Förstå datalagringsmodeller
Moderna affärssystem hanterar allt större mängder heterogena data. Den här heterogeniteten innebär att ett enda datalager normalt inte är den bästa metoden. I stället är det ofta bättre att lagra olika typer av data i olika datalager, som var och en fokuserar på en specifik arbetsbelastning eller användningsmönster. Termen polyglott beständighet används för att beskriva lösningar som använder en blandning av datalagringstekniker. Därför är det viktigt att förstå de viktigaste lagringsmodellerna och deras kompromisser.
Att välja rätt datalager för dina behov är ett viktigt beslut. Det finns hundratals implementeringar att välja bland från SQL- och NoSQL-databaser. Datalager kategoriseras ofta genom hur de strukturerar data och vilka typer av åtgärder som de stöder. Den här artikeln beskriver flera av de vanligaste lagringsmodellerna. Tänk på att en viss datalagringsteknik kan ha stöd för flera lagringsmodeller. Ett hanteringssystem för relationsdatabaser (RDBMS) kan till exempel också ha stöd för nyckel/värde- eller graflager. Faktum är att det finns en allmän trend för så kallat stöd för flera modeller , där ett enda databassystem stöder flera modeller. Men det är fortfarande användbart att förstå de olika modellerna på hög nivå.
Det är inte alla datalager i en viss kategori som ger samma funktionsuppsättning. De flesta datalager innehåller serverfunktioner för att fråga och bearbeta data. Ibland är den här funktionen inbyggd i datalagringsmotorn. I andra fall är datalagrings- och bearbetningsfunktionerna åtskilda, och det kan finnas flera alternativ för bearbetning och analys. Datalager har också stöd för olika program- och hanteringsgränssnitt.
Du bör normalt börja med att överväga vilken lagringsmodell som passar dina behov bäst. Tänk dig sedan ett särskilt datalager i den kategorin, baserat på faktorer som funktionsuppsättning, kostnad och hur enkelt det är att hantera.
Kommentar
Läs mer om att identifiera och granska dina datatjänstkrav för molnimplementering i Microsoft Cloud Adoption Framework för Azure. På samma sätt kan du också lära dig om att välja lagringsverktyg och tjänster.
Relationsdatabas för hanteringssystem
Relationsdatabaser ordnar data som en serie med tvådimensionella tabeller med rader och kolumner. De flesta leverantörer tillhandahåller en dialekt av SQL (Structured Query Language) för att hämta och hantera data. En RDBMS implementerar normalt en transaktionsmässigt konsekvent mekanism som följer ACID-modellen (atomicitet, konsekvens, isolering, varaktighet) för att uppdatera information.
En RDBMS har normalt stöd för en modell med schema vid skrivning, där datastrukturen definieras i förväg, och alla läs- eller skrivåtgärder måste använda schemat.
Den här modellen är mycket användbar när starka konsekvensgarantier är viktiga – där alla ändringar är atomiska och transaktioner alltid lämnar data i ett konsekvent tillstånd. En RDBMS kan dock vanligtvis inte skalas ut horisontellt utan att partitionera data på något sätt. Dessutom måste data i en RDBMS normaliseras, vilket inte är lämpligt för varje datauppsättning.
Azure-tjänster
- Azure SQL Database | (säkerhetsbaslinje)
- Azure Database for MySQL | (säkerhetsbaslinje)
- Azure Database for PostgreSQL | (säkerhetsbaslinje)
- Azure Database for MariaDB | (säkerhetsbaslinje)
Arbetsbelastning
- Poster skapas och uppdateras ofta.
- Flera åtgärder måste utföras i en enda transaktion.
- Relationer tillämpas med begränsningar för databasen.
- Index används för att optimera frågeprestanda.
Datatyp
- Data är mycket normaliserade.
- Databasscheman krävs och framtvingas.
- Många-till-många-relationer mellan dataentiteter i databasen.
- Begränsningar definieras i schemat och används på alla data i databasen.
