Not
Åtkomst till denna sida kräver auktorisation. Du kan prova att logga in eller byta katalog.
Åtkomst till denna sida kräver auktorisation. Du kan prova att byta katalog.
Innan du tränar din modell måste du märka dina dokument med de anpassade entiteter som du vill extrahera. Dataetiketter är ett viktigt steg i utvecklingslivscykeln. Du kan skapa de entitetstyper som du vill extrahera från dina data och märka dessa entiteter i dina dokument. Dessa data används i nästa steg när du tränar din modell så att din modell kan lära sig av etiketterade data. Om du redan har etiketterat data kan du importera dem direkt till projektet, men du måste se till att dina data följer det godkända dataformatet. Mer information om hur du importerar etiketterade data till projektet finns i Skapa projekt .
Innan du skapar en anpassad NER-modell måste du först märka dina data. Om dina data inte redan är märkta kan du märka dem i Language Studio. Märkta data informerar modellen om hur text tolkas och används för träning och utvärdering.
Förutsättningar
Innan du kan märka dina data behöver du:
- Ett framgångsrikt skapat projekt med ett konfigurerat Azure Blob Storage-konto
- Textdata laddas upp till ditt lagringskonto .
Mer information finns ilivscykeln för projektutveckling.
Riktlinjer för dataetiketter
När du har förberett dina data, designat schemat och skapat projektet måste du märka dina data. Det är viktigt att märka dina data så att din modell vet vilka ord som är associerade med de entitetstyper som du behöver extrahera. När du etiketterar dina data i Language Studio (eller importerar etiketterade data) lagras dessa etiketter i JSON-dokumentet i din lagringscontainer som du har anslutit till det här projektet.
När du etiketterar dina data bör du tänka på:
I allmänhet leder mer märkta data till bättre resultat, förutsatt att data är korrekt märkta.
Precisionen, konsekvensen och fullständigheten hos dina märkta data är viktiga faktorer för att fastställa modellens prestanda.
- Märk exakt: Etikettera varje entitet alltid till rätt typ. Inkludera bara det du vill extrahera. Undvik onödiga data i etiketterna.
- Etikett konsekvent: Samma entitet bör ha samma etikett i alla dokument.
- Etikettera fullständigt: Märk alla förekomster av entiteten i alla dina dokument. Du kan använda funktionen automärkning för att säkerställa fullständig etikettering.
Märka dina data
Använd följande steg för att märka dina data:
Gå till projektsidan i Language Studio.
På menyn till vänster väljer du Dataetiketter. Du hittar en lista över alla dokument i lagringscontainern.
Tips
Du kan använda filtren på den översta menyn för att visa de omärkta dokumenten så att du kan börja märka dem. Du kan också använda filtren för att visa dokument som är märkta med en viss entitetstyp.
Ändra till en enda dokumentvy till vänster på den översta menyn eller välj ett visst dokument för att börja märka. Du hittar en lista över alla
.txtdokument som är tillgängliga i projektet till vänster. Du kan använda bakåt- och nästaknappen längst ned på sidan för att navigera i dina dokument.Kommentar
Om du har aktiverat flera språk för projektet hittar du listrutan Språk på den översta menyn, där du kan välja språk för varje dokument.
I fönstret till höger lägger du till entitetstyp i projektet så att du kan börja märka dina data med dem.
Du har två alternativ för att märka dokumentet:
Alternativ Beskrivning Etikett med hjälp av en pensel Välj penselikonen bredvid en entitetstyp i det högra fönstret och markera sedan texten i dokumentet som du vill kommentera med den här entitetstypen. Etikett med hjälp av en meny Markera ordet som du vill märka som en entitet och en meny visas. Välj den entitetstyp som du vill tilldela för den här entiteten. Följande skärmbild visar etikettering med hjälp av en pensel.
