Den här artikeln beskriver hur ett utvecklingsteam använde mått för att hitta flaskhalsar och förbättra prestandan för ett distribuerat system. Artikeln baseras på faktisk belastningstestning som vi gjorde för ett exempelprogram. Programmet kommer från aks-baslinjen (Azure Kubernetes Service) för mikrotjänster.
Den här artikeln ingår i en serie. Läs den första delen här.
Scenario: Ett klientprogram initierar en affärstransaktion som omfattar flera steg.
Det här scenariot omfattar ett drönarleveransprogram som körs på AKS. Kunder använder en webbapp för att schemalägga leveranser med drönare. Varje transaktion kräver flera steg som utförs av separata mikrotjänster på serverdelen:
- Leveranstjänsten hanterar leveranser.
- Drone Scheduler-tjänsten schemalägger drönare för upphämtning.
- Pakettjänsten hanterar paket.
Det finns två andra tjänster: en inmatningstjänst som accepterar klientbegäranden och placerar dem i en kö för bearbetning och en arbetsflödestjänst som samordnar stegen i arbetsflödet.
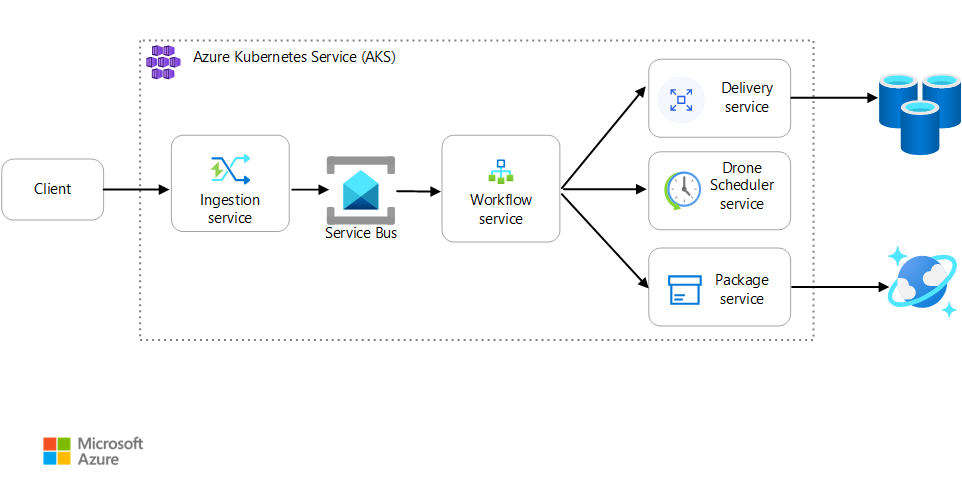
Mer information om det här scenariot finns i Designa en mikrotjänstarkitektur.
Test 1: Baslinje
För det första belastningstestet skapade teamet ett AKS-kluster med sex noder och distribuerade tre repliker av varje mikrotjänst. Belastningstestet var ett steg-belastningstest, med början hos två simulerade användare och upp till 40 simulerade användare.
| Inställningen | Värde |
|---|---|
| Klusternoder | 6 |
| Skida | 3 per tjänst |
Följande diagram visar resultatet av belastningstestet, som du ser i Visual Studio. Den lila linjen ritar användarbelastningen och den orange linjen ritar totalt antal begäranden.
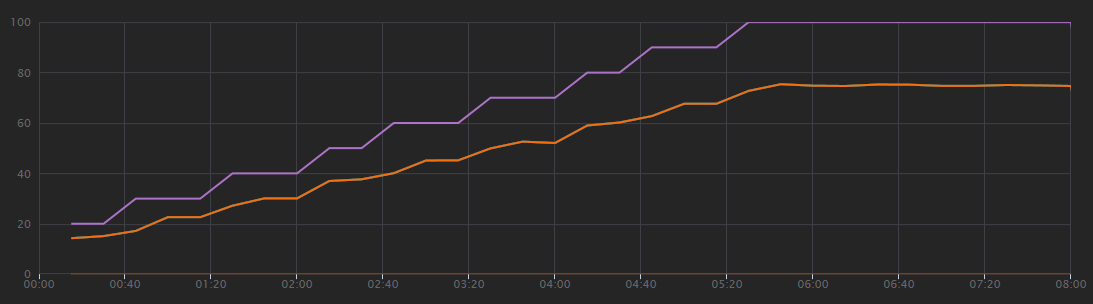
Det första du bör inse i det här scenariot är att klientbegäranden per sekund inte är ett användbart prestandamått. Det beror på att programmet bearbetar begäranden asynkront, så klienten får ett svar direkt. Svarskoden är alltid HTTP 202 (accepterad), vilket innebär att begäran accepterades men bearbetningen är inte slutförd.
Vad vi verkligen vill veta är om serverdelen håller jämna steg med begärandefrekvensen. Service Bus-kön kan absorbera toppar, men om serverdelen inte kan hantera en varaktig belastning hamnar bearbetningen längre och längre efter.
Här är ett mer informativt diagram. Den ritar antalet inkommande och utgående meddelanden i Service Bus-kön. Inkommande meddelanden visas i ljusblå och utgående meddelanden visas i mörkblå:
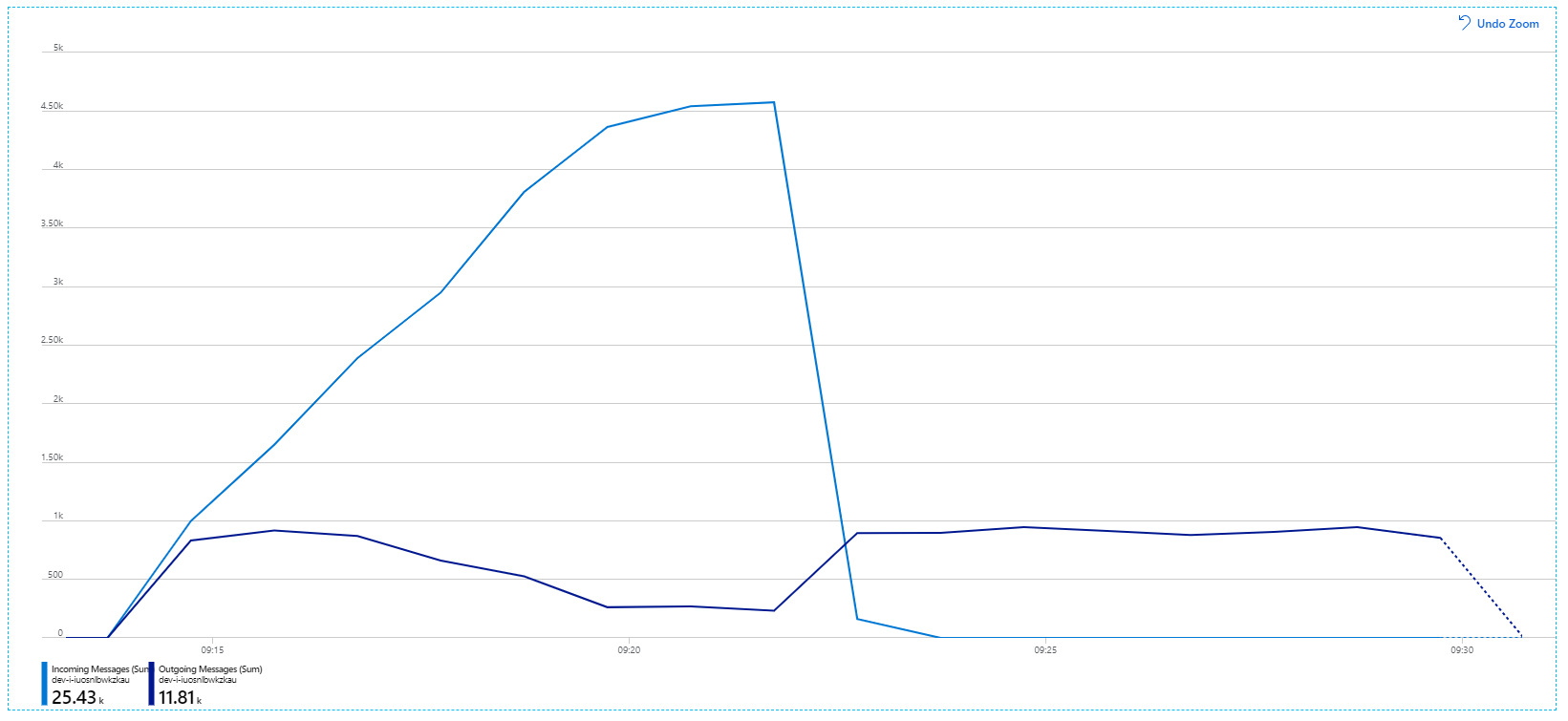
Det här diagrammet visar att hastigheten för inkommande meddelanden ökar, når en topp och sedan sjunker tillbaka till noll i slutet av belastningstestet. Men antalet utgående meddelanden når sin kulmen tidigt i testet och sjunker sedan faktiskt. Det innebär att arbetsflödestjänsten, som hanterar begäranden, inte hänger med. Även när belastningstestet är slut (runt 9:22 i diagrammet) bearbetas fortfarande meddelanden när arbetsflödestjänsten fortsätter att tömma kön.
