Felaktigt antimönster för instansiering
Ibland skapas nya instanser av en klass kontinuerligt, när det är tänkt att skapas en gång och sedan delas. Det här beteendet kan skada prestanda och kallas för ett felaktigt instansieringsantimönster. Ett antimönster är ett vanligt svar på ett återkommande problem som vanligtvis är ineffektivt och till och med kan vara kontraproduktivt.
Problembeskrivning
Många bibliotek tillhandahåller abstraheringar av externa resurser. De här klasserna hanterar vanligtvis internt sina egna anslutningar till resursen, och fungerar som mäklare som klienter kan använda för åtkomst till resursen. Här är några exempel på mäklarklasser som är relevanta i Azure-program:
System.Net.Http.HttpClient. Kommunicerar med en webbtjänst via HTTP.Microsoft.ServiceBus.Messaging.QueueClient. Skickar och tar emot meddelanden i en Service Bus-kö.Microsoft.Azure.Documents.Client.DocumentClient. Anslut till en Azure Cosmos DB-instans.StackExchange.Redis.ConnectionMultiplexer. Ansluter till Redis, inklusive Azure Cache for Redis.
De här klasserna ska instansieras en gång och återanvända under hela livslängden för ett program. Det är dock ett vanligt missförstånd att de här klasserna bara ska förvärvas vid behov snabbt frisläppas. (De som anges här råkar vara .NET-bibliotek, men mönstret är inte unikt för .NET.) Följande ASP.NET exempel skapar en instans av HttpClient för att kommunicera med en fjärrtjänst. Du hittar hela exemplet här.
public class NewHttpClientInstancePerRequestController : ApiController
{
// This method creates a new instance of HttpClient and disposes it for every call to GetProductAsync.
public async Task<Product> GetProductAsync(string id)
{
using (var httpClient = new HttpClient())
{
var hostName = HttpContext.Current.Request.Url.Host;
var result = await httpClient.GetStringAsync(string.Format("http://{0}:8080/api/...", hostName));
return new Product { Name = result };
}
}
}
Den här tekniken är inte skalbar i en webbapp. Ett nytt HttpClient-objekt skapas för varje användarbegäran. Vid hög belastning kan webbservern få slut på antalet tillgängliga sockets, vilket resulterar i SocketException-fel.
Det här problemet är inte begränsat till klassen HttpClient. Andra klasser som omsluter resurser eller är dyra att skapa kan orsaka liknande problem. I följande exempel skapas en instans av klassen ExpensiveToCreateService. Här är problemet inte nödvändigtvis att antalet sockets tar slut, utan snarare hur lång tid det tar att skapa varje instans. Att hela tiden skapa och ta bort instanser av den här klassen kan påverka skalbarheten i systemet negativt.
public class NewServiceInstancePerRequestController : ApiController
{
public async Task<Product> GetProductAsync(string id)
{
var expensiveToCreateService = new ExpensiveToCreateService();
return await expensiveToCreateService.GetProductByIdAsync(id);
}
}
public class ExpensiveToCreateService
{
public ExpensiveToCreateService()
{
// Simulate delay due to setup and configuration of ExpensiveToCreateService
Thread.SpinWait(Int32.MaxValue / 100);
}
...
}
Så här åtgärdar du felaktigt instansieringsantimönster
Om klassen som omsluter den externa resursen kan delas och är trådsäker så skapar du en delad singleton-instans eller en pool med återanvändbara instanser av klassen.
I följande exempel används en statisk HttpClient-instans, så att anslutningen delas mellan alla förfrågningar.
public class SingleHttpClientInstanceController : ApiController
{
private static readonly HttpClient httpClient;
static SingleHttpClientInstanceController()
{
httpClient = new HttpClient();
}
// This method uses the shared instance of HttpClient for every call to GetProductAsync.
public async Task<Product> GetProductAsync(string id)
{
var hostName = HttpContext.Current.Request.Url.Host;
var result = await httpClient.GetStringAsync(string.Format("http://{0}:8080/api/...", hostName));
return new Product { Name = result };
}
}
Att tänka på
Det viktiga i det här antimönstret är att upprepade gånger skapa och förstöra instanser av ett delbart objekt. Om en klass inte är delbar (om den inte är trådsäker) så gäller inte det här antimönstret.
