Analysera api-svar för dokument
Det här innehållet gäller för: ![]() v4.0 (förhandsversion)
v4.0 (förhandsversion) ![]() v3.1 (GA)
v3.1 (GA) ![]() v3.0 (GA)
v3.0 (GA)
I den här artikeln ska vi undersöka de olika objekt som returneras som en del av AnalyzeDocument svaret och hur du använder api-svaret för dokumentanalys i dina program.
Analysera dokumentbegäran
API:erna för dokumentinformation analyserar bilder, PDF-filer och andra dokumentfiler för att extrahera och identifiera olika innehåll, layout, format och semantiska element. Analysåtgärden är ett asynkront API. När du skickar ett dokument returneras en rubrik för åtgärdsplats som innehåller url:en som ska avsökas för slutförande. När en analysbegäran har slutförts innehåller svaret de element som beskrivs i modelldataextraheringen.
Svarselement
Innehållselement är de grundläggande textelement som extraheras från dokumentet.
Layoutelement grupperar innehållselement i strukturella enheter.
Formatelement beskriver teckensnitt och språk för innehållselement.
Semantiska element tilldelar innebörden till de angivna innehållselementen.
Alla innehållselement grupperas enligt sidor, angivna efter sidnummer (1indexerat). De sorteras också efter läsordning som ordnar semantiskt sammanhängande element, även om de korsar linje- eller kolumngränser. När läsordningen mellan stycken och andra layoutelement är tvetydig returnerar tjänsten vanligtvis innehållet i en ordning från vänster till höger, uppifrån och ned.
Kommentar
Dokumentinformation stöder för närvarande inte läsordning över sidgränser. Markeringsmarkeringar placeras inte inom de omgivande orden.
Den översta innehållsegenskapen innehåller en sammanlänkning av alla innehållselement i läsordning. Alla element anger sin position i läsarordningen via intervall i den här innehållssträngen. Innehållet i vissa element är inte alltid sammanhängande.
Analysera svar
Analyssvaret för varje API returnerar olika objekt. API-svar innehåller element från komponentmodeller där det är tillämpligt.
| Svarsinnehåll | beskrivning | API |
|---|---|---|
| Sidor | Ord, rader och intervall identifieras från varje sida i indatadokumentet. | Läs-, layout-, allmänt dokument-, fördefinierade och anpassade modeller |
| Punkterna | Innehåll som identifieras som stycken. | Läs-, layout-, allmänt dokument-, fördefinierade och anpassade modeller |
| Stilar | Identifierade egenskaper för textelement. | Läs-, layout-, allmänt dokument-, fördefinierade och anpassade modeller |
| Språk | Identifierat språk som är associerat med varje intervall i texten som extraherats | Lästa |
| Tabeller | Tabellinnehåll som identifierats och extraherats från dokumentet. Tabeller relaterar till tabeller som identifieras av den förtränad layoutmodellen. Innehåll som är märkt som tabeller extraheras som strukturerade fält i dokumentobjektet. | Modeller för layout, allmänt dokument, faktura och anpassade modeller |
| Siffror | Figurer (diagram, bilder) som identifierats och extraherats från dokumentet, vilket ger visuella representationer som underlättar förståelsen av komplex information. | Layoutmodell |
| sektioner | Hierarkisk dokumentstruktur identifierad och extraherad från dokumentet. Avsnitt eller underavsnitt med motsvarande element (stycke, tabell, figur) kopplade till det. | Layoutmodell |
| keyValuePairs | Nyckel/värde-par som identifieras av en förtränad modell. Nyckeln är ett textintervall från dokumentet med det associerade värdet. | Allmänna dokument- och fakturamodeller |
| Dokument | Identifierade fält returneras i fields ordlistan i listan över dokument |
Fördefinierade modeller, anpassade modeller. |
Mer information om de objekt som returneras av varje API finns i extrahering av modelldata.
