Rekommenderade aviseringsregler för Kubernetes-kluster
Aviseringar i Azure Monitor identifierar proaktivt problem som rör hälsotillstånd och prestanda för dina Azure-resurser. Den här artikeln beskriver hur du aktiverar och redigerar en uppsättning rekommenderade måttaviseringsregler som är fördefinierade för dina Kubernetes-kluster.
Aktivera rekommenderade aviseringsregler
Använd någon av följande metoder för att aktivera de rekommenderade aviseringsreglerna för klustret. Du kan aktivera aviseringsregler för både Prometheus och plattformsmått för samma kluster.
Kommentar
ARM-mallar är den enda metod som stöds för att aktivera rekommenderade aviseringar i Arc-aktiverade Kubernetes-kluster.
Med hjälp av Azure Portal skapas Prometheus-regelgruppen i samma region som klustret.
På menyn Aviseringar för klustret väljer du Konfigurera rekommendationer.
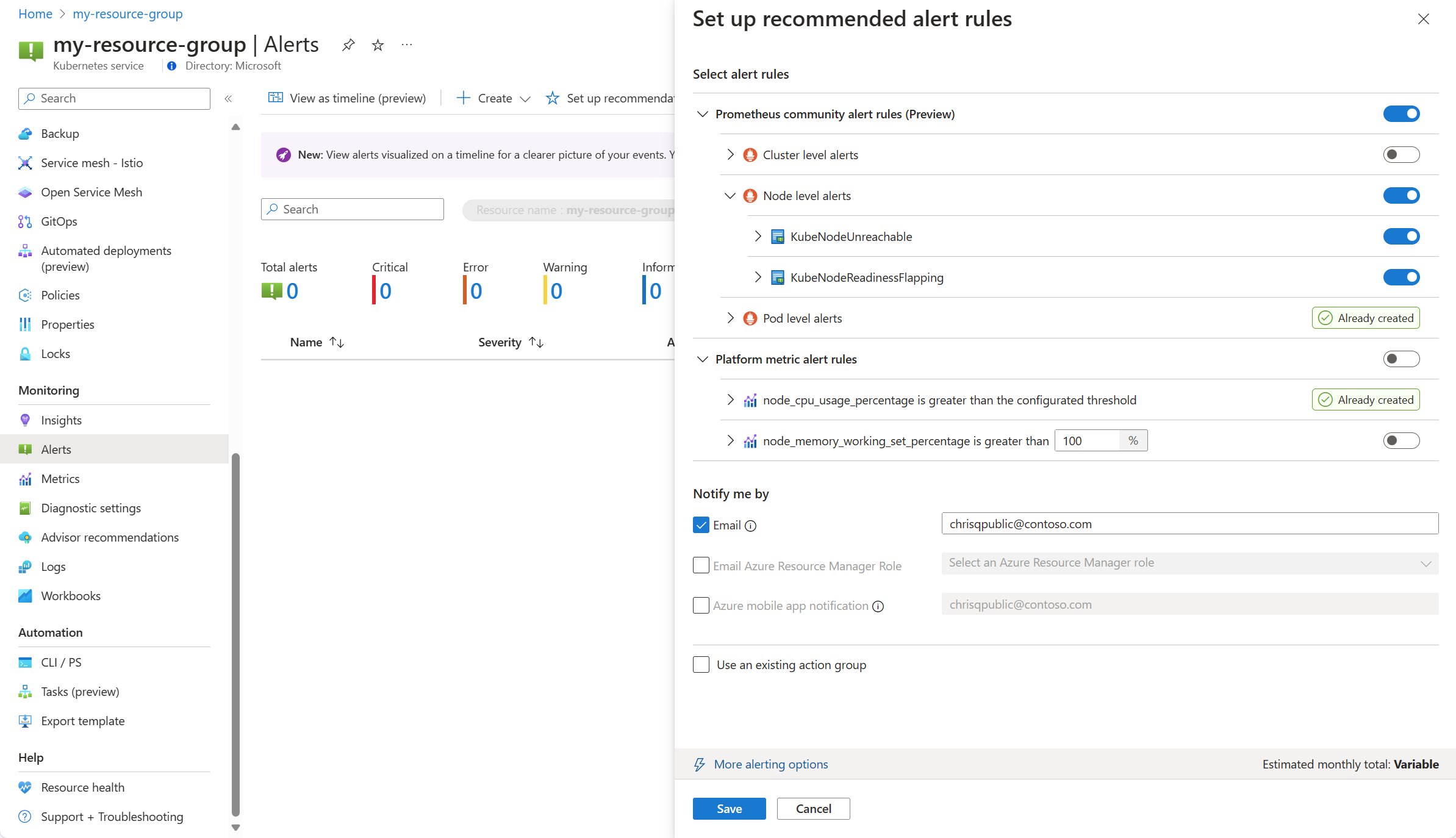
Tillgängliga Prometheus- och plattformsaviseringsregler visas med Prometheus-reglerna ordnade efter podd-, kluster- och nodnivå. Växla en grupp med Prometheus-regler för att aktivera den uppsättningen med regler. Expandera gruppen för att se de enskilda reglerna. Du kan lämna standardinställningarna eller inaktivera enskilda regler och redigera deras namn och allvarlighetsgrad.
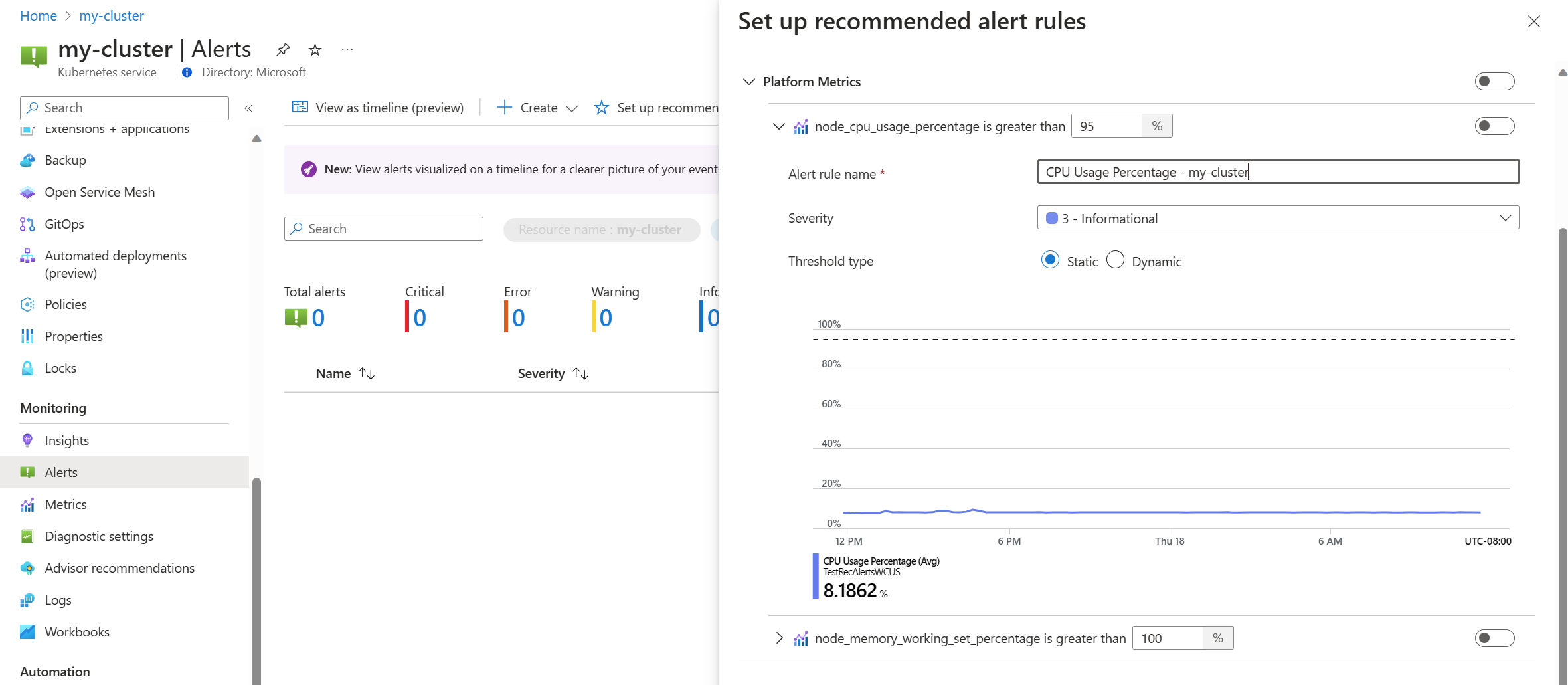
Växla en plattformsmåttregel för att aktivera den regeln. Du kan expandera regeln för att ändra dess information, till exempel namn, allvarlighetsgrad och tröskelvärde.
