Not
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
I de tidigare stegen av din RAG-lösning (retrieval-augmented generation) delade du upp dina dokument i bitar och berikade bitarna. I det här steget genererar du inbäddningar för dessa segment och eventuella metadatafält som du planerar att utföra vektorsökningar på.
Den här artikeln är en del av en serie. Läs introduktionen.
En inbäddning är en matematisk representation av ett objekt, till exempel text. När ett neuralt nätverk tränas skapar processen många representationer av ett objekt. Varje representation har anslutningar till andra objekt i nätverket. En inbäddning är viktig eftersom den fångar upp objektets semantiska innebörd.
Representationen av ett objekt har anslutningar till representationer av andra objekt, så du kan jämföra objekt matematiskt. I följande exempel visas hur inbäddningar fångar semantisk betydelse och relationer mellan objekt:
embedding (king) - embedding (man) + embedding (woman) = embedding (queen)
Inbäddningar jämförs med varandra genom att använda begreppen likhet och avstånd. Följande rutnät visar en jämförelse av inbäddningar.

I en RAG-lösning bäddar du in användarfrågan med samma inbäddningsmodell som dina segment. Sedan söker du i databasen efter relevanta vektorer för att returnera de mest semantiskt relevanta segmenten. Den ursprungliga texten i relevanta segment skickas till språkmodellen som grunddata.
Anmärkning
Vektorer representerar den semantiska betydelsen av text på ett sätt som möjliggör matematisk jämförelse. Du måste rensa segmenten så att den matematiska närheten mellan vektorer korrekt återspeglar deras semantiska relevans.
Förstå vikten av din inbäddningsmodell
Den inbäddningsmodell som du väljer kan avsevärt påverka relevansen för dina vektorsökresultat. Du måste noga överväga ordlistan för inbäddningsmodellen. Varje inbäddningsmodell tränas med ett specifikt ordförråd. Till exempel är vokabulärstorleken för de dubbelriktade kodarrepresentationerna från transformeringsmodellen (BERT) cirka 30 000 ord.
Vokabulären för en inbäddningsmodell är viktig eftersom den hanterar ord som inte finns i dess vokabulär på ett unikt sätt. Om ett ord inte finns i modellens vokabulär beräknar det fortfarande en vektor för det. Många modeller delar upp orden i underord. De behandlar underorden som distinkta token eller aggregerar vektorerna för underorden för att skapa en enda inbäddning.
Till exempel kanske ordet histamin inte finns i en inbäddningsmodells vokabulär. Ordet histamin har en semantisk betydelse som en kemikalie som kroppen släpper ut, vilket orsakar allergisymtom. Inbäddningsmodellen innehåller inte histamin. Så det kan skilja ordet i underord som finns i dess ordförråd, till exempel hans, taoch min.

De semantiska betydelserna i dessa underord är långt ifrån innebörden av histamin. De individuella eller kombinerade vektorvärdena i underorden resulterar i sämre vektormatchning jämfört med om ordet histamin fanns i modellens vokabulär.
Välj en inbäddningsmodell
Fastställ rätt inbäddningsmodell för ditt användningsfall. Överväg överlappningen mellan inbäddningsmodellens vokabulär och orden i dina data när du väljer en inbäddningsmodell.

Kontrollera först om du har domänspecifikt innehåll. Är dina dokument till exempel specifika för ett användningsfall, din organisation eller en bransch? Ett bra sätt att fastställa domänspecifikhet är att kontrollera om du kan hitta entiteter och nyckelord i ditt innehåll på Internet. Om du kan kan en allmän inbäddningsmodell sannolikt också göra det.
Allmänt eller icke-domänspecifikt innehåll
När du väljer en generell inbäddningsmodell, börja med modellrankningen på Hugging Face leaderboard. Utvärdera hur modellerna fungerar med dina data och börja med de översta modellerna.
