Hög tillgänglighet med SQL Managed Instance aktiverat av Azure Arc
SQL Managed Instance som aktiveras av Azure Arc distribueras i Kubernetes som ett containerbaserat program. Den använder Kubernetes-konstruktioner som tillståndskänsliga uppsättningar och beständig lagring för att tillhandahålla inbyggd:
- Hälsoövervakning
- Felidentifiering
- Automatisk redundansväxling för att upprätthålla tjänstens hälsa.
För ökad tillförlitlighet kan du även konfigurera SQL Managed Instance som aktiveras av Azure Arc för distribution med extra repliker i en konfiguration med hög tillgänglighet. Datakontrollanten för Arc-datatjänster hanterar:
- Övervakning
- Felidentifiering
- Automatisk redundans
Arc-aktiverad datatjänst tillhandahåller den här tjänsten utan användarintervention. Tjänsten:
- Konfigurerar tillgänglighetsgruppen
- Konfigurerar databasspeglingsslutpunkter
- Lägger till databaser i tillgänglighetsgruppen
- Samordnar redundans och uppgradering.
Det här dokumentet utforskar båda typerna av hög tillgänglighet.
SQL Managed Instance som aktiveras av Azure Arc ger olika nivåer av hög tillgänglighet beroende på om DEN SQL-hanterade instansen distribuerades som en Generell användning tjänstnivå eller Affärskritisk tjänstnivå.
Hög tillgänglighet på Generell användning tjänstnivå
På tjänstnivån Generell användning finns det bara en tillgänglig replik och den höga tillgängligheten uppnås via Kubernetes-orkestrering. Om till exempel en podd eller nod som innehåller containeravbildningen för den hanterade instansen kraschar, försöker Kubernetes att ställa upp en annan podd eller nod och ansluta till samma beständiga lagring. Under den här tiden är den SQL-hanterade instansen inte tillgänglig för programmen. Program måste återansluta och försöka utföra transaktionen igen när den nya podden är igång. Om load balancer är den tjänsttyp som används kan program återansluta till samma primära slutpunkt och Kubernetes omdirigerar anslutningen till den nya primära. Om tjänsttypen är nodeport måste programmen återansluta till den nya IP-adressen.
Verifiera inbyggd hög tillgänglighet
Om du vill verifiera den höga tillgängligheten för bygget som tillhandahålls av Kubernetes kan du:
- Ta bort podden för en befintlig hanterad instans
- Kontrollera att Kubernetes återställs från den här åtgärden
Under återställningen startar Kubernetes en annan podd och kopplar den beständiga lagringen.
Förutsättningar
- Kubernetes-klustret kräver delad fjärrlagring
- En SQL Managed Instance aktiverad av Azure Arc distribuerad med en replik (standard)
Visa poddarna.
kubectl get pods -n <namespace of data controller>Ta bort podden för den hanterade instansen.
kubectl delete pod <name of managed instance>-0 -n <namespace of data controller>Till exempel
user@pc:/# kubectl delete pod sql1-0 -n arc pod "sql1-0" deletedVisa poddarna för att kontrollera att den hanterade instansen återställs.
kubectl get pods -n <namespace of data controller>Till exempel:
user@pc:/# kubectl get pods -n arc NAME READY STATUS RESTARTS AGE sql1-0 2/3 Running 0 22s
När alla containrar i podden har återställts kan du ansluta till den hanterade instansen.
Hög tillgänglighet på Affärskritisk tjänstnivå
På tjänstnivån Affärskritisk, utöver vad som tillhandahålls internt av Kubernetes-orkestrering, tillhandahåller SQL Managed Instance för Azure Arc en innesluten tillgänglighetsgrupp. Den inneslutna tillgänglighetsgruppen bygger på SQL Server AlwaysOn-teknik. Det ger högre tillgänglighetsnivåer. SQL Managed Instance som aktiveras av Azure Arc som distribueras med Affärskritisk tjänstnivå kan distribueras med antingen 2 eller 3 repliker. Dessa repliker hålls alltid synkroniserade med varandra.
Med inneslutna tillgänglighetsgrupper är alla poddkrascher eller nodfel transparenta för programmet. Den inneslutna tillgänglighetsgruppen innehåller minst en annan podd som har alla data från den primära och som är redo att ta emot anslutningar.
