Snabbstart: anpassade Textanalys för hälsa
Använd den här artikeln om du vill komma igång med att skapa en anpassad Textanalys för hälsoprojekt där du kan träna anpassade modeller ovanpå Textanalys för hälsa för anpassad entitetsigenkänning. En modell är programvara för artificiell intelligens som är tränad att utföra en viss uppgift. För det här systemet extraherar modellerna sjukvårdsrelaterade namngivna entiteter och tränas genom att lära sig från märkta data.
I den här artikeln använder vi Language Studio för att demonstrera viktiga begrepp för anpassade Textanalys för hälsa. Som ett exempel skapar vi en anpassad Textanalys för hälsomodell för att extrahera anläggningen eller behandlingsplatsen från korta urladdningsanteckningar.
Förutsättningar
- Azure-prenumeration – Skapa en kostnadsfritt
Skapa en ny Azure AI Language-resurs och Ett Azure-lagringskonto
Innan du kan använda anpassade Textanalys för hälsa måste du skapa en Azure AI Language-resurs som ger dig de autentiseringsuppgifter som du behöver för att skapa ett projekt och börja träna en modell. Du behöver också ett Azure Storage-konto där du kan ladda upp din datauppsättning som används för att skapa din modell.
Viktigt!
För att snabbt komma igång rekommenderar vi att du skapar en ny Azure AI Language-resurs med hjälp av stegen i den här artikeln. Med hjälp av stegen i den här artikeln kan du skapa språkresursen och lagringskontot samtidigt, vilket är enklare än att göra det senare.
Om du har en befintlig resurs som du vill använda måste du ansluta den till lagringskontot. Mer information finns i vägledning för att använda en befintlig resurs.
Skapa en ny resurs från Azure-portalen
Logga in på Azure-portalen för att skapa en ny Azure AI Language-resurs.
I fönstret som visas väljer du Anpassad textklassificering och anpassad namngiven entitetsigenkänning från de anpassade funktionerna. Välj Fortsätt för att skapa resursen längst ned på skärmen.

Skapa en språkresurs med följande information.
Name beskrivning Prenumeration Din Azure-prenumeration. Resursgrupp En resursgrupp som ska innehålla din resurs. Du kan använda en befintlig eller skapa en ny. Region Regionen för språkresursen. Till exempel "USA, västra 2". Name Ett namn på resursen. Prisnivå Prisnivån för din språkresurs. Du kan använda nivån Kostnadsfri (F0) för att prova tjänsten. Kommentar
Om du får ett meddelande om att ditt inloggningskonto inte är ägare till det valda lagringskontots resursgrupp måste ditt konto ha en ägarroll tilldelad till resursgruppen innan du kan skapa en Språkresurs. Kontakta din Azure-prenumerationsägare om du vill ha hjälp.
I avsnittet Anpassad textklassificering och anpassad namngiven entitetsigenkänning väljer du ett befintligt lagringskonto eller väljer Nytt lagringskonto. Dessa värden hjälper dig att komma igång och inte nödvändigtvis de lagringskontovärden som du vill använda i produktionsmiljöer. Undvik svarstider när du skapar projektet genom att ansluta till lagringskonton i samma region som språkresursen.
Lagringskontovärde Rekommenderat värde Lagringskontonamn Valfritt namn Storage account type Standard LRS Kontrollera att meddelandet om ansvarsfull AI är markerat. Välj Granska + skapa längst ned på sidan och välj sedan Skapa.

Ladda upp exempeldata till blobcontainer
När du har skapat ett Azure-lagringskonto och anslutit det till språkresursen måste du ladda upp dokumenten från exempeldatauppsättningen till rotkatalogen för containern. Dessa dokument kommer senare att användas för att träna din modell.
Ladda ned exempeldatauppsättningen från GitHub.
Öppna zip-filen och extrahera mappen som innehåller dokumenten.
I Azure-portalen navigerar du till lagringskontot som du skapade och väljer det.
I ditt lagringskonto väljer du Containrar på den vänstra menyn under Datalagring. På skärmen som visas väljer du + Container. Ge containern namnet example-data och lämna standardnivån offentlig åtkomst.

När containern har skapats väljer du den. Välj sedan knappen Ladda upp för att välja filerna
.txtoch.jsonsom du laddade ned tidigare.


Den angivna urvalsdatamängden innehåller 12 kliniska anteckningar. Varje klinisk anteckning innehåller flera medicinska entiteter och behandlingsplatsen. Vi använder de fördefinierade entiteterna för att extrahera de medicinska entiteterna och träna den anpassade modellen att extrahera behandlingsplatsen med hjälp av entitetens inlärda komponenter och listkomponenter.
Skapa en anpassad Textanalys för hälsoprojekt
När resursen och lagringskontot har konfigurerats skapar du en ny anpassad Textanalys för hälsoprojektet. Ett projekt är ett arbetsområde för att skapa dina anpassade ML-modeller baserat på dina data. Ditt projekt kan bara nås av dig och andra som har åtkomst till den språkresurs som används.
Logga in på Language Studio. Ett fönster visas där du kan välja din prenumeration och språkresurs. Välj den språkresurs som du skapade i steget ovan.
Under avsnittet Extrahera information i Language Studio väljer du Anpassad Textanalys för hälsa.
Välj Skapa nytt projekt på den översta menyn på projektsidan. När du skapar ett projekt kan du märka data, träna, utvärdera, förbättra och distribuera dina modeller.

Ange projektinformationen, inklusive ett namn, en beskrivning och språket för filerna i projektet. Om du använder exempeldatauppsättningen väljer du Engelska. Du kan inte ändra namnet på projektet senare. Välj Nästa
Dricks
Datamängden behöver inte vara helt på samma språk. Du kan ha flera dokument, var och en med olika språk som stöds. Om datamängden innehåller dokument med olika språk eller om du förväntar dig text från olika språk under körningen väljer du alternativet Aktivera flerspråkig datauppsättning när du anger grundläggande information för projektet. Det här alternativet kan aktiveras senare från sidan Projektinställningar .
När du har valt Skapa nytt projekt visas ett fönster där du kan ansluta ditt lagringskonto. Om du redan har anslutit ett lagringskonto visas det anslutna lagringskontot. Om inte väljer du ditt lagringskonto i listrutan som visas och väljer Anslut lagringskonto. Detta anger de roller som krävs för ditt lagringskonto. Det här steget returnerar eventuellt ett fel om du inte har tilldelats som ägare på lagringskontot.
Kommentar
- Du behöver bara göra det här steget en gång för varje ny resurs som du använder.
- Den här processen kan inte ångras, om du ansluter ett lagringskonto till din Språkresurs kan du inte koppla från det senare.
- Du kan bara ansluta språkresursen till ett lagringskonto.
