Vad är nyckelordsigenkänning?
Nyckelordsigenkänning identifierar ett ord eller en kort fras i en ljudström. Den här tekniken kallas även för nyckelordss spotting.
Det vanligaste användningsfallet för nyckelordsigenkänning är röstaktivering av virtuella assistenter. Till exempel är "Hey Cortana" nyckelordet för Cortana-assistenten. När nyckelordet har erkänts utförs en scenariospecifik åtgärd. För scenarier med virtuella assistenter är en vanlig resulterande åtgärd taligenkänning av ljud som följer nyckelordet.
I allmänhet lyssnar virtuella assistenter alltid. Nyckelordsigenkänning fungerar som en sekretessgräns för användaren. Ett nyckelordskrav fungerar som en grind som hindrar orelaterat användarljud från att korsa den lokala enheten till molnet.
För att balansera noggrannhet, svarstid och beräkningskomplexitet implementeras nyckelordsigenkänning som ett flerstegssystem. För alla steg utöver den första bearbetas endast ljud om fasen innan den känner igen nyckelordet av intresse.
Det aktuella systemet är utformat med flera steg som sträcker sig över gränsen och molnet:
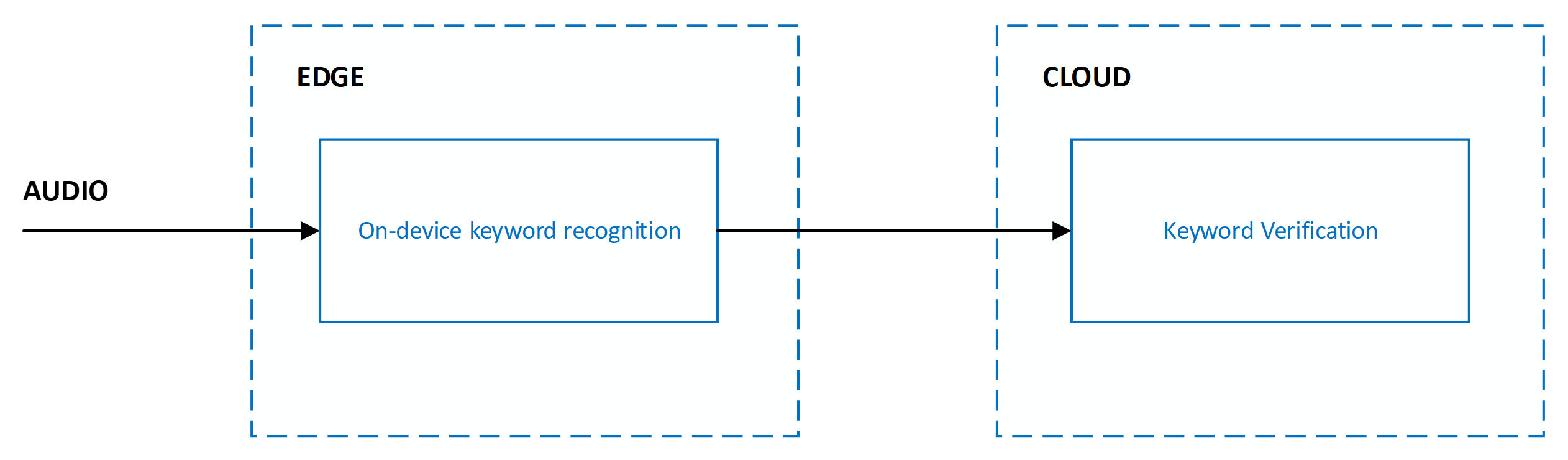
Noggrannheten för nyckelordsigenkänning mäts via följande mått:
- Rätt acceptfrekvens: Mäter systemets förmåga att identifiera nyckelordet när det talas av en användare. Rätt acceptfrekvens kallas även för den sanna positiva frekvensen.
- Falsk acceptfrekvens: Mäter systemets möjlighet att filtrera bort ljud som inte är nyckelordet som talas av en användare. Den falska acceptfrekvensen kallas även för falsk positiv frekvens.
Målet är att maximera rätt acceptfrekvens samtidigt som värdet för falskt accepterande minimeras. Det aktuella systemet är utformat för att identifiera ett nyckelord eller en fras som föregås av en kort tystnad. Det går inte att identifiera ett nyckelord mitt i en mening eller ett yttrande.
Anpassat nyckelord för enhetsmodeller
Med portalen för anpassat nyckelord i Speech Studio kan du generera nyckelordsigenkänningsmodeller som körs vid gränsen genom att ange valfritt ord eller en kort fras. Du kan anpassa nyckelordsmodellen ytterligare genom att välja rätt uttal.
Prissättning
Det kostar ingenting att använda anpassade nyckelord för att generera modeller, inklusive både Basic- och Advanced-modeller. Det kostar inte heller någon kostnad att köra modeller på enheten med Speech SDK när de används med andra Speech-tjänstfunktioner som tal till text.