Domänspecifikt innehåll
För domänspecifikt innehåll avgör du om du kan använda en domänspecifik modell. Dina data kan till exempel finnas i den biomedicinska domänen, så du kan använda BioGPT-modellen. Den här språkmodellen är förtränad på en omfattande samling av biomedicinsk litteratur. Du kan använda den för biomedicinsk textutvinning och generering. Om domänspecifika modeller är tillgängliga utvärderar du hur dessa modeller fungerar med dina data.
Om du inte har en domänspecifik modell eller om den domänspecifika modellen inte fungerar bra kan du finjustera en allmän inbäddningsmodell med din domänspecifika vokabulär.
Viktigt!
För alla modeller som du väljer måste du kontrollera att licensen passar dina behov och att modellen tillhandahåller det språkstöd som krävs.
Generera multimodala inbäddningar
Inbäddningar är inte begränsade till text. Du kan generera inbäddningar för text och andra medietyper, till exempel bilder, ljud och video. Processen för att generera inbäddningar liknar olika metoder. Läs in innehållet, skicka det genom inbäddningsmodellen och lagra den resulterande vektorn. Men valet av modell- och förbearbetningssteg varierar beroende på medietyp.
Du kan till exempel använda modeller som Contrastive Language–Image Pre-training (CLIP) för att generera inbäddningar av bilder. Du kan sedan använda inbäddningarna i vektorsökning för att hämta semantiskt liknande bilder. För video måste du definiera ett schema som extraherar specifika funktioner, till exempel objektnärvaro eller narrativ sammanfattning och använder specialiserade modeller för att generera inbäddningar för dessa funktioner.
Tips/Råd
Använd ett schema för att definiera de funktioner som du vill extrahera från multimodalt innehåll. Den här metoden optimerar dina inbäddningar för dina hämtningsmål.
Använd dimensionreduktion
Inbäddningsvektorer kan vara högdimensionella, vilket ökar lagrings- och beräkningskostnaderna. Tekniker för minskning av dimensionalitet hjälper till att göra inbäddningar mer hanterbara, kostnadseffektiva och tolkningsbara.
Du kan använda algoritmer som t-distribuerad stokastisk grann inbäddning (t-SNE) eller huvudkomponentanalys (PCA) för att minska antalet dimensionerna i dina vektorer. De här verktygen finns i bibliotek som PyTorch och scikit-learn.
Minskning av dimensionalitet kan förbättra semantisk klarhet och visualisering. Det hjälper också till att eliminera oanvända eller bullriga funktioner i täta inbäddningar.
Anmärkning
Minskning av dimensionalitet är ett steg efter bearbetning. Du tillämpar den när du har genererat inbäddningar för att optimera lagrings- och hämtningsprestanda.
Jämför inbäddningar
När du utvärderar inbäddningar kan du använda matematiska formler för att jämföra vektorer. Dessa formler hjälper dig att avgöra hur lika eller olika två inbäddningar är.
Vanliga jämförelsemetoder är:
- Cosininlikitet: Mäter vinkeln mellan två vektorer. Användbart för högdimensionella data.
- Euklidiska avstånd: Mäter det räta avståndet mellan två vektorer.
- Manhattanavstånd: Mäter den absoluta skillnaden mellan vektorkomponenter.
- Punktprodukt: Mäter projektionen av en vektor till en annan.
Tips/Råd
Välj din jämförelsemetod baserat på ditt användningsfall. Använd till exempel cosinuslikhet när du vill mäta semantisk närhet och använda euklidiskt avstånd när du vill mäta literal närhet.
Utvärdera inbäddningsmodeller
Om du vill utvärdera en inbäddningsmodell visualiserar du inbäddningarna och utvärderar avståndet mellan frågan och segmentvektorerna.
Visualisera inbäddningar
Du kan använda bibliotek, till exempel t-SNE, för att rita vektorerna för dina segment och din fråga i en X-Y-graf. Du kan sedan avgöra hur långt segmenten är från varandra och från frågan. I följande diagram visas segmentvektorer ritade. De två pilarna nära varandra representerar två segmentvektorer. Den andra pilen representerar en frågevektor. Du kan använda den här visualiseringen för att förstå hur långt frågan kommer från segmenten.
