Utskalning för Azure Analysis Services
Med utskalning kan klientfrågor distribueras mellan flera frågerepliker i en frågepool, vilket minskar svarstiderna under höga frågearbetsbelastningar. Du kan också separera bearbetningen från frågepoolen så att klientfrågor inte påverkas negativt av bearbetningsåtgärder. Utskalning kan konfigureras i Azure-portalen eller med hjälp av Analysis Services REST API.
Utskalning är tillgängligt för servrar på prisnivån Standard. Varje frågereplik debiteras med samma avgift som din server. Alla frågerepliker skapas i samma region som din server. Det antal frågerepliker som du kan konfigurera begränsas av den region som din server befinner sig i. Mer information finns i Tillgänglighet per region. Utskalning ökar inte mängden tillgängligt minne för servern. För att öka minnet behöver du uppgradera prenumerationsavtalet.
Varför skalar du ut?
I en typisk serverdistribution fungerar en server som både bearbetningsserver och frågeserver. Om antalet klientfrågor mot modeller på servern överskrider frågebearbetningsenheterna (QPU) för serverns plan, eller om modellbearbetning sker samtidigt som höga frågearbetsbelastningar, kan prestandan minska.
Med utskalning kan du skapa en frågepool med upp till sju fler frågereplikresurser (åtta totalt, inklusive din primära server). Du kan skala antalet repliker i frågepoolen för att uppfylla QPU-kraven vid kritiska tidpunkter, och du kan när som helst separera en bearbetningsserver från frågepoolen.
Oavsett hur många frågerepliker du har i en frågepool distribueras inte bearbetningsarbetsbelastningar mellan frågerepliker. Den primära servern fungerar som bearbetningsserver. Frågerepliker hanterar endast frågor mot modelldatabaserna som synkroniseras mellan den primära servern och varje replik i frågepoolen.
När du skalar ut kan det ta upp till fem minuter innan nya frågerepliker läggs till stegvis i frågepoolen. När alla nya frågerepliker är igång lastbalanseras nya klientanslutningar mellan resurser i frågepoolen. Befintliga klientanslutningar ändras inte från den resurs som de för närvarande är anslutna till. När du skalar in avslutas alla befintliga klientanslutningar till en frågepoolresurs som tas bort från frågepoolen. Klienter kan återansluta till en återstående frågepoolresurs.
Hur det fungerar
När du konfigurerar skalning första gången synkroniseras modelldatabaser på den primära servern automatiskt med nya repliker i en ny frågepool. Automatisk synkronisering sker bara en gång. Under automatisk synkronisering kopieras den primära serverns datafiler (krypterade i vila i bloblagring) till en andra plats, som också krypteras i vila i Blob Storage. Repliker i frågepoolen återfuktas sedan med data från den andra uppsättningen filer.
Även om en automatisk synkronisering endast utförs när du skalar ut en server för första gången, kan du även utföra en manuell synkronisering. Synkronisering säkerställer att data på repliker i frågepoolen matchar den primära serverns. När du bearbetar (uppdaterar) modeller på den primära servern måste en synkronisering utföras när bearbetningsåtgärderna har slutförts. Den här synkroniseringen kopierar uppdaterade data från den primära serverns filer i Blob Storage till den andra uppsättningen filer. Repliker i frågepoolen återfuktas sedan med uppdaterade data från den andra uppsättningen filer i Blob Storage.
När du utför en efterföljande utskalningsåtgärd, till exempel genom att öka antalet repliker i frågepoolen från två till fem, hydreras de nya replikerna med data från den andra uppsättningen filer i Blob Storage. Det finns ingen synkronisering. Om du sedan utför en synkronisering när du har skalat ut, skulle de nya replikerna i frågepoolen hydratiseras två gånger – en redundant hydrering. När du utför en efterföljande utskalningsåtgärd är det viktigt att tänka på följande:
Utför en synkronisering före utskalningsåtgärden för att undvika redundant hydrering av de tillagda replikerna. Samtidig synkronisering och utskalningsåtgärder som körs samtidigt tillåts inte.
När du automatiserar både bearbetning och utskalning är det viktigt att först bearbeta data på den primära servern, sedan utföra en synkronisering och sedan utföra utskalningsåtgärden. Den här sekvensen säkerställer minimal påverkan på QPU- och minnesresurser.
Under utskalningsåtgärder är alla servrar i frågepoolen, inklusive den primära servern, tillfälligt offline.
