GPT-4 Turbo med visionsbegrepp
GPT-4 Turbo with Vision är en stor multimodal modell (LMM) utvecklad av OpenAI som kan analysera bilder och ge textsvar på frågor om dem. Den innehåller både bearbetning av naturligt språk och visuell förståelse. Den här guiden innehåller information om funktionerna och begränsningarna i GPT-4 Turbo with Vision.
Information om hur du provar GPT-4 Turbo with Vision finns i snabbstarten.
Chattar med vision
Modellen GPT-4 Turbo with Vision besvarar allmänna frågor om vad som finns i bilderna eller videorna som du laddar upp.
Förbättringar
Med förbättringar kan du införliva andra Azure AI-tjänster (till exempel Azure AI Vision) för att lägga till nya funktioner i chatt-med-vision-upplevelsen.
Objektgrundning: Azure AI Vision kompletterar GPT-4 Turbo med Visions textsvar genom att identifiera och hitta framträdande objekt i indatabilderna. På så sätt kan chattmodellen ge mer exakta och detaljerade svar om innehållet i bilden.
Viktigt!
Om du vill använda visionsförbättringar behöver du en resurs för visuellt innehåll. Den måste vara på den betalda nivån (S1) och i samma Azure-region som din GPT-4 Turbo med Vision-resurs.
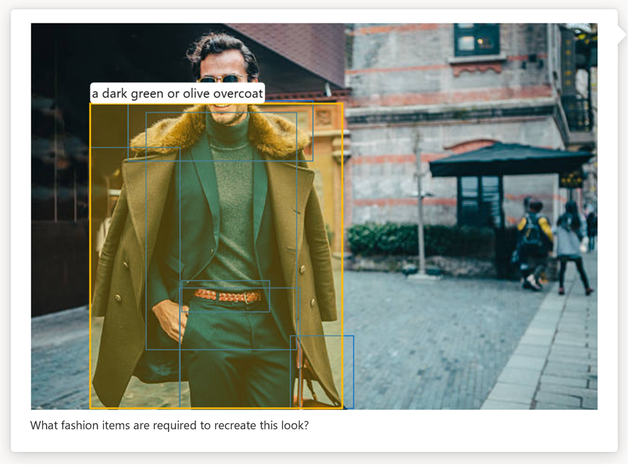

Optisk teckenigenkänning (OCR): Azure AI Vision kompletterar GPT-4 Turbo med Vision genom att tillhandahålla ocr-resultat av hög kvalitet som kompletterande information till chattmodellen. Det gör att modellen kan producera svar av högre kvalitet för bilder med tät text, transformerade bilder och talintensiva finansiella dokument, och ökar de olika språk som modellen kan känna igen i text.
Viktigt!
Om du vill använda visionsförbättringar behöver du en resurs för visuellt innehåll. Den måste vara på den betalda nivån (S1) och i samma Azure-region som din GPT-4 Turbo med Vision-resurs.

Videoprompt: Med förbättringar av videoprompten kan du använda videoklipp som indata för AI-chatt, vilket gör att modellen kan generera sammanfattningar och svar om videoinnehåll. Den använder Azure AI Vision Video Retrieval för att prova en uppsättning bildrutor från en video och skapa en transkription av talet i videon.
Kommentar
För att kunna använda videouppdateringsförbättringen behöver du både en Azure AI Vision-resurs på den betalda nivån (S1) utöver din Azure OpenAI-resurs.
Särskild prisinformation
Viktigt!
Prisinformationen kan komma att ändras i framtiden.
GPT-4 Turbo med Vision ackumulerar avgifter som andra Azure OpenAI-chattmodeller. Du betalar en pris per token för anvisningarna och slutförandena, som beskrivs på sidan Prissättning. Basavgifterna och ytterligare funktioner beskrivs här:
Grundpriser för GPT-4 Turbo med Vision är:
- Indata: 0,01 USD per 1 000 token
- Utdata: $0.03 per 1000 tokens
Mer information om hur text och bilder översätts till token finns i avsnittet Tokens i översikten .
Om du aktiverar Förbättringar gäller ytterligare användning för att använda GPT-4 Turbo with Vision med Azure AI Vision-funktioner.
| Modell | Pris |
|---|---|
| + Förbättrade tilläggsfunktioner för OCR | 1,5 USD per 1 000 transaktioner |
| + Förbättrade tilläggsfunktioner för objektidentifiering | 1,5 USD per 1 000 transaktioner |
| + Förbättrad tilläggsfunktion för integrering av videohämtning 1 | Inmatning: 0,05 USD per minut video Transaktioner: 0,25 USD per 1 000 frågor i indexet för videohämtning |
1 Bearbetningsvideor omfattar användning av extra token för att identifiera nyckelramar för analys. Antalet ytterligare token motsvarar ungefär summan av token i textinmatningen, plus 700 token.
