Cluster autoscaling in Azure Kubernetes Service (AKS) overview
To keep up with application demands in Azure Kubernetes Service (AKS), you might need to adjust the number of nodes that run your workloads. The cluster autoscaler component watches for pods in your cluster that can't be scheduled because of resource constraints. When the cluster autoscaler detects unscheduled pods, it scales up the number of nodes in the node pool to meet the application demand. It also regularly checks nodes that don't have any scheduled pods and scales down the number of nodes as needed.
This article helps you understand how the cluster autoscaler works in AKS. It also provides guidance, best practices, and considerations when configuring the cluster autoscaler for your AKS workloads. If you want to enable, disable, or update the cluster autoscaler for your AKS workloads, see Use the cluster autoscaler in AKS.
About the cluster autoscaler
Clusters often need a way to scale automatically to adjust to changing application demands, such as between workdays and evenings or weekends. AKS clusters can scale in the following ways:
- The cluster autoscaler periodically checks for pods that can't be scheduled on nodes because of resource constraints. The cluster then automatically increases the number of nodes. Manual scaling is disabled when you use the cluster autoscaler. For more information, see How does scale up work?.
- The Horizontal Pod Autoscaler uses the Metrics Server in a Kubernetes cluster to monitor the resource demand of pods. If an application needs more resources, the number of pods is automatically increased to meet the demand.
- The Vertical Pod Autoscaler automatically sets resource requests and limits on containers per workload based on past usage to ensure pods are scheduled onto nodes that have the required CPU and memory resources.
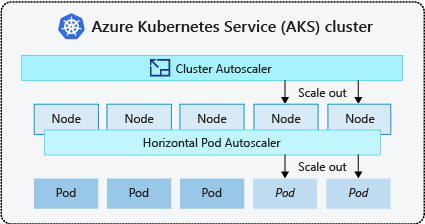
It's a common practice to enable cluster autoscaler for nodes and either the Vertical Pod Autoscaler or Horizontal Pod Autoscaler for pods. When you enable the cluster autoscaler, it applies the specified scaling rules when the node pool size is lower than the minimum node count, up to the maximum node count. The cluster autoscaler waits to take effect until a new node is needed in the node pool or until a node might be safely deleted from the current node pool. For more information, see How does scale down work?
Best practices and considerations
- When implementing availability zones with the cluster autoscaler, we recommend using a single node pool for each zone. You can set the
--balance-similar-node-groupsparameter toTrueto maintain a balanced distribution of nodes across zones for your workloads during scale up operations. When this approach isn't implemented, scale down operations can disrupt the balance of nodes across zones. - For clusters with more than 400 nodes, we recommend using Azure CNI or Azure CNI Overlay.
- To effectively run workloads concurrently on both Spot and Fixed node pools, consider using priority expanders. This approach allows you to schedule pods based on the priority of the node pool.
- Exercise caution when assigning CPU/Memory requests on pods. The cluster autoscaler scales up based on pending pods rather than CPU/Memory pressure on nodes.
- For clusters concurrently hosting both long-running workloads, like web apps, and short/bursty job workloads, we recommend separating them into distinct node pools with Affinity Rules/expanders or using PriorityClass to help prevent unnecessary node drain or scale down operations.
- In an autoscaler-enabled node pool, scale down nodes by removing workloads, instead of manually reducing the node count. This can be problematic if the node pool is already at maximum capacity or if there are active workloads running on the nodes, potentially causing unexpected behavior by the cluster autoscaler.
- Nodes don't scale up if pods have a PriorityClass value below -10. Priority -10 is reserved for overprovisioning pods. For more information, see Using the cluster autoscaler with Pod Priority and Preemption.
- Don't combine other node autoscaling mechanisms, such as Virtual Machine Scale Set autoscalers, with the cluster autoscaler.
- The cluster autoscaler might be unable to scale down if pods can't move, such as in the following situations:
- A directly created pod not backed by a controller object, such as a Deployment or ReplicaSet.
- A pod disruption budget (PDB) that's too restrictive and doesn't allow the number of pods to fall below a certain threshold.
- A pod uses node selectors or anti-affinity that can't be honored if scheduled on a different node. For more information, see What types of pods can prevent the cluster autoscaler from removing a node?.
Important
Don't make changes to individual nodes within the autoscaled node pools. All nodes in the same node group should have uniform capacity, labels, taints and system pods running on them.
- The cluster autoscaler isn't responsible for enforcing a "maximum node count" in a cluster node pool irrespective of pod scheduling considerations. If any non-cluster autoscaler actor sets the node pool count to a number beyond the cluster autoscaler's configured maximum, the cluster autoscaler doesn't automatically remove nodes. The cluster autoscaler scale down behaviors remain scoped to removing only nodes that have no scheduled pods. The sole purpose of the cluster autoscaler's max node count configuration is to enforce an upper limit for scale up operations. It doesn't have any effect on scale down considerations.
