Lägga till en datauppsättning för professionell röstträning
När du är redo att skapa en anpassad text till talröst för ditt program är det första steget att samla in ljudinspelningar och tillhörande skript för att börja träna röstmodellen. Mer information om hur du spelar in röstexempel finns i självstudien. Speech-tjänsten använder dessa data för att skapa en unik röst som är justerad för att matcha rösten i inspelningarna. När du har tränat rösten kan du börja syntetisera tal i dina program.
Alla data som du laddar upp måste uppfylla kraven för den datatyp som du väljer. Det är viktigt att formatera dina data korrekt innan de laddas upp, vilket säkerställer att data bearbetas korrekt av Speech-tjänsten. Information om hur du bekräftar att dina data är korrekt formaterade finns i Träningsdatatyper.
Kommentar
- Standardprenumerationsanvändare (S0) kan ladda upp fem datafiler samtidigt. Om du når gränsen väntar du tills minst en av dina datafiler har importerats. Försök sedan igen.
- Det maximala antalet datafiler som tillåts importeras per prenumeration är 500 .zip filer för standardprenumerationsanvändare (S0). Mer information finns i kvoter och gränser för Speech-tjänsten.
Ladda upp dina data
När du är redo att ladda upp dina data går du till fliken Förbered träningsdata för att lägga till din första träningsuppsättning och ladda upp data. En träningsuppsättning är en uppsättning ljudyttranden och deras mappningsskript som används för att träna en röstmodell. Du kan använda en träningsuppsättning för att organisera dina träningsdata. Tjänsten kontrollerar databeredskapen per varje träningsuppsättning. Du kan importera flera data till en träningsuppsättning.
Följ dessa steg för att ladda upp träningsdata:
- Logga in på Speech Studio.
- Välj Anpassad röst> Projektnamnet >Förbered träningsdata>Ladda upp data.
- I guiden Ladda upp data väljer du en datatyp och väljer sedan Nästa.
- Välj lokala filer från datorn eller ange URL:en för Azure Blob Storage för att ladda upp data.
- Under Ange målträningsuppsättningen väljer du en befintlig träningsuppsättning eller skapar en ny. Om du har skapat en ny träningsuppsättning kontrollerar du att den är markerad i listrutan innan du fortsätter.
- Välj Nästa.
- Ange ett namn och en beskrivning för dina data och välj sedan Nästa.
- Granska uppladdningsinformationen och välj Skicka.
Kommentar
Dubblett-ID:t accepteras inte. Yttranden med samma ID tas bort.
Dubbletter av ljudnamn tas bort från träningen. Kontrollera att de data du väljer inte innehåller samma ljudnamn i filen .zip eller flera .zip filer. Om yttrande-ID:t (antingen i ljud- eller skriptfiler) är dubbletter avvisas de.
Datafiler verifieras automatiskt när du väljer Skicka. Dataverifiering innehåller en serie kontroller av ljudfilerna för att verifiera filformat, storlek och samplingshastighet. Om det finns några fel kan du åtgärda dem och skicka dem igen.
När du har laddat upp data kan du kontrollera informationen i träningsuppsättningens detaljvy. På informationssidan kan du ytterligare kontrollera uttalsproblemet och brusnivån för var och en av dina data. Uttalspoängen på meningsnivå varierar från 0-100. En poäng under 70 indikerar normalt ett talfel eller ett felmatchat skript. Yttranden med en övergripande poäng som är lägre än 70 avvisas. En tung accent kan minska uttalspoängen och påverka den genererade digitala rösten.
Lösa dataproblem online
Efter uppladdningen kan du kontrollera datainformationen för träningsuppsättningen. Innan du fortsätter att träna din röstmodell bör du försöka lösa eventuella dataproblem.
Du kan identifiera och lösa dataproblem per yttrande i Speech Studio.