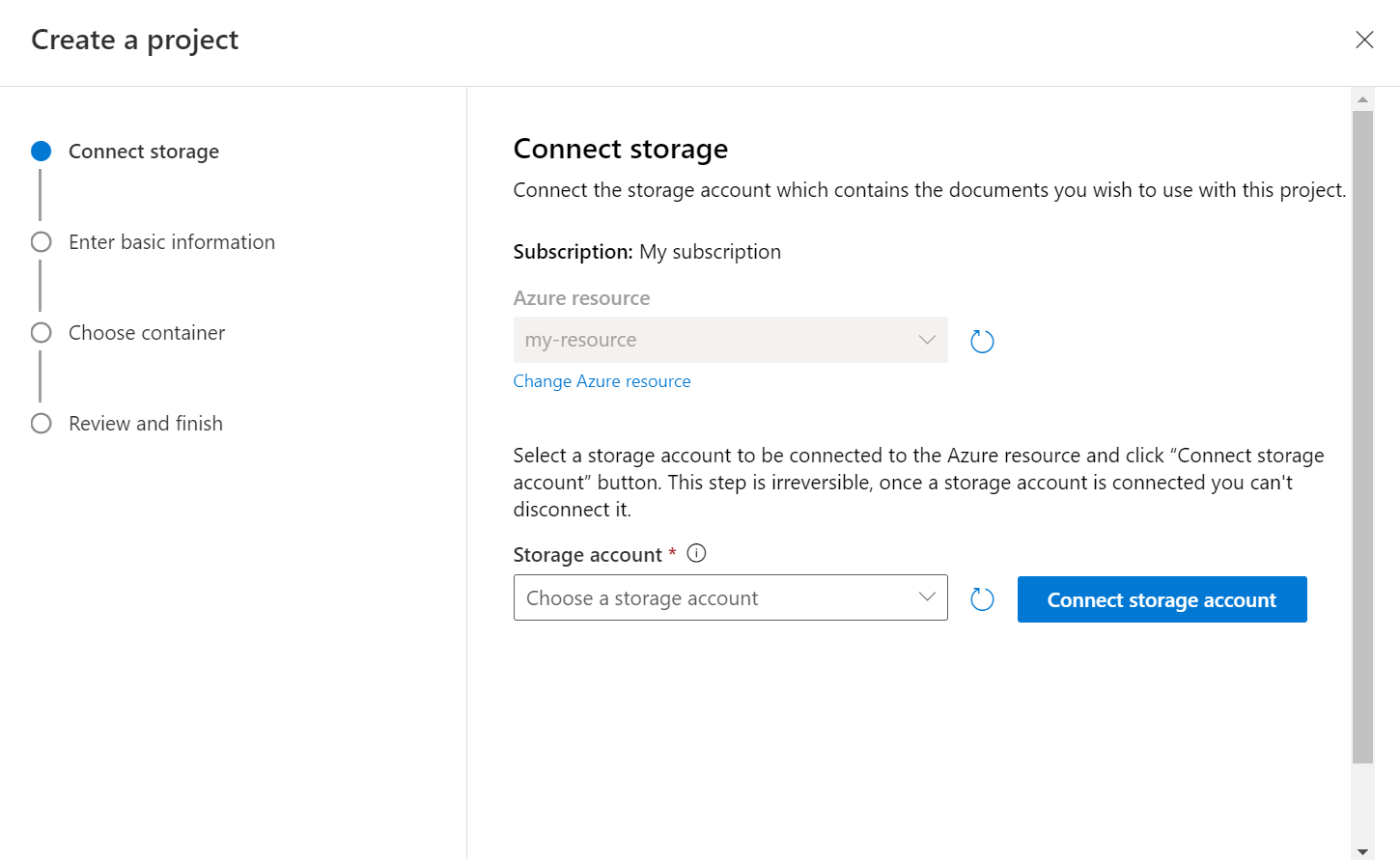
Välj den container där du har laddat upp datamängden.
Om du redan har etiketterat data kontrollerar du att de följer formatet som stöds och väljer Ja, mina filer är redan märkta och jag har formaterat JSON-etikettfilen och väljer etikettfilen i den nedrullningsbara menyn. Välj Nästa. Om du använder datauppsättningen från snabbstarten behöver du inte granska formateringen för JSON-etikettfilen.
Granska de data som du har angett och välj Skapa projekt.


Träna din modell
När du har skapat ett projekt börjar du vanligtvis märka de dokument som du har i containern som är ansluten till projektet. För den här snabbstarten har du importerat en exempeltaggad datauppsättning och initierat projektet med JSON-exempeletikettfilen så att du inte behöver lägga till ytterligare etiketter.
Så här börjar du träna din modell inifrån Language Studio:
Välj Träningsjobb på menyn till vänster.
Välj Starta ett träningsjobb på den översta menyn.
Välj Träna en ny modell och skriv in modellnamnet i textrutan. Du kan också skriva över en befintlig modell genom att välja det här alternativet och välja den modell som du vill skriva över från den nedrullningsbara menyn. Att skriva över en tränad modell är oåterkalleligt, men det påverkar inte dina distribuerade modeller förrän du distribuerar den nya modellen.
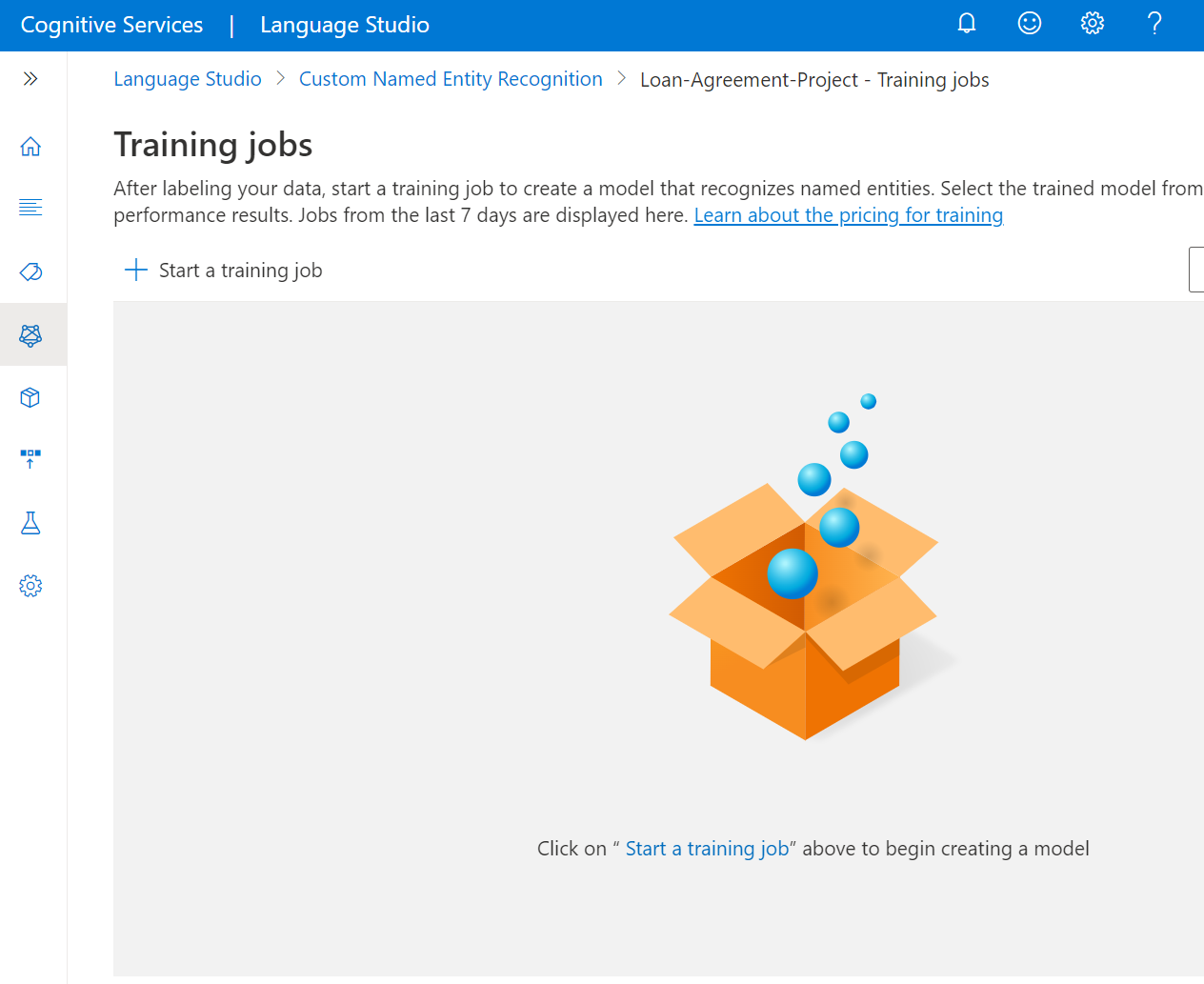
Välj datadelningsmetod. Du kan välja Att automatiskt dela upp testuppsättningen från träningsdata där systemet delar upp dina märkta data mellan tränings- och testuppsättningarna, enligt de angivna procentandelarna. Eller så kan du använda en manuell delning av tränings- och testdata. Det här alternativet är bara aktiverat om du har lagt till dokument i testuppsättningen. Se dataetiketter och hur du tränar en modell för information om datadelning.
Välj knappen Träna.
Om du väljer ID för träningsjobb i listan visas en sidoruta där du kan kontrollera träningsförloppet, jobbstatusen och annan information för det här jobbet.
