Anteckning
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
TILLÄMPAS PÅ: alla API-hanteringsnivåer
Denna artikel presenterar funktioner i Azure API Management som hjälper dig att hantera generativa AI API:er, såsom de som tillhandahålls av Azure OpenAI Service. Azure API Management erbjuder en rad policyer, mätvärden och andra funktioner för att förbättra säkerhet, prestanda och tillförlitlighet för API:erna som betjänar dina intelligenta appar. Tillsammans kallas dessa funktioner för AI-gatewayfunktioner för dina generativa AI-API:er.
Anteckning
- Använd AI Gateway-funktioner för att hantera API:er som exponeras av Azure OpenAI Service, som är tillgängliga via Azure AI Model Inference API eller med OpenAI-kompatibla modeller som hanteras via tredjepartsleverantörer.
- AI-gatewayfunktioner är funktioner i API Managements befintliga API-gateway, inte en separat API-gateway. För mer information om API-hantering, se Översikt över Azure API-hantering.
Utmaningar i hanteringen av generativa AI-API:er
En av de viktigaste resurserna du har inom generativa AI-tjänster är tokens. Azure OpenAI Service tilldelar kvoter för dina modellimplementeringar uttryckt i tokens per minut (TPM) som sedan fördelas bland dina modellkonsumenter - till exempel olika applikationer, utvecklarteam, avdelningar inom företaget, etc.
Azure gör det enkelt att ansluta en enskild app till Azure OpenAI-tjänsten: du kan ansluta direkt med en API-nyckel som har en TPM-gräns konfigurerad direkt på modellimplementeringsnivån. Men när du börjar expandera din applikationsportfölj, presenteras du med flera appar som anropar ett eller till och med flera Azure OpenAI Service-slutpunkter som har implementerats som betala efter behov eller Provisioned Throughput Units (PTU) instanser. Det medför vissa utmaningar:
- Hur spåras tokenanvändning över flera applikationer? Kan korsbelastningar beräknas för flera applikationer/team som använder Azure OpenAI-tjänstmodeller?
- Hur säkerställer du att en enskild app inte konsumerar hela TPM-kvoten, så att andra appar inte har någon möjlighet att använda Azure OpenAI Service-modellerna?
- Hur distribueras API-nyckeln på ett säkert sätt över flera applikationer?
- Hur fördelas belastningen över flera Azure OpenAI-slutpunkter? Kan du säkerställa att den tilldelade kapaciteten i PTUs används helt innan du återgår till betalning per användning-instans?
Resten av den här artikeln beskriver hur Azure API Management kan hjälpa dig att möta dessa utmaningar.
Importera resursen Azure OpenAI Service som ett API
Importera ett API från en Azure OpenAI Service-endpoint till Azure API-hantering med en enkel klick-upplevelse. API Management effektiviserar introduktionsprocessen genom att automatiskt importera OpenAPI-schemat för Azure OpenAI API och upprättar autentisering till Azure OpenAI-slutpunkten med hjälp av hanterad identitet, vilket eliminerar behovet av manuell konfiguration. Inom samma användarvänliga upplevelse kan du förkonfigurera principer för tokengränser, generera tokenmått och semantisk cachelagring.

Policy för tokenbegränsning
Konfigurera policyn för begränsning av tokens för Azure OpenAI för att hantera och upprätthålla gränser per API-användare baserat på användningen av Azure OpenAI-tjänstens tokens. Med denna policy kan du ställa in en gräns för hastigheten, uttryckt i tokens-per-minut (TPM). Du kan också ställa in en kvot för tokens över en specificerad tidsperiod, såsom per timme, dagligen, veckovis, månadsvis eller årligen.
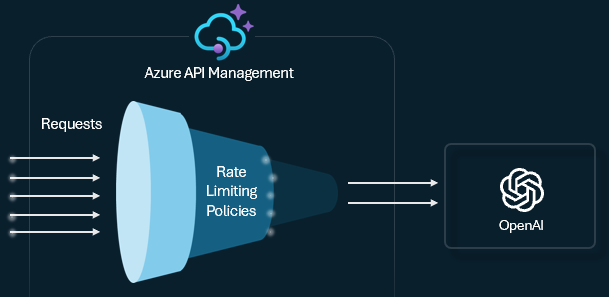
Denna policy ger flexibilitet för att tilldela token-baserade gränser på alla räknarnycklar, såsom abonnemangsnyckel, ursprungs-IP-adress, eller en godtycklig nyckel definierad genom ett policysuttryck. Policyn möjliggör också förberäkning av prompt-token på Azure API Management-sidan, vilket minimerar onödiga förfrågningar till Azure OpenAI-tjänstens backend om prompten redan överskrider begränsningen.
Det följande enkla exemplet visar hur man ställer in en TPM-begränsning på 500 per abonnemangsnyckel.
<azure-openai-token-limit counter-key="@(context.Subscription.Id)"
tokens-per-minute="500" estimate-prompt-tokens="false" remaining-tokens-variable-name="remainingTokens">
</azure-openai-token-limit>
Tips
Api Management tillhandahåller motsvarande llm-token-limit-princip för att hantera och framtvinga tokengränser för andra LLM-API:er.