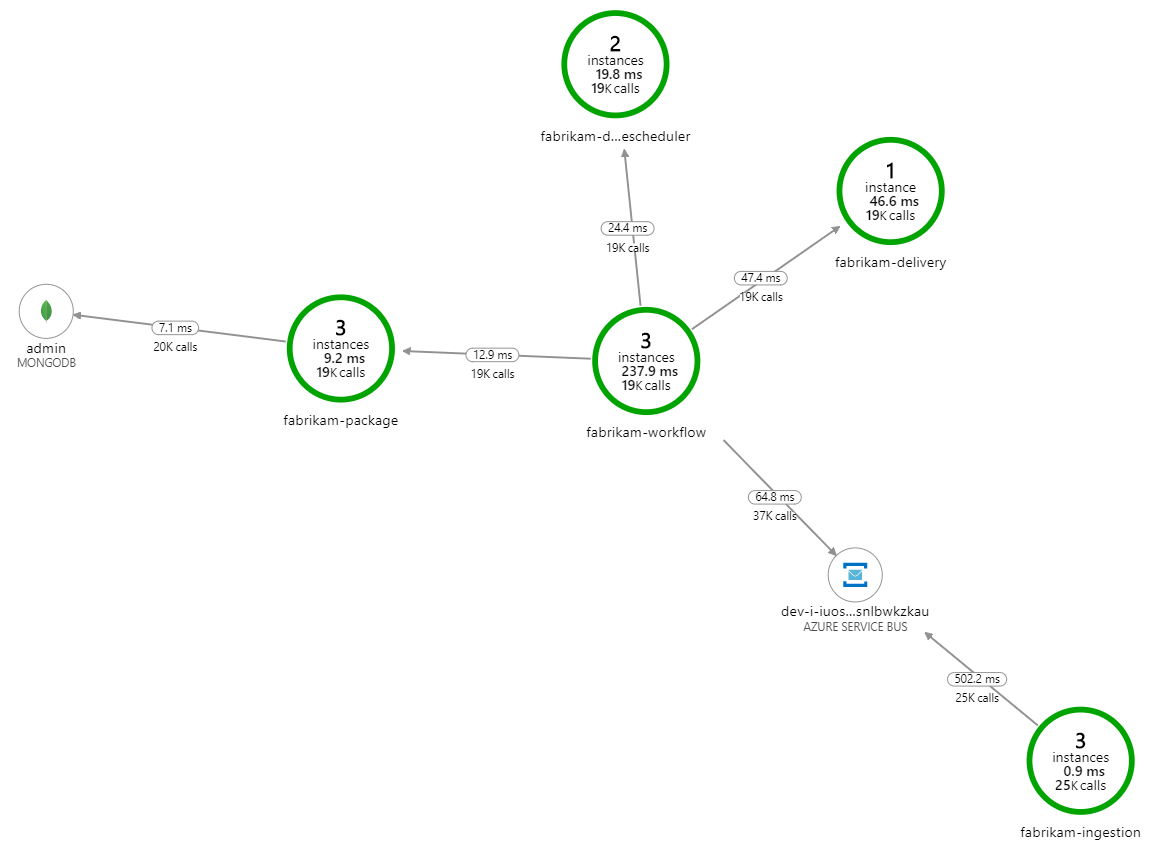
Vad gör bearbetningen långsammare? Det första du bör leta efter är fel eller undantag som kan tyda på ett systematiskt problem. Programkartan i Azure Monitor visar diagrammet över anrop mellan komponenter och är ett snabbt sätt att upptäcka problem och klicka sedan på för att få mer information.
Programkartan visar att arbetsflödestjänsten får fel från leveranstjänsten:
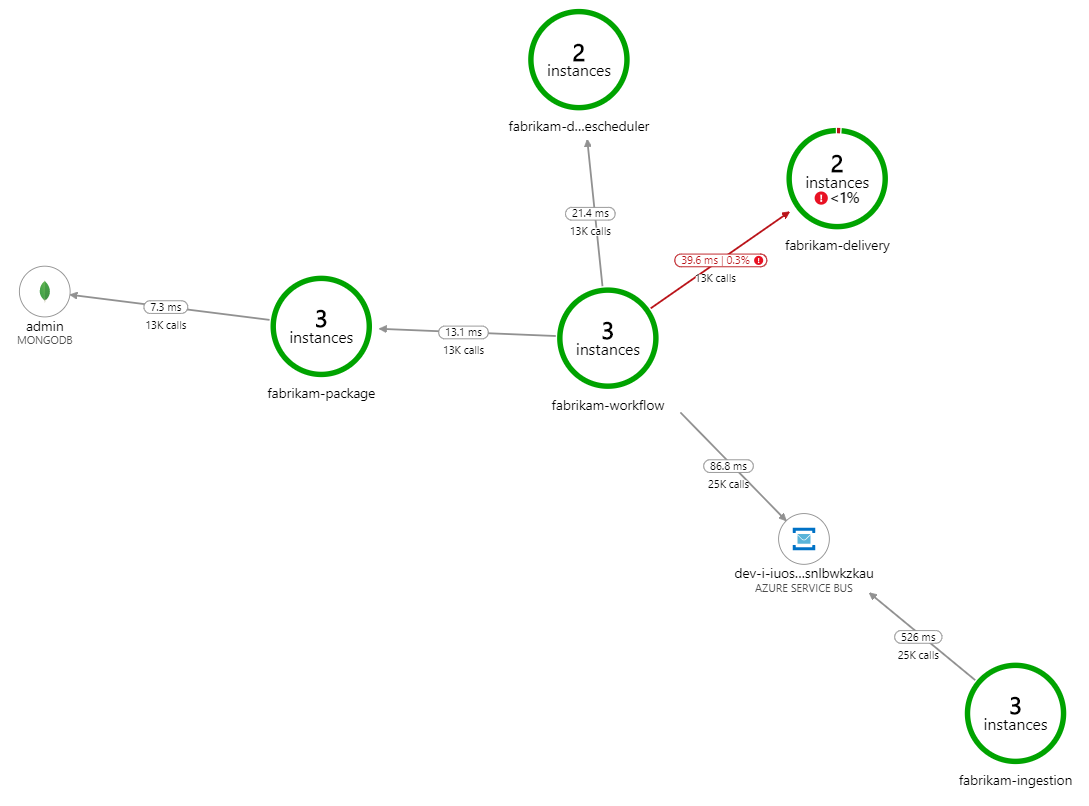
Om du vill se mer information kan du välja en nod i diagrammet och klicka i en transaktionsvy från slutpunkt till slutpunkt. I det här fallet visar det att leveranstjänsten returnerar HTTP 500-fel. Felmeddelandena anger att ett undantag utlöses på grund av minnesgränser i Azure Cache for Redis.