Kommentar
- Endast slutförda träningsjobb genererar modeller.
- Träningen kan ta lite tid mellan ett par minuter och flera timmar baserat på storleken på dina märkta data.
- Du kan bara köra ett träningsjobb i taget. Du kan inte starta ett annat träningsjobb i samma projekt förrän det pågående jobbet har slutförts.

Distribuera din modell
Vanligtvis efter att ha tränat en modell skulle du granska dess utvärderingsinformation och göra förbättringar om det behövs. I den här snabbstarten distribuerar du bara din modell och gör den tillgänglig för dig att prova i Language Studio, eller så kan du anropa förutsägelse-API:et.
Så här distribuerar du din modell inifrån Language Studio:
Välj Distribuera en modell från menyn till vänster.
Välj Lägg till distribution för att starta ett nytt distributionsjobb.
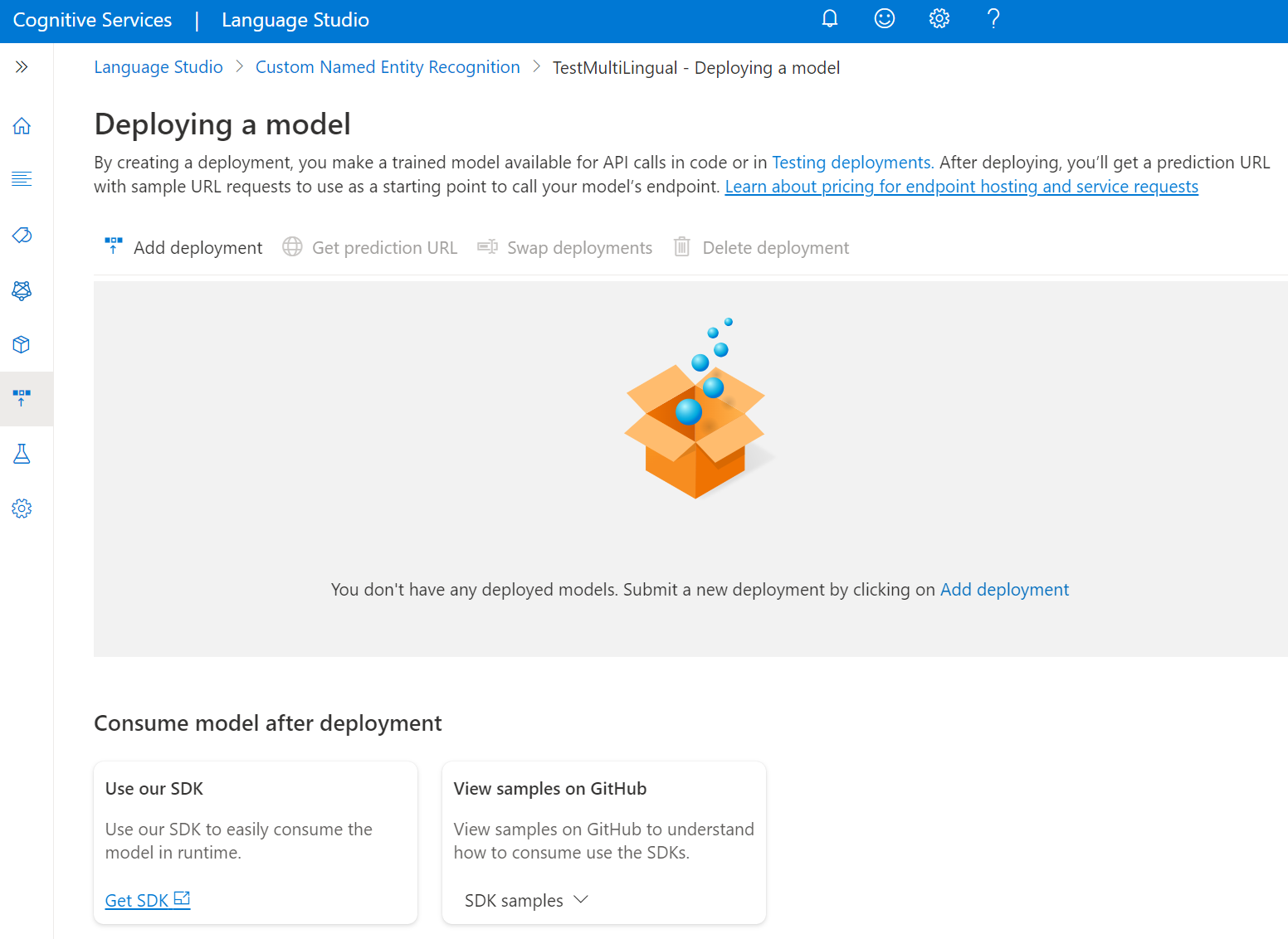
Välj Skapa ny distribution för att skapa en ny distribution och tilldela en tränad modell i listrutan nedan. Du kan också skriva över en befintlig distribution genom att välja det här alternativet och välja den tränade modell som du vill tilldela till den i listrutan nedan.
Kommentar
Om du skriver över en befintlig distribution krävs inte ändringar i api-anropet för förutsägelse , men de resultat du får baseras på den nyligen tilldelade modellen.

Välj Distribuera för att starta distributionsjobbet.
När distributionen har slutförts visas ett förfallodatum bredvid den. Distributionen upphör att gälla när den distribuerade modellen inte kommer att användas för förutsägelse, vilket vanligtvis sker tolv månader efter att en träningskonfiguration upphör att gälla.


Testa din modell
När din modell har distribuerats kan du börja använda den för att extrahera entiteter från din text via Förutsägelse-API. I den här snabbstarten använder du Language Studio för att skicka anpassade Textanalys för hälsoförutsägelseaktivitet och visualisera resultaten. I exempeldatauppsättningen som du laddade ned tidigare hittar du några testdokument som du kan använda i det här steget.
Så här testar du dina distribuerade modeller från Language Studio:
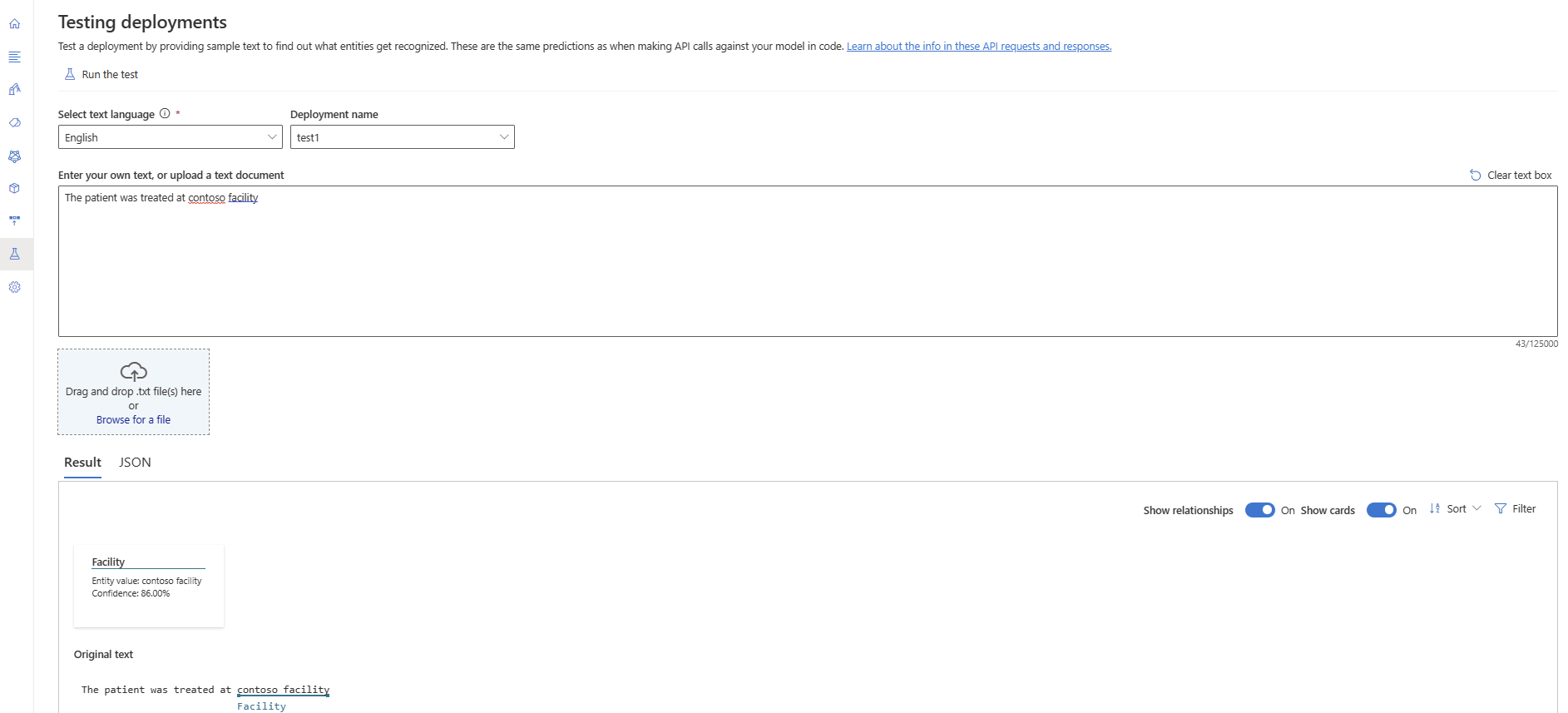
Välj Testa distributioner på menyn till vänster.
