Skapa och träna en anpassad klassificeringsmodell
Det här innehållet gäller för:![]() v4.0 (förhandsversion) | Tidigare versioner:
v4.0 (förhandsversion) | Tidigare versioner:![]() v3.1 (GA)
v3.1 (GA)![]() v3.0 (GA)
v3.0 (GA)
Viktigt!
Anpassad klassificeringsmodell finns för närvarande i offentlig förhandsversion. Funktioner, metoder och processer kan ändras, före allmän tillgänglighet (GA), baserat på användarfeedback.
Anpassade klassificeringsmodeller kan klassificera varje sida i en indatafil för att identifiera dokument i. Klassificerarmodeller kan också identifiera flera dokument eller flera instanser av ett enda dokument i indatafilen. Anpassade modeller för dokumentinformation kräver så få som fem träningsdokument per dokumentklass för att komma igång. För att komma igång med att träna en anpassad klassificeringsmodell behöver du minst fem dokument för varje klass och två dokumentklasser .
Indatakrav för anpassad klassificeringsmodell
Kontrollera att din träningsdatauppsättning följer indatakraven för Dokumentinformation.
För bästa resultat anger du ett tydligt foto eller en genomsökning av hög kvalitet per dokument.
Filformat som stöds:
Modell PDF Bild:
JPEG/JPG, PNG, BMP, TIFF, HEIFMicrosoft kancelarija:
Word (DOCX), Excel (XLSX), PowerPoint (PPTX) och HTMLLästa ✔ ✔ ✔ Layout ✔ ✔ ✔ (2024-02-29-preview, 2023-10-31-preview) Allmänt dokument ✔ ✔ Inbyggda ✔ ✔ Anpassad extrahering ✔ ✔ Anpassad klassificering ✔ ✔ ✔ (2024-02-29-preview) För PDF och TIFF kan upp till 2 000 sidor bearbetas (med en kostnadsfri nivåprenumeration bearbetas endast de två första sidorna).
Filstorleken för att analysera dokument är 500 MB för den betalda nivån (S0) och 4 MB för den kostnadsfria nivån (F0).
Bilddimensionerna måste vara mellan 50 x 50 bildpunkter och 10 000 px x 10 000 bildpunkter.
Om dina PDF-filer är låsta med lösenord måste du ta bort låset innan du skickar filerna.
Den minsta höjden på texten som ska extraheras är 12 bildpunkter för en bild på 1 024 x 768 bildpunkter. Den här dimensionen motsvarar ungefär
8-punkttext vid 150 punkter per tum (DPI).För anpassad modellträning är det maximala antalet sidor för träningsdata 500 för den anpassade mallmodellen och 50 000 för den anpassade neurala modellen.
För anpassad extraheringsmodellträning är den totala storleken på träningsdata 50 MB för mallmodellen och 1G-MB för den neurala modellen.
För anpassad klassificeringsmodellträning är
1GBden totala storleken på träningsdata med högst 10 000 sidor.
Tips för träningsdata
Följ dessa tips för att ytterligare optimera din datauppsättning för träning:
Använd om möjligt textbaserade PDF-dokument i stället för bildbaserade dokument. Skannade PDF-filer hanteras som bilder.
Om formulärbilderna har lägre kvalitet använder du en större datamängd (till exempel 10–15 bilder).
Ladda upp dina träningsdata
När du har sammanställt uppsättningen formulär eller dokument för träning måste du ladda upp den till en Azure Blob Storage-container. Om du inte vet hur du skapar ett Azure Storage-konto med en container följer du azure storage-snabbstarten för Azure-portalen. Du kan använda den kostnadsfria prisnivån (F0) för att prova tjänsten och uppgradera senare till en betald nivå för produktion. Om datauppsättningen är ordnad som mappar bevarar du den strukturen eftersom Studio kan använda dina mappnamn för etiketter för att förenkla etiketteringsprocessen.
Skapa ett klassificeringsprojekt i Document Intelligence Studio
Document Intelligence Studio tillhandahåller och samordnar alla API-anrop som krävs för att slutföra din datauppsättning och träna din modell.
Börja med att navigera till Document Intelligence Studio. Första gången du använder Studio måste du initiera din prenumeration, resursgrupp och resurs. Följ sedan kraven för anpassade projekt för att konfigurera Studio för åtkomst till din träningsdatauppsättning.
