Förbättra motståndskraften genom att replikera Log Analytics-arbetsytan mellan regioner (förhandsversion)
Att replikera Log Analytics-arbetsytan mellan regioner förbättrar motståndskraften genom att du kan växla över till den replikerade arbetsytan och fortsätta om det uppstår ett regionalt fel. Den här artikeln förklarar hur Log Analytics-replikering av arbetsytor fungerar, hur du replikerar din arbetsyta, hur du växlar över och tillbaka och hur du bestämmer när du ska växla mellan dina replikerade arbetsytor.
Här är en video som ger en snabb översikt över hur Log Analytics-replikering av arbetsytor fungerar:
Viktigt!
Även om vi ibland använder termen redundans, till exempel i API-anropet, används redundans ofta för att beskriva en automatisk process. Därför använder den här artikeln termen switchover för att betona att övergången till den replikerade arbetsytan är en åtgärd som du utlöser manuellt.
Behörigheter som krävs
| Åtgärd | Behörigheter som krävs |
|---|---|
| Aktivera replikering av arbetsytor | Microsoft.OperationalInsights/workspaces/write och Microsoft.Insights/dataCollectionEndpoints/write behörigheter, enligt den inbyggda rollen Övervakningsdeltagare, till exempel |
| Växla över och växla tillbaka (utlösa redundans och återställning efter fel) | Microsoft.OperationalInsights/locations/workspaces/failover, Microsoft.OperationalInsights/workspaces/failback, och Microsoft.Insights/dataCollectionEndpoints/triggerFailover/action behörigheter enligt den inbyggda rollen Övervakningsdeltagare, till exempel |
| Kontrollera arbetsytans tillstånd | Microsoft.OperationalInsights/workspaces/read behörigheter till Log Analytics-arbetsytan enligt den inbyggda rollen Övervakningsdeltagare, till exempel |
Så här fungerar replikering av Log Analytics-arbetsyta
Din ursprungliga arbetsyta och region kallas primär. Den replikerade arbetsytan och den alternativa regionen kallas sekundär.
Replikeringsprocessen för arbetsytan skapar en instans av din arbetsyta i den sekundära regionen. Processen skapar den sekundära arbetsytan med samma konfiguration som din primära arbetsyta, och Azure Monitor uppdaterar automatiskt den sekundära arbetsytan med eventuella framtida ändringar som du gör i konfigurationen av den primära arbetsytan.
Den sekundära arbetsytan är en "skugg"-arbetsyta endast i återhämtningssyfte. Du kan inte se den sekundära arbetsytan i Azure Portal och du kan inte hantera eller komma åt den direkt.
När du aktiverar replikering av arbetsytor skickar Azure Monitor även nya loggar som matas in till din primära arbetsyta till den sekundära regionen. Loggar som du matar in till arbetsytan innan du aktiverar replikering av arbetsytor kopieras inte över.
Om ett avbrott påverkar din primära region kan du växla över och omdirigera alla inmatnings- och frågebegäranden till den sekundära regionen. När Azure har åtgärdat avbrotten och den primära arbetsytan är felfri igen kan du växla tillbaka till den primära regionen.
När du växlar över blir den sekundära arbetsytan aktiv och din primära blir inaktiv. Azure Monitor matar sedan in nya data via inmatningspipelinen i den sekundära regionen i stället för den primära regionen. När du växlar över till den sekundära regionen replikerar Azure Monitor alla data som du matar in från den sekundära regionen till den primära regionen. Processen är asynkron och påverkar inte svarstiden för inmatning.
Viktigt!
När du har växlat över till den sekundära regionen, om den primära regionen inte kan bearbeta inkommande loggdata, buffrar Azure Monitor data i den sekundära regionen i upp till 11 dagar. Under de första fyra dagarna försöker Azure Monitor automatiskt replikera data regelbundet.