Typer av modeller
Du kan använda anpassat nyckelord för att generera två typer av enhetsmodeller för valfritt nyckelord.
| Modelltyp | beskrivning |
|---|---|
| Grundläggande | Passar bäst för demo eller snabba prototyper. Modeller genereras med en gemensam basmodell och kan ta upp till 15 minuter att vara redo. Modeller kanske inte har optimala noggrannhetsegenskaper. |
| Avancerad | Passar bäst för produktintegrering. Modeller genereras med anpassning av en gemensam basmodell med hjälp av simulerade träningsdata för att förbättra noggrannhetsegenskaperna. Det kan ta upp till 48 timmar innan modeller är klara. |
Kommentar
Du kan visa en lista över regioner som stöder typen Avancerad modell i supportdokumentationen för nyckelordsigenkänningsregionen.
Ingen av modelltyperna kräver att du laddar upp träningsdata. Anpassat nyckelord hanterar datagenerering och modellträning fullt ut.
Uttal
När du skapar en ny modell genererar anpassat nyckelord automatiskt möjliga uttal av det angivna nyckelordet. Du kan lyssna på varje uttal och välja alla varianter som nära representerar hur du förväntar dig att användarna ska säga nyckelordet. Alla andra uttal bör inte väljas.
Det är viktigt att vara medveten om de uttal du väljer för att säkerställa bästa noggrannhetsegenskaper. Om du till exempel väljer fler uttal än du behöver kan du få högre false accept-priser. Om du väljer för få uttal, där inte alla förväntade variationer omfattas, kan du få lägre korrekta acceptfrekvenser.
Testmodeller
När anpassade nyckelord genererar enhetsmodeller kan modellerna testas direkt på portalen. Du kan använda portalen för att tala direkt i webbläsaren och få resultat för nyckelordsigenkänning.
Nyckelordsverifiering
Nyckelordsverifiering är en molntjänst som minskar effekten av falska accepter från enhetsmodeller med robusta modeller som körs i Azure. Justering eller träning krävs inte för att nyckelordsverifiering ska fungera med nyckelordet. Inkrementella modelluppdateringar distribueras kontinuerligt till tjänsten för att förbättra noggrannheten och svarstiden och är transparenta för klientprogram.
Prissättning
Nyckelordsverifiering används alltid i kombination med tal till text. Det kostar ingenting att använda nyckelordsverifiering utöver kostnaden för tal till text.
Nyckelordsverifiering och tal till text
När nyckelordsverifiering används är det alltid i kombination med tal till text. Båda tjänsterna körs parallellt, vilket innebär att ljud skickas till båda tjänsterna för samtidig bearbetning.
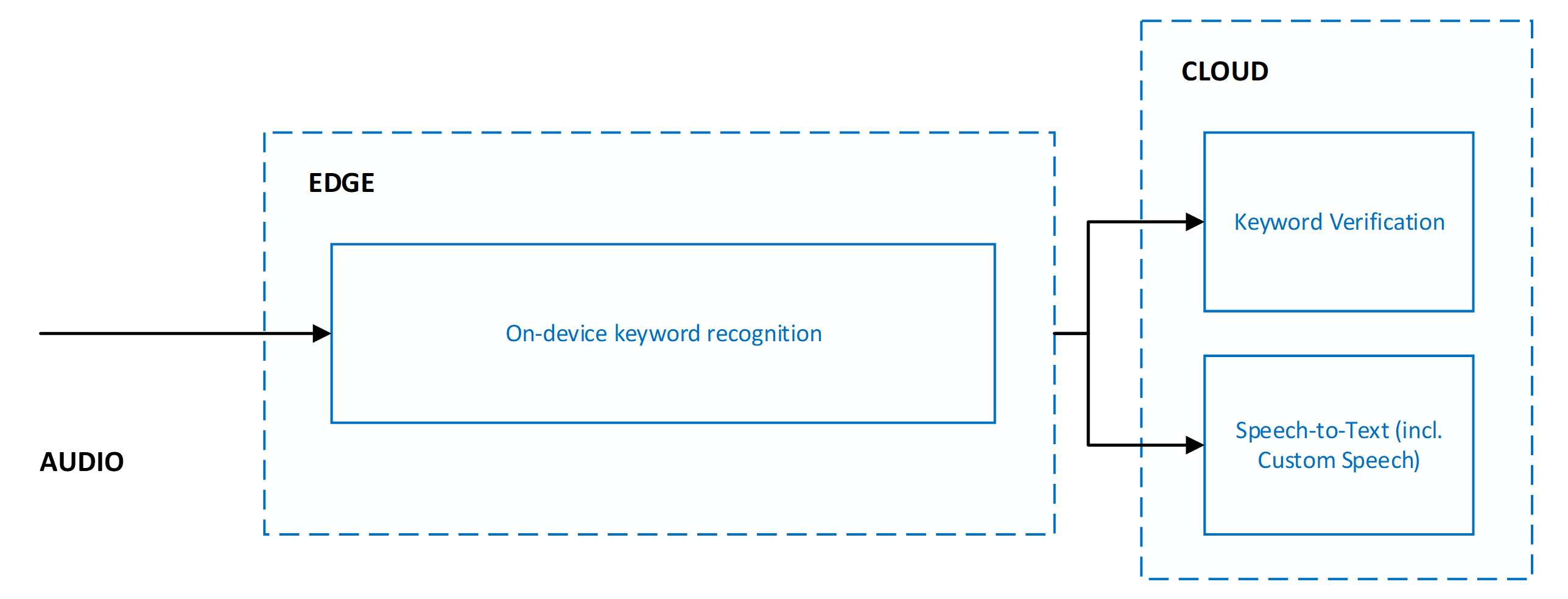
Om du kör nyckelordsverifiering och tal till text parallellt får du följande fördelar:
- Ingen annan svarstid för tal till textresultat: Parallell körning innebär att nyckelordsverifiering inte lägger till någon svarstid. Klienten får tal till textresultat så snabbt. Om nyckelordsverifieringen fastställer att nyckelordet inte fanns i ljudet avslutas bearbetningen av tal till text. Den här åtgärden skyddar mot onödigt tal till textbearbetning. Bearbetning av nätverks- och molnmodeller ökar den användarupplevda svarstiden för röstaktivering. Mer information finns i Rekommendationer och riktlinjer.
