Självstudie: Använda Pandas för att läsa/skriva Azure Data Lake Storage Gen2-data i en serverlös Apache Spark-pool i Synapse Analytics
Lär dig hur du använder Pandas för att läsa/skriva data till Azure Data Lake Storage Gen2 (ADLS) med hjälp av en serverlös Apache Spark-pool i Azure Synapse Analytics. Exempel i den här självstudien visar hur du läser csv-data med Pandas i Synapse, samt excel- och parquet-filer.
I den här självstudien får du lära dig att:
- Läsa/skriva ADLS Gen2-data med Pandas i en Spark-session.
Om du inte har någon Azure-prenumeration skapar du ett kostnadsfritt konto innan du börjar.
Förutsättningar
Azure Synapse Analytics-arbetsyta med ett Azure Data Lake Storage Gen2-lagringskonto konfigurerat som standardlagring (eller primär lagring). Du måste vara Storage Blob Data-deltagare i Data Lake Storage Gen2-filsystemet som du arbetar med.
Serverlös Apache Spark-pool på din Azure Synapse Analytics-arbetsyta. Mer information finns i Skapa en Spark-pool i Azure Synapse.
Konfigurera ett sekundärt Azure Data Lake Storage Gen2-konto (som inte är standard för Synapse-arbetsytan). Du måste vara Storage Blob Data-deltagare i Data Lake Storage Gen2-filsystemet som du arbetar med.
Skapa länkade tjänster – I Azure Synapse Analytics definierar en länkad tjänst din anslutningsinformation till tjänsten. I den här självstudien lägger du till en länkad Azure Synapse Analytics- och Azure Data Lake Storage Gen2-tjänst.
- Öppna Azure Synapse Studio och välj fliken Hantera .
- Under Externa anslutningar väljer du Länkade tjänster.
- Om du vill lägga till en länkad tjänst väljer du Ny.
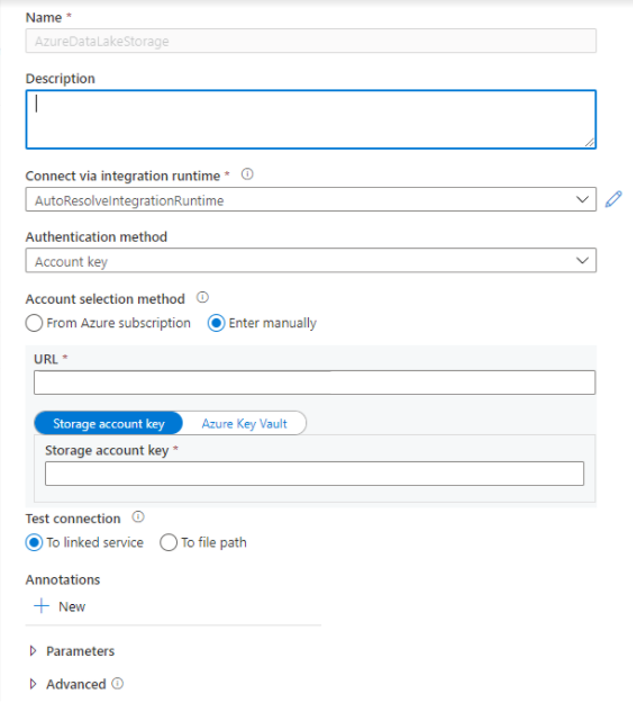
- Välj panelen Azure Data Lake Storage Gen2 i listan och välj Fortsätt.
- Ange dina autentiseringsuppgifter. Kontonyckel, tjänstens huvudnamn (SP), Autentiseringsuppgifter och Hanterad tjänstidentitet (MSI) stöds för närvarande autentiseringstyper. Kontrollera att Storage Blob Data Contributor har tilldelats lagring för SP och MSI innan du väljer den för autentisering. Testa anslutningen för att kontrollera att dina autentiseringsuppgifter är korrekta. Välj Skapa.
Viktigt!
