Cachelagring är en vanlig teknik för att förbättra prestanda och skalbarhet i system. Den cachelagrar data genom att tillfälligt kopiera data som används ofta till snabb lagring som finns nära programmet. Om den snabba datalagringen ligger närmare än originalkällan kan cachelagring förbättra svarstiden för klientprogram betydligt. Det går helt enkelt att komma åt data snabbare.
Cachelagring är allra mest effektivt när en klientinstans läser samma data upprepade gånger, och i synnerhet om samtliga av följande punkter gäller för det ursprungliga datalagret:
- det förblir relativt statiskt
- det är långsamt jämfört med cacheminnet
- det har hög konkurrensnivå
- det är avlägset och nätverksfördröjning kan orsaka långsam åtkomst.
För distribuerade program används vanligtvis en eller båda av följande strategier när data cachelagras:
- De använder en privat cache, där data lagras lokalt på datorn som kör en instans av ett program eller en tjänst.
- De använder en delad cache som fungerar som en gemensam källa som kan nås av flera processer och datorer.
I båda fallen kan cachelagring utföras på klientsidan och på serversidan. Cachelagring på klientsidan sker via processen som tillhandahåller användargränssnittet för ett system. Det kan vara en webbläsare eller ett skrivbordsprogram (lokalt program). Cachelagring på serversidan sker via processen som tillhandahåller företagstjänsterna av fjärrtyp.
Den enklaste typen av cachelagring är minnesintern lagring. Den ligger i adressutrymmet i en enskild process och koms åt direkt av den kod som körs i processen. Den här typen av cache är snabb att komma åt. Det kan också vara ett effektivt sätt att lagra blygsamma mängder statiska data. Storleken på en cache begränsas vanligtvis av mängden minne som är tillgängligt på den dator som är värd för processen.
Om du behöver lagra mer i cachen än vad som är fysiskt möjligt i minnet kan du skriva cachelagrade data till det lokala filsystemet. Den här processen går långsammare att komma åt än data som lagras i minnet, men den bör fortfarande vara snabbare och mer tillförlitlig än att hämta data i ett nätverk.
Om flera instanser av ett program som använder den här modellen körs samtidigt har varje programinstans sin egen oberoende cache med en egen datakopia.
Du kan tänka på cachedata som en ögonblicksbild av den ursprungliga informationen vid en tidigare tidpunkt. Om dessa data inte är statiska är det troligt att olika programinstanser har olika versioner av data i sina cacheminnen. Det innebär att en fråga som utförs av dessa instanser kan returnera olika resultat. Se bild 1.
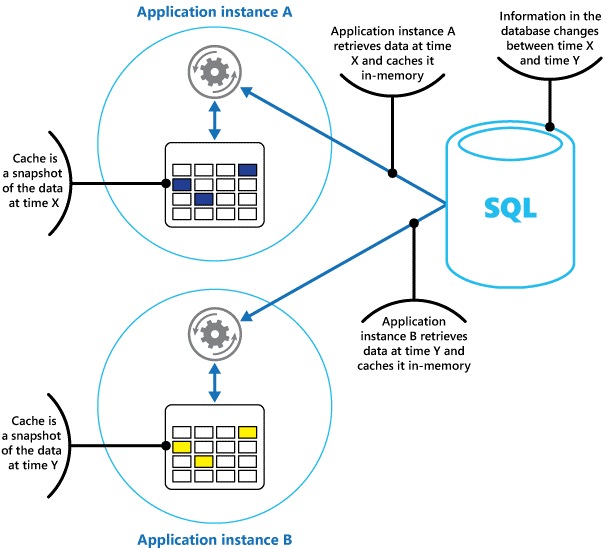
Bild 1: Använda en minnesintern cache i olika instanser av ett program.
Om du använder en delad cache kan det bidra till att minska oron för att data kan skilja sig åt i varje cache, vilket kan inträffa vid minnesintern cachelagring. Delad cachelagring säkerställer att olika programinstanser ser samma vy av cachelagrade data. Cacheminnet hittas på en separat plats, som vanligtvis finns som en del av en separat tjänst, enligt bild 2.
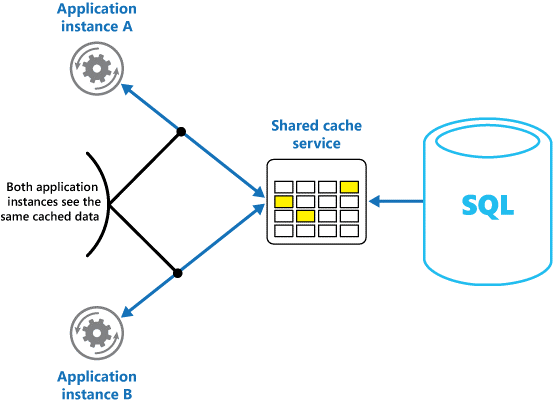
Bild 2: Använda en delad cache.
En viktig fördel med delad cachelagring är skalbarheten. Många delade cachetjänster implementeras med hjälp av ett kluster med servrar och använder programvara för att distribuera data över klustret transparent. En programinstans skickar helt enkelt en begäran till cachetjänsten. Den underliggande infrastrukturen avgör platsen för cachelagrade data i klustret. Det är enkelt att utöka cachen genom att lägga till servrar.
Det finns två huvudsakliga nackdelarna med delad cachelagring:
- Cachen är långsammare att komma åt eftersom den inte längre lagras lokalt för varje programinstans.
- Kravet på en separat cachetjänst kan göra lösningen mer komplex.
I följande avsnitt beskriver vi i detalj vad du ska tänka på när du skapar och använder cachelagring.
Cachelagring kan kraftigt förbättra prestanda, skalbarhet och tillgänglighet. Ju mer data du har och ju större antal användare som behöver åtkomst till dem, desto större blir fördelarna med cachelagring. Cachelagring minskar svarstiden och konkurrensen som är associerad med hantering av stora mängder samtidiga begäranden i det ursprungliga datalagret.
En databas kanske bara klarar ett begränsat antal samtidiga anslutningar. Om data hämtas från en delad cache, i stället för den underliggande databasen, kommer klientprogram åt dessa data även om inga tillgängliga anslutningar finns. Om själva databasen blir otillgänglig går det dessutom eventuellt att fortsätta att använda cachade data.
Överväg att cachelagra data som läses ofta men ändras sällan (till exempel data som har en högre andel läsåtgärder än skrivåtgärder). Vi rekommenderar däremot inte att du använder cachen som huvudsaklig förvaring av viktig information. Se i stället till att alla ändringar som programmet inte har råd att förlora alltid sparas i ett beständigt datalager. Om cacheminnet inte är tillgängligt kan programmet fortfarande fortsätta att fungera med hjälp av datalagret och du förlorar inte viktig information.
Nyckeln till effektiv cachelagring ligger i att fastställa vilka data som är lämpligast att lagra i cachen och att cachelagra vid rätt tidpunkt. Data kan läggas till i cacheminnet på begäran första gången de hämtas av ett program. Programmet behöver bara hämta data en gång från datalagret och att efterföljande åtkomst kan uppfyllas med hjälp av cachen.
Cachelagringen kan annars helt eller delvis fyllas med data i förväg, vanligtvis när programmet startas. Den här metoden kallas seeding. Seeding är eventuellt inte lämpligt för stora cacheminnen. Metoden kan innebära en plötslig, hög belastning på den ursprungliga datalagringen när programmet börjar köras.
Ofta kan en analys av användningsmönster hjälpa dig att besluta om en cache ska förkonfigureras, helt eller delvis, och vilka data som ska cachelagras. Du kan till exempel använda cacheminnet med statiska användarprofildata för kunder som använder programmet regelbundet (kanske varje dag), men inte för kunder som bara använder programmet en gång i veckan.
Cachelagring fungerar vanligtvis väl med data som inte kan ändras eller som ändras sällan. Det kan till exempel vara referensinformation, som produkt- och prisinformation i ett e-handelsprogram, eller delade statiska resurser som är dyra att konstruera. Vissa eller alla dessa data kan läsas in i cacheminnet när programmet startas, för minimerad resursanvändning och bättre prestanda. Du kanske också vill ha en bakgrundsprocess som regelbundet uppdaterar referensdata i cacheminnet för att säkerställa att de är uppdaterade. Eller så kan bakgrundsprocessen uppdatera cacheminnet när referensdata ändras.
Cachelagring är mindre användbart för dynamiska data, även om det finns vissa undantag. Läs mer i avsnittet Cachelagra dynamiska data nedan. När de ursprungliga data ändras regelbundet blir antingen den cachelagrade informationen inaktuell snabbt eller omkostnaderna för att synkronisera cacheminnet med det ursprungliga datalagret minskar cachelagringens effektivitet.
En cache behöver inte innehålla fullständiga data för en entitet. Om ett dataobjekt till exempel representerar ett flervärdesobjekt, till exempel en bankkund med namn, adress och kontosaldo, kan vissa av dessa element förbli statiska, till exempel namn och adress. Andra element, till exempel kontosaldot, kan vara mer dynamiska. I dessa situationer kan det vara användbart att cachelagrar statiska delar av data och hämtar (eller beräknar) endast återstående information när den behövs.