Välj den distribution som du vill testa. Du kan bara testa modeller som har tilldelats distributioner.
Välj den distribution som du vill köra frågor mot/testa i listrutan.
Du kan ange den text som du vill skicka till begäran eller ladda upp en
.txtfil som ska användas.Välj Kör testet på den översta menyn.
På fliken Resultat kan du se de extraherade entiteterna från din text och deras typer. Du kan också visa JSON-svaret under fliken JSON .

Rensa resurser
När du inte längre behöver projektet kan du ta bort projektet med Hjälp av Language Studio.
- Välj den språktjänstfunktion som du använder överst på sidan, s
- Välj det projekt som du vill ta bort
- Välj Ta bort i den översta menyn.
Förutsättningar
- Azure-prenumeration – Skapa en kostnadsfritt
Skapa en ny Azure AI Language-resurs och Ett Azure-lagringskonto
Innan du kan använda anpassade Textanalys för hälsa måste du skapa en Azure AI Language-resurs, som ger dig de autentiseringsuppgifter som du behöver för att skapa ett projekt och börja träna en modell. Du behöver också ett Azure-lagringskonto där du kan ladda upp din datauppsättning som ska användas för att skapa din modell.
Viktigt!
För att komma igång snabbt rekommenderar vi att du skapar en ny Azure AI Language-resurs med hjälp av stegen i den här artikeln, som gör att du kan skapa språkresursen och skapa och/eller ansluta ett lagringskonto samtidigt, vilket är enklare än att göra det senare.
Om du har en befintlig resurs som du vill använda måste du ansluta den till lagringskontot. Mer information finns i Skapa projekt .
Skapa en ny resurs från Azure-portalen
Logga in på Azure-portalen för att skapa en ny Azure AI Language-resurs.
I fönstret som visas väljer du Anpassad textklassificering och anpassad namngiven entitetsigenkänning från de anpassade funktionerna. Välj Fortsätt för att skapa resursen längst ned på skärmen.
Skapa en språkresurs med följande information.
Name beskrivning Prenumeration Din Azure-prenumeration. Resursgrupp En resursgrupp som ska innehålla din resurs. Du kan använda en befintlig eller skapa en ny. Region Regionen för språkresursen. Till exempel "USA, västra 2". Name Ett namn på resursen. Prisnivå Prisnivån för din språkresurs. Du kan använda nivån Kostnadsfri (F0) för att prova tjänsten. Kommentar
Om du får ett meddelande om att ditt inloggningskonto inte är ägare till det valda lagringskontots resursgrupp måste ditt konto ha en ägarroll tilldelad till resursgruppen innan du kan skapa en Språkresurs. Kontakta din Azure-prenumerationsägare om du vill ha hjälp.
I avsnittet Anpassad textklassificering och anpassad namngiven entitetsigenkänning väljer du ett befintligt lagringskonto eller väljer Nytt lagringskonto. Dessa värden hjälper dig att komma igång och inte nödvändigtvis de lagringskontovärden som du vill använda i produktionsmiljöer. Undvik svarstider när du skapar projektet genom att ansluta till lagringskonton i samma region som språkresursen.
Lagringskontovärde Rekommenderat värde Lagringskontonamn Valfritt namn Storage account type Standard LRS Kontrollera att meddelandet om ansvarsfull AI är markerat. Välj Granska + skapa längst ned på sidan och välj sedan Skapa.
Ladda upp exempeldata till blobcontainer
När du har skapat ett Azure-lagringskonto och anslutit det till språkresursen måste du ladda upp dokumenten från exempeldatauppsättningen till rotkatalogen för containern. Dessa dokument kommer senare att användas för att träna din modell.
Ladda ned exempeldatauppsättningen från GitHub.
Öppna zip-filen och extrahera mappen som innehåller dokumenten.
I Azure-portalen navigerar du till lagringskontot som du skapade och väljer det.
I ditt lagringskonto väljer du Containrar på den vänstra menyn under Datalagring. På skärmen som visas väljer du + Container. Ge containern namnet example-data och lämna standardnivån offentlig åtkomst.
När containern har skapats väljer du den. Välj sedan knappen Ladda upp för att välja filerna
.txtoch.jsonsom du laddade ned tidigare.
Den angivna urvalsdatamängden innehåller 12 kliniska anteckningar. Varje klinisk anteckning innehåller flera medicinska entiteter och behandlingsplatsen. Vi använder de fördefinierade entiteterna för att extrahera de medicinska entiteterna och träna den anpassade modellen att extrahera behandlingsplatsen med hjälp av entitetens inlärda komponenter och listkomponenter.