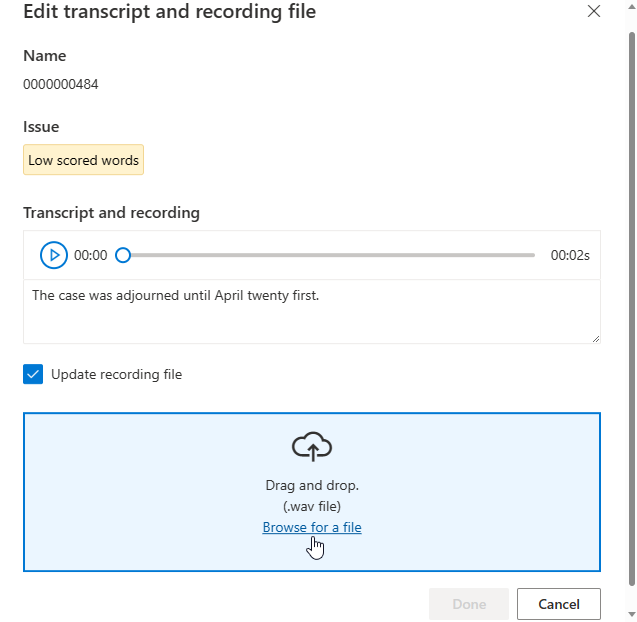
På detaljsidan går du till sidan Accepterade data eller Avvisade data . Välj enskilda yttranden som du vill ändra och välj sedan Redigera.
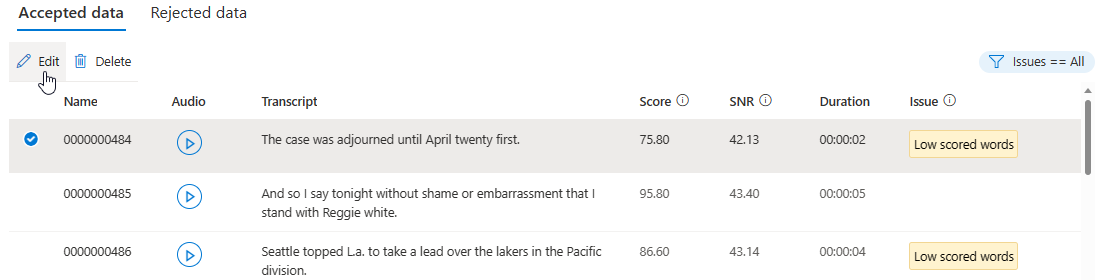
Du kan välja vilka dataproblem som ska visas baserat på dina kriterier.
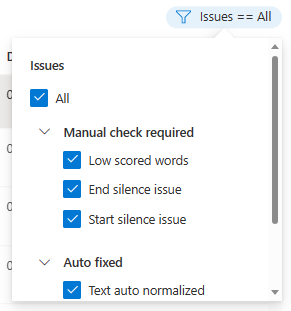
Redigeringsfönstret visas.
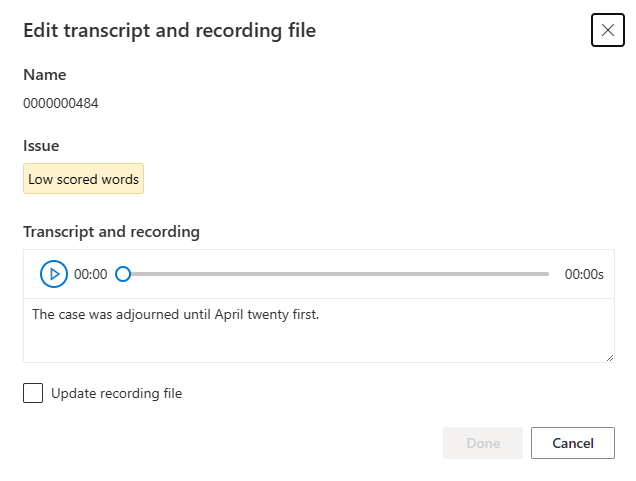
Uppdatera avskriften eller inspelningsfilen enligt problembeskrivningen i redigeringsfönstret.
Du kan redigera avskriften i textrutan och sedan välja Klar
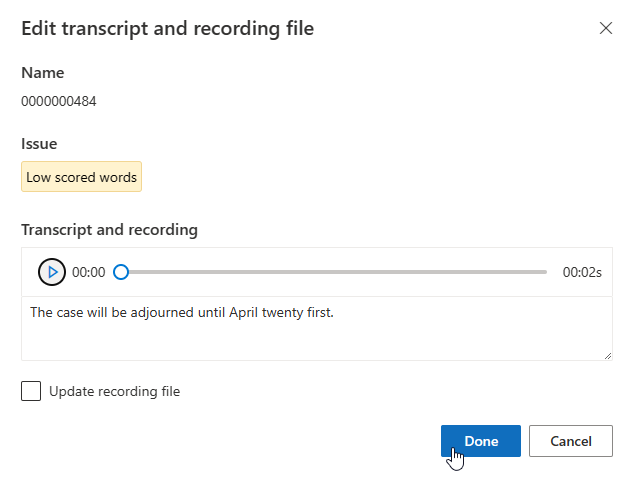
Om du behöver uppdatera inspelningsfilen väljer du Uppdatera inspelningsfil och laddar sedan upp den fasta inspelningsfilen (.wav).