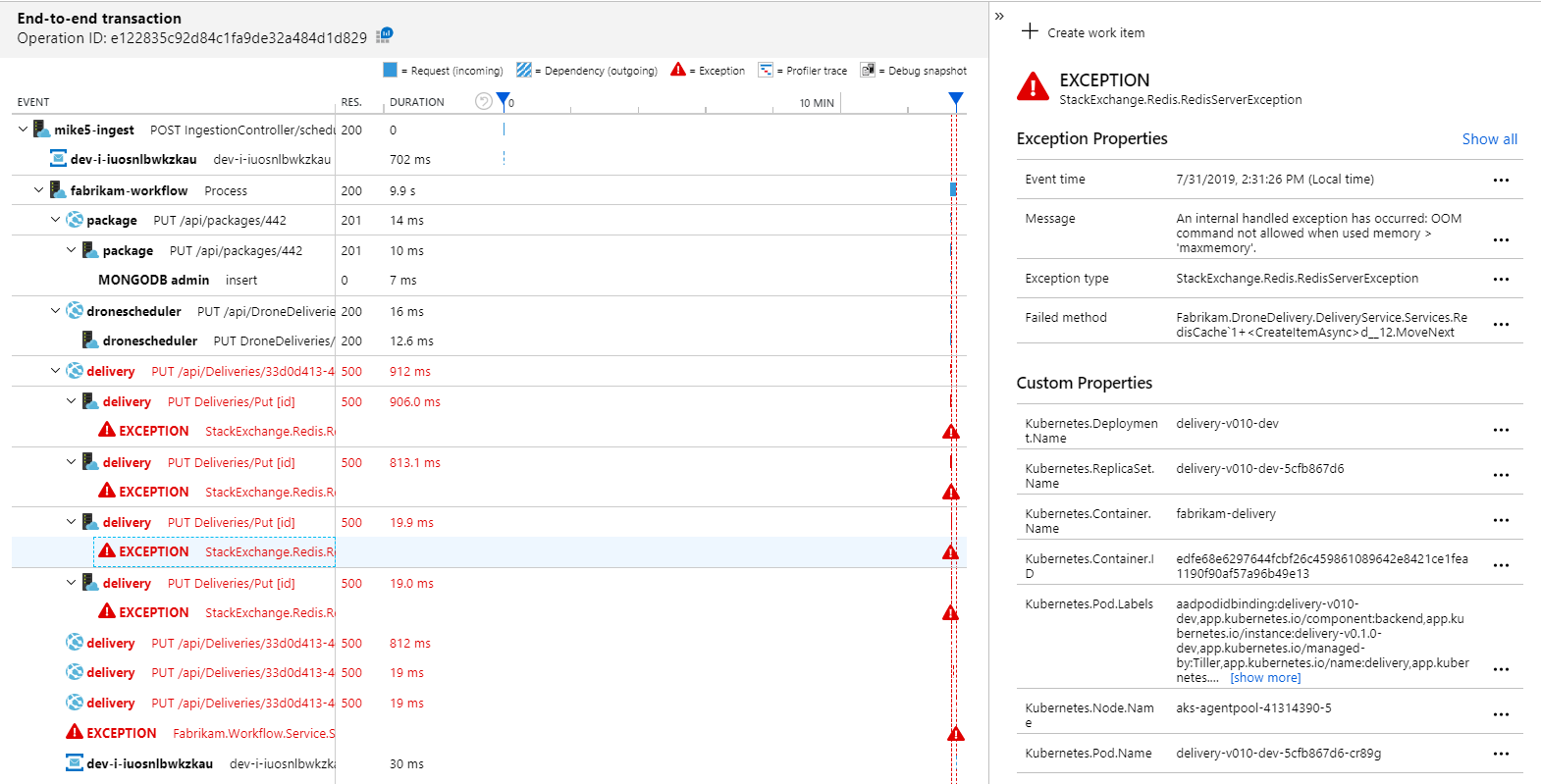
Du kanske märker att dessa anrop till Redis inte visas på programkartan. Det beror på att .NET-biblioteket för Application Insights inte har inbyggt stöd för att spåra Redis som ett beroende. (En lista över vad som stöds finns i Automatisk insamling av beroenden.) Som reserv kan du använda TrackDependency-API :et för att spåra eventuella beroenden. Belastningstestning visar ofta den här typen av luckor i telemetrin, som kan åtgärdas.
Test 2: Ökad cachestorlek
För det andra belastningstestet ökade utvecklingsteamet cachestorleken i Azure Cache for Redis. (Se Skala Azure Cache for Redis.) Den här ändringen löste undantagen om slut på minne och nu visar programkartan noll fel:
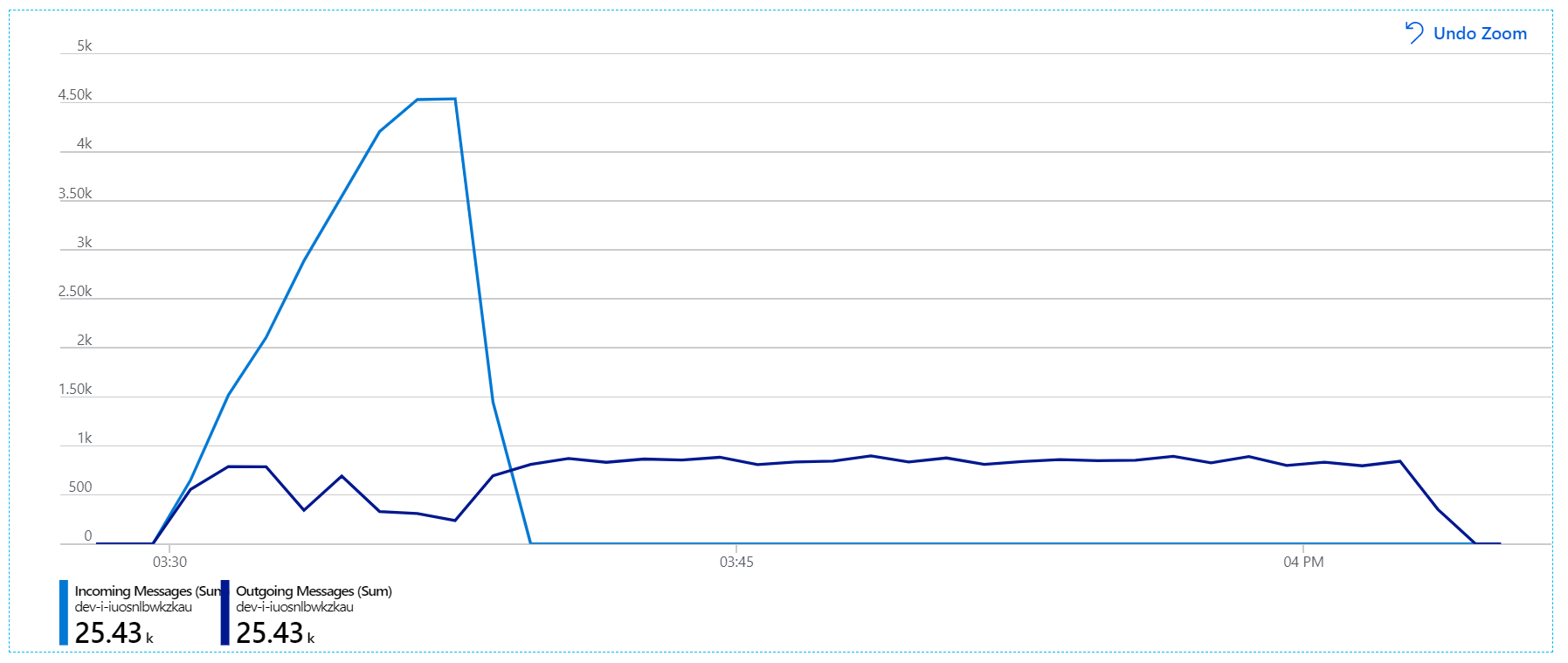
Det finns dock fortfarande en dramatisk fördröjning i bearbetningen av meddelanden. Vid belastningstestets topp är inkommande meddelandefrekvens mer än 5× utgående hastighet:
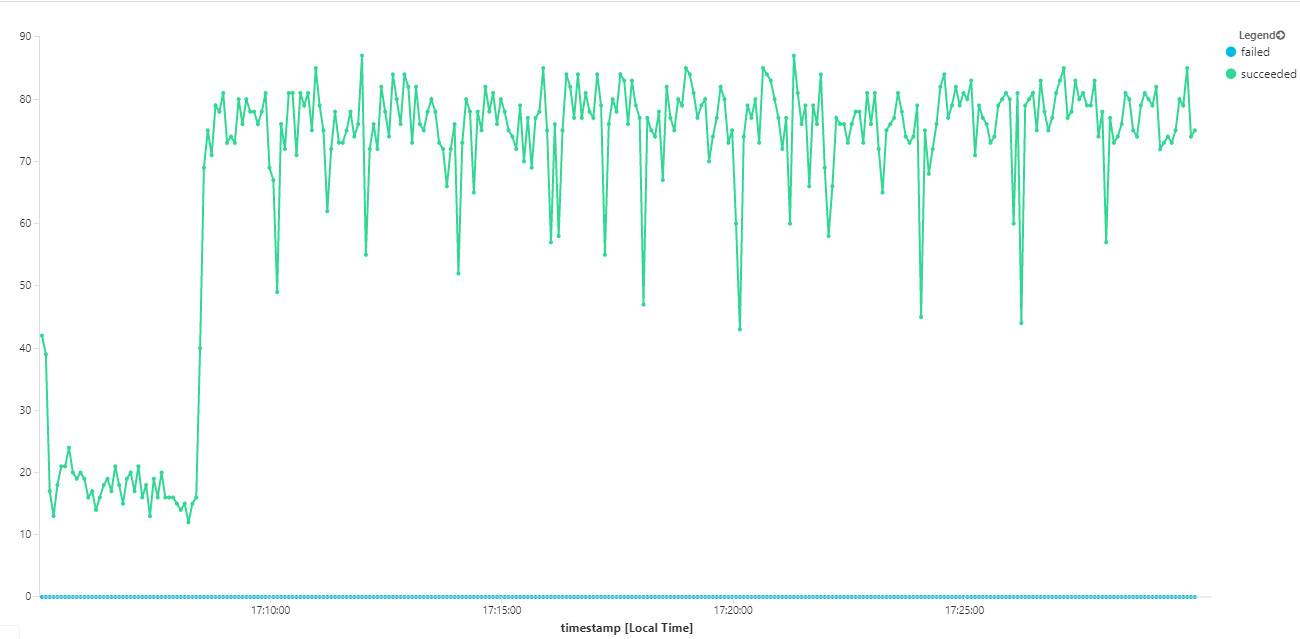
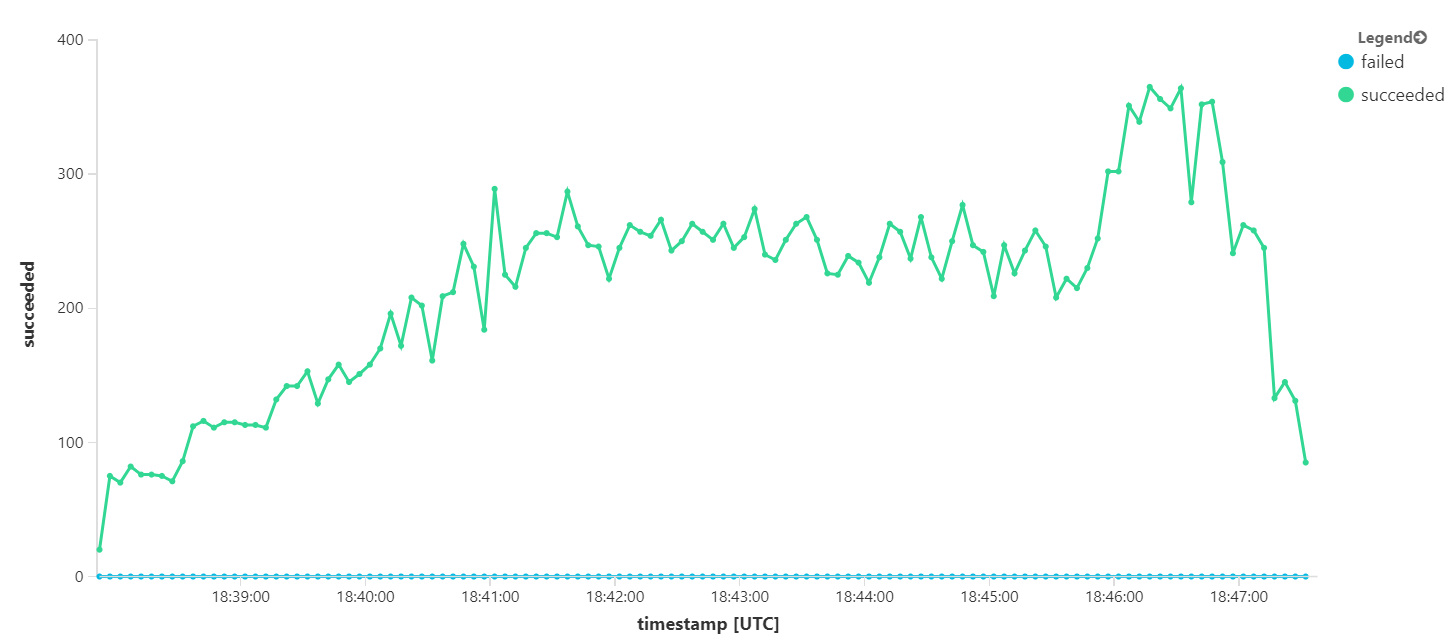
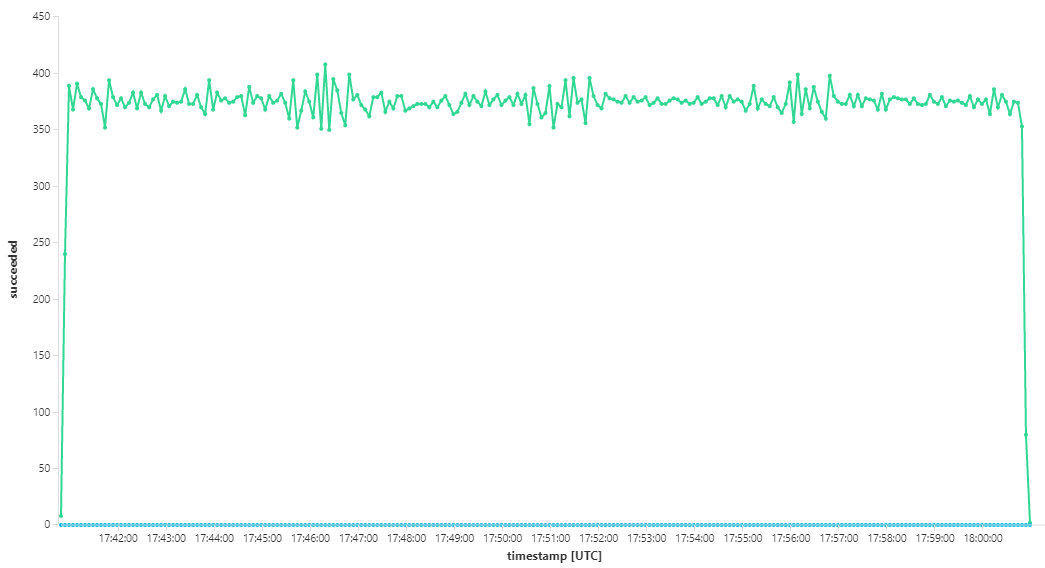
I följande diagram mäts dataflödet när det gäller slutförande av meddelanden, dvs. den hastighet med vilken arbetsflödestjänsten markerar Service Bus-meddelandena som slutförda. Varje punkt i diagrammet representerar 5 sekunders data, vilket visar maximalt dataflöde på ~16 per sekund.
