Flytta data till vFXT-klustret – Parallell datamatning
När du har skapat ett nytt vFXT-kluster kan din första uppgift vara att flytta data till en ny lagringsvolym i Azure. Men om din vanliga metod för att flytta data utfärdar ett enkelt kopieringskommando från en klient, kommer du sannolikt att se en långsam kopieringsprestanda. Entrådad kopiering är inte ett bra alternativ för att kopiera data till Avere vFXT-klustrets serverdelslagring.
Eftersom Avere vFXT för Azure-klustret är en skalbar cache för flera klienter är det snabbaste och mest effektiva sättet att kopiera data till det med flera klienter. Den här tekniken parallelliserar inmatning av filer och objekt.
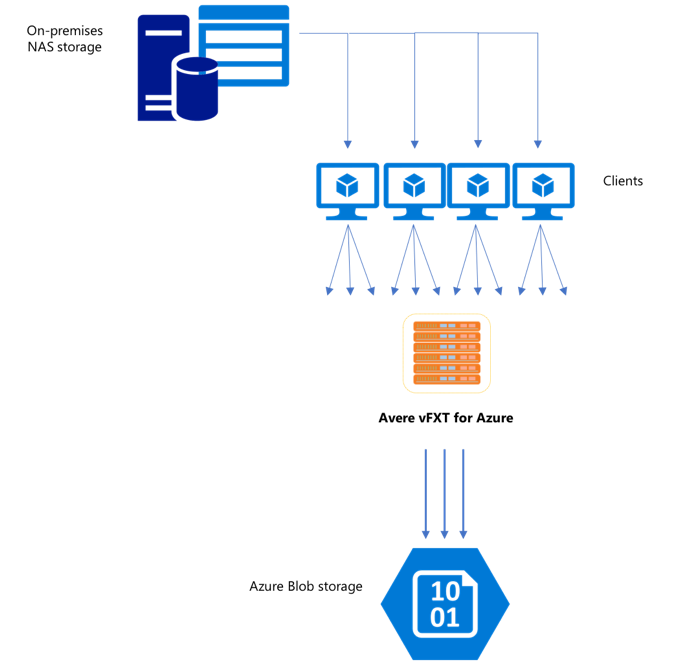
Kommandona cp eller copy som ofta används för att överföra data från ett lagringssystem till ett annat är entrådade processer som endast kopierar en fil i taget. Det innebär att filservern bara matar in en fil i taget, vilket är slöseri med klustrets resurser.
Den här artikeln beskriver strategier för att skapa ett system för kopiering av flera klienter med flera trådar för att flytta data till Avere vFXT-klustret. Den förklarar filöverföringsbegrepp och beslutspunkter som kan användas för effektiv datakopiering med flera klienter och enkla kopieringskommandon.
Det förklarar också några verktyg som kan hjälpa. Verktyget msrsync kan användas för att delvis automatisera processen att dela upp en datamängd i bucketar och använda rsync kommandon. Skriptet parallelcp är ett annat verktyg som läser källkatalogen och utfärdar kopieringskommandon automatiskt. rsync Verktyget kan också användas i två faser för att tillhandahålla en snabbare kopia som fortfarande ger datakonsekvens.
Klicka på länken för att gå till ett avsnitt:
- Exempel på manuell kopiering – En grundlig förklaring med hjälp av kopieringskommandon
- Exempel på tvåfasrsync
- Delvis automatiserat exempel (msrsync)
- Exempel på parallellkopiering
Mall för virtuell dataingestor-dator
En Resource Manager-mall är tillgänglig på GitHub för att automatiskt skapa en virtuell dator med de parallella datainmatningsverktyg som nämns i den här artikeln.
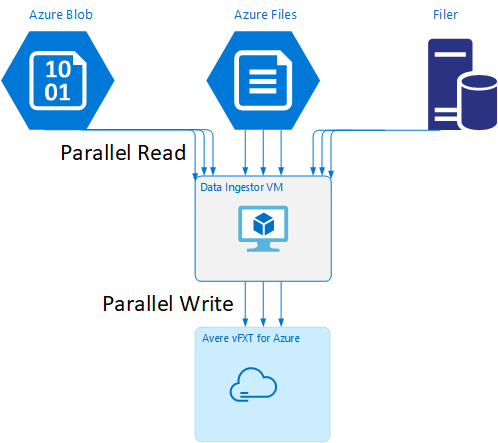
Den virtuella datorn för dataingestor är en del av en självstudiekurs där den nyligen skapade virtuella datorn monterar Avere vFXT-klustret och laddar ned sitt bootstrap-skript från klustret. Mer information finns i Bootstrap a data ingestor VM .