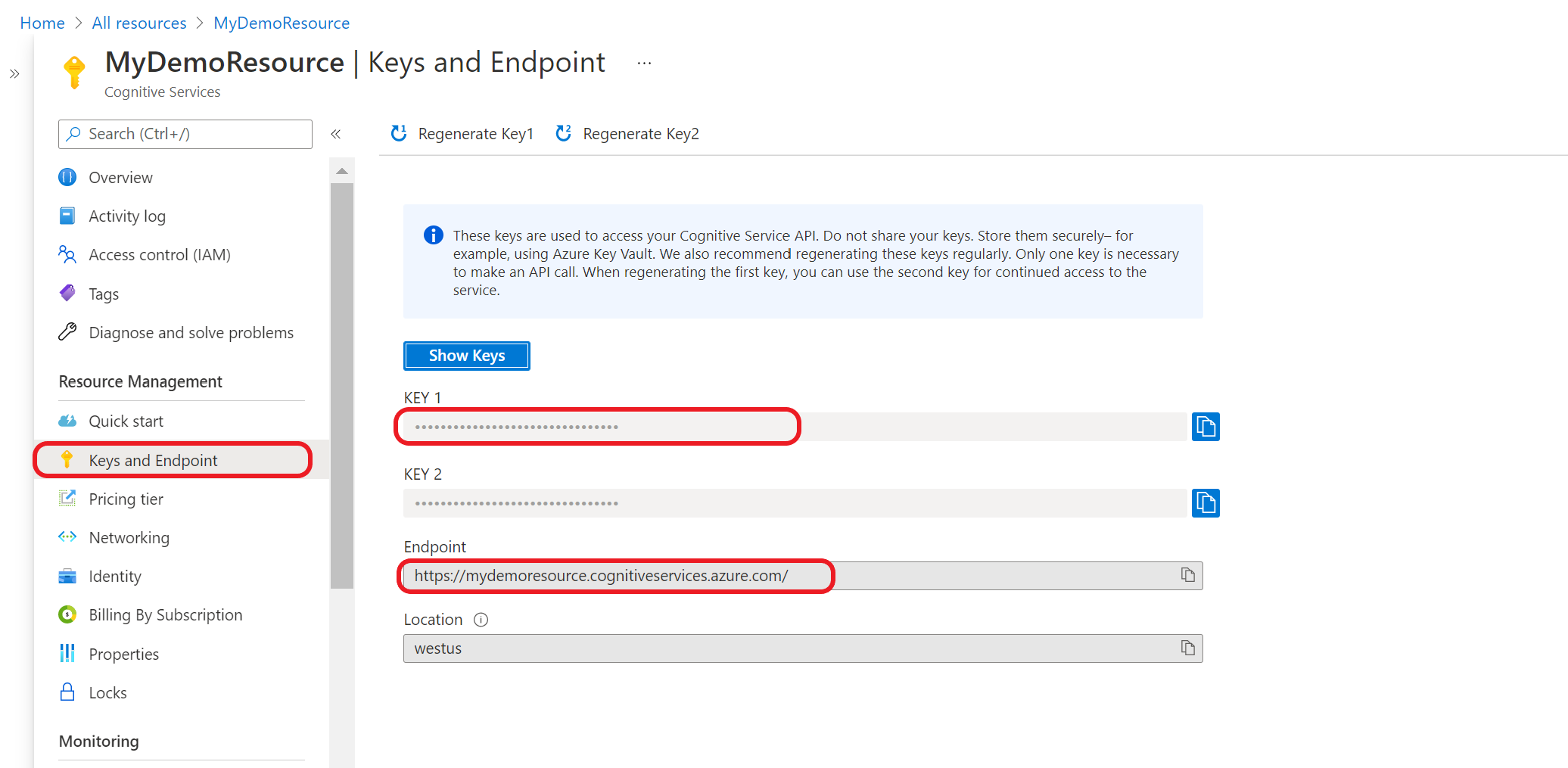
Hämta dina resursnycklar och slutpunkt
Gå till resursöversiktssidan i Azure-portalen
På menyn till vänster väljer du Nycklar och Slutpunkt. Du använder slutpunkten och nyckeln för API-begäranden

Skapa en anpassad Textanalys för hälsoprojekt
När resursen och lagringskontot har konfigurerats skapar du en ny anpassad Textanalys för hälsoprojektet. Ett projekt är ett arbetsområde för att skapa dina anpassade ML-modeller baserat på dina data. Ditt projekt kan bara nås av dig och andra som har åtkomst till den språkresurs som används.
Använd den etikettfil som du laddade ned från exempeldata i föregående steg och lägg till den i brödtexten i följande begäran.
Projektjobb för utlösare för import
Skicka en POST-begäran med hjälp av följande URL, rubriker och JSON-brödtext för att importera din etikettfil. Kontrollera att din etikettfil följer det godkända formatet.
Om det redan finns ett projekt med samma namn ersätts data för projektet.
{Endpoint}/language/authoring/analyze-text/projects/{projectName}/:import?api-version={API-VERSION}
| Platshållare | Värde | Exempel |
|---|---|---|
{ENDPOINT} |
Slutpunkten för att autentisera din API-begäran. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Namnet på projektet. Det här värdet är skiftlägeskänsligt. | myProject |
{API-VERSION} |
Den version av API:et som du anropar. Värdet som refereras här är för den senaste versionen som släppts. Mer information om andra tillgängliga API-versioner finns i Modelllivscykel . | 2022-05-01 |
Sidhuvuden
Använd följande rubrik för att autentisera din begäran.
| Tangent | Värde |
|---|---|
Ocp-Apim-Subscription-Key |
Nyckeln till resursen. Används för att autentisera dina API-begäranden. |
Brödtext
Använd följande JSON i din begäran. Ersätt platshållarvärdena nedan med dina egna värden.
{
"projectFileVersion": "{API-VERSION}",
"stringIndexType": "Utf16CodeUnit",
"metadata": {
"projectName": "{PROJECT-NAME}",
"projectKind": "CustomHealthcare",
"description": "Trying out custom Text Analytics for health",
"language": "{LANGUAGE-CODE}",
"multilingual": true,
"storageInputContainerName": "{CONTAINER-NAME}",
"settings": {}
},
"assets": {
"projectKind": "CustomHealthcare",
"entities": [
{
"category": "Entity1",
"compositionSetting": "{COMPOSITION-SETTING}",
"list": {
"sublists": [
{
"listKey": "One",
"synonyms": [
{
"language": "en",
"values": [
"EntityNumberOne",
"FirstEntity"
]
}
]
}
]
}
},
{
"category": "Entity2"
},
{
"category": "MedicationName",
"list": {
"sublists": [
{
"listKey": "research drugs",
"synonyms": [
{
"language": "en",
"values": [
"rdrug a",
"rdrug b"
]
}
]
}
]
}
"prebuilts": "MedicationName"
}
],
"documents": [
{
"location": "{DOCUMENT-NAME}",
"language": "{LANGUAGE-CODE}",
"dataset": "{DATASET}",
"entities": [
{
"regionOffset": 0,
"regionLength": 500,
"labels": [
{
"category": "Entity1",
"offset": 25,
"length": 10
},
{
"category": "Entity2",
"offset": 120,
"length": 8
}
]
}
]
},
{
"location": "{DOCUMENT-NAME}",
"language": "{LANGUAGE-CODE}",
"dataset": "{DATASET}",
"entities": [
{
"regionOffset": 0,
"regionLength": 100,
"labels": [
{
"category": "Entity2",
"offset": 20,
"length": 5
}
]
}
]
}
]
}
}
| Key | Platshållare | Värde | Exempel |
|---|---|---|---|
multilingual |
true |
Ett booleskt värde som gör att du kan ha dokument på flera språk i datauppsättningen och när din modell distribueras kan du fråga modellen på alla språk som stöds (inte nödvändigtvis i dina träningsdokument). Mer information om flerspråkig support finns i språkstöd . | true |
projectName |
{PROJECT-NAME} |
Projektnamn | myproject |
storageInputContainerName |
{CONTAINER-NAME} |
Containerns namn | mycontainer |
entities |
Matris som innehåller alla entitetstyper som du har i projektet. Det här är de entitetstyper som kommer att extraheras från dina dokument till. | ||
category |
Namnet på entitetstypen, som kan vara användardefinierad för nya entitetsdefinitioner eller fördefinierade för fördefinierade entiteter. | ||
compositionSetting |
{COMPOSITION-SETTING} |
Regel som definierar hur du hanterar flera komponenter i entiteten. Alternativen är combineComponents eller separateComponents. |
combineComponents |
list |
Matris som innehåller alla underlistor som du har i projektet för en specifik entitet. Listor kan läggas till i fördefinierade entiteter eller nya entiteter med inlärda komponenter. | ||
sublists |
[] |
Matris som innehåller underlistor. Varje underlista är en nyckel och dess associerade värden. | [] |
listKey |
One |
Ett normaliserat värde för listan över synonymer som ska mappas tillbaka till i förutsägelsen. | One |
synonyms |
[] |
Matris som innehåller alla synonymer | Synonym |
language |
{LANGUAGE-CODE} |
En sträng som anger språkkoden för synonymen i underlistan. Om projektet är ett flerspråkigt projekt och du vill stödja din lista över synonymer för alla språk i projektet måste du uttryckligen lägga till synonymerna i varje språk. Mer information om språkkoder som stöds finns i Språkstöd . | en |
values |
"EntityNumberone", "FirstEntity" |
En lista över kommaavgränsade strängar som matchas exakt för extrahering och mappning till listnyckeln. | "EntityNumberone", "FirstEntity" |
prebuilts |
MedicationName |
Namnet på den fördefinierade komponenten som fyller i den fördefinierade entiteten. Fördefinierade entiteter läses automatiskt in i projektet som standard, men du kan utöka dem med listkomponenter i din etikettfil. | MedicationName |
documents |
Matris som innehåller alla dokument i projektet och en lista över de entiteter som är märkta i varje dokument. | [] | |
location |
{DOCUMENT-NAME} |
Platsen för dokumenten i lagringscontainern. Eftersom alla dokument finns i roten i containern bör detta vara dokumentnamnet. | doc1.txt |
dataset |
{DATASET} |
Testuppsättningen som filen ska gå till när den delas upp före träningen. Möjliga värden för det här fältet är Train och Test. |
Train |
regionOffset |
Den inkluderande teckenpositionen i början av texten. | 0 |
|
regionLength |
Längden på avgränsningsrutan i termer av UTF16-tecken. Utbildningen tar endast hänsyn till data i den här regionen. | 500 |
|
category |
Den typ av entitet som är associerad med det angivna textintervallet. | Entity1 |
|
offset |
Startpositionen för entitetstexten. | 25 |
|
length |
Längden på entiteten när det gäller UTF16-tecken. | 20 |
|
language |
{LANGUAGE-CODE} |
En sträng som anger språkkoden för dokumentet som används i projektet. Om projektet är ett flerspråkigt projekt väljer du språkkoden för de flesta dokumenten. Mer information om språkkoder som stöds finns i Språkstöd . | en |
När du har skickat din API-begäran får du ett 202 svar som anger att jobbet har skickats korrekt. Extrahera värdet i svarshuvudena operation-location . Den formateras så här:
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/import/jobs/{JOB-ID}?api-version={API-VERSION}
{JOB-ID} används för att identifiera din begäran, eftersom den här åtgärden är asynkron. Du använder den här URL:en för att hämta status för importjobbet.