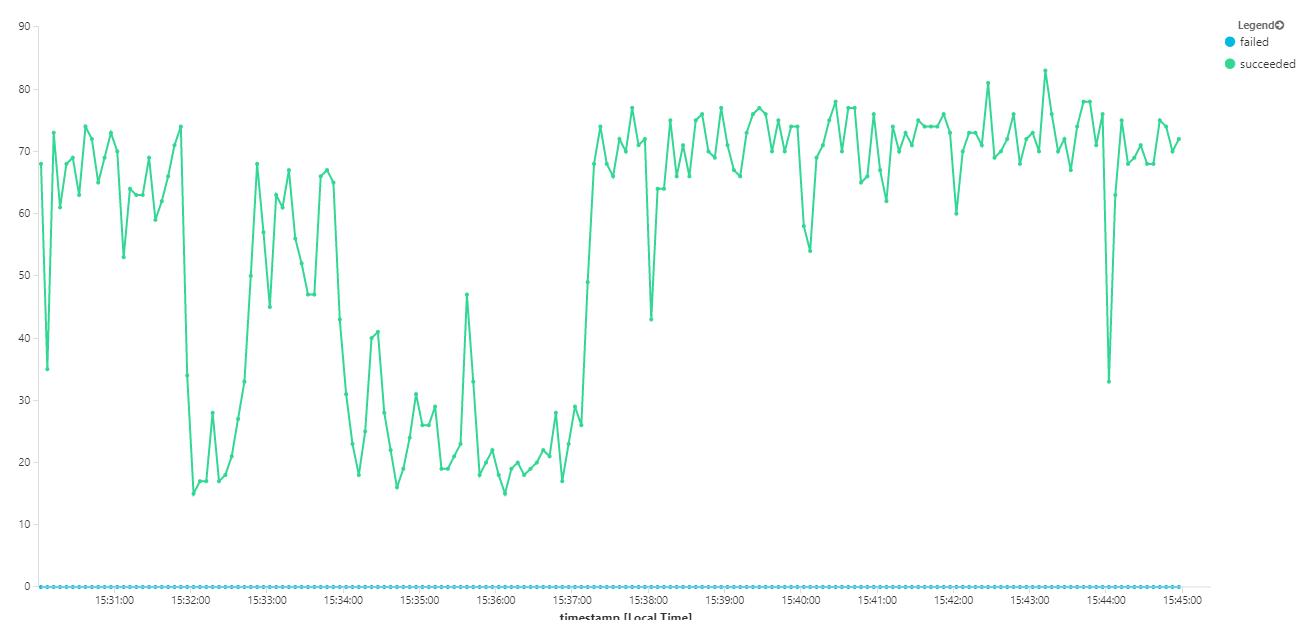
Det här diagrammet genererades genom att köra en fråga på Log Analytics-arbetsytan med hjälp av Kusto-frågespråket:
let start=datetime("2020-07-31T22:30:00.000Z");
let end=datetime("2020-07-31T22:45:00.000Z");
dependencies
| where cloud_RoleName == 'fabrikam-workflow'
| where timestamp > start and timestamp < end
| where type == 'Azure Service Bus'
| where target has 'https://dev-i-iuosnlbwkzkau.servicebus.windows.net'
| where client_Type == "PC"
| where name == "Complete"
| summarize succeeded=sumif(itemCount, success == true), failed=sumif(itemCount, success == false) by bin(timestamp, 5s)
| render timechart
Test 3: Skala ut serverdelstjänsterna
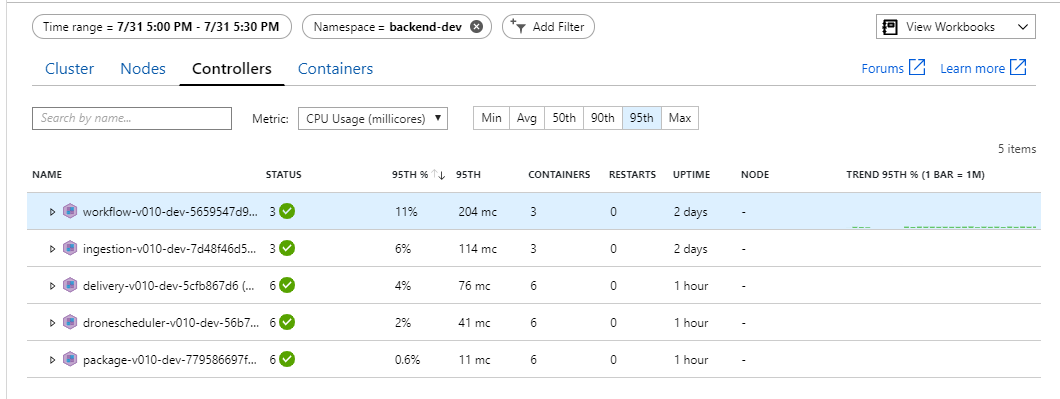
Det verkar som om serverdelen är flaskhalsen. Ett enkelt nästa steg är att skala ut affärstjänsterna (paket, leverans och Drone Scheduler) och se om dataflödet förbättras. För nästa belastningstest skalade teamet ut dessa tjänster från tre repliker till sex repliker.
| Inställningen | Värde |
|---|---|
| Klusternoder | 6 |
| Inmatningstjänst | 3 repliker |
| Arbetsflödestjänst | 3 repliker |
| Package, Delivery, Drone Scheduler services | 6 repliker vardera |
Tyvärr visar det här belastningstestet bara en blygsam förbättring. Utgående meddelanden håller fortfarande inte jämna steg med inkommande meddelanden:
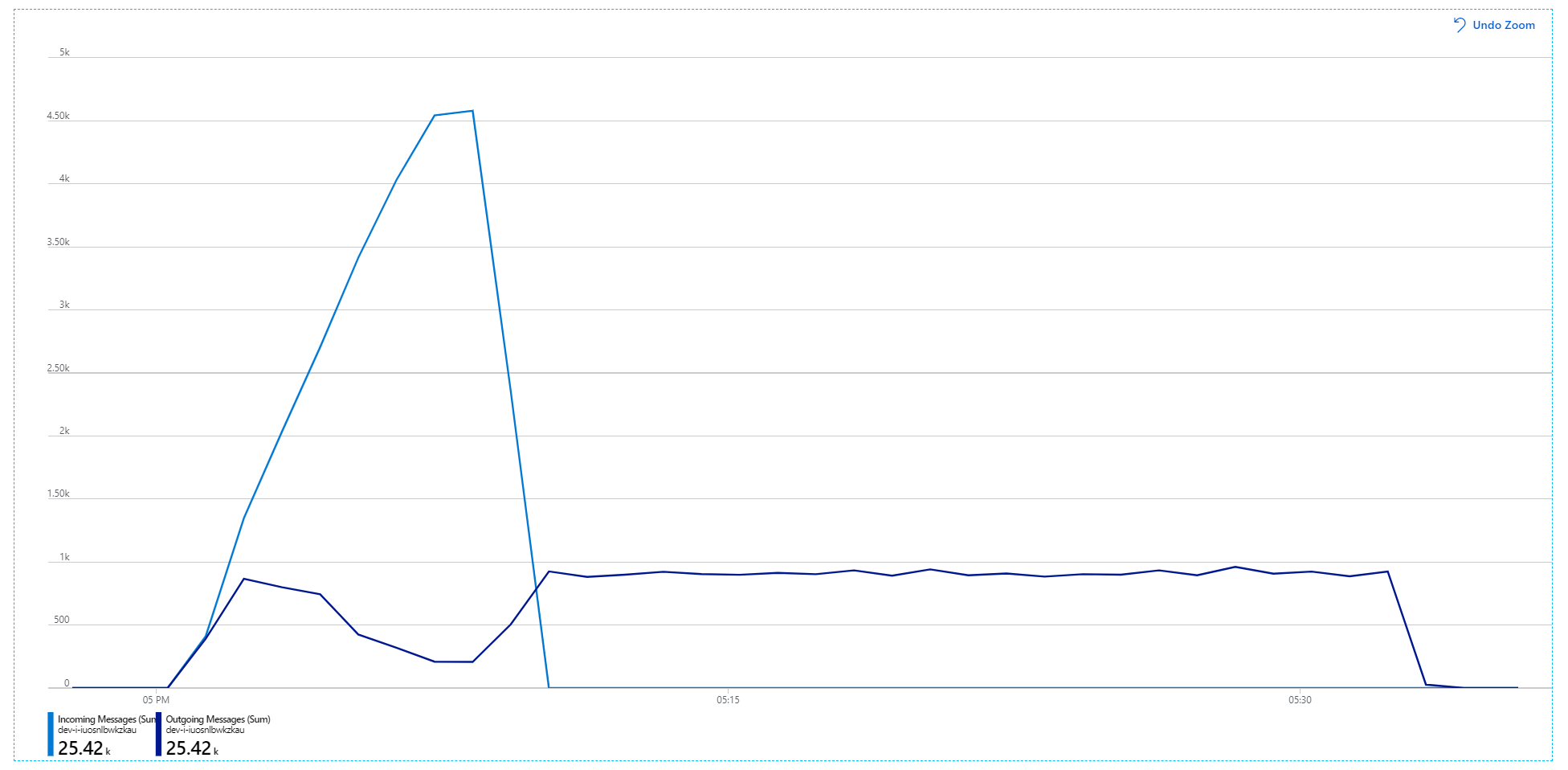
Dataflödet är mer konsekvent, men det maximala uppnådda är ungefär samma som föregående test:
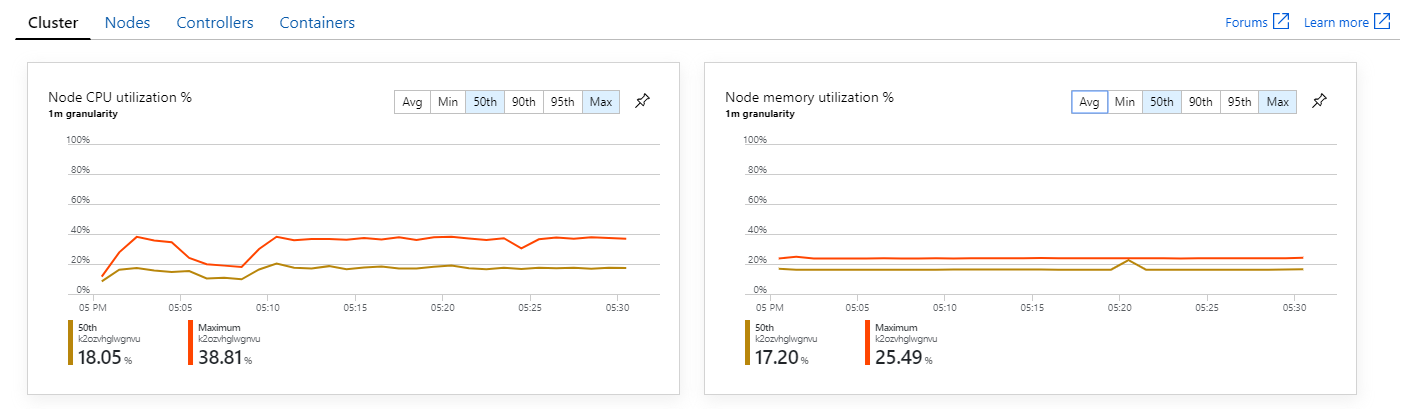
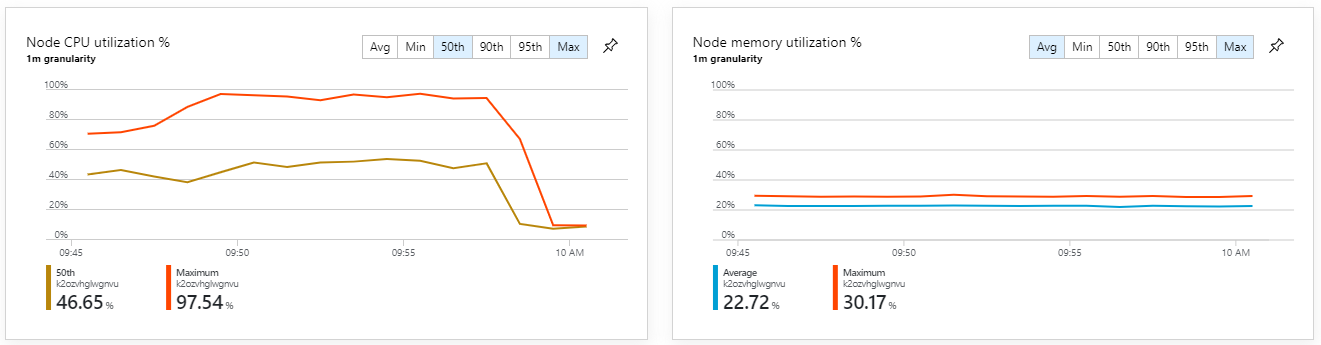
Om du tittar på Azure Monitor-containerinsikter verkar problemet inte orsakas av resursöverbelastning i klustret. För det första visar måtten på nodnivå att processoranvändningen förblir under 40 % även vid den 95:e percentilen, och minnesanvändningen är cirka 20 %.
