Distribuerade program och tjänster som körs i molnet är till sin natur komplexa delar av programvara som utgör många rörliga delar. I en produktionsmiljö är det viktigt att kunna spåra hur användarna använder systemet, spåra resursutnyttjande och i allmänhet övervaka systemets hälsa och prestanda. Du kan använda den här informationen som diagnostiskt stöd för att identifiera och åtgärda problem samt för att upptäcka potentiella problem och förebygga att de uppstår.
Scenarier för övervakning och diagnostik
Du kan använda övervakning för att få en överblick över hur bra ett system fungerar. Övervakning är en viktig del av att upprätthålla tjänstens målsättning för kvalitet. Vanliga scenarier för att samla in övervakningsdata är:
- Se till att systemet förblir felfritt.
- Spåra tillgänglighet för systemet och dess komponentelementet.
- Underhålla prestanda för att säkerställa att systemets dataflöde inte försämras oväntat medan arbetsvolymen ökar.
- Garantera att systemet uppfyller alla servicenivåavtal (SLA:er) som har upprättats med kunderna.
- Skydda systemets och användarnas sekretess och säkerhet samt deras data.
- Spåra åtgärder som utförs för gransknings- och föreskriftssyften.
- Övervaka daglig användning av systemet och upptäcka trender som kan leda till problem om de inte åtgärdas.
- Spåra problem som uppstår, från en första rapport via analyser av möjliga orsaker, korrigering, efterföljande programuppdateringar och distribution.
- Spåra åtgärder och felsöka programversioner.
Kommentar
Den här listan är inte avsedd att vara omfattande. Det här dokumentet fokuserar på scenarier som är de vanligaste situationerna för övervakning. Det kan finnas andra som är mindre vanliga eller som är specifika för din miljö.
I följande avsnitt beskrivs dessa scenarier mer utförligt. Information för varje scenario tas upp i följande format:
- En kort översikt över scenariot.
- De typiska kraven i det här scenariot.
- Rådata för instrumentation som krävs för att stödja scenariot och möjliga källor till den här informationen.
- Hur dessa rådata kan analyseras och kombineras för att generera meningsfull diagnostisk information.
Hälsoövervakning
Ett system är felfritt om det körs och kan genomföra begäranden. Syftet med hälsoövervakning är att skapa en ögonblicksbild av systemets aktuella status, så att du kan kontrollera att systemets alla komponenter fungerar som de ska.
Krav för hälsoövervakning
En operatör ska snabbt meddelas (inom några sekunder) om någon del av systemet bedöms vara felaktig. Operatören ska kunna kontrollera vilka av systemets delar som fungerar normalt och vilka delar som har problem. Systemets hälsostatus kan framhävas med ett trafikljussystem:
- Rött betyder ohälsosamt (systemet har stoppats)
- Gult betyder delvis felfritt (systemet körs med begränsad funktionalitet)
- Grönt betyder helt felfritt
Med en omfattande hälsoövervakning av systemet kan en operatör granska hela systemet nedåt och visa hälsostatus för delsystem och komponenter. Om systemets övergripande hälsostatus till exempel beskrivs som delvis felfritt ska operatören kunna zooma in och avgöra vilka funktioner som inte är tillgängliga.
Krav för insamling av data, instrumentation och datakällor
De rådata som krävs som stöd för hälsoövervakning kan genereras till följd av:
- Spårning av användarbegäran. Den här informationen kan användas för att avgöra vilka begäranden som lyckats, misslyckats och hur lång tid varje begärande tar.
- Syntetisk användarövervakning. Den här processen simulerar stegen som utförs av en användare och följer en fördefinierad rad steg. Resultatet för varje steg ska hämtas.
- Undantag för loggning, fel och aviseringar. Den här informationen kan hämtas tack vare spårningsinstruktioner som bäddats in i programkoden, samt hämta information från händelseloggarna för alla tjänster som refererar till systemet.
- Hälsoövervakning av tredjepartstjänster som systemet använder. Den här övervakningen kan behöva hämta och parsa data för hälsotillstånd som tjänsterna tillhandahåller. Den här informationen kan ha en mängd olika format.
- Slutpunktsövervakning. Den här mekanismen beskrivs mer utförligt i avsnittet ”Tillgänglighetsövervakning”.
- Insamling av omgivande prestandainformation, som processoranvändning i bakgrunden eller aktivitet för I/O (inklusive nätverket).
Analysera hälsodata
Hälsoövervakningens huvudsakliga fokus är att snabbt ange huruvida systemet körs. Heta analyser av omedelbara data kan utlösa en avisering om fel upptäcks i viktiga komponenter. (Det går inte att svara på en rad pingar i följd, till exempel.) Operatorn kan sedan vidta lämpliga korrigerande åtgärder.
Ett mer avancerat system kan innehålla förutsägande element som utför kalla analyser framför senaste och aktuella arbetsbelastningar. En kall analys kan upptäcka trender och avgöra huruvida systemet sannolikt är felfritt eller om det behöver ytterligare resurser. Det här förutsägande elementet ska baseras på kritiska prestandamått, som:
- Antalet begäranden som är riktade mot varje tjänst eller undersystem.
- Svarstider för de här begärandena.
- Mängden data som flödar till och från varje tjänst.
Om värdet för alla mått överskrider ett angivet tröskelvärde kan systemet utlösa en avisering som ger en operatör eller automatisk skalning (om tillgängligt) möjligheten att vidta förebyggande åtgärder som behövs för att upprätthålla systemhälsan. De här åtgärderna kan handla om att lägga till resurser, starta om en eller flera tjänster som misslyckats eller tillämpa begränsning på begäranden med lägre prioritet.
Tillgänglighetsövervakning
Ett helt felfritt system kräver att komponenterna och delsystemen som utgör systemet är tillgängliga. Tillgänglighetsövervakning är nära förknippat med hälsoövervakning. Medan hälsoövervakning ger en omedelbar insikt i systemets aktuella hälsotillstånd handlar tillgänglighetsövervakning om att spåra systemets tillgänglighet och dess komponenter, för att generera statistik om drifttid för systemet.
I många system är vissa komponenter (till exempel en databas) konfigurerade med inbyggd redundans för att möjliggöra snabb växling vid ett allvarligt fel eller anslutningsproblem. I den bästa av världar är användaren inte medveten om att ett sådant fel inträffat. Från ett tillgänglighetsövervakningsperspektiv är det dock nödvändigt att samla in så mycket information som möjligt om de här felen, för att ta reda på orsaken och vidta åtgärder så att de inte uppstår igen.
De data som krävs för att spåra tillgänglighet kan vara beroende av ett antal faktorer med lägre nivå. Många av faktorerna kan vara specifika för programmet, systemet och miljön. Ett effektivt övervakningssystem samlar in tillgänglighetsdata som motsvarar faktorerna med låg nivå och aggregera dem för att ge en övergripande bild av systemet. I exempelvis ett e-handelssystem kan verksamhetsfunktionerna som gör det möjligt för en kund att göra en beställning bero på databasen där beställningsinformationen lagras och betalningssystemet som hanterar de monetära transaktionerna när beställningarna betalas. Tillgängligheten för systemets beställningsdel är därför en tillgänglighetsfunktion för databasen och undersystemet för betalning.
Krav för tillgänglighetsövervakning
En operatör bör även kunna visa historisk tillgänglighet för varje system och undersystem och använda informationen för att upptäcka eventuella trender som kan orsaka att ett eller flera delsystem misslyckas regelbundet. (Misslyckas tjänster vid vissa tillfällen på dagen som motsvarar en bearbetningshöjdpunkt?)
En övervakningslösning bör ge en omedelbar och historisk översikt över varje undersystems tillgänglighet eller otillgänglighet. Den bör också snabbt kunna meddela en operatör när en eller flera tjänster misslyckas eller när användare inte kan ansluta till tjänster. Det här handlar inte bara om övervakning av varje tjänst, utan också om att undersöka vilka åtgärder som varje användare utför, om dessa åtgärder misslyckas när de försöker kommunicera med en tjänst. Anslutningsfel i viss omfattning är normalt och kan bero på övergående fel. Det kan dock vara praktiskt om systemet kan generera ett meddelande för antalet anslutningsfel till ett särskilt delsystem som uppstår under en viss period.
Krav för insamling av data, instrumentation och datakällor
Precis som med hälsoövervakning kan de rådata som krävs som stöd för tillgänglighetsövervakning genereras som ett resultat av syntetisk användarövervakning eller loggning av undantag, fel och aviseringar som kan uppstå. Dessutom kan tillgänglighetsdata hämtas från slutpunktsövervakningen. Programmet kan exponera en eller flera hälsa slutpunkter, som testar åtkomst till ett funktionsområde i systemet. Övervakningssystemet kan pinga varje slutpunkt genom att följa ett definierat schema och samla in resultatet (lyckat eller misslyckat).
Alla tidsgränser, nätverksanslutningsfel och anslutningsförsök måste registreras. Alla data ska tidsstämplas.
Analysera tillgänglighetsdata
Instrumentationsdata måste aggregeras och korrelera för att ge stöd för följande typer av analys:
- Omedelbar tillgänglighet för system och undersystem.
- Felfrekvens för tillgänglighet i systemet och undersystemen. I den bästa av världar ska en operatör kunna korrelera felen med särskilda åtgärder: vad pågick när systemet misslyckades?
- En historisk vy över felfrekvenser för systemet eller undersystem vid särskilda tidsperioder och belastningen på systemet (antalet användarbegäranden) när ett fel inträffat.
- Orsaker till att systemet eller undersystem är otillgängliga. Anledningarna kan exempelvis vara att en tjänst inte körs, att anslutningen kopplades ifrån, att nätverket är anslutet men har ett avbrott eller att det är anslutet med har återkommande problem.
Du kan beräkna procentandelen för en tjänsts tillgänglighet under en viss tidsperiod med hjälp av följande formel:
%Availability = ((Total Time – Total Downtime) / Total Time ) * 100
Det här är användbart för SLA-syften. (Serviceavtalsövervakning beskrivs mer detaljerat senare i den här vägledningen.) Definitionen av stilleståndstid beror på tjänsten. Exempelvis definierar Build-tjänsten i Visual Studio Team Service driftstopp som den tid (totalt antal minuter sammanlagt) som Build-tjänsten varit otillgänglig. En minut anses vara otillgänglig om alla kundinitierade kontinuerliga HTTP-åtgärdsbegäranden till Build-tjänsten under hela minuten antingen resulterar i en felkod eller inte returnerar något svar.
Prestandaövervakning
Om systemet utsätts för mer och mer stress (genom ökat antal användare) ökar storleken på datauppsättningarna som användarna har åtkomst till och risken att det uppstår problem med en eller flera komponenter ökar. Ofta föregås komponentfel av prestandaförsämring. Om du upplever en minskning kan du vidta förebyggande åtgärder för att avhjälpa situationen.
Systemets prestanda beror på ett antal faktorer. Varje faktor mäts vanligtvis via nyckelindikatorer (KPI:er), som antalet databastransaktioner per sekund eller antalet nätverksbegäranden som hanteras inom en viss tidsram. Vissa av dessa KPI:er kan finnas som specifika prestandamått, medan andra kan härledas från en kombination av mått.
Kommentar
För att kunna avgöra om prestandan är bra eller dålig krävs förståelse för den prestandanivå som systemet bör kunna köra på. Detta kräver att system övervakas medan det körs under normal belastning och att data hämtas för alla KPI:er under en tidsperiod. Det här kan innefatta att systemet körs under simulerad belastning i en testmiljö och att lämpliga data samlas in innan systemet driftsätts i en produktionsmiljö.
Du bör också säkerställa att prestandaövervakningen inte överbelastar systemet. Du kan eventuellt justera detaljnivån för de data som prestandaövervakningen samlar in dynamiskt.
Krav för prestandaövervakning
För kontroll av systemets prestanda behöver operatören vanligtvis information om:
- Svarsfrekvenser för användarbegäranden.
- Antal samtida användarbegäranden.
- Nätverkstrafikens volym.
- Frekvens för företagstransaktioner som håller på att slutföras.
- Genomsnittlig bearbetningstid för begäranden.
Det kan också vara bra att tillhandahålla verktyg som ger operatören möjligheten att upptäcka korrelationer som:
- Antal samtida användare jämfört med svarstid för begäranden (den tid det tar att starta bearbetning för ett begärande när användaren har skickat det).
- Antal samtida användare jämfört med genomsnittlig svarstid (den tid det tar för att slutföra ett begärande när bearbetning startat).
- Antal begäranden jämfört med antal bearbetningsfel.
Tillsammans med den här funktionella informationen på hög nivå ska en operatör kunna få en detaljerad vy av varje komponents prestanda i systemet. Dessa data är vanligtvis försedda via prestandaräknare på låg nivå som spårar information som:
- Minnesanvändning.
- Antal trådar.
- Bearbetningstid för CPU.
- Kölängd för begärande.
- Avgifter för disk eller I/O-nätverk och fel.
- Antal skrivna eller lästa byte.
- Indikatorer för mellanprogram, exempelvis kölängd.
Alla visualiseringar ska tillåta en operatör att ange en tidsperiod. De data som visas kan vara en ögonblicksbild av den aktuella situationen eller en historisk vy över prestandan.
En operatör ska kunna generera en avisering baserad på ett prestandamått för alla angivna värden under en angiven tidsperiod.
Krav för insamling av data, instrumentation och datakällor
Du kan samla in prestandadata på hög nivå (dataflöde, antal samtida användare, antal företagstransaktioner, felfrekvens och så vidare) genom att övervaka förloppet för användarnas begäranden när de tas emot och passerar genom systemet. Det här innefattar införlivandet av spårningsrapporter vid nyckelpunkter i programkoden, tillsammans med tidsinformation. Alla fel, undantag och aviseringar ska samlas in med tillräckliga data för korrelation mellan dem och de begäranden som orsakade dem. Internet Information Services-loggen (IIS) är en annan användbar källa.
Om möjligt ska du hämta prestandadata för alla externa system som används i programmet. De här externa systemen kan ange sina egna prestandaräknare eller andra funktioner för att begära prestandadata. Om detta inte är möjligt registrerar du information som start- och sluttid för när varje begärande gjordes till ett externt system, tillsammans med status (slutfört, misslyckat eller varning) för åtgärden. Du kan till exempel använda ett stoppur för att ta tid på begäranden: starta tidtagningen när ett begärande startar och stoppa sedan tidtagningen när begärandet avslutas.
Prestandadata på låg nivå för enskilda komponenter i ett system kan finnas tillgängliga genom funktioner och tjänster, som Windows prestandaräknare eller Azure Diagnostics.
Analysera prestandadata
En stor del av analysarbetet består av att aggregera prestandadata efter typ av användarbegäran eller det undersystem eller den tjänst som varje begäran skickas till. Exempel på användarbegäranden är när en artikel läggs till i en kundvagn eller när ett begärande om att gå till kassan görs i ett e-handelssystem.
Ett annat vanligt krav är att prestandadata sammanfattas i valda percentiler. En operatör kan exempelvis avgöra svarstiden för 99 procent av begäranden, 95 procent av begäranden och 70 procent av begäranden. Det kan finnas SLA-mål eller andra mål för vardera percentil. Pågående resultat ska rapporteras i nära realtid för att bidra till att upptäcka omedelbara problem. Resultatet bör av statistiska skäl också aggregeras under längre tid.
Vid problem med fördröjningar som påverkar prestandan ska en operatör snabbt kunna identifiera anledningen till att flaskhalsen uppstår genom att utreda fördröjningen i varje steg som ett begärande utför. Prestandadata måste därför tillhandahålla ett sätt för att korrelera prestandamått för vardera steg, för att förknippa dem till en specifik begäran.
Beroende på visualiseringskraven kan det vara användbart att generera och lagra en datakub som innehåller vyer över rådata. Den här datakuben kan tillåta komplexa ad hoc-frågor och -analyser av prestandainformation.
Säkerhetsövervakning
Alla kommersiella system som innehåller känsliga data måste implementera en säkerhetsstruktur. Säkerhetsmekanismens komplexitet är vanligtvis en funktion för känsliga data. I ett system som kräver att användare autentiseras ska du registrera:
- Alla inloggningsförsök, huruvida de misslyckas eller lyckas.
- Alla åtgärder som utförs av – och information om alla resurser som nås av – en autentiserad användare.
- När en användare avslutar en session och loggar ut.
Med hjälp av övervakning kan du upptäcka attacker på systemet. Ett stort antal misslyckade inloggningsförsök kan exempelvis tyda på en nyckelsökningsattack. En oväntat ökning av begäranden kan bero på en distribuerad överbelastningsattack (DDoS). Du måste vara förberedd på att övervaka alla begäranden till alla källor, oavsett källan för de här begärandena. Ett system som är inloggningskänsligt kan av misstag exponera källor för omvärlden, utan att en användare faktiskt loggar in.
Krav för säkerhetsövervakning
De viktigaste aspekterna i säkerhetsövervakning ska göra det möjligt för en operatör att snabbt:
- Identifiera försök till intrång av en icke-autentiserad enhet.
- Identifiera enheter som försökt utföra åtgärder på data som de inte har beviljats åtkomst till.
- Avgöra huruvida systemet eller någon del av systemet angripits utifrån eller inifrån. (Till exempel kan en autentiserad angripare försöka avsluta systemet.)
För att stödja dessa krav bör en operatör meddelas om:
- Ett konto gör upprepade misslyckade inloggningsförsök inom en angiven period.
- Ett autentiserat konto försöker upprepade gånger komma åt en förbjuden resurs under en angiven period.
- Ett stort antal oautentiserade eller obehöriga begäranden sker under en angiven period.
Den information som har angetts för en operatör bör innehålla källans värdadress för varje begärande. Om säkerhetsöverträdelser uppstår från ett visst adressintervall kan de här värdarna blockeras.
En viktig del i att upprätthålla ett systems säkerhet är att snabbt identifiera åtgärder som avviker från det vanliga mönstret. Information som antalet misslyckade eller lyckade inloggningsbegäranden kan visas visuellt för att identifiera om det finns en aktivitetstoppar vid en ovanlig tidpunkt. (Ett exempel på en sådan aktivitet är användare som loggar in kl 03:00 och utför många åtgärder, trots att deras arbetsdag börjar vid 09:00). Den här informationen kan också användas för att konfigurera tidsbaserad automatisk skalning. Om en operatör iakttar att ett stort antal användare regelbundet loggar in vid en viss tid på dagen kan operatören upprätta ytterligare autentiseringstjänster för att hantera arbetsbelastningen och sedan stänga ned de ytterligare tjänsterna när en höjdpunkt passerat.
Krav för insamling av data, instrumentation och datakällor
Säkerhet är en omfattande aspekt av de mest distribuerade systemen. Viktiga data genereras troligen på flera platser i ett system. Du bör överväga att anta ett förhållningssätt mer likt Säkerhetsinformation och händelsehantering (SIEM) för att samla in säkerhetsrelaterad information som är konsekvensen av utlösta händelser i programmet, nätverksutrustning, servrar, brandväggar, antivirusprogram och andra intrångsskyddande element.
Säkerhetsövervakning kan innefatta data från verktyg som inte är en del av programmet. De här verktygen kan innefatta funktioner som identifierar portskanningsaktiviteter från externa agenturer eller nätverksfilter som identifierar icke-autentiserade åtkomstförsök till program eller data.
Oavsett måste insamlade data göra det möjligt för en administratör att avgöra en attacks syfte och vidta lämpliga åtgärder.
Analysera säkerhetsdata
En säkerhetsövervakningsfunktion är en rad källor varifrån data uppstår. De olika formaten och detaljnivån kräver ofta komplexa analyser av insamlade data för att förknippa dem till en enhetlig informationstråd. Bortsett från de enklaste fallen (som att spåra ett stort antal misslyckade inloggningar eller upprepade försök till att få oauktoriserad åtkomst till kritiska resurser) är det kanske inte möjligt att utföra komplex automatisk bearbetning av säkerhetsdata. I stället kan det vara bättre att skriva dessa data, tidsstämplade men i övrigt i sin ursprungliga form, till en säker lagringsplats för att möjliggöra manuell expertanalys.
SLA-övervakning
Många kommersiella system med stöd för betalande kunder ger garantier om systemets prestanda i form av SLA:er. SLA-tillstånd anger i huvudsak att systemet kan hantera en definierad mängd arbete inom en överenskommen tidsram och utan att förlora nödvändig information. SLA-övervakning har som syfte att säkerställa att systemet kan uppfylla mätbara SLA:er.
Kommentar
SLA-övervakning är nära förknippat med prestandaövervakning. Medan prestandaövervakningens syfte är att säkerställa att systemet fungerar optimalt kontrolleras SLA-övervakning av avtalsskyldighet som definierar vad optimalt faktiskt innebär.
SLA:er definieras ofta enligt följande:
- Systemets totala tillgänglighet. En organisation kan till exempel garantera att systemet är tillgängligt 99,9 procent av tiden. Det innebär max nio timmars nedtid per år eller ungefär tio minuter per vecka.
- Driftdataflöde. Den här aspekten uttrycks ofta som en eller flera övre vattenmärken, som garanti för att systemet har stöd för upp till 100 000 samtida användare eller kan hantera 10 000 samtida företagstransaktioner.
- Driftsvarstid. Systemet kan också ge garantier för vilken frekvens som begäranden bearbetas inom. Ett exempel är att 99 procent av alla företagstransaktioner avslutas inom två sekunder och att inga enskilda transaktioner tar längre tid än tio sekunder.
Kommentar
Vissa kontrakt för kommersiella system kan även innehålla SLA:er för teknisk support. Ett exempel är att alla supportärenden kommer att få ett svar inom fem minuter och att 99 procent av alla problem kommer att åtgärdas helt inom en arbetsdag. Effektiv ärendeuppföljning (beskrivs senare i det här avsnittet) är nyckeln till att uppfylla SLA:er som de här.
Krav för övervakning av SLA-övervakning
På den högsta nivån ska en operatör snabbt kunna avgöra huruvida systemet uppfyller avtalade SLA:er eller inte. Om inte ska operatören kunna gå nedåt och granska underliggande faktorer nedåt för att fastställa orsakerna till att prestandan är under standard.
Vanliga indikatorer på hög nivå som kan skildras visuellt innefattar:
- Tjänstens drifttid i procent.
- Programmets dataflöde (mätt i termer av lyckade transaktioner eller åtgärder per sekund).
- Antal lyckade/misslyckade programbegäranden.
- Antal program- och systemfel, undantag och varningar.
Alla de här indikatorerna ska kunna filtreras bort av en angiven tidsperiod.
Ett molnprogram omfattar sannolikt ett antal undersystem och komponenter. En operatör ska kunna välja en indikator på hög nivå och visa hur den är sammansatt från hälsotillståndet för de underliggande elementen. Om exempelvis det övergripande systemets drifttid sjunker nedanför ett godkänt värde ska en operatör kunna zooma in och avgöra vilka element som bidrar till felet.
Kommentar
Systemets drifttid måste definieras noggrant. I ett system som använder redundans för att säkerställa maximal tillgänglighet kan enskilda elements instanser misslyckas, men systemet kan ändå fungera. Systemets drifttid som visas av hälsoövervakningen ska ange varje elements aggregerade drifttid och inte nödvändigtvis huruvida systemet faktiskt stoppats. Dessutom kan fel vara sporadiska. Det innebär att även om ett visst system är otillgängligt kan återstoden av systemet vara tillgängligt, fast med begränsad funktionalitet. (I ett e-handelssystem kan ett systemfel hindra en kund från att göra en beställning, fast kunden fortfarande kan söka i produktkatalogen.)
I varningssyfte ska systemet kunna skicka en händelse om någon av indikatorerna på hög nivå överstiger ett särskilt tröskelvärde. Informationen på låg nivå för de olika faktorerna som utgör indikatorn på hög nivå ska vara tillgängliga som kontextuella data i aviseringssystemet.
Krav för insamling av data, instrumentation och datakällor
De rådata som krävs som stöd för SLA-övervakning liknar de rådata som krävs för prestandaövervakning, samt andra hälsoaspekter och tillgänglighetsövervakning. (Mer information finns i avsnitten.) Du kan samla in dessa data genom att:
- Genomföra slutpunktsövervakning.
- Undantag för loggning, fel och aviseringar.
- Spåra användarbegäranden.
- Övervaka tillgänglighet av tredjepartstjänster som systemet använder.
- Använda prestandamått och -räknare.
Alla data måste vara tidsstämplade och tidsstämplade.
Analysera SLA-data
Instrumentationsdata måste aggregeras för att generera en bild över systemets totala prestanda. Aggregerade data måste också ha stöd för att granska nedåt för att aktivera prestandagranskning i de underliggande undersystemen. Du ska exempelvis kunna:
- Beräkna det totala antalet användarbegäranden under en viss tidsperiod och avgöra slutförandefrekvens och misslyckandegrad för de här begärandena.
- Generera en övergripande vy över systemets svarstider genom att kombinera svarstiderna för användarbegärandena.
- Beräkna den övergripande svarstiden för ett begärande i svarstiderna för begärandets enskilda arbetsobjekt genom att analysera förloppet för användarbegäranden.
- Avgör systemets övergripande tillgänglighet i procentandel av drifttiden för en viss tidsperiod.
- Analysera procentandelen av tillgänglighet i tid för enskilda komponenter och tjänster i systemet. Det här kan innefatta parsningsloggar som genererats av tredjepartstjänster.
Många kommersiella system krävs för att rapportera verkliga prestandasiffror gentemot överenskomna SLA:er för en angiven tidsperiod, vanligtvis en månad. Den här informationen kan användas till att beräkna krediter eller annan typ av återbetalning till kunden om SLA:erna inte uppnås under tidsperioden. Du kan beräkna en tjänsts tillgänglighet genom att använda den teknik som beskrivs i avsnittet Analysera tillgänglighetsdata.
För interna syften kan en organisation också spåra antalet incidenter och vad som ledde till att tjänsterna misslyckades. Minimera nedtid och uppfyll SLA:er genom att ta reda på hur du snabbt löser de här problemen eller eliminerar de helt.
Granskning
Beroende på programmets egenskaper kan det finnas lagstiftning för krav på granskning av användaråtgärder och registrering av all dataåtkomst. Granskning kan leda till bevismaterial som kopplar samman kunder till ett visst begärande. Nonrepudiation är en viktig faktor i många e-affärssystem för att upprätthålla förtroende mellan en kund och den organisation som ansvarar för programmet eller tjänsten.
Krav för granskning
En analytiker måste kunna spåra sekvensen för verksamhetsåtgärder som användare utför, så att du kan rekonstruera användarnas åtgärder. Det här kan vara nödvändigt för registrering eller som en del i en rättsteknisk utredning.
Granskning av information är högkänsligt. Den innehåller troligtvis data som identifierar systemanvändarna och åtgärderna som de utför. Därför presenteras granskningsinformation troligtvis i form av rapporter som endast är tillgängliga för betrodda analytiker istället för som ett interaktivt system med stöd för granskning nedåt i grafiska åtgärder. En analytiker ska kunna generera en mängd rapporter. Rapporterna kan exempelvis ordna alla användares aktiviteter som inträffar inom en angiven tidsram, visa en enskild användares aktiviteter i kronologisk ordning eller lista i vilken ordning åtgärder utförts gentemot en eller flera resurser.
Krav för insamling av data, instrumentation och datakällor
De huvudsakliga informationskällorna för granskning kan innefatta:
- Säkerhetssystemet som hanterar användarautentisering.
- Spårningsloggar som registrerar användaraktivitet.
- Säkerhetsloggar som spårar alla identifierbara och icke-identifierbara nätverksbegäranden.
Formatet för granskningsdata och hur de lagras kan styras av lagstiftade krav. Exempelvis är det kanske inte möjligt att på något vis rensa data. (Den måste registreras i sitt ursprungliga format.) Åtkomst till lagringsplatsen där den lagras måste skyddas för att förhindra manipulering.
Analysera granskningsdata
En analytiker måste kunna komma åt rådata i sin helhet och ursprungliga format. Bortsett från kraven på att generera vanliga granskningsrapporter är verktygen för att analysera data troligtvis specialiserade och förvaras utanför systemet.
Användarövervakning
Användarövervakning registrerar hur ett programs funktioner och komponenter används. En operatör kan använda den insamlade informationen till att:
Avgöra vilka funktioner som används mycket och avgöra alla potentiella surfpunkter i systemet. Element med hög trafik kan dra nytta av funktionell partitionering eller till och med replikering för att sprida ut belastningen på jämnare vis. En operatör kan också använda den här informationen för att avgöra vilka funktioner som används sällan och som eventuellt ska dras tillbaka eller ersättas i framtida versioner av systemet.
Hämta information om drifthändelserna i systemet under normal användning. På en e-handelssida kan du exempelvis registrera statistisk information om antalet transaktioner och kunder som ansvarar för dem. Den här informationen kan användas för kapacitetsplanering allt eftersom att antalet kunder ökar.
Identifiera (möjligen indirekt) användarnöjdhet med hjälp av systemets prestanda eller funktioner. Om ett stort antal kunder i ett e-handelssystem regelbundet lämnar sina kundvagnar kan det exempelvis bero på ett problem med funktionen för att gå till kassan.
Generera faktureringsinformation. Ett kommersiellt program eller tjänster för flera innehavare kan debitera kunder för de resurser de använder.
Tvinga fram kvoter. Om en användare i ett system för flera användare överskrider sin utbetalda kvot för bearbetningstid eller resursanvändning under en viss tidsperiod, kan deras åtkomst begränsas eller så kan bearbetningen begränsas.
Krav för användarövervakning
Om en operatör ska kontrollera systemanvändningen behöver den vanligtvis visa information som innefattar:
- Antalet begäranden som bearbetas av varje undersystem och dirigeras till varje resurs.
- Det arbete som utförs av varje användare.
- Mängden datalagring som varje användare använder.
- Resurser som varje användare använder.
En operatör ska även kunna generera diagram. Ett diagram kan exempelvis visa de mest resurshungriga användarna eller de mest använda resurserna eller systemfunktionerna.
Krav för insamling av data, instrumentation och datakällor
Spårning av användning kan utföras på relativt hög nivå. Den kan notera start- och sluttider för varje begärande och dess egenskaper (läsa, skriva osv. beroende på resursen i fråga). Du kan hämta den här informationen genom att:
- Spåra användaraktivitet.
- Läs in prestandaräknare som mäter användning för varje resurs.
- Övervakning av resursanvändningen för varje användare.
I avläsningssyfte måste du också kunna identifiera vilka användare som ansvarar för att utföra vilka åtgärder och vilka resurser som dessa åtgärder använder. Den insamlade informationen ska vara tillräckligt detaljerad för att kunna aktivera korrekt fakturering.
Ärendeuppföljning
Kunder och andra användare kan rapportera problem om oväntade händelser eller beteenden inträffar i systemet. Ärendeuppföljning handlar om att hantera problemen, associera dem med försök att lösa systemets underliggande problem och informera kunder om möjliga lösningar.
Krav på ärendeuppföljning
Operatörer utför ofta ärendeuppföljning med hjälp av ett separat system som gör det möjligt för dem att registrera och rapportera den probleminformation som användarna rapporterar. Den här informationen kan innefatta åtgärderna som användaren försökte utföra, symptom på problemet, händelseföljd och eventuella fel- eller varningsmeddelanden som utlösts.
Krav för insamling av data, instrumentation och datakällor
Den inledande datakällan för ärendeuppföljningsdata är användaren som först rapporterade problemet. Användaren kan tillhandahålla ytterligare information som:
- En kraschdump (om programmet innefattar en komponent som kör på användarens skrivbord).
- En ögonblicksbild av skärmen.
- Datum och tid för när felet inträffade, tillsammans med annan information om omgivningen, som användarens plats.
Den här informationen kan användas till att bidra till felsökning och till att skapa kvarvarande uppgifter för framtida lanseringar av programvaran.
Analysera ärendeuppföljningsdata
Olika användare kan rapportera samma problem. Ärendeuppföljningsystemet ska associera till vanliga rapporter.
Felsökningsförloppet ska registreras gentemot vardera felrapport. När problemet är löst informeras kunden om lösningen.
Om en användare rapporterar ett problem som har en känd lösning i ärendeuppföljningsystemet kan operatören omedelbart meddela användaren om lösningen.
Spåra åtgärder och felsöka programversioner
När en användare rapporterar ett problem är användaren ofta bara medveten om den omedelbara effekt som det har på deras åtgärder. Användaren kan bara rapportera ett resultat om sina egna upplevelser till en operatör som ansvarar för att underhålla systemet. Detta är vanligtvis bara synliga symptom på ett eller flera grundläggande problem. I många fall behöver en analytiker leta i kronologisk ordning efter de underliggande åtgärderna, för att kunna fastställa problemets rotorsak. Processen kallas rotorsaksanalys.
Kommentar
Rotorsaksanalysen kan uppdaga ineffektivitet i ett programs design. I sådana fall kan det vara möjligt att omarbeta berörda element och distribuera dem som en del av en senare version. Den här processen kräver noggrann kontroll och de uppdaterade komponenterna bör övervakas noggrant.
Krav för spårning och felsökning
Om du vill spåra oväntade händelser och andra problem är det viktigt att dina övervakningsdata tillhandahåller tillräckligt med information så att en analytiker kan spåra problemens ursprung och återskapa i vilken ordning som de inträffade. Den här informationen måste vara tillräcklig för att en analytiker ska kunna diagnostisera problemets rotorsak. En utvecklare kan sedan genomföra nödvändiga ändringar så att det inte inträffar igen.
Krav för insamling av data, instrumentation och datakällor
Felsökning kan innefatta alla de metoder (och respektive parametrar) som uppstått som del av en åtgärd för att bygga ett träd som avbildar det logiska flödet genom systemet när en kund gör ett visst begärande. Undantag och varningar som systemet genererar som resultat av flödet måste samlas in och loggas.
Som stöd för felsökning kan systemet tillhandahålla krokar som en operatör kan använda till att hämta tillståndsinformation vid kritiska punkter i systemet. Eller så kan systemet leverera utförlig information steg för steg allt eftersom de valda åtgärderna bearbetas. Att läsa in data på den här nivån kan skapa ytterligare belastning på systemet och bör vara en tillfällig process. En operatör använder i huvudsak den här processen när en väldigt ovanlig händelse inträffar och är svår att replikera eller när en ny version av ett eller flera element i ett system kräver noggrann övervakning för att säkerställa att elementen fungerar som förväntat.
Pipeline för övervakning och diagnostik
Det kan vara en stor utmaning att övervaka ett stort distribuerat system. Alla scenarion som beskrivs i föregående avsnitt ska inte nödvändigtvis betraktas i sin enskildhet. Det är troligt att det uppstår en väsentlig överlappning i övervaknings- och diagnostikdata som krävs för vardera situation, trots att informationen kan behöva bearbetas och presenteras på olika sätt. Därför bör du anta en holistisk syn på övervakning och diagnostik.
Du kan betrakta hela övervaknings- och diagnostikprocessen som en pipeline som består av de steg som visas nedan på bild 1.
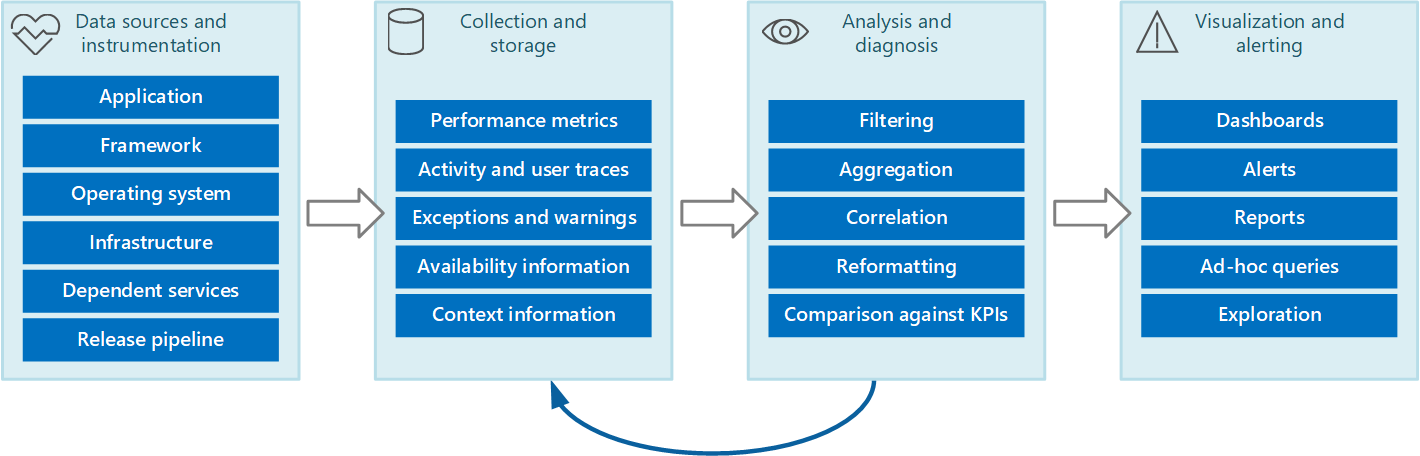
Bild 1 – Stegen i pipelinen för övervakning och diagnostik.
På bild 1 visas hur data för övervakning och diagnostik kan komma från en mängd olika datakällor. Stegen för instrumentation och insamling har att göra med att identifiera källorna som data måste läsas in ifrån och avgöra vilka data som ska läsas in, hur de ska hämtas och hur dessa data ska formateras så att de enkelt kan kontrolleras. Steget för analys/diagnos använder rådata för att generera meningsfull information som en operatör kan använda för att avgöra systemets tillstånd. Operatören kan med den här informationen ta beslut om möjliga åtgärder som ska vidtas och sedan skicka tillbaka resultatet till stegen för instrumentation och insamling. Fasen för visualisering/aviseringar visar en förbrukningsvy som kan användas av systemets tillstånd. Information kan visas i nära realtid med hjälp av en serie instrumentpaneler. Det kan generera rapporter, diagram och tabeller och på sås vis tillhandahålla en historisk översikt över de data som kan hjälpa dig att identifiera långsiktiga trender. Om information visar att en KPI riskerar att överskrida acceptabla gränser kan det här steget också utlösa en avisering till en operatör. I vissa fall kan en avisering också användas för att utlösa en automatiserad process som försöker vidta åtgärder, till exempel autoskalning.
Observera att de här stegen utgör en kontinuerlig flödesprocess där stegen sker parallellt. Vi rekommenderar att alla faser konfigureras dynamiskt. Vid vissa tidpunkter, särskilt när ett system som nyligen har driftsatts eller har upplevt problem, kan det vara nödvändigt att samla in utökade data oftare. Vid andra tillfällen bör det vara möjligt att återgå till att läsa in basnivån för viktig information för att verifiera att systemet fungerar korrekt.
Dessutom bör hela övervakningsprocessen anses vara en pågående lösning i realtid som ska finjusteras och förbättras allteftersom feedback tas emot. Du kan till exempel börja med att mäta många faktorer för att fastställa systemets hälsa. Analysering över tid kan leda till förfining, då du avfärdar mått som är irrelevanta, vilket gör att du ökar fokus på de data du behöver och att bakgrundsljud minskar.
Källor för övervaknings- och diagnostikdata
Informationen som används för övervakningsprocessen kan komma från flera källor, som visas i bild 1. På programnivå kommer information från spårningsloggar som införlivas i systemets kod. Utvecklare bör följa en standardmetod för att spåra flödeskontrollen via sin kod. Exempelvis kan en post till en metod generera ett spårningsmeddelande som anger namnet på metoden, den aktuella tiden, värdet för varje parameter och annan relevant information. Det kan också vara användbart att registrera in- och utloggningstider.
Du bör logga alla undantag och varningar och se till att du behåller en fullständig spårning av eventuella kapslade undantag och varningar. Du bör helst hämta information som identifierar användaren som kör koden tillsammans med informationen för korrelationsaktivitet (för att spåra begäranden när de passerar genom systemet). Du bör också logga åtkomstförsök till alla resurser, som meddelandeköer, databaser, filer och andra beroende tjänster. Den här informationen kan användas för mätnings- och granskningsändamål.
Många program använder bibliotek och ramverk för att utföra vanliga uppgifter som att komma åt ett datalager eller kommunicera via ett nätverk. De här ramverken kan konfigureras för att tillhandahålla egna spårningsmeddelanden och rå diagnostisk information, som transaktionsfrekvens och lyckade och misslyckade dataöverföring.
Kommentar
Många moderna ramverk publicerar automatiskt prestanda och spårningshändelser. Insamling av den här information handlar bara om att skapa ett sätt att hämta och lagra den där den kan bearbetas och analyseras.
Operativsystemet där programmet körs kan vara en källa för systemomfattande information på låg nivå, till exempel prestandaräknare som anger I/O-frekvens, minnesanvändning och CPU-användning. Fel i operativsystemet (till exempel att det inte gick att öppna en fil korrekt) kan också rapporteras.
Du bör också ha de underliggande infrastrukturerna och komponenterna som kör ditt system i åtanke. Virtuella datorer, virtuella nätverk och lagringstjänster kan vara källor med viktiga prestandaräknare och andra diagnostikdata på infrastrukturnivå.
Om programmet använder andra externa tjänster, till exempel en webbserver eller databashanteringssystem, kan de här tjänsterna publicera sin egen spårningsinformation samt egna loggar och prestandaräknare. Exempel innefattar SQL Server Dynamic Management Views för spårningsåtgärder som utförs mot en SQL Server-databas och IIS-spårningsloggar för registrering av begäranden till en webbserver.
Allt eftersom att systemkomponenterna förändras och nya versioner lanseras är det är viktigt att kunna tillskriva varje versions problem, händelser och mått. Den här informationen ska kopplas till versionspipelinen, så att problem med en viss komponentversion snabbt kan spåras och korrigeras.
Säkerhetsproblem kan uppstå när som helst i systemet. Exempelvis kan en användare försöka logga in med ett ogiltigt användar-ID eller lösenord. En autentiserad användare kan försöka få oauktoriserad åtkomst till en resurs. Eller så kan en användare försöka komma åt krypterad information med en ogiltig eller för gammal åtkomstnyckel. Säkerhetsrelaterad information för lyckade eller misslyckade begäranden ska alltid loggas.
Avsnittet Arrangera ett program innehåller mer vägledning till informationen som du bör läsa in. Du kan använda en mängd strategier för att samla in den här informationen:
Program/systemövervakning. Den här strategin använder interna källor inuti programmet, programmets ramverk, operativsystem och infrastruktur. Programkoden kan generera sina egna övervakningsdata vid viktiga punkter under livscykeln för ett klientbegärande. Programmet kan innehålla spårningsuppgifter som kan aktiveras eller inaktiveras beroende på omständigheterna. Det kan också vara möjligt att mata in diagnostik dynamiskt med hjälp av ett ramverk för diagnostik. De här ramverken har vanligtvis plugin-program som kan ansluta till olika instrumentationspunkter i koden och hämta spårningsdata vid de här punkterna.
Dessutom kan din kod eller den underliggande infrastrukturen generera händelser vid kritiska punkter. Övervakning av agenter som konfigurerats för att lyssna efter de här händelserna kan registrera händelseinformationen.
Verklig användarövervakning. Med den här metoden registreras interaktioner mellan en användare och programmet, och flödet för varje begärande och svar observeras. Den här informationen kan ha ett dubbelt syfte: den kan användas för att mäta användning efter varje användare och för att avgöra huruvida användare tar emot service på lämplig nivå (exempelvis snabb svarstid, låg fördröjning och minimalt med fel). Du kan använda inlästa data till att identifiera viktiga områden där fel oftast uppstår. Du kan också använda data för att identifiera element då systemet blir långsammare, möjligen på grund av surfpunkter i programmet eller någon annan form av flaskhals. Om du använder den här metoden noggrant kan det vara möjligt att rekonstruera användarnas flöden via programmet för felsökning och testning.
Viktigt!
Du bör ha i åtanke att de data som läses in via övervakningen av riktiga användare är högkänsligt material, då de innehåller konfidentiellt material. Om du sparar inlästa data ska du lagra de på ett säkert sätt. Om du vill använda data för prestandaövervakning eller felsökning ska du först ta bort alla personuppgifter.
Syntetisk användarövervakning. Med den här metoden kan du skriva din egna testklient som simulerar en användare och utför en konfigurerbar men typisk rad åtgärder. Du kan spåra testklientens prestanda som hjälp för att avgöra systemets tillstånd. Du kan också använda flera instanser av testklienten som en del av ett belastningstest för att fastställa hur systemet svarar under hög belastning och vilken typ av övervakning av utdata som genereras under dessa villkor.
Kommentar
Du kan implementera verklig och syntetisk användarövervakning genom att inkludera kod som spårar och tar tid på metodanropets körning och andra viktiga delar i ett program.
Profilering. Den här metoden är primärt avsett för att övervaka och förbättra programmets prestanda. Istället för att fungera på den funktionella nivån för verklig och syntetisk användarövervakning läses information på lägre nivåer in medan programmet körs. Du kan implementera profilering genom att använda periodisk provtagning på ett programs körningstillstånd (avgöra vilka delar i koden som programmet använder vid en viss tidpunkt). Du kan också använda instrumentation som infogar avsökningar i koden vid viktiga föreningspunkter (till exempel start och slut för ett metodanrop ) och registrerar vilka metoder som anropades vid vilken tidpunkt och hur lång tid varje anrop tog. Du kan sedan analysera dina data och avgöra vilka delar i programmet som kan orsaka prestandaproblemen.
Slutpunktsövervakning. Den här metoden använder en eller flera diagnostiska slutpunkter som exponeras specifikt av programmet för att aktivera övervakning. En slutpunkt skapar en gångstig i programkoden och kan returnera information om systemets hälsotillstånd. Olika slutpunkter kan fokusera på olika aspekter av funktionen. Du kan skriva en egen diagnostikklient som skickar regelbundna begäranden till slutpunkterna och sammanställa svaren. Mer information finns i mönstret Hälsoslutpunktsövervakning.
För maximal täckning bör du använda en kombination av dessa metoder.
Instrumentering av ett program
Instrumentation är en viktig del i övervakningsprocessen. Du kan bara ta meningsfulla beslut om prestandan och hälsotillståndet för ett system om du först hämtade data som gör att du kan ta de här besluten. Den information som du samlar in med hjälp av instrumentation bör vara tillräckliga för att utvärdera prestanda, diagnostisera problem och ta beslut utan att behöva logga in på en fjärransluten produktionsserver och utföra spårning (och felsökning) manuellt. Instrumentationsdata omfattar vanligtvis mått och information som skrivs till spårningsloggar.
Innehållet i en spårningslogg kan vara resultatet av textdata som skrivs av programmet eller binära data som skapas till följd av en spårningshändelse, om programmet använder händelsespårning för Windows (ETW). De kan också genereras från systemloggar som registrerar händelser från delar av infrastrukturen, till exempel en webbserver. Textloggsmeddelanden utformas ofta för att vara läsbara för mänskliga ögat, men de bör också skrivas i ett format som gör det möjligt för automatiserade system att enkelt parsa dem.
Du bör också kategorisera loggar. Skriv inte alla spårningsdata till en enskild logg, utan registrera spårningsutdata från systemets olika driftaspekter med hjälp av separata loggar. Du kan då snabbt filtrera loggmeddelanden genom att läsa i respektive logg, istället för att behöva bearbeta en enda lång fil. Skriv aldrig information som har andra säkerhetskrav (som granskningsinformation och felsökningsdata) till samma logg.
Kommentar
En logg kan implementeras som en fil i filsystemet eller lagras i något annat format, till exempel som blob i bloblagring. Logginformation kan också lagras på ett mer strukturerat sätt, som rader i en tabell.
Mått är vanligtvis mått eller beräkningar från vissa aspekter eller resurser i systemet vid en viss tidpunkt, med en eller flera associerade taggar eller dimensioner (kallas i bland för ett prov). En enskild instans för ett mått är vanligtvis inte användbar på egen hand. Måtten måste i stället samlas över tid. Det är viktigt att tänka på vilka mått som du ska registrera och hur ofta. Om du genererar data för mått för ofta kan den extra belastningen på systemet bli avsevärd, medan du riskerar att gå miste om omständigheter som orsakar en betydande händelse om du läser in måtten för sällan. Övervägandena varierar från mått till mått. CPU-användning på en server kan exempelvis variera avsevärt från en sekund till en annan, men hög användning blir bara ett problem om det är långlivat i mer ett antal minuter.
Information för att korrelera data
Du kan enkelt övervaka enskilda prestandaräknare på systemnivå, hämta mått för resurser och hämta spårningsinformation för program från olika loggfiler. Vissa typer av övervakning kräver dock att analys- och diagnostiksteget i övervakningspipelinen korrelerar informationen som hämtats från flera källor. Dessa data kan ta sig olika former i dina rådata och analysprocessen måste anges med tillräckliga instrumentationsdata för att kunna mappa de olika formaten. På nivån för programmets ramverk kan exempelvis en uppgift identifieras av tråd-ID. I ett program kan samma jobb associeras med användar-ID:t för den användare som utför uppgiften.
Det är också osannolikt att 1:1-mappning används mellan trådar och användarbegäranden, eftersom asynkrona åtgärder kan återanvända samma trådar för att utföra åtgärder å en eller flera användares vägnar. För att göra saker och ting ytterligare lite mer komplicerade kan ett enskilt begärande hanteras av fler än en tråd, eftersom utförandet flödar i systemet. Om det är möjligt ska du associera ett begärande med ett unikt aktivitets-ID som sprids i systemet som en del av begärandets kontext. (Tekniken för att generera och inkludera aktivitets-ID:n i spårningsinformation beror på tekniken som används för att hämta spårningsdata.)
Alla övervakningsdata ska tidsstämplas på samma sätt. Du skapar konsekvens genom att registrera alla datum och tidpunkter med hjälp av Koordinerad universell tid. Detta hjälper dig att enkelt spåra händelsesekvenser.
Kommentar
Datorer i olika tidszoner och nätverk kan kanske inte synkroniseras. Var inte beroende av att använda enbart tidsstämplar för korrelering av instrumentationsdata som sträcker sig över flera datorer.
Information som ska ingå i instrumentationsdata
Ha följande punkter i åtanke när du bestämmer dig för vilka instrumentationsdata du behöver samla in:
Kontrollera att informationen som lästs in av spårningshändelser är läsbar för mänskliga ögat och datorer. Anta väldefinierade scheman för den här informationen för att underlätta den automatiserade bearbetningen av loggdata i de olika systemen och skapa konsekvens bland åtgärder och för den tekniska personalen som läser loggarna. Inkludera miljöinformation, som distributionsmiljö, vilken dator som ska köra processen, processinformation och anropsstack.
Aktivera profilering endast när det är nödvändigt, eftersom det kan det innebära stor belastning på systemet. Profilering med hjälp av instrumentation registrerar en händelse (till exempel ett metodanrop) varje gång en sådan uppstår, medan sampling endast registrerar utvalda händelser. Markeringen kan vara tidsbaserad (en gång var n sekund) eller frekvensbaserad (en gång var n begäranden). Om händelser inträffar ofta kan profilering med instrumentation orsaka för mycket belastning och påverka den totala prestandan. I sådana fall kan en samplingsmetod vara att föredra. Om frekvensen för händelser däremot är låg kan sampling gå miste om dem. I sådana fall kan instrumentation vara en bättre metod.
Genom att tillhandahålla tillräckligt med kontext blir det möjligt för en utvecklare eller administratör att avgöra källan för varje begärande. Det här kan innefatta en typ av aktivitets-ID som identifierar en viss instans för ett begärande. Det kan även innefatta information som kan användas för att korrelera aktiviteten med dataarbetet som utförs och de resurser som används. Observera att jobbet kan korsa process- och datorgränser. För mätning bör kontexten också innefatta (antingen direkt eller indirekt via annan korrelerad information) en referens till kunden som skickade begärandet. Den här kontexten ger värdefull information om programmets hälsa vid tillfället då dina övervakningsdata lästes in.
Registrera alla begäranden och de platser eller regioner där begärandena görs. Den här informationen kan bidra till att avgöra huruvida det finns några platsspecifika surfpunkter. Den här informationen kan också användas för att fastställa huruvida du vill partitionera om ett program eller de data som används.
Registrera och hämta noggrant information om undantag. Kritisk felsökningsinformation går ofta förlorad på grund av undermålig undantagshantering. Hämta fullständig information om undantag som programmet genererar, inklusive interna undantag och annan kontextinformation. Inkludera om möjligt anropsstacken.
Var konsekvent i de data som de olika elementen i programmet läser in, eftersom detta kan bidra till analyseringen av händelser och korrelera dem med användarbegäranden. Överväg att använda ett omfattande och konfigurerbart loggningspaket för att samla in information, istället för att förlita dig på att utvecklare ska anta samma metod när de implementerar olika delar av systemet. Samla in data från huvudsakliga prestandaräknare, som volymen för I/O-utförande, nätverksanvändning, antal begäranden, minnesanvändning och CPU-användning. Vissa infrastrukturtjänster kan ange sina egna specifika prestandaräknare, till exempel antalet anslutningar till en databas, den hastighet som transaktioner utförs med och antalet transaktioner som lyckas eller misslyckas. Program kan också definiera sina egna specifika prestandaräknare.
Logga alla anrop till externa tjänster, till exempel databassystem, webbtjänster eller andra tjänster på systemnivå som ingår i infrastrukturen. Registrera information om den tid det tar att utföra varje anrop och huruvida anropet lyckas eller misslyckas. Hämta möjligt in information om alla nya försök och fel för tillfälliga fel som uppstår.
Säkerställa kompatibilitet med telemetrisystem
Ofta genereras informationen som instrumentation producerar som en rad händelser och skickas till ett separat telemetrisystem för bearbetning och analys. Ett telemetrisystem är vanligtvis oberoende av specifika program eller teknik, men det förväntar sig att information följer ett visst format som vanligtvis definieras av ett schema. Schemat anger effektivt ett kontrakt som definierar datafältet och -typerna som telemetrisystemet kan mata in. Schemat måste vara generaliserat, så att data kan komma från flera olika plattformar och enheter.
Ett gemensamt schema ska innefatta fält som är gemensamma för alla instrumentationshändelser, till exempel händelsenamn, tidpunkt för händelsen, avsändarens IP-adress och den information som krävs för korrelering med andra händelser (som användar-ID, ett enhets-ID och ett program-ID). Kom ihåg att antalet enheter inte påverkar att händelser utlöses, så schemat bör inte bero på enhetstypen. Dessutom kan flera enheter utlösa händelser från samma program – programmet kan ha stöd för roaming eller andra format för distribuering mellan flera enheter.
Schemat kan också innehålla domänfält som är relevanta för ett visst scenario som är gemensamt för olika program. Detta kan vara information om undantag, programstart- och sluthändelser samt lyckade eller misslyckade API-anrop för webbtjänsten. Alla program som använder samma uppsättning domänfält ska generera samma uppsättning händelser, aktivera en uppsättning gemensamma rapporter och analyser som ska skapas.
Slutligen kan ett schema innehålla anpassade fält för att samla in information om programspecifika händelser.
Metodtips för instrumentering av program
I följande lista sammanställs metodtips för instrumentering av ett distribuerat program som körs i molnet.
Gör loggar lätta att läsa och enkla att parsa. Använd om möjligt strukturerad loggning. Var kort och beskrivande i loggmeddelanden.
Identifiera källan och tillhandahåll kontext och tidtagningsinformation i alla loggar när varje loggpost skrivs.
Använd samma tidszon och format för alla tidsstämplar. På så vis blir det enklare att korrelera händelser för åtgärder som sträcker sig över maskinvara och tjänster som körs på flera olika geografiska platser.
Kategorisera loggar och skriv meddelanden till lämplig loggfil.
Lämna inte ut känslig information om systemet eller personlig information om användare. Skrubba informationen innan den är inloggad, men se till att relevant information bevaras. Ta till exempel bort ID och lösenord från alla strängar för databasanslutning, men skriv återstående information till loggen, så att en analytiker kan avgöra om systemet har åtkomst till rätt databas. Logga alla kritiska undantag, men låt administratören aktivera eller inaktivera loggning för lägre nivåer av undantag och varningar. Hämta och logga också all logikinformation för omprövning. Dessa data kan vara användbara vid övervakning av systemets tillfälliga hälsotillstånd.
Spåra utanför processers anrop, till exempel begäranden till externa webbtjänster och databaser.
Blanda inte loggmeddelanden med olika säkerhetskrav i samma loggfil. Skriv till exempel inte felsöknings- och granskningsinformation till samma logg.
Med undantag för granskningshändelser ska du se till att alla loggningsanrop är ”fire-and-forget”-åtgärder som inte blockerar verksamhetsåtgärders utveckling. Granskningshändelser är undantag eftersom de är viktiga för verksamheten och kan klassificeras som en grundläggande del av verksamheten.
Se till att loggning kan utökas och inte har några direkta beroenden på ett konkret mål. Istället för att exempelvis skriva information med hjälp av System.Diagnostics.Trace definierar du ett abstrakt gränssnitt (som ILogger) som exponerar loggningsmetoder och kan implementeras via lämpliga medel.
Se till att all loggning är felsäker och aldrig utlöser övergripande fel. Loggning får inte utlösa undantag.
Hantera instrumentation som en pågående iterativ process och granska loggarna regelbundet, inte bara när det uppstår ett problem.
Samla in och lagra data
Insamlingsstegen för övervakningsprocessen är att hämta informationen som instrumentation genererar, formatera data så att det blir enklare för analys-/diagnossteget att förbruka och spara transformerade data i ett tillförlitligt lager. Instrumentationsdata som du samlar in från olika delar av ett distribuerat system kan lagras på olika platser och med olika format. Exempelvis kan din programkod generera spårningsloggfiler och loggdata för programhändelser medan prestandaräknare som övervakar viktiga aspekter av den infrastruktur som används i ditt program kan läsas in via andra tekniker. Alla komponenter och tjänster från tredjepart som ditt program använder kan tillhandahålla instrumentationsinformation i olika format med hjälp av separata spårningsfiler, bloblagring och även ett anpassad datalager.
Insamling av data utförs ofta genom en samling tjänster som kan köras fristående från det program som genererar instrumentationsdata. Bild 2 visar ett exempel på den här arkitekturen, med undersystemet för insamling av instrumentationsdata.
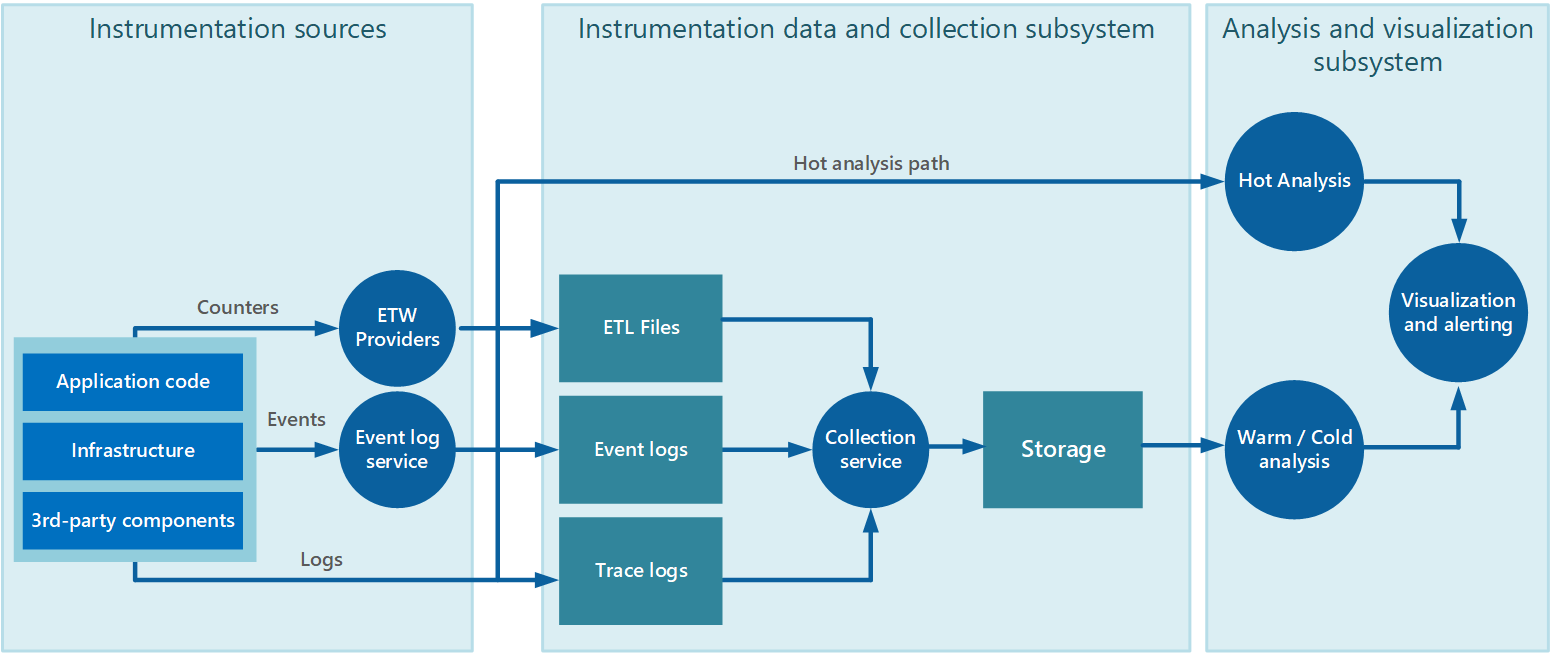
Bild 2 – Samla in instrumentationsdata.
Observera att detta är en förenklad vy. Samlingstjänsten är inte nödvändigtvis en enda process och kan omfatta många beståndsdelar som körs på olika datorer, så som beskrivs i följande avsnitt. Om analysen för vissa telemetridata dessutom måste genomföras snabbt (heta analyser, så som beskrivs i avsnitt Stöd för heta, varma och kalla analyser beskrivs senare i det här dokumentet) kan lokala komponenter som fungerar utanför insamlingstjänsten utföra analysuppgifter omedelbart. Bild 2 visar den här situationen för valda händelser. Efter analytisk behandling kan resultatet skickas direkt till undersystemet för visualisering och aviseringar. Data som är föremål för varm eller kall analys hålls kvar i lagring under tiden den väntar på bearbetning.
Azure-program och -tjänster innehåller en möjlig lösning för att samla in data i Azure Diagnostics. Azure Diagnostics samlar in data från följande källor för varje beräkningsnod, aggregerar och överför dem sedan till Azure Storage:
- IIS-loggar
- Det gick inte begära loggar i IIS
- Windows-händelseloggar
- Prestandaräknare
- Kraschdumpar
- Azure Diagnostics-infrastrukturloggar
- Anpassa felloggar
- .NET EventSource
- Manifestbaserad ETW
Mer information finns i artikeln om telemetrigrunderna och felsökning i Azure.
Strategier för insamling av instrumentationsdata
Med molnets elastiska egenskaper i åtanke och för att undvika att behöva hämta telemetridata manuellt från varje nod i systemet bör du ordna så att data överförs till en central plats och konsolideras. I ett system som omfattar flera datacenter kan det vara användbart att först samla in, konsolidera och lagra data utefter region och sedan aggregera regionala data till ett enda centralt system.
Du kan optimera användningen av bandbredd genom att välja att överföra mindre brådskande data i block, som batchar. Data får dock inte fördröjas på obestämd tid, särskilt inte om de innehåller tidskänslig information.
Hämta och skicka instrumentationsdata
Undersystemet för insamling av instrumentationsdata kan aktivt hämta instrumentationsdata från flera loggar och andra källor för varje instans av programmet (hämtningsmodellen). Det kan också fungera som en passiv mottagare som väntar på att data skickas från komponenterna som utgör vardera instans av programmet (skickamodellen).
En metod för att implementera skickamodellen är att använda övervakningsagenter som kör lokalt med varje instans av programmet. En övervakningsagent är en separat process som regelbundet hämtar telemetridata som samlats in på den lokala noden och skriver informationen direkt till centraliserad lagring som alla instanser av programmet delar. Det här är den mekanism som Azure Diagnostics implementerar. Varje instans av en webb- eller arbetsroll för Azure kan konfigureras att hämta diagnostik och annan spårningsinformation som lagras lokalt. Övervakningsagenten som körs medan varje instans kopierar angivna data till Azure Storage. Mer information om den här processen finns i artikeln om hur du aktiverar diagnostik i Azure Cloud Services och virtuella datorer. Vissa element, till exempel IIS-loggar, kraschdumpar och anpassade felloggar skrivs till bloblagring. Data från Windows-händelselogg, ETW-händelser och prestandaräknare registreras i tabellagring. På bild 3 visas följande mekanism.
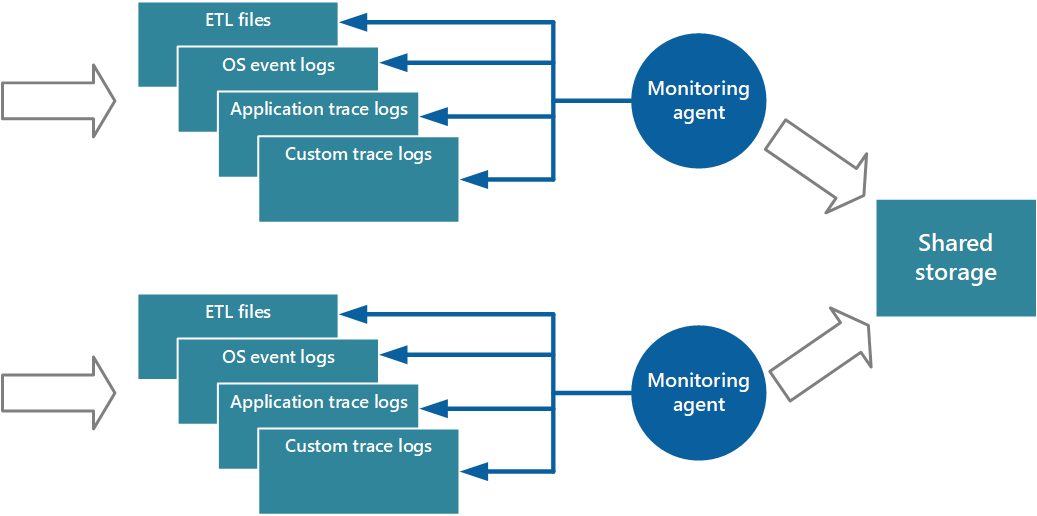
Bild 3 – Använda en övervakningsagent för att hämta information och skriva till delad lagring.
Kommentar
Användning av en övervakningsagent är helt anpassat för att läsa in instrumentationsdata som hämtas naturligt från en datakälla. Ett exempel är information från SQL Server med dynamiska hanteringsvyer eller längden på en Azure Service Bus-kö.
Det är möjligt att lagra telemetridata för ett småskaligt program som körs på ett begränsat antal noder på en enda plats med den metod som beskrivs. Ett komplext, högt skalbart, globalt molnprogram kan däremot generera stora mängder data från hundratals webb- och arbetsroller, databasshards och andra tjänster. Det här dataflödet kan enkelt överbelasta I/O-bandbredden som finns på en enskild central plats. Därför måste din telemetrilösning vara skalbar för att förhindra att den blir en flaskhals allteftersom systemet utökas. Helst bör din lösning omfatta en grad av redundans för att minska risken för att förlora viktig övervakningsinformation (till exempel gransknings- eller faktureringsdata) om en del av systemet skulle krascha.
Bemöt de här problemen genom att implementera köer, så som visas i bild 4. I den här arkitekturen publicerar den lokala övervakningsagenten (om den kan konfigureras korrekt) eller (om inte) den anpassade datainsamlingstjänsten data i en kö. En separat process som körs asynkront (tjänsten för att skriva till lager i bild 4) hämtar data i den här kön och skriver den till den delade lagringen. En meddelandekö är lämplig för det här scenariot eftersom det skapar ”minst en gång”-semantik som bidrar till att säkerställa att köade data inte går förlorade när de skickas. Du kan implementera tjänsten för att skriva till lager med hjälp av en separat arbetsroll.
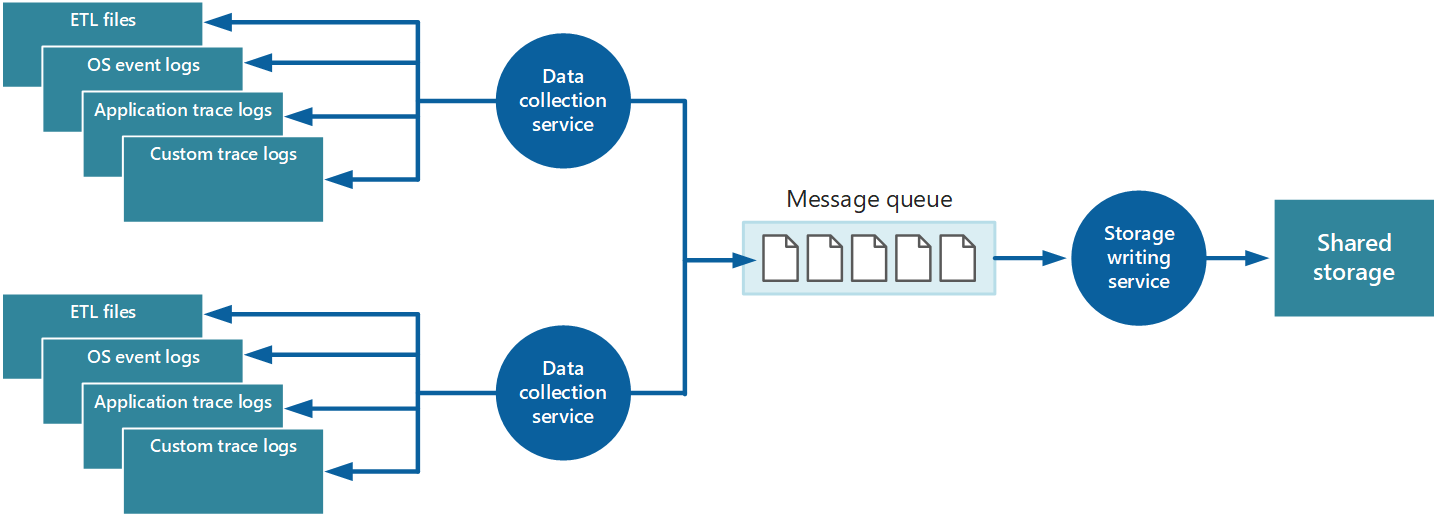
Bild 4 – Använda en kö för att buffra instrumentationsdata.
Tjänsten för lokal datainsamling kan lägga till data i en kö omedelbart efter att den har tagits emot. Kön fungerar som en buffert och tjänsten för att skriva till lager kan hämta och skriva data i sin egen takt. Som standard körs en kö på principen först in, först ut. Du kan dock prioritera meddelanden för att påskynda via kön om de innehåller data som måste hanteras snabbare. Mer information finns i mönstret Prioritetskö. Du kan också använda olika kanaler (till exempel Service Bus-ämnen) för att dirigera data till olika mål, beroende på vilket format som krävs för analytisk bearbetning.
För skalbarhet kan du köra flera instanser av tjänsten för att skriva till lager. Om det finns ett stort antal händelser kan du använda en händelsehubb för att skicka data till olika beräkningsresurser för bearbetning och lagring.
Konsolidera instrumentationsdata
De instrumentationsdata som tjänsten för datainsamling hämtar från en enda instans av ett program skapar en lokaliserad vy över den instansens hälsa och prestanda. Om du vill fastställa systemets övergripande hälsa är det nödvändigt att konsolidera vissa aspekter av de data som finns i de lokala vyerna. Det här kan du utföra efter att data har lagrats, men i vissa fall kan du också uppnå det under tiden som data samlas in. I stället för att skrivas direkt till en delad lagringsplats kan instrumentationsdata skickas via en separat tjänst för datakonsolidering som kombinerar data och fungerar som ett filter och en rensningsprocess. Till exempel kan instrumentationsdata som innehåller samma korrelationsinformation, exempelvis ett aktivitets-ID, slås samman. (Det är möjligt att en användare börjar utföra en affärsåtgärd på en nod och sedan överförs till en annan nod i händelse av nodfel, eller beroende på hur belastningsutjämning har konfigurerats.) Den här processen kan också identifiera och ta bort duplicerade data (alltid en möjlighet om telemetritjänsten använder meddelandeköer för att skicka ut instrumentationsdata till lagring). I bild 5 visas ett exempel på den här strukturen.
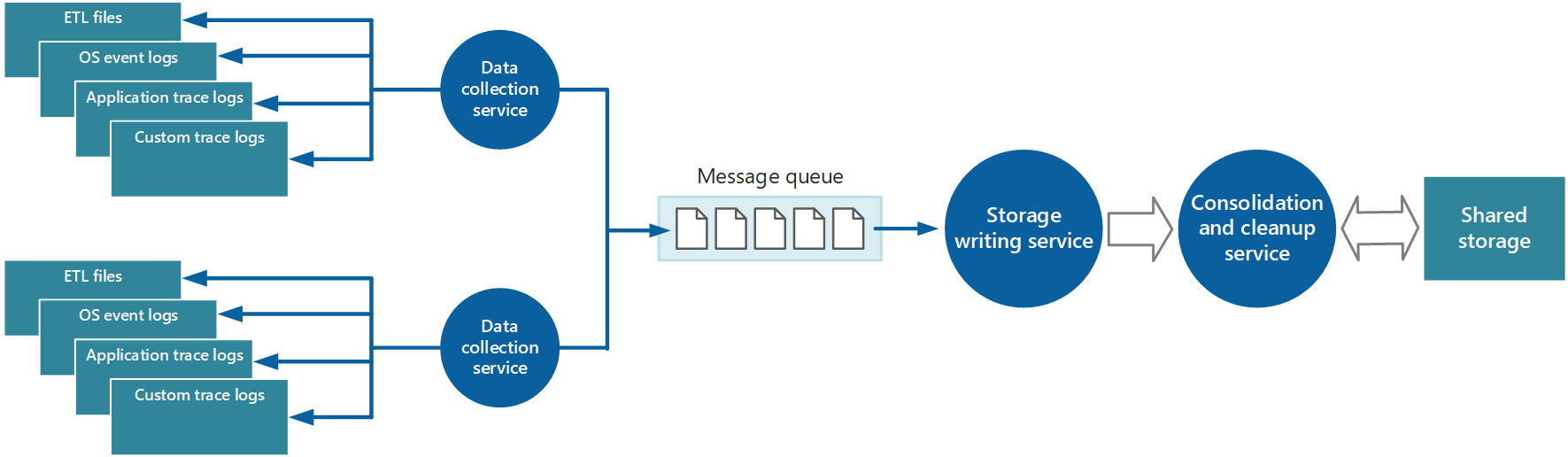
Bild 5 – Använda en separat tjänst för att konsolidera och rensa instrumentationsdata.
Lagra instrumentationsdata
Tidigare diskussioner har förmedlat en förenklad bild av hur instrumentationsdata lagras. I verkligheten kan det vara användbart att lagra de olika typerna av information med hjälp av tekniker som är mer anpassade till hur de olika typerna kommer att användas.
Till exempel finns det vissa likheter för åtkomst mellan Azure-blob och -tabellagring. De har dock begränsningar i vilka åtgärder som du kan utföra och kornigheten för dess data är ganska olik. Om du behöver utföra mer analytiska åtgärder eller kräver sökfunktioner för fullständig text på dina data kan det vara mer användbart att använda datalagring med funktioner som är optimerade för specifika typer av frågor och dataåtkomst. Till exempel:
- Prestandaräknardata kan lagras i en SQL-databas för att aktivera ad hoc-analyser.
- Spårningsloggar kan lagras bättre i Azure Cosmos DB.
- Säkerhetsinformation kan skrivas till HDFS.
- Information som kräver fullständig textsökning kan lagras via Elasticsearch (som också kan öka sökhastigheten med hjälp av omfattande indexering).
Du kan implementera ytterligare en tjänst som regelbundet hämtar data från en delad lagringsplats, partitionerar och filtrerar data utefter dess syfte och sedan skriver den till en lämplig uppsättning av datalager som visas i bild 6. En annan metod är att inkludera den här funktionen i konsoliderings- och rensningsprocessen och skriva data direkt till lagringsplatserna när de hämtas, istället för att spara dem i en mellanliggande delad lagringsplats. Varje metod har sina för- och nackdelar. Genom att implementera en separat partitioneringstjänst minskas belastningen på konsoliderings- och rensningstjänsten och gör det möjligt för åtminstone vissa av dina partitionerade data att återskapas vid behov (beroende på hur mycket data som lagrats på den delade lagringsplatsen). Detta förbrukar dock ytterligare resurser. Dessutom kan det vara en fördröjning mellan mottagandet av instrumentationsdata från varje programinstans och konverteringen av data till tillämplig information.
Bild 6 – Partitionera data enligt analys- och lagringskrav.
Samma instrumentationsdata kan krävas för flera ändamål. Prestandaräknare kan till exempel användas för att ge en historisk översikt över systemets prestanda över tid. Genom att kombinera den här informationen med andra användningsdata kan du generera kundens faktureringsinformation. I sådana situationer kan samma data skickas till flera mål, till exempel en dokumentdatabas som kan fungera som en långsiktig lagring av faktureringsinformation och en flerdimensionell lagring för hantering av komplexa prestandaanalyser.
Du bör också överväga hur snabbt dina data behövs. Data som innehåller information för aviseringar måste kunna nås snabbt. Därför ska de lagras i snabb datalagring samt indexerade eller strukturerade för att optimera de frågor som aviseringssystemet utfört. I vissa fall kan det vara nödvändigt för telemetritjänsten som samlar in data på varje nod att formatera och spara data lokalt, så att en lokal instans av aviseringssystemet snabbt kan meddela dig om eventuella problem. Samma data kan skickas till tjänsten för att skriva till lager, som visas i tidigare diagram, och lagras centralt om det krävs av andra orsaker.
Information som används för mer övervägda analyser, rapportering och för att upptäcka historiska trender är mindre brådskande och kan lagras på ett sätt som stödjer datautvinning och ad hoc-frågor. Mer information finns i avsnittet Stöd för heta, varma och kalla analyser senare i det här dokumentet.
Loggrotation och datakvarhållning
Instrumentation kan generera stora mängder data. Dessa data kan lagras på flera platser, från och med råa loggfiler, spårningsfiler och annan information som lästs in vid varje nod för konsoliderade, rensade och partitionerade vyer över data som lagras på delad lagringsplats. I vissa fall när data har bearbetats och överförts kan rå källdata tas bort från varje nod. I annat fall kan det vara nödvändigt eller helt enkelt praktiskt att spara den råa informationen. Till exempelvis kan det vara bättre att lämna data som genererats för felsökning i sitt råa format, och sedan snabbt tas bort efter att eventuella buggar har åtgärdats.
Prestandadata har ofta längre livslängd så att de kan användas för att upptäcka prestandatrender och kapacitetsplanering. Samlad vy över dessa data lagras vanligtvis online under en begränsad period för snabb åtkomst. Efteråt kan den arkiveras eller tas bort. Data som samlas in för mätning och fakturering av kunder kan behöva sparas på obestämd tid. Dessutom kan lagstiftning bestämma att information som hämtats i gransknings- och säkerhetssyfte och måste arkiveras och sparas. Dessa data är också känsliga och kan behöva krypteras och skyddas på annat sätt för att förhindra manipulation. Du ska aldrig registrera användares lösenord eller annan information som kan användas för identitetsbedrägerier. Sådan information ska rensas från dessa data innan de lagras.
Nedåtsampling
Det är användbart att lagra historiska data så att du kan upptäcka långvariga trender. I stället för att spara gamla data i sin helhet kan det vara möjligt att minska upplösningen och spara lagringskostnader genom att nedåtsampla data. Istället för att exempelvis spara prestandaindikatorer minut för minut kan du konsolidera data som är äldre än en månad och skapa en vy timme för timme.
Metodtips för att samla in och lagra loggningsinformation
I följande lista sammanfattas metodtips för insamling och lagring av loggningsinformation:
Övervakningsagenten eller tjänsten för datainsamling ska köras som en tjänst utanför processen och bör vara enkel att distribuera.
Alla utdata från övervakningsagenten eller tjänsten för datainsamling bör ha ett format som är oberoende av dator, operativsystem och nätverksprotokoll. Till exempel generera information i ett självbeskrivande format, som JSON, MessagePack eller Protobuf istället för ETL/ETW. Genom att använda ett standardformat är det möjligt för systemet att konstruera processpipelines – komponenter som läser, transformerar och skickar data i det överenskomna formatet kan enkelt integreras.
Processen för övervakning och insamling av data måste vara felsäker och får inte utlösa sammanhängande felvillkor.
Om ett tillfälligt fel i uppstår när information ska skickas till en dataplats ska övervakningsagenten eller tjänsten för datainsamling förberedas till att ändra ordningen på telemetridata, så att den senaste information skickas först. (Övervakningsagenten/tjänsten för datainsamling kan utses att ta bort äldre data eller spara lokalt och överföra dem senare för att komma ifatt, efter eget gottfinnande.)
Analysera data och diagnostisera problem
En viktig del av övervaknings- och diagnostikprocessen är att analysera den insamlade informationen för att få en bild av systemets övergripande hälsa. Du bör har definierat dina egna KPI:er och prestandamått och det är viktigt att förstå hur du kan strukturera de data som har samlats in för att uppfylla analyskraven. Det är också viktigt att förstå hur data som hämtas i olika mått och loggfiler korreleras, eftersom den här informationen kan vara viktig för att spåra en händelsesekvens och diagnostisera problem som uppstår.
Så som beskrivs i avsnittet Konsolidera instrumentationsdata hämtas data för varje del av systemet vanligtvis lokalt, men behöver generellt kombineras med data som genererats på andra sidor som deltar i systemet. Den här informationen kräver noggrann korrelation så att data kombineras korrekt. Användningsdata för en åtgärd kan exempelvis omfatta en nod som är värd för en webbplats som en användare ansluter till, en nod som kör en separat tjänst som en del av den här åtgärden och datalagring på en annan nod. Den här informationen måste vara sammanlänkande för att kunna ge en övergripande vy av åtgärdens resurs- och användningsdata. Viss förbearbetning och filtrering av data kan ske på noden där data samlas in, medan aggregering och formatering är mer benägna att ske på en central nod.
Stöd för heta, varma och kalla analyser
Analysera och formatera om data för visualiserings-, rapporterings- och aviseringsändamål kan vara en komplicerad process som använder en egen uppsättning resurser. Vissa typer av övervakning är brådskande och kräver omedelbar dataanalys för att vara effektiv. Detta kallas het analys. Det inkluderar exempelvis analyser som krävs för aviseringar och vissa aspekter av säkerhetsövervakning (som att upptäcka en attack på systemet). Data som krävs för de här ändamålen måste vara tillgängliga snabbt och strukturerade för effektiv bearbetning. I vissa fall kan det vara nödvändigt att flytta analysbearbetningen till de enskilda noderna där data lagras.
Andra former av analys är mindre brådskande och kan kräva viss beräkning och sammansättning efter att rådata har tagits emot. Detta kallas varm analys. Prestandaanalys hamnar ofta i den här kategorin. I det här fallet är det inte troligt att en isolerad, enskild prestandahändelse är statistiskt betydande. (Det kan bero på en plötslig topp eller ett plötsligt fel.) Data från en serie händelser bör ge en mer tillförlitlig bild av systemets prestanda.
Varm analys kan också användas för att diagnostisera problem. En hälsohändelse bearbetas vanligtvis via het analys och kan utlösa en avisering omedelbart. En operatör ska kunna ta reda på anledningarna till hälsohändelsen genom att kontrollera data från den varma sökvägen. Dessa data ska innehålla information om händelserna som orsakade problemet som utlöste hälsohändelsen.
Vissa typer av övervakning genererar mer långsiktiga data. Den här analysen kan utföras vid ett senare tillfälle, möjligen enligt ett fördefinierat schema. I vissa fall kan analysen behöva utföra komplex filtrering av stora mängder data som hämtats under en viss tidsperiod. Detta kallas kall analys. Ett nyckelkrav är att data lagras på ett säkert sätt när de har hämtats. Användarövervakning och -granskning kräver korrekt återgivning av systemets tillstånd vid regelbundna tidpunkter, men den här tillståndsinformationen behöver inte vara tillgänglig för bearbetning direkt efter att den lästs in.
En operatör kan också tillhandahålla data för förutsägande hälsoanalys genom att använda kall analys. Operatören kan samla in historisk information över en angiven period och använda den tillsammans med aktuell hälsoinformation (hämtad från den heta sökvägen) och upptäcka trender som kan vara orsaken till hälsoproblemet. I sådana fall kan det vara nödvändigt att utlösa en avisering, så att åtgärder kan vidtas.
Korrelera data
De data som instrumentation hämtar kan ge en ögonblicksbild av systemets tillstånd, men syftet med analyser är att göra data tillämpliga. Till exempel:
- Vad orsakade intensiv I/O-belastning på systemnivå vid en viss tid?
- Är ett stort antal databasåtgärder orsaken?
- Speglas det här i databasens svarstider, antalet transaktioner per sekund och programmets svarstider vid samma föreningspunkt?
I sådana fall kan en åtgärd som kan minska belastningen vara att dela upp data mellan flera servrar. Dessutom kan undantag uppstå på grund av ett fel på en nivå i systemet. Ett undantag på en nivå utlöser ofta ett annat fel på nivån ovan.
Därför måste du kunna korrelera de olika typerna av övervakningsdata på varje nivå, så att du får en övergripande vy av systemets tillstånd och programmen som körs. Du kan använda den här informationen för avgöra huruvida systemet fungerar bra eller inte samt ta reda på vad som kan göras för att förbättra kvaliteten på systemet.
Så som beskrivs i avsnittet Information korrelering av data måste du säkerställa att rå instrumentationsdata innefattar tillräckligt med information om kontext och aktivitets-ID som stöd för de korrelerade händelsernas obligatoriska sammansättningar. Dessa data kan dessutom lagras i olika format och det kan vara nödvändigt att parsa informationen för att konvertera den till ett standardformat för analyser.
Felsökning och diagnostisera problem
Diagnos kräver att det går att avgöra orsaken till det oväntade beteendet, inklusive att utföra en rotorsaksanalys. Information som vanligtvis krävs inkluderar:
- Utförlig information från händelseloggar och spårningar, antingen för hela systemet eller för ett specifikt undersystem under ett angivet tidsintervall.
- Slutför stackspår som uppstår på grund av undantag och fel på någon angiven nivå inuti systemet eller i ett specifikt undersystem under en angiven period.
- Kraschdumpar för alla misslyckade processer antingen var som helst i systemet eller för ett angivet undersystem under ett angivet tidsintervall.
- Aktivitetsloggar som registrerar åtgärderna som utförs av antingen alla användare eller för utvalda användare under en angiven period.
Att analysera data för felsökningssyften kräver ofta djup teknisk förståelse för systemets arkitektur och de olika komponenterna som utgör lösningen. Därför krävs ofta en hög nivå av manuella åtgärder för att tolka data, fastställa orsaken till problemen och rekommendera en lämplig åtgärdsstrategi. Det kan vara bra att spara en kopia av den här informationen i sitt ursprungliga format och göra den tillgänglig för kall analys av en expert.
Visualisera data och utlösa aviseringar
En viktig del av alla övervakningssystem är möjligheten att presentera data så att en operatör snabbt kan upptäcka trender eller problem. Möjlighet att snabbt kunna informera en operatör när en betydande händelse som kan kräva åtgärder inträffar är också betydande.
Datapresentation kan ha flera former, inklusive visualisering med hjälp av instrumentpaneler, aviseringar och rapportering.
Visualisering med hjälp av instrumentpaneler
Det vanligaste sättet att visualisera data är att använda instrumentpaneler som kan visa information som en serie diagram, tabeller och eller någon annan bild. Objekten kan parameteriseras och en analytiker ska kunna välja viktiga parametrar (t.ex tidsperiod) för en specifik situation.
Instrumentpaneler kan ordnas hierarkiskt. Översta instrumentpanelerna kan ge en övergripande vy av varje aspekt av systemet, men gör det möjligt för en operatör att öka informationens detaljnivå. En instrumentpanel som förmedlar övergripande disk-I/O för systemet bör exempelvis tillåta att en analytiker visar I/O-hastighet för varje enskild disk för att säkerställa huruvida en eller flera specifika enheter svarar för en oproportionerlig mängd eller trafik. Helst ska instrumentpanelen också visa relaterad information, till exempel källan för varje begärande (användare eller aktivitet) som genererar den här I/O. Den här informationen kan sedan användas till att avgöra huruvida (och hur) belastning ska spridas ut jämnare över enheten, och huruvida systemet kan prestera bättre om fler enheter läggs till.
En instrumentpanel kan också använda färgkodning eller andra visuella tips som anger värden som verkar vara avvikande eller som är utanför ett förväntat intervall. Från föregående exempel:
- En disk med en I/O-hastighet som närmar sig sin maximala kapacitet under en längre tid (en het disk) kan markeras i rött.
- En disk med en I/O-hastighet som körs regelbundet på sin maxgräns under korta perioder (en varm disk) kan markeras i gult.
- En disk som visar normal användning kan visas i grönt.
Observera att för ett instrumentpanelssystem ska fungera effektivt måste det ha rådata att arbeta med. Om du skapar ett eget instrumentpanelssystem eller använder en instrumentpanel som utvecklats av någon annan organisation ska du vara medveten om vilka instrumentationsdata du behöver hämta, vid vilka kornighetsnivåer och hur de bör formateras så att instrumentpanelen kan förbruka dem.
En bra instrumentpanel visar inte bara information, utan tillåter också att analytiker ställer ad hoc-frågor om informationen. Vissa system har hanteringsverktyg som en operatör kan utföra de här uppgifterna och utforska underliggande data med. Beroende på vilken lagringsplats som används till att lagra information kan det också vara möjligt att skicka frågedata direkt eller importera dem till verktygen som Microsoft Excel-ark för ytterligare analys och rapportering.
Kommentar
Du bör begränsa åtkomsten till instrumentpanelen till auktoriserad personal, eftersom den här informationen kan vara kommersiellt känslig. Du bör också skydda underliggande data för instrumentpaneler, så att användare inte kan ändra dem.
Skicka aviseringar
Aviseringar är analyseringsprocessen för övervakning och instrumentationsdata samt generering av aviseringar om en betydande händelse upptäcks.
Med hjälp av aviseringar kan du säkerställa att systemet förblir felfritt, dynamiskt och säkert. En viktig del av ett system är att garantera användarna prestanda, tillgänglighet och sekretess då data kan behöva aktiveras omedelbart. En operatör kan behöva meddelas om händelsen som utlöste aviseringen. Aviseringar kan också användas till att anropa systemfunktioner, till exempel autoskalning.
Aviseringar beror vanligtvis på följande instrumentationsdata:
- Säkerhetshändelser. Om händelseloggarna anger att upprepade autentiserings- eller auktoriseringsfel inträffar kan systemet vara under attack och en operatör bör informeras.
- Prestandamått. Systemet måste snabbt svara om ett visst prestandamått överskrider ett angivet tröskelvärde.
- Tillgänglighetsinformation. Om ett fel upptäcks kan det vara nödvändigt att snabbt starta om ett eller flera undersystem eller växla till en säkerhetskopieringsresurs. Upprepade fel i ett undersystem kan betyda att allvarligare fel finns.
Operatörer kan ta emot aviseringsinformation via flera leveranskanaler, till exempel e-postmeddelande, sökarenhet eller ett SMS. En avisering kan också inkludera en indikation på hur allvarlig en situation är. Många aviseringssystem har stöd för prenumerationsgrupper och alla operatörer som är medlemmar i samma grupp kan få samma uppsättning aviseringar.
Ett aviseringssystem ska anpassas och lämpliga värden från underliggande instrumentationsdata kan anges som parametrar. Med den här metoden kan en operatör filtrera data och fokusera på de tröskelvärden eller kombinationsvärden som är av intresse. Observera att i vissa fall kan råa instrumentationsdata skickas till aviseringssystemet. I vissa situationer kan det vara mer effektivt att ange aggregerade data. (Till exempel kan en avisering aktiveras om processoranvändningen för en nod har överskridit 90 procent under de senaste 10 minuterna). Informationen i aviseringssystemet bör innefatta all nödvändig information om sammanfattning och kontext. Dessa data kan minska risken för att falsk-positiva händelser utlöser en avisering.
Rapportering
Rapportering används till att generera en översiktlig vy av systemet. Förutom den aktuella informationen kan detta innefatta historiska data. Själva rapporteringskraven är indelade i två kategorier: driftsrapportering och säkerhetsrapportering.
Driftsrapportering omfattar vanligtvis följande aspekter:
- Aggregera statistik som du kan använda för att förstå resursanvändningen för det övergripande systemet eller angivna undersystem under en angiven tidsperiod.
- Identifiera trender i resursanvändningen för det övergripande systemet eller angivna undersystem under en angiven period.
- Övervaka de undantag som har inträffat i hela systemet eller i angivna undersystem under en angiven period.
- Fastställa programmets effektivitet när det gäller distribuerade resurser och förstå om mängden resurser (och deras associerade kostnad) kan minskas utan att prestandan påverkas i onödan.
Säkerhetsrapportering innebär spårning av kundens systemanvändning. Det kan omfatta:
- Granska användaråtgärder. Det här kräver att enskilda begäranden som vardera användare utför registreras tillsammans med datum och tid. Data bör struktureras så att en administratör snabbt kan återskapa åtgärdssekvenser som användare utför under en angiven period.
- Spåra resursanvändning av användare. Det är obligatoriskt att registrera hur ett begärande om en användare använder de olika resurserna som utgör systemet och hur länge. En administratör måste kunna använda dessa data till att generera en användarrapport under en angiven period, möjligtvis för faktureringssyften.
Ofta kan batchprocesser generera rapporter enligt ett definierat schema. (Svarstiden är normalt inte ett problem.) Men de bör också vara tillgängliga för generering på ad hoc-basis om det behövs. Om du exempelvis lagrar data i en relationsdatabas, som Azure SQL Database, kan du extrahera och formatera data samt presentera dem som en uppsättning rapporter med hjälp av ett verktyg som SQL Server Reporting Services.
Nästa steg
- Översikt över Azure Monitor
- Övervaka, diagnostisera och felsöka Microsoft Azure Storage
- Översikt över aviseringar i Microsoft Azure
- Visa aviseringar om hälsotillståndet för tjänsten med hjälp av Azure Portal
- Vad är Application Insights?
- Prestandadiagnostik för virtuella Azure-datorer
- Ladda ned och installera SQL Server Data Tools (SSDT) för Visual Studio
Relaterade resurser
- I Autoscaling guidance (Vägledning för automatisk skalning) beskrivs hur du minskar hanteringen av merarbete genom att minska behovet av att en operatör regelbundet övervakar systemets prestanda och tar beslut om att lägga till eller ta bort resurser.
- Hälsoslutpunktsövervakningsmönster beskriver hur du implementerar funktionella kontroller i ett program som externa verktyg kan komma åt via exponerade slutpunkter med jämna mellanrum.
- Mönster för prioritetskö visar hur du prioriterar köade meddelanden så att brådskande begäranden tas emot och kan bearbetas före mindre brådskande meddelanden.