissa befintliga processer. I planeringssyfte är det viktigt att förstå omfattningen av migreringen som ska utföras.
I det föregående flödesschemat gäller beslut 1 ett beslut på hög nivå om huruvida du ska migrera till en helt Azure-intern miljö. Om du flyttar till en helt Azure-intern miljö rekommenderar vi att du återskapar ETL-bearbetningen med pipelines och aktiviteter i Azure Data Factory eller Azure Synapse Pipelines. Om du inte flyttar till en helt Azure-intern miljö är beslut 2 om ett befintligt ETL-verktyg från tredje part redan används.
I Teradata-miljön kan en del eller all ETL-bearbetning utföras av anpassade skript med Teradata-specifika verktyg som BTEQ och TPT. I det här fallet bör din metod vara att omkonstruera med datafabriken.
Tips
Utnyttja investeringar i befintliga verktyg från tredje part för att minska kostnader och risker.
Om ett ETL-verktyg från tredje part redan används, och särskilt om det finns en stor investering i färdigheter eller flera befintliga arbetsflöden och scheman använder verktyget, är beslut 3 om verktyget effektivt kan stödja Azure Synapse som målmiljö. Helst innehåller verktyget "interna" anslutningsappar som kan utnyttja Azure-funktioner som PolyBase eller COPY INTO för den mest effektiva datainläsningen. Det finns ett sätt att anropa en extern process, till exempel PolyBase eller COPY INTO, och skicka lämpliga parametrar. I det här fallet använder du befintliga kunskaper och arbetsflöden, med Azure Synapse som den nya målmiljön.
Om du bestämmer dig för att behålla ett befintligt ETL-verktyg från tredje part kan det finnas fördelar med att köra verktyget i Azure-miljön (i stället för på en befintlig lokal ETL-server) och att Azure Data Factory hantera den övergripande orkestreringen av befintliga arbetsflöden. En särskild fördel är att färre data måste laddas ned från Azure, bearbetas och sedan laddas upp till Azure igen. Beslut 4 handlar alltså om att låta det befintliga verktyget köras som det är eller flytta det till Azure-miljön för att uppnå fördelar med kostnad, prestanda och skalbarhet.
Återskapa befintliga Teradata-specifika skript
Om vissa eller alla befintliga Teradata Warehouse ETL/ELT-bearbetning hanteras av anpassade skript som använder Teradata-specifika verktyg, till exempel BTEQ, MLOAD eller TPT, måste dessa skript kodas om för den nya Azure Synapse miljön. Om ETL-processer implementerades med lagrade procedurer i Teradata måste dessa också kodas om.
Tips
Inventeringen av ETL-uppgifter som ska migreras bör innehålla skript och lagrade procedurer.
Vissa element i ETL-processen är enkla att migrera, till exempel genom enkel massdatainläsning till en mellanlagringstabell från en extern fil. Det kan till och med vara möjligt att automatisera dessa delar av processen, till exempel genom att använda PolyBase i stället för snabb belastning eller MLOAD. Om de exporterade filerna är Parquet kan du använda en intern Parquet-läsare, vilket är ett snabbare alternativ än PolyBase. Andra delar av processen som innehåller godtyckliga komplexa SQL- och/eller lagrade procedurer tar mer tid att återskapa.
Ett sätt att testa Teradata SQL för kompatibilitet med Azure Synapse är att samla in några representativa SQL-instruktioner från Teradata-loggar och sedan prefixa dessa frågor med EXPLAINoch sedan – förutsatt att en liknande migrerad datamodell i Azure Synapse – kör dessa EXPLAIN instruktioner i Azure Synapse. Alla inkompatibla SQL-objekt genererar ett fel och felinformationen kan fastställa omoderingsaktivitetens skala.
Microsoft-partner erbjuder verktyg och tjänster för att migrera Teradata SQL och lagrade procedurer till Azure Synapse.
Använda ETL-verktyg från tredje part
Som beskrivs i föregående avsnitt kommer det befintliga äldre informationslagersystemet i många fall redan att fyllas i och underhållas av ETL-produkter från tredje part. En lista över Microsofts dataintegreringspartner för Azure Synapse finns i Dataintegreringspartner.
Datainläsning från Teradata
Tillgängliga alternativ vid inläsning av data från Teradata
Tips
Verktyg från tredje part kan förenkla och automatisera migreringsprocessen och därmed minska risken.
När det gäller att migrera data från ett Teradata-informationslager finns det några grundläggande frågor som är kopplade till datainläsning som måste lösas. Du måste bestämma hur data ska flyttas fysiskt från den befintliga lokala Teradata-miljön till Azure Synapse i molnet och vilka verktyg som ska användas för att utföra överföringen och belastningen. Tänk på följande frågor, som beskrivs i nästa avsnitt.
Kommer du att extrahera data till filer eller flytta dem direkt via en nätverksanslutning?
Kommer du att samordna processen från källsystemet eller från Azure-målmiljön?
Vilka verktyg kommer du att använda för att automatisera och hantera processen?
Vill du överföra data via filer eller nätverksanslutningar?
Tips
Förstå de datavolymer som ska migreras och den tillgängliga nätverksbandbredden eftersom dessa faktorer påverkar migreringsmetodens beslut.