- Data kräver hög integritet. Index och relationer måste fortsätta att fungera korrekt.
- Data kräver stark konsekvens. Transaktioner fungerar på ett sätt som säkerställer att alla data är 100 % konsekventa för alla användare och processer.
- Storleken på enskilda dataposter är liten till medelstor.
Exempel
- Lagerhantering
- Beställningshantering
- Rapportdatabas
- Redovisning
Nyckel/värdelager
Ett nyckel-/värdelager associerar varje datavärde med en unik nyckel. De flesta nyckel/värde-lager har endast stöd för enkla fråge-, infognings- och borttagningsåtgärder. För att ändra ett värde (delvis eller helt) måste ett program skriva över befintliga data för hela värdet. I de flesta implementeringar är läsning eller skrivning av ett enskilt värde en atomisk åtgärd.
Ett program kan lagra godtyckliga data som en uppsättning värden. All schemainformation måste tillhandahållas av programmet. Nyckel-/värdearkivet hämtar eller lagrar bara värdet efter nyckel.
Nyckel-/värdelager är mycket optimerade för program som utför enkla sökningar, men är mindre lämpliga om du behöver köra frågor mot data i olika nyckel-/värdelager. Nyckel-/värdelager är inte heller optimerade för frågor efter värde.
Ett enda nyckel/värde-lager kan vara extremt skalbart, eftersom datalagret enkelt kan distribuera data över flera noder på separata datorer.
Azure-tjänster
- Azure Cosmos DB för Table och Azure Cosmos DB for NoSQL | (Säkerhetsbaslinje för Azure Cosmos DB)
- Azure Cache for Redis | (säkerhetsbaslinje)
- Azure Table Storage | (säkerhetsbaslinje)
Arbetsbelastning
- Data nås med en enda nyckel, till exempel en ordlista.
- Inga kopplingar, lås eller unioner krävs.
- Inga aggregeringsmetoder används.
- Sekundärindex används vanligtvis inte.
Datatyp
- Varje nyckel är associerad med ett enda värde.
- Det finns inget tvingande schema.
- Inga relationer mellan entiteter.
Exempel
- Cachelagring av data
- Sessionshantering
- Användarinställningar och profilhantering
- Produktrekommendation och annonsvisning
Dokumentdatabaser
En dokumentdatabas lagrar en samling dokument, där varje dokument består av namngivna fält och data. Data kan vara enkla värden eller komplexa element som listor och underordnade samlingar. Dokument hämtas med unika nycklar.
Vanligtvis innehåller ett dokument data för en enskild entitet, till exempel en kund eller en beställning. Ett dokument kan innehålla information som skulle spridas över flera relationstabeller i en RDBMS. Dokument behöver inte ha samma struktur. Program kan lagra olika data i dokumenten allt eftersom affärsbehoven ändras.
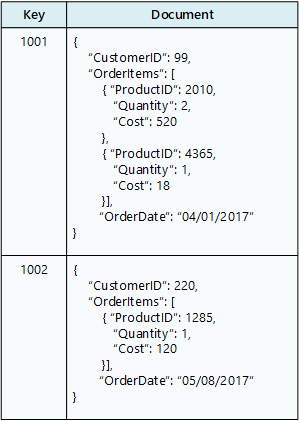
Azure-tjänst
Arbetsbelastning
- Infognings- och uppdateringsåtgärder sker ofta.
- Inget matchningsfel för objektrelationell impedans. Dokumenten kan matcha objektstrukturerna som används i programkoden på ett bättre sätt.
- Enskilda dokument hämtas och skrivs som ett enda block.
- Data kräver index på flera fält.
Datatyp
- Data kan hanteras på ett avnormaliserat sätt.
- Storleken på enskilda dokumentdata är relativt liten.
- Varje dokumenttyp kan använda ett eget schema.
- Dokument kan innehålla valfria fält.