Välj antingen en eller flera meddelandemetoder för att skapa en ny åtgärdsgrupp eller välj en befintlig åtgärdsgrupp med meddelandeinformationen för den här uppsättningen aviseringsregler.
Spara regelgruppen genom att klicka på Spara .



Redigera rekommenderade aviseringsregler
När regelgruppen har skapats kan du inte använda samma sida i portalen för att redigera reglerna. För Prometheus-mått måste du redigera regelgruppen för att ändra alla regler i den, inklusive att aktivera regler som inte redan har aktiverats. För plattformsmått kan du redigera varje aviseringsregel.
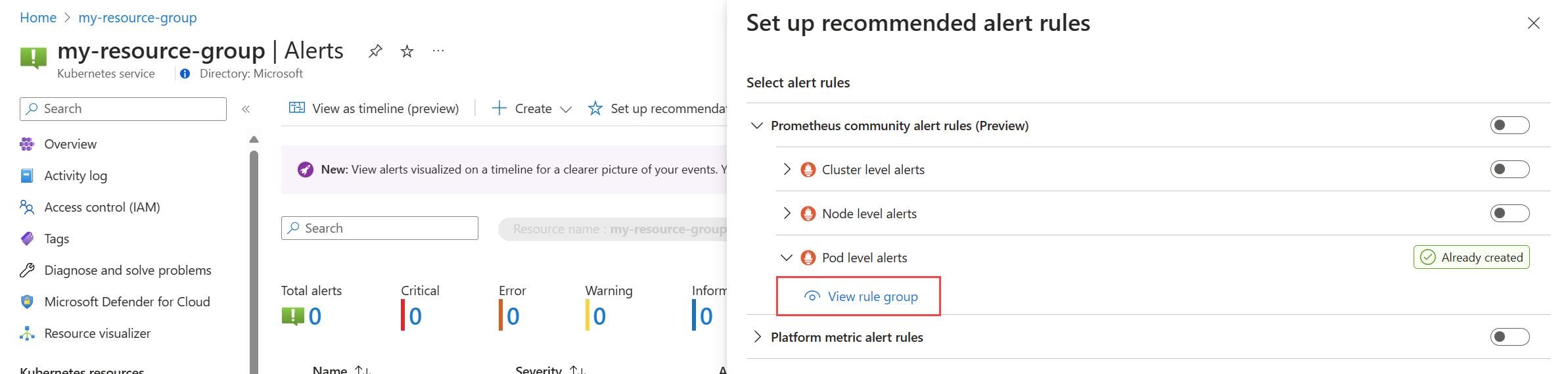
På menyn Aviseringar för klustret väljer du Konfigurera rekommendationer. Regler eller regelgrupper som redan har skapats kommer att märkas som Redan skapade.