Elementegenskaper
Spänner över
Intervall anger den logiska positionen för varje element i den övergripande läsordningen, där varje intervall anger en teckenförskjutning och längd i den översta innehållssträngsegenskapen. Som standard returneras teckenförskjutningar och längder i enheter med användarupplevda tecken (även kallade grapheme clusters eller textelement). För att hantera olika utvecklingsmiljöer som använder olika teckenenheter kan användaren ange stringIndexIndex frågeparametern för att returnera intervallförskjutningar och längder i Unicode-kodpunkter (Python 3) eller UTF16-kodenheter (Java, JavaScript, .NET). Mer information finns i stöd för flerspråkiga/emojier.
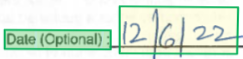
Avgränsningsregion
Avgränsningsregioner beskriver den visuella positionen för varje element i filen. När element inte är visuellt sammanhängande eller korssidor (tabeller) beskrivs positionerna för de flesta element via en matris med avgränsningsregioner. Varje region anger sidnumret (1indexerat) och avgränsningspolygonen. Avgränsningspolygonen beskrivs som en sekvens med punkter, medsols från vänster i förhållande till elementets naturliga orientering. För quadrilaterals är ritpunkter övre vänstra, övre högra, nedre högra och nedre vänstra hörnen. Varje punkt representerar dess x- och y-koordinat i den sidenhet som anges av enhetsegenskapen. I allmänhet är måttenhet för bilder bildpunkter medan PDF-filer använder tum.
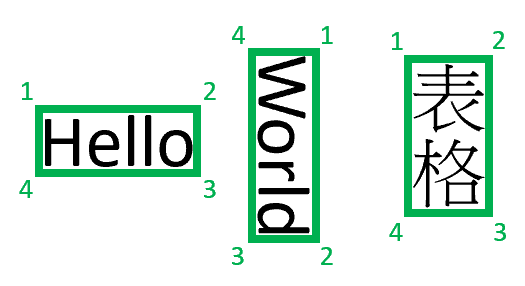
Kommentar
För närvarande returnerar Dokumentinformation endast fyrhörn quadrilateraler som avgränsningspolygoner. Framtida versioner kan returnera olika antal punkter för att beskriva mer komplexa former, till exempel böjda linjer eller icke-rektangulära bilder. Avgränsningsregioner som endast tillämpas på renderade filer, om filen inte återges returneras inte avgränsningsregioner. Filer med docx/xlsx/pptx/html-format återges för närvarande inte.
Innehållselement
Word
Ett ord är ett innehållselement som består av en sekvens med tecken. Med Dokumentinformation definieras ett ord som en sekvens med intilliggande tecken, där blanksteg separerar ord från varandra. För språk som inte använder blankstegsavgränsare mellan ord returneras varje tecken som ett separat ord, även om det inte representerar en semantisk ordenhet.

Markeringsmarkeringar
Ett markeringsmärke är ett innehållselement som representerar ett visuellt tecken som anger tillståndet för en markering. Kryssrutan är en vanlig form av markeringsmarkeringar. Men de representeras också via alternativknappar eller en rutad cell i ett visuellt formulär. Tillståndet för en markeringsmarkering kan markeras eller avmarkeras, med en annan visuell representation för att ange tillståndet.

Layoutelement
Rad
En rad är en ordnad sekvens med efterföljande innehållselement avgränsade med ett visuellt blanksteg, eller de som omedelbart ligger intill för språk utan utrymmesavgränsare mellan ord. Innehållselement i samma vågräta plan (rad) men avgränsade med mer än ett enda visuellt utrymme delas oftast upp i flera rader. Även om den här funktionen ibland delar upp semantiskt sammanhängande innehåll i separata rader, möjliggör den representation av textinnehåll uppdelat i flera kolumner eller celler. Linjer i lodrät skrivning identifieras i lodrät riktning.

Stycke
Ett stycke är en ordnad sekvens med rader som utgör en logisk enhet. Vanligtvis delar raderna gemensam justering och avstånd mellan linjer. Stycken avgränsas ofta via indrag, extra avstånd eller punkter/numrering. Innehåll kan bara tilldelas till ett enda stycke. Markera stycken kan också associeras med en funktionell roll i dokumentet. Roller som stöds för närvarande är sidhuvud, sidfot, sidnummer, rubrik, avsnittsrubrik och fotnot.

