Anpassade modeller för Dokumentinformation
Viktigt!
- Versioner av den offentliga förhandsversionen av Document Intelligence ger tidig åtkomst till funktioner som är i aktiv utveckling.
- Funktioner, metoder och processer kan ändras, före allmän tillgänglighet (GA), baserat på användarfeedback.
- Den offentliga förhandsversionen av Dokumentinformationsklientbiblioteken är som standard REST API version 2024-02-29-preview.
- Förhandsversion 2024-02-29-preview är för närvarande endast tillgänglig i följande Azure-regioner:
- USA, östra
- USA, västra 2
- Europa, västra
Det här innehållet gäller för:![]() v4.0 (förhandsversion) | Tidigare versioner:
v4.0 (förhandsversion) | Tidigare versioner:![]() v3.1 (GA)
v3.1 (GA)![]() v3.0 (GA)
v3.0 (GA)![]() v2.1 (GA)
v2.1 (GA)
Det här innehållet gäller för:![]() v3.1 (GA) | Senaste version:
v3.1 (GA) | Senaste version:![]() v4.0 (förhandsversion) | Tidigare versioner:
v4.0 (förhandsversion) | Tidigare versioner:![]() v3.0
v3.0![]() v2.1
v2.1
Det här innehållet gäller för:![]() v3.0 (GA) | Senaste versionerna:
v3.0 (GA) | Senaste versionerna:![]() v4.0 (förhandsversion)
v4.0 (förhandsversion)![]() v3.1 | Tidigare version:
v3.1 | Tidigare version:![]() v2.1
v2.1
Det här innehållet gäller för:![]() v2.1 | Senaste version:
v2.1 | Senaste version:![]() v4.0 (förhandsversion)
v4.0 (förhandsversion)
Dokumentinformation använder avancerad maskininlärningsteknik för att identifiera dokument, identifiera och extrahera information från formulär och dokument och returnera extraherade data i en strukturerad JSON-utdata. Med Dokumentinformation kan du använda dokumentanalysmodeller, förbyggda/förtränade eller dina tränade fristående anpassade modeller.
Anpassade modeller innehåller nu anpassade klassificeringsmodeller för scenarier där du behöver identifiera dokumenttypen innan du anropar extraheringsmodellen. Klassificerarmodeller är tillgängliga från och med API:et 2023-07-31 (GA) . En klassificeringsmodell kan paras ihop med en anpassad extraheringsmodell för att analysera och extrahera fält från formulär och dokument som är specifika för ditt företag för att skapa en lösning för dokumentbearbetning. Fristående anpassade extraheringsmodeller kan kombineras för att skapa sammansatta modeller.
Anpassade dokumentmodelltyper
Anpassade dokumentmodeller kan vara en av två typer, anpassad mall eller anpassat formulär och anpassade neurala eller anpassade dokumentmodeller. Märknings- och träningsprocessen för båda modellerna är identisk, men modellerna skiljer sig åt på följande sätt:
Anpassade extraheringsmodeller
Skapa en anpassad extraheringsmodell genom att märka en datamängd med dokument med de värden som du vill extrahera och träna modellen på den märkta datamängden. Du behöver bara fem exempel av samma formulär- eller dokumenttyp för att komma igång.
Anpassad neural modell
Viktigt!
Från och med version 4.0 – 2024-02-29-preview API stöder anpassade neurala modeller nu överlappande fält och tabell, rad- och cellnivåförtroende.
Den anpassade neurala modellen (anpassat dokument) använder djupinlärningsmodeller och basmodeller som tränats på en stor samling dokument. Den här modellen finjusteras eller anpassas sedan till dina data när du tränar modellen med en märkt datauppsättning. Anpassade neurala modeller stöder strukturerade, halvstrukturerade och ostrukturerade dokument för att extrahera fält. Anpassade neurala modeller stöder för närvarande engelskspråkiga dokument. När du väljer mellan de två modelltyperna börjar du med en neural modell för att avgöra om den uppfyller dina funktionella behov. Mer information om anpassade dokumentmodeller finns i neurala modeller .
Anpassad mallmodell
Den anpassade mallen eller den anpassade formulärmodellen förlitar sig på en konsekvent visuell mall för att extrahera etiketterade data. Varianser i den visuella strukturen i dina dokument påverkar modellens noggrannhet. Strukturerade formulär som enkäter eller program är exempel på konsekventa visuella mallar.
Träningsuppsättningen består av strukturerade dokument där formateringen och layouten är statiska och konstanta från en dokumentinstans till en annan. Anpassade mallmodeller stöder nyckel/värde-par, markeringsmarkeringar, tabeller, signaturfält och regioner. Mallmodeller och kan tränas på dokument på något av de språk som stöds. Mer information finns ianpassade mallmodeller.