Inneslutna tillgänglighetsgrupper
En tillgänglighetsgrupp binder en eller flera användardatabaser till en logisk grupp så att hela gruppen med databaser redundansväxlar över till den sekundära repliken som en enda enhet när det sker en redundansväxling. En tillgänglighetsgrupp replikerar endast data i användardatabaserna, men inte data i systemdatabaser som inloggningar, behörigheter eller agentjobb. En innesluten tillgänglighetsgrupp innehåller metadata från systemdatabaser som msdb och master databaser. När inloggningar skapas eller ändras i den primära repliken skapas de automatiskt i de sekundära replikerna. På samma sätt får de sekundära replikerna även dessa ändringar när ett agentjobb skapas eller ändras i den primära repliken.
SQL Managed Instance som aktiveras av Azure Arc använder det här begreppet innesluten tillgänglighetsgrupp och lägger till Kubernetes-operatorn så att dessa kan distribueras och hanteras i stor skala.
Funktioner som innehöll tillgänglighetsgrupper aktiverar:
När den distribueras med flera repliker skapas en enda tillgänglighetsgrupp med samma namn som den Arc-aktiverade SQL-hanterade instansen. Som standard har den inneslutna tillgänglighetsgruppen tre repliker, inklusive primära. Alla CRUD-åtgärder för tillgänglighetsgruppen hanteras internt, inklusive att skapa tillgänglighetsgruppen eller koppla repliker till den tillgänglighetsgrupp som skapats. Du kan inte skapa fler tillgänglighetsgrupper i en instans.
Alla databaser läggs automatiskt till i tillgänglighetsgruppen, inklusive alla användar- och systemdatabaser som
masterochmsdb. Den här funktionen ger en vy med ett enda system i tillgänglighetsgruppens repliker. Observera bådecontainedag_masterochcontainedag_msdbdatabaser om du ansluter direkt till instansen. Databasernacontainedag_*representerarmasterochmsdbinuti tillgänglighetsgruppen.En extern slutpunkt etableras automatiskt för att ansluta till databaser i tillgänglighetsgruppen. Den här slutpunkten
<managed_instance_name>-external-svcspelar rollen som tillgänglighetsgrupplyssnare.
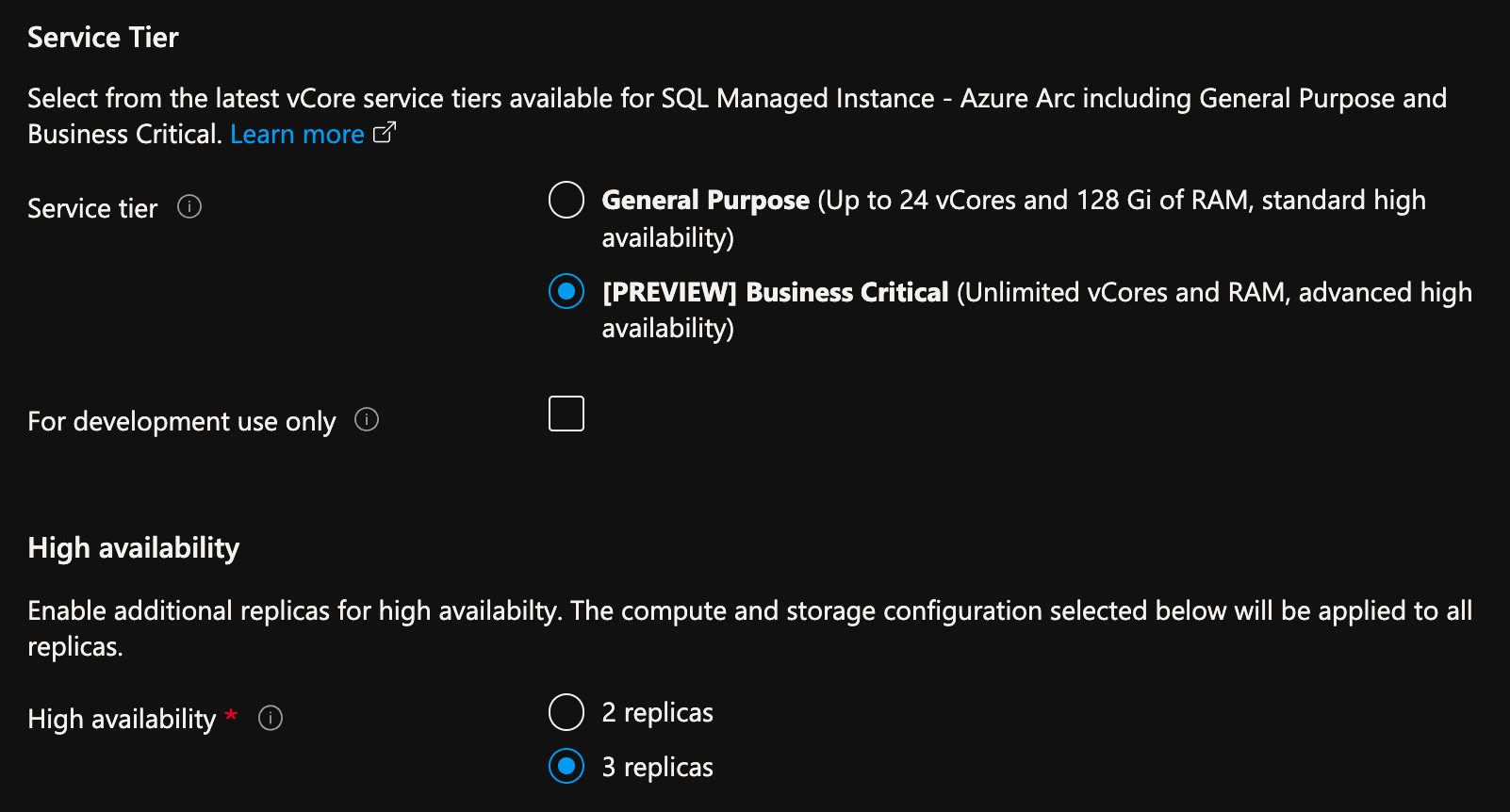
Distribuera SQL Managed Instance aktiverat av Azure Arc med flera repliker med hjälp av Azure Portal
Från Azure Portal går du till sidan Skapa SQL Managed Instance som aktiveras av Azure Arc:
