Anteckning
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Viktigt!
- Azure AI Content Understanding är tillgängligt som förhandsversion. Offentliga förhandsversioner ger tidig åtkomst till funktioner som är i aktiv utveckling.
- Funktioner, metoder och processer kan ändra eller ha begränsade funktioner innan allmän tillgänglighet (GA).
- Mer information finns i Kompletterande användningsvillkor för Förhandsversioner av Microsoft Azure.
Med Azure AI Content Understanding kan du generera en standarduppsättning videometadata och skapa anpassade fält för ditt specifika användningsfall med hjälp av generativa modeller. Content Understanding hjälper till att effektivt hantera, kategorisera, hämta och skapa arbetsflöden för videotillgångar. Det förbättrar medietillgångsbiblioteket, stöder arbetsflöden som markeringsgenerering, kategoriserar innehåll och underlättar program som hämtningsförhöjd generation (RAG).
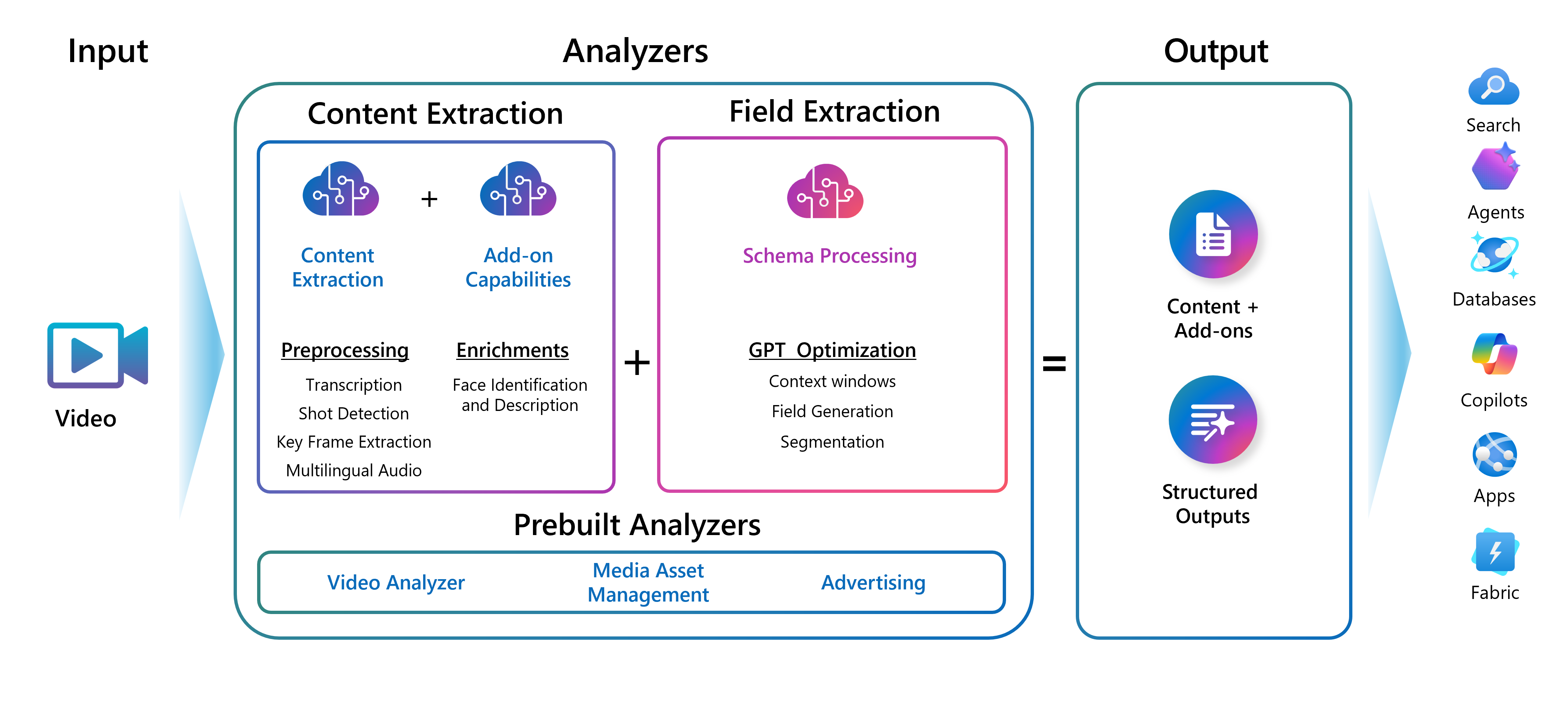
Den förbyggda videoanalysatorn levererar RAG-redo Markdown som innehåller:
- Avskrift: Infogade avskrifter i standardformat för WEBVTT
- Beskrivning: Segmentbeskrivningar med naturligt språk med visuell kontext och talkontext
- Segmentering: Automatisk scensegmentering som delar upp videon i logiska segment
- Nyckelramar: Ordnade miniatyrbilder för nyckelramar som möjliggör djupare analys
Det här formatet kan skickas direkt till ett vektorlager för att aktivera en agent eller RAG-arbetsflöden – ingen efterbearbetning krävs.