Expandera regeln eller regelgruppen. Klicka på Visa regelgrupp för Prometheus och Visa aviseringsregel för plattformsmått.
För Prometheus-regelgrupper:
välj Regler för att visa aviseringsreglerna i gruppen.
Klicka på ikonen Redigera bredvid en regel som du vill ändra. Använd vägledningen i Skapa en aviseringsregel för att ändra regeln.
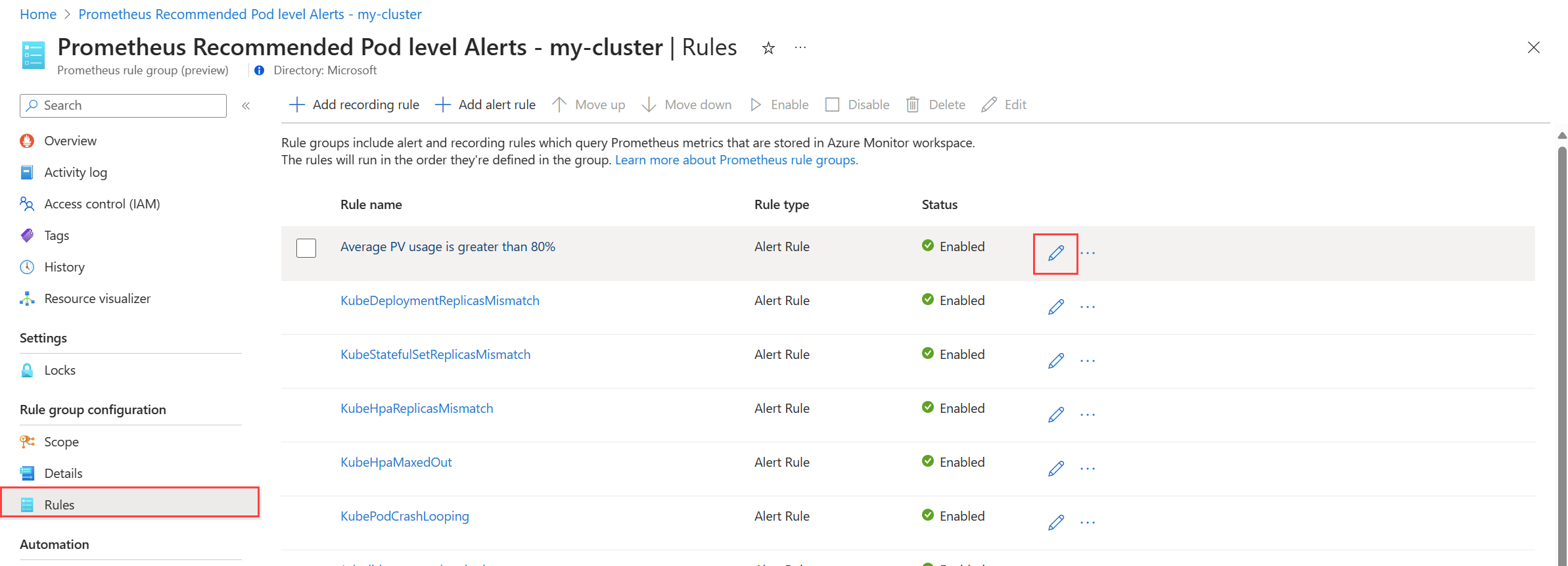
När du är klar med att redigera regler i gruppen klickar du på Spara för att spara regelgruppen.