Strategisk planering
När du utformar en strategi för att kopiera data parallellt bör du förstå kompromisserna i filstorlek, filantal och katalogdjup.
- När filerna är små är måttet av intresse filer per sekund.
- När filer är stora (10MiBi eller större) är måttet av intresse byte per sekund.
Varje kopieringsprocess har en dataflödeshastighet och en filöverföringshastighet, som kan mätas genom att tidsbegränsa längden på kopieringskommandot och beräkna filstorleken och antalet filer. Att förklara hur du mäter priserna ligger utanför omfånget för det här dokumentet, men det är viktigt att förstå om du kommer att hantera små eller stora filer.
Exempel på manuell kopiering
Du kan skapa en flertrådad kopia på en klient manuellt genom att köra mer än ett kopieringskommando samtidigt i bakgrunden mot fördefinierade uppsättningar med filer eller sökvägar.
Linux/UNIX-kommandot cp innehåller argumentet -p för att bevara ägarskap och mtime-metadata. Det är valfritt att lägga till det här argumentet i kommandona nedan. (Om du lägger till argumentet ökar antalet filsystemanrop som skickas från klienten till målfilsystemet för metadataändring.)
Det här enkla exemplet kopierar två filer parallellt:
cp /mnt/source/file1 /mnt/destination1/ & cp /mnt/source/file2 /mnt/destination1/ &
När du har utfärdat det här kommandot jobs visar kommandot att två trådar körs.
Förutsägbar filnamnsstruktur
Om dina filnamn är förutsägbara kan du använda uttryck för att skapa parallella kopieringstrådar.
Om katalogen till exempel innehåller 1 000 filer som numreras sekventiellt från 0001 till 1000kan du använda följande uttryck för att skapa tio parallella trådar som varje kopierar 100 filer:
cp /mnt/source/file0* /mnt/destination1/ & \
cp /mnt/source/file1* /mnt/destination1/ & \
cp /mnt/source/file2* /mnt/destination1/ & \
cp /mnt/source/file3* /mnt/destination1/ & \
cp /mnt/source/file4* /mnt/destination1/ & \
cp /mnt/source/file5* /mnt/destination1/ & \
cp /mnt/source/file6* /mnt/destination1/ & \
cp /mnt/source/file7* /mnt/destination1/ & \
cp /mnt/source/file8* /mnt/destination1/ & \
cp /mnt/source/file9* /mnt/destination1/
Okänd filnamnsstruktur
Om din filnamnsstruktur inte är förutsägbar kan du gruppera filer efter katalognamn.
Det här exemplet samlar in hela kataloger som ska skickas till cp kommandon som körs som bakgrundsuppgifter:
/root
|-/dir1
| |-/dir1a
| |-/dir1b
| |-/dir1c
|-/dir1c1
|-/dir1d
När filerna har samlats in kan du köra parallella kopieringskommandon för att rekursivt kopiera underkatalogerna och allt deras innehåll:
cp /mnt/source/* /mnt/destination/
mkdir -p /mnt/destination/dir1 && cp /mnt/source/dir1/* mnt/destination/dir1/ &
cp -R /mnt/source/dir1/dir1a /mnt/destination/dir1/ &
cp -R /mnt/source/dir1/dir1b /mnt/destination/dir1/ &
cp -R /mnt/source/dir1/dir1c /mnt/destination/dir1/ & # this command copies dir1c1 via recursion
cp -R /mnt/source/dir1/dir1d /mnt/destination/dir1/ &
När monteringspunkter ska läggas till
När du har tillräckligt med parallella trådar som går mot en enda målfilsystemmonteringspunkt, kommer det att finnas en punkt där det inte ger mer dataflöde att lägga till fler trådar. (Dataflödet mäts i filer/sekund eller byte/sekund, beroende på din typ av data.) Eller ännu värre, övertrådning kan ibland orsaka en dataflödesförsämring.