Därifrån kan du anpassa analysatorn för mer detaljerad kontroll av utdata. Du kan definiera anpassade fält, segment eller aktivera ansiktsidentifiering. Med anpassning kan du använda den fulla kraften i generativa modeller för att extrahera djupa insikter från videons visuella och ljudinformation.
Med anpassning kan du till exempel:
- Definiera anpassade fält: för att identifiera vilka produkter och varumärken som visas eller nämns i videon.
- Generera anpassade segment: för att segmentera en nyhetssändning i kapitel baserat på de ämnen eller nyheter som diskuteras.
-
Identifiera personer som använder en personkatalog så att en kund kan märka konferenstalare i bilder med hjälp av ansiktsidentifiering,
CEO John Doetill exempel ,CFO Jane Smith.
Varför ska du använda Content Understanding för video?
Innehållstolkning för video har många potentiella användningsområden. Du kan till exempel anpassa metadata för att tagga specifika scener i en träningsvideo, vilket gör det enklare för anställda att hitta och gå tillbaka till viktiga avsnitt. Du kan också använda metadataanpassning för att identifiera produktplacering i kampanjvideor, vilket hjälper marknadsföringsteam att analysera varumärkesexponering. Ta med användarfall omfattar:
- Sändningsmedia och underhållning: Hantera stora bibliotek med shower, filmer och klipp genom att generera detaljerade metadata för varje mediaresurs.
- Utbildning och e-learning: Index och hämta specifika ögonblick i utbildningsvideor eller föreläsningar.
- Företagsutbildning: Organisera träningsvideor efter viktiga ämnen, scener eller viktiga ögonblick.
- Marknadsföring och reklam: Analysera kampanjvideor för att extrahera produktplaceringar, varumärkesframträdanden och viktiga meddelanden.
Exempel på fördefinierad videoanalys
Med den fördefinierade videoanalysatorn (prebuilt-videoAnalyzer) kan du ladda upp en video och få en omedelbart användbar kunskapstillgång. Tjänsten paketar varje klipp i både rikt formaterad Markdown och JSON. Med den här processen kan sökindexet eller chattagenten matas in utan anpassad limkod.
Du kan till exempel skapa basen
prebuilt-videoAnalyzerpå följande sätt:{ "config": {}, "BaseAnalyzerId": "prebuilt-videoAnalyzer", }Därefter skulle analys av en 30-sekunders reklamvideo resultera i följande utdata:
# Video: 00:00.000 => 00:30.000 Width: 1280 Height: 720 ## Segment 1: 00:00.000 => 00:06.000 A lively room filled with people is shown, where a group of friends is gathered around a television. They are watching a sports event, possibly a football match, as indicated by the decorations and the atmosphere. Transcript WEBVTT 00:03.600 --> 00:06.000 <Speaker 1>Get new years ready. Key Frames - 00:00.600  - 00:01.200  ## Segment 2: 00:06.000 => 00:10.080 The scene transitions to a more vibrant and energetic setting, where the group of friends is now celebrating. The room is decorated with football-themed items, and everyone is cheering and enjoying the moment. Transcript WEBVTT 00:03.600 --> 00:06.000 <Speaker 1>Go team! Key Frames - 00:06.200  - 00:07.080  *…additional data omitted for brevity…*
Genomgång
Vi publicerade nyligen en genomgång för RAG on Video med hjälp av Content Understanding. https://www.youtube.com/watch?v=fafneWnT2kw& lc=Ugy2XXFsSlm7PgIsWQt4AaABAg
Förmågor
Under huven omvandlar två steg råa pixlar till affärsklara insikter. Diagrammet nedan visar hur extrahering matar generering, vilket säkerställer att varje nedströmssteg har den kontext som behövs.