I Studio väljer du panelen Anpassad klassificeringsmodell i avsnittet anpassade modeller på sidan och väljer knappen Skapa ett projekt .
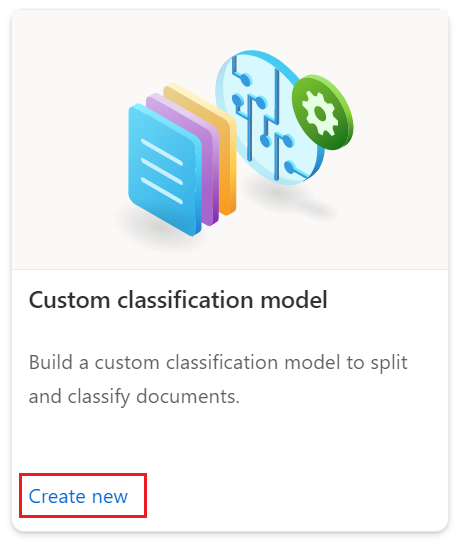
I dialogrutan Skapa projekt anger du ett namn för projektet, eventuellt en beskrivning och väljer Fortsätt.
Välj eller skapa sedan en dokumentinformationsresurs innan du väljer Fortsätt.
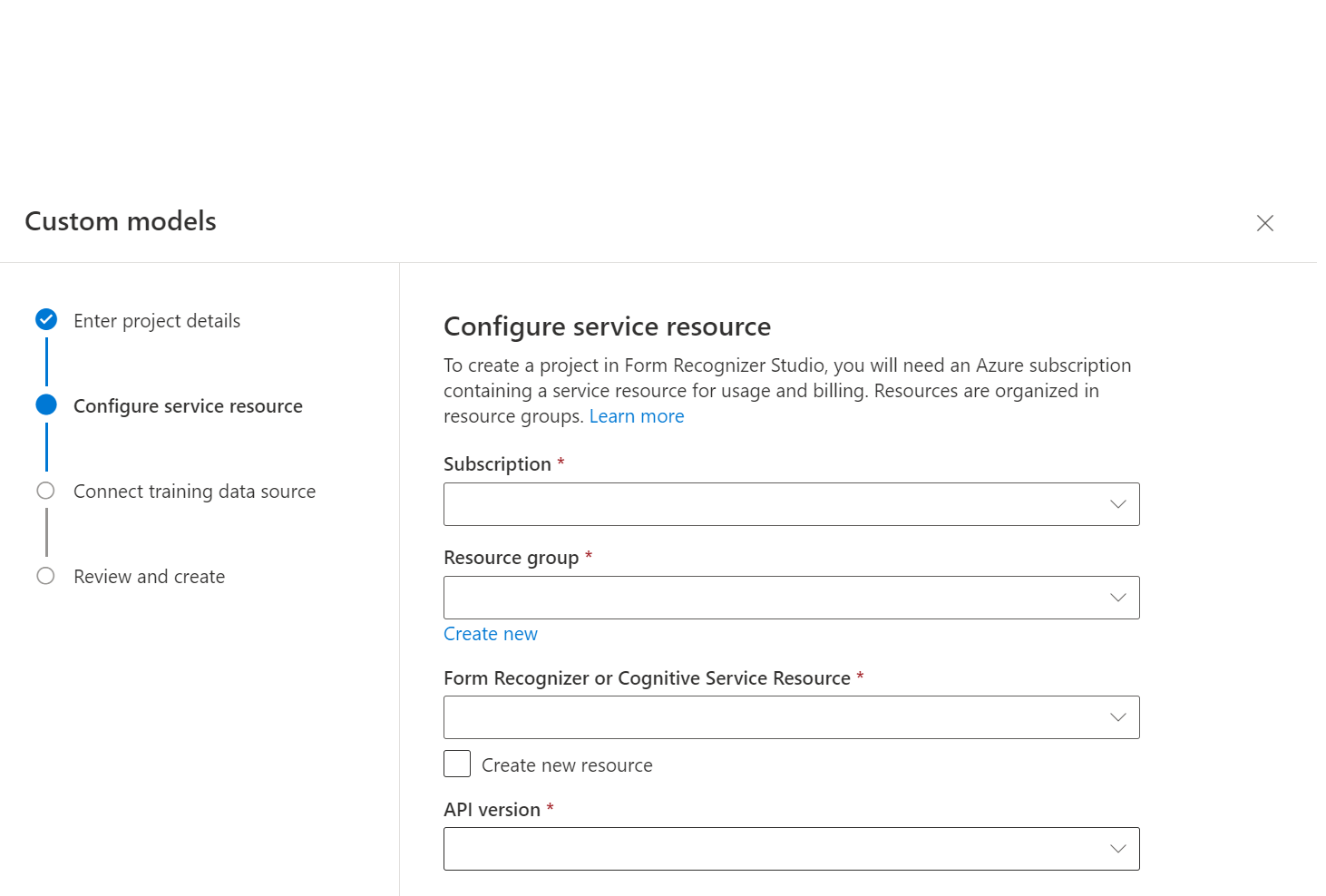
Välj sedan det lagringskonto som du använde för att ladda upp din anpassade modellträningsdatauppsättning. Mappsökvägen bör vara tom om träningsdokumenten finns i containerns rot. Om dokumenten finns i en undermapp anger du den relativa sökvägen från containerroten i fältet Mappsökväg . När lagringskontot har konfigurerats väljer du Fortsätt.
Viktigt!
Du kan antingen ordna träningsdatauppsättningen efter mappar där mappnamnet är etiketten eller klassen för dokument eller skapa en platt lista med dokument som du kan tilldela en etikett till i Studio.
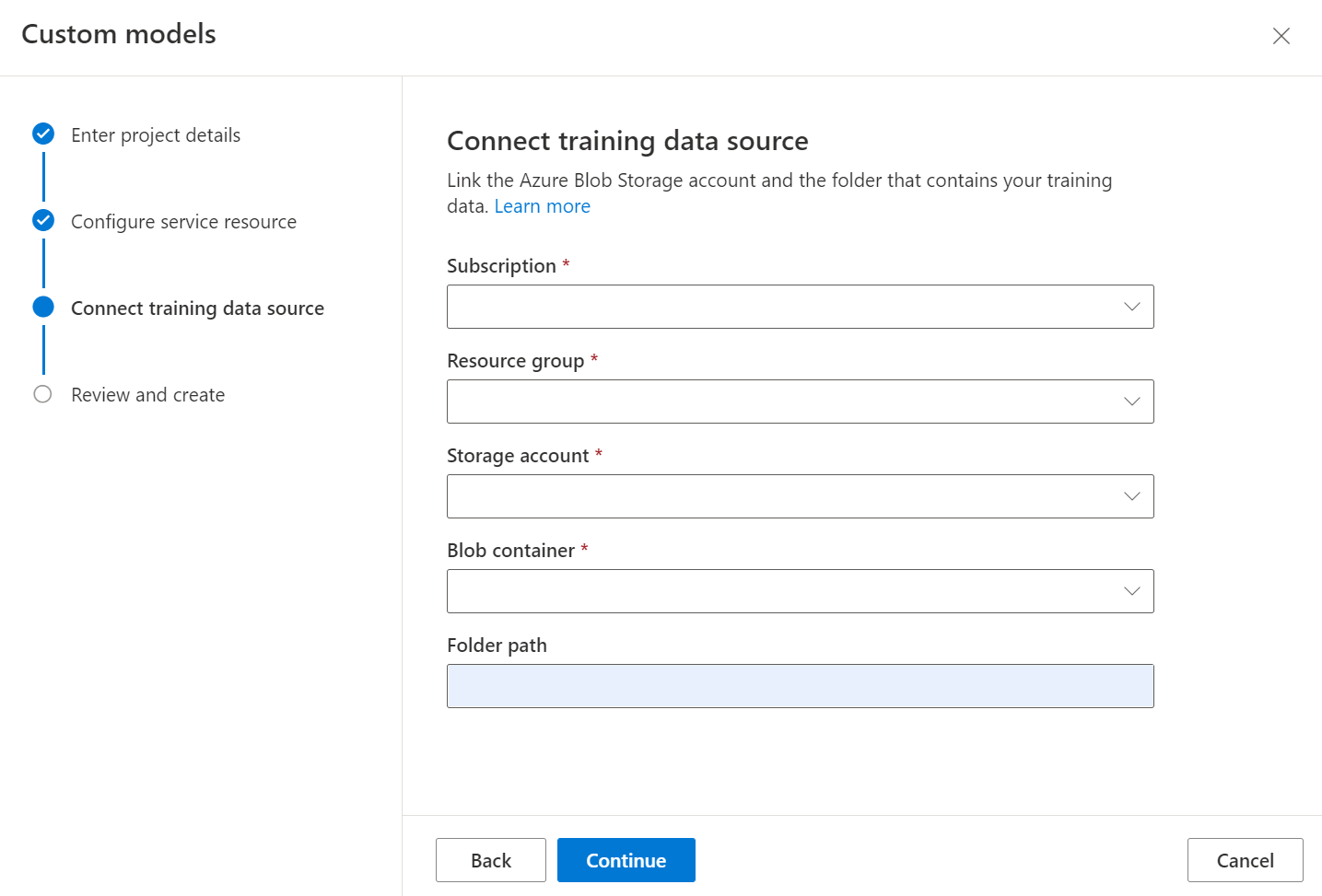