När detta händer kan du lägga till monteringspunkter på klientsidan till andra VFXT-kluster-IP-adresser med samma fjärrfilsystemmonteringssökväg:
10.1.0.100:/nfs on /mnt/sourcetype nfs (rw,vers=3,proto=tcp,addr=10.1.0.100)
10.1.1.101:/nfs on /mnt/destination1type nfs (rw,vers=3,proto=tcp,addr=10.1.1.101)
10.1.1.102:/nfs on /mnt/destination2type nfs (rw,vers=3,proto=tcp,addr=10.1.1.102)
10.1.1.103:/nfs on /mnt/destination3type nfs (rw,vers=3,proto=tcp,addr=10.1.1.103)
Genom att lägga till monteringspunkter på klientsidan kan du förgrena ytterligare kopieringskommandon till de ytterligare /mnt/destination[1-3] monteringspunkterna, vilket ger ytterligare parallellitet.
Om dina filer till exempel är mycket stora kan du definiera kopieringskommandona för att använda distinkta målsökvägar och skicka ut fler kommandon parallellt från klienten som utför kopian.
cp /mnt/source/file0* /mnt/destination1/ & \
cp /mnt/source/file1* /mnt/destination2/ & \
cp /mnt/source/file2* /mnt/destination3/ & \
cp /mnt/source/file3* /mnt/destination1/ & \
cp /mnt/source/file4* /mnt/destination2/ & \
cp /mnt/source/file5* /mnt/destination3/ & \
cp /mnt/source/file6* /mnt/destination1/ & \
cp /mnt/source/file7* /mnt/destination2/ & \
cp /mnt/source/file8* /mnt/destination3/ & \
I exemplet ovan riktas alla tre målmonteringspunkterna mot klientfilens kopieringsprocesser.
När du ska lägga till klienter
Slutligen, när du har nått klientens funktioner, kommer tillägg av fler kopieringstrådar eller ytterligare monteringspunkter inte att ge några ytterligare filer/sek eller byte/sek ökningar. I så fall kan du distribuera en annan klient med samma uppsättning monteringspunkter som kör sina egna uppsättningar med filkopieringsprocesser.
Exempel:
Client1: cp -R /mnt/source/dir1/dir1a /mnt/destination/dir1/ &
Client1: cp -R /mnt/source/dir2/dir2a /mnt/destination/dir2/ &
Client1: cp -R /mnt/source/dir3/dir3a /mnt/destination/dir3/ &
Client2: cp -R /mnt/source/dir1/dir1b /mnt/destination/dir1/ &
Client2: cp -R /mnt/source/dir2/dir2b /mnt/destination/dir2/ &
Client2: cp -R /mnt/source/dir3/dir3b /mnt/destination/dir3/ &
Client3: cp -R /mnt/source/dir1/dir1c /mnt/destination/dir1/ &
Client3: cp -R /mnt/source/dir2/dir2c /mnt/destination/dir2/ &
Client3: cp -R /mnt/source/dir3/dir3c /mnt/destination/dir3/ &
Client4: cp -R /mnt/source/dir1/dir1d /mnt/destination/dir1/ &
Client4: cp -R /mnt/source/dir2/dir2d /mnt/destination/dir2/ &
Client4: cp -R /mnt/source/dir3/dir3d /mnt/destination/dir3/ &
Skapa filmanifest
När du har förstått metoderna ovan (flera kopieringstrådar per mål, flera mål per klient, flera klienter per nätverkstillgängligt källfilsystem) bör du överväga den här rekommendationen: Skapa filmanifest och sedan använda dem med kopieringskommandon mellan flera klienter.