Vi rekommenderar att du utför prestandatestning och användningsanalys för att avgöra om prepopulering eller inläsning på begäran av cachen, eller en kombination av båda, är lämplig. Beslutet bör baseras på hur ofta data ändras och användningsmönstret. Cacheanvändning och prestandaanalys är viktiga i program som drabbas av stora belastningar och måste vara mycket skalbara. I mycket skalbara scenarier kan du till exempel använda cacheminnet för att minska belastningen på datalagret vid tider med hög belastning.
Cacheminnen kan också användas för att undvika att upprepa beräkningar medan programmet körs. Om en åtgärd omvandlar data eller utför en komplicerad beräkning kan resultatet av åtgärden sparas i cacheminnet. Om samma beräkning krävs igen kan programmet hämta resultatet från cacheminnet.
Ett program kan ändra data som lagras i ett cacheminne. Vi rekommenderar dock att du tänker på cacheminnet som ett tillfälligt datalager som kan försvinna när som helst. Lagra inte endast värdefulla data i cacheminnet. se till att du även behåller informationen i det ursprungliga datalagret. Då minimerar du risken för att förlora data om cacheminnet blir otillgänglig.
När du lagrar snabbt föränderlig information i ett beständigt datalager kan det medföra ett omkostnader för systemet. Ta till exempel en enhet som kontinuerligt rapporterar status eller andra mått. Om ett program väljer att inte cachelagra dessa data eftersom den cachelagrade informationen hela tiden blir inaktuell så kan detsamma gälla när dessa data lagras och hämtas från datalagret. Under den tid det tar att spara och hämta dessa data kan de ha ändrats.
Överväg här att lagra den dynamiska informationen direkt i cachen i stället för i lagret för beständiga data. Om data är icke-kritiska och inte kräver granskning spelar det ingen roll om enstaka ändring går förlorad.
I de flesta fall är data i ett cacheminne en kopia av data som finns i det ursprungliga datalagret. Data i det ursprungliga datalagret kan ha ändrats efter cachelagringen, vilket innebär att dessa cachelagrade data blir inaktuella. I många system går det att konfigurera cachen så att data löper ut. Det minskar den tid under vilken data kan vara inaktuella.
När cachelagrade data upphör att gälla tas de bort från cacheminnet och programmet måste hämta data från det ursprungliga datalagret (det kan placera den nyligen hämtade informationen i cacheminnet igen). Du kan ange en princip för hur data ska löpa ut när du konfigurerar cachen. I många cachetjänster kan du fastställa utgångsperioden för enskilda objekt via programmering i cacheminnet när du lagrar dem. Med vissa cacheminnen kan du ange förfalloperioden som ett absolut värde, eller som ett glidande värde som gör att objektet tas bort från cacheminnet om det inte nås inom den angivna tiden. Den här inställningen åsidosätter eventuella principer som gäller för hela cachen, men endast för angivna objekt.
Anteckning
Överväg noggrant utgångstiden för cachen och objekten i den. Om du gör den för kort upphör objekten att gälla för snabbt, och då minskar du fördelarna med cachen. Om du gör perioden för lång riskerar data att bli inaktuella.
Det är också möjligt att cacheminnet blir fullt om data ligger kvar för länge. I det fallet kan ett begärande om att lägga till nya objekt i cacheminnet orsaka att andra objekt tvingas bort i en process som kallas avlägsning. Cachetjänster avlägsnar typiskt sett data enligt principen tidigast använd (LRU), men du kan vanligtvis åsidosätta den här principen och förhindra att objekt tas bort. Om du gör det riskerar du att överskrida utrymmet i cacheminnet. Det betyder att försök att lägga till objekt i cacheminnet misslyckas med ett undantag.
I vissa cachelagringsimplementeringar finns ytterligare avlägsningsprinciper. Det finns flera typer av avlägsningsprinciper. Dessa kan vara:
- En princip som används senast (i förväntningen att data inte kommer att krävas igen).
- först in först ut (när äldsta data avlägsnas först)
- händelseutlöst avlägsningsprincip (till exempel att data ändras).
Data som lagras i ett cacheminne på klientsidan anses vanligtvis ligga utanför ramen för den tjänst som tillhandahåller data till klienten. En tjänst kan inte direkt tvinga en klient att lägga till eller ta bort information från en cache på klientsidan.
Det innebär att det är möjligt för en klient som använder ett felaktigt konfigurerat cacheminne att fortsätta använda gammal information. Om exempelvis principer för förfallodatum inte implementeras kan en klient använda gammal information som cachelagrats lokalt, även om informationen i den ursprungliga datakällan har ändrats.
Om du skapar ett webbprogram som hanterar data via en HTTP-anslutning kan du implicit tvinga en webbklient (till exempel en webbläsare eller webbproxy) att hämta den senaste informationen. Det här kan du göra om en resurs uppdateras av en ändring i URI:t för den resursen. Webbklienter använder vanligtvis URI:t för en resurs som nyckel i klientcacheminnet. Om URI:t ändras ignorerar webbklienten eventuella tidigare cachelagrade versioner av en resurs och hämtar den nya versionen i stället.
Cacheminnen är ofta utformade för att delas av flera programinstanser. Varje programinstans kan läsa och ändra data i cacheminnet. Det innebär samma samtidighetsproblem i cacheminnen som i andra delade datalager. I en situation där ett program behöver ändra data som lagras i cacheminnet kan du behöva se till att uppdateringar som görs av en instans av programmet inte skriver över de ändringar som görs av en annan instans.
Beroende på datatypen och sannolikheten för kollisioner finns två metoder för samtidighet:
- Optimistisk. Precis innan data uppdateras kontrollerar programmet om data i cacheminnet har ändrats sedan de hämtades. Om alla data är desamma kan ändringen göras. Programmet måste annars bestämma om de ska uppdateras. (Affärslogik som styr det här beslutet är programspecifik.) Den här metoden är lämplig för situationer där uppdateringar är ovanliga eller där kollisioner sannolikt inte inträffar.
- Pessimistisk. När data hämtas låser programmet in dem i cacheminnet för att förhindra att någon annan instans ändrar dem. Den här processen säkerställer att kollisioner inte kan inträffa, men de kan också blockera andra instanser som behöver bearbeta samma data. Pessimistisk samtidighet kan påverka skalbarheten i lösningar och rekommenderas endast för tillfälligt bruk. Den här metoden kan vara lämplig i situationer där kollisioner är sannolika. Det kan i synnerhet vara om ett program uppdaterar flera objekt i cacheminnet och måste se till att ändringarna tillämpas konsekvent.
Undvik att använda ett cacheminne som primärt datalager. Den rollen har det ursprungliga datalagret, varifrån cacheminnet fylls. Det ursprungliga datalagret är din garanti för att det finns data.
Var noga med att inte införa kritiska beroenden, som kräver att en delad cachetjänst är tillgänglig, i lösningar. Ett program bör fortsätta att fungera även om tjänsten som tillhandahåller den delade cachen inte är tillgängligt. Programmet får inte svara eller misslyckas i väntan på att cachetjänsten ska återupptas.
Du måste därför se till att programmet kan identifiera tillgängligheten för cachetjänsten och återgå till det ursprungliga datalagret om den inte är tillgänglig. Circuit-Breaker-mönstret (kretsbrytare) är användbart för att hantera det här scenariot. Den tjänst som tillhandahåller cacheminnet kan återskapas. När den blir tillgänglig kan cacheminnet fyllas igen när data läses in från det ursprungliga datalagret, efter en strategi som Cache aside-mönstret (cache åsidosatt).
Systemets skalbarhet kan dock påverkas om programmet återgår till det ursprungliga datalagret när cacheminnet är tillfälligt otillgängligt. Medan datalagret återställs kan det ursprungliga datalagret översköljas med databegäranden, vilket resulterar i uppnådda tidsgränser och misslyckade anslutningar.
Överväg att implementera en lokal, privat cache i varje instans av ett program, tillsammans med den delade cachen som alla programinstanser har åtkomst till. När programmet hämtar ett objekt kan det först söka i det lokala cacheminnet, därefter i det delade cacheminnet och slutligen i det ursprungliga datalagret. Det lokala cacheminnet kan fyllas med data från det delade. Om det inte är tillgängligt fylls det via databasen.
Den här metoden kräver noggrann konfigurering för att förhindra att den lokala cachen blir inaktuell jämfört med det delade cacheminnet. Den lokala cachen fungerar dock som buffert om den delade cachen inte kan nås. Bild 3 visar den här strukturen.
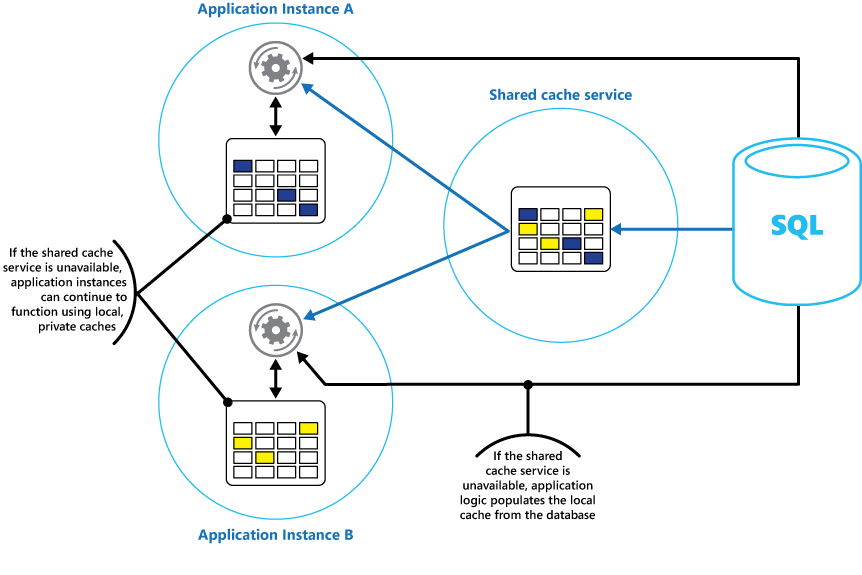
Bild 3: Använda en lokal privat cache med en delad cache.