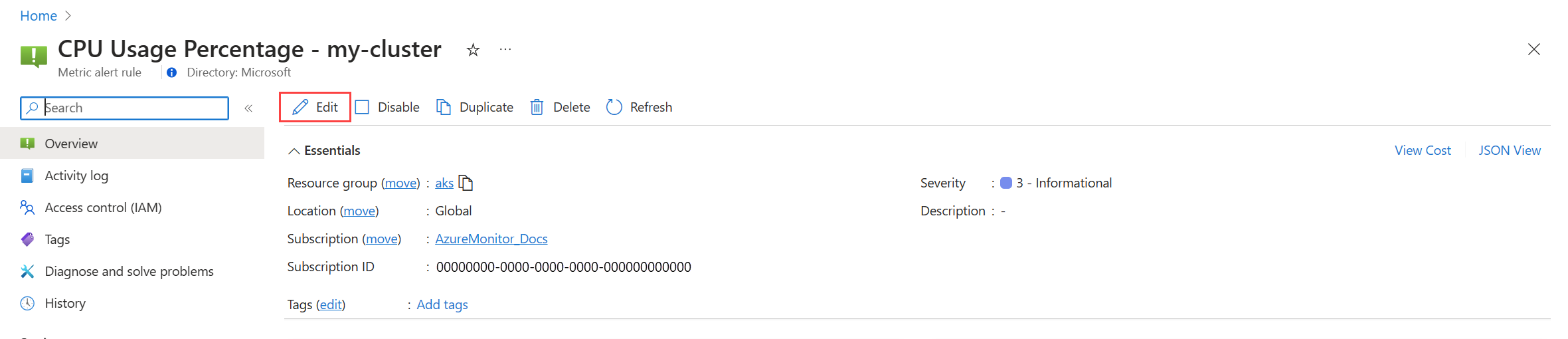
För plattformsmått:
klicka på Redigera för att öppna informationen för aviseringsregeln. Använd vägledningen i Skapa en aviseringsregel för att ändra regeln.



Inaktivera aviseringsregelgrupp
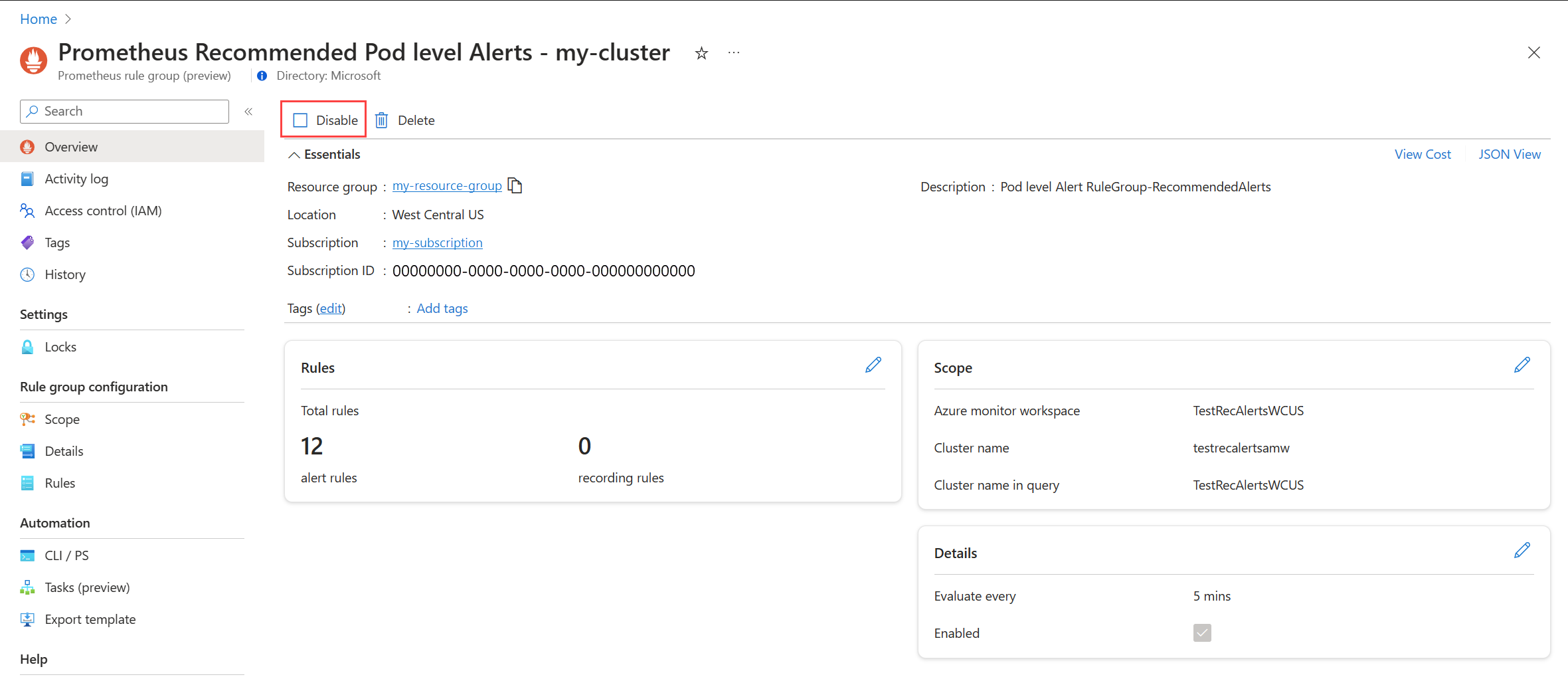
Inaktivera regelgruppen för att sluta ta emot aviseringar från reglerna i den.
Visa prometheus-aviseringsregelgruppen eller aviseringsregeln för plattformsmått enligt beskrivningen i Redigera rekommenderade aviseringsregler.
På menyn Översikt väljer du Inaktivera.

Information om rekommenderade aviseringsregler
I följande tabeller visas information om varje rekommenderad aviseringsregel. Källkoden för var och en är tillgänglig i GitHub tillsammans med felsökningsguider från Prometheus-communityn.
Aviseringsregler för Prometheus-communityn
Aviseringar på klusternivå
| Aviseringsnamn | beskrivning | Standardtröskelvärde | Tidsram (minuter) |
|---|---|---|---|
| KubeCPUQuotaOvercommit | Cpu-resurskvoten som allokerats till namnområden överskrider de tillgängliga CPU-resurserna på klustrets noder med mer än 50 % under de senaste 5 minuterna. | >1.5 | 5 |
| KubeMemoryQuotaOvercommit | Den minnesresurskvot som allokerats till namnområden överskrider de tillgängliga minnesresurserna på klustrets noder med mer än 50 % under de senaste 5 minuterna. | >1.5 | 5 |
| KubeContainerOOMKilledCount | En eller flera containrar i poddar har avlivats på grund av OOM-händelser (out-of-memory) under de senaste 5 minuterna. | >0 | 5 |
| KubeClientErrors | Antalet klientfel (HTTP-statuskoder som börjar med 5xx) i Kubernetes API-begäranden överskrider 1 % av den totala API-begärandefrekvensen under de senaste 15 minuterna. | >0.01 | 15 |
| KubePersistentVolumeFillingUp | Den beständiga volymen fylls på och förväntas få slut på tillgängligt utrymme utvärderat på det tillgängliga utrymmesförhållandet, använt utrymme och den förutsagda linjära trenden för tillgängligt utrymme under de senaste 6 timmarna. Dessa villkor utvärderas under de senaste 60 minuterna. | Ej tillämpligt | 60 |
| KubePersistentVolumeInodesFillingUp | Mindre än 3 % av innoderna i en beständiga volym är tillgängliga under de senaste 15 minuterna. | <0.03 | 15 |