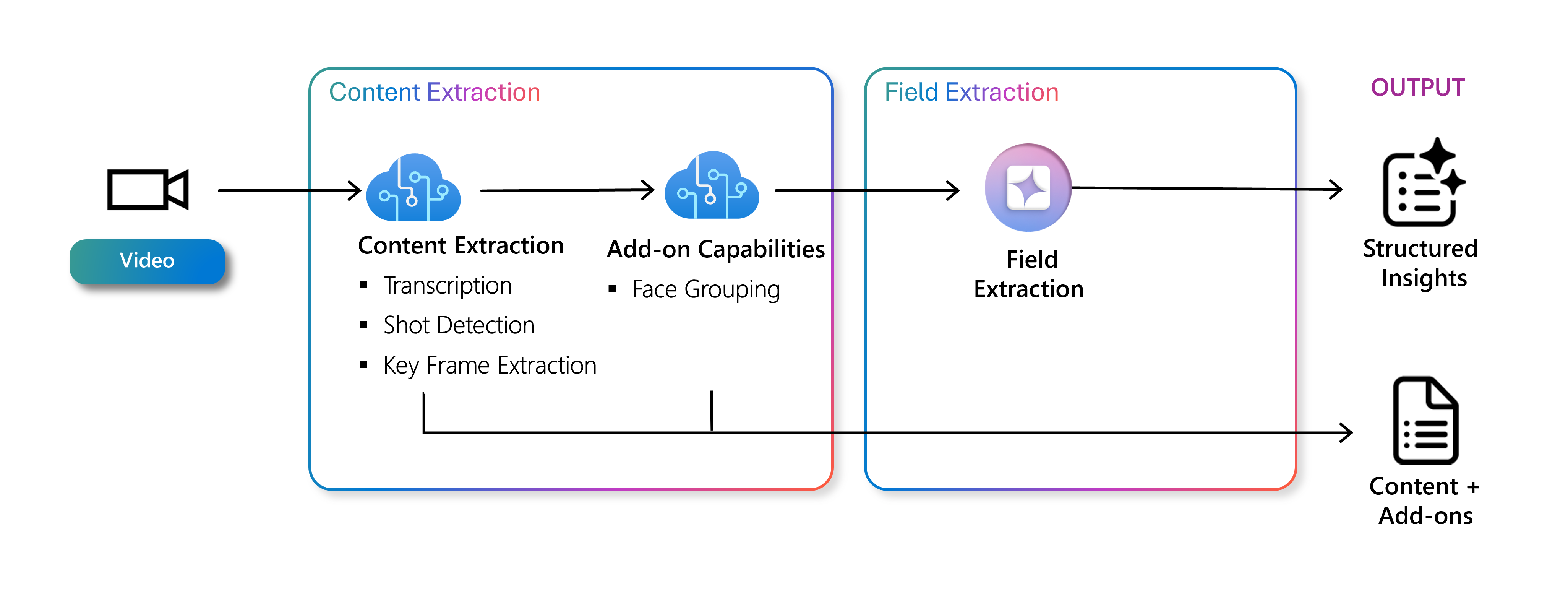
Tjänsten körs i två steg. Det första steget, extrahering av innehåll, handlar om att samla in grundläggande metadata, till exempel transkriptioner, bilder och ansikten. Den andra fasen, fältextrahering, använder en generativ modell för att skapa anpassade fält och utföra segmentering. Du kan också aktivera ett ansiktstillägg för att identifiera individer och beskriva dem i videon.
Funktioner för extrahering av innehåll
Det första passet handlar om att extrahera en första uppsättning detaljer – vem som talar, var är snitten och vilka ansikten som återkommer. Det skapar en solid metadataryggrad som senare steg kan resonera över.
Transkription: Konverterar konversationsljud till sökbara och analysbara textbaserade transkriptioner i WebVTT-format. Tidsstämplar på meningsnivå är tillgängliga om
"returnDetails": trueär inställt. Content Understanding stöder den fullständiga uppsättningen tal till text-språk i Azure AI. Information om språkstöd för video är samma som ljud, seSpråkhantering för ljud för mer information. Följande transkriptionsinformation är viktig att tänka på:Diarisering: Skiljer mellan talare i en konversation i utdata och tillskriver delar av avskriften till specifika talare.