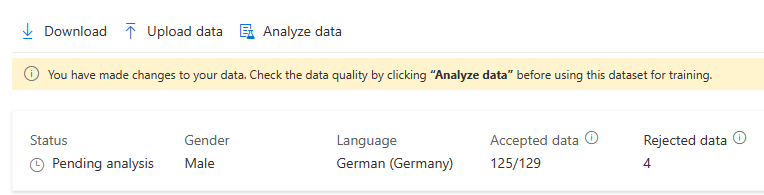
När du har gjort ändringar i dina data måste du kontrollera datakvaliteten genom att klicka på Analysera data innan du använder den här datamängden för träning.
Du kan inte välja den här träningsuppsättningen för träningsmodellen innan analysen är klar.
Du kan också ta bort yttranden med problem genom att välja dem och klicka på Ta bort.
Vanliga dataproblem
Problemen är indelade i tre typer. Se följande tabeller för att kontrollera respektive typ av fel.
Avvisas automatiskt
Data med dessa fel används inte för träning. Importerade data med fel ignoreras, så du behöver inte ta bort dem. Du kan åtgärda dessa datafel online eller ladda upp korrigerade data igen för träning.
| Kategori | Name | beskrivning |
|---|---|---|
| Skript | Ogiltig avgränsare | Du måste avgränsa yttrande-ID:t och skriptinnehållet med ett fliktecken. |
| Skript | Ogiltigt skript-ID | Skriptrads-ID:t måste vara numeriskt. |
| Skript | Duplicerat skript | Varje rad i skriptinnehållet måste vara unik. Raden dupliceras med {}. |
| Skript | Skriptet är för långt | Skriptet måste vara mindre än 1 000 tecken. |
| Skript | Inget matchande ljud | ID:t för varje yttrande (varje rad i skriptfilen) måste matcha ljud-ID:t. |
| Skript | Inget giltigt skript | Det finns inget giltigt skript i den här datamängden. Åtgärda de skriptrader som visas i den detaljerade problemlistan. |
| Ljud | Inget matchande skript | Inga ljudfiler matchar skript-ID:t. Namnet på de .wav filerna måste matcha med ID:erna i skriptfilen. |
| Ljud | Ogiltigt ljudformat | Ljudformatet för .wav filer är ogiltigt. Kontrollera filformatet .wav med hjälp av ett ljudverktyg som SoX. |
| Ljud | Låg samplingsfrekvens | Samplingsfrekvensen för .wav filer får inte vara lägre än 16 KHz. |
| Ljud | För långt ljud | Ljudvaraktigheten är längre än 30 sekunder. Dela upp det långa ljudet i flera filer. Det är en bra idé att göra yttranden kortare än 15 sekunder. |
| Ljud | Inget giltigt ljud | Inget giltigt ljud hittades i den här datauppsättningen. Kontrollera dina ljuddata och ladda upp igen. |
| Obalans | Låg poängsatt yttrande | Uttalspoängen på meningsnivå är lägre än 70. Granska skriptet och ljudinnehållet för att se till att de matchar. |
Automatiskt fast
Följande fel åtgärdas automatiskt, men du bör granska och bekräfta att korrigeringarna har utförts korrekt.
| Kategori | Name | beskrivning |
|---|---|---|
| Obalans | Tystnaden har korrigerats automatiskt | Starttystnaden identifieras vara kortare än 100 ms och har utökats till 100 ms automatiskt. Ladda ned den normaliserade datamängden och granska den. |
| Obalans | Tystnaden har korrigerats automatiskt | Sluttystnaden identifieras vara kortare än 100 ms och har utökats till 100 ms automatiskt. Ladda ned den normaliserade datamängden och granska den. |
| Skript | Automatisk normaliserad text | Text normaliseras automatiskt för siffror, symboler och förkortningar. Granska skriptet och ljudet för att se till att de matchar. |
Manuell kontroll krävs
Olösta fel som anges i nästa tabell påverkar kvaliteten på träningen, men data med dessa fel utesluts inte under träningen. För utbildning av högre kvalitet är det en bra idé att åtgärda dessa fel manuellt.