Sida
En sida är en gruppering av innehåll som vanligtvis motsvarar en sida av ett pappersark. En renderad sida kännetecknas av bredd och höjd i den angivna enheten. I allmänhet använder bilder pixel medan PDF-filer använder tum. Vinkelegenskapen beskriver den övergripande textvinkeln i grader för sidor som kan roteras.
Kommentar
För kalkylblad som Excel mappas varje blad till en sida. För presentationer, till exempel PowerPoint, mappas varje bild till en sida. För filformat utan ett inbyggt begrepp med sidor utan återgivning som HTML- eller Word-dokument betraktas huvudinnehållet i filen som en enda sida.
Register
En tabell ordnar innehållet i en grupp celler i en rutnätslayout. Raderna och kolumnerna kan avgränsas visuellt med rutnätslinjer, färgband eller större avstånd. Positionen för en tabellcell anges via dess rad- och kolumnindex. En cell kan sträcka sig över flera rader och kolumner.
Baserat på dess position och formatering kan en cell klassificeras som allmänt innehåll, radrubrik, kolumnrubrik, stub-huvud eller beskrivning:
En radrubrikcell är vanligtvis den första cellen i en rad som beskriver de andra cellerna i raden.
En kolumnrubrikcell är vanligtvis den första cellen i en kolumn som beskriver de andra cellerna i en kolumn.
En rad eller kolumn kan innehålla flera rubrikceller för att beskriva hierarkiskt innehåll.
En stub-huvudcell är vanligtvis cellen i den första raden och den första kolumnpositionen. Den kan vara tom eller beskriva värdena i rubrikcellerna i samma rad/kolumn.
En beskrivningscell visas vanligtvis längst upp eller längst ned i en tabell och beskriver det övergripande tabellinnehållet. Det kan dock ibland visas i mitten av en tabell för att dela upp tabellen i avsnitt. Normalt sträcker sig beskrivningsceller över flera celler i en enda rad.
En tabellrubrik anger innehåll som förklarar tabellen. En tabell kan dessutom ha en associerad bildtext och en uppsättning fotnoter. Till skillnad från en beskrivningscell ligger en bildtext vanligtvis utanför rutnätslayouten. En tabellfotnot kommenterar innehåll i tabellen, ofta märkt med en fotnotssymbol som ofta finns under tabellrutnätet.
Layouttabeller skiljer sig från dokumentfält som extraherats från tabelldata. Layouttabeller extraheras från tabellvisualiseringsinnehåll i dokumentet utan att ta hänsyn till innehållets semantik. I själva verket är vissa layouttabeller utformade enbart för visuell layout och innehåller inte alltid strukturerade data. Metoden för att extrahera strukturerade data från dokument med olika visuell layout, till exempel specificerad information om ett kvitto, kräver vanligtvis betydande efterbearbetning. Det är viktigt att mappa rad- eller kolumnrubrikerna till strukturerade fält med normaliserade fältnamn. Beroende på dokumenttyp använder du fördefinierade modeller eller tränar en anpassad modell för att extrahera sådant strukturerat innehåll. Den resulterande informationen visas som dokumentfält. Sådana tränade modeller kan också hantera tabelldata utan rubriker och strukturerade data i icke-tabellform, till exempel avsnittet arbetsupplevelse i ett CV.

Siffror
Siffror (diagram, bilder) i dokument spelar en avgörande roll när det gäller att komplettera och förbättra textinnehållet, vilket ger visuella representationer som underlättar förståelsen av komplex information. Figurobjektet som identifieras av layoutmodellen har nyckelegenskaper som boundingRegions (figurens rumsliga platser på dokumentsidorna, inklusive sidnumret och polygonkoordinaterna som beskriver figurens gräns), spans (beskriver textintervallen som är relaterade till figuren och anger deras förskjutningar och längder i dokumentets text. Den här anslutningen hjälper till att associera figuren med dess relevanta textkontext), elements (identifierarna för textelement eller stycken i dokumentet som är relaterade till eller beskriver figuren) och caption om det finns några.