| KubePersistentVolumeErrors | En eller flera beständiga volymer befinner sig i en misslyckad eller väntande fas under de senaste 5 minuterna. | >0 | 5 |
| KubeContainerWaiting | En eller flera containrar i Kubernetes-poddar är i vänteläge under de senaste 60 minuterna. | >0 | 60 |
| KubeDaemonSetNotScheduled | En eller flera poddar har inte schemalagts på någon nod under de senaste 15 minuterna. | >0 | 15 |
| KubeDaemonSetMisScheduled | En eller flera poddar har saknats i klustret under de senaste 15 minuterna. | >0 | 15 |
| KubeQuotaAlmostFull | Användningen av Kubernetes-resurskvoter är mellan 90 % och 100 % av de hårda gränserna under de senaste 15 minuterna. | >0,9 <1 | 15 |
Aviseringar på nodnivå
| Aviseringsnamn | beskrivning | Standardtröskelvärde | Tidsram (minuter) |
|---|---|---|---|
| KubeNodeUnreachable | En nod har inte kunnat nås under de senaste 15 minuterna. | 1 | 15 |
| KubeNodeReadinessFlapping | Beredskapsstatusen för en nod har ändrats mer än 2 gånger under de senaste 15 minuterna. | 2 | 15 |
Aviseringar på poddnivå
| Aviseringsnamn | beskrivning | Standardtröskelvärde | Tidsram (minuter) |
|---|---|---|---|
| KubePVUsageHigh | Den genomsnittliga användningen av beständiga volymer (PV:er) i podden överstiger 80 % under de senaste 15 minuterna. | >0.8 | 15 |
| KubeDeploymentReplicasMismatch | Det finns ett matchningsfel mellan önskat antal repliker och antalet tillgängliga repliker under de senaste 10 minuterna. | Ej tillämpligt | 10 |
| KubeStatefulSetReplicasMismatch | Antalet färdiga repliker i StatefulSet matchar inte det totala antalet repliker i StatefulSet under de senaste 15 minuterna. | Ej tillämpligt | 15 |
| KubeHpaReplicasMismatch | Autoskalning av vågrät podd i klustret har inte matchat önskat antal repliker under de senaste 15 minuterna. | Ej tillämpligt | 15 |
| KubeHpaMaxedOut | HPA (Horizontal Pod Autoscaler) i klustret har körts med maximalt antal repliker under de senaste 15 minuterna. | Ej tillämpligt | 15 |
| KubePodCrashLooping | En eller flera poddar är i ett CrashLoopBackOff-villkor, där podden kontinuerligt kraschar efter start och inte kan återställas under de senaste 15 minuterna. | >=1 | 15 |