| Kategori | Name | beskrivning |
|---|---|---|
| Skript | Icke-normaliserad text | Det här skriptet innehåller symboler. Normalisera symbolerna så att de matchar ljudet. Normalisera / till exempel till snedstreck. |
| Skript | Inte tillräckligt med frågeyttranden | Minst 10 procent av de totala yttrandena ska vara fråge meningar. Detta hjälper röstmodellen att uttrycka en ifrågasättande ton korrekt. |
| Skript | Inte tillräckligt med utropstecken | Minst 10 procent av de totala yttrandena ska vara utrops meningar. Detta hjälper röstmodellen att uttrycka en upphetsad ton korrekt. |
| Skript | Ingen giltig slutpunktion | Lägg till något av följande i slutet av raden: fullständigt stopp (halvbredd" eller fullbredd " 。 '), utropstecken (halvbredd '!' eller fullbredd '!' ), eller frågetecken ( halvbredd '?' eller full bredd '?'). |
| Ljud | Låg samplingsfrekvens för neural röst | Vi rekommenderar att samplingsfrekvensen för dina .wav filer ska vara 24 KHz eller högre för att skapa neurala röster. Om den är lägre höjs den automatiskt till 24 KHz. |
| Volume | Den totala volymen är för låg | Volymen får inte vara lägre än -18 dB (10 procent av maxvolymen). Kontrollera volymens genomsnittsnivå inom rätt intervall under provinspelningen eller dataförberedelsen. |
| Volume | Volymspill | Spillande volym identifieras på {}s. Justera inspelningsutrustningen för att undvika att volymen flödar över vid dess högsta värde. |
| Volume | Starta tystnadsproblem | De första 100 ms tystnaden är inte rena. Minska inspelningsbrusgolvet och låt de första 100 msna vara tysta. |
| Volume | Avsluta tystnadsproblem | De sista 100 ms tystnaden är inte rena. Minska inspelningsbrusgolvet och lämna de sista 100 ms i slutet tyst. |
| Obalans | Låg poängsatta ord | Granska skriptet och ljudinnehållet för att se till att de matchar och kontrollera ljudnivån. Minska längden på lång tystnad eller dela upp ljudet i flera yttranden om det är för långt. |
| Obalans | Starta tystnadsproblem | Extra ljud hördes före det första ordet. Granska skriptet och ljudinnehållet för att se till att de matchar, kontrollera ljudnivån och gör de första 100 ms tysta. |
| Obalans | Avsluta tystnadsproblem | Extra ljud hördes efter sista ordet. Granska skriptet och ljudinnehållet för att se till att de matchar, kontrollera ljudnivån och gör de sista 100 ms tysta. |
| Obalans | Lågt signalbrusförhållande | Ljud-SNR-nivån är lägre än 20 dB. Minst 35 dB rekommenderas. |
| Obalans | Ingen poäng är tillgänglig | Det gick inte att identifiera talinnehåll i det här ljudet. Kontrollera ljud- och skriptinnehållet för att kontrollera att ljudet är giltigt och matchar skriptet. |
Nästa steg
Du behöver en träningsdatauppsättning för att skapa en professionell röst. En träningsdatauppsättning innehåller ljud- och skriptfiler. Ljudfilerna är inspelningar av rösttalangen som läser skriptfilerna. Skriptfilerna är texten i ljudfilerna.
I den här artikeln skapar du en träningsuppsättning och hämtar dess resurs-ID. Med hjälp av resurs-ID:t kan du sedan ladda upp en uppsättning ljud- och skriptfiler.
Skapa en träningsuppsättning
Om du vill skapa en träningsuppsättning använder du den TrainingSets_Create åtgärden för det anpassade röst-API:et. Skapa begärandetexten enligt följande instruktioner:
- Ange den obligatoriska
projectIdegenskapen. Se skapa ett projekt. - Ange den obligatoriska
voiceKindegenskapen tillMaleellerFemale. Det går inte att ändra typen senare. - Ange den obligatoriska
localeegenskapen. Detta bör vara språkvarianten för träningsuppsättningsdata. Språkvarianten för träningsuppsättningen bör vara samma som språkvarianten för medgivandeuttryck. Språkvarianten kan inte ändras senare. Du hittar språklistan för text till tal här. - Du kan också ange
descriptionegenskapen för beskrivningen av träningsuppsättningen. Beskrivningen av träningsuppsättningen kan ändras senare.
Gör en HTTP PUT-begäran med hjälp av URI:n enligt följande TrainingSets_Create exempel.