{
"figures": [
{
"boundingRegions": [],
"spans": [],
"elements": [
"/paragraphs/15",
...
],
"caption": {
"content": "Here is a figure with some text",
"boundingRegions": [],
"spans": [],
"elements": [
"/paragraphs/15"
]
}
}
]
}
Avsnitt
Hierarkisk dokumentstrukturanalys är avgörande för att organisera, förstå och bearbeta omfattande dokument. Den här metoden är viktig för att semantiskt segmentera långa dokument för att öka förståelsen, underlätta navigeringen och förbättra informationshämtningen. Tillkomsten av RAG (Retrieval Augmented Generation) i dokumentgenerativ AI understryker betydelsen av hierarkisk dokumentstrukturanalys. Layoutmodellen stöder avsnitt och underavsnitt i utdata, som identifierar relationen mellan avsnitt och objekt i varje avsnitt. Den hierarkiska strukturen underhålls i elements varje avsnitt.
{
"sections": [
{
"spans": [],
"elements": [
"/paragraphs/0",
"/sections/1",
"/sections/2",
"/sections/5"
]
},
...
}
Formulärfält (nyckelvärdepar)
Ett formulärfält består av en fältetikett (nyckel) och ett värde. Fältetiketten är vanligtvis en beskrivande textsträng som beskriver innebörden av fältet. Det visas ofta till vänster om värdet, även om det också kan visas över eller under värdet. Fältvärdet innehåller innehållsvärdet för en specifik fältinstans. Värdet kan bestå av ord, markeringsmarkeringar och andra innehållselement. Den kan också vara tom för ofyllda formulärfält. En särskild typ av formulärfält har ett markeringsmarkeringsvärde med fältetiketten till höger. Dokumentfältet är ett liknande men distinkt begrepp från allmänna formulärfält. Fältetiketten (nyckeln) i ett allmänt formulärfält måste visas i dokumentet. Därför kan den inte i allmänhet samla in information som handelsnamnet i ett kvitto. Dokumentfält är märkta och extraherar ingen nyckel. Dokumentfält mappar endast ett extraherat värde till en märkt nyckel. Mer information finns i dokumentfält.

Formatelement
Format
Ett formatelement beskriver teckensnittsformatet som ska tillämpas på textinnehåll. Innehållet anges via intervall i den globala innehållsegenskapen. För närvarande är det enda identifierade teckensnittsformatet om texten är handskriven. När andra formatmallar läggs till kan text beskrivas via flera icke-konfigurationsformatobjekt. För kompakthet beskrivs all text som delar det specifika teckensnittsformatet (med samma konfidens) via ett enda formatobjekt.
{
"confidence": 1,
"spans": [
{
"offset": 2402,
"length": 7
}
],
"isHandwritten": true
}
Språk
Ett språkelement beskriver det identifierade språket för innehåll som anges via intervall i den globala innehållsegenskapen. Det identifierade språket anges via en BCP-47-språktagg för att ange primärt språk och valfri skript- och regioninformation. Till exempel identifieras engelska och traditionella kinesiska som "en" respektive zh-Hant. Regionala stavningsskillnader för engelska i Storbritannien kan leda till att text identifieras som en-GB. Språkelement täcker inte text utan ett dominerande språk (t.ex. siffror).
Semantiska element
Kommentar
De semantiska element som beskrivs här gäller för fördefinierade modeller för dokumentinformation. Dina anpassade modeller kan returnera olika datarepresentationer. Till exempel kan datum och tid som returneras av en anpassad modell representeras i ett mönster som skiljer sig från iso 8601-standardformatering.
Dokument
Ett dokument är en semantiskt komplett enhet. En fil kan innehålla flera dokument, till exempel flera skatteformulär i en PDF-fil, eller flera kvitton på en enda sida. Ordningen på dokument i filen påverkar dock inte den information som den förmedlar i grunden.
Kommentar
Dokumentinformation stöder för närvarande inte flera dokument på en enda sida.