Möjliga felscenarier för den här begäran:
- Den valda resursen har inte rätt behörigheter för lagringskontot.
- Den
storageInputContainerNameangivna finns inte. - Ogiltig språkkod används, eller om språkkodtypen inte är sträng.
multilingualvärdet är en sträng och inte ett booleskt värde.
Hämta status för importjobb
Använd följande GET-begäran för att hämta statusen för din import av projektet. Ersätt platshållarvärdena nedan med dina egna värden.
Begäran-URL
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/import/jobs/{JOB-ID}?api-version={API-VERSION}
| Platshållare | Värde | Exempel |
|---|---|---|
{ENDPOINT} |
Slutpunkten för att autentisera din API-begäran. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Namnet på projektet. Det här värdet är skiftlägeskänsligt. | myProject |
{JOB-ID} |
ID:t för att hitta modellens träningsstatus. Det här värdet finns i det location rubrikvärde som du fick i föregående steg. |
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
Den version av API:et som du anropar. Värdet som refereras här är för den senaste versionen som släppts. Mer information om andra tillgängliga API-versioner finns i Modelllivscykel . | 2022-05-01 |
Sidhuvuden
Använd följande rubrik för att autentisera din begäran.
| Tangent | Värde |
|---|---|
Ocp-Apim-Subscription-Key |
Nyckeln till resursen. Används för att autentisera dina API-begäranden. |
Träna din modell
När du har skapat ett projekt börjar du vanligtvis märka de dokument som du har i containern som är ansluten till projektet. I den här snabbstarten har du importerat en exempeltaggad datauppsättning och initierat projektet med JSON-exempeltaggarfilen.
Starta träningsjobbet
När projektet har importerats kan du börja träna din modell.
Skicka en POST-begäran med hjälp av följande URL, rubriker och JSON-brödtext för att skicka ett träningsjobb. Ersätt platshållarvärdena med dina egna värden.
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/:train?api-version={API-VERSION}
| Platshållare | Värde | Exempel |
|---|---|---|
{ENDPOINT} |
Slutpunkten för att autentisera din API-begäran. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Namnet på projektet. Det här värdet är skiftlägeskänsligt. | myProject |
{API-VERSION} |
Den version av API:et som du anropar. Värdet som refereras här är för den senaste versionen som släppts. Mer information om andra tillgängliga API-versioner finns i Modelllivscykel . | 2022-05-01 |
Sidhuvuden
Använd följande rubrik för att autentisera din begäran.
| Tangent | Värde |
|---|---|
Ocp-Apim-Subscription-Key |
Nyckeln till resursen. Används för att autentisera dina API-begäranden. |
Begärandetext
Använd följande JSON i begärandetexten. Modellen ges när {MODEL-NAME} träningen är klar. Endast lyckade träningsjobb skapar modeller.
{
"modelLabel": "{MODEL-NAME}",
"trainingConfigVersion": "{CONFIG-VERSION}",
"evaluationOptions": {
"kind": "percentage",
"trainingSplitPercentage": 80,
"testingSplitPercentage": 20
}
}
| Key | Platshållare | Värde | Exempel |
|---|---|---|---|
| modelLabel | {MODEL-NAME} |
Modellnamnet som har tilldelats din modell när den har tränats. | myModel |
| trainingConfigVersion | {CONFIG-VERSION} |
Det här är den modellversion som används för att träna modellen. | 2022-05-01 |
| evaluationOptions | Alternativ för att dela upp dina data mellan tränings- och testuppsättningar. | {} |
|
| typ | percentage |
Dela upp metoder. Möjliga värden är percentage eller manual. Mer information finns i Träna en modell . |
percentage |
| trainingSplitPercentage | 80 |
Procentandel av dina taggade data som ska ingå i träningsuppsättningen. Rekommenderat värde är 80. |
80 |
| testingSplitPercentage | 20 |
Procentandel av dina taggade data som ska ingå i testuppsättningen. Rekommenderat värde är 20. |
20 |
Kommentar
Och trainingSplitPercentage testingSplitPercentage krävs endast om Kind anges till percentage och summan av båda procentandelarna ska vara lika med 100.
När du har skickat din API-begäran får du ett 202 svar som anger att jobbet har skickats korrekt. Extrahera värdet i svarshuvudena location . Den är formaterad så här:
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/train/jobs/{JOB-ID}?api-version={API-VERSION}
{JOB-ID} används för att identifiera din begäran, eftersom den här åtgärden är asynkron. Du kan använda den här URL:en för att hämta träningsstatusen.
Hämta status för träningsjobb
Det kan ta någon gång mellan 10 och 30 minuter att träna den här exempeldatamängden. Du kan använda följande begäran för att fortsätta avsöka statusen för träningsjobbet tills det har slutförts.
Använd följande GET-begäran för att få status för din modells träningsförlopp. Ersätt platshållarvärdena nedan med dina egna värden.
Begäran-URL
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/train/jobs/{JOB-ID}?api-version={API-VERSION}
| Platshållare | Värde | Exempel |
|---|---|---|
{ENDPOINT} |
Slutpunkten för att autentisera din API-begäran. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Namnet på projektet. Det här värdet är skiftlägeskänsligt. | myProject |
{JOB-ID} |
ID:t för att hitta modellens träningsstatus. Det här värdet finns i det location rubrikvärde som du fick i föregående steg. |
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
Den version av API:et som du anropar. Värdet som refereras här är för den senaste versionen som släppts. Mer information om andra tillgängliga API-versioner finns i Modelllivscykel . | 2022-05-01 |
Sidhuvuden
Använd följande rubrik för att autentisera din begäran.
| Tangent | Värde |
|---|---|
Ocp-Apim-Subscription-Key |
Nyckeln till resursen. Används för att autentisera dina API-begäranden. |
Svarstext
När du har skickat begäran får du följande svar.
{
"result": {
"modelLabel": "{MODEL-NAME}",
"trainingConfigVersion": "{CONFIG-VERSION}",
"estimatedEndDateTime": "2022-04-18T15:47:58.8190649Z",
"trainingStatus": {
"percentComplete": 3,
"startDateTime": "2022-04-18T15:45:06.8190649Z",
"status": "running"
},
"evaluationStatus": {
"percentComplete": 0,
"status": "notStarted"
}
},
"jobId": "{JOB-ID}",
"createdDateTime": "2022-04-18T15:44:44Z",
"lastUpdatedDateTime": "2022-04-18T15:45:48Z",
"expirationDateTime": "2022-04-25T15:44:44Z",
"status": "running"
}
Distribuera din modell
Vanligtvis efter att ha tränat en modell skulle du granska dess utvärderingsinformation och göra förbättringar om det behövs. I den här snabbstarten distribuerar du bara din modell och gör den tillgänglig för dig att prova i Language Studio, eller så kan du anropa förutsägelse-API:et.