Synkronisering tillåts även om det inte finns några repliker i frågepoolen. Om du skalar ut från noll till en eller flera repliker med nya data från en bearbetningsåtgärd på den primära servern ska du först utföra synkroniseringen utan repliker i frågepoolen och sedan skala ut. Om du synkroniserar innan du skalar ut undviks redundant hydrering av de nyligen tillagda replikerna.
När du tar bort en modelldatabas från den primära servern tas den inte automatiskt bort från repliker i frågepoolen. Du måste utföra en synkroniseringsåtgärd med hjälp av PowerShell-kommandot Sync-AzAnalysisServicesInstance, som tar bort filer för den databasen från replikens delade bloblagringsplats och sedan tar bort modelldatabasen på replikerna i frågepoolen. Kontrollera om det finns en modelldatabas på repliker i frågepoolen men inte på den primära servern genom att se till att inställningen Separera bearbetningsservern från frågepoolen är ja. Använd sedan SQL Server Management Studio (SSMS) för att ansluta till den primära servern med hjälp av kvalificeraren
:rwför att se om databasen finns. Anslut sedan till repliker i frågepoolen genom att ansluta utan kvalificeraren:rwför att se om samma databas också finns. Om databasen finns på repliker i frågepoolen men inte på den primära servern kör du en synkroniseringsåtgärd.När du byter namn på en databas på den primära servern krävs ytterligare ett steg för att säkerställa att databasen är korrekt synkroniserad med alla repliker. När du har bytt namn utför du en synkronisering med hjälp av kommandot Sync-AzAnalysisServicesInstance och anger parametern
-Databasemed det gamla databasnamnet. Den här synkroniseringen tar bort databasen och filerna med det gamla namnet från alla repliker. Utför sedan en annan synkronisering som anger parametern-Databasemed det nya databasnamnet. Den andra synkroniseringen kopierar den nyligen namngivna databasen till den andra uppsättningen filer och återfuktar alla repliker. Dessa synkroniseringar kan inte utföras med hjälp av kommandot Synkronisera modell i portalen.
Synkroniseringsläge
Som standard extraheras frågerepliker i sin helhet, inte stegvis. Rehydrering sker i steg. De kopplas från och kopplas två åt gången (förutsatt att det finns minst tre repliker) för att säkerställa att minst en replik hålls online för frågor vid en viss tidpunkt. I vissa fall kan klienter behöva återansluta till en av onlinereplikerna medan den här processen pågår. Med inställningen ReplicaSyncMode kan du nu ange att synkronisering av frågerepliker ska ske parallellt. Parallell synkronisering ger följande fördelar:
- Betydande minskning av synkroniseringstiden.
- Data mellan repliker är mer benägna att vara konsekventa under synkroniseringsprocessen.
- Eftersom databaserna finns online på alla repliker under synkroniseringsprocessen behöver klienterna inte ansluta på nytt.
- Minnesintern cache uppdateras inkrementellt med endast ändrade data, vilket kan vara snabbare än att helt rehydrera modellen.
Ange ReplicaSyncMode
Använd SSMS för att ange ReplicaSyncMode i Avancerade egenskaper. Möjliga värden är:
1(standard): Fullständig replikdatabasåterhämtning i steg (inkrementell).2: Optimerad synkronisering parallellt.
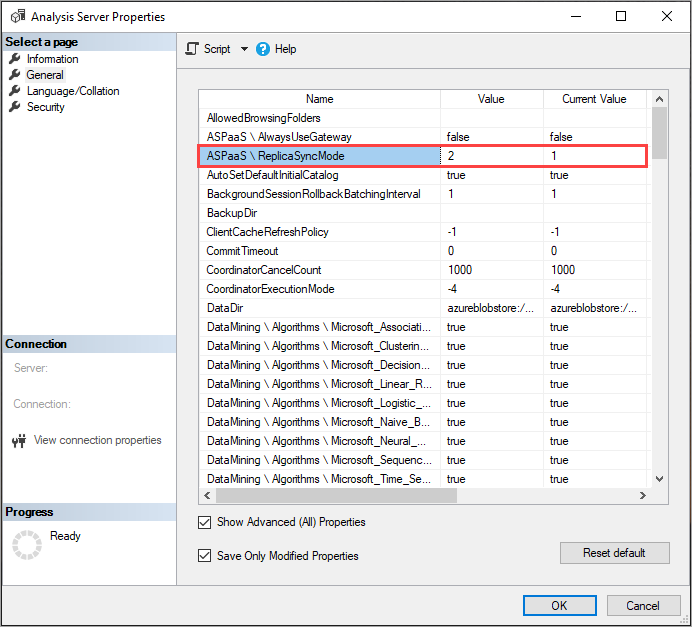
När du anger ReplicaSyncMode=2, beroende på hur mycket av cacheminnet som behöver uppdateras, kan mer minne förbrukas av frågereplikerna. För att hålla databasen online och tillgänglig för frågor, beroende på hur mycket av data som har ändrats, kan åtgärden kräva upp till dubbelt så mycket minne på repliken eftersom både de gamla och nya segmenten sparas i minnet samtidigt. Repliknoder har samma minnesallokering som den primära noden och det finns normalt extra minne på den primära noden för uppdateringsåtgärder, så det kan vara osannolikt att replikerna skulle få slut på minne. Dessutom är det vanliga scenariot att databasen uppdateras stegvis på den primära noden, och därför bör kravet på dubbelt minne vara ovanligt. Om synkroniseringsåtgärden stöter på ett fel med slut på minne försöker den igen med hjälp av standardtekniken (koppla/koppla bort två i taget).