Om språket i dina dokument och extraheringsscenarier stöder anpassade neurala modeller rekommenderar vi att du använder anpassade neurala modeller över mallmodeller för högre noggrannhet.
Dricks
Om du vill bekräfta att träningsdokumenten innehåller en konsekvent mall för visuella objekt tar du bort alla användarangivna data från varje formulär i uppsättningen. Om de tomma formulären är identiska i utseende representerar de en konsekvent visuell mall.
Mer information finns iTolka och förbättra noggrannheten och konfidensen för anpassade modeller.
Indatakrav
För bästa resultat anger du ett tydligt foto eller en genomsökning av hög kvalitet per dokument.
Filformat som stöds:
Modell PDF Bild:
jpeg/jpg, png, bmp, tiff, heifMicrosoft Office:
Word (docx), Excel (xlsx), PowerPoint (pptx)Läsa ✔ ✔ ✔ Layout ✔ ✔ ✔ (2024-02-29-preview, 2023-10-31-preview och senare) Allmänt dokument ✔ ✔ Inbyggda ✔ ✔ Anpassad extrahering ✔ ✔ Anpassad klassificering ✔ ✔ ✔ ✱ Microsoft Office-filer stöds för närvarande inte för andra modeller eller versioner.
För PDF och TIFF kan upp till 2 000 sidor bearbetas (med en prenumeration på den kostnadsfria nivån bearbetas endast de två första sidorna).
Filstorleken för att analysera dokument är 500 MB för den betalda nivån (S0) och 4 MB för den kostnadsfria nivån (F0).
Bilddimensionerna måste vara mellan 50 x 50 bildpunkter och 10 000 px x 10 000 bildpunkter.
Om dina PDF-filer är låsta med lösenord måste du ta bort låset innan du skickar filerna.
Den minsta höjden på texten som ska extraheras är 12 bildpunkter för en bild på 1 024 x 768 bildpunkter. Den här dimensionen motsvarar ungefär
8-punkttext vid 150 punkter per tum.För anpassad modellträning är det maximala antalet sidor för träningsdata 500 för den anpassade mallmodellen och 50 000 för den anpassade neurala modellen.
För anpassad extraheringsmodellträning är den totala storleken på träningsdata 50 MB för mallmodellen och 1G-MB för den neurala modellen.
För anpassad klassificeringsmodellträning är
1GBden totala storleken på träningsdata med högst 10 000 sidor.
Byggläge
Åtgärden skapa anpassad modell lägger till stöd för mallenoch neurala anpassade modeller. Tidigare versioner av REST-API:et och klientbiblioteken har endast stöd för ett enda byggläge som nu kallas mallläge .
Mallmodeller accepterar endast dokument som har samma grundläggande sidstruktur – ett enhetligt visuellt utseende – eller samma relativa placering av element i dokumentet.
Neurala modeller stöder dokument som har samma information, men olika sidstrukturer. Exempel på dessa dokument är USA W2-formulär, som delar samma information, men varierar i utseende mellan företag. Neurala modeller stöder för närvarande endast engelsk text.
Den här tabellen innehåller länkar till SDK-referenser för programmeringsspråket build mode och kodexempel på GitHub:
| Programmeringsspråk | SDK-referens | Kodexempel |
|---|---|---|
| C#/.NET | DocumentBuildMode Struct | Sample_BuildCustomModelAsync.cs |
| Java | DocumentBuildMode-klass | BuildModel.java |
| JavaScript | DocumentBuildMode-typ | buildModel.js |
| Python | DocumentBuildMode Uppräkning | sample_build_model.py |
Jämföra modellfunktioner
I följande tabell jämförs anpassade mallar och anpassade neurala funktioner:
| Funktion | Anpassad mall (formulär) | Anpassad neural (dokument) |
|---|---|---|
| Dokumentstruktur | Mall, formulär och strukturerad | Strukturerad, halvstrukturerad och ostrukturerad |
| Träningstid | 1 till 5 minuter | 20 minuter till 1 timme |
| Extrahering av data | Nyckel/värde-par, tabeller, markeringsmarkeringar, koordinater och signaturer | Nyckel/värde-par, markeringsmarkeringar och tabeller |
| Överlappande fält | Stöds inte | Stöds |
| Dokumentvariationer | Kräver en modell per varje variant | Använder en enskild modell för alla varianter |
| Språkstöd | Stöd för flera språk | Engelska, med förhandsversionsstöd för stöd för spanska, franska, tyska, italienska och nederländska |
Anpassad klassificeringsmodell
Dokumentklassificering är ett nytt scenario som stöds av Document Intelligence med API:et 2023-07-31 (v3.1 GA). API:et för dokumentklassificerare stöder klassificerings- och delningsscenarier. Träna en klassificeringsmodell för att identifiera de olika typer av dokument som programmet stöder. Indatafilen för klassificeringsmodellen kan innehålla flera dokument och klassificera varje dokument inom ett associerat sidintervall. Mer information finns ianpassade klassificeringsmodeller .