- Välj Konfigurera beräkning + lagring under Beräkning + Lagring. Portalen visar avancerade inställningar.
- Under Tjänstnivå väljer du Affärskritisk.
- Kontrollera "Endast för utveckling" om du använder för utvecklingsändamål.
- Under Hög tillgänglighet väljer du antingen 2 repliker eller 3 repliker.
Distribuera med flera repliker med Hjälp av Azure CLI
När en SQL Managed Instance som aktiveras av Azure Arc distribueras på Affärskritisk tjänstnivå skapar distributionen flera repliker. Konfigurationen och konfigurationen av inneslutna tillgänglighetsgrupper mellan dessa instanser utförs automatiskt under etableringen.
Följande kommando skapar till exempel en hanterad instans med 3 repliker.
Indirekt anslutet läge:
az sql mi-arc create -n <instanceName> --k8s-namespace <namespace> --use-k8s --tier <tier> --replicas <number of replicas>
Exempel:
az sql mi-arc create -n sqldemo --k8s-namespace my-namespace --use-k8s --tier BusinessCritical --replicas 3
Direktanslutet läge:
az sql mi-arc create --name <name> --resource-group <group> --location <Azure location> –subscription <subscription> --custom-location <custom-location> --tier <tier> --replicas <number of replicas>
Exempel:
az sql mi-arc create --name sqldemo --resource-group rg --location uswest2 –subscription xxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx --custom-location private-location --tier BusinessCritical --replcias 3
Som standard konfigureras alla repliker i synkront läge. Det innebär att alla uppdateringar på den primära instansen replikeras synkront till var och en av de sekundära instanserna.
Visa och övervaka status för hög tillgänglighet
När distributionen är klar ansluter du till den primära slutpunkten från SQL Server Management Studio.
Verifiera och hämta slutpunkten för den primära repliken och anslut till den från SQL Server Management Studio.
Om SQL-instansen till exempel distribuerades med kör service-type=loadbalancerdu kommandot nedan för att hämta slutpunkten för att ansluta till:
az sql mi-arc list --k8s-namespace my-namespace --use-k8s
eller
kubectl get sqlmi -A
Hämta de primära och sekundära slutpunkterna och tillgänglighetsgruppens status
kubectl describe sqlmi Använd kommandona eller az sql mi-arc show för att visa de primära och sekundära slutpunkterna och status för hög tillgänglighet.