I vissa cachetjänster finns ett alternativ för hög tillgänglighet med automatisk redundans om cachen inte är tillgänglig. Det här syftar till att stödja stora cacheminnen som innehåller relativt långlivade data. Det innebär vanligtvis att data som lagras på en primär cacheserver replikeras till en sekundär cacheserver. Om ett fel uppstår på den primära servern eller om anslutningen bryts växlar systemet till den sekundära servern.
För att undvika fördröjning kopplad till skrivning till flera mål kan replikeringen till den sekundära servern ske asynkront när data skrivs till cachen på den primära servern. Den här metoden leder till att viss cachelagrad information kan gå förlorad om det uppstår ett fel, men andelen av dessa data bör vara liten jämfört med cachens totala storlek.
Om en delad cache är stor kan det vara bra att partitionera lagrade data mellan noder. Det här gör du för att minska risken för konkurrens och förbättra skalbarheten. I många delade cacheminnen kan du dynamiskt lägga till och ta bort noder och balansera om data över partitioner. Den här metoden kan omfatta klustring. Uppsättningen noder presenteras då för klientprogram som en enda sammanhängande cache. Internt sprids dock data mellan noder enligt en fördefinierad distributionsstrategi som fördelar belastningen jämnt. Mer information om möjliga partitioneringsstrategier finns i Vägledning för datapartitionering.
Klustring kan också öka tillgängligheten för cachen. Om en nod inte fungerar är resten av cachen fortfarande tillgänglig. Klustring används ofta tillsammans med replikering och redundans. Varje nod kan replikeras och repliken kan snabbt tas i bruk om en nod misslyckas.
Många läs- och skrivåtgärder omfattar sannolikt enkla datavärden och objekt. Ibland är det dock nödvändigt att lagra och hämta stora mängder data snabbt. Att seeda ett cacheminne kan till exempel innebära att skriva hundratals eller tusentals objekt till cachen. Ett program kan också behöva hämta ett stort antal relaterade objekt från cacheminnet, kopplat till samma begäran.
Många stora cacheminnen har batchåtgärder för dessa ändamål. Det innebär att klientprogram kan packa ihop stora mängder objekt i en enskild begäran. Det går då att undvika nackdelar kopplade till att utföra ett stort antal små begäranden.
För att cache-aside-mönstret ska fungera måste den programinstans som fyller cacheminnet ha åtkomst till den senaste och konsekventa dataversionen. I ett system som implementerar slutlig konsekvens (till exempel en replikerad databas) är det inte säkert att så är fallet.
En instans av ett program kan ändra ett dataobjekt och ogiltigförklara den cachelagrade versionen av objektet. En annan instans av programmet kan försöka läsa objektet från ett cacheminne, vilket orsakar en cachemiss. Data läses istället från datalagret och läggs till i cacheminnet. Men om datalagret inte har synkroniserats helt med de andra replikerna kan programinstansen läsa och fylla i cacheminnet med det gamla värdet.
Mer information om hur du hanterar datakonsekvens finns i introduktionen till datakonsekvens.
Oavsett cachetjänst bör du överväga att skydda de data som lagras i cacheminnet från obehörig åtkomst. Det finns två huvudsakliga frågeställningar:
- sekretessen för data i cacheminnet
- säkerheten för de data som flödar mellan cacheminnet och det program som använder det.
För att skydda data i cacheminnet kan cachetjänsten använda en autentiseringsfunktion som kräver att programmet anger följande:
- vilka identiteter som kan komma åt data i cacheminnet
- vilka åtgärder (läsa, skriva) som dessa identiteter ska kunna utföra.
När en identitet har beviljats skriv- eller läsåtkomst till cacheminnet kan identiteten använda alla data i cacheminnet för att minska kostnaderna för läsning och skrivning av data.
Om du vill begränsa åtkomsten till undergrupper av cachelagrade data kan du göra något av följande:
- Dela cacheminnet i partitioner (genom att använda olika cacheservrar) och bevilja endast åtkomst till partitioner som identiteten i fråga ska kunna använda.
- Kryptera data i varje undergrupp med olika nycklar. Tillhandahåll endast krypteringsnycklar till de identiteter som ska ha åtkomst till varje undergrupp. Eventuellt kan ett klientprogram fortfarande hämta alla data i cacheminnet, men det kan bara dekryptera data som det har nycklarna till.
Du måste också skydda informationen när den förs vidare till och från cacheminnet. Det gör du med hjälp av säkerhetsfunktionerna i nätverksinfrastrukturen som klientprogram använder för att ansluta till cacheminnet. Om cachen har implementerats med en lokal server inom samma organisation som är värd för klientprogrammen kan själva isoleringen av nätverket vara tillräcklig. Om cachen är fjärrplacerad och kräver en TCP- eller HTTP-anslutning via ett offentligt nätverk (till exempel internet) rekommenderar vi du överväger SSL.
Azure Cache for Redis är en implementering av Redis-cachen med öppen källkod som körs som en tjänst i ett Azure-datacenter. Det ger en cachelagringstjänst som kan nås från alla Azure-program, oavsett om programmet har implementerats som molntjänst, webbplats eller i en virtuell Azure-dator. Cacheminnen kan delas av klientprogram som har rätt åtkomstnyckel.
Azure Cache for Redis är en högpresterande cachelagringslösning som ger tillgänglighet, skalbarhet och säkerhet. Den körs vanligtvis som tjänst, fördelad på en eller flera dedikerade datorer. Den försöker lagra så mycket data som möjligt minnesinternt, för att säkerställa snabb åtkomst. Den här arkitekturen är avsedd att ge låg latens och hög genomströmning genom att minska behovet av långsamma I/O-åtgärder.
Azure Cache for Redis är kompatibelt med många av de olika API:er som används av klientprogram. Om du har befintliga program som redan använder Azure Cache for Redis som körs lokalt tillhandahåller Azure Cache for Redis en snabb migreringsväg till cachelagring i molnet.
Redis är mer än en enkel cacheserver. Det är en distribuerad minnesintern databas med en omfattande kommandouppsättning som stöder många vanliga scenarier. Dessa beskrivs senare i det här dokumentet, i avsnittet Använda Redis-cachelagring. I det här avsnittet sammanfattas några av de viktigaste funktionerna i Redis.
Redis stöder både läs- och skrivåtgärder. I Redis kan skrivåtgärder skyddas från systemfel genom att de regelbundet lagras, antingen i en lokal fil med en ögonblicksbild eller i en loggfil av typen lägg-endast-till. Den här situationen är inte fallet i många cacheminnen, vilket bör betraktas som övergående datalager.
Alla skrivningar är asynkrona och blockerar inte klienter från att läsa och skriva data. När Redis startar läses data från ögonblicksbilden eller loggfilen in och används till att skapa den minnesinterna cachen. Mer information finns i dokumentationen ombeständighet i Redis på Redis webbplats.
Anteckning
Redis garanterar inte att alla skrivningar sparas om det uppstår ett oåterkalleligt fel, men i värsta fall kan du förlora bara några sekunders data. Kom ihåg att en cache inte är avsedd att fungera som en auktoritativ datakälla, och det är program som använder cachen för att säkerställa att kritiska data sparas korrekt i ett lämpligt datalager. Mer information finns i cache-aside-mönstret.
Redis är ett nyckelvärdeslager där värden kan innehålla enkla typer eller komplexa datastrukturer som hashvärden, listor och uppsättningar. Det stöder en uppsättning atomiska operationer för dessa datatyper. Nycklar kan vara permanenta. De kan också taggas med en begränsad utgångstid. Nyckeln och dess motsvarande värde tas då automatiskt bort från cachen. Mer information om Redis nycklar och värden finns i presentationen av datatyper och abstraktioner i Redis på Redis webbplats.
Redis stöder primär/underordnad replikering för att säkerställa tillgänglighet och upprätthålla dataflödet. Skrivåtgärder till en primär Redis-nod replikeras till en eller flera underordnade noder. Läsåtgärder kan hanteras av den primära eller någon av de underordnade.
Om du har en nätverkspartition kan underordnade fortsätta att hantera data och sedan transparent synkronisera om med den primära när anslutningen återupprättas. Mer information finns på sidan om replikering på Redis webbplats.
Redis tillhandahåller även klustring, som gör att du transparent kan partitionera data horisontellt på servrar och därmed sprida belastningen. Funktionen ger bättre skalbarhet. Nya Redis-servrar kan läggas till och data partitioneras om allt eftersom cacheminnet växer.