Kommentar
Från och med api-versionsdokumentklassificeringen 2024-02-29-preview stöder nu Office-dokumenttyper för klassificering. Den här API-versionen introducerar också inkrementell träning för klassificeringsmodellen.
Anpassade modellverktyg
Dokumentinformation v3.1 och senare modeller stöder följande verktyg, program och bibliotek, program och bibliotek:
| Funktion | Resurser | Model ID |
|---|---|---|
| Anpassad modell | • Document Intelligence Studio • REST API • C# SDK • Python SDK |
custom-model-id |
Document Intelligence v2.1 stöder följande verktyg, program och bibliotek:
Kommentar
Anpassade modelltyper anpassade neurala och anpassade mallar är tillgängliga med Document Intelligence version v3.1 och v3.0 API:er.
| Funktion | Resurser |
|---|---|
| Anpassad modell | • Etikettverktyg för dokumentinformation• REST API • Klientbiblioteks-SDK • Docker-container för dokumentinformation |
Skapa en anpassad modell
Extrahera data från specifika eller unika dokument med hjälp av anpassade modeller. Du behöver följande resurser:
En Azure-prenumeration Du kan skapa en kostnadsfritt.
En instans av dokumentinformation i Azure-portalen. Du kan använda den kostnadsfria prisnivån (
F0) för att prova tjänsten. När resursen har distribuerats väljer du Gå till resurs för att hämta din nyckel och slutpunkt.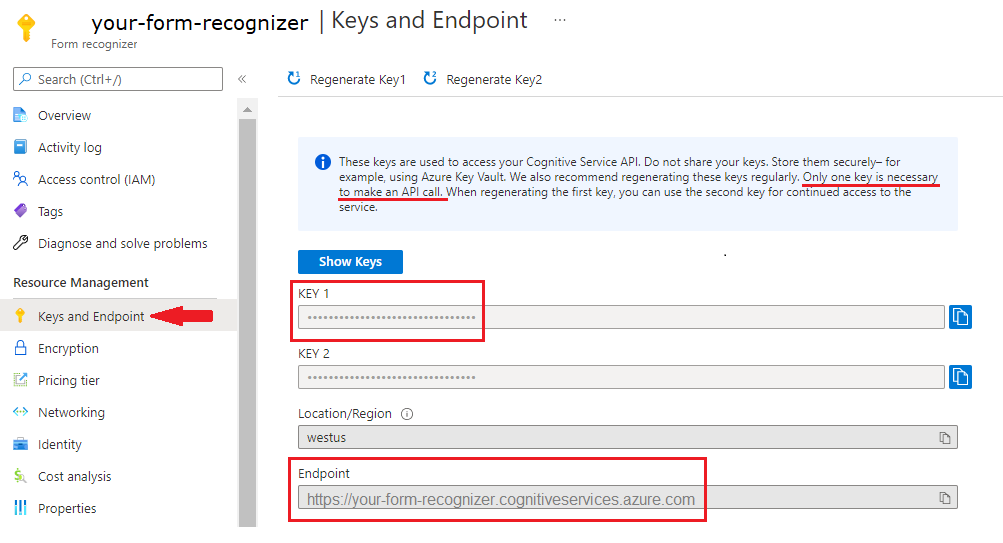
Exempel på märkningsverktyg
Dricks
- För en förbättrad upplevelse och avancerad modellkvalitet kan du prova Document Intelligence v3.0 Studio.
- v3.0 Studio stöder alla modeller som tränats med v2.1-märkta data.
- Du kan läsa api-migreringsguiden för detaljerad information om migrering från v2.1 till v3.0.
- Se våra REST API- eller C#-, Java-, JavaScript- eller Python SDK-snabbstarter för att komma igång med v3.0-versionen.
Exempeletikettverktyget för dokumentinformation är ett öppen källkod verktyg som gör att du kan testa de senaste funktionerna i funktionerna för dokumentinformation och optisk teckenigenkänning (OCR).
Prova snabbstarten för exempeletiketteringsverktyget för att komma igång med att skapa och använda en anpassad modell.
Document Intelligence Studio
Kommentar
Document Intelligence Studio är tillgängligt med v3.1- och v3.0-API:er.
På startsidan för Document Intelligence Studio väljer du Anpassade extraheringsmodeller.
Under Mina projekt väljer du Skapa ett projekt.