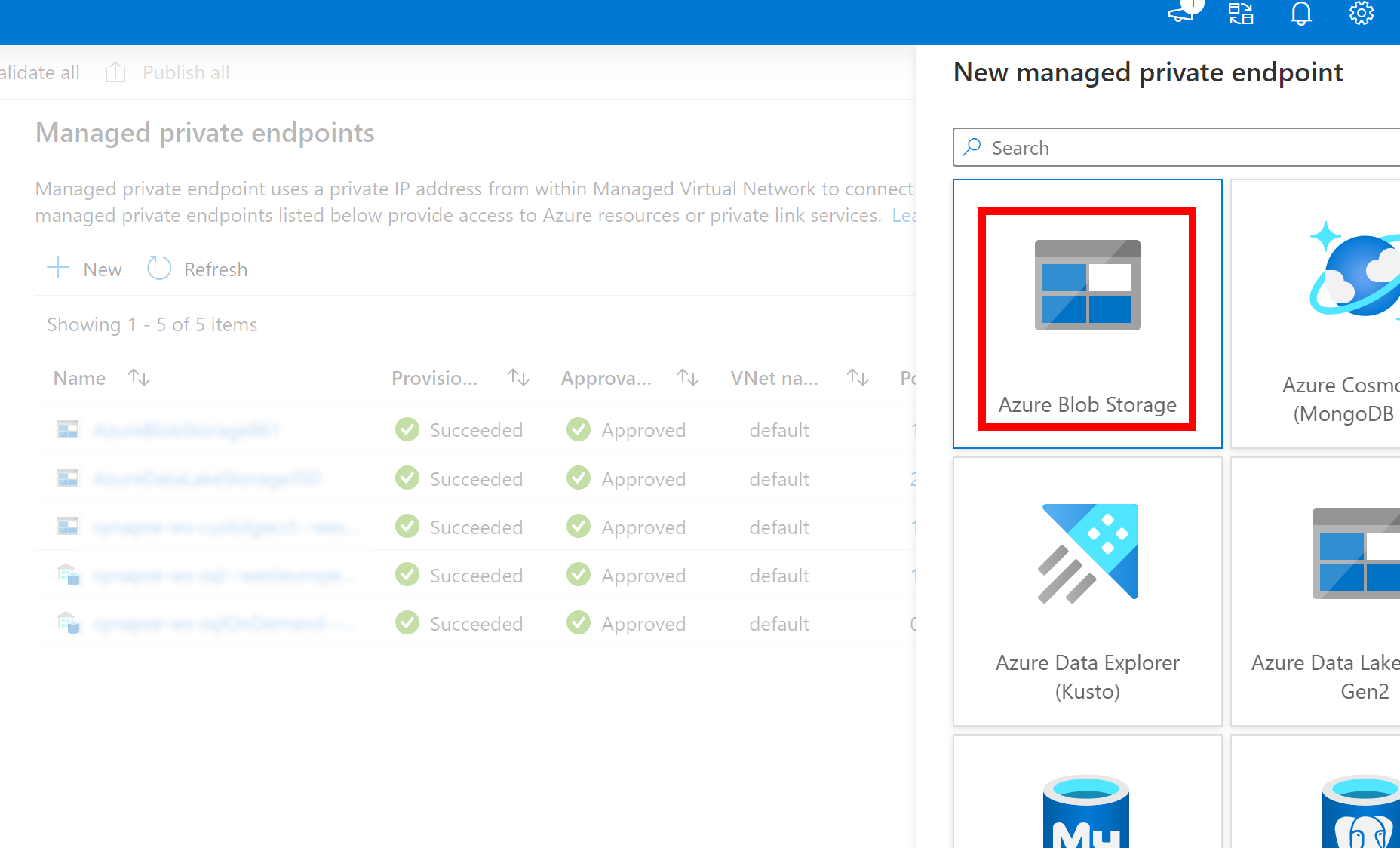
- Om den länkade tjänsten ovan till Azure Data Lake Storage Gen2 använder en hanterad privat slutpunkt (med en dfs-URI ) måste vi skapa en annan sekundär hanterad privat slutpunkt med azure bloblagringsalternativet (med en blob-URI ) för att säkerställa att den interna fsspec/adlfs-koden kan ansluta med hjälp av BlobServiceClient-gränssnittet .
- Om den sekundära hanterade privata slutpunkten inte är korrekt konfigurerad visas ett felmeddelande som ServiceRequestError: Det går inte att ansluta till värden [storageaccountname].blob.core.windows.net:443 ssl:True [Namn eller tjänst är inte känd]
Kommentar
- Pandas-funktionen stöds i Python 3.8 - och Spark3-serverlös Apache Spark-pool i Azure Synapse Analytics.
- Stöd för följande versioner: pandas 1.2.3, fsspec 2021.10.0, adlfs 0.7.7
- Har funktioner som stöder både Azure Data Lake Storage Gen2 URI (abfs[s]://file_system_name@account_name.dfs.core.windows.net/file_path) och FSSPEC kort URL (abfs[s]://container_name/file_path).
Logga in på Azure-portalen
Logga in på Azure-portalen.
Läsa/skriva data till standard-ADLS-lagringskontot för Synapse-arbetsytan
Pandas kan läsa/skriva ADLS-data genom att ange filsökvägen direkt.
Kör följande kod.
Kommentar
Uppdatera fil-URL:en i det här skriptet innan du kör den.
#Read data file from URI of default Azure Data Lake Storage Gen2
import pandas
#read csv file
df = pandas.read_csv('abfs[s]://file_system_name@account_name.dfs.core.windows.net/file_path')
print(df)
#write csv file
data = pandas.DataFrame({'Name':['A', 'B', 'C', 'D'], 'ID':[20, 21, 19, 18]})
data.to_csv('abfs[s]://file_system_name@account_name.dfs.core.windows.net/file_path')
#Read data file from FSSPEC short URL of default Azure Data Lake Storage Gen2
import pandas
#read csv file
df = pandas.read_csv('abfs[s]://container_name/file_path')
print(df)
#write csv file
data = pandas.DataFrame({'Name':['A', 'B', 'C', 'D'], 'ID':[20, 21, 19, 18]})
data.to_csv('abfs[s]://container_name/file_path')
Läsa/skriva data med hjälp av ett sekundärt ADLS-konto
Pandas kan läsa/skriva sekundära ADLS-kontodata:
- med länkad tjänst (med autentiseringsalternativ – lagringskontonyckel, tjänstens huvudnamn, hanterar tjänstidentitet och autentiseringsuppgifter).
