Anteckning
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Med anpassat tal kan du utvärdera och förbättra noggrannheten för taligenkänning för dina program och produkter. En anpassad talmodell kan användas för tal till text i realtid, talöversättning och batch-transkription.
Direkt använder taligenkänning en universell språkmodell som basmodell som tränas med Microsoft-ägda data och återspeglar vanligt talat språk. Basmodellen är förtränad med dialekter och fonetik som representerar olika vanliga domäner. När du gör en begäran om taligenkänning används den senaste basmodellen för varje språk som stöds som standard. Basmodellen fungerar bra i de flesta taligenkänningsscenarier.
En anpassad modell kan användas för att utöka basmodellen för att förbättra igenkänningen av domänspecifik vokabulär som är specifik för programmet genom att tillhandahålla textdata för att träna modellen. Det kan också användas för att förbättra igenkänningen baserat på programmets specifika ljudvillkor genom att tillhandahålla ljuddata med referensavskrifter.
Du kan också träna en modell med strukturerad text när data följer ett mönster, ange anpassade uttal och anpassa visningstextformatering med anpassad inverterad textnormalisering, anpassad omskrivning och anpassad svordomsfiltrering.
Hur fungerar det?
Med anpassat tal kan du ladda upp dina egna data, testa och träna en anpassad modell, jämföra noggrannhet mellan modeller och distribuera en modell till en anpassad slutpunkt.
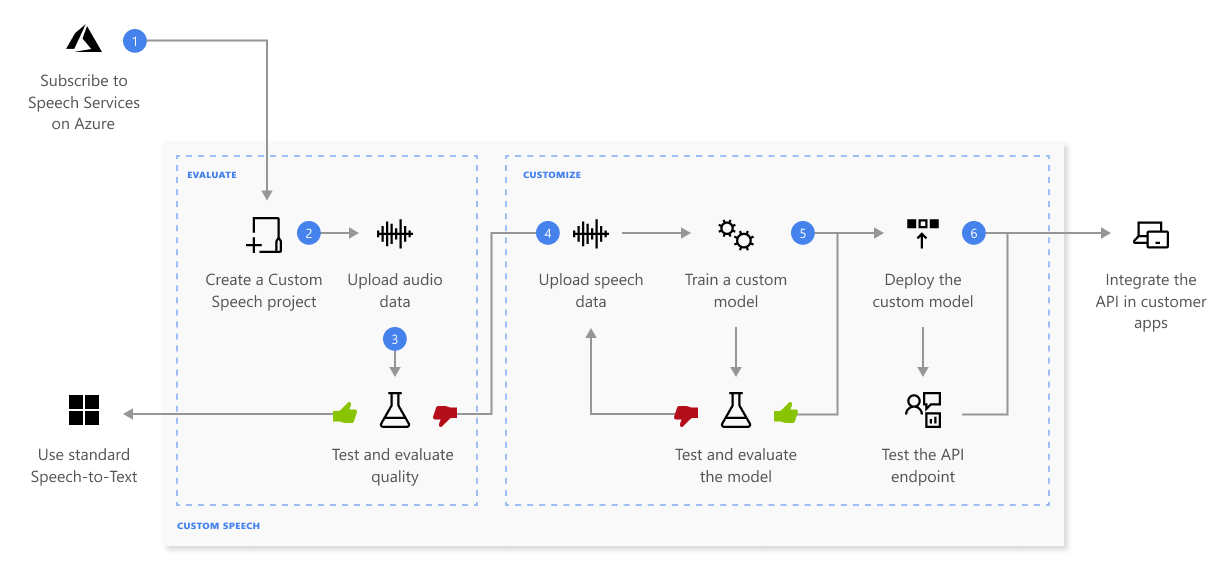
Här är mer information om sekvensen med steg som visas i föregående diagram:
Skapa ett projekt och välj en modell. Använd en som du skapar i Azure-portalen för talresurser. Om du tränar en anpassad modell med ljuddata väljer du en tjänstresurs i en region med dedikerad maskinvara för att träna ljuddata. Mer information finns i fotnoter i regionstabellen.
