Introduktion till filmontering/avmontering av API:er i Azure Synapse Analytics
Azure Synapse Studio-teamet har skapat två nya monterings-/avmonterings-API:er i Microsoft Spark Utilities-paketet (mssparkutils). Du kan använda dessa API:er för att ansluta fjärrlagring (Azure Blob Storage eller Azure Data Lake Storage Gen2) till alla fungerande noder (drivrutinsnoder och arbetsnoder). När lagringen är på plats kan du använda det lokala fil-API:et för att komma åt data som om de lagras i det lokala filsystemet. Mer information finns i Introduktion till Microsoft Spark-verktyg.
Artikeln visar hur du använder monterings-/avmonterings-API:er på din arbetsyta. Du får lära dig detta:
- Montera Data Lake Storage Gen2 eller Blob Storage.
- Så här kommer du åt filer under monteringspunkten via det lokala filsystemets API.
- Så här kommer du åt filer under monteringspunkten med hjälp av API:et
mssparktuils fs. - Så här kommer du åt filer under monteringspunkten med hjälp av Spark-läs-API:et.
- Demontera monteringspunkten.
Varning
Monteringen av Azure-filresurser är tillfälligt inaktiverad. Du kan använda Montering av Data Lake Storage Gen2 eller Azure Blob Storage i stället, enligt beskrivningen i nästa avsnitt.
Azure Data Lake Storage Gen1-lagring stöds inte. Du kan migrera till Data Lake Storage Gen2 genom att följa migreringsvägledningen för Azure Data Lake Storage Gen1 till Gen2 innan du använder monterings-API:erna.
Montera lagring
Det här avsnittet visar hur du monterar Data Lake Storage Gen2 steg för steg som ett exempel. Montering av Blob Storage fungerar på liknande sätt.
Exemplet förutsätter att du har ett Data Lake Storage Gen2-konto med namnet storegen2. Kontot har en container med namnet mycontainer som du vill montera /test i Spark-poolen.
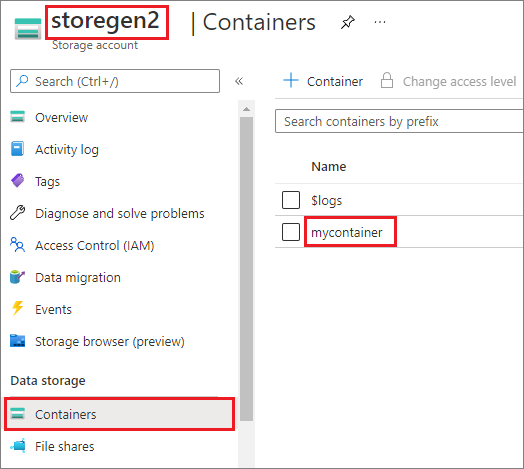
Om du vill montera containern med namnet mycontainermssparkutils måste du först kontrollera om du har behörighet att komma åt containern. För närvarande stöder Azure Synapse Analytics tre autentiseringsmetoder för utlösarmonteringsåtgärden: linkedService, accountKeyoch sastoken.
Montera med hjälp av en länkad tjänst (rekommenderas)
Vi rekommenderar en utlösarmontering via länkad tjänst. Den här metoden undviker säkerhetsläckor eftersom mssparkutils den inte lagrar några egna hemlighets- eller autentiseringsvärden. mssparkutils I stället hämtar alltid autentiseringsvärden från den länkade tjänsten för att begära blobdata från fjärrlagring.