Exempel:
kubectl describe sqlmi sqldemo -n my-namespace
eller
az sql mi-arc show --name sqldemo --k8s-namespace my-namespace --use-k8s
Exempel på utdata>
"status": {
"endpoints": {
"logSearchDashboard": "https://10.120.230.404:5601/app/kibana#/discover?_a=(query:(language:kuery,query:'custom_resource_name:sqldemo'))",
"metricsDashboard": "https://10.120.230.46:3000/d/40q72HnGk/sql-managed-instance-metrics?var-hostname=sqldemo-0",
"mirroring": "10.15.100.150:5022",
"primary": "10.15.100.150,1433",
"secondary": "10.15.100.156,1433"
},
"highAvailability": {
"healthState": "OK",
"mirroringCertificate": "-----BEGIN CERTIFICATE-----\n...\n-----END CERTIFICATE-----"
},
"observedGeneration": 1,
"readyReplicas": "2/2",
"state": "Ready"
}
Du kan ansluta till den primära slutpunkten med SQL Server Management Studio och verifiera DMV:er som:
SELECT * FROM sys.dm_hadr_availability_replica_states
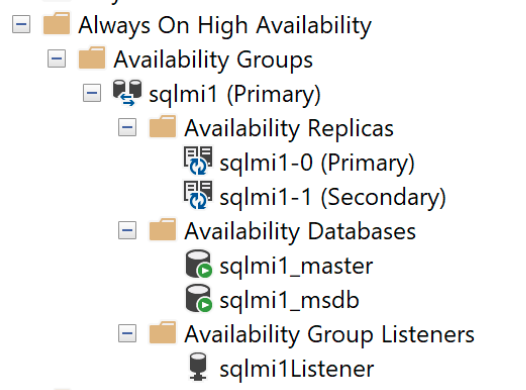
Och instrumentpanelen för innesluten tillgänglighet:
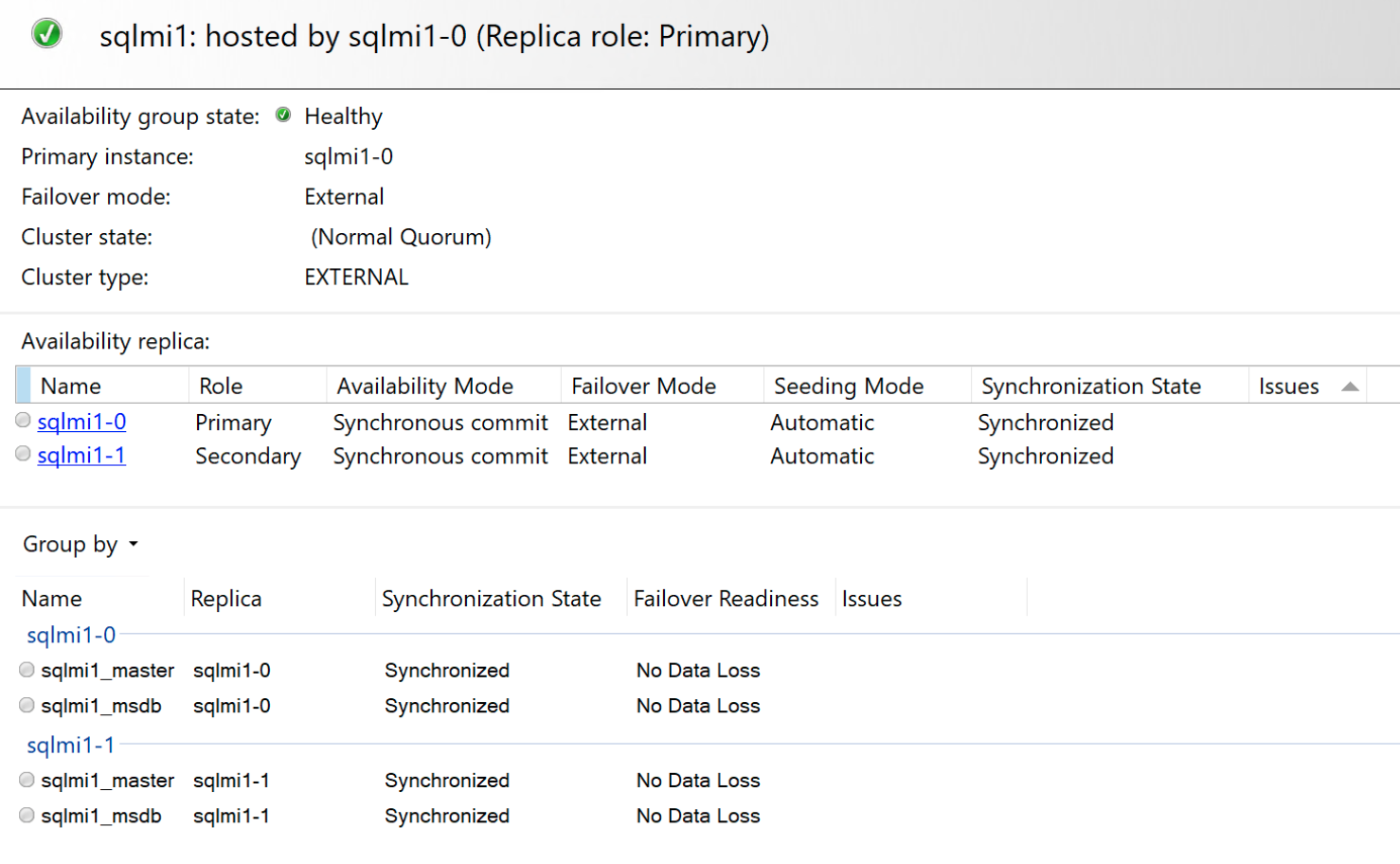
Redundansscenarier
Till skillnad från SQL Server AlwaysOn-tillgänglighetsgrupper är den inneslutna tillgänglighetsgruppen en hanterad lösning för hög tillgänglighet. Därför är redundanslägena begränsade jämfört med de vanliga lägena som är tillgängliga med SQL Server AlwaysOn-tillgänglighetsgrupper.
Distribuera Affärskritisk SQL-hanterade instanser på tjänstnivå i antingen tvåreplikkonfiguration eller tre replikkonfigurationer. Effekterna av fel och efterföljande återställning är olika för varje konfiguration. En instans av tre repliker ger en högre nivå av tillgänglighet och återställning än en två replikinstans.
I en konfiguration med två repliker, när båda nodtillstånden är SYNCHRONIZED, om den primära repliken blir otillgänglig, befordras den sekundära repliken automatiskt till primär. När den misslyckade repliken blir tillgänglig uppdateras den med alla väntande ändringar. Om det finns anslutningsproblem mellan replikerna kanske den primära repliken inte genomför några transaktioner eftersom varje transaktion måste checkas in på båda replikerna innan en lyckad återställning returneras på den primära.