Regioner som stöds
Replikering av arbetsytor stöds för närvarande för arbetsytor i en begränsad uppsättning regioner, ordnade efter regiongrupper (grupper med geografiskt angränsande regioner). När du aktiverar replikering väljer du en sekundär plats i listan över regioner som stöds i samma regiongrupp som arbetsytans primära plats. Till exempel kan en arbetsyta i Europa, västra replikeras i Europa, norra, men inte i USA, västra 2, eftersom dessa regioner finns i olika regiongrupper.
Dessa regiongrupper och regioner stöds för närvarande:
| Regiongrupp | Regioner | Kommentar |
|---|---|---|
| Nordamerika | USA, östra | Replikering stöds inte till eller från regionen USA, östra 2. |
| USA, östra 2 | Replikering stöds inte till eller från regionen USA, östra. | |
| USA, västra | ||
| USA, västra 2 | ||
| Centrala USA | ||
| USA, södra centrala | ||
| Kanada, centrala | ||
| Europa | Västeuropa | |
| Europa, norra | ||
| Storbritannien, södra | ||
| Storbritannien, västra | ||
| Tyskland, västra centrala | ||
| Centrala Frankrike |
Krav på datahemvist
Olika kunder har olika krav på datahemvist, så det är viktigt att du styr var dina data lagras. Azure Monitor bearbetar och lagrar loggar i de primära och sekundära regioner som du väljer. Mer information finns i Regioner som stöds.
Stöd för Sentinel och andra tjänster
Olika tjänster och funktioner som använder Log Analytics-arbetsytor är kompatibla med replikering och växling av arbetsytor. Dessa tjänster och funktioner fortsätter att fungera när du växlar över till den sekundära arbetsytan.
Till exempel kan regionala nätverksproblem som orsakar svarstid för logginmatning påverka Sentinel-kunder. Kunder som använder replikerade arbetsytor kan växla över till sin sekundära region för att fortsätta arbeta med sin Log Analytics-arbetsyta och Sentinel. Men om nätverksproblemet påverkar Sentinel-tjänstens hälsa kan du inte åtgärda problemet genom att byta till en annan region.
Vissa Azure Monitor-funktioner, inklusive Application Insights och VM Insights, är för närvarande endast delvis kompatibla med replikering och växling av arbetsytor. Den fullständiga listan finns i Begränsningar och begränsningar.
Aktivera och inaktivera replikering av arbetsytor
Du aktiverar och inaktiverar replikering av arbetsytor med hjälp av ett REST-kommando. Kommandot utlöser en tidskrävande åtgärd, vilket innebär att det kan ta några minuter innan de nya inställningarna tillämpas. När du har aktiverat replikering kan det ta upp till en timme för alla tabeller (datatyper) att börja replikera, och vissa datatyper kan börja replikeras före andra. Ändringar som du gör i tabellscheman när du har aktiverat replikering av arbetsytor – till exempel nya anpassade loggtabeller eller anpassade fält som du skapar eller diagnostikloggar som konfigurerats för nya resurstyper – kan ta upp till en timme att börja replikera.
Viktigt!
Replikering av Log Analytics-arbetsytor som är länkade till ett dedikerat kluster stöds för närvarande inte.
Aktivera replikering av arbetsytor
Om du vill aktivera replikering på Log Analytics-arbetsytan använder du det här PUT kommandot:
PUT
https://management.azure.com/subscriptions/<subscription_id>/resourcegroups/<resourcegroup_name>/providers/microsoft.operationalinsights/workspaces/<workspace_name>?api-version=2023-01-01-preview
body:
{
"properties": {
"replication": {
"enabled": true,
"location": "<secondary_region>"
}
},
"location": "<primary_region>"
}
Där:
<subscription_id>: Prenumerations-ID:t som är relaterat till din arbetsyta.<resourcegroup_name>: Resursgruppen som innehåller din Log Analytics-arbetsyteresurs.<workspace_name>: Namnet på din arbetsyta.<primary_region>: Den primära regionen för din Log Analytics-arbetsyta.<secondary_region>: Den region där Azure Monitor skapar den sekundära arbetsytan.