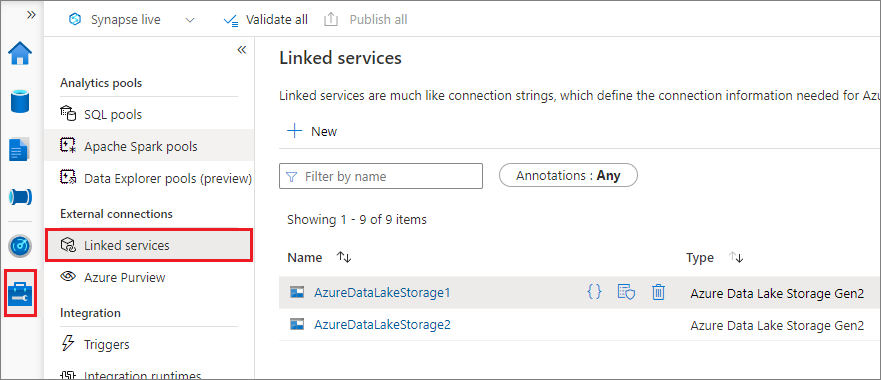
Du kan skapa en länkad tjänst för Data Lake Storage Gen2 eller Blob Storage. För närvarande stöder Azure Synapse Analytics två autentiseringsmetoder när du skapar en länkad tjänst:
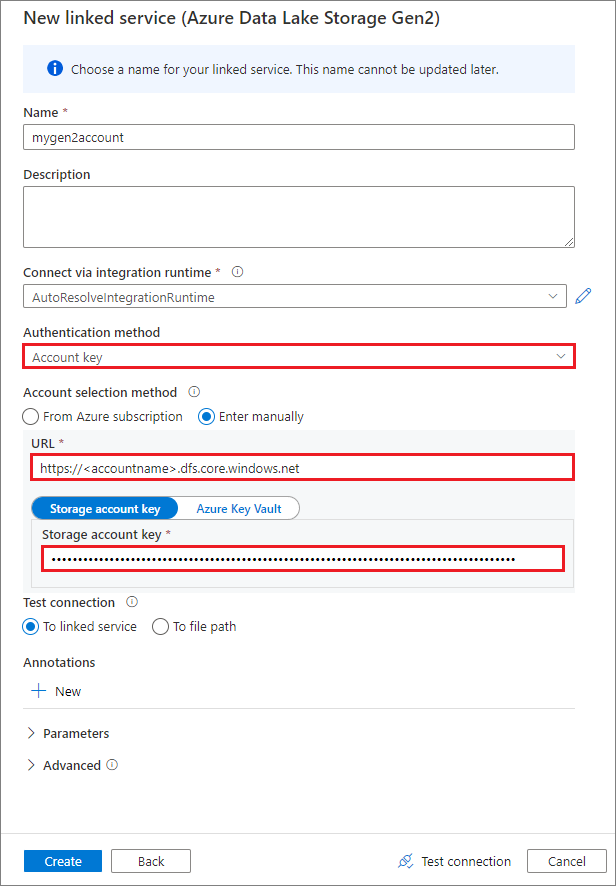
Skapa en länkad tjänst med hjälp av en kontonyckel
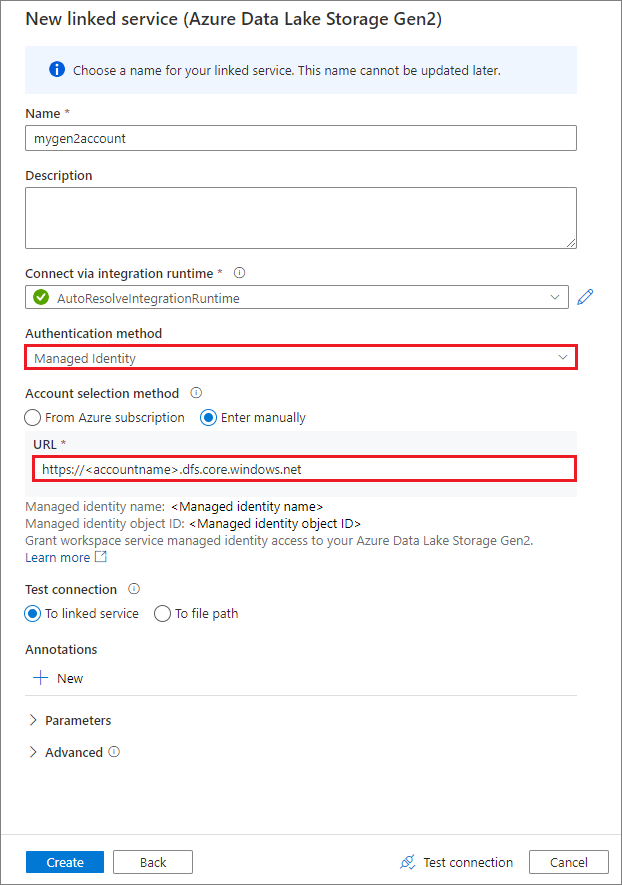
Skapa en länkad tjänst med hjälp av en hanterad identitet
Viktigt!
- Om den länkade tjänsten ovan till Azure Data Lake Storage Gen2 använder en hanterad privat slutpunkt (med en dfs-URI ) måste vi skapa en annan sekundär hanterad privat slutpunkt med azure bloblagringsalternativet (med en blob-URI ) för att säkerställa att den interna fsspec/adlfs-koden kan ansluta med hjälp av BlobServiceClient-gränssnittet .
- Om den sekundära hanterade privata slutpunkten inte är korrekt konfigurerad visas ett felmeddelande som ServiceRequestError: Det går inte att ansluta till värden [storageaccountname].blob.core.windows.net:443 ssl:True [Namn eller tjänst är inte känd]
Kommentar
Om du skapar en länkad tjänst med hjälp av en hanterad identitet som autentiseringsmetod kontrollerar du att MSI-filen för arbetsytan har rollen Storage Blob Data Contributor för den monterade containern.