Träning av en anpassad klassificerare kräver utdata från layoutmodellen för varje dokument i datauppsättningen. Kör layout på alla dokument före modellträningsprocessen.
Granska slutligen projektinställningarna och välj Skapa projekt för att skapa ett nytt projekt. Du bör nu vara i etikettfönstret och se filerna i datauppsättningen i listan.
Märka dina data
I projektet behöver du bara märka varje dokument med lämplig klassetikett.
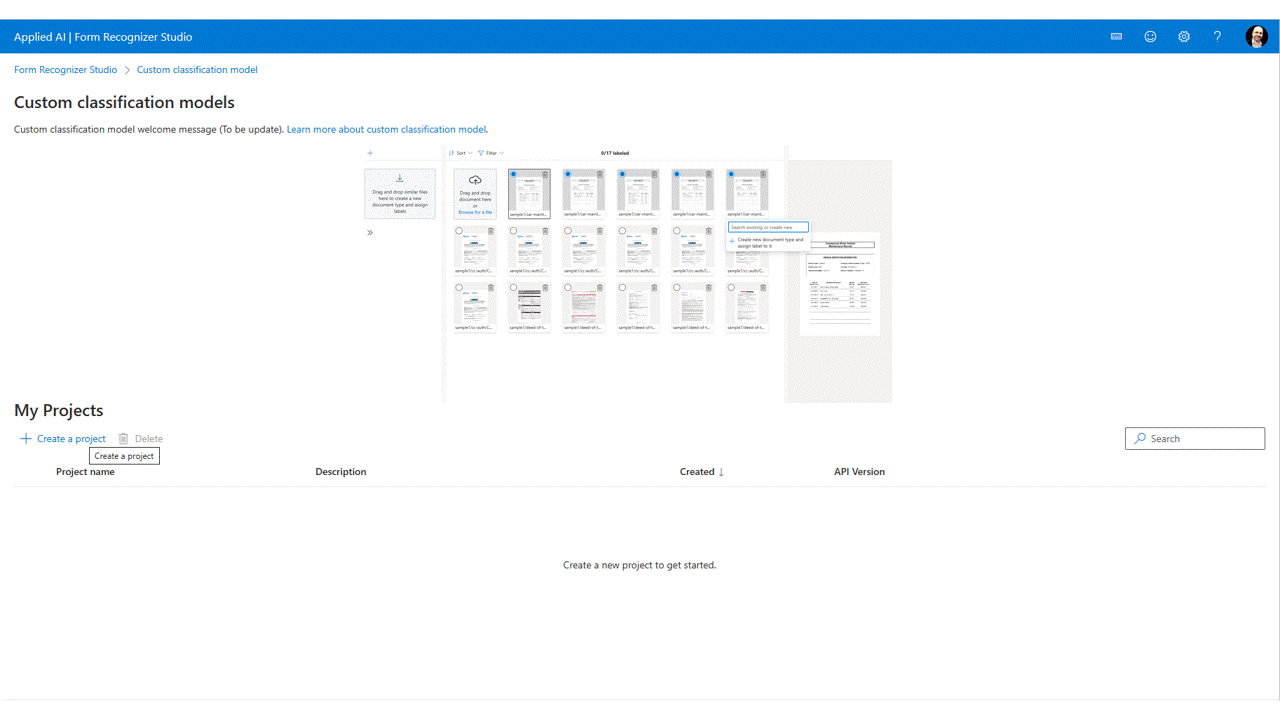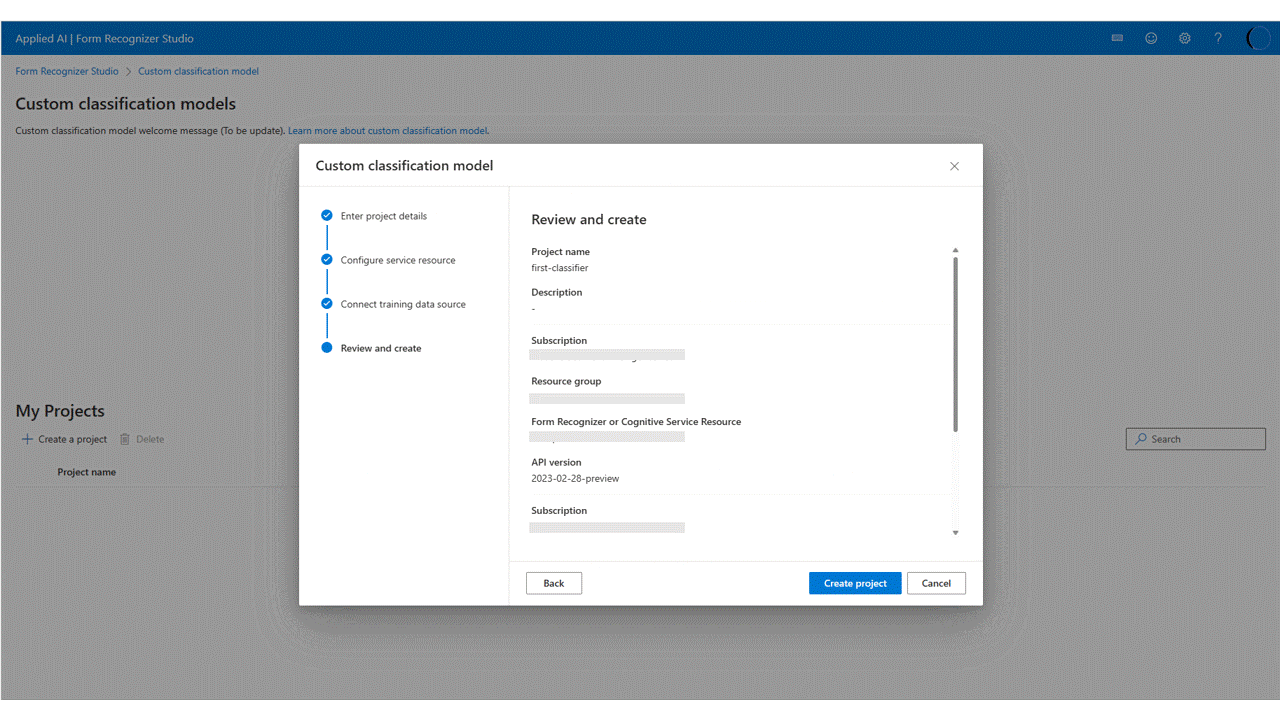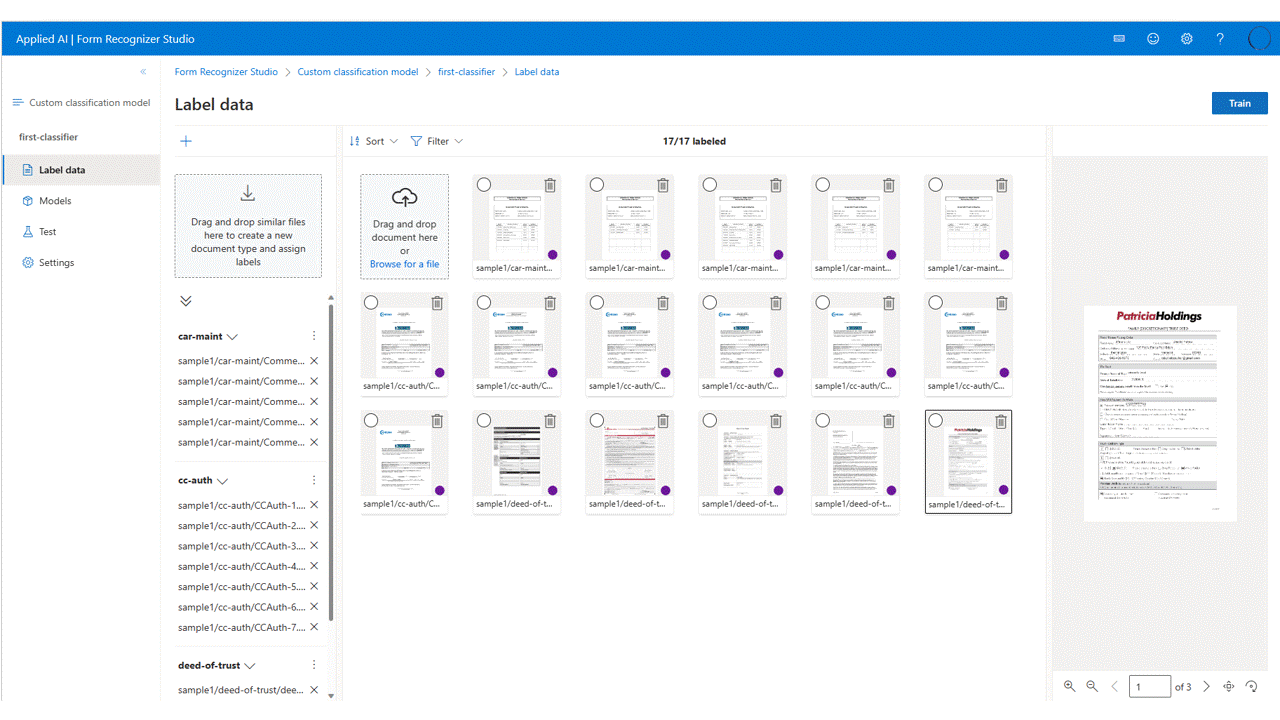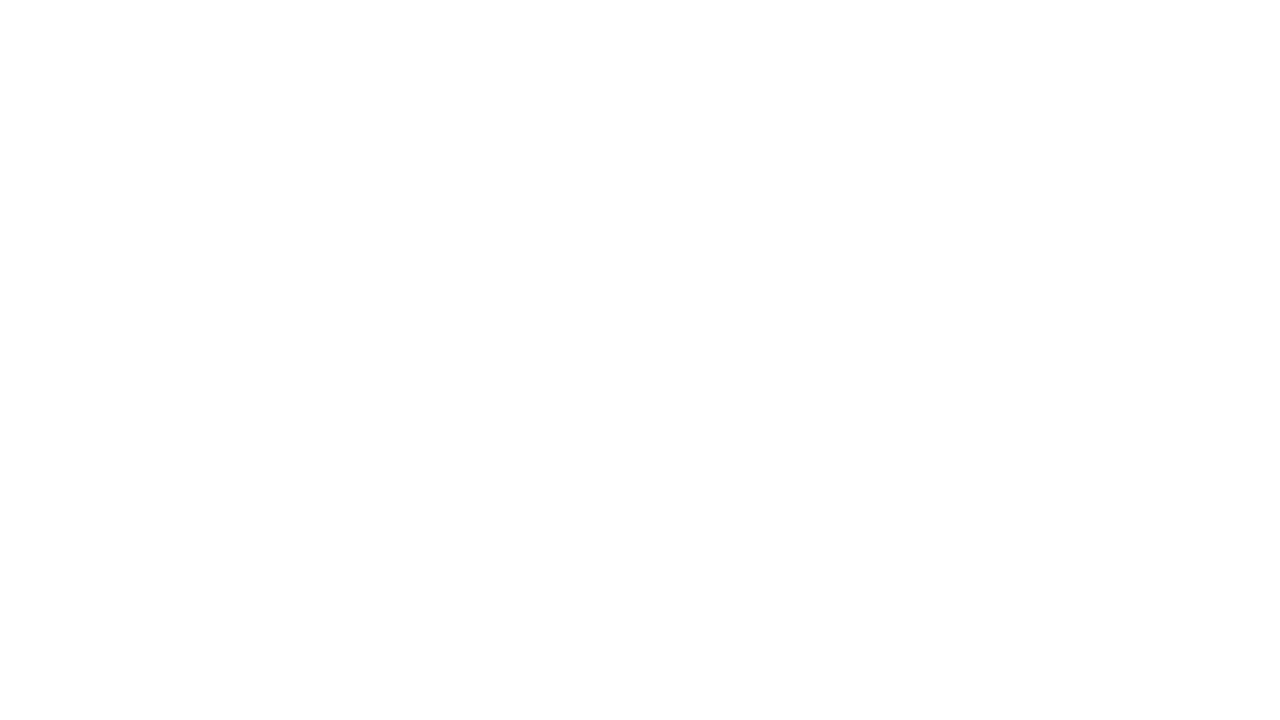
Du ser de filer som du laddade upp till lagring i fillistan, redo att märkas. Du har några alternativ för att märka din datauppsättning.