Utsänd policyn för tokenmetrisk
Policyn för Azure OpenAI emit token metric skickar mätvärden till Application Insights om konsumtionen av LLM-tokens via Azure OpenAI-tjänstens API:er. Policyn hjälper till att ge en översikt över användningen av modeller från Azure OpenAI Service över flera applikationer eller API-användare. Denna policy kan vara användbar för fall av återdebitering, övervakning och kapacitetsplanering.
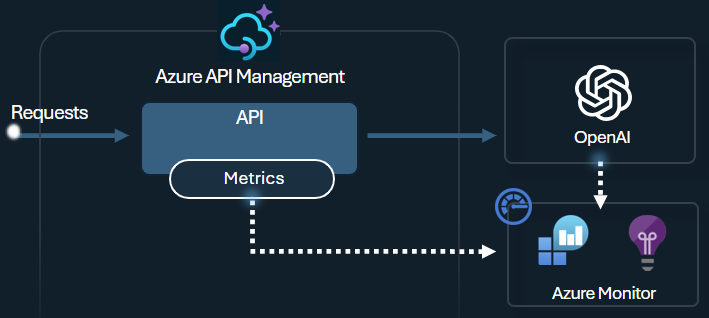
Denna policy registrerar promptar, avslutningar och totala tokenanvändningsmetrik och skickar dem till ett Application Insights-namnutrymme som du väljer. Dessutom kan du konfigurera eller välja från fördefinierade dimensioner för att dela upp användningsstatistik för tokens, så att du kan analysera statistik efter prenumerations-ID, IP-adress eller en anpassad dimension efter eget val.
Till exempel skickar följande policy metrik till Application Insights uppdelade efter klientens IP-adress, API och användare.
<azure-openai-emit-token-metric namespace="openai">
<dimension name="Client IP" value="@(context.Request.IpAddress)" />
<dimension name="API ID" value="@(context.Api.Id)" />
<dimension name="User ID" value="@(context.Request.Headers.GetValueOrDefault("x-user-id", "N/A"))" />
</azure-openai-emit-token-metric>
Tips
Api Management tillhandahåller motsvarande llm-emit-token-metric-policy för att skicka mått för andra LLM-API:er.
Backend belastningsutjämnare och kretsbrytare
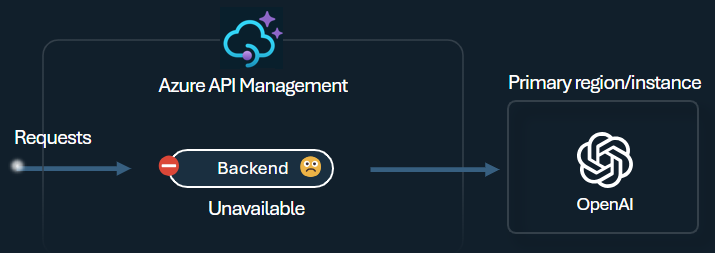
En av utmaningarna när man bygger intelligenta applikationer är att säkerställa att applikationerna är motståndskraftiga mot backend-fel och kan hantera hög belastning. Genom att konfigurera dina Azure OpenAI-tjänstslutpunkter med hjälp av backends i Azure API Management kan du balansera belastningen över dem. Du kan också definiera regler för brytare för att sluta vidarebefordra förfrågningar till Azure OpenAI Service-backend om de inte svarar.
Bakgrundens lastbalanserare stöder rundgång, viktad och prioriteringsbaserad lastbalansering, vilket ger dig flexibiliteten att definiera en lastfördelningsstrategi som uppfyller dina specifika krav. Till exempel, definiera prioriteringar inom lastbalanserarens konfiguration för att säkerställa optimal användning av specifika Azure OpenAI-slutpunkter, särskilt de som har köpts som PTU:er.
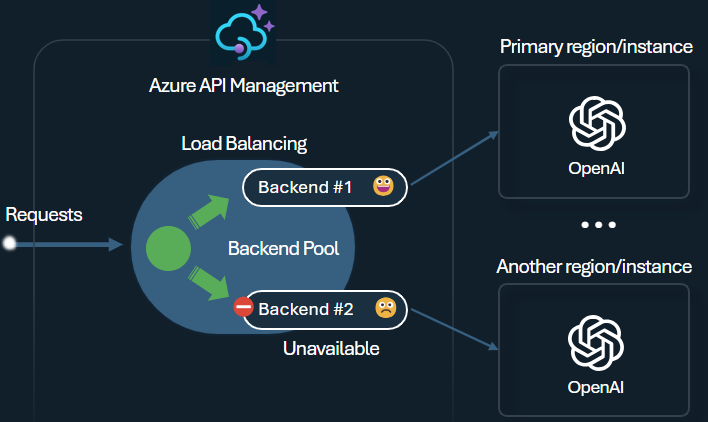
Backendens kretsbrytare har en dynamisk utlösningstid och tillämpar värden från Retry-After-headers som tillhandahålls av backendens system. Detta säkerställer precis och snabb återställning av backend-systemen, vilket maximerar användningen av dina prioriterade backend-system.