Ladda upp testdata. Ladda upp testdata för att utvärdera tal till text-erbjudandet för dina program, verktyg och produkter.
Träna en modell. Ange skriftliga avskrifter och relaterad text, tillsammans med motsvarande ljuddata. Att testa en modell före och efter träningen är valfritt men rekommenderas.
Kommentar
Du betalar för användning av anpassad talmodell och slutpunktsvärd. Du debiteras också för anpassad talmodellträning om basmodellen skapades den 1 oktober 2023 och senare. Du debiteras inte för träning om basmodellen skapades före oktober 2023. Mer information finns i Prissättning för Azure AI Speech och avsnittet Avgift för anpassning i migreringsguiden för tal till text 3.2.
Testigenkänningskvalitet. Använd Speech Studio för att spela upp uppladdat ljud och inspektera taligenkänningskvaliteten för dina testdata.
Testa modellen kvantitativt. Utvärdera och förbättra noggrannheten för tal till text-modellen. Speech-tjänsten tillhandahåller en kvantitativ ordfelfrekvens (WER), som du kan använda för att avgöra om mer utbildning krävs.
Distribuera en modell. När du är nöjd med testresultaten distribuerar du modellen till en anpassad slutpunkt. Förutom batch-transkription måste du distribuera en anpassad slutpunkt för att använda en anpassad talmodell.
Välj din modell
Det finns några metoder för att använda anpassade talmodeller:
- Basmodellen ger korrekt taligenkänning direkt för en rad olika scenarier. Basmodeller uppdateras regelbundet för att förbättra noggrannheten och kvaliteten. Om du använder basmodeller rekommenderar vi att du använder de senaste standardbasmodellerna. Om en nödvändig anpassningsfunktion endast är tillgänglig med en äldre modell kan du välja en äldre basmodell.
- En anpassad modell utökar basmodellen så att den inkluderar domänspecifik vokabulär som delas mellan alla områden i den anpassade domänen.
- Flera anpassade modeller kan användas när den anpassade domänen har flera områden, var och en med ett specifikt ordförråd.
Ett rekommenderat sätt att se om basmodellen räcker är att analysera transkriptionen som produceras från basmodellen och jämföra den med en mänskligt genererad transkription för samma ljud. Du kan jämföra avskrifterna och få en wer-poäng (word error rate). Om WER-poängen är hög rekommenderar vi att du tränar en anpassad modell för att identifiera felaktigt identifierade ord.
Flera modeller rekommenderas om vokabulären varierar mellan domänområdena. Till exempel rapporterar olympiska kommentatorer om olika evenemang, var och en associerad med sin egen vernacular. Eftersom varje os-händelseförråd skiljer sig avsevärt från andra ökar skapandet av en anpassad modell som är specifik för en händelse noggrannheten genom att begränsa yttrandenas data i förhållande till den specifika händelsen. Därför behöver modellen inte söka igenom orelaterade data för att göra en matchning. Oavsett, träning kräver fortfarande en anständig mängd träningsdata. Inkludera ljud från olika kommentatorer som har olika accenter, kön, ålder osv.
Modellstabilitet och livscykel
En basmodell eller anpassad modell som distribuerats till en slutpunkt med anpassat tal har åtgärdats tills du bestämmer dig för att uppdatera den. Taligenkänningens noggrannhet och kvalitet förblir konsekventa, även när en ny basmodell släpps. På så sätt kan du låsa beteendet för en specifik modell tills du bestämmer dig för att använda en nyare modell.
Oavsett om du tränar din egen modell eller använder en ögonblicksbild av en basmodell kan du använda modellen under en begränsad tid. Mer information finns i Livscykel för modell och slutpunkt.
Ansvarsfull AI
Ett AI-system innehåller inte bara tekniken, utan även de personer som använder den, de personer som påverkas av den och miljön där den distribueras. Läs transparensanteckningarna om du vill veta mer om ansvarsfull AI-användning och distribution i dina system.
- Antecknings- och användningsfall för transparens
- Egenskaper och begränsningar
- Integrering och ansvarsfull användning
- Data, sekretess och säkerhet