När du har skapat en länkad tjänst kan du enkelt montera containern i Spark-poolen med hjälp av följande Python-kod:
mssparkutils.fs.mount(
"abfss://mycontainer@<accountname>.dfs.core.windows.net",
"/test",
{"linkedService": "mygen2account"}
)
Kommentar
Du kan behöva importera mssparkutils om den inte är tillgänglig:
from notebookutils import mssparkutils
Vi rekommenderar inte att du monterar en rotmapp, oavsett vilken autentiseringsmetod du använder.
Monteringsparametrar:
- fileCacheTimeout: Blobar cachelagras i den lokala temp-mappen i 120 sekunder som standard. Under den här tiden kontrollerar blobfuse inte om filen är uppdaterad eller inte. Parametern kan ställas in för att ändra standardtidsgränsen för timeout. När flera klienter ändrar filer samtidigt, för att undvika inkonsekvenser mellan lokala filer och fjärrfiler, rekommenderar vi att du förkortar cachetiden eller till och med ändrar den till 0 och alltid får de senaste filerna från servern.
- timeout: Tidsgränsen för monteringsåtgärden är som standard 120 sekunder. Parametern kan ställas in för att ändra standardtidsgränsen för timeout. När det finns för många exekutorer eller när monteringen överskrider tidsgränsen rekommenderar vi att du ökar värdet.
- omfång: Omfångsparametern används för att ange monteringens omfattning. Standardvärdet är "jobb". Om omfånget är inställt på "jobb" visas monteringen endast för det aktuella klustret. Om omfånget är inställt på "arbetsyta" visas monteringen för alla notebook-filer på den aktuella arbetsytan och monteringspunkten skapas automatiskt om den inte finns. Lägg till samma parametrar i avmonterings-API:et för att demontera monteringspunkten. Monteringen på arbetsytans nivå stöds endast för länkad tjänstautentisering.
Du kan använda följande parametrar:
mssparkutils.fs.mount(
"abfss://mycontainer@<accountname>.dfs.core.windows.net",
"/test",
{"linkedService":"mygen2account", "fileCacheTimeout": 120, "timeout": 120}
)
Montera via signaturtoken för delad åtkomst eller kontonyckel
Förutom montering via en länkad tjänst har mssparkutils stöd för att uttryckligen skicka en kontonyckel eller sas-token (signatur för delad åtkomst) som en parameter för att montera målet.
Av säkerhetsskäl rekommenderar vi att du lagrar kontonycklar eller SAS-token i Azure Key Vault (som visas i följande exempelbild). Du kan sedan hämta dem med hjälp av API:et mssparkutil.credentials.getSecret . Mer information finns i Hantera lagringskontonycklar med Key Vault och Azure CLI (äldre).
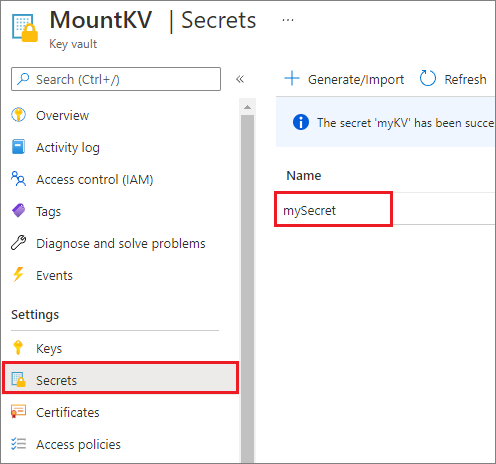
Här är exempelkoden:
from notebookutils import mssparkutils
accountKey = mssparkutils.credentials.getSecret("MountKV","mySecret")
mssparkutils.fs.mount(
"abfss://mycontainer@<accountname>.dfs.core.windows.net",
"/test",
{"accountKey":accountKey}
)
Kommentar
Av säkerhetsskäl ska du inte lagra autentiseringsuppgifter i kod.
Komma åt filer under monteringspunkten med hjälp av mssparkutils fs API
Huvudsyftet med monteringsåtgärden är att låta kunderna komma åt data som lagras i ett fjärrlagringskonto med hjälp av ett lokalt filsystem-API. Du kan också komma åt data med hjälp av API:et mssparkutils fs med en monterad sökväg som parameter. Sökvägsformatet som används här är lite annorlunda.
Förutsatt att du har monterat Data Lake Storage Gen2-containern mycontainer på /test med hjälp av monterings-API:et. När du kommer åt data via ett lokalt filsystems-API:
- För Spark-versioner som är mindre än eller lika med 3.3 är
/synfs/{jobId}/test/{filename}sökvägsformatet . - För Spark-versioner som är större än eller lika med 3.4 är
/synfs/notebook/{jobId}/test/{filename}sökvägsformatet .