Dessutom kan varje server i klustret replikeras med hjälp av primär/underordnad replikering. Det säkerställer tillgänglighet för varje nod i klustret. Mer information om kluster och horisontell partitionering finns i Redis-kursen om kluster på Redis webbplats.
Ett Redis-cacheminne har en begränsad storlek som beror på vilka resurser som finns på värddatorn. När du konfigurerar Redis-servern anger du den maximala mängden minne som kan användas. Du kan också konfigurera en nyckel i en Redis-cache så att den har en förfallotid, varefter den tas bort automatiskt från cachen. Via den här funktionen kan du förhindra att cachen fylls med gamla och inaktuella data.
När minnet fylls kan Redis automatiskt avlägsna nycklar och deras värden genom att följa ett antal principer. Standardvärdet är LRU (används minst nyligen), men du kan också välja andra principer, till exempel att ta bort nycklar slumpmässigt eller stänga av borttagning helt och hållet (i vilket fall försök att lägga till objekt i cacheminnet misslyckas om det är fullt). Mer information finns på sidan om att använda Redis som LRU-cache.
Med Redis kan klientprogram skicka ett antal åtgärder som läs- och skrivdata i cacheminnet som en atomisk transaktion. Alla kommandon i transaktionen körs garanterat sekventiellt. Inga kommandon som utfärdas av andra samtidiga klienter vävs in mellan dem.
Det här är dock inte sanna transaktioner eftersom en relationsdatabas skulle utföra dem. Transaktionsbearbetning består av två faser: den första inträffar när kommandon ställs i kö och den andra när dessa kommandon körs. Under fasen när kommandon ställs i kö skickas de kommandon som ingår i transaktionen in av klienten. Om ett fel inträffar nu (till exempel ett syntaxfel eller fel antal parametrar) vägrar Redis sedan att bearbeta hela transaktionen och tar bort den.
Under körningsfasen utför Redis varje köat kommando i följd. Om ett kommando misslyckas under den här fasen fortsätter Redis med nästa köade kommando och återställer inte effekterna av kommandon som redan har körts. Den här förenklade transaktionsformen hjälper till att undvika prestandaproblem orsakade av konkurrens.
Redis implementerar en form av optimistisk låsning för att göra det enklare att upprätthålla konsekvens. Du hittar mer information om transaktioner och låsningar i Redis på sidan om transaktioner på Redis-webbplatsen.
Redis stöder även icke-transaktionell batchbearbetning av begäranden. Redis-protokollet som klienter använder för att skicka kommandon till en Redis-server gör att klienter kan skicka serier med åtgärder i samma begäran. Det här kan minska fragmenteringen av paket i nätverket. När batchen bearbetas utförs varje kommando. Om något av dessa kommandon är felaktigt konfigurerade avvisas de (vilket inte sker med en transaktion), men de återstående kommandona utförs. Det finns inte heller någon garanti för i vilken ordning kommandona i batchen ska bearbetas.
Redis fokuserar enbart på att ge snabb åtkomst till data. Systemet är avsett att köras i en betrodd miljö som endast kan användas av betrodda klienter. I Redis finns funktioner för en begränsad säkerhetsmodell baserad på lösenordsautentisering. (Det går att ta bort autentiseringen helt, även om vi inte rekommenderar detta.)
Alla autentiserade klienter delar samma globala lösenord och har åtkomst till samma resurser. Om du behöver mer omfattande inloggningssäkerhet måste du implementera ett eget säkerhetsskikt framför Redis-servern. Alla begäranden från klienter behöver sedan passera detta ytterligare lager. Redis ska inte exponeras direkt för ej betrodda eller oautentiserade klienter.
Du kan begränsa åtkomsten till kommandon genom att inaktivera dem eller byta namn på dem. Ge endast de nya namnen till privilegierade klienter.
Redis har inte direkt stöd för någon form av datakryptering, så all kodning måste utföras av klientprogram. Dessutom tillhandahåller Redis ingen form av transportsäkerhet. Om du behöver skydda data i nätverket rekommenderar vi en SSL-proxy.
Mer information finns på sidan om säkerhet i Redis på Redis webbplats.
Anteckning
Azure Cache for Redis tillhandahåller ett eget säkerhetslager genom vilket klienter ansluter. De underliggande Redis-servrarna exponeras inte för det offentliga nätverket.
Azure Cache for Redis ger åtkomst till Redis-servrar som finns i ett Azure-datacenter. Systemet fungerar som en fasad som ger åtkomstkontroll och säkerhet. Du kan etablera ett cacheminne med hjälp av Azure-portalen.
Portalen tillhandahåller ett antal fördefinierade konfigurationer. Dessa sträcker sig från en 53 GB cache som körs som en dedikerad tjänst som stöder SSL-kommunikation (för sekretess) och huvud-/underordnad replikering med ett serviceavtal (SLA) med 99,9 % tillgänglighet, ned till en cache på 250 MB utan replikering (inga tillgänglighetsgarantier) som körs på delad maskinvara.
Med Azure-portalen kan du också konfigurera avlägsningsprincipen för cachen och styra åtkomsten genom att lägga till användare till de roller som tillhandahålls. Dessa roller, som definierar vilka åtgärder som kan utföras av medlemmar, är bland andra Owner, Contributor och Reader (ägare, deltagare och läsare). Medlemmar med rollen Owner (ägare) har fullständig kontroll över cacheminnet, inklusive säkerhet, och dess innehåll. Medlemmar med rollen Contributor (deltagare) kan läsa och skriva information i cacheminnet. Medlemmar med rollen Reader (läsare) kan bara hämta data från cacheminnet.
De flesta administrativa uppgifter utförs via Azure-portalen. Därför är många av de administrativa kommandon som är tillgängliga i standardversionen av Redis inte tillgängliga, inklusive möjligheten att ändra konfigurationen programmatiskt, stänga av Redis-servern, konfigurera ytterligare underordnade eller med två medel spara data på disk.
Azure-portalen har ett praktiskt grafiskt gränssnitt där du kan övervaka prestanda för cacheminnet. Du kan till exempelvis visa antalet anslutningar som görs, antalet begäranden som utförs, mängden läs- och skrivåtgärder och antalet cacheträffar jämfört med cachemissar. Med den här informationen kan du avgöra effektiviteten i cacheminnet. Vid behov kan du växla till en annan konfiguration eller ändra avlägsningsprincipen.
Du kan dessutom skapa aviseringar som skickar e-postmeddelanden till en administratör om ett eller flera kritiska mått faller utanför ett förväntat intervall. Du kanske vill varna en administratör om antalet cachemissar överskrider ett angivet värde under den senaste timmen, eftersom det innebär att cacheminnet kanske är för litet eller att data avlägsnas för snabbt.
Du kan också övervaka CPU, minne och nätverksanvändning för cacheminnet.
Mer information och exempel som visar hur du skapar och konfigurerar en Azure Cache for Redis finns på sidan Varv runt Azure Cache for Redis på Azure-bloggen.
Om du skapar ASP.NET webbprogram som körs med hjälp av Azure-webbroller kan du spara information om sessionstillstånd och HTML-utdata i en Azure Cache for Redis. Med sessionstillståndsprovidern för Azure Cache for Redis kan du dela sessionsinformation mellan olika instanser av en ASP.NET webbapp och är mycket användbar i webbgruppssituationer där klient-server-tillhörighet inte är tillgänglig och cachelagring av sessionsdata i minnet inte skulle vara lämpligt.
Att använda sessionstillståndsprovidern med Azure Cache for Redis ger flera fördelar, bland annat:
- delade sessionstillstånd med ett stort antal instanser av ASP.NET-webbappar
- förbättrad skalbarhet
- funktioner för kontrollerad, samtidig åtkomst till samma sessionstillståndsdata för flera läsare och en enda skrivare
- komprimering för att spara minne och förbättra nätverkets prestanda.
Mer information finns i ASP.NET sessionstillståndsprovider för Azure Cache for Redis.
Anteckning
Använd inte sessionstillståndsprovidern för Azure Cache for Redis med ASP.NET program som körs utanför Azure-miljön. Latensen för att komma åt cachen utanför Azure kan utesluta prestandafördelarna med cachelagring av data.
På samma sätt kan du med utdatacacheprovidern för Azure Cache for Redis spara DE HTTP-svar som genereras av en ASP.NET webbapp. Om du använder utdatacacheprovidern med Azure Cache for Redis kan du förbättra svarstiderna för program som renderar komplexa HTML-utdata. Programinstanser som genererar liknande svar kan använda delade utdatafragment i cacheminnet i stället för att generera dessa HTML-utdata på nytt. Mer information finns i ASP.NET cacheprovider för utdata för Azure Cache for Redis.
Azure Cache for Redis fungerar som en fasad för de underliggande Redis-servrarna. Om du behöver en avancerad konfiguration som inte omfattas av Azure Redis-cachen (till exempel en cache som är större än 53 GB) kan du skapa och vara värd för dina egna Redis-servrar med hjälp av Azure Virtual Machines.
Det här är en potentiellt komplex process eftersom du kan behöva skapa flera virtuella datorer för att fungera som primära och underordnade noder om du vill implementera replikering. Om du vill skapa ett kluster behöver du dessutom flera primärservrar och underordnade servrar. En minimal klustrad replikeringstopologi som ger hög tillgänglighet och skalbarhet består av minst sex virtuella datorer ordnade som tre par primära/underordnade servrar (ett kluster måste innehålla minst tre primära noder).