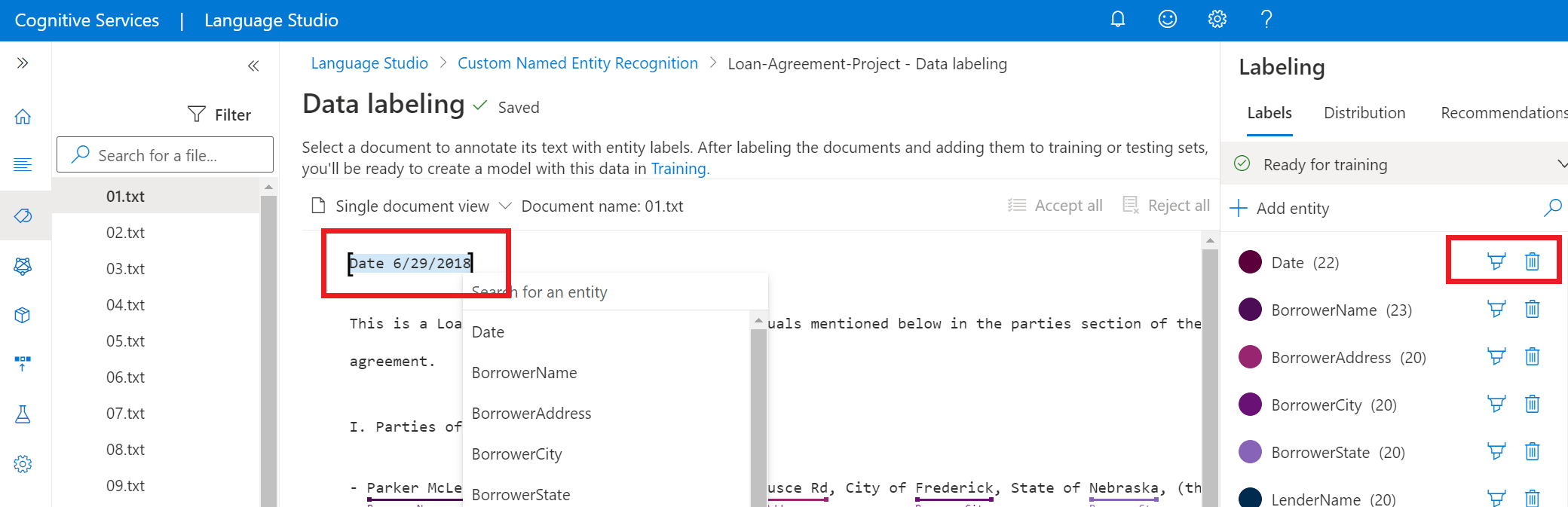
I den högra rutan under pivoten Etiketter hittar du alla entitetstyper i projektet och antalet märkta instanser per var och en.
I den nedre delen av fönstret till höger kan du lägga till det aktuella dokumentet du tittar på i träningssetet eller testsetet. Som standardinställning läggs alla dokument till i träningsuppsättningen. Läs mer om tränings- och testuppsättningar och hur de används för modellträning och utvärdering.
Tips
Om du planerar att använda automatisk datadelning använder du standardalternativet att tilldela alla dokument till din träningsuppsättning.
Under pivoten Distribution kan du visa fördelningen mellan tränings- och testuppsättningar. Du har två alternativ för att visa:
- Totalt antal instanser där du kan visa antalet alla märkta instanser av en viss entitetstyp.
- dokument med minst en etikett där varje dokument räknas om det innehåller minst en märkt instans av den här entiteten.
När du etiketterar synkroniseras ändringarna regelbundet, om de inte sparas ännu får du en varning överst på sidan. Om du vill spara manuellt väljer du knappen Spara etiketter längst ned på sidan.

Ta bort etiketter
Ta bort en etikett
- Välj den entitet som du vill ta bort en etikett från.
- Bläddra igenom menyn som visas och välj Ta bort etikett.
Ta bort entiteter
Om du vill ta bort en entitet väljer du borttagningsikonen bredvid den entitet som du vill ta bort. Om du tar bort en entitet tas alla dess märkta instanser bort från datauppsättningen.
Nästa steg
När du har märkt dina data kan du börja träna en modell som lär sig baserat på dina data.