I en Kubernetes-miljö är det möjligt att enskilda poddar är resursbegränsade även när noderna inte är det. Men vyn på poddnivå visar att alla poddar är felfria.
Från det här testet verkar det som om det inte hjälper att bara lägga till fler poddar i serverdelen. Nästa steg är att titta närmare på arbetsflödestjänsten för att förstå vad som händer när meddelanden bearbetas. Application Insights visar att den genomsnittliga varaktigheten för arbetsflödestjänstens Process åtgärd är 246 ms.
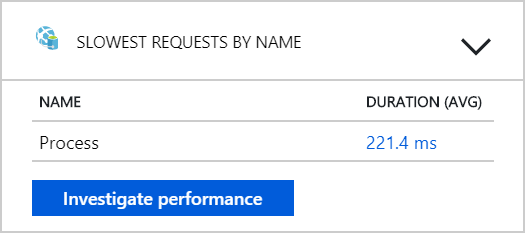
Vi kan också köra en fråga för att hämta mått för de enskilda åtgärderna inom varje transaktion:
| Mål | percentile_duration_50 | percentile_duration_95 |
|---|---|---|
https://dev-i-iuosnlbwkzkau.servicebus.windows.net/ | dev-i-iuosnlbwkzkau |
86.66950203 | 283.4255578 |
| leverans | 37 | 57 |
| package | 12 | 17 |
| dronecheduler | 21 | 41 |
Den första raden i den här tabellen representerar Service Bus-kön. De andra raderna är anropen till serverdelstjänsterna. Här är Log Analytics-frågan för den här tabellen som referens:
let start=datetime("2020-07-31T22:30:00.000Z");
let end=datetime("2020-07-31T22:45:00.000Z");
let dataset=dependencies
| where timestamp > start and timestamp < end
| where (cloud_RoleName == 'fabrikam-workflow')
| where name == 'Complete' or target in ('package', 'delivery', 'dronescheduler');
dataset
| summarize percentiles(duration, 50, 95) by target
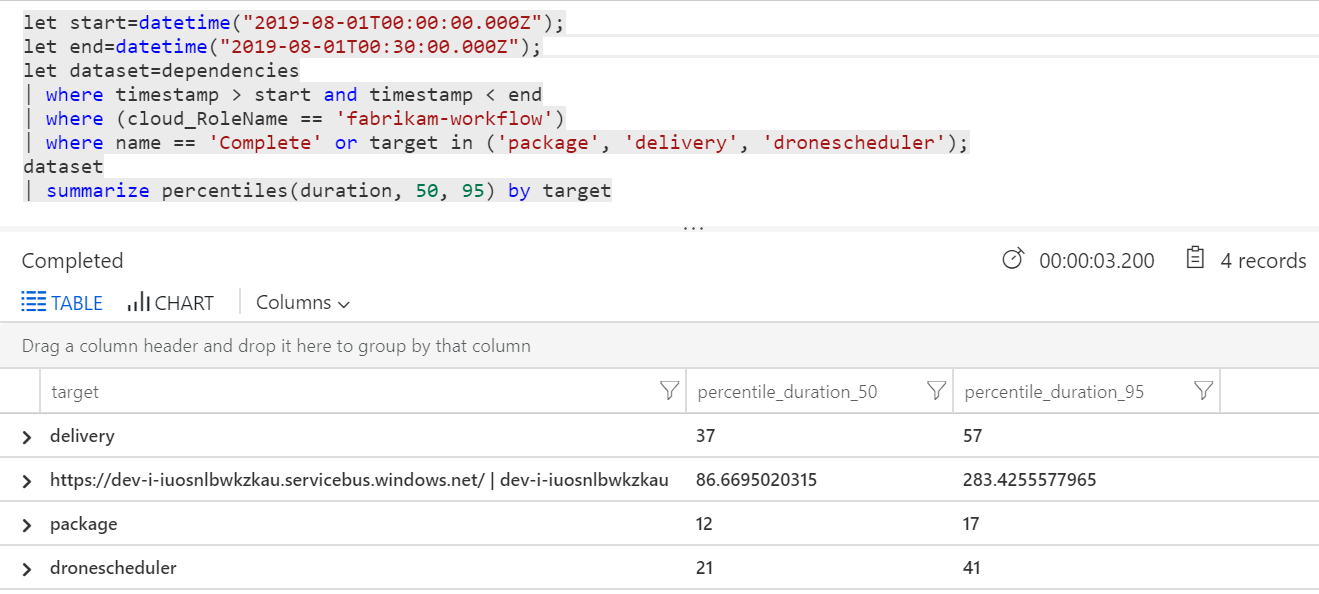
De här svarstiderna ser rimliga ut. Men här är den viktigaste insikten: Om den totala åtgärdstiden är ~250 ms, sätter det en strikt övre gräns för hur snabbt meddelanden kan bearbetas i seriellt. Nyckeln till att förbättra dataflödet är därför större parallellitet.
Det bör vara möjligt i det här scenariot av två skäl:
- Det här är nätverksanrop, så merparten av tiden ägnas åt att vänta på I/O-slutförande
- Meddelandena är oberoende och behöver inte bearbetas i ordning.