Det här scenariot använder UNIX-kommandot find för att skapa manifest för filer eller kataloger:
user@build:/mnt/source > find . -mindepth 4 -maxdepth 4 -type d
./atj5b55c53be6-01/support/gsi/2018-07-22T21:12:06EDT
./atj5b55c53be6-01/support/pcap/2018-07-23T01:34:57UTC
./atj5b55c53be6-01/support/trace/rolling
./atj5b55c53be6-03/support/gsi/2018-07-22T21:12:06EDT
./atj5b55c53be6-03/support/pcap/2018-07-23T01:34:57UTC
./atj5b55c53be6-03/support/trace/rolling
./atj5b55c53be6-02/support/gsi/2018-07-22T21:12:06EDT
./atj5b55c53be6-02/support/pcap/2018-07-23T01:34:57UTC
./atj5b55c53be6-02/support/trace/rolling
Omdirigera det här resultatet till en fil: find . -mindepth 4 -maxdepth 4 -type d > /tmp/foo
Sedan kan du iterera via manifestet med hjälp av BASH-kommandon för att räkna filer och fastställa underkatalogernas storlek:
ben@xlcycl1:/sps/internal/atj5b5ab44b7f > for i in $(cat /tmp/foo); do echo " `find ${i} |wc -l` `du -sh ${i}`"; done
244 3.5M ./atj5b5ab44b7f-02/support/gsi/2018-07-18T00:07:03EDT
9 172K ./atj5b5ab44b7f-02/support/gsi/stats_2018-07-18T05:01:00UTC
124 5.8M ./atj5b5ab44b7f-02/support/gsi/stats_2018-07-19T01:01:01UTC
152 15M ./atj5b5ab44b7f-02/support/gsi/stats_2018-07-20T01:01:00UTC
131 13M ./atj5b5ab44b7f-02/support/gsi/stats_2018-07-20T21:59:41UTC_partial
789 6.2M ./atj5b5ab44b7f-02/support/gsi/2018-07-20T21:59:41UTC
134 12M ./atj5b5ab44b7f-02/support/gsi/stats_2018-07-20T22:22:55UTC_vfxt_catchup
7 16K ./atj5b5ab44b7f-02/support/pcap/2018-07-18T17:12:19UTC
8 83K ./atj5b5ab44b7f-02/support/pcap/2018-07-18T17:17:17UTC
575 7.7M ./atj5b5ab44b7f-02/support/cores/armada_main.2000.1531980253.gsi
33 4.4G ./atj5b5ab44b7f-02/support/trace/rolling
281 6.6M ./atj5b5ab44b7f-01/support/gsi/2018-07-18T00:07:03EDT
15 182K ./atj5b5ab44b7f-01/support/gsi/stats_2018-07-18T05:01:00UTC
244 17M ./atj5b5ab44b7f-01/support/gsi/stats_2018-07-19T01:01:01UTC
299 31M ./atj5b5ab44b7f-01/support/gsi/stats_2018-07-20T01:01:00UTC
256 29M ./atj5b5ab44b7f-01/support/gsi/stats_2018-07-20T21:59:41UTC_partial
889 7.7M ./atj5b5ab44b7f-01/support/gsi/2018-07-20T21:59:41UTC
262 29M ./atj5b5ab44b7f-01/support/gsi/stats_2018-07-20T22:22:55UTC_vfxt_catchup
11 248K ./atj5b5ab44b7f-01/support/pcap/2018-07-18T17:12:19UTC
11 88K ./atj5b5ab44b7f-01/support/pcap/2018-07-18T17:17:17UTC
645 11M ./atj5b5ab44b7f-01/support/cores/armada_main.2019.1531980253.gsi
33 4.0G ./atj5b5ab44b7f-01/support/trace/rolling
244 2.1M ./atj5b5ab44b7f-03/support/gsi/2018-07-18T00:07:03EDT
9 158K ./atj5b5ab44b7f-03/support/gsi/stats_2018-07-18T05:01:00UTC
124 5.3M ./atj5b5ab44b7f-03/support/gsi/stats_2018-07-19T01:01:01UTC
152 15M ./atj5b5ab44b7f-03/support/gsi/stats_2018-07-20T01:01:00UTC
131 12M ./atj5b5ab44b7f-03/support/gsi/stats_2018-07-20T21:59:41UTC_partial
789 8.4M ./atj5b5ab44b7f-03/support/gsi/2018-07-20T21:59:41UTC
134 14M ./atj5b5ab44b7f-03/support/gsi/stats_2018-07-20T22:25:58UTC_vfxt_catchup
7 159K ./atj5b5ab44b7f-03/support/pcap/2018-07-18T17:12:19UTC
7 157K ./atj5b5ab44b7f-03/support/pcap/2018-07-18T17:17:17UTC
576 12M ./atj5b5ab44b7f-03/support/cores/armada_main.2013.1531980253.gsi
33 2.8G ./atj5b5ab44b7f-03/support/trace/rolling
Slutligen måste du skapa de faktiska filkopieringskommandona till klienterna.