| KubeJobStale | Minst en jobbinstans har inte slutförts under de senaste 6 timmarna. | >0 | 360 |
| KubePodContainerRestart | En eller flera containrar i poddar i Kubernetes-klustret har startats om minst en gång under den senaste timmen. | >0 | 15 |
| KubePodReadyStateLow | Procentandelen poddar i ett redo tillstånd ligger under 80 % för distribution eller daemonset i Kubernetes-klustret under de senaste 5 minuterna. | <0.8 | 5 |
| KubePodFailedState | En eller flera poddar är i ett misslyckat tillstånd under de senaste 5 minuterna. | >0 | 5 |
| KubePodNotReadyByController | En eller flera poddar är inte i ett klart tillstånd (dvs. i fasen "Väntar" eller "Okänd" under de senaste 15 minuterna. | >0 | 15 |
| KubeStatefulSetGenerationMismatch | Den observerade genereringen av en Kubernetes StatefulSet matchar inte dess metadatagenerering under de senaste 15 minuterna. | Ej tillämpligt | 15 |
| KubeJobFailed | Ett eller flera Kubernetes-jobb har misslyckats under de senaste 15 minuterna. | >0 | 15 |
| KubeContainerAverageCPUHigh | Den genomsnittliga CPU-användningen per container överstiger 95 % under de senaste 5 minuterna. | >0.95 | 5 |
| KubeContainerAverageMemoryHigh | Den genomsnittliga minnesanvändningen per container överstiger 95 % under de senaste 5 minuterna. | >0.95 | 10 |
| KubeletPodStartUpLatencyHigh | Den 99:e percentilen av poddens startsvarstid överskrider 60 sekunder under de senaste 10 minuterna. | >60 | 10 |
Aviseringsregler för plattformsmått
| Aviseringsnamn | beskrivning | Standardtröskelvärde | Tidsram (minuter) |
|---|---|---|---|
| Cpu-procentandelen för noder är större än 95 % | Nodens CPU-procentandel är större än 95 % under de senaste 5 minuterna. | 95 | 5 |
| Procentandelen arbetsuppsättning för nodminne är större än 100 % | Arbetsuppsättningen för nodminnet är större än 100 % under de senaste 5 minuterna. | 100 | 5 |
Måttaviseringar för äldre containerinsikter (förhandsversion)
Måttregler i Container Insights drogs tillbaka den 31 maj 2024. Dessa regler var i offentlig förhandsversion men drogs tillbaka utan att nå allmän tillgänglighet eftersom de nya rekommenderade måttaviseringar som beskrivs i den här artikeln nu är tillgängliga.