Om dokumenten är ordnade i mappar uppmanar Studio dig att använda mappnamnen som etiketter. Det här steget förenklar etikettering till ett enda val.
Om du vill tilldela en etikett till ett dokument väljer du på markeringen lägg till etikett för att tilldela en etikett.
Styra val till dokument med flera val för att tilldela en etikett
Nu bör du ha alla dokument i datamängden märkta. Om du tittar på lagringskontot hittar du .ocr.json filer som motsvarar varje dokument i din träningsdatauppsättning och en ny klassnamn.jsonl-fil för varje klass märkt. Den här träningsdatauppsättningen skickas för att träna modellen.
Träna din modell
Med din datauppsättning märkt är du nu redo att träna din modell. Välj knappen Träna i det övre högra hörnet.
I dialogrutan träningsmodell anger du ett unikt klassificerar-ID och, om du vill, en beskrivning. Klassificerarens ID accepterar en strängdatatyp.
Välj Träna för att starta träningsprocessen.
Klassificerarmodeller tränas om några minuter.
Gå till menyn Modeller för att visa status för tågåtgärden.
Testa modellen
När modellträningen är klar kan du testa din modell genom att välja modellen på sidan modelllista.
Välj modellen och välj på knappen Testa .
Lägg till en ny fil genom att bläddra efter en fil eller släppa en fil i dokumentväljaren.
När du har valt en fil väljer du knappen Analysera för att testa modellen.
Modellresultatet visas med listan över identifierade dokument, en konfidenspoäng för varje dokument som identifieras och sidintervallet för vart och ett av de identifierade dokumenten.
Verifiera din modell genom att utvärdera resultaten för varje dokument som identifieras.
Träna en anpassad klassificerare med hjälp av SDK eller API
Studio samordnar API-anropen så att du kan träna en anpassad klassificerare. Träningsdatauppsättningen för klassificeraren kräver utdata från layout-API:et som matchar versionen av API:et för din träningsmodell. Om du använder layoutresultat från en äldre API-version kan det resultera i en modell med lägre noggrannhet.
Studio genererar layoutresultat för din träningsdatauppsättning om datauppsättningen inte innehåller layoutresultat. När du använder API:et eller SDK:n för att träna en klassificerare måste du lägga till layoutresultatet i mapparna som innehåller de enskilda dokumenten. Layoutresultatet ska vara i formatet för API-svaret när du anropar layouten direkt. SDK-objektmodellen är annorlunda, kontrollera att layout results är API-resultaten och inte SDK response.
Felsöka
Klassificeringsmodellen kräver resultat från layoutmodellen för varje träningsdokument. Om du inte anger layoutresultatet försöker Studio köra layoutmodellen för varje dokument innan klassificeraren tränas. Den här processen begränsas och kan resultera i ett 429-svar.
Innan du tränar med klassificeringsmodellen i Studio kör du layoutmodellen för varje dokument och laddar upp den till samma plats som det ursprungliga dokumentet. När layoutresultatet har lagts till kan du träna klassificerarmodellen med dina dokument.
Nästa steg
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för