Test 4: Öka parallelliteten
I det här testet fokuserade teamet på att öka parallelliteten. För att göra det justerade de två inställningar på Service Bus-klienten som används av arbetsflödestjänsten:
| Inställningen | Beskrivning | Standardvärde | Nytt värde |
|---|---|---|---|
MaxConcurrentCalls |
Det maximala antalet meddelanden som ska bearbetas samtidigt. | 1 | 20 |
PrefetchCount |
Hur många meddelanden klienten hämtar i förväg till sin lokala cache. | 0 | 3000 |
Mer information om de här inställningarna finns i Metodtips för prestandaförbättringar med service bus-meddelanden. När testet kördes med de här inställningarna skapades följande diagram:
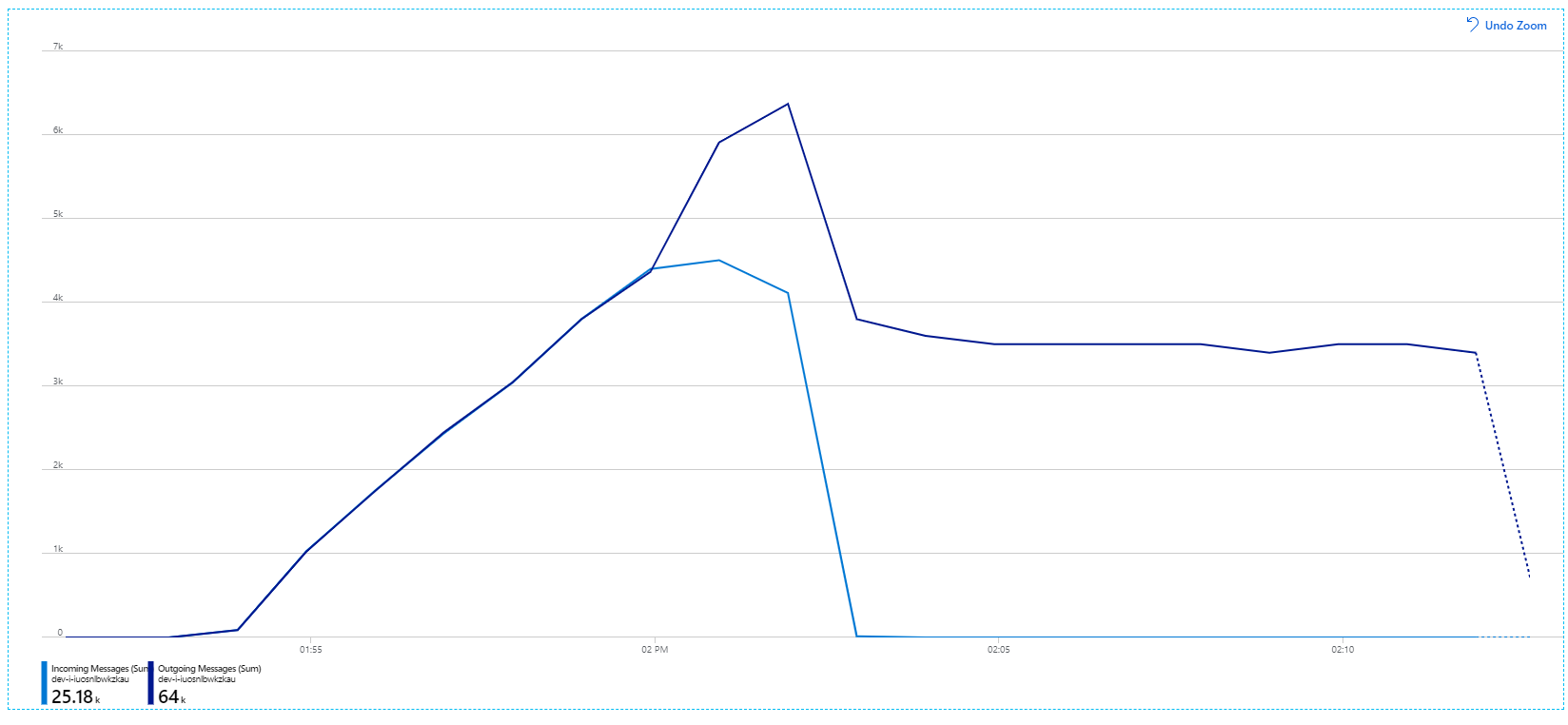
Kom ihåg att inkommande meddelanden visas i ljusblå, och utgående meddelanden visas i mörkblå.
Vid första anblicken är detta en mycket konstig graf. Ett tag spårar den utgående meddelandefrekvensen exakt den inkommande hastigheten. Men sedan, vid ungefär 2:03-märket, planar hastigheten för inkommande meddelanden ut, medan antalet utgående meddelanden fortsätter att öka, vilket faktiskt överstiger det totala antalet inkommande meddelanden. Det verkar omöjligt.
Ledtråden till det här mysteriet finns i vyn Beroenden i Application Insights. Det här diagrammet sammanfattar alla anrop som arbetsflödestjänsten har gjort till Service Bus:
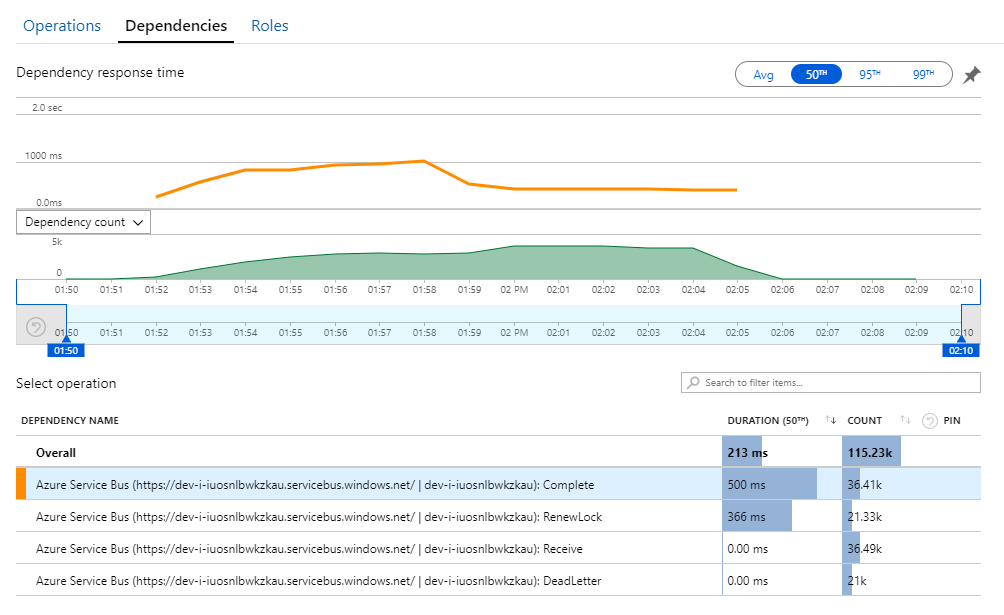
Observera att posten för DeadLetter. Att anrop anger att meddelanden går in i Service Bus-kön med obeställbara meddelanden.
För att förstå vad som händer måste du förstå Peek-Lock-semantik i Service Bus. När en klient använder Peek-Lock hämtar och låser Service Bus ett meddelande atomiskt. Meddelandet levereras garanterat inte till andra mottagare när låset hålls kvar. Om låset upphör att gälla blir meddelandet tillgängligt för andra mottagare. Efter ett maximalt antal leveransförsök (som kan konfigureras) placerar Service Bus meddelandena i en kö med obeställbara meddelanden, där de kan granskas senare.
Kom ihåg att arbetsflödestjänsten förinstallerar stora mängder meddelanden – 3 000 meddelanden i taget). Det innebär att den totala tiden för att bearbeta varje meddelande är längre, vilket resulterar i att meddelanden överskrider tidsgränsen, går tillbaka till kön och slutligen hamnar i kön med obeställbara meddelanden.