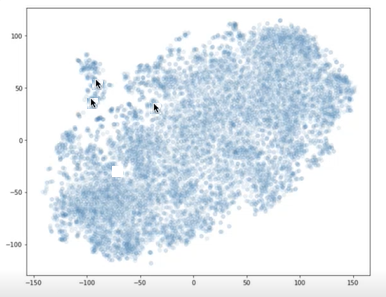
Två pilar pekar på ritpunkter nära varandra, och en annan pil visar en ritpunkt långt borta från de andra två.
Beräkna inbäddningsavstånd
Du kan använda en programmatisk metod för att utvärdera hur väl inbäddningsmodellen fungerar med dina frågor och segment. Beräkna avståndet mellan frågevektorerna och segmentvektorerna. Du kan använda euklidiska avståndet eller Manhattan-avståndet.
Utvärdera inbäddningsmodeller med hjälp av hämtningsprestanda
Om du vill välja den bästa inbäddningsmodellen utvärderar du hur bra den presterar i hämtningsscenarier. Bädda in ditt innehåll, utföra vektorsökning och utvärdera om rätt objekt hämtas.
Du kan experimentera med olika modeller, jämförelseformler och dimensionsinställningar. Använd utvärderingsmått för att avgöra vilken modell som ger bäst resultat för ditt användningsfall.
Viktigt!
Hämtningsprestanda är det mest praktiska sättet att utvärdera inbäddningskvaliteten. Använd verkliga frågor och innehåll för att testa dina modeller.
Finjustera inbäddningsmodeller
Om en allmän eller domänspecifik modell inte uppfyller dina behov kan du finjustera den med dina egna data. Finjustering justerar modellens vikter så att de bättre representerar ditt ordförråd och din semantik.
Finjustering kan förbättra hämtningsprecisionen, särskilt för specialiserade domäner som kodsökning eller juridiska dokument. Men det kräver noggrann utvärdering och kan ibland försämra prestanda om träningsdata är dåliga.
Moderna tekniker som RL (one-bit reinforcement learning) gör finjusteringen mer kostnadseffektiv.
Tips/Råd
Innan du finjusterar din modell bör du utvärdera om prompt-teknik eller begränsad avkodning kan lösa problemet. Använd utvärderingsmått och hämtningsprestanda för att vägleda din finjustering.
Använd Hugging Face-topplistan
Hugging Face Leaderboard innehåller uppdaterade rankingar av inbäddningsmodeller. Använd den för att identifiera modeller med bäst prestanda för ditt användningsfall.
När du granskar modeller bör du tänka på följande:
- Token: Storleken på modellens vokabulär.
- Minne: Modellens storlek och slutsatsdragningskostnad.
- Mått: Storleken på utdatavektorerna.
Anmärkning
Större modeller är inte alltid bättre. De kan öka kostnaderna utan att förbättra prestandan. Använd dimensionsminskning och utvärdering av hämtning för att hitta rätt balans.
Förstå inbäddningsekonomi
När du väljer en inbäddningsmodell måste du hitta en kompromiss mellan prestanda och kostnad. Stora inbäddningsmodeller har vanligtvis bättre prestanda vid benchmarking av datauppsättningar. Men den ökade prestandan tillför kostnader. Stora vektorer kräver mer utrymme i en vektordatabas. De kräver också mer beräkningsresurser och tid för att jämföra inbäddningar. Små inbäddningsmodeller har vanligtvis lägre prestanda på samma prestandamått. De kräver mindre utrymme i vektordatabasen och mindre beräkning och tid för att jämföra inbäddningar.
När du utformar systemet bör du överväga kostnaden för inbäddning när det gäller krav på lagring, beräkning och prestanda. Du måste verifiera modellernas prestanda genom experimentering. De offentligt tillgängliga riktmärkena är ofta akademiska datamängder och kanske inte direkt gäller för dina affärsdata och användningsfall. Beroende på kraven kan du gynna prestanda jämfört med kostnad eller acceptera en kompromiss med tillräckligt bra prestanda för lägre kostnad.