Separera bearbetningen från frågepoolen
För maximal prestanda för både bearbetning och frågeåtgärder kan du välja att separera bearbetningsservern från frågepoolen. När de avgränsas tilldelas nya klientanslutningar endast till frågerepliker i frågepoolen. Om bearbetningsåtgärderna bara tar en kort stund kan du välja att separera bearbetningsservern från frågepoolen under den tid det tar att utföra bearbetnings- och synkroniseringsåtgärder och sedan inkludera den i frågepoolen igen. Det kan ta upp till fem minuter innan åtgärden slutförs om du separerar bearbetningsservern från frågepoolen eller lägger till den i frågepoolen igen.
Övervaka QPU-användning
Övervaka servermåtten i Azure-portalen för att avgöra om det är nödvändigt att skala ut för servern. Om din QPU regelbundet maxar ut innebär det att antalet frågor mot dina modeller överskrider QPU-gränsen för din plan. Måttet för jobbkölängd för frågepool ökar också när antalet frågor i frågetrådspoolens kö överskrider tillgänglig QPU.
Ett annat bra mått att titta på är genomsnittlig QPU per ServerResourceType. Det här måttet jämför genomsnittlig QPU för den primära servern med frågepoolen.
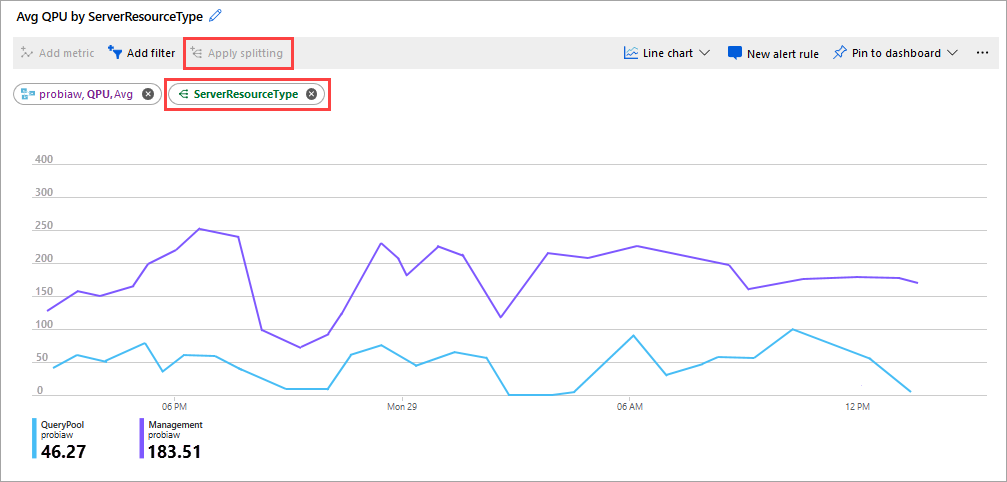
Så här konfigurerar du QPU efter ServerResourceType
- I ett linjediagram för Mått klickar du på Lägg till mått.
- I RESURS väljer du din server och sedan i MÅTTNAMNOMRÅDE väljer du Analysis Services standardmått, sedan I MÅTT väljer du QPU och sedan i AGGREGERING väljer du Avg.
- Klicka på Använd delning.
- I VÄRDEN väljer du ServerResourceType.
Detaljerad diagnostikloggning
Använd Azure Monitor-loggar för mer detaljerad diagnostik av utskalade serverresurser. Med loggar kan du använda Log Analytics-frågor för att dela upp QPU och minne efter server och replik. Mer information finns i Analysera loggar på Log Analytics-arbetsytan. Exempelfrågor finns i Exempel på Kusto-frågor.