Dokumenttypen beskriver dokument som delar en gemensam uppsättning semantiska fält, som representeras av ett strukturerat schema, oberoende av dess visuella mall eller layout. Till exempel kan alla dokument av typen "kvitto" innehålla försäljningsnamnet, transaktionsdatumet och transaktionssumman, även om restaurang- och hotellkvitton ofta skiljer sig åt i utseende.
Ett dokumentelement innehåller listan över identifierade fält bland de fält som anges i det semantiska schemat för den identifierade dokumenttypen:
Ett dokumentfält kan extraheras eller härledas. Extraherade fält representeras via det extraherade innehållet och eventuellt dess normaliserade värde, om det kan tolkas.
Ett härledt fält har inte innehållsegenskap och representeras endast via dess värde.
Ett matrisfält innehåller ingen innehållsegenskap. Innehållet kan sammanfogas från innehållet i matriselementen.
Ett objektfält innehåller en innehållsegenskap som anger det fullständiga innehållet som representerar det objekt som kan vara en supermängd av de extraherade underfälten.
Det semantiska schemat för en dokumenttyp beskrivs via de fält som det innehåller. Varje fältschema anges via dess kanoniska namn och värdetyp. Fältvärdetyper inkluderar grundläggande (till exempel sträng), sammansatta (till exempel adress) och strukturerade (till exempel matriser, objekt). Fältvärdetypen anger också den semantiska normalisering som utförs för att konvertera identifierat innehåll till en normaliseringsrepresentation. Normaliseringen kan vara språkberoende.
Grundläggande typer
| Fältvärdetyp | beskrivning | Normaliserad representation | Exempel (Fältinnehåll –> värde) |
|---|---|---|---|
| sträng | Oformaterad text | Samma som innehåll | MerchantName: "Contoso" → "Contoso" |
| datum | Datum | ISO 8601 – ÅÅÅÅ-MM-DD | InvoiceDate: "2022-05-07" → "2022-05-07" |
| time | Tid | ISO 8601 – hh:mm:ss | TransactionTime: "21:45" → "21:45:00" |
| phoneNumber | Telefonnummer | E.164 – +{CountryCode}{SubscriberNumber} | WorkPhone: "(800) 555-7676" → "+18005557676" |
| countryRegion | Land/region | ISO 3166-1 alfa-3 | CountryRegion: "USA" → "USA" |
| selectionMark | Är markerad | "signerad" eller "osignerad" | AcceptEula: ☑ → "selected" |
| underskrift | Är signerad | Samma som innehåll | LendeeSignature: {signature} → "signerad" |
| Nummer | Flyttalsnummer | Flyttalsnummer | Kvantitet: "1,20" → 1,2 |
| integer | Heltalsnummer | 64-bitars signerat nummer | Antal: "123" → 123 |
| boolean | Booleskt värde | sant/falskt | IsStatutoryEmployee: ☑ → sant |
Sammansatta typer
Valuta: Valutabelopp med valfri valutaenhet. Ett värde, till exempel:
InvoiceTotal: $123.45{ "amount": 123.45, "currencySymbol": "$" }Adress: Parsad adress. Till exempel:
ShipToAddress: 123 Main St., Redmond, WA 98052{ "poBox": "PO Box 12", "houseNumber": "123", "streetName": "Main St.", "city": "Redmond", "state": "WA", "postalCode": "98052", "countryRegion": "USA", "streetAddress": "123 Main St." }
Strukturerade typer
Matris: Lista över fält av samma typ
"Items": { "type": "array", "valueArray": [ ] }Objekt: Namngiven lista över underfält av potentiellt olika typer
"InvoiceTotal": { "type": "currency", "valueCurrency": { "currencySymbol": "$", "amount": 110 }, "content": "$110.00", "boundingRegions": [ { "pageNumber": 1, "polygon": [ 7.3842, 7.465, 7.9181, 7.465, 7.9181, 7.6089, 7.3842, 7.6089 ] } ], "confidence": 0.945, "spans": [ { "offset": 806, "length": 7 } ] }
Nästa steg
Prova att bearbeta dina egna formulär och dokument med Document Intelligence Studio.
Slutför en snabbstart för dokumentinformation och kom igång med att skapa en app för dokumentbearbetning på valfritt utvecklingsspråk.
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för