Exempel på bildprisberäkning
Viktigt!
Följande innehåll är bara ett exempel och priserna kan komma att ändras i framtiden.
För ett typiskt användningsfall tar du en bild med både synliga objekt och text och en 100-tokens promptinmatning. När tjänsten bearbetar prompten genererar den 100 token för utdata. I bilden kan både text och objekt identifieras. Priset för den här transaktionen skulle vara:
| Artikel | Detalj | Kostnad |
|---|---|---|
| Textpromptinmatning | 100 texttoken | $0.001 |
| Exempel på bildindata (se Bildtoken) | 170 + 85 bildtoken | $0.00255 |
| Förbättrade tilläggsfunktioner för OCR | $1.50 /1000 transaktioner | 0,0015 USD |
| Förbättrade tilläggsfunktioner för object grounding | $1.50 /1000 transaktioner | 0,0015 USD |
| Utdatatoken | 100 token (antas) | $0.003 |
| Totalt | $0.00955 |
Exempel på videoprisberäkning
Viktigt!
Följande innehåll är bara ett exempel och priserna kan komma att ändras i framtiden.
För ett typiskt användningsfall kan du ta en 3-minuters video med en 100-tokens promptinmatning. Videon har en avskrift som är 100 token lång och när tjänsten bearbetar prompten genererar den 100 token för utdata. Prissättningen för den här transaktionen skulle vara:
| Artikel | Detalj | Kostnad |
|---|---|---|
| GPT-4 Turbo med Vision-indatatoken | 100 texttoken | $0.001 |
| Extra kostnad för att identifiera ramar | 100 indatatoken + 700 tokens + 1 videohämtningstransaktion | 0,00825 USD |
| Bildindata och avskriftsindata | 20 bilder (85 token vardera) + 100 transkriptionstoken | $0.018 |
| Utdatatoken | 100 token (antas) | $0.003 |
| Totalt | 0,03025 USD |
Dessutom finns det en engångskostnad för indexering på 0,15 USD för att generera videohämtningsindexet för den här 3-minutersvideon. Det här indexet kan återanvändas i valfritt antal anrop för videohämtning och GPT-4 Turbo med Vision API.
Begränsningar
I det här avsnittet beskrivs begränsningarna för GPT-4 Turbo med Vision.
Bildstöd
- Begränsning av bildförbättringar per chattsession: Förbättringar kan inte tillämpas på flera bilder i ett enda chattsamtal.
- Maximal bildstorlek för indata: Den maximala storleken för indatabilder är begränsad till 20 MB.
- Objektgrundning i api för förbättringar: När förbättrings-API:et används för objekt grounding och modellen identifierar dubbletter av ett objekt genereras en avgränsningsruta och etikett för alla dubbletter i stället för separata för varje.
- Låg upplösningsprecision: När bilder analyseras med inställningen "låg upplösning" möjliggör den snabbare svar och använder färre indatatoken för vissa användningsfall. Detta kan dock påverka precisionen för objekt- och textigenkänning i bilden.
- Begränsning av bildchatt: När du laddar upp bilder i Azure OpenAI Studio eller API:et finns det en gräns på 10 bilder per chattsamtal.
Videostöd
- Låg upplösning: Videoramar analyseras med GPT-4 Turbo med visionens inställning "låg upplösning", vilket kan påverka noggrannheten för små objekt och textigenkänning i videon.
- Gränser för videofiler: Både MP4- och MOV-filtyper stöds. I Azure OpenAI Studio måste videor vara mindre än 3 minuter långa. När du använder API:et finns det ingen sådan begränsning.
- Promptgränser: Videoprompter innehåller bara en video och inga bilder. I Azure OpenAI Studio kan du rensa sessionen för att prova en annan video eller bilder.
- Begränsat bildruteval: Tjänsten väljer 20 bildrutor från hela videon, vilket kanske inte fångar upp alla kritiska ögonblick eller information. Bildruteval kan spridas ungefär jämnt via videon eller fokuseras av en specifik videohämtningsfråga, beroende på uppmaningen.
- Språkstöd: Tjänsten stöder främst engelska för grundning med transkriptioner. Avskrifter ger inte korrekt information om texter i låtar.
Nästa steg
- Kom igång med GPT-4 Turbo with Vision genom att följa snabbstarten.
- Om du vill ha en mer djupgående titt på API:erna och använda videofrågor i chatten följer du instruktionsguiden.
- Se API-referensen för slutföranden och inbäddningar
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för