Typen av delad resurs kan avgöra om du bör använda en singleton-instans eller skapa en pool. Klassen
HttpClientär avsedd att vara delad snarare än att placeras i pooler. Andra objekt kan ha stöd för poolning, så att systemet kan sprida belastningen över flera instanser.Objekt som du delar mellan flera förfrågningar måste vara trådsäkra. Klassen
HttpClientär avsedd att användas på det här sättet, men andra klasser kanske inte har stöd för samtidiga förfrågningar, så kontrollera den tillgängliga dokumentationen.Var försiktig med att ange egenskaper för delade objekt eftersom detta kan leda till konkurrenstillstånd. Om du till exempel anger
DefaultRequestHeaderspå klassenHttpClientinnan varje begäran kan detta skapa ett konkurrenstillstånd. Ange sådana egenskaper en gång (till exempel under starten) och skapa separata instanser om du behöver konfigurera andra inställningar.Vissa typer av resurser är begränsade och ska inte behållas. Databasanslutningar är ett exempel. Om du behåller en öppen databasanslutning som inte behövs kanske inte andra samtidiga användare kan få åtkomst till databasen.
I .NET Framework skapas många objekt som upprättar anslutningar till externa resurser med hjälp av statiska fabriksmetoder i andra klasser som hanterar de här anslutningarna. Dessa objekt är avsedda att sparas och återanvändas, snarare än att tas bort och sedan skapas igen. I Azure Service Bus skapas till exempel
QueueClient-objektet via ettMessagingFactory-objekt. Internt så hanterarMessagingFactoryanslutningar. Mer information finns i Best Practices for performance improvements using Service Bus Messaging (Metodtips för att förbättra prestanda med hjälp av Service Bus-meddelanden).
Så här identifierar du felaktigt instansieringsantimönster
Symptom på det här problemet kan vara ett lägre dataflöde eller ett större antal fel, tillsammans med något av följande:
- En ökning av antalet undantag som visar på att antalet resurser som sockets, databasanslutningar, filhandtag och så vidare håller på att ta slut.
- Ökad minnesanvändning och skräpinsamling.
- En ökning av nätverks-, disk- eller databasaktiviteten.
Du kan göra följande för att identifiera problemet:
- Utför processövervakning i produktionssystemet och identifiera punkter där svarstiderna är långsammare eller systemet slutar fungera på grund av bristande resurser.
- Granska telemetridata som samlas in vid de här punkterna och avgör vilka åtgärder som kan skapar och förstör resursintensiva objekt.
- Belastningstesta varje misstänkt åtgärd i en kontrollerad testmiljö snarare än i produktionssystemet.
- Granska källkoden och undersök hur mäklarobjekten hanteras.
Titta på stackspår för åtgärder som är långsamma eller som genererar undantag när systemet är under belastning. Den här informationen hjälper dig att identifiera hur dessa åtgärder använder resurser. Undantag kan hjälpa dig att avgöra om fel orsakas av att det är ont om delade resurser.
Exempeldiagnos
I följande avsnitt används stegen på exempelprogrammet som beskrivs ovan.
Identifiera punkter där systemet är långsamt eller slutar fungera
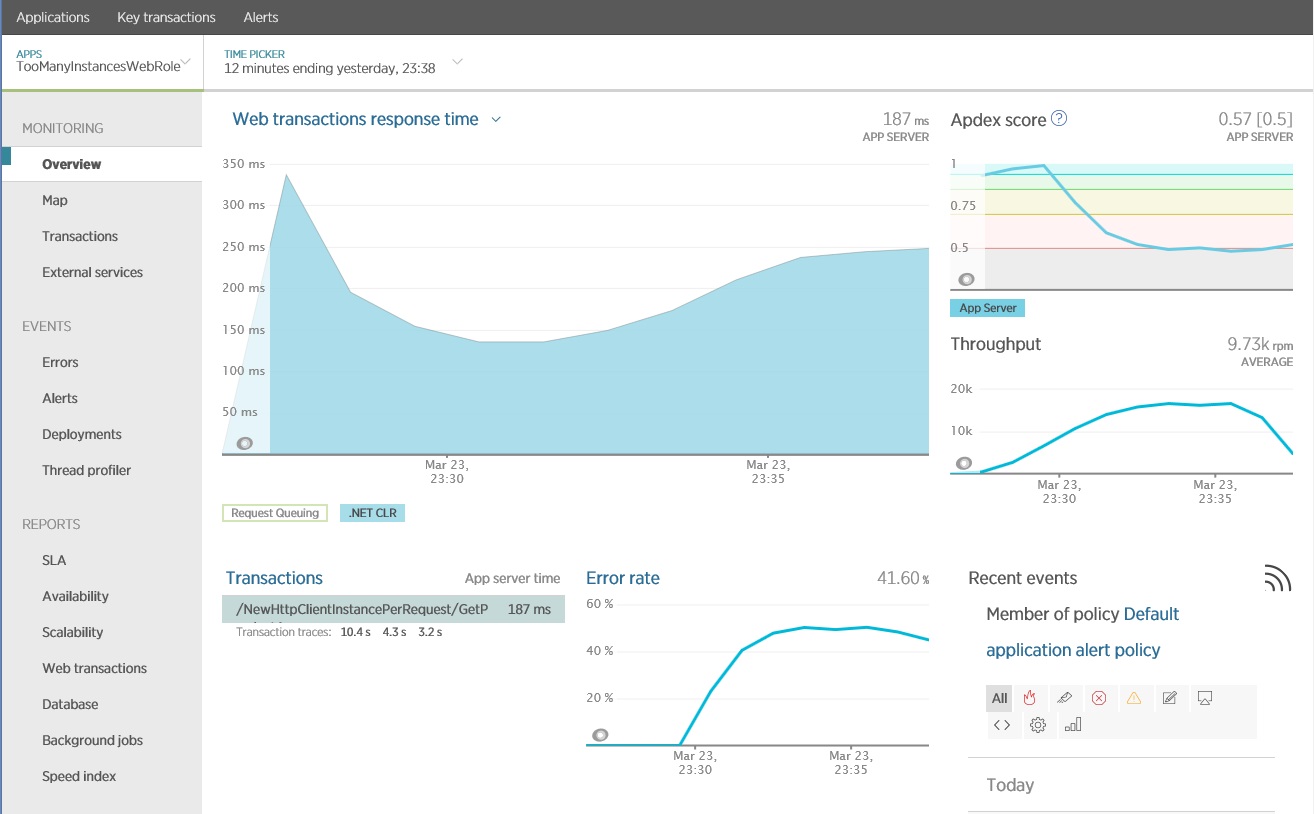
På följande bild visas resultat som genererats med hjälp av New Relic APM. Bilden visar även åtgärder med dålig svarstid. I det här fallet bör du undersöka metoden GetProductAsync i kontrollanten NewHttpClientInstancePerRequest lite närmare. Observera att felfrekvensen även blir högre när de här åtgärderna körs.
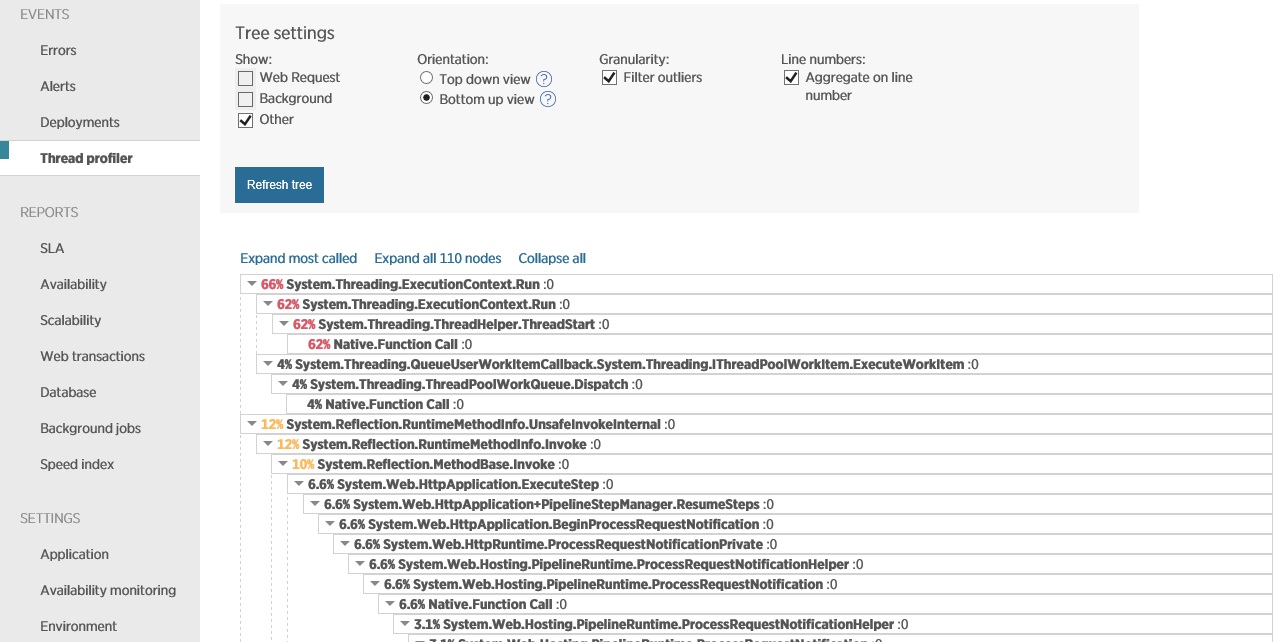
Granska telemetridata och hitta korrelationer
I nästa bild visas data som hämtats med hjälp av trådprofilering under samma period som i föregående bild. Systemet spenderar mycket tid på att öppna socketanslutningar, och ännu mer tid på att stänga dem och hantera socketundantag.

