Not
Åtkomst till denna sida kräver auktorisation. Du kan prova att logga in eller byta katalog.
Åtkomst till denna sida kräver auktorisation. Du kan prova att byta katalog.
Den här sidan förklarar hur Azure Databricks använder Lakeguard för att framtvinga användarisolering i delade beräkningsmiljöer och detaljerad åtkomstkontroll i dedikerad beräkning.
Vad är Lakeguard?
Lakeguard är en uppsättning tekniker på Databricks som framtvingar kodisolering och datafiltrering så att flera användare kan dela samma beräkningsresurs på ett säkert och kostnadseffektivt sätt och få åtkomst till data med detaljerade åtkomstkontroller för beräkning som erbjuder privilegierad maskinåtkomst.
Hur fungerar Lakeguard?
I delade beräkningsmiljöer som klassisk standardberäkning, serverlös beräkning och SQL-lager isolerar Lakeguard användarkod från Spark-motorn och från andra användare. Den här designen gör det möjligt för många användare att dela samma beräkningsresurser samtidigt som strikta gränser mellan användare, Spark-drivrutin och exekutorer hålls.
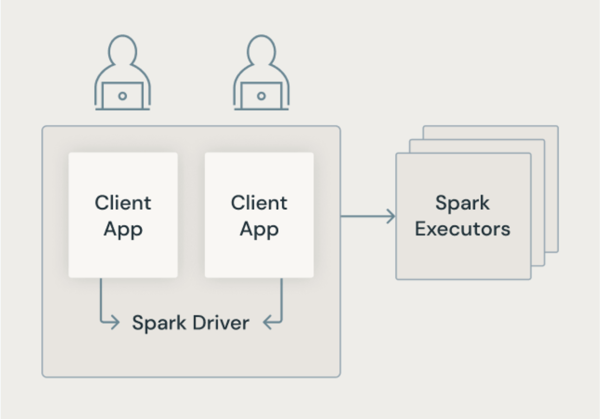
Klassisk Spark-arkitektur
Följande bild visar hur användarprogram i den traditionella Spark-arkitekturen delar en JVM med privilegierad åtkomst till den underliggande datorn.
Lakeguard-arkitektur
Lakeguard isolerar all användarkod med hjälp av säkra containrar. Detta gör att flera arbetsbelastningar kan köras på samma beräkningsresurs samtidigt som strikt isolering mellan användare upprätthålls.
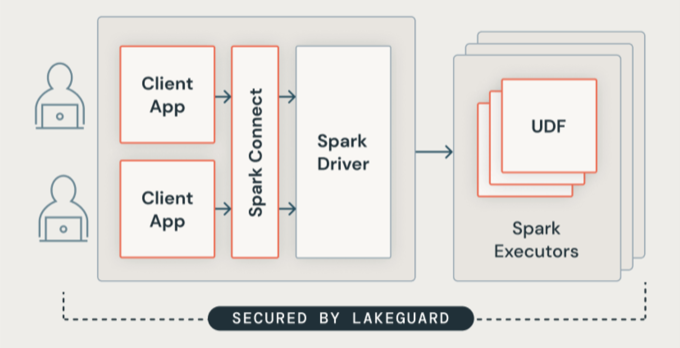
Spark-klientisolering
Lakeguard isolerar klientprogram från Spark-drivrutinen och från varandra med hjälp av två viktiga komponenter:
Spark Connect: Lakeguard använder Spark Connect (introducerades med Apache Spark 3.4) för att frikoppla klientprogram från drivrutinen. Klientprogram och drivrutiner delar inte längre samma JVM eller classpath. Den här separationen förhindrar obehörig dataåtkomst. Den här designen hindrar också användare från att komma åt data som resulterar i överhämtning när frågor inkluderar filter på rad- eller kolumnnivå.
Anmärkning
Spark Connect skjuter upp analys och namnupplösning till exekveringstid, vilket kan förändra hur din kod beter sig. Se Jämför Spark Connect med Spark Classic.
Sandbox-miljö för containrar: Varje klientprogram körs i sin egen isolerade containermiljö. Detta hindrar användarkod från att komma åt andra användares data eller den underliggande datorn. Sandbox-miljön använder containerbaserade isoleringstekniker för att skapa säkra gränser mellan användare.
UDF-isolering
Spark-kören isolerar som standard inte UDF:er. Denna brist på isolering kan göra det möjligt för UDF:er att skriva filer eller komma åt den underliggande datorn.
Lakeguard isolerar användardefinierad kod, inklusive UDF:er, på Spark-utförare genom att:
- Sandbox-miljö för körning på Spark-utförare.
- Isolera utgående nätverkstrafik från UDF:er för att förhindra obehörig extern åtkomst.
- Replikera klientmiljön till UDF-sandbox-miljön så att användarna kan komma åt nödvändiga bibliotek.
Den här isoleringen gäller för UDF:er för standardberäkning och python-UDF:er på serverlösa beräknings- och SQL-lager.