Så här använder du textanalys för hälsa
Viktigt!
Textanalys för hälsa är en funktion som tillhandahålls "AS IS" och "WITH ALL FAULTS". Textanalys för hälsa är inte avsedd eller tillgänglig för användning som medicinteknisk enhet, kliniskt stöd, diagnostikverktyg eller annan teknik som är avsedd att användas för diagnos, botemedel, lindring, behandling eller förebyggande av sjukdomar eller andra tillstånd, och ingen licens eller rätt beviljas av Microsoft att använda den här funktionen för sådana ändamål. Denna funktion är inte utformad eller avsedd att genomföras eller användas som ersättning för professionell medicinsk rådgivning eller hälso- och sjukvårdsutlåtande, diagnos, behandling eller klinisk bedömning av en sjukvårdspersonal, och bör inte användas som sådan. Kunden är ensam ansvarig för all användning av textanalys för hälsa. Kunden måste ha separat licens för alla källvokabulär som den avser att använda under de villkor som anges för det UMLS Metathesaurus licensavta, bilaga eller någon framtida motsvarande länk. Kunden ansvarar för att säkerställa att licensvillkoren följs, inklusive eventuella geografiska eller andra tillämpliga begränsningar.
Textanalys för hälsa tillåter nu extrahering av SDOH (Social Determinants of Health) och etnicitetsomnämnanden i text. Denna funktion kanske inte täcker alla potentiella SDOH och härleder inte slutsatser baserade på SDOH eller etnicitet (till exempel visas information om substansanvändning, men missbruket härleds inte). Alla beslut som utnyttjar utdata från textanalysen för hälsa som påverkar individer eller resursallokering (inklusive, men inte begränsat till, de som rör fakturering, personal eller behandlingshantering av vård) bör fattas med mänsklig tillsyn och inte enbart baseras på resultaten av modellen. Syftet med SDOH och etnicitetsextrahering är att hjälpa leverantörer att förbättra hälsoresultaten och det bör inte användas för att stigmatisera eller dra negativa slutsatser om användare eller konsumenter av SDOH-data eller patientpopulationer utöver det angivna syftet att hjälpa leverantörer att förbättra hälsoresultaten.
Textanalys för hälsa kan användas för att extrahera och märka relevant medicinsk information från ostrukturerade texter som läkaranteckningar, sammanfattningar av ansvarsfrihet, kliniska dokument och elektroniska hälsojournaler. Tjänsten utför namngiven entitetsigenkänning, relationsextrahering, entitetslänkning och kontrollidentifiering för att upptäcka insikter från indatatexten. Information om de returnerade konfidenspoängen finns i transparensanteckningen.
Dricks
Om du vill testa funktionen utan att skriva någon kod använder du Language Studio.
Det finns två sätt att anropa tjänsten:
- En Docker-container (synkron)
- Använda det webbaserade API:et och klientbiblioteken (asynkrona)
Utvecklingsalternativ
Om du vill använda textanalys för hälsa skickar du ostrukturerad ostrukturerad text för analys och hanterar API-utdata i ditt program. Analysen utförs som den är, utan ytterligare anpassning till den modell som används för dina data. Det finns två sätt att använda textanalys för hälsa:
| Utvecklingsalternativ | beskrivning |
|---|---|
| Language Studio | Language Studio är en webbaserad plattform där du kan prova entitetslänkning med textexempel utan ett Azure-konto och dina egna data när du registrerar dig. Mer information finns på Language Studio-webbplatsen eller language studio-snabbstarten. |
| REST API eller klientbibliotek (Azure SDK) | Integrera textanalys för hälsa i dina program med hjälp av REST-API:et eller klientbiblioteket som är tillgängligt på flera olika språk. Mer information finns i snabbstarten Textanalys för hälsa. |
| Docker-container | Använd den tillgängliga Docker-containern för att distribuera den här funktionen lokalt. Med dessa docker-containrar kan du föra tjänsten närmare dina data av kompatibilitets-, säkerhets- eller andra driftsskäl. |
Indataspråk
Textanalys för hälsa stöder engelska utöver flera språk som för närvarande är i förhandsversion. Du kan använda det värdbaserade API:et eller distribuera API:et i en container, enligt beskrivningen under Stöd för textanalys för hälsospråk.
Skicka data
Om du vill skicka en API-begäran behöver du din language-resursslutpunkt och nyckel.
