Anteckning
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Viktigt!
Översättningar som inte är engelska tillhandahålls endast för enkelhetens skull. Se versionen EN-US av det här dokumentet för bindningsversionen.
I det här avsnittet går vi igenom vad noggrannhet innebär för OCR och hur du utvärderar det för din kontext.
Precisionsmått på Word-nivå
Texten består av rader, ord och tecken. Ett populärt mått på noggrannhet för OCR är ordfelfrekvens (WER), eller hur många ord som har blivit felaktigt utskrivna i det extraherade resultatet. Ju lägre WER, desto högre noggrannhet.
WER definieras som:
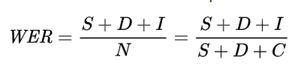
Var:
| Begrepp | Definition | Exempel |
|---|---|---|
| S | Antal felaktiga ord ("ersatt") i utdata. | "Velvet" extraheras som "Veivet" eftersom "l" identifieras som "i". |
| D | Antal saknade ("borttagna") ord i utdata. | För texten "Företagsnamn: Microsoft" extraheras inte Microsoft eftersom det är handskrivet eller svårt att läsa. |
| Jag | Antal icke-existerande ("infogade") ord i utdata. | "Avdelning" delas felaktigt in i tre ord som "Dep artm ent". I det här fallet är resultatet ett borttaget ord och tre infogade ord. |
| C | Antal korrekt extraherade ord i utdata. | Alla ord som extraheras korrekt. |
| N | Antal totalt antal ord i referensen (N=S+D+C) exklusive I eftersom dessa ord saknades från den ursprungliga referensen och var felaktigt förutsagda som närvarande. | Tänk dig en bild med meningen "Microsoft, med huvudkontor i Redmond, WA tillkännagav en ny produkt som heter Velvet for finance departments." Anta att OCR-utdata är " , med huvudkontor i Redmond, WA tillkännagav en ny produkt som heter Veivet for finance dep artm ents." I det här fallet S (Velvet) = 1, D (Microsoft) = 1, I (dep artm ents) = 3, C (11) och N = S + D + C = 13. Därför WER = (S + D + I) / N = 5 / 13 = 0,38 eller 38% (av 100). |
Använda ett konfidensvärde
Som beskrivs i ett tidigare avsnitt ger tjänsten ett konfidensvärde för varje förutsagt ord i OCR-utdata. Kunder använder det här värdet för att kalibrera anpassade tröskelvärden för sitt innehåll och sina scenarier för att dirigera innehållet för automatisk bearbetning eller skicka det vidare till human-in-the-loop-processen. De resulterande mätningarna avgör den scenariospecifika noggrannheten.
Scenarioexempel för OCR-systemprestanda
Prestandakonsekvenserna för OCR-systemet kan variera beroende på scenarier där OCR-tekniken tillämpas. Vi går igenom några exempel för att illustrera det konceptet.
- Efterlevnad av medicinska enheter: I det här första exemplet måste ett multinationellt läkemedelsföretag med en mängd olika produktportföljer med patent, enheter, mediciner och behandlingar analysera FDA-kompatibel produktetikettinformation och analysresultatdokument. Företaget kanske föredrar ett tröskelvärde med lågt konfidensvärde för att tillämpa human-in-the-loop eftersom kostnaden för felaktigt extraherade data kan ha betydande inverkan för konsumenter och böter från tillsynsmyndigheter.
- Bild- och dokumentbearbetning: I det här andra exemplet utför ett företag bearbetning av försäkrings- och låneprogram. Kunden som använder OCR kanske föredrar ett tröskelvärde för medelhögt konfidensvärde eftersom den automatiserade textextraheringen kombineras nedströms med andra informationsindata och steg från människa i loopen för en holistisk granskning av program.
- Innehållsmoderering: För en stor mängd e-handelskatalogdata som importerats från leverantörer i stor skala kanske kunden föredrar ett tröskelvärde med högt förtroendevärde med hög noggrannhet eftersom även en liten andel falskt flaggat innehåll kan generera mycket omkostnader för sina mänskliga granskningsteam och leverantörer.
Systembegränsningar och metodtips för att förbättra systemprestanda
Tjänsten stöder bilder (JPEG, PNG och BMP) och dokument (PDF och TIFF). De tillåtna gränserna för antal sidor, bildstorlekar, pappersstorlekar och filstorlekar visas på översiktssidan för OCR.
Dokumentgenomsökningens kvalitet, upplösning, kontrast, ljusförhållanden, rotation och textattribut som storlek, färg och densitet kan påverka ocr-resultatens noggrannhet. Vi rekommenderar till exempel att bilden är minst 50 x 50 bildpunkter. Kunder bör referera till produktspecifikationerna och testa tjänsten på sina dokument för att verifiera lämpligheten för deras situation.
I följande exempel visas några svåra fall för OCR där du ser missade och felaktiga textextraheringar.

Den aktuella versionen stöder endast handskrift eller kursiv text för engelska. Den här begränsningen påverkar även eventuella relaterade funktioner, till exempel klassificering i utskrifts- och handskriftsstil (förhandsversion) för varje textrad.
OCR:s prestanda varierar beroende på den verkliga användning som kunderna implementerar. För att säkerställa optimala prestanda i sina scenarier bör kunderna göra sina egna utvärderingar av de lösningar som de implementerar med hjälp av OCR. Tjänsten ger ett konfidensvärde i intervallet mellan 0 och 1 för varje identifierat ord som ingår i OCR-utdata. Kunder bör skanna en exempeldatauppsättning som representerar deras innehåll för att få en uppfattning om intervallet för konfidenspoäng och den resulterande extraheringskvaliteten. De kan sedan besluta om tröskelvärdena för konfidensvärdet för att avgöra om resultaten ska skickas för direkt bearbetning (STP) eller granskas av en människa. Kunden kan till exempel skicka resultat med ett konfidensvärde som är större än eller lika med 0,80 för direkt bearbetning och tillämpa mänsklig granskning på resultat med ett konfidensvärde som är mindre än 0,80.