Vi rekommenderar att du använder en mssparkutils.fs.getMountPath() för att få rätt sökväg:
path = mssparkutils.fs.getMountPath("/test")
Kommentar
När du monterar lagringen med workspace omfång skapas monteringspunkten under /synfs/workspace mappen . Och du måste använda mssparkutils.fs.getMountPath("/test", "workspace") för att få rätt väg.
När du vill komma åt data med hjälp av API:et mssparkutils fs är sökvägsformatet så här: synfs:/notebook/{jobId}/test/{filename}. Du kan se att synfs används som schema i det här fallet, i stället för en del av den monterade sökvägen. Naturligtvis kan du också använda det lokala filsystemschemat för att komma åt data. Exempel: file:/synfs/notebook/{jobId}/test/{filename}
Följande tre exempel visar hur du kommer åt en fil med en monteringspunktsökväg med hjälp mssparkutils fsav .
Lista kataloger:
mssparkutils.fs.ls(f'file:{mssparkutils.fs.getMountPath("/test")}')Läsa filinnehåll:
mssparkutils.fs.head(f'file:{mssparkutils.fs.getMountPath("/test")}/myFile.csv')Skapa en katalog:
mssparkutils.fs.mkdirs(f'file:{mssparkutils.fs.getMountPath("/test")}/myDir')
Komma åt filer under monteringspunkten med hjälp av Spark-läs-API:et
Du kan ange en parameter för att komma åt data via Spark-läs-API:et. Sökvägsformatet här är detsamma när du använder API:et mssparkutils fs .
Läsa en fil från ett monterat Data Lake Storage Gen2-lagringskonto
I följande exempel förutsätts att ett Data Lake Storage Gen2-lagringskonto redan har monterats och sedan läser du filen med hjälp av en monteringssökväg:
%%pyspark
df = spark.read.load(f'file:{mssparkutils.fs.getMountPath("/test")}/myFile.csv', format='csv')
df.show()
Kommentar
När du monterar lagringen med en länkad tjänst bör du alltid uttryckligen ange konfiguration av spark-länkad tjänst innan du använder synfs-schema för att komma åt data. Mer information finns i ADLS Gen2-lagring med länkade tjänster.
Läsa en fil från ett monterat Blob Storage-konto
Om du har monterat ett Blob Storage-konto och vill komma åt det med hjälp mssparkutils av eller Spark-API:et måste du uttryckligen konfigurera SAS-token via Spark-konfigurationen innan du försöker montera containern med hjälp av monterings-API:et:
Om du vill komma åt ett Blob Storage-konto med hjälp
mssparkutilsav eller Spark-API:et efter en utlösarmontering uppdaterar du Spark-konfigurationen enligt följande kodexempel. Du kan kringgå det här steget om du bara vill komma åt Spark-konfigurationen med hjälp av det lokala fil-API:et efter monteringen.blob_sas_token = mssparkutils.credentials.getConnectionStringOrCreds("myblobstorageaccount") spark.conf.set('fs.azure.sas.mycontainer.<blobStorageAccountName>.blob.core.windows.net', blob_sas_token)Skapa den länkade tjänsten
myblobstorageaccountoch montera Blob Storage-kontot med hjälp av den länkade tjänsten:%%spark mssparkutils.fs.mount( "wasbs://mycontainer@<blobStorageAccountName>.blob.core.windows.net", "/test", Map("linkedService" -> "myblobstorageaccount") )Montera Blob Storage-containern och läs sedan filen med hjälp av en monteringssökväg via det lokala fil-API:et:
# mount the Blob Storage container, and then read the file by using a mount path with open(mssparkutils.fs.getMountPath("/test") + "/myFile.txt") as f: print(f.read())Läs data från den monterade Blob Storage-containern via Spark-läs-API:et:
%%spark // mount blob storage container and then read file using mount path val df = spark.read.text(f'file:{mssparkutils.fs.getMountPath("/test")}/myFile.txt') df.show()
Demontera monteringspunkten
Använd följande kod för att demontera monteringspunkten (/test i det här exemplet):
mssparkutils.fs.unmount("/test")
Kända begränsningar
Avmonteringsmekanismen är inte automatisk. När programkörningen är klar måste du uttryckligen anropa ett avmonterings-API i koden för att demontera monteringspunkten för att frigöra diskutrymmet. Annars finns monteringspunkten fortfarande i noden när programkörningen har slutförts.
Montering av ett Data Lake Storage Gen1-lagringskonto stöds inte för tillfället.
Kända problem:
- I Spark 3.4 kan monteringspunkterna vara otillgängliga när flera aktiva sessioner körs parallellt i samma kluster. Du kan montera med
workspaceomfång för att undvika det här problemet.
Nästa steg
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för