Kommentar
Du hittar nyckeln och slutpunkten för språkresursen på Azure-portalen. De kommer att finnas på resursens nyckel- och slutpunktssida under resurshantering.
Analysen utförs när begäran har tagits emot. Om du skickar en begäran med hjälp av REST-API:et eller klientbiblioteket returneras resultatet asynkront. Om du använder Docker-containern returneras de synkront.
När du använder den här funktionen asynkront är API-resultaten tillgängliga i 24 timmar från den tidpunkt då begäran matades in och anges i svaret. Efter den här tidsperioden rensas resultaten och är inte längre tillgängliga för hämtning.
Skicka en FHIR-begäran (Fast Healthcare Interoperability Resources)
Fast Healthcare Interoperability Resources (FHIR) är kommunikationsstandarden för hälsoindustrin som utvecklats av organisationen Health Level Seven International (HL7). Standarden definierar dataformat (resurser) och API-strukturen för utbyte av elektroniska sjukvårdsdata. Om du vill ta emot resultatet med hjälp av FHIR-strukturen måste du skicka FHIR-versionen i API-begärandetexten.
| Parameternamn | Type | Värde |
|---|---|---|
| fhirVersion | sträng | 4.0.1 |
Hämta resultat från funktionen
Beroende på din API-begäran och de data du skickar till textanalysen för hälsa får du:
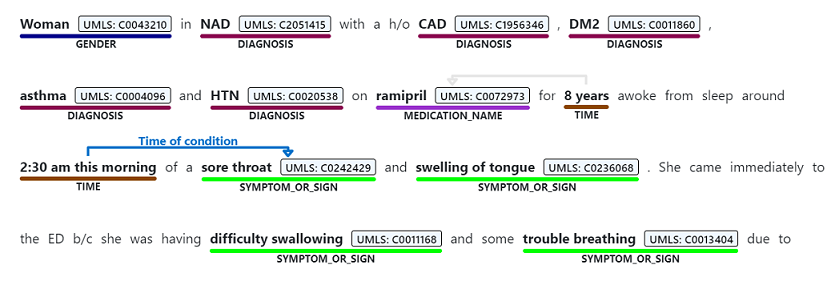
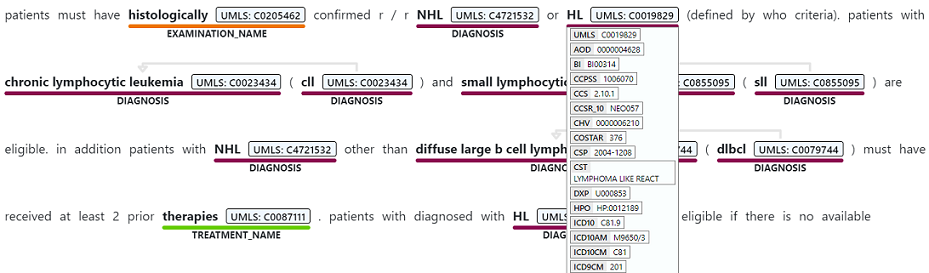
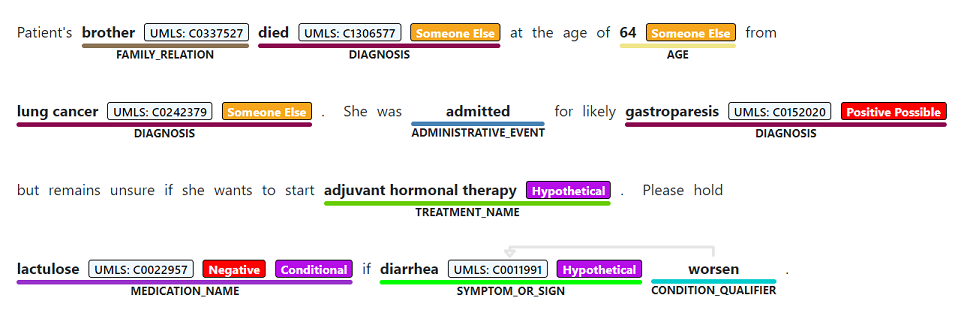
Namngiven entitetsigenkänning används för att utföra en semantisk extrahering av ord och fraser som nämns från ostrukturerad text som är associerade med någon av de entitetstyper som stöds, till exempel diagnos, medicineringsnamn, symptom/tecken eller ålder.

Tjänst- och datagränser
Information om storleken och antalet begäranden som du kan skicka per minut och sekund finns i artikeln om tjänstbegränsningar .