Semantisk cachepolicy
Konfigurera Azure OpenAI semantic caching policys för att optimera användningen av token genom att lagra fullständiga svar för liknande uppmaningar.
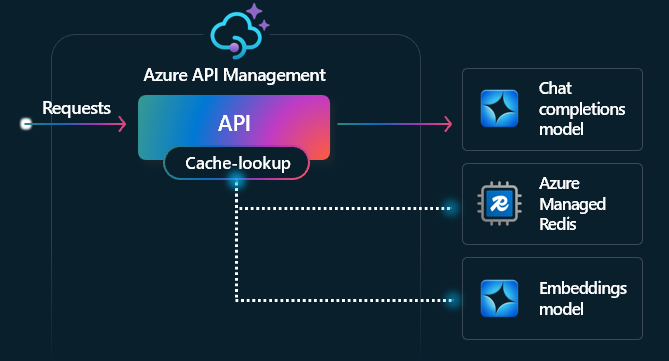
I API Management aktiverar du semantisk cachelagring med hjälp av Azure Redis Enterprise, Azure Managed Redis eller en annan extern cache som är kompatibel med RediSearch och registreras i Azure API Management. Genom att använda Azure OpenAI Service Embeddings API lagrar och hämtar policys azure-openai-semantic-cache-store och azure-openai-semantic-cache-lookup semantiskt liknande prompt-kompletteringar från cachen. Denna metod säkerställer återanvändning av fullföljanden, vilket resulterar i minskad förbrukning av tokens och förbättrad svarsprestanda.
Tips
För att aktivera semantisk cachelagring för andra LLM-API:er tillhandahåller API Management motsvarande principer för llm-semantic-cache-store-policy och llm-semantic-cache-lookup-policy .
Loggning av tokenanvändning, uppmaningar och slutföranden
Aktivera en diagnostikinställning i DIN API Management-instans för att logga begäranden som bearbetas av gatewayen för REST-API:er för stora språkmodeller. För varje begäran skickas data till Azure Monitor, inklusive tokenanvändning (prompttoken, slutförandetoken och totalt antal token), namnet på den modell som används och eventuellt begärande- och svarsmeddelandena (prompt och slutförande). Stora begäranden och svar delas upp i flera loggposter som numreras sekventiellt för senare återuppbyggnad om det behövs.
API Management-administratören kan använda LLM-gatewayloggar tillsammans med API Management-gatewayloggar för scenarier som följande:
- Beräkna användning för fakturering – Beräkna användningsstatistik för fakturering baserat på antalet token som förbrukas av varje program eller API-konsument (till exempel segmenterat efter prenumerations-ID eller IP-adress).
- Inspektera meddelanden – För att hjälpa till med felsökning och granskning, för att granska och analysera uppmaningar och slutresultat.
Läs mer om övervakning av API Management med Azure Monitor.
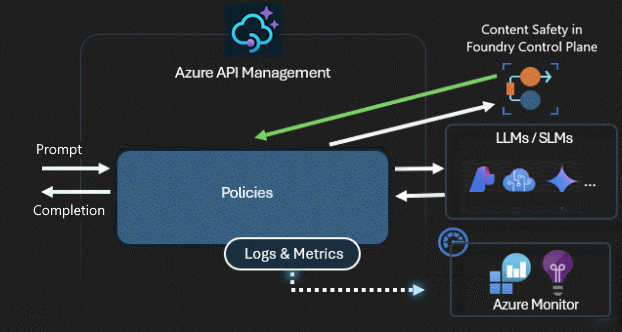
Innehållssäkerhetsprincip
För att skydda användare från skadligt, stötande eller vilseledande innehåll kan du automatiskt moderera alla inkommande begäranden till ett LLM-API genom att konfigurera llm-content-safety-principen . Principen tillämpar innehållssäkerhetskontroller på LLM-prompter genom att överföra dem först till Azure AI Content Safety-tjänsten innan den skickas till serverdelens LLM-API.
Laboratorier och prov
- Labb för AI-gatewayfunktionerna i Azure API Management
- AI-gateway-workshop
- Azure API Management (APIM) – Azure OpenAI-exempel (Node.js)
- Python-exempelkod för att använda Azure OpenAI med API-hantering
Arkitektur- och designöverväganden
- Referensarkitektur för AI-gateway med HJÄLP av API Management
- AI-hubbens gateway landningszonsaccelerator
- Designa och implementera en gatewaylösning med Azure OpenAI-resurser
- Använd en gateway framför flera Azure OpenAI-distributioner eller instanser
Relaterat innehåll
- Blogg: Introduktion till AI-funktioner i Azure API Management
- Blogg: Integrering av Azure innehållssäkerhet med API-hantering för Azure OpenAI-slutpunkter
- Utbildning: Hantera dina generativa AI API:er med Azure API Management
- Smart belastningsbalansering för OpenAI-endpoints och Azure API-hantering
- Autentisera och auktorisera åtkomst till Azure OpenAI API:er med hjälp av Azure API Management