- Dokumentdata är halvstrukturerade, vilket innebär att datatyperna för varje fält inte definieras strikt.
Exempel
- Produktkatalog
- Innehållshantering
- Lagerhantering
Grafdatabaser
En grafdatabas lagrar två typer av information, noder och kanter. Kanter anger relationer mellan noder. Noder och kanter kan ha egenskaper som ger information om noden eller kanten, ungefär som kolumner i en tabell. Kanter kan också ha en riktning som visar relationens typ.
Graph-databaser kan effektivt utföra frågor i nätverket med noder och kanter och analysera relationerna mellan entiteter. Följande diagram visar en organisations personaldatabas strukturerad som ett diagram. Entiteterna är anställda och avdelningar, och kanterna anger rapporteringsrelationer och de avdelningar där anställda arbetar.
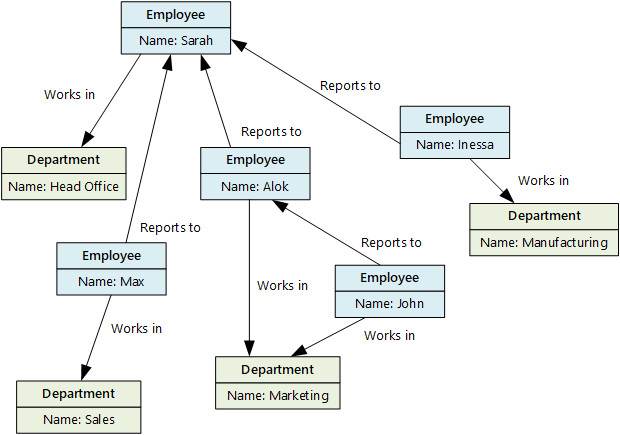
Den här strukturen gör det enkelt att utföra frågor som "Hitta alla anställda som rapporterar direkt eller indirekt till Sarah" eller "Vem arbetar på samma avdelning som John?" För stora grafer med många entiteter och relationer kan du utföra mycket komplexa analyser mycket snabbt. Många grafdatabaser ger ett frågespråk som du kan använda för att gå igenom ett nätverk med relationer på ett effektivt sätt.
Azure-tjänster
Arbetsbelastning
- Komplexa relationer mellan dataobjekt som omfattar många hopp mellan relaterade dataobjekt.
- Relationen mellan dataobjekt är dynamisk och ändras med tiden.
- Relationerna mellan objekt är första klassens medborgare, som inte behöver sekundärnycklar och kopplingar för att förflyttas.
Datatyp
- Noder och relationer.
- Noder liknar tabellrader eller JSON-dokument.
- Relationer är lika viktiga som noder och exponeras direkt i frågespråket.
- Sammansatta objekt, t.ex. en person med flera telefonnummer, blir ofta uppdelade i separata mindre noder, som kombineras med överföringsbara relationer
Exempel
- Organisationsscheman
- Sociala diagram
- Upptäckt av bedrägerier
- Rekommendationsmotorer
Datanalys
Dataanalyslager ger enormt parallella lösningar för inmatning, lagring och analys av data. Data distribueras över flera servrar för att maximera skalbarheten. Stora datafilformat som avgränsarfiler (CSV), parquet och ORC används ofta i dataanalys. Historiska data lagras vanligtvis i datalager som bloblagring eller Azure Data Lake Storage Gen2, som sedan nås av Azure Synapse, Databricks eller HDInsight som externa tabeller. Ett typiskt scenario med data som lagras som parquet-filer för prestanda beskrivs i artikeln Använda externa tabeller med Synapse SQL.
Azure-tjänster
- Azure Synapse Analytics | (säkerhetsbaslinje)
- Azure Data Lake | (säkerhetsbaslinje)
- Azure Data Explorer | (säkerhetsbaslinje)
- Azure Analysis Services
- HDInsight | (säkerhetsbaslinje)
- Azure Databricks | (säkerhetsbaslinje)
Arbetsbelastning
- Datanalys
- Enterprise BI
Datatyp
- Historiska data från flera källor.