Varje primärt/underordnat par ska finnas nära varandra för att minimera svarstiden. Varje uppsättning par kan dock köras i olika Azure-datacenter som finns i olika regioner, om du vill söka efter cachelagrade data nära de program som mest sannolikt använder dem. Ett exempel på hur du bygger och konfigurerar en Redis-nod som körs som virtuell Azure-dator finns i inlägget om att köra Redis på en virtuell CentOS Linux-dator i Azure.
Anteckning
Om du implementerar din egen Redis-cache på det här sättet ansvarar du för att övervaka, hantera och skydda tjänsten.
Att partitionera en cache innebär att dela cachen på flera datorer. Den här strukturen ger många fördelar jämfört med en enda cacheserver:
- Du kan skapa ett cacheminne som är mycket större än det som kan lagras på en enskild server.
- Du kan distribuera data på flera servrar och förbättra tillgängligheten. Om en server slutar fungera eller blir otillgänglig blir de data som den innehåller otillgängliga. Data på de återstående servrarna kan fortfarande nås. För en cache är detta inte avgörande eftersom cachelagrade data bara är en tillfällig kopia av data som lagras i en databas. Cachelagrade data på en server som blir otillgänglig kan cachelagras på en annan server i stället.
- Du kan sprida belastningen över servrarna, vilket ger bättre prestanda och skalbarhet.
- Du kan placera data fysiskt nära de användare som använder dem, vilket förkortar svarstiden.
För cacheminnen är det vanligast att partitionera med horisontell partitionering. I den här strategin är varje partition (eller fragment) en Redis-cache i sig. Data omdirigeras till en specifik partition med hjälp av logiken för horisontell partitionering. Den kan använda olika metoder för att distribuera data. I dokumentationen om mönster för horisontell partitionering finns mer information om hur du implementerar horisontell partitionering.
Om du vill implementera partitionering i ett Redis-cacheminne kan du använda någon av följande metoder:
- Routning för frågor på serversidan. I den här tekniken skickar ett klientprogram en begäran till någon av de Redis-servrar som ingår i cacheminnet (sannolikt den närmaste servern). Varje Redis-server lagrar metadata som beskriver den partition som den innehåller, och som även innehåller information om vilka partitioner som finns på andra servrar. Redis-servern undersöker klientbegäran. Om det går att lösa lokalt utförs den begärda åtgärden. Annars vidarebefordras begäran till rätt server. Den här modellen implementeras av Redis-klustring och beskrivs närmare i Redis-kursen om kluster på Redis webbplats. Redis-klustring är transparent för klientprogram och ytterligare Redis-servrar kan läggas till i klustret (och data partitioneras om) utan att du behöver konfigurera om klienterna.
- Partitionering på klientsidan. I den här modellen innehåller klientprogrammet logik (eventuellt i form av ett bibliotek) som skickar begäranden till rätt Redis-server. Den här metoden kan användas med Azure Cache for Redis. Skapa flera Azure Cache for Redis (en för varje datapartition) och implementera logiken på klientsidan som dirigerar begäranden till rätt cache. Om partitioneringsschemat ändras (om till exempel ytterligare Azure Cache for Redis skapas) kan klientprogram behöva konfigureras om.
- Proxystödd partitionering. I det här schemat skickar klientprogram begäranden till en mellanliggande proxytjänst som förstår hur data är partitionerad och sedan dirigerar begäran till rätt Redis-server. Den här metoden kan också användas med Azure Cache for Redis. proxytjänsten kan implementeras som en Azure-molntjänst. Den här metoden kräver en extra nivå av komplexitet när du implementerar tjänsten. Begäranden kan ta längre tid att genomföra än partitionering på klientsidan.
Sidan om partitionering och om att dela data mellan flera Redis-instanser på Redis webbplats innehåller ytterligare information om hur du implementerar partitionering med Redis.
Redis stöder klientprogram på många programmeringsspråk. Om du skapar nya program med hjälp av .NET Framework rekommenderar vi att du använder StackExchange.Redis-klientbiblioteket. Det här biblioteket innehåller en .NET Framework-objektmodell som tar fram informationen för att ansluta till en Redis-server, skickar kommandon och ta emot svar. Den är tillgänglig i Visual Studio som ett NuGet-paket. Du kan använda samma bibliotek för att ansluta till en Azure Cache for Redis eller en anpassad Redis-cache som finns på en virtuell dator.
När du vill ansluta till en Redis-server använder du den statiska Connect-metoden för klassen ConnectionMultiplexer. Den anslutning som skapas med den här metoden är avsedd att användas under hela klientprogrammets livslängd. Samma anslutning kan användas av flera samtidiga trådar. Återanslut och koppla inte från varje gång du utför en Redis-åtgärd eftersom detta kan försämra prestandan.
Du kan ange anslutningsparametrar, som adressen till Redis-värden och lösenordet. Om du använder Azure Cache for Redis är lösenordet antingen den primära eller sekundära nyckeln som genereras för Azure Cache for Redis med hjälp av Azure-portalen.
När du har anslutit till Redis-servern kan du hämta ett handtag på Redis-databasen som fungerar som cacheminne. Redis-anslutning tillhandahåller metoden GetDatabase för att göra det här. Du kan sedan hämta objekt från cacheminnet och lagra data i cacheminnet via metoderna StringGet och StringSet. Dessa metoder förväntar sig en nyckel som parameter. De returnerar antingen objektet i cacheminnet som har ett motsvarande värde (StringGet) eller lägger till objektet i cachen med den här nyckeln (StringSet).
Beroende på Redis-serverns plats kan många åtgärder orsaka viss fördröjning när en begäran skickas till servern och ett svar returneras till klienten. StackExchange-biblioteket innehåller asynkrona versionerna av många av de metoder som det visar, i syfte att hjälpa klientprogram att svara snabbt. Dessa metoder stöder det aktivitetsbaserade asynkrona mönstret i .NET Framework.
Följande kodavsnitt visar en metod med namnet RetrieveItem. Det illustrerar en implementering av cache-aside-mönstret baserat på Redis och StackExchange-biblioteket. Metoden tar ett strängnyckelvärde och försöker att hämta motsvarande objekt från Redis-cacheminnet genom att anropa metoden StringGetAsync (den asynkrona versionen av StringGet).
Om objektet inte hittas hämtas det från den underliggande datakällan med hjälp av GetItemFromDataSourceAsync metoden (som är en lokal metod och inte en del av StackExchange-biblioteket). Det läggs sedan till i cachen via metoden StringSetAsync, så att det kan hämtas snabbare nästa gång.
// Connect to the Azure Redis cache
ConfigurationOptions config = new ConfigurationOptions();
config.EndPoints.Add("<your DNS name>.redis.cache.windows.net");
config.Password = "<Redis cache key from management portal>";
ConnectionMultiplexer redisHostConnection = ConnectionMultiplexer.Connect(config);
IDatabase cache = redisHostConnection.GetDatabase();
...
private async Task<string> RetrieveItem(string itemKey)
{
// Attempt to retrieve the item from the Redis cache
string itemValue = await cache.StringGetAsync(itemKey);
// If the value returned is null, the item was not found in the cache
// So retrieve the item from the data source and add it to the cache
if (itemValue == null)
{
itemValue = await GetItemFromDataSourceAsync(itemKey);
await cache.StringSetAsync(itemKey, itemValue);
}
// Return the item
return itemValue;
}
Metoderna StringGet och StringSet är inte begränsade till att hämta eller lagra strängvärden. De kan ta alla objekt som är serialiserade som en matris bestående av byte. Om du behöver spara ett .NET-objekt kan du serialisera som en byte-dataström och använda metoden StringSet för att skriva till cachen.
Du kan på liknande sätt läsa ett objekt från cacheminnet genom att använda metoden StringGet och avserialisera det som ett .NET-objekt. Följande kod visar en uppsättning tilläggsmetoder för gränssnittet IDatabase (metoden GetDatabase i en Redis-anslutning returnerar ett IDatabase-objekt), och viss exempelkod som använder dessa metoder för att läsa och skriva ett BlogPost-objekt till cachen:
public static class RedisCacheExtensions
{
public static async Task<T> GetAsync<T>(this IDatabase cache, string key)
{
return Deserialize<T>(await cache.StringGetAsync(key));
}
public static async Task<object> GetAsync(this IDatabase cache, string key)
{
return Deserialize<object>(await cache.StringGetAsync(key));
}
public static async Task SetAsync(this IDatabase cache, string key, object value)
{
await cache.StringSetAsync(key, Serialize(value));
}
static byte[] Serialize(object o)
{
byte[] objectDataAsStream = null;
if (o != null)
{
var jsonString = JsonSerializer.Serialize(o);
objectDataAsStream = Encoding.ASCII.GetBytes(jsonString);
}
return objectDataAsStream;
}
static T Deserialize<T>(byte[] stream)
{
T result = default(T);
if (stream != null)
{
var jsonString = Encoding.ASCII.GetString(stream);
result = JsonSerializer.Deserialize<T>(jsonString);
}
return result;
}
}
Följande kod illustrerar en metod som kallas RetrieveBlogPost och som använder dessa tilläggsmetoder för att läsa och skriva ett serialiserbart BlogPost-objekt till cacheminnet efter cache-aside-mönstret:
// The BlogPost type
public class BlogPost
{
private HashSet<string> tags;
public BlogPost(int id, string title, int score, IEnumerable<string> tags)
{
this.Id = id;
this.Title = title;
this.Score = score;
this.tags = new HashSet<string>(tags);
}
public int Id { get; set; }
public string Title { get; set; }
public int Score { get; set; }
public ICollection<string> Tags => this.tags;
}
...
private async Task<BlogPost> RetrieveBlogPost(string blogPostKey)
{
BlogPost blogPost = await cache.GetAsync<BlogPost>(blogPostKey);
if (blogPost == null)
{
blogPost = await GetBlogPostFromDataSourceAsync(blogPostKey);
await cache.SetAsync(blogPostKey, blogPost);
}
return blogPost;
}
Redis stöder pipelining av kommandon om ett klientprogram skickar flera asynkrona begäranden. Redis kan multiplexbehandla begäranden med samma anslutning i stället för att ta emot och svara på kommandon i en strikt sekvens.