- Ersätt
YourResourceKeymed din Speech-resursnyckel. - Ersätt
YourResourceRegionmed din Speech-resursregion. - Ersätt
JessicaTrainingSetIdmed ett valfritt träningsuppsättnings-ID. Skiftlägeskänsligt ID används i träningsuppsättningens URI och kan inte ändras senare.
curl -v -X PUT -H "Ocp-Apim-Subscription-Key: YourResourceKey" -H "Content-Type: application/json" -d '{
"description": "300 sentences Jessica data in general style.",
"projectId": "ProjectId",
"locale": "en-US",
"voiceKind": "Female"
} ' "https://YourResourceRegion.api.cognitive.microsoft.com/customvoice/trainingsets/JessicaTrainingSetId?api-version=2024-02-01-preview"
Du bör få en svarstext i följande format:
{
"id": "JessicaTrainingSetId",
"description": "300 sentences Jessica data in general style.",
"projectId": "ProjectId",
"locale": "en-US",
"voiceKind": "Female",
"status": "Succeeded",
"createdDateTime": "2023-04-01T05:30:00.000Z",
"lastActionDateTime": "2023-04-02T10:15:30.000Z"
}
Ladda upp träningsuppsättningsdata
Om du vill ladda upp en träningsuppsättning med ljud och skript använder du den TrainingSets_UploadData driften av det anpassade röst-API:et.
Innan du anropar det här API:et ska du lagra inspelnings- och skriptfiler i Azure Blob. I exemplet nedan är inspelningsfiler *.wav, skriptfiler är https://contoso.blob.core.windows.net/voicecontainer/jessica300/*.txt.https://contoso.blob.core.windows.net/voicecontainer/jessica300/
Skapa begärandetexten enligt följande instruktioner:
- Ange den obligatoriska
kindegenskapen tillAudioAndScript. Typen avgör typen av träningsuppsättning. - Ange den obligatoriska
audiosegenskapen. Ange följande egenskaper iaudiosegenskapen:- Ange den obligatoriska
containerUrlegenskapen till URL:en för Azure Blob Storage-containern som innehåller ljudfilerna. Använd signaturer för delad åtkomst (SAS) för en container med både läs- och listbehörigheter. - Ange den obligatoriska
extensionsegenskapen till filnamnstilläggen för ljudfilerna. - Du kan också ange
prefixegenskapen för att ange ett prefix för blobnamnet.
- Ange den obligatoriska
- Ange den obligatoriska
scriptsegenskapen. Ange följande egenskaper iscriptsegenskapen:- Ange den obligatoriska
containerUrlegenskapen till URL:en för Azure Blob Storage-containern som innehåller skriptfilerna. Använd signaturer för delad åtkomst (SAS) för en container med både läs- och listbehörigheter. - Ange den obligatoriska
extensionsegenskapen till tilläggen för skriptfilerna. - Du kan också ange
prefixegenskapen för att ange ett prefix för blobnamnet.
- Ange den obligatoriska
Gör en HTTP POST-begäran med hjälp av URI:n enligt följande TrainingSets_UploadData exempel.
- Ersätt
YourResourceKeymed din Speech-resursnyckel. - Ersätt
YourResourceRegionmed din Speech-resursregion. - Ersätt
JessicaTrainingSetIdom du angav ett annat träningsuppsättnings-ID i föregående steg.
curl -v -X POST -H "Ocp-Apim-Subscription-Key: YourResourceKey" -H "Content-Type: application/json" -d '{
"kind": "AudioAndScript",
"audios": {
"containerUrl": "https://contoso.blob.core.windows.net/voicecontainer?mySasToken",
"prefix": "jessica300/",
"extensions": [
".wav"
]
},
"scripts": {
"containerUrl": "https://contoso.blob.core.windows.net/voicecontainer?mySasToken",
"prefix": "jessica300/",
"extensions": [
".txt"
]
}
} ' "https://YourResourceRegion.api.cognitive.microsoft.com/customvoice/trainingsets/JessicaTrainingSetId:upload?api-version=2024-02-01-preview"
Svarshuvudet innehåller egenskapen Operation-Location . Använd den här URI:n för att få information om den TrainingSets_UploadData åtgärden. Här är ett exempel på svarshuvudet:
Operation-Location: https://eastus.api.cognitive.microsoft.com/customvoice/operations/284b7e37-f42d-4054-8fa9-08523c3de345?api-version=2024-02-01-preview
Operation-Id: 284b7e37-f42d-4054-8fa9-08523c3de345