- Normalt avnormaliserade i ett "star"- eller "snowflake"-schema, som består av fakta- och dimensionstabeller.
- Läses normalt in med nya data med schemalagd grund.
- Dimensionstabeller innehåller ofta flera historiska versioner av en entitet, som kallas en långsam ändringsdimension.
Exempel
- Informationslager för företag
Kolumnseriedatabaser
En kolumnseriedatabas ordnar data i rader och kolumner. I sin enklaste form kan en kolumnseriedatabas se ut att vara väldigt lik en relationsdatabas, åtminstone begreppsmässigt. Den verkliga kraften i en kolumnseriedatabas ligger i den avnormaliserade metoden för att strukturera null-optimerade data.
Du kan tänka dig en kolumnseriedatabas som att den innehåller tabelldata med kolumner, men kolumnerna är indelade i grupper som kallas kolumnserier. Varje kolumnserie har en uppsättning kolumner som är logiskt relaterade till varandra och normalt hämtas eller ändras som en enhet. Andra data som kan nås separat kan lagras i separata kolumnserier. I en kolumnserie kan nya kolumner läggas till dynamiskt, och rader kan vara null-optimerade (dvs. en rad behöver inte ha ett värde för varje kolumn).
Följande diagram visar ett exempel med två kolumnserier, Identity och Contact Info. Data för en enda entitet har samma radnyckel i varje kolumnserie. Den här strukturen, där rader för ett visst objekt i en kolumnfamilj kan variera dynamiskt, är en stor fördel med metoden med kolumnserier, som gör att den här typen av datalager passar mycket bra för lagring av strukturerade beräkningsbara data.

Till skillnad från ett nyckel/värde-lager eller en dokumentdatabas lagrar de flesta kolumnseriedatabaser data i nyckelordning, snarare än att beräkna ett hash-värde. Många implementeringar gör det möjligt att skapa index över specifika kolumner i en kolumnserie. Index gör det möjligt att hämta data efter kolumnvärde, i stället för radnyckel.
Läs- och skrivåtgärder för en rad är normalt atomiska med en enda kolumnserie, även om vissa implementeringar ger atomicitet över hela raden, som sträcker sig över flera kolumnserier.
Azure-tjänster
Arbetsbelastning
- De flesta kolumnseriedatabaser utför skrivåtgärder mycket snabbt.
- Uppdaterings- och borttagningsåtgärder är ovanliga.
- Utformade för att ge högt dataflöde och åtkomst med kort svarstid.
- Stöder enkel frågeåtkomst till en viss uppsättning fält inom en mycket större post.
- Stora möjligheter till skalning.
Datatyp
- Data lagras i tabeller som består av en nyckelkolumn och en eller flera kolumnserier.
- Vissa kolumner kan variera efter enskilda rader.
- Enskilda celler går att komma åt via get- och put-kommandon
- Flera rader returneras med ett skanningskommando.
Exempel
- Rekommendationer
- Personanpassning
- Sensordata
- Telemetri
- Meddelandefunktion
- Analys av sociala medier
- Webbanalys
- Aktivitetsövervakning
- Väder och andra Time Series-data
Sökmotordatabaser
Med en sökmotordatabas kan program söka efter information som lagras i externa datalager. En sökmotordatabas kan indexerar stora mängder data och ge nästan realtidsåtkomst till dessa index.
Index kan vara flerdimensionella och kan stödja fritextsökningar över stora textdatavolymer. Indexering kan utföras med hjälp av en pull-modell, som utlöses av sökmotordatabasen, eller en push-modell som initieras av extern programkod.
Sökningen kan vara exakt eller fuzzy. En fuzzy-sökning söker efter dokument som matchar en uppsättning villkor och beräknar hur väl de matchar. En del sökmotorer har även stöd för språklig analys som kan ge träffar baserat på synonymer, utökningar av genre (till exempel matchning av dogs till pets) och ordstamsigenkänning (matchning av ord med samma rot).