Du kan också se det här beteendet i undantagen, där flera MessageLostLockException undantag registreras:
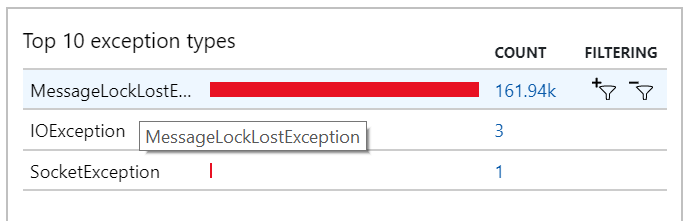
Test 5: Öka låsvaraktigheten
För det här belastningstestet har meddelandelåsets varaktighet angetts till 5 minuter för att förhindra tidsgränser för lås. Diagrammet över inkommande och utgående meddelanden visar nu att systemet håller jämna steg med hastigheten för inkommande meddelanden:
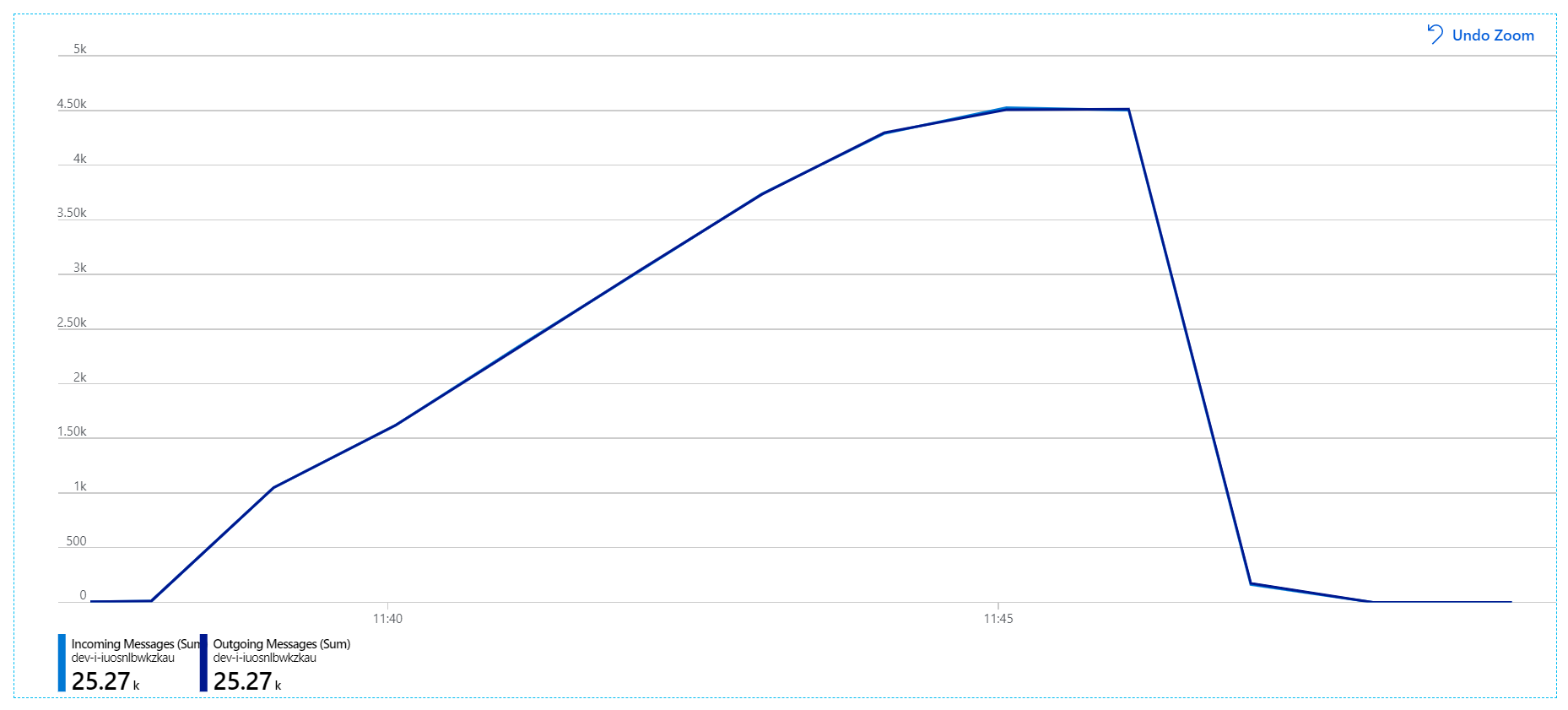
Under den totala varaktigheten för belastningstestet på 8 minuter slutförde programmet 25 K-åtgärder, med ett högsta dataflöde på 72 åtgärder/sek, vilket motsvarar en ökning på 400 % i maximalt dataflöde.
Men att köra samma test med en längre varaktighet visade att programmet inte kunde upprätthålla den här hastigheten:
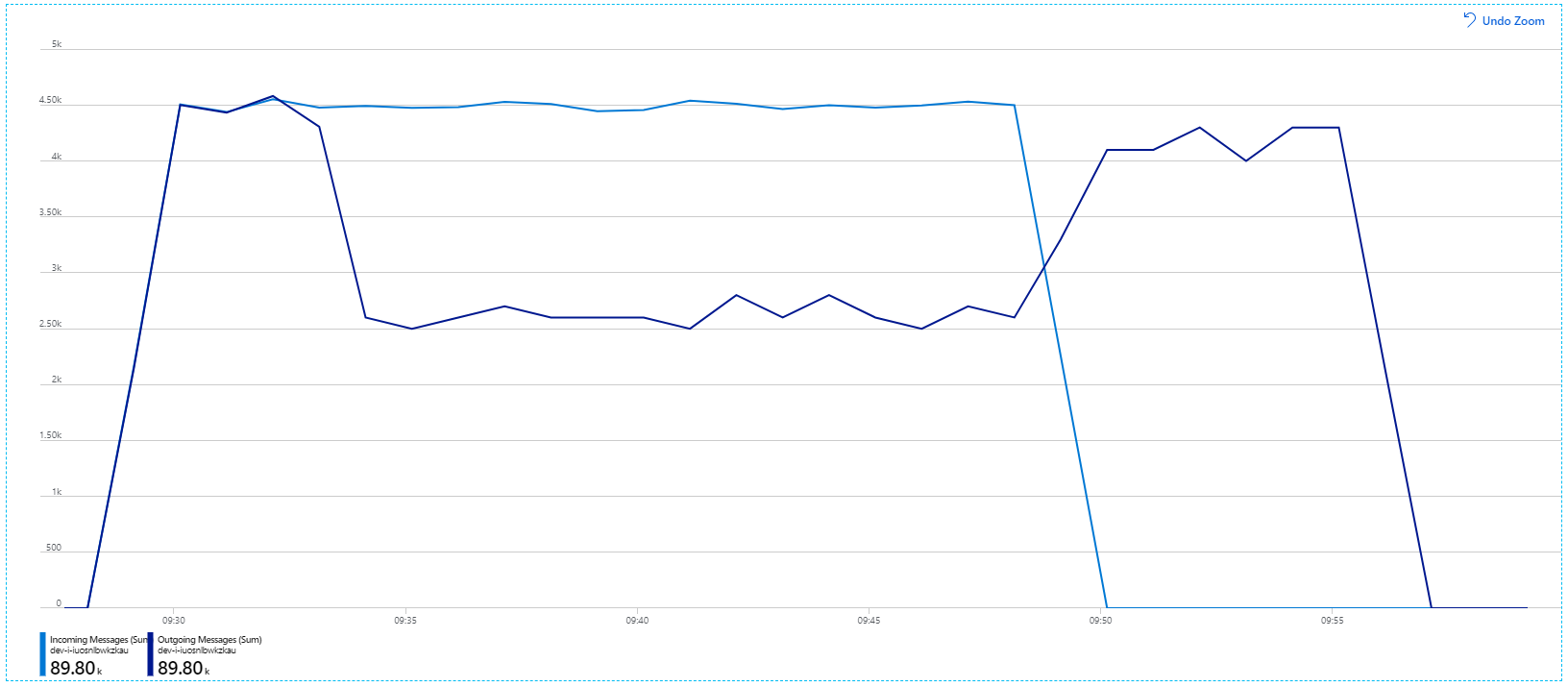
Containermåtten visar att den maximala CPU-användningen var nära 100 %. Nu verkar programmet vara CPU-bundet. Skalning av klustret kan förbättra prestanda nu, till skillnad från föregående försök att skala ut.
Test 6: Skala ut serverdelstjänsterna (igen)
För det sista belastningstestet i serien skalade teamet ut Kubernetes-klustret och poddarna på följande sätt:
| Inställning | Värde |
|---|---|
| Klusternoder | 12 |
| Inmatningstjänst | 3 repliker |
| Arbetsflödestjänst | 6 repliker |
| Package, Delivery, Drone Scheduler services | 9 repliker vardera |
Det här testet resulterade i ett högre varaktigt dataflöde, utan några betydande fördröjningar i bearbetningen av meddelanden. Dessutom låg processoranvändningen för noder under 80 %.
Sammanfattning
I det här scenariot identifierades följande flaskhalsar:
- Minnesfel i Azure Cache for Redis.
- Brist på parallellitet i meddelandebearbetningen.
- Otillräcklig varaktighet för meddelandelås, vilket leder till att tidsgränser för lås och meddelanden placeras i kön med obeställbara meddelanden.
- CPU-överbelastning.
För att diagnostisera dessa problem förlitade sig utvecklingsteamet på följande mått:
- Frekvens för inkommande och utgående Service Bus-meddelanden.
- Programkarta i Application Insights.
- Fel och undantag.
- Anpassade Log Analytics-frågor.
- Processor- och minnesanvändning i Azure Monitor containerinsikter.
Nästa steg
Mer information om utformningen av det här scenariot finns i Designa en arkitektur för mikrotjänster.