Konfigurera utskalning
I Azure-portalen
I portalen klickar du på Skala ut. Använd skjutreglaget för att välja antalet frågereplikservrar. Antalet repliker som du väljer är utöver din befintliga server.
I Avgränsa bearbetningsservern från frågepoolen väljer du Ja för att undanta bearbetningsservern från frågeservrar. Klientanslutningar med standard anslutningssträng (utan
:rw) omdirigeras till repliker i frågepoolen.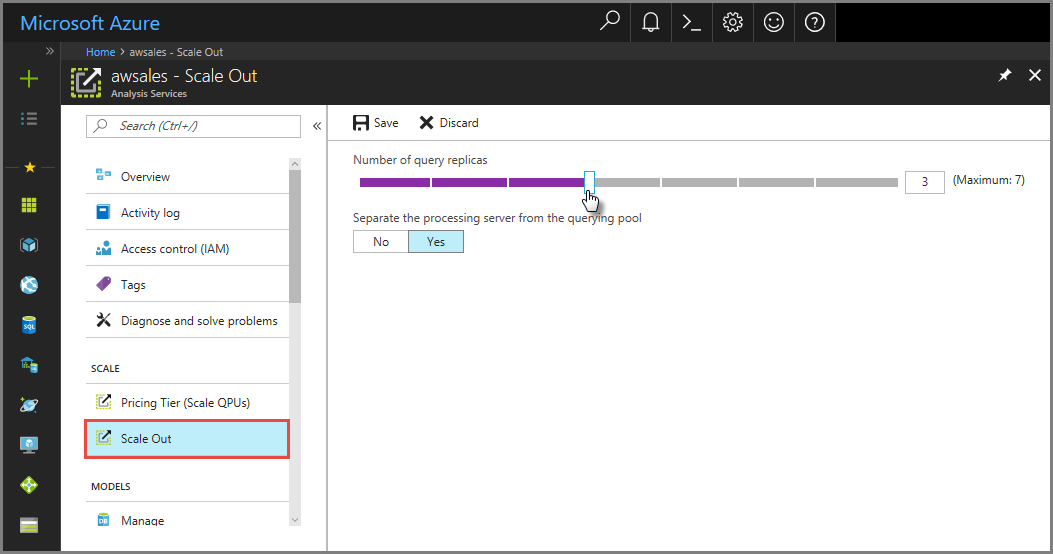
Klicka på Spara för att etablera dina nya frågereplikservrar.
När du konfigurerar utskalning för en server första gången synkroniseras modeller på den primära servern automatiskt med repliker i frågepoolen. Automatisk synkronisering sker bara en gång när du först konfigurerar utskalning till en eller flera repliker. Efterföljande ändringar av antalet repliker på samma server utlöser inte någon annan automatisk synkronisering. Automatisk synkronisering sker inte igen även om du ställer in servern på noll repliker och sedan skalar ut till valfritt antal repliker igen.
Synkronisera
Synkroniseringsåtgärder måste utföras manuellt eller med hjälp av REST-API:et.
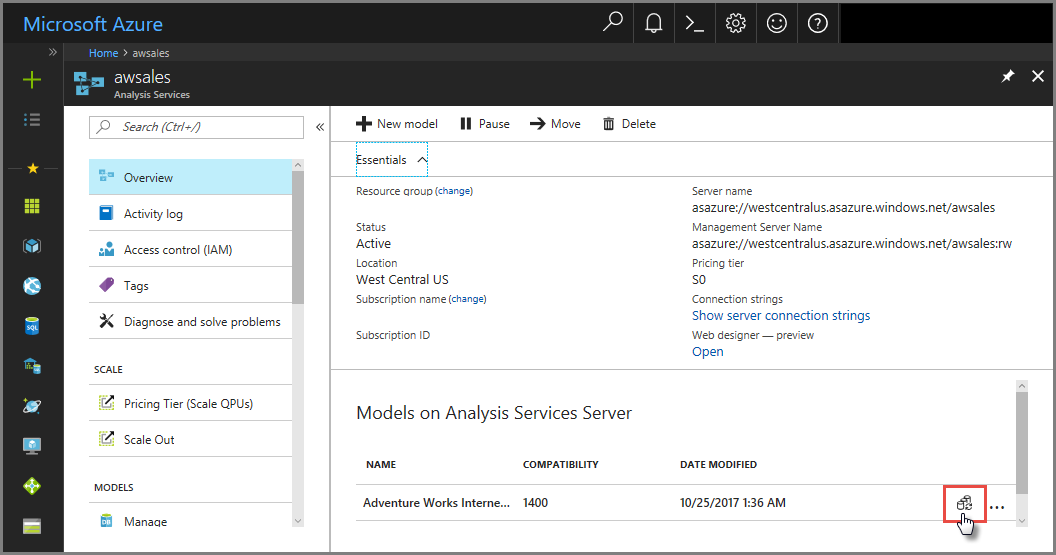
I Azure-portalen
I Översiktsmodell >> Synkronisera modell.