Cluster autoscaler profile
The cluster autoscaler profile is a set of parameters that control the behavior of the cluster autoscaler. You can configure the cluster autoscaler profile when you create a cluster or update an existing cluster.
Optimizing the cluster autoscaler profile
You should fine-tune the cluster autoscaler profile settings according to your specific workload scenarios while also considering tradeoffs between performance and cost. This section provides examples that demonstrate those tradeoffs.
It's important to note that the cluster autoscaler profile settings are cluster-wide and applied to all autoscale-enabled node pools. Any scaling actions that take place in one node pool can affect the autoscaling behavior of other node pools, which can lead to unexpected results. Make sure you apply consistent and synchronized profile configurations across all relevant node pools to ensure you get your desired results.
Example 1: Optimizing for performance
For clusters that handle substantial and bursty workloads with a primary focus on performance, we recommend increasing the scan-interval and decreasing the scale-down-utilization-threshold. These settings help batch multiple scaling operations into a single call, optimizing scaling time and the utilization of compute read/write quotas. It also helps mitigate the risk of swift scale down operations on underutilized nodes, enhancing the pod scheduling efficiency. Also increase ok-total-unready-countand max-total-unready-percentage.
For clusters with daemonset pods, we recommend setting ignore-daemonset-utilization to true, which effectively ignores node utilization by daemonset pods and minimizes unnecessary scale down operations. See profile for bursty workloads
Example 2: Optimizing for cost
If you want a cost-optimized profile, we recommend setting the following parameter configurations:
- Reduce
scale-down-unneeded-time, which is the amount of time a node should be unneeded before it's eligible for scale down. - Reduce
scale-down-delay-after-add, which is the amount of time to wait after a node is added before considering it for scale down. - Increase
scale-down-utilization-threshold, which is the utilization threshold for removing nodes. - Increase
max-empty-bulk-delete, which is the maximum number of nodes that can be deleted in a single call. - Set
skip-nodes-with-local-storageto false. - Increase
ok-total-unready-countandmax-total-unready-percentage.
Common issues and mitigation recommendations
View scaling failures and scale-up not triggered events via CLI or Portal.
Not triggering scale up operations
| Common causes | Mitigation recommendations |
|---|---|
| PersistentVolume node affinity conflicts, which can arise when using the cluster autoscaler with multiple availability zones or when a pod's or persistent volume's zone differs from the node's zone. | Use one node pool per availability zone and enabling --balance-similar-node-groups. You can also set the volumeBindingMode field to WaitForFirstConsumer in the pod specification to prevent the volume from being bound to a node until a pod using the volume is created. |
| Taints and Tolerations/Node affinity conflicts | Assess the taints assigned to your nodes and review the tolerations defined in your pods. If necessary, make adjustments to the taints and tolerations to ensure that your pods can be efficiently scheduled on your nodes. |
Scale up operation failures
| Common causes | Mitigation recommendations |
|---|---|
| IP address exhaustion in the subnet | Add another subnet in the same virtual network and add another node pool into the new subnet. |
| Core quota exhaustion | Approved core quota has been exhausted. Request a quota increase. The cluster autoscaler enters an exponential backoff state within the specific node group when it experiences multiple failed scale up attempts. |
| Max size of node pool | Increase the max nodes on the node pool or create a new node pool. |
| Requests/Calls exceeding the rate limit | See 429 Too Many Requests errors. |
Scale down operation failures
| Common causes | Mitigation recommendations |
|---|---|
| Pod preventing node drain/Unable to evict pod | • View what types of pods can prevent scale down. • For pods using local storage, such as hostPath and emptyDir, set the cluster autoscaler profile flag skip-nodes-with-local-storage to false. • In the pod specification, set the cluster-autoscaler.kubernetes.io/safe-to-evict annotation to true. • Check your PDB, as it might be restrictive. |
| Min size of node pool | Reduce the minimum size of the node pool. |
| Requests/Calls exceeding the rate limit | See 429 Too Many Requests errors. |
| Write operations locked | Don't make any changes to the fully managed AKS resource group (see AKS support policies). Remove or reset any resource locks you previously applied to the resource group. |
Other issues
| Common causes | Mitigation recommendations |
|---|---|
| PriorityConfigMapNotMatchedGroup | Make sure that you add all the node groups requiring autoscaling to the expander configuration file. |
Node pool in backoff
Node pool in backoff was introduced in version 0.6.2 and causes the cluster autoscaler to back off from scaling a node pool after a failure.
Depending on how long the scaling operations have been experiencing failures, it may take up to 30 minutes before making another attempt. You can reset the node pool's backoff state by disabling and then re-enabling autoscaling.

Azure Kubernetes Service