Om du har fyra klienter använder du det här kommandot:
for i in 1 2 3 4 ; do sed -n ${i}~4p /tmp/foo > /tmp/client${i}; done
Om du har fem klienter använder du något liknande:
for i in 1 2 3 4 5; do sed -n ${i}~5p /tmp/foo > /tmp/client${i}; done
Och för sex... Extrapolera efter behov.
for i in 1 2 3 4 5 6; do sed -n ${i}~6p /tmp/foo > /tmp/client${i}; done
Du får N-resulterande filer, en för var och en av dina N-klienter som har sökvägsnamnen till de nivå-fyra kataloger som erhålls som en del av utdata från find kommandot.
Använd varje fil för att skapa kopieringskommandot:
for i in 1 2 3 4 5 6; do for j in $(cat /tmp/client${i}); do echo "cp -p -R /mnt/source/${j} /mnt/destination/${j}" >> /tmp/client${i}_copy_commands ; done; done
Ovanstående ger dig N-filer , var och en med ett kopieringskommando per rad, som kan köras som ett BASH-skript på klienten.
Målet är att köra flera trådar av dessa skript samtidigt per klient parallellt på flera klienter.
Använda en rsync-process med två faser
Standardverktyget rsync fungerar inte bra för att fylla i molnlagring via Avere vFXT för Azure-systemet eftersom det genererar ett stort antal åtgärder för att skapa och byta namn på filer för att garantera dataintegriteten. Du kan dock använda --inplace alternativet med rsync för att hoppa över den mer noggranna kopieringsproceduren om du följer det med en andra körning som kontrollerar filintegriteten.
En standardkopieringsåtgärd rsync skapar en tillfällig fil och fyller den med data. Om dataöverföringen har slutförts byter den temporära filen namn till det ursprungliga filnamnet. Den här metoden garanterar konsekvens även om filerna används under kopiering. Men den här metoden genererar fler skrivåtgärder, vilket gör filflytten långsammare genom cachen.
Alternativet --inplace skriver den nya filen direkt på den slutliga platsen. Filer är inte garanterade att vara konsekventa under överföringen, men det är inte viktigt om du skapar ett lagringssystem för användning senare.
Den andra rsync åtgärden fungerar som en konsekvenskontroll av den första åtgärden. Eftersom filerna redan har kopierats är den andra fasen en snabbgenomsökning för att säkerställa att filerna på målet matchar filerna på källan. Om några filer inte matchar kopieras de på nytt.
Du kan utfärda båda faserna tillsammans i ett kommando:
rsync -azh --inplace <source> <destination> && rsync -azh <source> <destination>
Den här metoden är en enkel och tids effektiv metod för datauppsättningar upp till det antal filer som den interna kataloghanteraren kan hantera. (Det här är vanligtvis 200 miljoner filer för ett 3-nodskluster, 500 miljoner filer för ett kluster med sex noder och så vidare.)
Använda msrsync-verktyget
Verktyget msrsync kan också användas för att flytta data till en serverdelskärnare för Avere-klustret. Det här verktyget är utformat för att optimera bandbreddsanvändningen genom att köra flera parallella rsync processer. Den är tillgänglig från GitHub på https://github.com/jbd/msrsync.
msrsync delar upp källkatalogen i separata "bucketar" och kör sedan enskilda rsync processer på varje bucket.
Preliminära tester med en virtuell dator med fyra kärnor visade bästa effektivitet när du använde 64 processer. Använd alternativet msrsync -p för att ange antalet processer till 64.
Du kan också använda --inplace argumentet med msrsync kommandon. Om du använder det här alternativet kan du överväga att köra ett andra kommando (som med rsync, som beskrivs ovan) för att säkerställa dataintegriteten.
msrsync kan bara skriva till och från lokala volymer. Källan och målet måste vara tillgängliga som lokala monteringar i klustrets virtuella nätverk.
Följ dessa anvisningar om du vill använda msrsync för att fylla i en Azure-molnvolym med ett Avere-kluster:
Installera
msrsyncoch dess förutsättningar (rsync och Python 2.6 eller senare)Fastställ det totala antalet filer och kataloger som ska kopieras.