Det här minskar svarstiden genom att nätverket används effektivare. Följande kodavsnitt visar ett exempel där information om två kunder hämtas samtidigt. Koden skickar två begäranden och utför vissa andra bearbetningar (visas inte) innan den väntar på att ta emot resultaten. Metoden Wait för cacheobjektet liknar .NET Framework-metoden Task.Wait:
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
var task1 = cache.StringGetAsync("customer:1");
var task2 = cache.StringGetAsync("customer:2");
...
var customer1 = cache.Wait(task1);
var customer2 = cache.Wait(task2);
Mer information om hur du skriver klientprogram som kan använda Azure Cache for Redis finns i dokumentationen om Azure Cache for Redis. Mer information finns också på StackExchange.Redis.
Sidan om pipelines och multiplex på samma webbplats innehåller mer information om asynkrona åtgärder och pipelining med Redis och StackExchange-biblioteket.
Det enklaste användningsområdet för Redis för cachelagring är nyckelvärdepar där värdet är en otolkad sträng av godtycklig längd som kan innehålla alla binära data. (Det är i princip en matris med byte som kan behandlas som en sträng). Det här scenariot visades i avsnittet Implementera Redis-cacheklientprogram tidigare i den här artikeln.
Observera att nycklarna även innehåller otolkade data, så du kan använda valfri binär information som nyckel. Ju längre nyckeln är, desto mer diskutrymme tar den upp och desto längre tid tar det för att utföra sökåtgärder. Utforma nyckelutrymmet noggrant, med tanke på användbarhet och enkelt underhåll, och använd beskrivande (men inte för utförliga) nycklar.
Du kan till exempel använda strukturerade nycklar som "customer:100" för att referera till nyckeln för kund nummer 100, istället för bara "100". Med det här schemat kan du enkelt skilja mellan värden som lagrar olika datatyper. Du skulle till exempel kunna använda nyckeln "orders:100" för att referera till nyckeln för beställning nummer 100.
Förutom endimensionella binära strängar kan ett värde i ett Redis-nyckelvärdespar också hålla mer strukturerad information, inklusive listor, uppsättningar (sorterade och osorterade) och hashvärden. Redis tillhandahåller en omfattande kommandouppsättning som kan ändra dessa typer. Många av dessa kommandon är tillgängliga för .NET Framework-program via ett klientbiblioteket, till exempel StackExchange. I presentationen av datatyper och abstraktioner i Redis på Redis webbplats finns en detaljerad beskrivning av dessa typer och de kommandon du kan använda för att hantera dem.
I det här avsnittet beskrivs några vanliga användningsområden för dessa typer av data och kommandon.
Redis stöder ett antal atomiska get-and-set-åtgärder för strängvärden. Dessa åtgärder ta bort eventuella konkurrensproblem som kan uppstå när du använder separata kommandon för GET och SET. De tillgängliga åtgärderna är bland andra:
INCR,INCRBY,DECRochDECRBY, som utför atomiska öknings- och minskningsåtgärder på datavärden av heltalstyp. StackExchange-biblioteket innehåller överbelastade versioner av metodernaIDatabase.StringIncrementAsyncochIDatabase.StringDecrementAsyncför att utföra de här åtgärderna och returnera resultatvärdet som lagras i cacheminnet. Följande kodavsnitt illustrerar hur du använder dessa metoder:ConnectionMultiplexer redisHostConnection = ...; IDatabase cache = redisHostConnection.GetDatabase(); ... await cache.StringSetAsync("data:counter", 99); ... long oldValue = await cache.StringIncrementAsync("data:counter"); // Increment by 1 (the default) // oldValue should be 100 long newValue = await cache.StringDecrementAsync("data:counter", 50); // Decrement by 50 // newValue should be 50GETSET, som hämtar värdet som har associerats med en nyckel och ändrar det till ett nytt värde. StackExchange-biblioteket gör den här åtgärden tillgänglig via metodenIDatabase.StringGetSetAsync. I kodfragmentet nedan visas ett exempel på den här metoden. Den här koden returnerar det aktuella värdet som har associerats med nyckeln data:counter från föregående exempel. Den återställer sedan värdet för den här nyckeln till noll, och allt ingår i samma åtgärd:ConnectionMultiplexer redisHostConnection = ...; IDatabase cache = redisHostConnection.GetDatabase(); ... string oldValue = await cache.StringGetSetAsync("data:counter", 0);MGETochMSET, som kan returnera och ändra en uppsättning strängvärden som en enda åtgärd. MetodernaIDatabase.StringGetAsyncochIDatabase.StringSetAsyncöverlagras för att stödja den här funktionen, vilket visas i följande exempel:ConnectionMultiplexer redisHostConnection = ...; IDatabase cache = redisHostConnection.GetDatabase(); ... // Create a list of key-value pairs var keysAndValues = new List<KeyValuePair<RedisKey, RedisValue>>() { new KeyValuePair<RedisKey, RedisValue>("data:key1", "value1"), new KeyValuePair<RedisKey, RedisValue>("data:key99", "value2"), new KeyValuePair<RedisKey, RedisValue>("data:key322", "value3") }; // Store the list of key-value pairs in the cache cache.StringSet(keysAndValues.ToArray()); ... // Find all values that match a list of keys RedisKey[] keys = { "data:key1", "data:key99", "data:key322"}; // values should contain { "value1", "value2", "value3" } RedisValue[] values = cache.StringGet(keys);
Du kan också kombinera flera åtgärder i en enda Redis-transaktion. Det beskrivs i avsnittet Redis-transaktioner och -batchar tidigare i den här artikeln. StackExchange-biblioteket erbjuder funktioner för transaktioner via gränssnittet ITransaction.
Du skapar ett objekt av typen ITransaction med hjälp av metoden IDatabase.CreateTransaction. Du kan anropa kommandon för transaktionen genom att använda de metoder som tillhandahålls av objektet ITransaction.
Gränssnittet ITransaction ger åtkomst till en uppsättning metoder som liknar de som nås via gränssnittet IDatabase, förutom att alla metoder är asynkrona. Det innebär att de endast utförs när ITransaction.Execute metoden anropas. Värdet som returneras av metoden ITransaction.Execute visar om transaktionen skapades (true) eller inte skapades (false).
I följande kodavsnitt visas ett exempel som ökar och minskar två räknare i samma transaktion:
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
ITransaction transaction = cache.CreateTransaction();
var tx1 = transaction.StringIncrementAsync("data:counter1");
var tx2 = transaction.StringDecrementAsync("data:counter2");
bool result = transaction.Execute();
Console.WriteLine("Transaction {0}", result ? "succeeded" : "failed");
Console.WriteLine("Result of increment: {0}", tx1.Result);
Console.WriteLine("Result of decrement: {0}", tx2.Result);
Kom ihåg att Redis-transaktioner skiljer sig från transaktioner i relationsdatabaser. Metoden Execute köar helt enkelt alla kommandon som utgör den transaktion som ska köras. Om något av dem är felaktigt stoppas transaktionen. När alla kommandon har kunnat ställas i kö körs varje kommando asynkront.
Om ett kommando misslyckas fortsätter de övriga att bearbetas. Om du behöver verifiera att ett kommando har slutförts måste du hämta resultatet med hjälp av egenskapen Result (resultat) för motsvarande aktivitet, så som visas i exemplet ovan. När egenskapen Result (resultat) läses blockeras anropstråden tills uppgiften har slutförts.
Mer information finns i Transaktioner i Redis.
När du utför batchåtgärder kan du använda gränssnittet IBatch i StackExchange-biblioteket. Det här gränssnittet ger åtkomst till en uppsättning metoder som liknar de som nås via gränssnittet IDatabase, förutom att alla metoder är asynkrona.
Du skapar objekt av typen IBatch med hjälp av metoden IDatabase.CreateBatch. Du kör sedan batchen med hjälp av metoden IBatch.Execute, som visas i följande exempel. Den här koden anger bara ett strängvärde, ökar och minskar samma räknare som användes i föregående exempel. Resultatet visas sedan:
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
IBatch batch = cache.CreateBatch();
batch.StringSetAsync("data:key1", 11);
var t1 = batch.StringIncrementAsync("data:counter1");
var t2 = batch.StringDecrementAsync("data:counter2");
batch.Execute();
Console.WriteLine("{0}", t1.Result);
Console.WriteLine("{0}", t2.Result);
Det är viktigt att förstå att om ett kommando i en batch misslyckas på grund av att det är felaktigt kan de andra kommandona fortfarande köras, till skillnad från en transaktion. Metoden IBatch.Execute returnerar inte någon indikation på lyckad eller misslyckad.
Redis stöder fire-and-forget-åtgärder (starta och glöm) med hjälp av kommandoflaggor. I det här fallet initierar klienten helt enkelt en åtgärd men har inget intresse av resultatet och väntar inte på att kommandot ska slutföras. I exemplet nedan ser du hur du utför INCR-kommandot som fire-and-forget-åtgärd:
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
await cache.StringSetAsync("data:key1", 99);
...
cache.StringIncrement("data:key1", flags: CommandFlags.FireAndForget);
När du sparar ett objekt i ett Redis-cacheminne anger du en bortre tidsgräns där objektet tas bort från cachen automatiskt. Du kan också fråga hur mycket mer tid en nyckel har innan den upphör med hjälp av kommandot TTL. Det här kommandot är tillgängligt för StackExchange-program via metoden IDatabase.KeyTimeToLive.
I följande kodavsnitt ser du hur du ställer in en förfallotid på 20 sekunder för en nyckel och sedan frågar om den återstående livslängden för nyckeln:
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
// Add a key with an expiration time of 20 seconds
await cache.StringSetAsync("data:key1", 99, TimeSpan.FromSeconds(20));
...
// Query how much time a key has left to live
// If the key has already expired, the KeyTimeToLive function returns a null
TimeSpan? expiry = cache.KeyTimeToLive("data:key1");
Du kan också ange förfallotiden till ett visst datum och en viss tid genom att använda kommandot EXPIRE. Det är tillgängligt i StackExchange-biblioteket som metoden KeyExpireAsync:
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
// Add a key with an expiration date of midnight on 1st January 2015
await cache.StringSetAsync("data:key1", 99);
await cache.KeyExpireAsync("data:key1",
new DateTime(2015, 1, 1, 0, 0, 0, DateTimeKind.Utc));
...
Tips
Du kan manuellt ta bort ett objekt från cacheminnet med hjälp av kommandot DEL. Det är tillgängligt via StackExchange-biblioteket som metoden IDatabase.KeyDeleteAsync.
En Redis-uppsättning är en samling av flera objekt som delar en enda nyckel. Du kan skapa en uppsättning med hjälp av kommandot SADD (uppsättning, lägg till). Du kan hämta objekten i en uppsättning med hjälp av kommandot SMEMBERS (uppsättning, medlemmar). StackExchange-biblioteket implementerar SADD-kommandot med metoden IDatabase.SetAddAsync och SMEMBERS-kommandot med metoden IDatabase.SetMembersAsync.
Du kan också kombinera befintliga uppsättningar och skapa nya uppsättningar med hjälp av kommandona SDIFF (uppsättning, skillnad), SINTRING (uppsättning, skärning) och SUNION (uppsättning, union). StackExchange-biblioteket kombinerar dessa åtgärder i metoden IDatabase.SetCombineAsync. Den första parametern för den här metoden anger den uppsättningsåtgärd som ska utföras.
I följande kodavsnitt ser du hur uppsättningar kan vara användbara för att snabbt lagra och hämta samlingar med relaterade objekt. Den här koden använder typen BlogPost som beskrevs i avsnittet Implementera Redis-cacheklientprogram tidigare i den här artikeln.
Ett objekt av typen BlogPost innehåller fyra fält: ett ID, ett namn, en rangordning och en samling taggar. I det första kodfragmentet nedan visas exempeldata som har använts för att fylla i en C#-lista över BlogPost-objekt:
List<string[]> tags = new List<string[]>
{
new[] { "iot","csharp" },
new[] { "iot","azure","csharp" },
new[] { "csharp","git","big data" },
new[] { "iot","git","database" },
new[] { "database","git" },
new[] { "csharp","database" },
new[] { "iot" },
new[] { "iot","database","git" },
new[] { "azure","database","big data","git","csharp" },
new[] { "azure" }
};
List<BlogPost> posts = new List<BlogPost>();
int blogKey = 0;
int numberOfPosts = 20;
Random random = new Random();
for (int i = 0; i < numberOfPosts; i++)
{
blogKey++;
posts.Add(new BlogPost(
blogKey, // Blog post ID
string.Format(CultureInfo.InvariantCulture, "Blog Post #{0}",
blogKey), // Blog post title
random.Next(100, 10000), // Ranking score
tags[i % tags.Count])); // Tags--assigned from a collection
// in the tags list
}
Du kan lagra taggar för varje BlogPost-objekt som en uppsättning i ett Redis-cacheminne och associera varje uppsättning med ID:t för BlogPost. Det gör att ett program snabbt kan hitta alla taggar som hör till ett visst blogginlägg. Om du vill söka i motsatt riktning och hitta alla blogginlägg som delar en viss tagg kan du skapa en annan uppsättning som innehåller bloggposterna som har referens till tagg-ID:t i nyckeln:
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
// Tags are easily represented as Redis Sets
foreach (BlogPost post in posts)
{
string redisKey = string.Format(CultureInfo.InvariantCulture,
"blog:posts:{0}:tags", post.Id);
// Add tags to the blog post in Redis
await cache.SetAddAsync(
redisKey, post.Tags.Select(s => (RedisValue)s).ToArray());
// Now do the inverse so we can figure out which blog posts have a given tag
foreach (var tag in post.Tags)
{
await cache.SetAddAsync(string.Format(CultureInfo.InvariantCulture,
"tag:{0}:blog:posts", tag), post.Id);
}
}
Med dessa strukturer kan du utföra många vanliga frågor mycket effektivt. Du kan exempelvis söka efter och visa alla taggar för blogginlägget 1 så här:
// Show the tags for blog post #1
foreach (var value in await cache.SetMembersAsync("blog:posts:1:tags"))
{
Console.WriteLine(value);
}
Du hittar alla taggar som är gemensamma för blogginlägg 1 och blogginlägg 2 genom att utföra en SINTRING-åtgärd (uppsättning, skärning) så här:
// Show the tags in common for blog posts #1 and #2
foreach (var value in await cache.SetCombineAsync(SetOperation.Intersect, new RedisKey[]
{ "blog:posts:1:tags", "blog:posts:2:tags" }))
{
Console.WriteLine(value);
}
Och du också hitta alla blogginlägg som innehåller en viss tagg:
// Show the ids of the blog posts that have the tag "iot".
foreach (var value in await cache.SetMembersAsync("tag:iot:blog:posts"))
{
Console.WriteLine(value);
}
En vanlig åtgärd som krävs för många program är att hitta nyligen använda objekt. En blogg vill kanske visa information om vilka blogginlägg som har lästs senast.
Du kan implementera den här funktionen med en Redis-lista. Ett Redis-listan innehåller flera objekt som delar samma nyckel. Listan fungerar som en dubbelsidig kö. Du kan skicka objekt till valfri ände av listan med hjälp av kommandona LPUSH (skicka åt vänster) och RPUSH (skicka åt höger). Du kan hämta objekt från valfri ände av listan med hjälp av kommandona LPOP (hämta från vänster) och RPOP (hämta från höger). Du kan också returnera en uppsättning element med hjälp av kommandona LRANGE (vänster intervall) och RRANGE (höger intervall).
I kodavsnitten ser du hur du kan utföra dessa åtgärder genom att använda StackExchange-biblioteket. I den här koden använder vi typen BlogPost från föregående exempel. När ett blogginlägg läses av en användare skickar metoden IDatabase.ListLeftPushAsync namnet på blogginlägget till en lista som är kopplad till nyckeln blog:recent_posts i Redis-cacheminnet.
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
string redisKey = "blog:recent_posts";
BlogPost blogPost = ...; // Reference to the blog post that has just been read
await cache.ListLeftPushAsync(
redisKey, blogPost.Title); // Push the blog post onto the list
Allteftersom användare läser fler blogginlägg skickas namnen på inläggen till samma lista. Listan sorteras efter den sekvens i vilken namnen har lagts till. De senast lästa blogginläggen ligger till vänster i listan. (Om samma blogginlägg läses mer än en gång får den flera poster i listan.)
Du kan visa namnen på de senast lästa inläggen med metoden IDatabase.ListRange. Den här metoden tar den nyckel som innehåller listan, en startpunkt och en slutpunkt. Följande kod hämtar namnen på de 10 blogginläggen längst till vänster i listan (objekt från 0 till 9):
// Show latest ten posts
foreach (string postTitle in await cache.ListRangeAsync(redisKey, 0, 9))
{
Console.WriteLine(postTitle);
}
Observera att ListRangeAsync metoden inte tar bort objekt från listan. Om du vill göra det kan du använda metoderna IDatabase.ListLeftPopAsync och IDatabase.ListRightPopAsync.
Om du vill förhindra att listan växer i all oändlighet kan du regelbundet gallra bort objekt genom att ta bort delar av listan. Kodfragmentet nedan visar hur du tar bort alla objekt från listan utom de fem längst till vänster:
await cache.ListTrimAsync(redisKey, 0, 5);
Som standard lagras inte objekten i en uppsättning i någon specifik ordning. Du kan skapa en ordnad uppsättning med hjälp av kommandot ZADD (sorterad uppsättning, lägg till) (metoden IDatabase.SortedSetAdd i StackExchange-biblioteket). Objekten sorteras med hjälp av ett numeriskt värde som kallas poäng. Det tillhandahålls som parameter i kommandot.
Följande kodavsnitt lägger till namnet på ett blogginlägg i en sorterad lista. I det här exemplet har varje blogginlägget även ett poängfält med blogginläggets rangordning.
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
string redisKey = "blog:post_rankings";
BlogPost blogPost = ...; // Reference to a blog post that has just been rated
await cache.SortedSetAddAsync(redisKey, blogPost.Title, blogPost.Score);
Du kan hämta namn på blogginlägg och poäng i stigande ordning med metoden IDatabase.SortedSetRangeByRankWithScores:
foreach (var post in await cache.SortedSetRangeByRankWithScoresAsync(redisKey))
{
Console.WriteLine(post);
}
Anteckning
StackExchange-biblioteket innehåller IDatabase.SortedSetRangeByRankAsync också metoden som returnerar data i poängordning, men den returnerar inte poängen.
Du kan också hämta objekt i fallande ordning efter resultat och begränsa antalet objekt som returneras genom att ange ytterligare parametrar i metoden IDatabase.SortedSetRangeByRankWithScoresAsync. I nästa exempel visas namn och poäng för de 10 översta blogginläggen i rangordningen:
foreach (var post in await cache.SortedSetRangeByRankWithScoresAsync(
redisKey, 0, 9, Order.Descending))
{
Console.WriteLine(post);
}
I nästa exempel används metoden IDatabase.SortedSetRangeByScoreWithScoresAsync, som begränsar vilka objekt som returneras till de som faller inom ett visst poängintervall:
// Blog posts with scores between 5000 and 100000
foreach (var post in await cache.SortedSetRangeByScoreWithScoresAsync(
redisKey, 5000, 100000))
{
Console.WriteLine(post);
}
Förutom att den fungerar som cacheminne tillhandahåller Redis-servern meddelanden via en mekanism med hög kapacitet för utgivare/prenumerant. Klientprogram kan prenumerera på en kanal, och andra program och tjänster kan publicera meddelanden på kanalen. De prenumererande programmen får sedan dessa meddelanden och kan bearbeta dem.
Redis tillhandahåller kommandot SUBSCRIBE (prenumerera) som klientprogram använder för att prenumerera på kanaler. Det här kommandot förväntar sig namnet på en eller flera kanaler på vilka programmet ska ta emot meddelanden. StackExchange-biblioteket innehåller gränssnittet ISubscription, vilket gör det möjligt för .NET Framework-program att prenumerera på och publicera till kanaler.
Du skapar ett ISubscription-objekt med hjälp av metoden GetSubscriber för anslutningen till Redis-servern. Du lyssnar sedan efter meddelanden på en kanal med hjälp av metoden SubscribeAsync för objektet. Följande kodexempel visar hur du prenumererar på en kanal med namnet messages:blogPosts.
ConnectionMultiplexer redisHostConnection = ...;
ISubscriber subscriber = redisHostConnection.GetSubscriber();
...
await subscriber.SubscribeAsync("messages:blogPosts", (channel, message) => Console.WriteLine("Title is: {0}", message));
Den första parametern i metoden Subscribe är namnet på kanalen. Det här namnet följer samma konventioner som används av nycklar i cacheminnet. Namnet kan innehålla binära data, men vi rekommenderar att du använder relativt korta, meningsfulla strängar för att säkerställa bra prestanda och underhåll.
Observera också att namnområdet som används av kanaler är skilt från det som används av nycklar. Det innebär att du kan ha kanaler och nycklar med samma namn, även om det kan göra programkoden svårare att underhålla.
Den andra parametern är en åtgärdsdelegering. Det här ombudet körs asynkront när ett nytt meddelande visas på kanalen. Det här exemplet visar bara meddelandet på konsolen (meddelandet innehåller namnet på ett blogginlägg).
Om du vill publicera en kanal kan ett program använda Redis-kommandot PUBLISH (publicera). I StackExchange-bibliotek finns metoden IServer.PublishAsync för att utföra den här åtgärden. Nästa kodfragmentet visar hur du publicerar ett meddelande på kanalen messages:blogPosts:
ConnectionMultiplexer redisHostConnection = ...;
ISubscriber subscriber = redisHostConnection.GetSubscriber();
...
BlogPost blogPost = ...;
subscriber.PublishAsync("messages:blogPosts", blogPost.Title);
Det finns flera punkter du bör känna till om mekanismen för publicera/prenumerera:
- Flera prenumeranter kan prenumerera på samma kanal och de får alla meddelanden som publiceras till kanalen.
- Prenumeranter får endast meddelanden som har publicerats efter att de har prenumererat. Kanaler buffrar inte och när ett meddelande har publicerats skickar Redis-infrastrukturen meddelandet till varje prenumerant och tar sedan bort det.
- Som standard tas meddelanden emot av prenumeranter i den ordning de skickas. I ett system med hög aktivitet, med ett stort antal meddelanden och många prenumeranter och utgivare, kan garanterad sekventiell leverans av meddelanden ge sämre prestanda i systemet. Om varje meddelande är fristående och ordningen oviktigt kan du aktivera samtidig bearbetning i Redis-systemet. Det kan förbättra svarstiden. Du kan åstadkomma det här i StackExchange-klienten genom att ställa in PreserveAsyncOrder för anslutningen som används av prenumeranten till false (falskt):
ConnectionMultiplexer redisHostConnection = ...;
redisHostConnection.PreserveAsyncOrder = false;
ISubscriber subscriber = redisHostConnection.GetSubscriber();
När du väljer serialiseringsformat behöver du överväga kompromisserna mellan prestanda, samverkan, versionshantering, kompabilitet med befintliga system, datakomprimering och minnesanvändning. När du utvärderar prestandan bör du komma ihåg att prestandamåtten är mycket beroende av kontexten. De återspeglar kanske inte den faktiska arbetsbelastningen och räknar kanske inte med nyare bibliotek och versioner. Det finns ingen enskild "snabbaste" serialiserare för alla scenarier.
Några alternativ att tänka på:
Protocol Buffers (även kallat Protobuf) är ett serialiseringsformat utvecklat av Google för effektivt serialisera strukturerade data. Den använder starkt inskrivna definitionsfiler för att definiera meddelandestrukturer. Dessa definitionsfiler kompileras sedan till språkspecifik kod för serialisering och avserialisering av meddelanden. Protobuf kan användas via befintliga RPC-mekanismer. Det kan också generera en RPC-tjänst.
Apache Thrift använder ett liknande tillvägagångssätt, med starkt typifierade definitionsfiler och ett kompileringssteg för att generera kod för serialisering och RPC-tjänster.
Apache Avro har liknande funktioner som Protokollbuffertar och Thrift, men det finns inget kompileringssteg. I stället innehåller serialiserade data alltid ett schema som beskriver strukturen.
JSON är en öppen standard med textfält som kan läsas av människor. Det fungerar med många olika plattformar. JSON använder inte meddelandescheman. Eftersom det är ett textbaserat format är det inte särskilt effektivt över kabeln. I vissa fall kanske du dock returnerar cachelagrade objekt direkt till en klient via HTTP. Då kan du om du lagrar JSON spara kostnaden för att avserialisera från ett annat format och sedan serialisera till JSON.
binär JSON (BSON) är ett binärt serialiseringsformat som använder en struktur som liknar JSON. BSON har utformats för att vara kompakt, enkelt att läsa av och för att gå snabbt att serialisera och deserialisera, i förhållande till JSON. Nyttolasterna är jämförbara i storlek med JSON. Beroende på data kan en BSON-nyttolast vara mindre eller större än en JSON-nyttolast. BSON har några ytterligare datatyper som inte är tillgängliga i JSON, särskilt BinData (för bytematriser) och Datum.
MessagePack är ett binärt serialiseringsformat som är utformat för att vara kompakt för smidig överföring. Det finns inga meddelandescheman eller typkontroll för meddelanden.
Bond är ett ramverk för flera plattformar, för att jobba med schematiserade data. Det har funktioner för serialisering och deserialisering över olika språk. Några av de främsta skillnaderna från andra system i listan är funktioner för arv, typalias och generisk typ.
gRPC är ett RPC-system med öppen källkod som utvecklats av Google. Standardinställningen är att det använder Protocol Buffers som definitionsspråk och underliggande filutbytesformat för meddelanden.
- Dokumentation om Azure Cache for Redis
- Vanliga frågor och svar om Azure Cache for Redis
- Aktivitetsbaserat asynkront mönster
- Redis-dokumentation
- StackExchange.Redis
- Guide för datapartitionering
Följande mönster kan också vara relevanta för ditt scenario när du implementerar cachelagring i dina program:
Cache-aside-mönster: det här mönstret beskriver hur du på begäran läser in data i ett cacheminne från ett datalager. Det här mönstret hjälper också till att upprätthålla konsekvens mellan data i cacheminnet och data i den ursprungliga datalagringen.
Sharding-mönster (horisontell partitionering)innehåller information om hur du använder horisontell partitionering för att förbättra skalbarheten vid lagring av och åtkomst till stora mängder data.