Flerspråkig transkription: Genererar flerspråkiga avskrifter. Språk och lokala inställningar tillämpas per fras i utskriften. Utdatafraser när
"returnDetails": trueär inställd. Avvikande från språkigenkänning aktiveras den här funktionen när varken språk eller lokal har angetts, eller om språket är inställt påauto.Anmärkning
När flerspråkig transkription används ger alla filer med nationella inställningar som inte stöds ett resultat baserat på närmaste språk som stöds, vilket sannolikt är felaktigt. Det här resultatet är ett känt beteende. Undvik transkriptionskvalitetsproblem genom att se till att du konfigurerar nationella inställningar när du inte använder en flerspråkig transkription som stöds.
Nyckelramextraktion: Extraherar nyckelramar från videor för att helt representera varje tagning, vilket säkerställer att varje tagning har tillräckligt med nyckelramar för att fältextraheringen ska fungera effektivt.
Skottdetektering: Identifierar videosegment som är i linje med klippgränser där det är möjligt, vilket möjliggör exakt redigering och ompaketering av innehåll med pauser som exakt matchar befintliga redigeringar. Utdata är en lista över tidsstämplar i millisekunder i
cameraShotTimesMs. Utdata returneras endast när"returnDetails": truehar angetts.
Extrahering och segmentering av fält
Därefter lägger de generativa modellskikten lager av betydelse – taggar scener, sammanfattar handlingar och delar upp filmklipp i segment enligt din begäran. I den här åtgärden omvandlas frågor till strukturerade data.
Anpassade fält
Forma utdata så att de matchar företagets vokabulär. Använd ett fieldSchema objekt där varje post definierar ett fälts namn, typ och beskrivning. Under körning fyller den generativa modellen dessa fält för varje segment.
Exempel:
Hantering av medietillgångar:
- Videokategori: Hjälper redaktörer och producenter att organisera innehåll genom att klassificera det som Nyheter, Sport, Intervju, Dokumentär, Annons osv. Användbart för metadatataggning och snabbare innehållsfiltrering och hämtning.
- Färgschema: Förmedlar stämning och atmosfär, viktigt för narrativ konsekvens och läsarengagemang. Genom att identifiera färgteman kan du hitta matchande klipp för snabbare videoredigering.
Reklam:
- Märke: Identifierar varumärkesnärvaro, kritisk för att analysera annonspåverkan, varumärkessynlighet och association med produkter. Den här funktionen gör det möjligt för annonsörer att utvärdera varumärkesstatus och säkerställa efterlevnad av varumärkesriktlinjer.
- Annonskategorier: Kategoriserar annonstyper efter bransch, produkttyp eller målgruppssegment, som stöder riktade annonseringsstrategier, kategorisering och prestandaanalys.
Exempel:
"fieldSchema": {
"description": "Extract brand presence and sentiment per scene",
"fields": {
"brandLogo": {
"type": "string",
"method": "generate",
"description": "Brand being promoted in the video. Include the product name if available."
},
"Sentiment": {
"type": "string",
"method": "classify",
"description": "Ad categories",
"enum": [
"Consumer Packaged Goods",
"Groceries",
"Technology"
]
}
}
}
Segmenteringsläge
Anmärkning
Om du anger segmentering utlöses fältextrahering även om inga fält har definierats.
Content Understanding erbjuder tre sätt att dela upp en video så att du kan få utdata som du behöver för hela videor eller korta klipp. Du kan använda de här alternativen genom att ange egenskapen SegmentationMode på en anpassad analysator.
Hel video –
segmentationMode : noSegmentationTjänsten behandlar hela videofilen som ett enda segment och extraherar metadata under hela dess varaktighet.Exempel:
- Efterlevnadskontroller som söker efter specifika varumärkessäkerhetsproblem var som helst i en annons
- beskrivande sammanfattningar i full längd
Automatisk segmentering –
segmentationMode = autoTjänsten analyserar tidslinjen och delar upp den åt dig. Grupperar efterföljande skott i sammanhängande scener, begränsade till en minut vardera.Exempel:
- Skapa storyboards från en show
- Infoga annonser i mitten av rulle vid logiska pauser.
Anpassad segmentering –
segmentationMode : customDu beskriver logiken i naturligt språk och modellen skapar segment som ska matchas. AngesegmentationDefinitionmed en sträng som beskriver hur du vill att videon ska segmenteras. Anpassad inställning tillåter segment av varierande längd från sekunder till minuter beroende på frågan.Exempel:
- Dela upp en nyhetssändning i berättelser.