Om du redan har aktiverat dessa äldre aviseringsregler bör du inaktivera dem och aktivera den nya upplevelsen.
Inaktivera måttaviseringsregler
- På insights-menyn för klustret väljer du Rekommenderade aviseringar (förhandsversion).
- Ändra status för varje aviseringsregel till Inaktiverad.
Mappning av äldre aviseringar
I följande tabell mappas var och en av de äldre måttaviseringar för Container Insights till motsvarande rekommenderade Prometheus-måttaviseringar.
| Rekommenderad avisering för anpassat mått | Motsvarande prometheus/plattformsmått rekommenderad avisering | Villkor |
|---|---|---|
| Antal inaktuella jobb | KubeJobStale (aviseringar på poddnivå) | Minst en jobbinstans har inte slutförts under de senaste 6 timmarna. |
| Container-CPU % | KubeContainerAverageCPUHigh (aviseringar på poddnivå) | Den genomsnittliga CPU-användningen per container överstiger 95 % under de senaste 5 minuterna. |
| Minne för arbetsuppsättning för containrar % | KubeContainerAverageMemoryHigh (aviseringar på poddnivå) | Den genomsnittliga minnesanvändningen per container överstiger 95 % under de senaste 5 minuterna. |
| Antal misslyckade poddar | KubePodFailedState (aviseringar på poddnivå) | En eller flera poddar är i ett misslyckat tillstånd under de senaste 5 minuterna. |
| Nod-CPU % | Cpu-procentandelen för noder är större än 95 % (plattformsmått) | Nodens CPU-procentandel är större än 95 % under de senaste 5 minuterna. |
| Noddiskanvändning % | Ej tillämpligt | Genomsnittlig diskanvändning för en nod är större än 80 %. |
| Noden i NotReady status | KubeNodeUnreachable (aviseringar på nodnivå) | En nod har inte kunnat nås under de senaste 15 minuterna. |
| Minnesuppsättning för nodarbetsuppsättning % | Procentandelen arbetsuppsättning för nodminne är större än 100 % | Arbetsuppsättningen för nodminnet är större än 100 % under de senaste 5 minuterna. |
| OOM-avlivade containrar | KubeContainerOOMKilledCount (aviseringar på klusternivå) | En eller flera containrar i poddar har avlivats på grund av OOM-händelser (out-of-memory) under de senaste 5 minuterna. |
| Beständiga volymanvändning % | KubePVUsageHigh (aviseringar på poddnivå) | Den genomsnittliga användningen av beständiga volymer (PV:er) i podden överstiger 80 % under de senaste 15 minuterna. |
| Poddar redo i procent | KubePodReadyStateLow (aviseringar på poddnivå) | Procentandelen poddar i ett redo tillstånd ligger under 80 % för distribution eller daemonset i Kubernetes-klustret under de senaste 5 minuterna. |
| Antal containrar som startar om | KubePodContainerRestart (aviseringar på poddnivå) | En eller flera containrar i poddar i Kubernetes-klustret har startats om minst en gång under den senaste timmen. |