- Framtvingat nyckelordsprefix i tal till text-resultat: Tal till text-bearbetning säkerställer att resultaten som skickas till klienten prefixet med nyckelordet. Det här beteendet möjliggör ökad noggrannhet i tal till text-resultat för tal som följer nyckelordet.
- Ökad timeout för tal till text: På grund av den förväntade förekomsten av nyckelordet i början av ljud tillåter tal till text en längre paus på upp till fem sekunder efter nyckelordet innan det fastställer slutet av talet och avslutar tal till textbearbetning. Det här beteendet säkerställer att användarupplevelsen hanteras korrekt för mellanlagrade kommandon (<nyckelords><pauskommando>><) och länkade kommandon (<nyckelordskommando).>><
Nyckelordsverifieringssvar och svarstidsöverväganden
För varje begäran till tjänsten returnerar nyckelordsverifiering ett av två svar: godkänt eller avvisat. Svarstiden för bearbetningen varierar beroende på nyckelordets längd och längden på det ljudsegment som förväntas innehålla nyckelordet. Svarstid för bearbetning omfattar inte nätverkskostnader mellan klienten och Speech-tjänsterna.
| Svar på nyckelordsverifiering | beskrivning |
|---|---|
| Godkänd | Anger att tjänsten trodde att nyckelordet fanns i ljudströmmen som tillhandahålls som en del av begäran. |
| Avvisat | Anger att tjänsten trodde att nyckelordet inte fanns i ljudströmmen som tillhandahålls som en del av begäran. |
Avvisade fall ger ofta högre svarstider eftersom tjänsten bearbetar mer ljud än godkända fall. Som standard bearbetar nyckelordsverifiering högst två sekunders ljud för att söka efter nyckelordet. Om nyckelordet inte hittas på två sekunder överskrider tjänsten tidsgränsen och signalerar ett avvisat svar till klienten.
Använda nyckelordsverifiering med enhetsmodeller från anpassat nyckelord
Speech SDK möjliggör sömlös användning av enhetsmodeller som genereras med hjälp av anpassat nyckelord med nyckelordsverifiering och tal till text. Den hanterar transparent:
- Ljud som gating till nyckelordsverifiering och taligenkänning baserat på resultatet av en modell på enheten.
- Kommunicera nyckelordet till nyckelordsverifiering.
- Kommunicera fler metadata till molnet för orkestrering av scenariot från slutpunkt till slutpunkt.
Du behöver inte uttryckligen ange några konfigurationsparametrar. All nödvändig information extraheras automatiskt från den enhetsmodell som genereras av ett anpassat nyckelord.
Exemplet och självstudierna som är länkade här visar hur du använder Speech SDK:
- Röstassistentexempel på GitHub
- Självstudie: Röstaktivera din assistent som skapats med Hjälp av Azure AI Bot Service med C# Speech SDK
- Självstudie: Skapa ett anpassat kommandoprogram med enkla röstkommandon
Integrering och scenarier för Speech SDK
Speech SDK möjliggör enkel användning av anpassade modeller för nyckelordsigenkänning på enheten som genereras med anpassad nyckelords- och nyckelordsverifiering. För att säkerställa att dina produktbehov kan uppfyllas stöder SDK följande två scenarier:
| Scenario | beskrivning | Exempel |
|---|---|---|
| Nyckelordsigenkänning från slutpunkt till slutpunkt med tal till text | Passar bäst för produkter som använder en anpassad nyckelordsmodell på enheten från anpassat nyckelord med nyckelordsverifiering och tal till text. Det här scenariot är det vanligaste. | |
| Nyckelordsigenkänning offline | Passar bäst för produkter utan nätverksanslutning som använder en anpassad nyckelordsmodell på enheten från anpassat nyckelord. |