- använda lagringsalternativ för att direkt skicka klient-ID och hemlighet, SAS-nyckel, lagringskontonyckel och anslutningssträng.
Använda länkad tjänst
Kör följande kod.
Kommentar
Uppdatera fil-URL:en och det länkade tjänstnamnet i det här skriptet innan du kör den.
#Read data file from URI of secondary Azure Data Lake Storage Gen2
import pandas
#read data file
df = pandas.read_csv('abfs[s]://file_system_name@account_name.dfs.core.windows.net/ file_path', storage_options = {'linked_service' : 'linked_service_name'})
print(df)
#write data file
data = pandas.DataFrame({'Name':['A', 'B', 'C', 'D'], 'ID':[20, 21, 19, 18]})
data.to_csv('abfs[s]://file_system_name@account_name.dfs.core.windows.net/file_path', storage_options = {'linked_service' : 'linked_service_name'})
#Read data file from FSSPEC short URL of default Azure Data Lake Storage Gen2
import pandas
#read data file
df = pandas.read_csv('abfs[s]://container_name/file_path', storage_options = {'linked_service' : 'linked_service_name'})
print(df)
#write data file
data = pandas.DataFrame({'Name':['A', 'B', 'C', 'D'], 'ID':[20, 21, 19, 18]})
data.to_csv('abfs[s]://container_name/file_path', storage_options = {'linked_service' : 'linked_service_name'})
Använda lagringsalternativ för att direkt skicka klient-ID och hemlighet, SAS-nyckel, lagringskontonyckel och anslutningssträng.
Kör följande kod.
Kommentar
Uppdatera fil-URL:en och storage_options i det här skriptet innan du kör den.
#Read data file from URI of secondary Azure Data Lake Storage Gen2
import pandas
#read data file
df = pandas.read_csv('abfs[s]://file_system_name@account_name.dfs.core.windows.net/ file_path', storage_options = {'account_key' : 'account_key_value'})
## or storage_options = {'sas_token' : 'sas_token_value'}
## or storage_options = {'connection_string' : 'connection_string_value'}
## or storage_options = {'tenant_id': 'tenant_id_value', 'client_id' : 'client_id_value', 'client_secret': 'client_secret_value'}
print(df)
#write data file
data = pandas.DataFrame({'Name':['A', 'B', 'C', 'D'], 'ID':[20, 21, 19, 18]})
data.to_csv('abfs[s]://file_system_name@account_name.dfs.core.windows.net/file_path', storage_options = {'account_key' : 'account_key_value'})
## or storage_options = {'sas_token' : 'sas_token_value'}
## or storage_options = {'connection_string' : 'connection_string_value'}
## or storage_options = {'tenant_id': 'tenant_id_value', 'client_id' : 'client_id_value', 'client_secret': 'client_secret_value'}
#Read data file from FSSPEC short URL of default Azure Data Lake Storage Gen2
import pandas
#read data file
df = pandas.read_csv('abfs[s]://container_name/file_path', storage_options = {'account_key' : 'account_key_value'})
## or storage_options = {'sas_token' : 'sas_token_value'}
## or storage_options = {'connection_string' : 'connection_string_value'}
## or storage_options = {'tenant_id': 'tenant_id_value', 'client_id' : 'client_id_value', 'client_secret': 'client_secret_value'}
print(df)
#write data file
data = pandas.DataFrame({'Name':['A', 'B', 'C', 'D'], 'ID':[20, 21, 19, 18]})
data.to_csv('abfs[s]://container_name/file_path', storage_options = {'account_key' : 'account_key_value'})
## or storage_options = {'sas_token' : 'sas_token_value'}
## or storage_options = {'connection_string' : 'connection_string_value'}
## or storage_options = {'tenant_id': 'tenant_id_value', 'client_id' : 'client_id_value', 'client_secret': 'client_secret_value'}
Exempel för att läsa/skriva parquet-fil
Kör följande kod.
Kommentar
Uppdatera fil-URL:en i det här skriptet innan du kör den.
import pandas
#read parquet file
df = pandas.read_parquet('abfs[s]://file_system_name@account_name.dfs.core.windows.net/ parquet_file_path')
print(df)
#write parquet file
df.to_parquet('abfs[s]://file_system_name@account_name.dfs.core.windows.net/ parquet_file_path')
Exempel på excel-fil för läsning/skrivning
Kör följande kod.
Kommentar
Uppdatera fil-URL:en i det här skriptet innan du kör den.
import pandas
#read excel file
df = pandas.read_excel('abfs[s]://file_system_name@account_name.dfs.core.windows.net/ excel_file_path')
print(df)
#write excel file
df.to_excel('abfs[s]://file_system_name@account_name.dfs.core.windows.net/excel_file_path')
Nästa steg
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för