{ "segmentationMode": "custom", "segmentationDefinition": "news broadcasts divided by individual stories" }
Tillägg för ansiktsidentifiering och beskrivning
Anmärkning
Den här funktionen är begränsad åtkomst och omfattar ansiktsidentifiering och gruppering. kunder måste registrera sig för åtkomst på Ansiktsigenkänning. Ansiktsegenskaper medför extra kostnader.
Beskrivning av ansiktsidentifiering är ett tillägg som ger kontext till extrahering av innehåll och fältextrahering med hjälp av ansiktsinformation.
Extrahering av innehåll – Gruppering och identifiering
Ansiktstillägget möjliggör gruppering och identifiering som utdata från avsnittet om extrahering av innehåll. För att aktivera ansiktsfunktioner, ställ in "enableFace":true i analyskonfigurationen.
-
Gruppering: Grupperade ansikten visas i en video för att extrahera en representativ ansiktsbild för varje person och tillhandahåller segment där var och en finns. Grupperade ansiktsdata är tillgängliga som metadata och kan användas för att generera anpassade metadatafält när
returnDetails: truedet gäller analysatorn. -
Identifikation: Etiketter personer i videon med namn baserat på en ansikts-API-personkatalog. Kunder kan aktivera den här funktionen genom att ange ett namn för en Face API-katalog i den aktuella resursens
personDirectoryId-egenskap i analysatorn. Om du vill använda den här funktionen måste du först skapa en personDirectory och sedan referera till den i analysatorn. Mer information om hur du gör det finns i Skapa en personkatalog
Fältextrahering – Ansiktsbeskrivning
Funktionen för fältextrahering förbättras genom att ge detaljerade beskrivningar av identifierade ansikten i videon. Den här funktionen innehåller attribut som ansiktshår, känslor och förekomsten av kändisar, vilket kan vara avgörande för olika analys- och indexeringsändamål. För att aktivera ansiktsbeskrivningsfunktioner, ställ in disableFaceBlurring : true i analyskonfigurationen.
Exempel:
-
Exempelfält: emotionDescription: Innehåller en beskrivning av den primära personens känslotillstånd i det här klippet (till exempel
happy,sad,angry) -
Exempelfält: facialHairDescription: Beskriver typen av ansiktshår (till exempel
beard,mustache,clean-shaven)
Viktiga fördelar
Content Understanding ger flera viktiga fördelar jämfört med andra lösningar för videoanalys:
- Segmentbaserad analys med flera ramar: Identifiera åtgärder, händelser, ämnen och teman genom att analysera flera bildrutor från varje videosegment i stället för enskilda bildrutor.
- Kundanpassning: Anpassa fälten och segmenteringen som du genererar genom att ändra schemat i enlighet med ditt specifika användningsfall.
- Generativa modeller: Beskriv på naturligt språk vilket innehåll du vill extrahera, och Content Understanding använder generativa modeller för att extrahera dessa metadata.
- Optimerad förbearbetning: Utför flera förbearbetningssteg för innehållsextrahering, till exempel transkription och scenidentifiering, optimerade för att ge omfattande kontext till AI-generativa modeller.
Tekniska begränsningar
Specifika begränsningar för videobearbetning att tänka på:
- Ramsampling (~ 1 FPS): Analysatorn inspekterar ungefär en bildruta per sekund. Snabba rörelser, eller enbildshändelser, kan missas.
- Bildruteupplösning (512 × 512 px): Samplade bildrutor ändras till 512 bildpunkter kvadratiska. Små textobjekt eller avlägsna objekt kan gå förlorade.
- Tal: Endast talade ord transkriberas. Musik, ljudeffekter och omgivande brus ignoreras.
Indatakrav
Information om format som stöds finns i Tjänstkvoter och -gränser.
Språk och regioner som stöds
Datasekretess och säkerhet
Precis som med alla Azure AI-tjänster läser du Microsofts dokumentation om data, skydd och sekretess .
Viktigt!
Om du bearbetar biometriska data (till exempel aktivera ansiktsgruppering eller ansiktsidentifiering) måste du uppfylla alla krav på meddelande, medgivande och borttagning enligt GDPR eller andra tillämpliga lagar. Se Data och sekretess för Ansiktsigenkänning.
Nästa steg
Bearbeta videor i Azure AI Foundry-portalen.
Snabbstart: Analysera videoinnehåll med analysmallar.
Prover: