Detta klientprojekt hjälpte ett Fortune 500-livsmedelsföretag att förbättra sina efterfrågeprognoser. Företaget levererar produkter direkt till flera butiker. Förbättringen hjälpte dem att optimera lagerhållningen av sina produkter i olika butiker i flera regioner i USA. För att uppnå detta arbetade Microsofts CSE-team (Commercial Software Engineering) med klientens dataforskare i en pilotstudie för att utveckla anpassade maskininlärningsmodeller för de valda regionerna. Modellerna tar hänsyn till:
- Kunddemografi
- Historiskt och prognostiserat väder
- Tidigare leveranser
- Produktreturer
- Särskilda händelser
Målet att optimera lagerhållningen utgjorde en viktig komponent i projektet och klienten realiserade ett betydande försäljningslyft i de tidiga fältförsöken. Teamet såg också en 40-procentig minskning av prognostisering av genomsnittligt absolut procentfel (MAPE) jämfört med en historisk genomsnittlig baslinjemodell.
En viktig del av projektet var att ta reda på hur man skalar upp arbetsflödet för datavetenskap från pilotstudien till produktionsnivå. Det här arbetsflödet på produktionsnivå krävde att CSE-teamet:
- Utveckla modeller för många regioner.
- Uppdatera och övervaka modellernas prestanda kontinuerligt.
- Underlätta samarbetet mellan data- och teknikteamen.
Det typiska arbetsflödet för datavetenskap är i dag närmare en engångslabbmiljö än ett produktionsarbetsflöde. En miljö för dataforskare måste vara lämplig för dem att:
- Förbered data.
- Experimentera med olika modeller.
- Justera hyperparametrar.
- Skapa en build-test-evaluate-refine-cykel.
De flesta verktyg som används för dessa uppgifter har specifika syften och är inte väl lämpade för automatisering. I en maskininlärningsåtgärd på produktionsnivå måste du tänka mer på programlivscykelhantering och DevOps.
CSE-teamet hjälpte klienten att skala upp åtgärden till produktionsnivåer. De implementerade olika aspekter av ci/CD-funktioner (kontinuerlig integrering och kontinuerlig leverans) och tog upp problem som observerbarhet och integrering med Azure-funktioner. Under implementeringen upptäckte teamet luckor i befintlig MLOps-vägledning. Dessa luckor behövde fyllas så att MLOps förstods bättre och tillämpades i stor skala.
Genom att förstå MLOps-metoder kan organisationer se till att de maskininlärningsmodeller som systemet producerar är produktionskvalitetsmodeller som förbättrar affärsprestanda. När MLOps implementeras behöver organisationen inte längre ägna så mycket av sin tid åt lågnivåinformation som rör infrastruktur- och ingenjörsarbete som krävs för att utveckla och köra maskininlärningsmodeller för drift på produktionsnivå. Implementering av MLOps hjälper även datavetenskaps- och programvaruteknikgrupperna att lära sig att arbeta tillsammans för att leverera ett produktionsklart system.
CSE-teamet använde det här projektet för att hantera maskininlärningscommunityns behov genom att ta itu med problem som att utveckla en MLOps-mognadsmodell. Dessa ansträngningar syftade till att förbättra MLOps-implementeringen genom att förstå de typiska utmaningarna för nyckelaktörerna i MLOps-processen.
Engagemang och tekniska scenarier
I scenariot med engagemang diskuteras de verkliga utmaningar som CSE-teamet måste lösa. Det tekniska scenariot definierar kraven för att skapa en MLOps-livscykel som är lika tillförlitlig som den väletablerade DevOps-livscykeln.
Scenario för engagemang
Kunden levererar produkter direkt till försäljningsställen enligt ett regelbundet schema. Varje försäljningsställe varierar i sina produktanvändningsmönster, så produktinventeringen måste variera i varje veckoleverans. Att maximera försäljningen och minimera produktreturen och förlorade försäljningsmöjligheter är målen med de metoder för efterfrågeprognoser som klienten använder. Det här projektet fokuserade på att använda maskininlärning för att förbättra prognoserna.
CSE-teamet delade upp projektet i två faser. Fas 1 fokuserade på att utveckla maskininlärningsmodeller för att stödja en fältbaserad pilotstudie om effektiviteten i maskininlärningsprognoser för en vald försäljningsregion. Framgången med fas 1 ledde till fas 2, där teamet skalade upp den första pilotstudien från en minimal grupp modeller som stödde en enda geografisk region till en uppsättning hållbara modeller på produktionsnivå för alla kundens försäljningsregioner. Ett primärt övervägande för den uppskalade lösningen var behovet av att hantera det stora antalet geografiska regioner och deras lokala butiker. Teamet dedikerade maskininlärningsmodellerna till både stora och små butiker i varje region.
Fas 1-pilotstudien fastställde att en modell som är dedikerad till en regions butiker kunde använda lokal försäljningshistorik, lokal demografi, väder och speciella händelser för att optimera efterfrågeprognosen för butikerna i regionen. Fyra modeller för prognostisering av ensemblemaskininlärning betjänade marknadsplatser i en enda region. Modellerna bearbetade data i veckobatch. Dessutom utvecklade teamet två baslinjemodeller med historiska data för jämförelse.
För den första versionen av den uppskalade fas 2-lösningen valde CSE-teamet 14 geografiska regioner att delta, inklusive små och stora marknadsplatser. De använde mer än 50 maskininlärningsprognosmodeller. Teamet förväntade sig ytterligare systemtillväxt och fortsatt förfining av maskininlärningsmodellerna. Det blev snabbt tydligt att den här storskaliga maskininlärningslösningen endast är hållbar om den baseras på principerna för bästa praxis i DevOps för maskininlärningsmiljön.
| Environment | Marknadsregion | Format | Modeller | Underindelning av modell | Modellbeskrivning |
|---|---|---|---|---|---|
| Utvecklingsmiljö | Varje geografisk marknad/region (till exempel norra Texas) | Stora formatbutiker (stormarknader, stora boxbutiker och så vidare) | Två ensemblemodeller | Produkter i långsam rörelse | Både långsamt och snabbt har en ensemble med en linjär regressionsmodell (LASSO) med minst absolut krympning och markeringsoperator och ett neuralt nätverk med kategoriska inbäddningar |
| Snabbrörliga produkter | Både långsamt och snabbt har en ensemble av en linjär LASSO-regressionsmodell och ett neuralt nätverk med kategoriska inbäddningar | ||||
| En ensemblemodell | Ej tillämpligt | Historiskt genomsnitt | |||
| Små formatbutiker (apotek, närbutiker och så vidare) | Två ensemblemodeller | Produkter i långsam rörelse | Både långsamt och snabbt har en ensemble av en linjär LASSO-regressionsmodell och ett neuralt nätverk med kategoriska inbäddningar | ||
| Snabbrörliga produkter | Långsam och båda har en ensemble av en LASSO linjär regressionsmodell och ett neuralt nätverk med kategoriska inbäddningar | ||||
| En ensemblemodell | Ej tillämpligt | Historiskt genomsnitt | |||
| Samma som ovan för ytterligare 13 geografiska regioner | |||||
| Samma som ovan för prod-miljön |
MLOps-processen tillhandahöll ett ramverk för det uppskalade systemet som hanterade hela livscykeln för maskininlärningsmodellerna. Ramverket omfattar utveckling, testning, distribution, drift och övervakning. Den uppfyller behoven i en klassisk CI/CD-process. Men på grund av dess relativa omognad jämfört med DevOps blev det uppenbart att befintlig MLOps-vägledning hade luckor. Projektteamet arbetade för att fylla i några av dessa luckor. De ville tillhandahålla en funktionell processmodell som försäkrar livskraften hos den uppskalade maskininlärningslösningen.
MLOps-processen som utvecklades från det här projektet gjorde ett betydande verkligt steg för att flytta MLOps till en högre mognadsnivå och livskraft. Den nya processen är direkt tillämplig på andra maskininlärningsprojekt. CSE-teamet använde det de lärde sig för att skapa ett utkast till en MLOps-mognadsmodell som vem som helst kan tillämpa på andra maskininlärningsprojekt.
Tekniskt scenario
MLOps, även kallat DevOps för maskininlärning, är en paraplyterm som omfattar filosofier, metoder och tekniker som är relaterade till implementering av maskininlärningslivscykler i en produktionsmiljö. Det är fortfarande ett relativt nytt koncept. Det har gjorts många försök att definiera vad MLOps är och många har ifrågasatt om MLOps kan undersumma allt från hur dataexperter förbereder data till hur de i slutändan levererar, övervakar och utvärderar maskininlärningsresultat. DevOps har haft flera år på sig att utveckla en uppsättning grundläggande metoder, men MLOps är fortfarande tidigt i sin utveckling. I takt med att den utvecklas upptäcker vi utmaningarna med att sammanföra två discipliner som ofta fungerar med olika kompetensuppsättningar och prioriteringar: programvaru-/ops-teknik och datavetenskap.
Implementering av MLOps i verkliga produktionsmiljöer har unika utmaningar som måste övervinnas. Teams kan använda Azure för att stödja MLOps-mönster. Azure kan också ge klienter tillgångshantering och orkestreringstjänster för att effektivt hantera maskininlärningslivscykeln. Azure-tjänster är grunden för MLOps-lösningen som vi beskriver i den här artikeln.
Krav för maskininlärningsmodell
Mycket av arbetet under fas 1-pilotfältstudien var att skapa de maskininlärningsmodeller som CSE-teamet tillämpade på de stora och små butikerna i en enda region. Viktiga krav för modellerna inkluderade:
Användning av Azure Mašinsko učenje-tjänsten.
Inledande experimentella modeller som har utvecklats i Jupyter Notebooks och implementerats i Python.
Kommentar
Teams använde samma metod för maskininlärning för stora och små butiker, men tränings- och bedömningsdata berodde på butikens storlek.
Data som kräver förberedelse för modellförbrukning.
Data som bearbetas på batchbasis i stället för i realtid.
Omträning av modell när kod eller data ändras, eller om modellen blir inaktuell.
Visning av modellprestanda i Power BI-instrumentpaneler.
Modellprestanda vid bedömning som anses vara betydande när MAPE <= 45 % jämfört med en historisk genomsnittlig baslinjemodell.
MLOps-krav
Teamet var tvunget att uppfylla flera viktiga krav för att skala upp lösningen från fas 1-pilotfältstudien, där endast ett fåtal modeller utvecklades för en enda försäljningsregion. Fas 2 implementerade anpassade maskininlärningsmodeller för flera regioner. Implementeringen omfattade:
Veckovis batchbearbetning för stora och små butiker i varje region för att träna om modellerna med nya datauppsättningar.
Kontinuerlig förfining av maskininlärningsmodellerna.
Integrering av processen development/test/package/test/deploy som är gemensam för CI/CD i en DevOps-liknande bearbetningsmiljö för MLOps.
Kommentar
Detta representerar en förändring i hur dataforskare och datatekniker ofta har arbetat tidigare.
En unik modell som representerar varje region för stora och små butiker baserat på butikshistorik, demografi och andra viktiga variabler. Modellen var tvungen att bearbeta hela datamängden för att minimera risken för bearbetningsfel.
Möjligheten att först skala upp för att stödja 14 försäljningsregioner med planer på att skala upp ytterligare.
Planer för ytterligare modeller för långsiktig prognostisering för regioner och andra butikskluster.
Lösning för maskininlärningsmodell
Livscykeln för maskininlärning, även kallad datavetenskapens livscykel, passar ungefär in i följande processflöde på hög nivå:
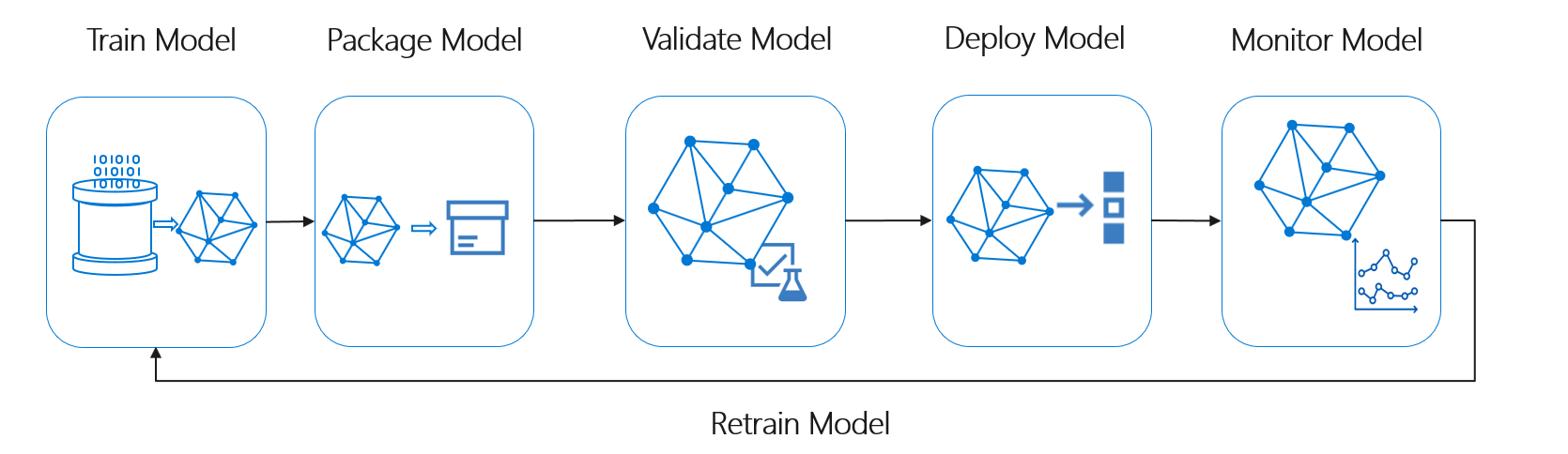
Distribuera modell här kan representera all operativ användning av den verifierade maskininlärningsmodellen. Jämfört med DevOps innebär MLOps den ytterligare utmaningen att integrera maskininlärningslivscykeln i den typiska CI/CD-processen.
Livscykeln för datavetenskap följer inte den typiska livscykeln för programvaruutveckling. Den omfattar användning av Azure Mašinsko učenje för att träna och poängsätta modellerna, så de här stegen måste ingå i CI/CD-automatiseringen.
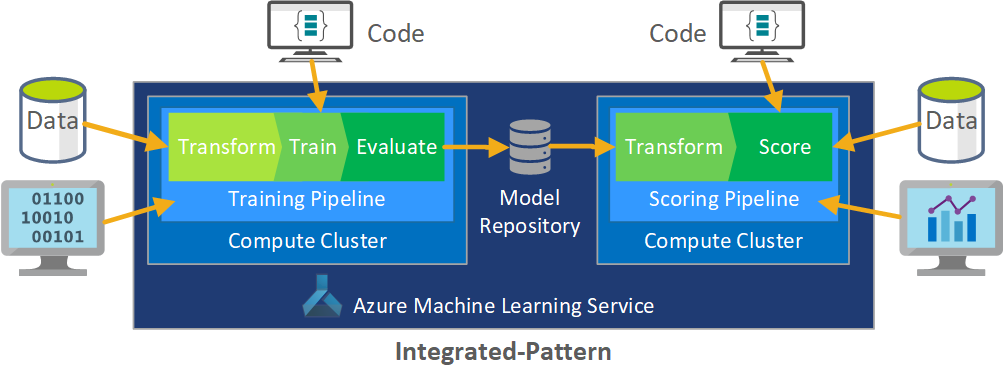
Batchbearbetning av data är grunden för arkitekturen. Två Azure Mašinsko učenje-pipelines är centrala i processen, en för träning och den andra för bedömning. Det här diagrammet visar den datavetenskapsmetodik som användes för den inledande fasen av klientprojektet:
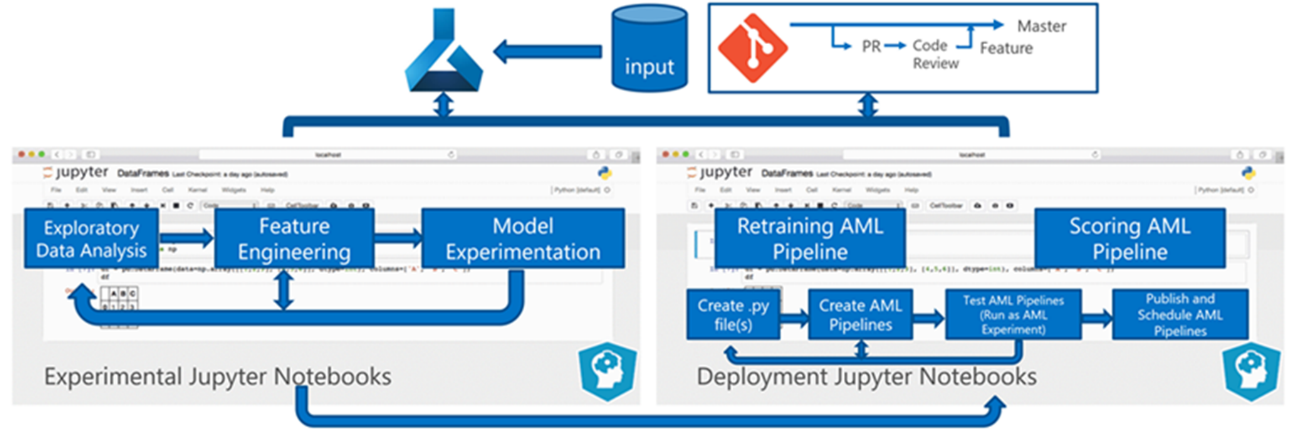
Teamet testade flera algoritmer. De valde slutligen en ensembledesign av en LASSO linjär regressionsmodell och ett neuralt nätverk med kategoriska inbäddningar. Teamet använde samma modell, definierad av produktnivån som klienten kunde lagra på plats, för både stora och små butiker. Teamet delade vidare in modellen i snabbrörliga och långsamma produkter.
Dataexperterna tränar maskininlärningsmodellerna när teamet släpper ny kod och när nya data är tillgängliga. Träningen sker vanligtvis varje vecka. Därför omfattar varje bearbetningskörning en stor mängd data. Eftersom teamet samlar in data från många källor i olika format kräver det konditionering för att placera data i ett förbrukningsbart format innan dataexperterna kan bearbeta dem. Datakonditioneringen kräver betydande manuell ansträngning och CSE-teamet identifierade den som en primär kandidat för automatisering.
Som nämnts utvecklade och tillämpade dataexperterna de experimentella Azure Mašinsko učenje-modellerna på en enda försäljningsregion i pilotfältstudien fas 1 för att utvärdera nyttan av den här prognosmetoden. CSE-teamet bedömde att försäljningslyftet för butikerna i pilotstudien var betydande. Denna framgång motiverade att lösningen tillämpades på fullständiga produktionsnivåer i fas 2, med början i 14 geografiska regioner och tusentals butiker. Teamet kan sedan använda samma mönster för att lägga till ytterligare regioner.
Pilotmodellen fungerade som grund för den uppskalade lösningen, men CSE-teamet visste att modellen behövde ytterligare förfining kontinuerligt för att förbättra prestandan.
MLOps-lösning
När MLOps-begreppen mognar upptäcker team ofta utmaningar när det gäller att sammanföra datavetenskap och DevOps-discipliner. Anledningen är att huvudaktörerna inom områdena, programvaruingenjörer och dataforskare, arbetar med olika kompetensuppsättningar och prioriteringar.
Men det finns likheter att bygga vidare på. MLOps, som DevOps, är en utvecklingsprocess som implementeras av en verktygskedja. MLOps-verktygskedjan innehåller bland annat:
- Versionskontroll
- Kodanalys
- Skapa automatisering
- Kontinuerlig integrering
- Testa ramverk och automatisering
- Efterlevnadsprinciper integrerade i CI/CD-pipelines
- Distributionsautomatisering
- Övervakning
- Haveriberedskap och hög tillgänglighet
- Paket- och containerhantering
Som nämnts ovan drar lösningen nytta av befintlig DevOps-vägledning, men utökas för att skapa en mer mogen MLOps-implementering som uppfyller klientens och data science-communityns behov. MLOps bygger på DevOps-vägledning med följande ytterligare krav:
- Data- och modellversionshantering är inte samma som kodversionshantering: Det måste finnas versionshantering av datauppsättningar när schemat och ursprungsdata ändras.
- Krav för digital granskningslogg: Spåra alla ändringar när du hanterar kod- och klientdata.
- Generalisering: Modeller skiljer sig från kod för återanvändning, eftersom dataexperter måste justera modeller baserat på indata och scenario. Om du vill återanvända en modell för ett nytt scenario kan du behöva finjustera/överföra/lära dig om den. Du behöver träningspipelinen.
- Inaktuella modeller: Modeller tenderar att förfalla över tid och du behöver möjlighet att träna om dem på begäran för att säkerställa att de förblir relevanta i produktionen.
MLOps-utmaningar
Omogen MLOps-standard
Standardmönstret för MLOps utvecklas fortfarande. En lösning skapas vanligtvis från grunden och görs för att passa en viss klients eller användares behov. CSE-teamet kände igen den här klyftan och försökte använda Metodtips för DevOps i det här projektet. De utökade DevOps-processen för att passa de ytterligare kraven i MLOps. Processen som teamet utvecklade är ett praktiskt exempel på hur ett MLOps-standardmönster ska se ut.
Skillnader i kunskapsuppsättningar
Programvarutekniker och dataexperter ger teamet unika färdigheter. De här olika kunskapsuppsättningarna kan göra det svårt att hitta en lösning som passar allas behov. Det är viktigt att skapa ett väl förstått arbetsflöde för modellleverans från experimentering till produktion. Teammedlemmar måste dela en förståelse för hur de kan integrera ändringar i systemet utan att bryta MLOps-processen.
Hantera flera modeller
Det finns ofta ett behov av att flera modeller löser svåra maskininlärningsscenarier. En av utmaningarna med MLOps är att hantera dessa modeller, inklusive:
- Har ett enhetligt versionsschema.
- Utvärdera och övervaka alla modeller kontinuerligt.
Spårningsbar ursprung för både kod och data behövs också för att diagnostisera modellproblem och skapa reproducerbara modeller. Anpassade instrumentpaneler kan förstå hur distribuerade modeller presterar och ange när de ska ingripa. Teamet skapade sådana instrumentpaneler för det här projektet.
Behov av datakonditionering
Data som används med dessa modeller kommer från många privata och offentliga källor. Eftersom de ursprungliga data är oorganiserade är det omöjligt för maskininlärningsmodellen att använda dem i dess råtillstånd. Dataexperterna måste villkora data i ett standardformat för maskininlärningsmodellförbrukning.
Mycket av pilotfälttestet fokuserade på att konditionering av rådata så att maskininlärningsmodellen kunde bearbeta dem. I ett MLOps-system bör teamet automatisera den här processen och spåra utdata.
MLOps-förfallomodell
Syftet med MLOps-mognadsmodellen är att klargöra principerna och metoderna och identifiera luckor i en MLOps-implementering. Det är också ett sätt att visa en klient hur de stegvis kan utöka sin MLOps-funktion i stället för att försöka göra allt på en gång. Klienten bör använda den som en guide för att:
- Beräkna omfånget för projektets arbete.
- Upprätta framgångskriterier.
- Identifiera slutprodukt.
MLOps-mognadsmodellen definierar fem nivåer av teknisk kapacitet:
| Nivå | beskrivning |
|---|---|
| 0 | Inga ops |
| 1 | DevOps men inga MLOps |
| 2 | Automatiserad utbildning |
| 3 | Automatiserad modelldistribution |
| 4 | Automatiserade åtgärder (fullständiga MLOps) |
Den aktuella versionen av MLOps-mognadsmodellen finns i artikeln MLOps maturity model (MLOps-mognadsmodell ).
MLOps-processdefinition
MLOps omfattar alla aktiviteter från att hämta rådata till att leverera modellutdata, även kallat bedömning:
- Datakonditionering
- Modellträning
- Modelltestning och utvärdering
- Skapa definition och pipeline
- Lanseringspipeline
- Distribution
- Resultat
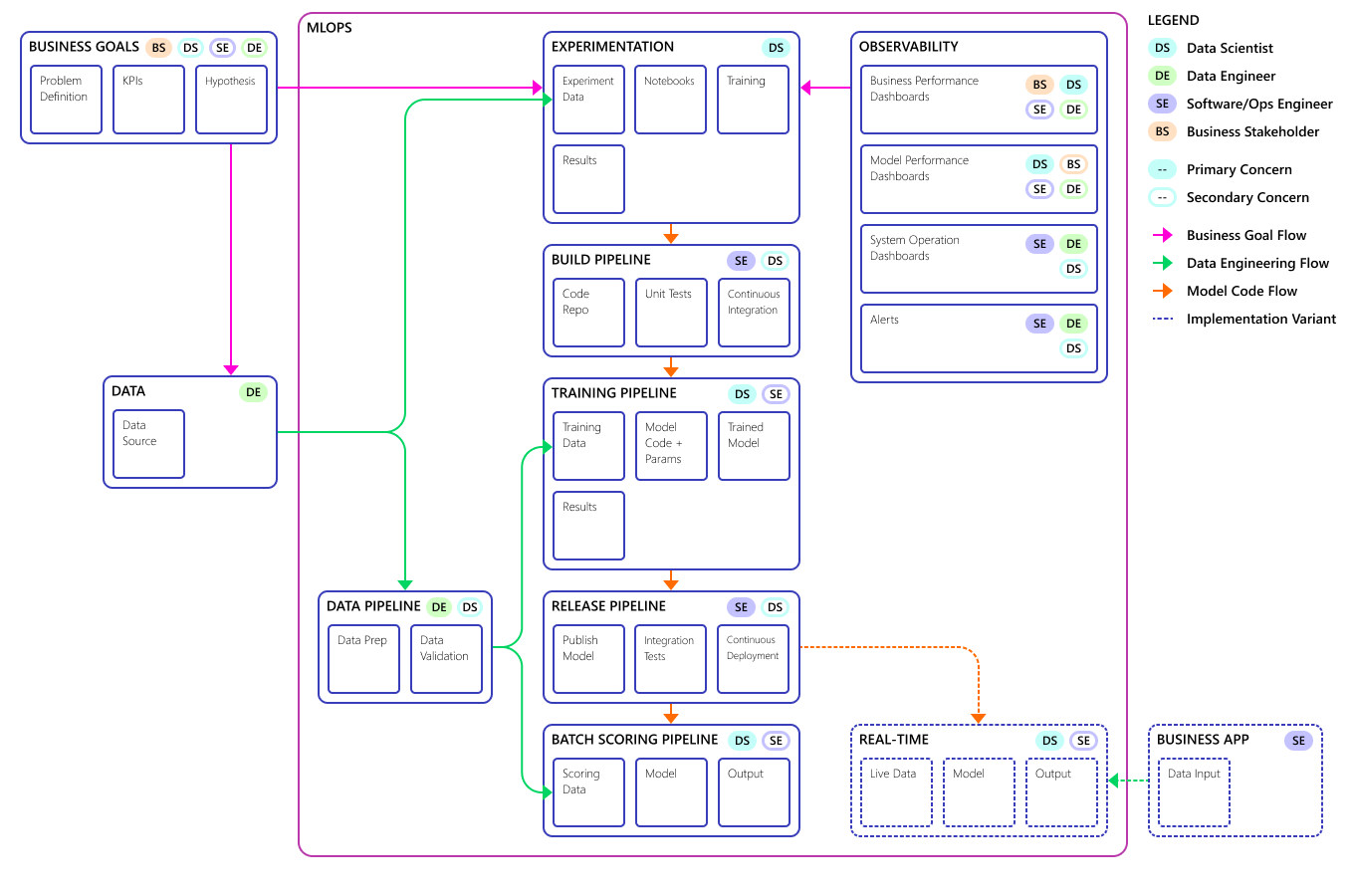
Grundläggande maskininlärningsprocess
Den grundläggande maskininlärningsprocessen liknar traditionell programvaruutveckling, men det finns betydande skillnader. Det här diagrammet illustrerar de viktigaste stegen i maskininlärningsprocessen:
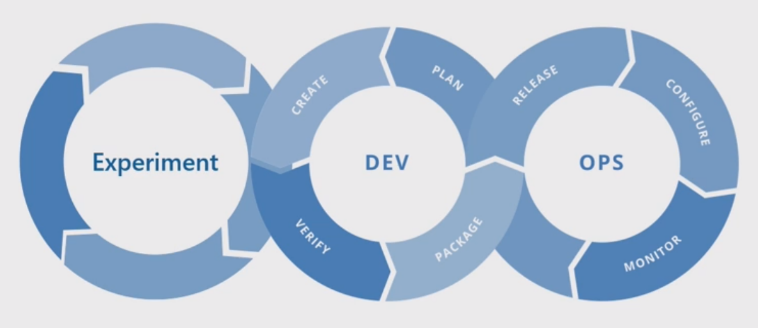
Experimentfasen är unik för datavetenskapens livscykel, vilket återspeglar hur dataexperter traditionellt utför sitt arbete. Det skiljer sig från hur kodutvecklare utför sitt arbete. Följande diagram illustrerar den här livscykeln mer detaljerat.
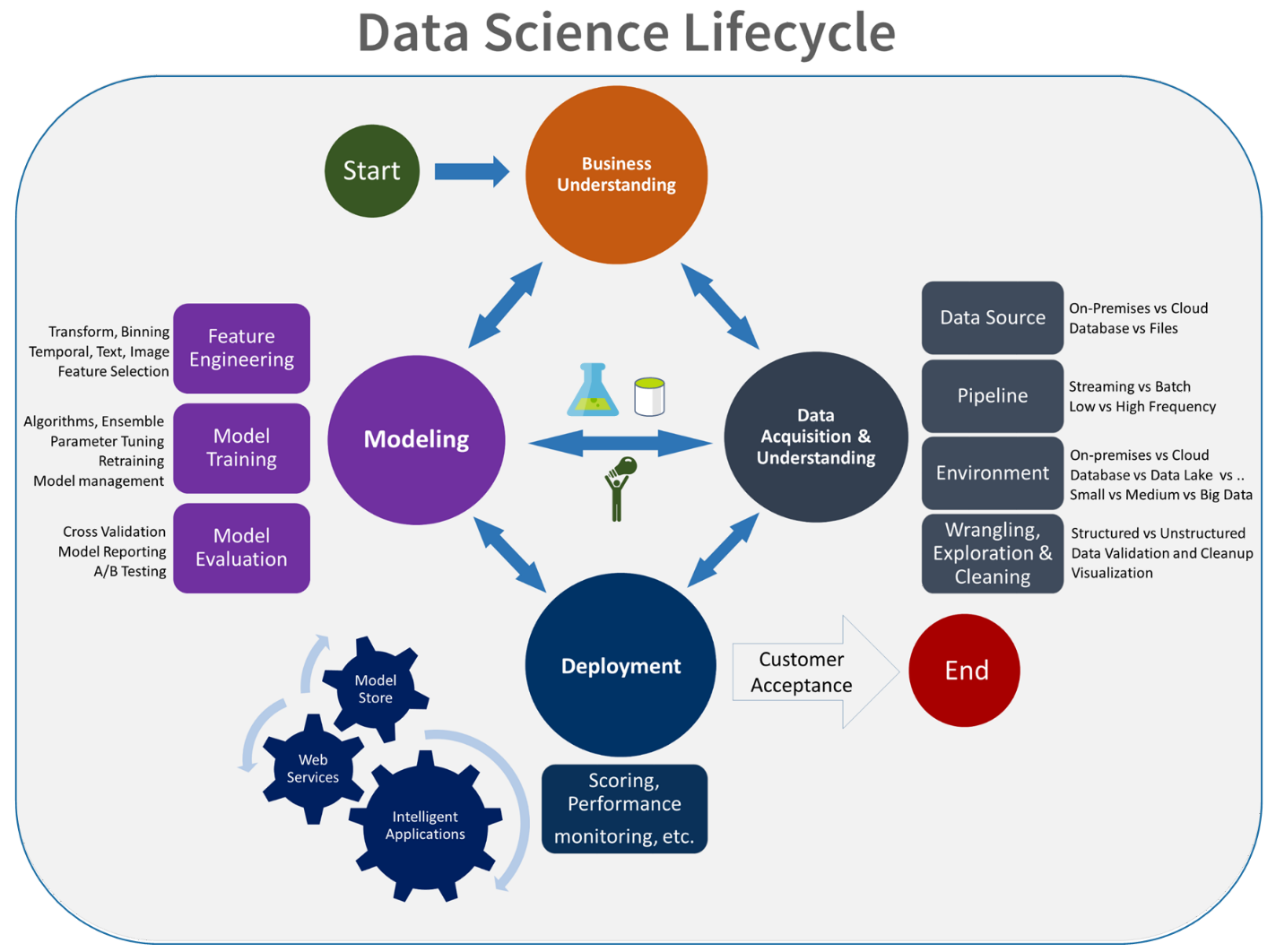
Att integrera den här datautvecklingsprocessen i MLOps är en utmaning. Här ser du det mönster som teamet använde för att integrera processen i ett formulär som MLOps kan stödja:
MLOps roll är att skapa en samordnad process som effektivt kan stödja storskaliga CI/CD-miljöer som är vanliga i system på produktionsnivå. Konceptuellt måste MLOps-modellen innehålla alla processkrav från experimentering till bedömning.
CSE-teamet förfinade MLOps-processen så att den passar klientens specifika behov. Det mest anmärkningsvärda behovet var batchbearbetning i stället för realtidsbearbetning. När teamet utvecklade det uppskalade systemet identifierade och löste de vissa brister. Den viktigaste av dessa brister ledde till utvecklingen av en brygga mellan Azure Data Factory och Azure Mašinsko učenje, som teamet implementerade med hjälp av en inbyggd anslutningsapp i Azure Data Factory. De skapade den här komponentuppsättningen för att underlätta den utlösande och statusövervakning som krävs för att processautomationen ska fungera.
En annan grundläggande förändring var att dataexperterna behövde förmågan att exportera experimentell kod från Jupyter Notebooks till MLOps-distributionsprocessen i stället för att utlösa träning och bedömning direkt.
Här är det sista mlOps-processmodellkonceptet:
Viktigt!
Poängsättning är det sista steget. Processen kör maskininlärningsmodellen för att göra förutsägelser. Detta åtgärdar det grundläggande kravet på affärsanvändningsfall för efterfrågeprognoser. Teamet bedömer kvaliteten på förutsägelserna med hjälp av MAPE, vilket är ett mått på förutsägelsenoggrannheten hos statistiska prognosmetoder och en förlustfunktion för regressionsproblem inom maskininlärning. I det här projektet ansåg teamet att MAPE <var = 45 % betydande.
MLOps-processflöde
I följande diagram beskrivs hur du tillämpar CI/CD-utvecklings- och versionsarbetsflöden på maskininlärningslivscykeln:
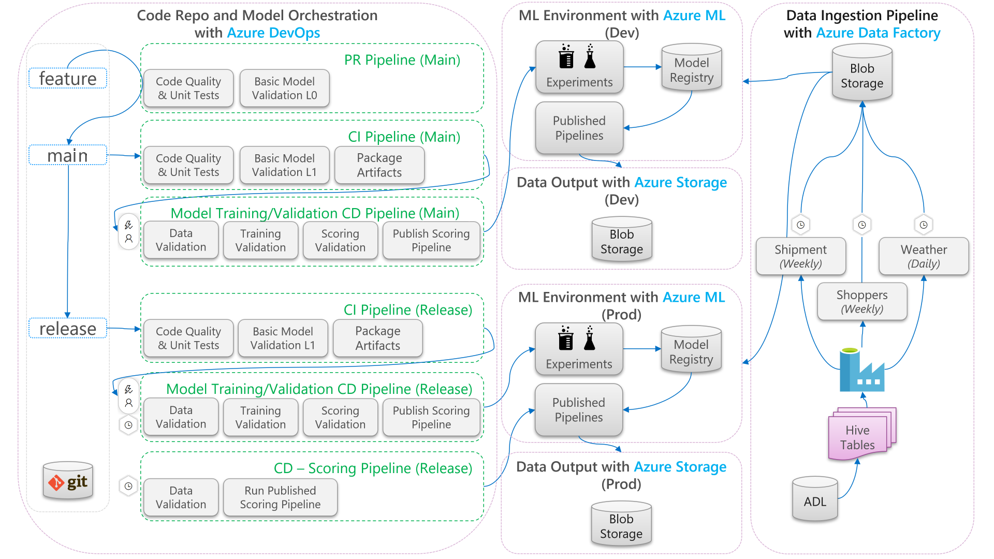
- När en pull-begäran (PR) skapas från en funktionsgren kör pipelinen kodvalideringstester för att verifiera kodens kvalitet via enhetstester och kodkvalitetstester. För att verifiera kvalitet uppströms kör pipelinen även grundläggande modellverifieringstester för att verifiera tränings- och bedömningsstegen från slutpunkt till slutpunkt med en exempeluppsättning med simulerade data.
- När PR slås samman till huvudgrenen kör CI-pipelinen samma kodvalideringstester och grundläggande modellverifieringstester med ökad epok. Pipelinen paketar sedan artefakterna, som innehåller koden och binärfilerna, som ska köras i maskininlärningsmiljön.
- När artefakterna är tillgängliga utlöses en cd-pipeline för modellverifiering. Den kör validering från slutpunkt till slutpunkt i utvecklingsmiljön för maskininlärning. En bedömningsmekanism publiceras. För ett batchbedömningsscenario publiceras en bedömningspipeline till maskininlärningsmiljön och utlöses för att ge resultat. Om du vill använda ett scenario för bedömning i realtid kan du publicera en webbapp eller distribuera en container.
- När en milstolpe har skapats och sammanfogats i versionsgrenen utlöses samma CI-pipeline och modellverifierings-CD-pipeline. Den här gången körs de mot koden från versionsgrenen.
Du kan betrakta MLOps-processdataflödet som visas ovan som ett arketypramverk för projekt som gör liknande arkitekturval.
Kodverifieringstester
Kodvalideringstester för maskininlärning fokuserar på att verifiera kodbasens kvalitet. Det är samma koncept som alla tekniska projekt som har kodkvalitetstester (linting), enhetstester och kodtäckningsmätningar.
Grundläggande modellverifieringstester
Modellverifiering syftar vanligtvis på validering av de fullständiga processstegen från slutpunkt till slutpunkt som krävs för att skapa en giltig maskininlärningsmodell. Den innehåller steg som:
- Dataverifiering: Säkerställer att indata är giltiga.
- Träningsverifiering: Säkerställer att modellen kan tränas.
- Bedömningsverifiering: Säkerställer att teamet kan använda den tränade modellen för bedömning med indata.
Det är dyrt och tidskrävande att köra hela den här uppsättningen steg i maskininlärningsmiljön. Därför gjorde teamet grundläggande modellverifieringstester lokalt på en utvecklingsdator. Den körde stegen ovan och använde följande:
- Datauppsättning för lokal testning: En liten datauppsättning, ofta en som är dold, som checkas in på lagringsplatsen och används som indatakälla.
- Lokal flagga: En flagga eller ett argument i modellens kod som anger att koden avser att datauppsättningen ska köras lokalt. Flaggan instruerar koden att kringgå alla anrop till maskininlärningsmiljön.
Det här målet med dessa valideringstester är inte att utvärdera den tränade modellens prestanda. I stället är det för att verifiera att koden för processen från slutpunkt till slutpunkt är av god kvalitet. Det säkerställer kvaliteten på koden som skickas uppströms, till exempel införlivandet av modellverifieringstester i PR- och CI-versionen. Det gör det också möjligt för tekniker och dataforskare att placera brytpunkter i koden i felsökningssyfte.
Cd-pipeline för modellverifiering
Målet med modellverifieringspipelinen är att validera modelltränings- och bedömningsstegen från slutpunkt till slutpunkt i maskininlärningsmiljön med faktiska data. Alla tränade modeller som skapas läggs till i modellregistret och taggas för att vänta på befordran när valideringen har slutförts. För batchförutsägelse kan befordran vara publicering av en bedömningspipeline som använder den här versionen av modellen. För realtidsbedömning kan modellen taggas för att indikera att den har befordrats.
Bedömning av CD-pipeline
Bedömnings-CD-pipelinen gäller för batchinferensscenariot, där samma modellorkestrerare som används för modellvalidering utlöser den publicerade bedömningspipelinen.
Utvecklings- och produktionsmiljöer
Det är en bra idé att skilja utvecklingsmiljön (utvecklingsmiljön) från produktionsmiljön (prod). Med separation kan systemet utlösa cd-pipelinen för modellverifiering och bedöma CD-pipelinen enligt olika scheman. För det beskrivna MLOps-flödet körs pipelines som riktar sig mot huvudgrenen i utvecklingsmiljön och pipelinen som riktar sig mot versionsgrenen i prod-miljön.
Kodändringar jämfört med dataändringar
De föregående avsnitten handlar främst om hur du hanterar kodändringar från utveckling till lansering. Dataändringar bör dock följa samma stränghet som kodändringar för att tillhandahålla samma valideringskvalitet och konsekvens i produktionen. Med en utlösare för dataändring eller en timerutlösare kan systemet utlösa cd-pipelinen för modellvalidering och cd-poängpipelinen från modellorkestreraren för att köra samma process som körs för kodändringar i versionsgrenens prod-miljö.
MLOps-personas och roller
Ett viktigt krav för alla MLOps-processer är att den uppfyller behoven hos de många användarna av processen. I designsyfte bör du betrakta dessa användare som enskilda personer. För det här projektet identifierade teamet dessa personer:
- Dataforskare: Skapar maskininlärningsmodellen och dess algoritmer.
- Ingenjör
- Datatekniker: Hanterar datakonditionering.
- Programvarutekniker: Hanterar modellintegrering i tillgångspaketet och CI/CD-arbetsflödet.
- Åtgärder eller IT: Övervakar systemåtgärder.
- Affärsintressent: Handlar om förutsägelserna från maskininlärningsmodellen och hur de hjälper verksamheten.
- Data slutanvändare: Förbrukar modellutdata på något sätt som hjälper dig att fatta affärsbeslut.
Teamet var tvunget att ta itu med tre viktiga resultat från persona- och rollstudierna:
- Dataforskare och tekniker har en missmatchning av tillvägagångssätt och färdigheter i sitt arbete. Att göra det enkelt för dataexperten och teknikern att samarbeta är en viktig faktor för utformningen av MLOps-processflödet. Det kräver nya kompetensförvärv av alla teammedlemmar.
- Det finns ett behov av att förena alla huvudpersonas utan att alienera någon. Ett sätt att göra detta är att:
- Se till att de förstår den konceptuella modellen för MLOps.
- Kom överens om vilka teammedlemmar som ska arbeta tillsammans.
- Upprätta arbetsriktlinjer för att uppnå gemensamma mål.
- Om företagsintressenten och data slutanvändaren behöver ett sätt att interagera med datautdata från modellerna är ett användarvänligt användargränssnitt standardlösningen.
Andra team kommer säkert att stöta på liknande problem i andra maskininlärningsprojekt när de skalas upp för produktionsanvändning.
MLOps-lösningsarkitektur
Logisk arkitektur
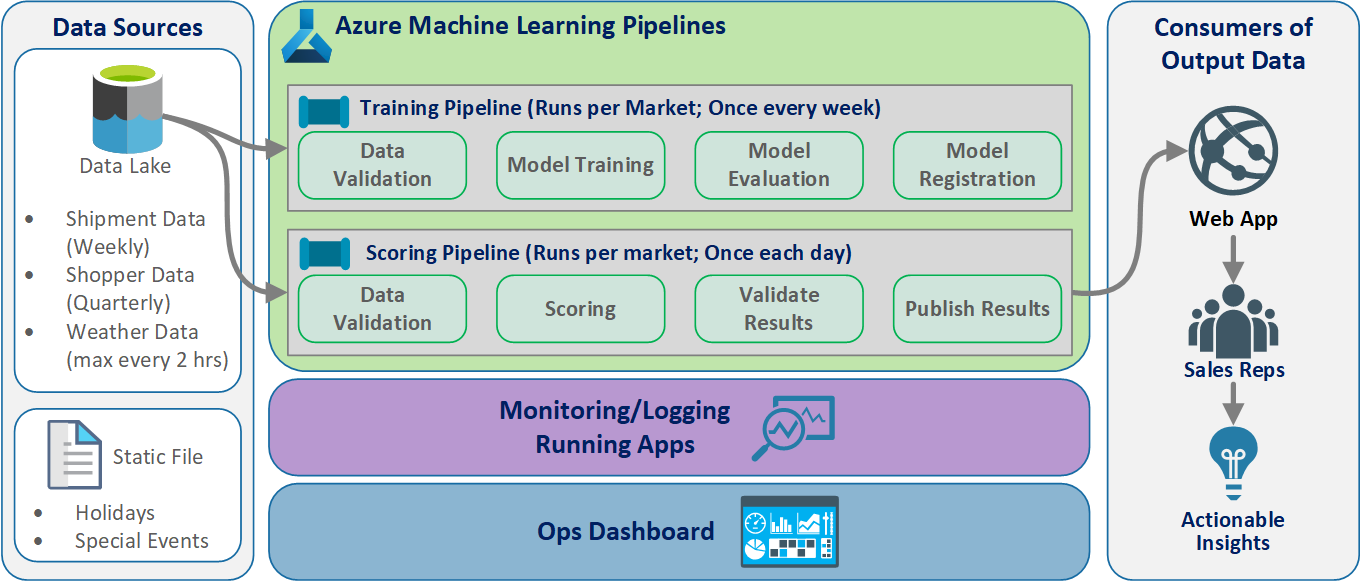
Data kommer från många källor i många olika format, så de villkoras innan de infogas i datasjön. Konditioneringen utförs med hjälp av mikrotjänster som fungerar som Azure Functions. Klienterna anpassar mikrotjänsterna så att de passar datakällorna och omvandlar dem till ett standardiserat csv-format som tränings- och bedömningspipelines använder.
Systemarkitektur
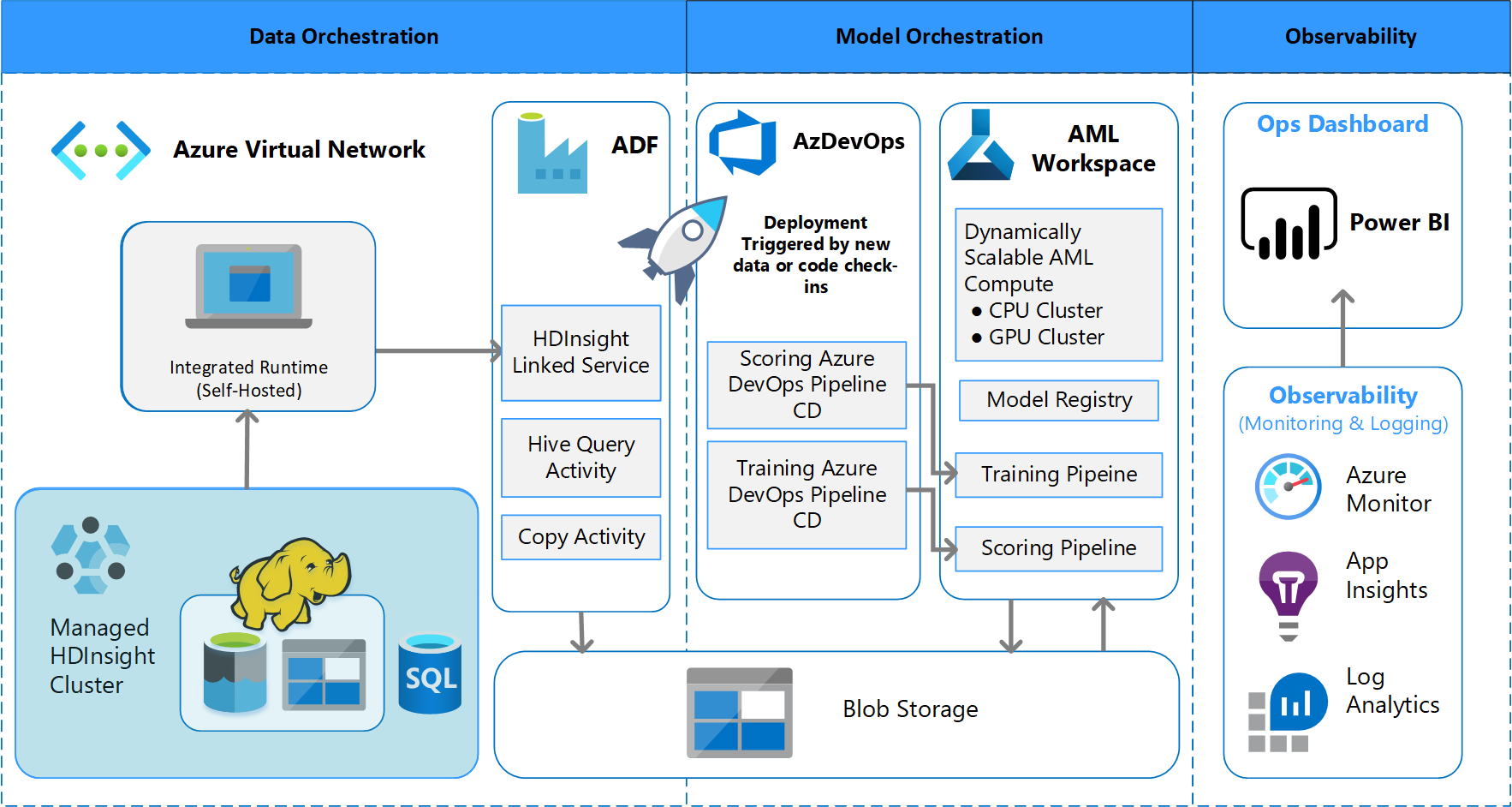
Arkitektur för batchbearbetning
Teamet utformade arkitekturdesignen för att stödja ett batchdatabehandlingsschema. Det finns alternativ, men det som används måste ha stöd för MLOps-processer. Fullständig användning av tillgängliga Azure-tjänster var ett designkrav. Följande diagram visar arkitekturen:
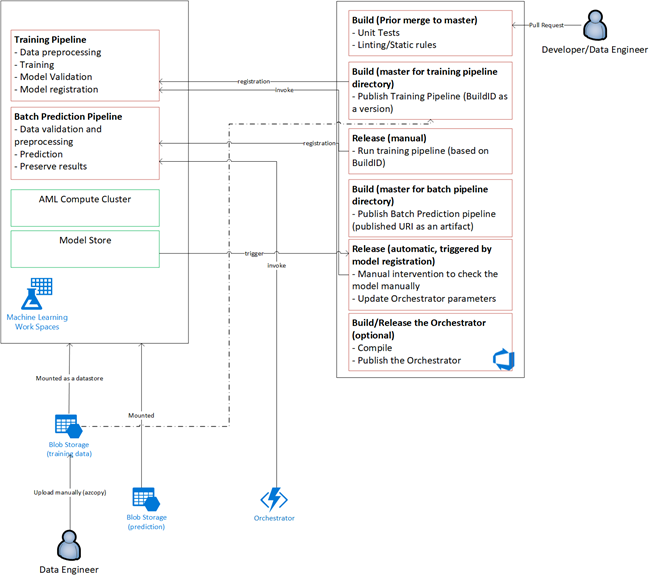
Översikt över lösningen
Azure Data Factory gör följande:
- Utlöser en Azure-funktion för att starta datainmatning och en körning av Azure Mašinsko učenje pipeline.
- Startar en hållbar funktion för att avsöka Azure Mašinsko učenje pipeline för slutförande.
Anpassade instrumentpaneler i Power BI visar resultatet. Andra Azure-instrumentpaneler som är anslutna till Azure SQL, Azure Monitor och App Insights via OpenCensus Python SDK spårar Azure-resurser. Dessa instrumentpaneler innehåller information om hälsotillståndet för maskininlärningssystemet. De ger också data som klienten använder för produktorderprognoser.
Modellorkestrering
Modellorkestrering följer dessa steg:
- När en pr skickas utlöser DevOps en kodvalideringspipeline.
- Pipelinen kör enhetstester, kodkvalitetstester och modellverifieringstester.
- När de sammanfogas till huvudgrenen körs samma kodverifieringstester och DevOps paketar artefakterna.
- DevOps-insamling av artefakter utlöser Azure Mašinsko učenje att göra:
- Datavalidering.
- Träningsverifiering.
- Bedömningsverifiering.
- När valideringen har slutförts körs den slutliga bedömningspipelinen.
- Om du ändrar data och skickar en ny PR utlöses valideringspipelinen igen, följt av den slutliga bedömningspipelinen.
Aktivera experimentering
Som nämnts stöder den traditionella livscykeln för maskininlärning för datavetenskap inte MLOps-processen utan ändringar. Den använder olika typer av manuella verktyg och experimentering, validering, paketering och modellöverföring som inte enkelt kan skalas för en effektiv CI/CD-process. MLOps kräver en hög processautomatiseringsnivå. Oavsett om en ny maskininlärningsmodell utvecklas eller om en gammal har ändrats, är det nödvändigt att automatisera livscykeln för maskininlärningsmodellen. I fas 2-projektet använde teamet Azure DevOps för att orkestrera och publicera om Azure Mašinsko učenje pipelines för träningsaktiviteter. Den långvariga huvudgrenen utför grundläggande testning av modeller och push-överför stabila versioner via den långvariga versionsgrenen.
Källkontroll blir en viktig del av den här processen. Git är det versionskontrollsystem som används för att spåra notebook- och modellkod. Det stöder även processautomatisering. Det grundläggande arbetsflödet som implementeras för källkontroll tillämpar följande principer:
- Använd formell versionshantering för kod och datauppsättningar.
- Använd en gren för ny kodutveckling tills koden har utvecklats och verifierats fullt ut.
- När ny kod har verifierats kan den sammanfogas till huvudgrenen.
- För en version skapas en permanent version av grenen som är separat från huvudgrenen.
- Använd versioner och källkontroll för de datauppsättningar som har villkorats för träning eller förbrukning, så att du kan upprätthålla integriteten för varje datauppsättning.
- Använd källkontroll för att spåra dina Jupyter Notebook-experiment.
Integrering med datakällor
Dataforskare använder många rådatakällor och bearbetade datamängder för att experimentera med olika maskininlärningsmodeller. Mängden data i en produktionsmiljö kan vara överväldigande. För att dataexperterna ska kunna experimentera med olika modeller måste de använda hanteringsverktyg som Azure Data Lake. Kravet på formell identifiering och versionskontroll gäller för alla rådata, förberedda datamängder och maskininlärningsmodeller.
I projektet villkorade dataexperterna följande data för indata till modellen:
- Historiska veckovisa leveransdata sedan januari 2017
- Historiska och prognostiserade dagliga väderdata för varje postnummer
- Shopper-data för varje butiks-ID
Integrering med källkontroll
För att få dataexperter att tillämpa metodtips för teknik är det nödvändigt att enkelt integrera de verktyg som de använder med källkontrollsystem som GitHub. Den här metoden möjliggör versionshantering av maskininlärningsmodeller, samarbete mellan teammedlemmar och haveriberedskap om teamen drabbas av dataförlust eller systemfel.
Stöd för modellensembler
Modelldesignen i det här projektet var en ensemblemodell. Dataexperter använde alltså många algoritmer i den slutliga modelldesignen. I det här fallet använde modellerna samma grundläggande algoritmdesign. Den enda skillnaden var att de använde olika träningsdata och bedömningsdata. Modellerna använde kombinationen av en LASSO-linjär regressionsalgoritm och ett neuralt nätverk.
Teamet utforskade, men implementerade inte, ett alternativ för att föra processen framåt till den punkt där det skulle stödja att många realtidsmodeller körs i produktion för att betjäna en viss begäran. Det här alternativet kan hantera användningen av ensemblemodeller i A/B-testning och interfolierade experiment.
Slutanvändargränssnitt
Teamet utvecklade slutanvändar-UIs för observerbarhet, övervakning och instrumentation. Som nämnts visar instrumentpaneler visuellt maskininlärningsmodelldata. Dessa instrumentpaneler visar följande data i ett användarvänligt format:
- Pipelinesteg, inklusive förbearbetning av indata.
- Så här övervakar du hälsotillståndet för bearbetningen av maskininlärningsmodellen:
- Vilka mått samlar du in från din distribuerade modell?
- MAPE: Genomsnittligt absolut procentfel, det nyckelmått som ska spåras för övergripande prestanda. (Rikta in ett MAPE-värde på <= 0,45 för varje modell.)
- RMSE 0: Rot-medelvärde-kvadratfel (RMSE) när det faktiska målvärdet = 0.
- RMSE Alla: RMSE på hela datauppsättningen.
- Hur utvärderar du om din modell fungerar som förväntat i produktionen?
- Finns det något sätt att se om produktionsdata avviker för mycket från förväntade värden?
- Presterar din modell dåligt i produktionen?
- Har du ett redundanstillstånd?
- Vilka mått samlar du in från din distribuerade modell?
- Spåra kvaliteten på bearbetade data.
- Visa bedömning/förutsägelser som skapats av maskininlärningsmodellen.
Programmet fyller i instrumentpanelerna efter datatypen och hur de bearbetar och analyserar data. Därför måste teamet utforma den exakta layouten för instrumentpanelerna för varje användningsfall. Här är två exempelinstrumentpaneler:
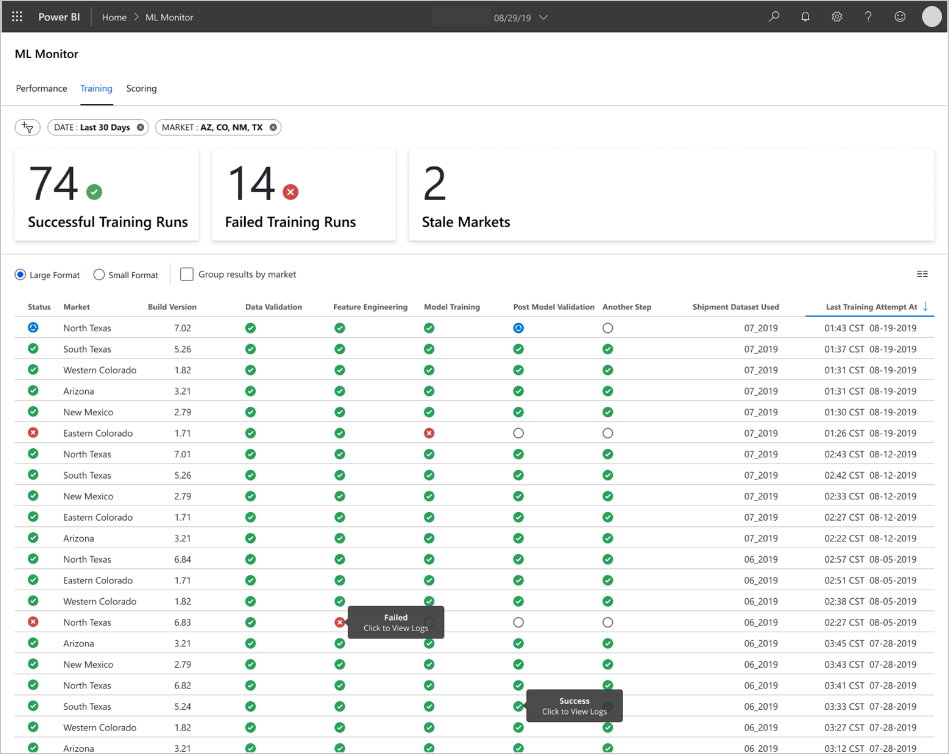
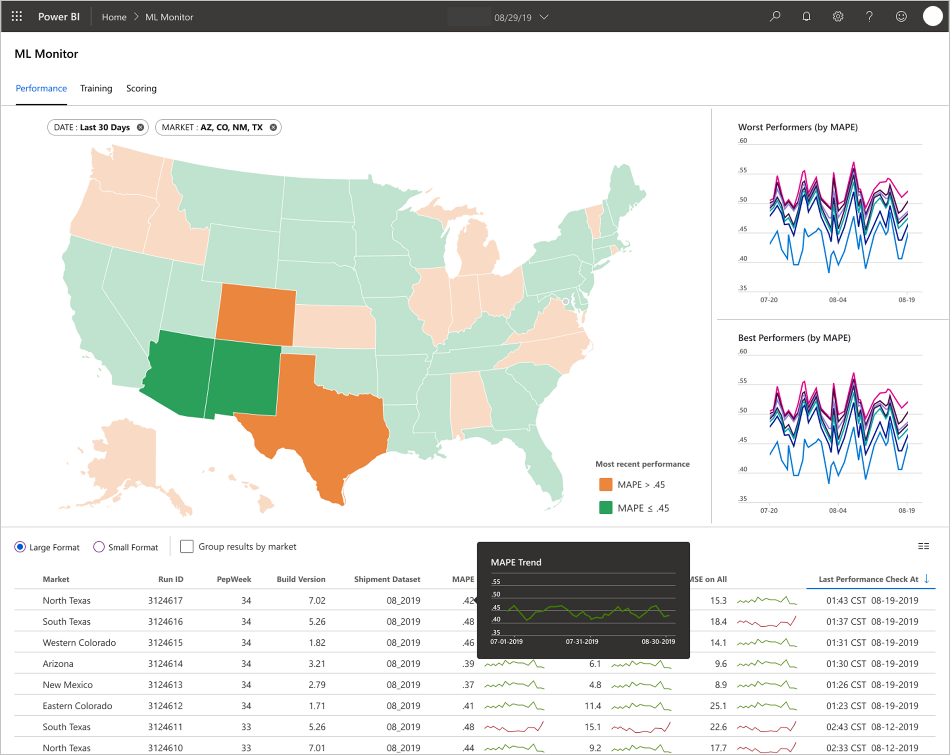
Instrumentpanelerna har utformats för att ge lättanvänd information för förbrukning av slutanvändaren av förutsägelserna för maskininlärningsmodellen.
Kommentar
Inaktuella modeller gör bedömningskörningar där dataexperterna tränade modellen som användes för att bedöma mer än 60 dagar från när poängsättningen ägde rum. På bedömningssidan på instrumentpanelen för ML Monitor visas det här hälsomåttet.
Komponenter
- Azure Machine Learning
- Azure Blob Storage
- Azure Data Lake Storage
- Azure Pipelines
- Azure Data Factory
- Azure Functions för Python
- Azure Monitor
- Azure SQL Database
- Azure-instrumentpaneler
- Power BI
Att tänka på
Här hittar du en lista över överväganden att utforska. De baseras på de lärdomar som CSE-teamet lärde sig under projektet.
Miljööverväganden
- Dataexperter utvecklar de flesta av sina maskininlärningsmodeller med hjälp av Python, som ofta börjar med Jupyter Notebooks. Det kan vara en utmaning att implementera dessa notebook-filer som produktionskod. Jupyter Notebooks är mer av ett experimentellt verktyg, medan Python-skript är lämpligare för produktion. Teams behöver ofta ägna tid åt att omstrukturera kod för att skapa modeller till Python-skript.
- Gör klienter som är nya för DevOps och maskininlärning medvetna om att experimentering och produktion kräver olika stränghet, så det är bra att separera de två.
- Verktyg som Azure Mašinsko učenje Visual Designer eller AutoML kan vara effektiva för att få grundläggande modeller från marken medan klienten ökar standardmetoderna för DevOps för resten av lösningen.
- Azure DevOps har plugin-program som kan integreras med Azure Mašinsko učenje för att utlösa pipelinesteg. MLOpsPython-lagringsplatsen har några exempel på sådana pipelines.
- Maskininlärning kräver ofta kraftfulla GPU-datorer (graphics processing unit) för träning. Om klienten inte redan har sådan maskinvara tillgänglig kan Azure Mašinsko učenje beräkningskluster tillhandahålla en effektiv sökväg för att snabbt etablera kostnadseffektiv kraftfull maskinvara som skalar automatiskt. Om en klient har avancerade säkerhets- eller övervakningsbehov finns det andra alternativ, till exempel virtuella standarddatorer, Databricks eller lokal beräkning.
- För att en klient ska lyckas måste deras modellskapande team (dataforskare) och distributionsteam (DevOps-tekniker) ha en stark kommunikationskanal. De kan åstadkomma detta med dagliga stand-up-möten eller en formell onlinechatttjänst. Båda metoderna hjälper till att integrera deras utvecklingsarbete i ett MLOps-ramverk.
Överväganden vid förberedelse av data
Den enklaste lösningen för att använda Azure Mašinsko učenje är att lagra data i en datalagringslösning som stöds. Verktyg som Azure Data Factory är effektiva för att skicka data till och från dessa platser enligt ett schema.
Det är viktigt att klienter ofta samlar in ytterligare omträningsdata för att hålla sina modeller uppdaterade. Om de inte redan har en datapipeline är det en viktig del av den övergripande lösningen att skapa en. Att använda en lösning som Datauppsättningar i Azure Mašinsko učenje kan vara användbart för versionshantering av data för att hjälpa till med spårning av modeller.
Överväganden för modellträning och utvärdering
Det är överväldigande för en klient som precis har kommit igång med sin maskininlärningsresa för att försöka implementera en fullständig MLOps-pipeline. Om det behövs kan de underlätta det genom att använda Azure Mašinsko učenje för att spåra experimentkörningar och genom att använda Azure Mašinsko učenje beräkning som träningsmål. De här alternativen kan skapa en lägre inträdeslösning för att börja integrera Azure-tjänster.
Att gå från ett notebook-experiment till repeterbara skript är en grov övergång för många dataforskare. Ju tidigare du kan få dem att skriva sin träningskod i Python-skript desto enklare blir det för dem att börja versionshantera sin träningskod och aktivera omträning.
Det är inte den enda möjliga metoden. Databricks stöder schemaläggning av notebook-filer som jobb. Men baserat på den aktuella klientupplevelsen är den här metoden svår att instrumentera med fullständiga DevOps-metoder på grund av testbegränsningar.
Det är också viktigt att förstå vilka mått som används för att betrakta en modell som en framgång. Enbart noggrannhet är ofta inte tillräckligt bra för att fastställa den övergripande prestandan för en modell jämfört med en annan.
Beräkningsöverväganden
- Kunder bör överväga att använda containrar för att standardisera sina beräkningsmiljöer. Nästan alla Azure Mašinsko učenje-beräkningsmål stöder användning av Docker. Att ha en container som hanterar beroendena kan minska friktionen avsevärt, särskilt om teamet använder många beräkningsmål.
Överväganden för modellhantering
- Azure Mašinsko učenje SDK tillhandahåller ett alternativ för att distribuera direkt till Azure Kubernetes Service (AKS) från en registrerad modell, vilket skapar gränser för vilka säkerhet/mått som finns på plats. Du kan försöka hitta en enklare lösning för klienter att testa sin modell, men det är bäst att utveckla en mer robust distribution till AKS för produktionsarbetsbelastningar.
Nästa steg
- Läs mer om MLOps
- MLOps på Azure
- Visualiseringar i Azure Monitor
- Mašinsko učenje livscykel
- Azure DevOps Mašinsko učenje-tillägg
- Azure Machine Learning CLI
- Utlös program, processer eller CI/CD-arbetsflöden baserat på Azure Machine Learning-händelser
- Konfigurera modellträning och distribution med Azure DevOps