När databastabellerna som ska migreras har skapats i Azure Synapse kan du flytta data för att fylla i dessa tabeller från det äldre Teradata-systemet och till den nya miljön. Det finns två grundläggande metoder:
Filextrakt: extrahera data från Teradata-tabellerna till flata filer, vanligtvis i CSV-format, via BTEQ, Snabb export eller Teradata Parallel Transporter (TPT). Använd TPT när det är möjligt eftersom det är det mest effektiva dataflödesflödet.
Den här metoden kräver utrymme för att landa de extraherade datafilerna. Utrymmet kan vara lokalt för Teradata-källdatabasen (om tillräckligt med lagringsutrymme är tillgängligt) eller fjärranslutet i Azure Blob Storage. Den bästa prestandan uppnås när en fil skrivs lokalt, eftersom det undviker nätverksomkostnader.
För att minimera kraven på lagring och nätverksöverföring är det bra att komprimera de extraherade datafilerna med hjälp av ett verktyg som gzip.
När de flata filerna har extraherats kan de antingen flyttas till Azure Blob Storage (sorterade med målinstansen Azure Synapse instans) eller läsas in direkt i Azure Synapse med PolyBase eller COPY INTO. Metoden för att fysiskt flytta data från lokal lokal lagring till Azure-molnmiljön beror på mängden data och den tillgängliga nätverksbandbredden.
Microsoft erbjuder olika alternativ för att flytta stora mängder data, inklusive AZCopy för att flytta filer över nätverket till Azure Storage, Azure ExpressRoute för att flytta massdata över en privat nätverksanslutning och Azure Data Box där filerna flyttas till en fysisk lagringsenhet som sedan skickas till ett Azure-datacenter för inläsning. Mer information finns i dataöverföring.
Direkt extrahering och inläsning över nätverket: Azure-målmiljön skickar en begäran om dataextrakt, vanligtvis via ett SQL-kommando, till det äldre Teradata-systemet för att extrahera data. Resultaten skickas över nätverket och läses in direkt i Azure Synapse, utan att behöva landa data i mellanliggande filer. Den begränsande faktorn i det här scenariot är normalt bandbredden för nätverksanslutningen mellan Teradata-databasen och Azure-miljön. För mycket stora datavolymer kanske den här metoden inte är praktisk.
Det finns också en hybridmetod som använder båda metoderna. Du kan till exempel använda metoden för direkt nätverksextrakt för mindre dimensionstabeller och exempel på större faktatabeller för att snabbt tillhandahålla en testmiljö i Azure Synapse. För de historiska faktatabellerna för stora volymer kan du använda metoden för att extrahera och överföra filer med hjälp av Azure Data Box.
Orkestrera från Teradata eller Azure?
Den rekommenderade metoden när du flyttar till Azure Synapse är att samordna dataextrahering och inläsning från Azure-miljön med hjälp av Azure Synapse Pipelines eller Azure Data Factory, samt associerade verktyg, till exempel PolyBase eller COPY INTO, för mest effektiv datainläsning. Den här metoden utnyttjar Azure-funktionerna och ger en enkel metod för att skapa återanvändbara pipelines för datainläsning.
Andra fördelar med den här metoden är minskad påverkan på Teradata-systemet under datainläsningsprocessen eftersom hanterings- och inläsningsprocessen körs i Azure och möjligheten att automatisera processen med hjälp av metadatadrivna datainläsningspipelines.
Vilka verktyg kan användas?
Uppgiften med datatransformering och förflyttning är den grundläggande funktionen för alla ETL-produkter. Om någon av dessa produkter redan används i den befintliga Teradata-miljön kan det förenkla datamigreringen från Teradata till Azure Synapse med det befintliga ETL-verktyget. Den här metoden förutsätter att ETL-verktyget stöder Azure Synapse som målmiljö. Mer information om verktyg som stöder Azure Synapse finns i Dataintegreringspartner.
Om du använder ett ETL-verktyg bör du överväga att köra verktyget i Azure-miljön för att dra nytta av Azures molnprestanda, skalbarhet och kostnad samt frigöra resurser i Teradata-datacentret. En annan fördel är minskad dataflytt mellan molnet och lokala miljöer.
Sammanfattning
Sammanfattnings nog är våra rekommendationer för migrering av data och associerade ETL-processer från Teradata till Azure Synapse:
Planera i förväg för att säkerställa en lyckad migreringsövning.
Skapa en detaljerad inventering av data och processer som ska migreras så snart som möjligt.
Använd systemmetadata och loggfiler för att få en korrekt förståelse för data- och processanvändningen. Förlita dig inte på dokumentation eftersom den kan vara inaktuell.
Förstå de datavolymer som ska migreras och nätverksbandbredden mellan det lokala datacentret och Azure-molnmiljöerna.
Överväg att använda en Teradata-instans på en virtuell Azure-dator som en språngbräda för att avlasta migreringen från den äldre Teradata-miljön.
Använd inbyggda Azure-standardfunktioner för att minimera migreringsarbetsbelastningen.
Identifiera och förstå de mest effektiva verktygen för dataextrahering och inläsning i både Teradata- och Azure-miljöer. Använd lämpliga verktyg i varje fas av processen.
Använd Azure-anläggningar, till exempel Azure Synapse Pipelines eller Azure Data Factory, för att orkestrera och automatisera migreringsprocessen samtidigt som påverkan på Teradata-systemet minimeras.
Nästa steg
Mer information om åtgärder för säkerhetsåtkomst finns i nästa artikel i den här serien: Säkerhet, åtkomst och åtgärder för Teradata-migreringar.