I en konfiguration med tre repliker måste en transaktion checka in minst 2 av de 3 replikerna innan ett lyckat meddelande returneras till programmet. I händelse av ett fel befordras en av sekundärfilerna automatiskt till primär medan Kubernetes försöker återställa den misslyckade repliken. När repliken blir tillgänglig kopplas den automatiskt tillbaka med den inneslutna tillgänglighetsgruppen och väntande ändringar synkroniseras. Om det finns anslutningsproblem mellan replikerna och fler än 2 repliker är osynkroniserade kommer den primära repliken inte att genomföra några transaktioner.
Kommentar
Vi rekommenderar att du distribuerar en Affärskritisk SQL Managed Instance i en konfiguration med tre repliker än en konfiguration med två repliker för att uppnå nästan noll dataförlust.
Om du vill redundansväxla från den primära repliken till en av sekundärfilerna kör du följande kommando för en planerad händelse:
Om du ansluter till primärt kan du använda följande T-SQL för att redundansväsa SQL-instansen till någon av sekundärfilerna:
ALTER AVAILABILITY GROUP current SET (ROLE = SECONDARY);
Om du ansluter till den sekundära kan du använda följande T-SQL för att höja upp önskad sekundär till primär replik.
ALTER AVAILABILITY GROUP current SET (ROLE = PRIMARY);
Önskad primär replik
Du kan också ange att en specifik replik ska vara den primära repliken med AZ CLI på följande sätt:
az sql mi-arc update --name <sqlinstance name> --k8s-namespace <namespace> --use-k8s --preferred-primary-replica <replica>
Exempel:
az sql mi-arc update --name sqldemo --k8s-namespace my-namespace --use-k8s --preferred-primary-replica sqldemo-3
Kommentar
Kubernetes försöker ange önskad replik, men det är inte garanterat.
Återställa en databas till en instans med flera repliker
Ytterligare steg krävs för att återställa en databas till en tillgänglighetsgrupp. Följande steg visar hur du återställer en databas till en hanterad instans och lägger till den i en tillgänglighetsgrupp.