REST-API
Använd synkroniseringsåtgärden.
Synkronisera en modell
POST https://<region>.asazure.windows.net/servers/<servername>:rw/models/<modelname>/sync
Hämta synkroniseringsstatus
GET https://<region>.asazure.windows.net/servers/<servername>/models/<modelname>/sync
Returnera statuskoder:
| Kod | beskrivning |
|---|---|
| -1 | Ogiltig |
| 0 | Replikering |
| 1 | Rehydrering |
| 2 | Slutförd |
| 3 | Misslyckad |
| 4 | Slutföra |
PowerShell
Kommentar
Vi rekommenderar att du använder Azure Az PowerShell-modulen för att interagera med Azure. Information om hur du kommer igång finns i Installera Azure PowerShell. Information om hur du migrerar till Az PowerShell-modulen finns i artikeln om att migrera Azure PowerShell från AzureRM till Az.
Innan du använder PowerShell installerar eller uppdaterar du den senaste Azure PowerShell-modulen.
Om du vill köra synkronisering använder du Sync-AzAnalysisServicesInstance.
Om du vill ange antalet frågerepliker använder du Set-AzAnalysisServicesServer. Ange den valfria -ReadonlyReplicaCount parametern.
Om du vill separera bearbetningsservern från frågepoolen använder du Set-AzAnalysisServicesServer. Ange den valfria -DefaultConnectionMode parameter som ska användas Readonly.
Mer information finns i Använda ett huvudnamn för tjänsten med modulen Az.AnalysisServices.
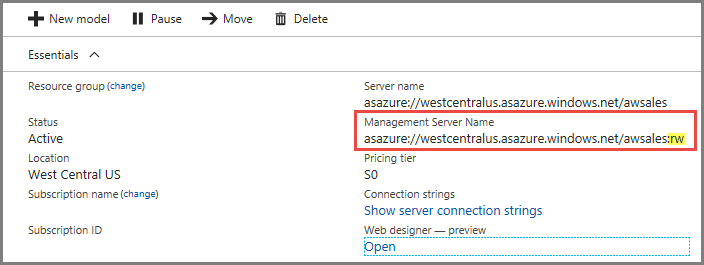
anslutningar
På serverns översiktssida finns det två servernamn. Om du ännu inte har konfigurerat utskalning för en server fungerar båda servernamnen likadant. När du har konfigurerat utskalning för en server måste du ange rätt servernamn beroende på anslutningstyp.
För slutanvändarklientanslutningar som Power BI Desktop, Excel och anpassade appar använder du Servernamn.
Använd hanteringsservernamn för SSMS, Visual Studio och anslutningssträng i PowerShell, Azure Function-appar och AMO. Namnet på hanteringsservern innehåller en särskild :rw (läs-skriv)-kvalificerare. Alla bearbetningsåtgärder utförs på (den primära) hanteringsservern.
Skala upp, skala ned eller skala ut
Du kan ändra prisnivån på en server med flera repliker. Samma prisnivå gäller för alla repliker. En skalningsåtgärd tar först ned alla repliker samtidigt och tar sedan upp alla repliker på den nya prisnivån.
Felsöka
Problem: Det går inte att hitta serverns< namn på serverns> instans i anslutningsläget "ReadOnly".
Lösning: När du väljer alternativet Separera bearbetningsservern från frågepoolen omdirigeras klientanslutningar med standardvärdet anslutningssträng (utan :rw) till frågepoolrepliker. Om replikerna i frågepoolen inte är online ännu eftersom synkroniseringen ännu inte har slutförts kan omdirigerade klientanslutningar misslyckas. För att förhindra misslyckade anslutningar måste det finnas minst två servrar i frågepoolen när du utför en synkronisering. Varje server synkroniseras individuellt medan andra är online. Om du väljer att inte ha bearbetningsservern i frågepoolen under bearbetningen kan du välja att ta bort den från poolen för bearbetning och sedan lägga till den i poolen igen när bearbetningen är klar, men före synkroniseringen. Använd mått för minne och QPU för att övervaka synkroniseringsstatus.
Relaterad information
Övervaka Azure Analysis ServicesHantera Azure Analysis Services
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för