Utför belastningstester
Använd belastningstester till att simulera vanliga åtgärder som användarna kan utföra. På så sätt kan du identifiera vilka delar av ett system som drabbas av resursuttömning under olika belastningar. Utför de här testerna i en kontrollerad miljö snarare än i produktionssystemet. I följande diagram visas genomflödet av förfrågningar som hanteras av kontrollanten NewHttpClientInstancePerRequest när användarbelastningen ökar till 100 samtidiga användare.
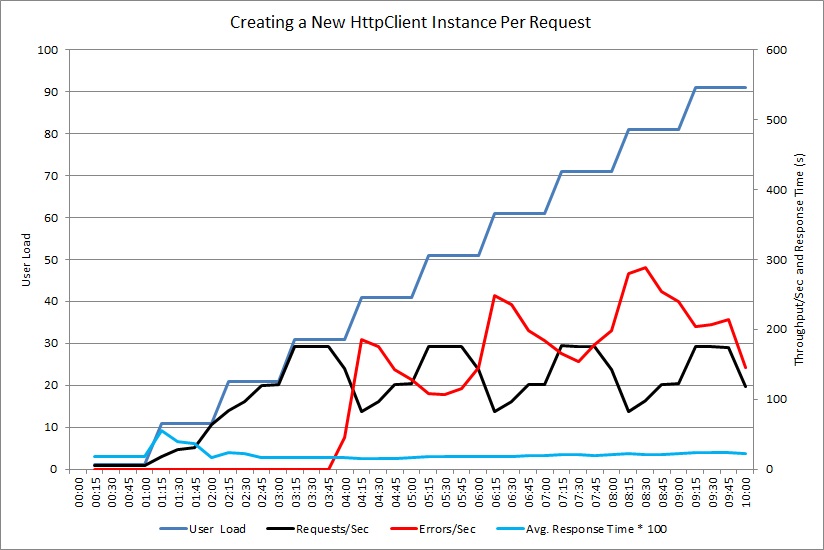
Först ökar antalet förfrågningar som hanteras per sekund när belastningen ökar. Vid ca 30 användare når dock mängden lyckade förfrågningar en gräns, och systemet börjar generera undantag. Sedan ökar mängden undantag gradvis med användarbelastningen.
I belastningstestet rapporteras de här felen som HTTP 500-fel (intern server). När du tittar på telemetrin ser du att de här felen orsakas av att systemet får slut på socketresurser när fler och fler HttpClient-objekt skapas.
I nästa diagram ser du ett liknande test för en kontrollant som skapar anpassade ExpensiveToCreateService-objekt.
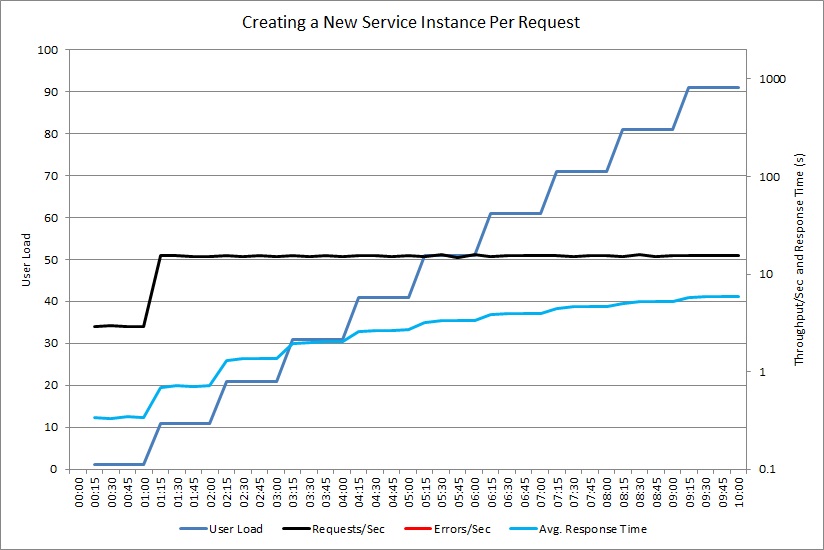
Den här gången genererar inte kontrollanten några undantag, men dataflödet når fortfarande en platå där medelsvarstiden ökar med en faktor på 20. (Diagrammet använder en logaritmisk skala för svarstid och dataflöde.) Telemetri visade att det var huvudorsaken ExpensiveToCreateService till problemet att skapa nya instanser av den.