Starta distributionsjobbet
Skicka en PUT-begäran med hjälp av följande URL, rubriker och JSON-brödtext för att skicka ett distributionsjobb. Ersätt platshållarvärdena nedan med dina egna värden.
{Endpoint}/language/authoring/analyze-text/projects/{projectName}/deployments/{deploymentName}?api-version={API-VERSION}
| Platshållare | Värde | Exempel |
|---|---|---|
{ENDPOINT} |
Slutpunkten för att autentisera din API-begäran. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Namnet på projektet. Det här värdet är skiftlägeskänsligt. | myProject |
{DEPLOYMENT-NAME} |
Namnet på distributionen. Det här värdet är skiftlägeskänsligt. | staging |
{API-VERSION} |
Den version av API:et som du anropar. Värdet som refereras här är för den senaste versionen som släppts. Mer information om andra tillgängliga API-versioner finns i Modelllivscykel . | 2022-05-01 |
Sidhuvuden
Använd följande rubrik för att autentisera din begäran.
| Tangent | Värde |
|---|---|
Ocp-Apim-Subscription-Key |
Nyckeln till resursen. Används för att autentisera dina API-begäranden. |
Begärandetext
Använd följande JSON i brödtexten i din begäran. Använd namnet på den modell som du tilldelar distributionen.
{
"trainedModelLabel": "{MODEL-NAME}"
}
| Key | Platshållare | Värde | Exempel |
|---|---|---|---|
| trainedModelLabel | {MODEL-NAME} |
Modellnamnet som ska tilldelas distributionen. Du kan bara tilldela modeller som tränats. Det här värdet är skiftlägeskänsligt. | myModel |
När du har skickat din API-begäran får du ett 202 svar som anger att jobbet har skickats korrekt. Extrahera värdet i svarshuvudena operation-location . Den formateras så här:
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/deployments/{DEPLOYMENT-NAME}/jobs/{JOB-ID}?api-version={API-VERSION}
{JOB-ID} används för att identifiera din begäran, eftersom den här åtgärden är asynkron. Du kan använda den här URL:en för att hämta distributionsstatusen.
Hämta status för distributionsjobb
Använd följande GET-begäran för att fråga efter status för distributionsjobbet. Du kan använda den URL som du fick från föregående steg eller ersätta platshållarvärdena nedan med dina egna värden.
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/deployments/{DEPLOYMENT-NAME}/jobs/{JOB-ID}?api-version={API-VERSION}
| Platshållare | Värde | Exempel |
|---|---|---|
{ENDPOINT} |
Slutpunkten för att autentisera din API-begäran. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Namnet på projektet. Det här värdet är skiftlägeskänsligt. | myProject |
{DEPLOYMENT-NAME} |
Namnet på distributionen. Det här värdet är skiftlägeskänsligt. | staging |
{JOB-ID} |
ID:t för att hitta modellens träningsstatus. Det här är i det location rubrikvärde som du fick i föregående steg. |
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
Den version av API:et som du anropar. Värdet som refereras här är för den senaste versionen som släppts. Mer information om andra tillgängliga API-versioner finns i Modelllivscykel . | 2022-05-01 |
Sidhuvuden
Använd följande rubrik för att autentisera din begäran.
| Tangent | Värde |
|---|---|
Ocp-Apim-Subscription-Key |
Nyckeln till resursen. Används för att autentisera dina API-begäranden. |
Svarstext
Du får följande begäran när du skickar begäran. Fortsätt att avsöka den här slutpunkten tills statusparametern ändras till "lyckades". Du bör få en 200 kod som anger att begäran har slutförts.
{
"jobId":"{JOB-ID}",
"createdDateTime":"{CREATED-TIME}",
"lastUpdatedDateTime":"{UPDATED-TIME}",
"expirationDateTime":"{EXPIRATION-TIME}",
"status":"running"
}
Göra förutsägelser med din tränade modell
När din modell har distribuerats kan du börja använda den för att extrahera entiteter från din text med hjälp av förutsägelse-API:et. I exempeldatauppsättningen som du laddade ned tidigare hittar du några testdokument som du kan använda i det här steget.
Skicka en anpassad Textanalys för hälsoaktivitet
Använd den här POST-begäran om du vill starta en anpassad Textanalys för hälsoextrahering.
{ENDPOINT}/language/analyze-text/jobs?api-version={API-VERSION}
| Platshållare | Värde | Exempel |
|---|---|---|
{ENDPOINT} |
Slutpunkten för att autentisera din API-begäran. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{API-VERSION} |
Den version av API:et som du anropar. Värdet som refereras här är för den senaste versionen som släppts. Mer information om andra tillgängliga API-versioner finns i Modelllivscykel . | 2022-05-01 |
Sidhuvuden
| Tangent | Värde |
|---|---|
| Ocp-Apim-Subscription-Key | Din nyckel som ger åtkomst till det här API:et. |
Brödtext
{
"displayName": "Extracting entities",
"analysisInput": {
"documents": [
{
"id": "1",
"language": "{LANGUAGE-CODE}",
"text": "Text1"
},
{
"id": "2",
"language": "{LANGUAGE-CODE}",
"text": "Text2"
}
]
},
"tasks": [
{
"kind": "CustomHealthcare",
"taskName": "Custom TextAnalytics for Health Test",
"parameters": {
"projectName": "{PROJECT-NAME}",
"deploymentName": "{DEPLOYMENT-NAME}"
}
}
]
}
| Key | Platshållare | Värde | Exempel |
|---|---|---|---|
displayName |
{JOB-NAME} |
Ditt jobbnamn. | MyJobName |
documents |
[{},{}] | Lista över dokument som aktiviteter ska köras på. | [{},{}] |
id |
{DOC-ID} |
Dokumentnamn eller ID. | doc1 |
language |
{LANGUAGE-CODE} |
En sträng som anger språkkoden för dokumentet. Om den här nyckeln inte anges förutsätter tjänsten standardspråket för projektet som valdes när projektet skapades. Se språkstöd för en lista över språkkoder som stöds. | en-us |
text |
{DOC-TEXT} |
Dokumentuppgift som aktiviteterna ska köras på. | Lorem ipsum dolor sit amet |
tasks |
Lista över uppgifter som vi vill utföra. | [] |
|
taskName |
Custom Text Analytics for Health Test |
Uppgiftsnamnet | Custom Text Analytics for Health Test |
kind |
CustomHealthcare |
Den typ av projekt eller uppgift som vi försöker utföra | CustomHealthcare |
parameters |
Lista över parametrar som ska skickas till uppgiften. | ||
project-name |
{PROJECT-NAME} |
Namnet på projektet. Det här värdet är skiftlägeskänsligt. | myProject |
deployment-name |
{DEPLOYMENT-NAME} |
Namnet på distributionen. Det här värdet är skiftlägeskänsligt. | prod |
Response
Du får ett 202-svar som anger att din uppgift har skickats. I svarshuvudena extraherar du operation-location.
operation-location är formaterad så här:
{ENDPOINT}/language/analyze-text/jobs/{JOB-ID}?api-version={API-VERSION}
Du kan använda den här URL:en för att fråga efter uppgiftens slutförandestatus och få resultatet när aktiviteten har slutförts.
Hämta aktivitetsresultat
Använd följande GET-begäran för att fråga efter status/resultat för den anpassade entitetsigenkänningsaktiviteten.