Exponera den externa slutpunkten för den primära instansen genom att skapa en ny Kubernetes-tjänst.
Fastställ den podd som är värd för den primära repliken. Anslut till den hanterade instansen och kör:
SELECT @@SERVERNAMEFrågan returnerar podden som är värd för den primära repliken.
Skapa Kubernetes-tjänsten till den primära instansen genom att köra följande kommando om Kubernetes-klustret använder
NodePorttjänster. Ersätt<podName>med namnet på servern som returnerades i föregående steg,<serviceName>med det önskade namnet för Kubernetes-tjänsten som skapades.kubectl -n <namespaceName> expose pod <podName> --port=1533 --name=<serviceName> --type=NodePortFör en LoadBalancer-tjänst kör du samma kommando, förutom att den typ av tjänst som skapats är
LoadBalancer. Till exempel:kubectl -n <namespaceName> expose pod <podName> --port=1533 --name=<serviceName> --type=LoadBalancerHär är ett exempel på den här kommandokörningen mot Azure Kubernetes Service, där podden som är värd för den primära är
sql2-0:kubectl -n arc-cluster expose pod sql2-0 --port=1533 --name=sql2-0-p --type=LoadBalancerHämta IP-adressen för Kubernetes-tjänsten som skapats:
kubectl get services -n <namespaceName>Återställ databasen till den primära instansslutpunkten.
Lägg till databassäkerhetskopieringsfilen i den primära instanscontainern.
kubectl cp <source file location> <pod name>:var/opt/mssql/data/<file name> -c <serviceName> -n <namespaceName>Exempel
kubectl cp /home/WideWorldImporters-Full.bak sql2-1:var/opt/mssql/data/WideWorldImporters-Full.bak -c arc-sqlmi -n arcÅterställ databassäkerhetskopian genom att köra kommandot nedan.
RESTORE DATABASE test FROM DISK = '/var/opt/mssql/data/<file name>.bak' WITH MOVE '<database name>' to '/var/opt/mssql/data/<file name>.mdf' ,MOVE '<database name>' to '/var/opt/mssql/data/<file name>_log.ldf' ,RECOVERY, REPLACE, STATS = 5; GOExempel
RESTORE Database WideWorldImporters FROM DISK = '/var/opt/mssql/data/WideWorldImporters-Full.BAK' WITH MOVE 'WWI_Primary' TO '/var/opt/mssql/data/WideWorldImporters.mdf', MOVE 'WWI_UserData' TO '/var/opt/mssql/data/WideWorldImporters_UserData.ndf', MOVE 'WWI_Log' TO '/var/opt/mssql/data/WideWorldImporters.ldf', MOVE 'WWI_InMemory_Data_1' TO '/var/opt/mssql/data/WideWorldImporters_InMemory_Data_1', RECOVERY, REPLACE, STATS = 5; GOLägg till databasen i tillgänglighetsgruppen.
För att databasen ska läggas till i tillgänglighetsgruppen måste den köras i fullständigt återställningsläge och en loggsäkerhetskopia måste göras. Kör TSQL-instruktionerna nedan för att lägga till den återställda databasen i tillgänglighetsgruppen.
ALTER DATABASE <databaseName> SET RECOVERY FULL; BACKUP DATABASE <databaseName> TO DISK='<filePath>' ALTER AVAILABILITY GROUP containedag ADD DATABASE <databaseName>I följande exempel läggs en databas med namnet
WideWorldImporterssom har återställts på instansen:ALTER DATABASE WideWorldImporters SET RECOVERY FULL; BACKUP DATABASE WideWorldImporters TO DISK='/var/opt/mssql/data/WideWorldImporters.bak' ALTER AVAILABILITY GROUP containedag ADD DATABASE WideWorldImporters
Viktigt!
Som bästa praxis bör du ta bort Kubernetes-tjänsten som skapades ovan genom att köra det här kommandot:
kubectl delete svc sql2-0-p -n arc
Begränsningar
SQL Managed Instance som aktiveras av Azure Arc-tillgänglighetsgrupper har samma begränsningar som tillgänglighetsgrupper för stordatakluster. Mer information finns i Distribuera SQL Server Big Data Cluster med hög tillgänglighet.
Relaterat innehåll
Läs mer om funktioner i SQL Managed Instance som aktiveras av Azure Arc