Använd till exempel avere-verktyget
prime.pymed argumentprime.py --directory /path/to/some/directory(tillgängligt genom att ladda ned URL https://github.com/Azure/Avere/blob/master/src/clientapps/dataingestor/prime.py).Om du inte använder
prime.pykan du beräkna antalet objekt med GNU-verktygetfindpå följande sätt:find <path> -type f |wc -l # (counts files) find <path> -type d |wc -l # (counts directories) find <path> |wc -l # (counts both)Dividera antalet objekt med 64 för att fastställa antalet objekt per process. Använd det här talet med
-falternativet för att ange storleken på bucketarna när du kör kommandot.msrsyncUtfärda kommandot för att kopiera filer:msrsync -P --stats -p 64 -f <ITEMS_DIV_64> --rsync "-ahv" <SOURCE_PATH> <DESTINATION_PATH>Om du använder
--inplacelägger du till en andra körning utan alternativet för att kontrollera att data kopieras korrekt:msrsync -P --stats -p 64 -f <ITEMS_DIV_64> --rsync "-ahv --inplace" <SOURCE_PATH> <DESTINATION_PATH> && msrsync -P --stats -p 64 -f <ITEMS_DIV_64> --rsync "-ahv" <SOURCE_PATH> <DESTINATION_PATH>Det här kommandot är till exempel utformat för att flytta 11 000 filer i 64 processer från /test/source-repository till /mnt/vfxt/repository:
msrsync -P --stats -p 64 -f 170 --rsync "-ahv --inplace" /test/source-repository/ /mnt/vfxt/repository && msrsync -P --stats -p 64 -f 170 --rsync "-ahv --inplace" /test/source-repository/ /mnt/vfxt/repository
Använda parallellkopieringsskriptet
Skriptet parallelcp kan också vara användbart för att flytta data till vFXT-klustrets serverdelslagring.
Skriptet nedan lägger till den körbara parallelcp. (Det här skriptet är utformat för Ubuntu. Om du använder en annan distribution måste du installera parallel separat.)
sudo touch /usr/bin/parallelcp && sudo chmod 755 /usr/bin/parallelcp && sudo sh -c "/bin/cat >/usr/bin/parallelcp" <<EOM
#!/bin/bash
display_usage() {
echo -e "\nUsage: \$0 SOURCE_DIR DEST_DIR\n"
}
if [ \$# -le 1 ] ; then
display_usage
exit 1
fi
if [[ ( \$# == "--help") || \$# == "-h" ]] ; then
display_usage
exit 0
fi
SOURCE_DIR="\$1"
DEST_DIR="\$2"
if [ ! -d "\$SOURCE_DIR" ] ; then
echo "Source directory \$SOURCE_DIR does not exist, or is not a directory"
display_usage
exit 2
fi
if [ ! -d "\$DEST_DIR" ] && ! mkdir -p \$DEST_DIR ; then
echo "Destination directory \$DEST_DIR does not exist, or is not a directory"
display_usage
exit 2
fi
if [ ! -w "\$DEST_DIR" ] ; then
echo "Destination directory \$DEST_DIR is not writeable, or is not a directory"
display_usage
exit 3
fi
if ! which parallel > /dev/null ; then
sudo apt-get update && sudo apt install -y parallel
fi
DIRJOBS=225
JOBS=225
find \$SOURCE_DIR -mindepth 1 -type d -print0 | sed -z "s/\$SOURCE_DIR\///" | parallel --will-cite -j\$DIRJOBS -0 "mkdir -p \$DEST_DIR/{}"
find \$SOURCE_DIR -mindepth 1 ! -type d -print0 | sed -z "s/\$SOURCE_DIR\///" | parallel --will-cite -j\$JOBS -0 "cp -P \$SOURCE_DIR/{} \$DEST_DIR/{}"
EOM
Exempel på parallellkopiering
I det här exemplet används det parallella kopieringsskriptet för att kompilera glibc med källfiler från Avere-klustret.
Källfilerna lagras på Monteringspunkten för Avere-klustret och objektfilerna lagras på den lokala hårddisken.
Det här skriptet använder parallellkopieringsskript ovan. Alternativet -j används med parallelcp och make för att få parallellisering.
sudo apt-get update
sudo apt install -y gcc bison gcc binutils make parallel
cd
wget https://mirrors.kernel.org/gnu/libc/glibc-2.27.tar.bz2
tar jxf glibc-2.27.tar.bz2
ln -s /nfs/node1 avere
time parallelcp glibc-2.27 avere/glibc-2.27
cd
mkdir obj
mkdir usr
cd obj
/home/azureuser/avere/glibc-2.27/configure --prefix=/home/azureuser/usr
time make -j
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för