{ENDPOINT}/language/analyze-text/jobs/{JOB-ID}?api-version={API-VERSION}
| Platshållare | Värde | Exempel |
|---|---|---|
{ENDPOINT} |
Slutpunkten för att autentisera din API-begäran. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{API-VERSION} |
Den version av API:et som du anropar. Värdet som refereras här är för den senaste versionen som släppts. Mer information om andra tillgängliga API-versioner finns i Modelllivscykel . | 2022-05-01 |
Sidhuvuden
| Tangent | Värde |
|---|---|
| Ocp-Apim-Subscription-Key | Din nyckel som ger åtkomst till det här API:et. |
Svarstext
Svaret är ett JSON-dokument med följande parametrar
{
"createdDateTime": "2021-05-19T14:32:25.578Z",
"displayName": "MyJobName",
"expirationDateTime": "2021-05-19T14:32:25.578Z",
"jobId": "xxxx-xxxx-xxxxx-xxxxx",
"lastUpdateDateTime": "2021-05-19T14:32:25.578Z",
"status": "succeeded",
"tasks": {
"completed": 1,
"failed": 0,
"inProgress": 0,
"total": 1,
"items": [
{
"kind": "CustomHealthcareLROResults",
"taskName": "Custom Text Analytics for Health Test",
"lastUpdateDateTime": "2020-10-01T15:01:03Z",
"status": "succeeded",
"results": {
"documents": [
{
"entities": [
{
"entityComponentInformation": [
{
"entityComponentKind": "learnedComponent"
}
],
"offset": 0,
"length": 11,
"text": "first entity",
"category": "Entity1",
"confidenceScore": 0.98
},
{
"entityComponentInformation": [
{
"entityComponentKind": "listComponent"
}
],
"offset": 0,
"length": 11,
"text": "first entity",
"category": "Entity1.Dictionary",
"confidenceScore": 1.0
},
{
"entityComponentInformation": [
{
"entityComponentKind": "learnedComponent"
}
],
"offset": 16,
"length": 9,
"text": "entity two",
"category": "Entity2",
"confidenceScore": 1.0
},
{
"entityComponentInformation": [
{
"entityComponentKind": "prebuiltComponent"
}
],
"offset": 37,
"length": 9,
"text": "ibuprofen",
"category": "MedicationName",
"confidenceScore": 1,
"assertion": {
"certainty": "negative"
},
"name": "ibuprofen",
"links": [
{
"dataSource": "UMLS",
"id": "C0020740"
},
{
"dataSource": "AOD",
"id": "0000019879"
},
{
"dataSource": "ATC",
"id": "M01AE01"
},
{
"dataSource": "CCPSS",
"id": "0046165"
},
{
"dataSource": "CHV",
"id": "0000006519"
},
{
"dataSource": "CSP",
"id": "2270-2077"
},
{
"dataSource": "DRUGBANK",
"id": "DB01050"
},
{
"dataSource": "GS",
"id": "1611"
},
{
"dataSource": "LCH_NW",
"id": "sh97005926"
},
{
"dataSource": "LNC",
"id": "LP16165-0"
},
{
"dataSource": "MEDCIN",
"id": "40458"
},
{
"dataSource": "MMSL",
"id": "d00015"
},
{
"dataSource": "MSH",
"id": "D007052"
},
{
"dataSource": "MTHSPL",
"id": "WK2XYI10QM"
},
{
"dataSource": "NCI",
"id": "C561"
},
{
"dataSource": "NCI_CTRP",
"id": "C561"
},
{
"dataSource": "NCI_DCP",
"id": "00803"
},
{
"dataSource": "NCI_DTP",
"id": "NSC0256857"
},
{
"dataSource": "NCI_FDA",
"id": "WK2XYI10QM"
},
{
"dataSource": "NCI_NCI-GLOSS",
"id": "CDR0000613511"
},
{
"dataSource": "NDDF",
"id": "002377"
},
{
"dataSource": "PDQ",
"id": "CDR0000040475"
},
{
"dataSource": "RCD",
"id": "x02MO"
},
{
"dataSource": "RXNORM",
"id": "5640"
},
{
"dataSource": "SNM",
"id": "E-7772"
},
{
"dataSource": "SNMI",
"id": "C-603C0"
},
{
"dataSource": "SNOMEDCT_US",
"id": "387207008"
},
{
"dataSource": "USP",
"id": "m39860"
},
{
"dataSource": "USPMG",
"id": "MTHU000060"
},
{
"dataSource": "VANDF",
"id": "4017840"
}
]
},
{
"entityComponentInformation": [
{
"entityComponentKind": "prebuiltComponent"
}
],
"offset": 30,
"length": 6,
"text": "100 mg",
"category": "Dosage",
"confidenceScore": 0.98
}
],
"relations": [
{
"confidenceScore": 1,
"relationType": "DosageOfMedication",
"entities": [
{
"ref": "#/documents/0/entities/1",
"role": "Dosage"
},
{
"ref": "#/documents/0/entities/0",
"role": "Medication"
}
]
}
],
"id": "1",
"warnings": []
}
],
"errors": [],
"modelVersion": "2020-04-01"
}
}
]
}
}
| Key | Exempelvärde | beskrivning |
|---|---|---|
| entiteter | [] | En matris som innehåller alla extraherade entiteter. |
| entityComponentKind | prebuiltComponent |
En variabel som anger vilken komponent som returnerade den specifika entiteten. Möjliga värden: prebuiltComponent, learnedComponent, listComponent |
| förskjutning | 0 |
Ett tal som anger startpunkten för den extraherade entiteten genom att indexera över tecknen |
| längd | 10 |
Ett tal som anger längden på den extraherade entiteten i antal tecken. |
| text | first entity |
Texten som extraherades för en specifik entitet. |
| category | MedicationName |
Namnet på entitetstypen eller kategorin som motsvarar den extraherade texten. |
| confidenceScore | 0.9 |
Ett tal som anger modellens säkerhetsnivå för den extraherade entiteten från 0 till 1 med högre tal som anger högre säkerhet. |
| assertion | certainty |
Intyg som är associerade med den extraherade entiteten. Kontroller stöds endast för fördefinierade Textanalys för hälsoentiteter. |
| name | Ibuprofen |
Det normaliserade namnet för den entitetslänkning som är associerad med den extraherade entiteten. Entitetslänkning stöds endast för fördefinierade Textanalys för hälsoentiteter. |
| länkar | [] | En matris som innehåller alla resultat från entitetslänkningen som är associerad med den extraherade entiteten. Entitetslänkning stöds endast för fördefinierade Textanalys för hälsoentiteter. |
| Datasource | UMLS |
Referensstandarden som är resultatet av entitetslänkningen som är associerad med den extraherade entiteten. Entitetslänkning stöds endast för fördefinierade Textanalys för hälsoentiteter. |
| ID | C0020740 |
Referenskoden som är resultatet av entitetens länkning som är associerad med den extraherade entiteten som tillhör den extraherade datakällan. Entitetslänkning stöds endast för fördefinierade Textanalys för hälsoentiteter. |
| Förbindelser | [] | Matris som innehåller alla extraherade relationer. Relationsextrahering stöds endast för fördefinierade Textanalys för hälsoentiteter. |
| relationType | DosageOfMedication |
Kategorin för den extraherade relationen. Relationsextrahering stöds endast för fördefinierade Textanalys för hälsoentiteter. |
| entiteter | "Dosage", "Medication" |
Entiteterna som är associerade med den extraherade relationen. Relationsextrahering stöds endast för fördefinierade Textanalys för hälsoentiteter. |
Rensa resurser
När du inte längre behöver projektet kan du ta bort det med följande DELETE-begäran . Ersätt platshållarvärdena med dina egna värden.
{Endpoint}/language/authoring/analyze-text/projects/{projectName}?api-version={API-VERSION}
| Platshållare | Värde | Exempel |
|---|---|---|
{ENDPOINT} |
Slutpunkten för att autentisera din API-begäran. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Namnet på projektet. Det här värdet är skiftlägeskänsligt. | myProject |
{API-VERSION} |
Den version av API:et som du anropar. Värdet som refereras här är för den senaste versionen som släppts. Mer information om andra tillgängliga API-versioner finns i Modelllivscykel . | 2022-05-01 |
Sidhuvuden
Använd följande rubrik för att autentisera din begäran.
| Tangent | Värde |
|---|---|
| Ocp-Apim-Subscription-Key | Nyckeln till resursen. Används för att autentisera dina API-begäranden. |
När du har skickat din API-begäran får du ett 202 svar som anger att projektet har slutförts, vilket innebär att projektet har tagits bort. Ett lyckat anrop resulterar med en rubrik för Åtgärd-plats som används för att kontrollera jobbets status.
Nästa steg
När du har skapat entitetsextraheringsmodellen kan du:
När du börjar skapa egna anpassade Textanalys för hälsoprojekt använder du instruktionsartiklarna för att lära dig mer om dataetiketter, träning och användning av din modell i detalj:
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för