Azure-tjänst
Arbetsbelastning
- Dataindex från flera källor och tjänster.
- Frågor är ad hoc och kan vara komplexa.
- Fulltextsökning krävs.
- Ad hoc-självbetjäningsfråga krävs.
Datatyp
- Halvstrukturerad eller ostrukturerad text
- Text med hänvisning till strukturerade data
Exempel
- Produktkataloger
- Webbplatssökning
- Loggning
Tidsseriedatabaser
Tidsseriedata är en uppsättning värden ordnade efter tid. Tidsseriedatabaser samlar vanligtvis in stora mängder data i realtid från ett stort antal källor. Uppdateringar sker sällan och borttagningar utförs ofta som massåtgärder. Även om de poster som skrivs till en tidsseriedatabas normalt är små finns det ofta ett stort antal poster, och den totala datamängden kan växa snabbt.
Azure-tjänst
Arbetsbelastning
- Poster läggs normalt till sekventiellt i tidsordning.
- En överväldigande andel av åtgärderna (95–99 %) är skrivningar.
- Uppdateringar sker sällan.
- Borttagningar sker som massborttagning och görs på sammanhängande block eller poster.
- Data läss sekventiellt i antingen stigande eller fallande tidsordning, ofta parallellt.
Datatyp
- En tidsstämpel används som primärnyckel och sorteringsmekanism.
- Taggar kan definiera ytterligare information om typen, ursprunget och annan information om posten.
Exempel
- Övervakning och händelsetelemetri.
- Sensor eller andra IoT-data.
Objektlagring
Objektlagring har optimerats för lagring och hämtning av stora binära objekt (bilder, filer, video- och ljudströmmar, stora programdataobjekt och dokument, diskavbildningar för virtuella datorer). Stora datafiler används också populärt i den här modellen, till exempel avgränsningsfil (CSV), parquet och ORC. Objektlager kan hantera extremt stora mängder ostrukturerade data.
Azure-tjänst
Arbetsbelastning
- Identifieras av nyckel.
- Innehåll är vanligtvis en tillgång, till exempel en avgränsare, bild eller videofil.
- Innehållet måste vara beständigt och externt till alla programnivåer.
Datatyp
- Datastorleken är stor.
- Värdet är täckande.
Exempel
- Bilder, videor, Office-dokument, PDF-filer
- Statisk HTML, JSON, CSS
- Logg- och granskningsfiler
- Säkerhetskopior av databasen
Delade filer
Ibland kan flata filer vara det mest effektiva sättet att lagra och hämta information. Genom att använda filresurser är det möjligt att komma åt filer över ett nätverk. Med rätt metoder för säkerhet och samtidig åtkomstkontroll kan delning av data på detta sätt göra det möjligt för distribuerade tjänster att tillhandahålla mycket skalbar dataåtkomst för att utföra grundläggande åtgärder på låg nivå, t.ex. enkla läs- och skrivförfrågningar.
Azure-tjänst
Arbetsbelastning
- Migrering från befintliga appar som samverkar med filsystemet.
- Kräver SMB-gränssnitt.
Datatyp
- Filer i en hierarkisk uppsättning med mappar.
- Tillgängligt med I/O-bibliotek av standardtyp.
Exempel
- Äldre filer
- Delat innehåll som är tillgängligt mellan ett antal virtuella datorer eller appinstanser
Med hjälp av den här förståelsen av olika datalagringsmodeller är nästa steg att utvärdera din arbetsbelastning och ditt program och bestämma vilket datalager som ska uppfylla dina specifika behov. Använd beslutsträdet för datalagring för att hjälpa till med den här processen.
Nästa steg
- Lösningar och tjänster för Azure Cloud Storage
- Granska dina lagringsalternativ
- Introduktion till Azure Storage
- Introduktion till Azure Data Explorer