Fyll i fälten för projektinformation.
Konfigurera tjänstresursen genom att lägga till lagringskontot och blobcontainern i Anslut din träningsdatakälla.
Granska och skapa projektet.
Lägg till exempeldokumenten för att märka, skapa och testa din anpassade modell.
En detaljerad genomgång för att skapa din första anpassade extraheringsmodell finns iSkapa en anpassad extraheringsmodell.
Sammanfattning av extrahering av anpassad modell
I den här tabellen jämförs de dataextraheringsområden som stöds:
| Modell | Formulärfält | Markeringsmarkeringar | Strukturerade fält (tabeller) | Signatur | Regionetiketter | Överlappande fält |
|---|---|---|---|---|---|---|
| Anpassad mall | ✔ | ✔ | ✔ | ✔ | ✔ | n/a |
| Anpassad neural | ✔ | ✔ | ✔ | n/a | * | ✔ (2024-02-29-preview) |
Tabellsymboler:
✔ — Stöds
**n/a– För närvarande inte tillgänglig;
*-Beter sig olika beroende på modell. Med mallmodeller genereras syntetiska data vid träningstillfället. Med neurala modeller väljs utgående text som identifieras i regionen.
Dricks
När du väljer mellan de två modelltyperna börjar du med en anpassad neural modell om den uppfyller dina funktionella behov. Mer information om anpassade neurala modeller finns i Anpassade neurala modeller.
Utvecklingsalternativ för anpassad modell
I följande tabell beskrivs de funktioner som är tillgängliga med de associerade verktygen och klientbiblioteken. Som bästa praxis bör du se till att du använder de kompatibla verktyg som anges här.
| Dokumenttyp | REST API | SDK | Etikett- och testmodeller |
|---|---|---|---|
| Anpassad mall v 4.0 v3.1 v3.0 | Dokumentinformation 3.1 | SDK för dokumentinformation | Document Intelligence Studio |
| Anpassad neural v4.0 v3.1 v3.0 | Dokumentinformation 3.1 | SDK för dokumentinformation | Document Intelligence Studio |
| Anpassat formulär v2.1 | DOKUMENTINFORMATION 2.1 GA API | SDK för dokumentinformation | Exempeletikettverktyg |
Kommentar
Anpassade mallmodeller som tränats med 3.0-API:et har några förbättringar jämfört med 2.1-API:et som härrör från förbättringar av OCR-motorn. Datauppsättningar som används för att träna en anpassad mallmodell med 2.1-API:et kan fortfarande användas för att träna en ny modell med hjälp av 3.0-API:et.
För bästa resultat anger du ett tydligt foto eller en genomsökning av hög kvalitet per dokument.
Filformat som stöds är JPEG/JPG, PNG, BMP, TIFF och PDF (textbäddas in eller genomsöks). PDF-filer med inbäddad text är bäst för att undvika fel vid extrahering och placering av tecken.
För PDF- och TIFF-filer kan upp till 2 000 sidor bearbetas. Med en prenumeration på den kostnadsfria nivån bearbetas endast de två första sidorna.
Filstorleken måste vara mindre än 500 MB för den betalda nivån (S0) och 4 MB för den kostnadsfria nivån (F0).
Bilddimensionerna måste vara mellan 50 × 50 bildpunkter och 10 000 × 10 000 bildpunkter.
PDF-måtten är upp till 17 x 17 tum, motsvarande pappersstorleken Juridisk eller A3 eller mindre.
Den totala storleken på träningsdata är 500 sidor eller mindre.
Om dina PDF-filer är låsta med lösenord måste du ta bort låset innan du skickar filerna.
Dricks
Träningsdata:
- Använd om möjligt textbaserade PDF-dokument i stället för bildbaserade dokument. Skannade PDF-filer hanteras som bilder.
- Ange endast en enskild instans av formuläret per dokument.
- För ifyllda formulär använder du exempel som har alla fält ifyllda.
- Använd formulär med olika värden i varje fält.
- Om dina formulärbilder är av lägre kvalitet använder du en större datauppsättning. Använd till exempel 10 till 15 bilder.
Språk och nationella inställningar som stöds
Se sidan Språkstöd – anpassade modeller för en fullständig lista över språk som stöds.
Nästa steg
Prova att bearbeta dina egna formulär och dokument med verktyget Exempeletiketter för dokumentinformation.
Slutför en snabbstart för dokumentinformation och kom igång med att skapa en app för dokumentbearbetning på valfritt utvecklingsspråk.
Prova att bearbeta dina egna formulär och dokument med Document Intelligence Studio.
Slutför en snabbstart för dokumentinformation och kom igång med att skapa en app för dokumentbearbetning på valfritt utvecklingsspråk.