Implementera lösningen och verifiera resultatet
Efter att metoden GetProductAsync ändrats så att en enda instans av HttpClient delas så visade ett andra belastningstest bättre prestanda. Inga fel rapporterades och systemet kunde hantera en ökad belastning på upp till 500 förfrågningar per sekund. Medelsvarstiden halverades jämfört med föregående test.
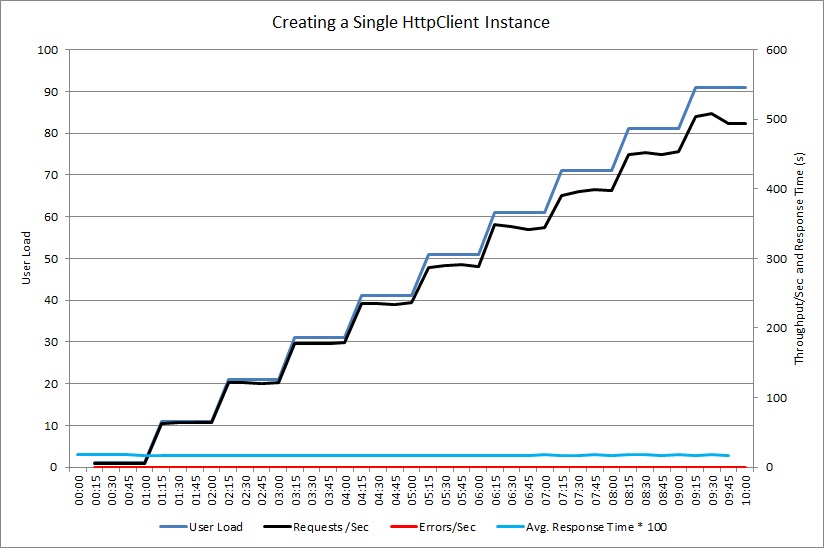
Du kan jämföra stackspårningstelemetrin i följande bild. Den här gången spenderas den mesta tiden i systemet på faktiskt arbete snarare än att öppna och stänga sockets.
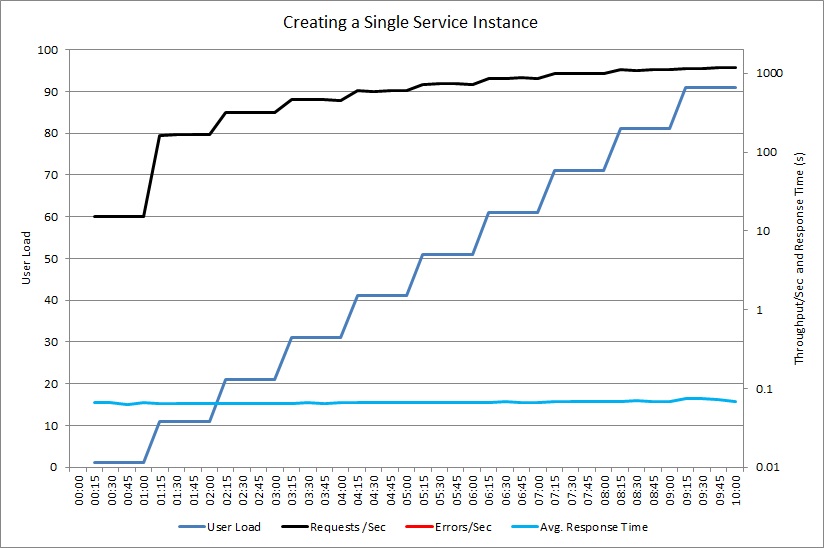
I nästa diagram ser du ett liknande belastningstest med en delad instans av ExpensiveToCreateService-objektet. Återigen ökar antalet förfrågningar som hanteras med antalet användare medan medelsvarstiden fortsätter att vara låg.
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för