De värden som stöds finns location i Regioner som stöds.
Kommandot PUT är en tidskrävande åtgärd som kan ta lite tid att slutföra. Ett lyckat anrop returnerar en 200 statuskod. Du kan spåra etableringstillståndet för din begäran enligt beskrivningen i Kontrollera etableringstillstånd för begäran.
Kontrollera etableringstillstånd för begäran
Kör det här GET kommandot för att kontrollera etableringstillståndet för din begäran:
GET
https://management.azure.com/subscriptions/<subscription_id>/resourceGroups/<resourcegroup_name>/providers/Microsoft.OperationalInsights/workspaces/<workspace_name>?api-version=2023-01-01-preview
Där:
<subscription_id>: Prenumerations-ID:t som är relaterat till din arbetsyta.<resourcegroup_name>: Resursgruppen som innehåller din Log Analytics-arbetsyteresurs.<workspace_name>: Namnet på din Log Analytics-arbetsyta.
GET Använd kommandot för att kontrollera att etableringstillståndet för arbetsytan ändras från Updating till Succeededoch att den sekundära regionen har angetts som förväntat.
Kommentar
När du aktiverar replikering för arbetsytor som interagerar med Sentinel kan det ta upp till 12 dagar att helt replikera Watchlist- och Threat Intelligence-data till den sekundära arbetsytan.
Associera datainsamlingsregler med slutpunkten för systemdatainsamling
Du använder regler för datainsamling (DCR) för att samla in loggdata med hjälp av Azure Monitor Agent och API:et för inmatning av loggar.
Om du har regler för datainsamling som skickar data till din primära arbetsyta måste du associera reglerna med en systemdatainsamlingsslutpunkt (DCE), som Azure Monitor skapar när du aktiverar replikering av arbetsytor. Namnet på systemdatainsamlingens slutpunkt är identiskt med ditt arbetsyte-ID. Endast datainsamlingsregler som du associerar med arbetsytans slutpunkt för systemdatainsamling möjliggör replikering och växling. Med det här beteendet kan du ange vilken uppsättning loggströmmar som ska replikeras, vilket hjälper dig att kontrollera dina replikeringskostnader.
Om du vill replikera data som du samlar in med hjälp av datainsamlingsregler associerar du dina datainsamlingsregler med systemdatainsamlingens slutpunkt för Log Analytics-arbetsytan:
I Azure Portal väljer du Regler för datainsamling.
På skärmen Datainsamlingsregler väljer du en datainsamlingsregel som skickar data till din primära Log Analytics-arbetsyta.
På sidan Översikt över datainsamlingsregeln väljer du Konfigurera DCE och väljer slutpunkten för systemdatainsamling i listan som är tillgänglig:
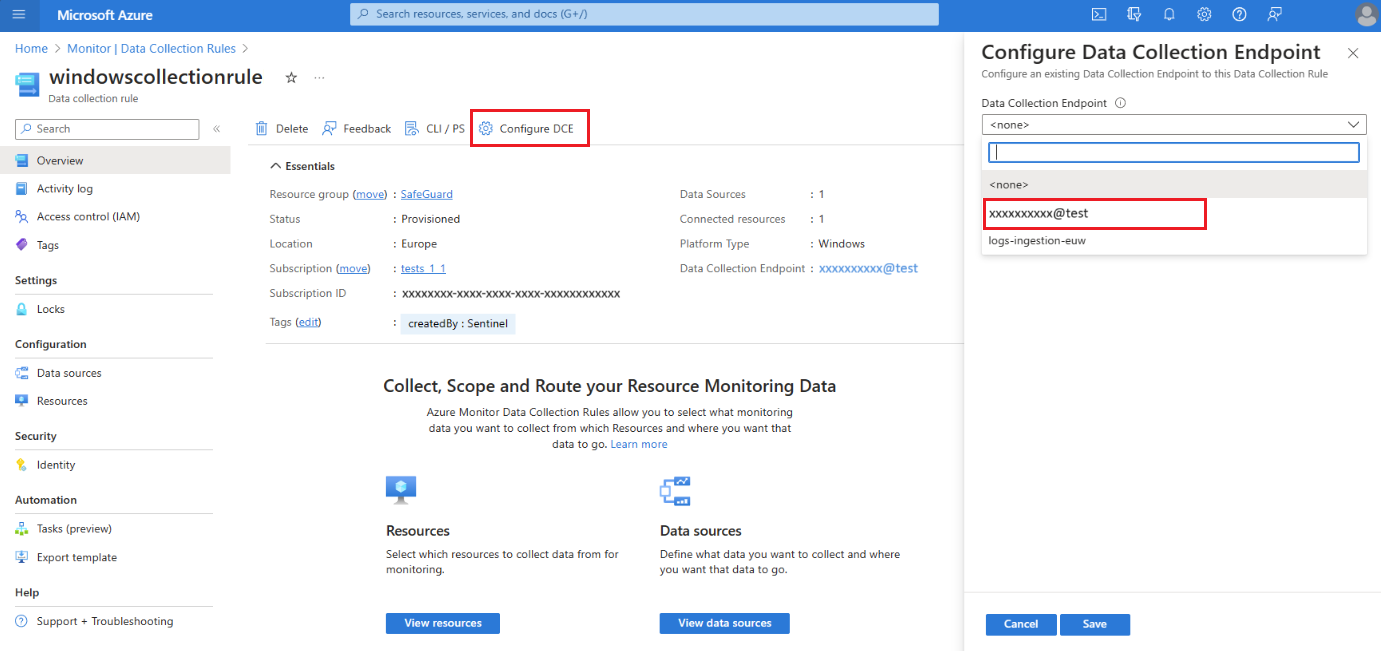 Mer information om System DCE finns i egenskaperna för arbetsytans objekt.
Mer information om System DCE finns i egenskaperna för arbetsytans objekt.

Viktigt!
Regler för datainsamling som är anslutna till en arbetsytas slutpunkt för systemdatainsamling kan endast riktas mot den specifika arbetsytan. Reglerna för datainsamling får inte riktas mot andra mål, till exempel andra arbetsytor eller Azure Storage-konton.
Inaktivera replikering av arbetsytor
Om du vill inaktivera replikering för en arbetsyta använder du det här PUT kommandot:
PUT
https://management.azure.com/subscriptions/<subscription_id>/resourcegroups/<resourcegroup_name>/providers/microsoft.operationalinsights/workspaces/<workspace_name>?api-version=2023-01-01-preview
body:
{
"properties": {
"replication": {
"enabled": false
}
},
"location": "<primary_region>"
}
Där:
<subscription_id>: Prenumerations-ID:t som är relaterat till din arbetsyta.<resourcegroup_name>: Resursgruppen som innehåller din arbetsyteresurs.<workspace_name>: Namnet på din arbetsyta.<primary_region>: Den primära regionen för din arbetsyta.
Kommandot PUT är en tidskrävande åtgärd som kan ta lite tid att slutföra. Ett lyckat anrop returnerar en 200 statuskod. Du kan spåra etableringstillståndet för din begäran enligt beskrivningen i Kontrollera etableringstillstånd för begäran.
Övervaka arbetsyta och tjänsthälsa
Svarstid för inmatning eller frågefel är exempel på problem som ofta kan hanteras genom att växla över till den sekundära regionen. Sådana problem kan identifieras med hjälp av Service Health-meddelanden och loggfrågor.
Service Health-meddelanden är användbara för tjänstrelaterade problem. Om du vill identifiera problem som påverkar din specifika arbetsyta (och eventuellt inte hela tjänsten) kan du använda andra mått:
- Skapa aviseringar baserat på arbetsytans resurshälsa
- Ange egna tröskelvärden för hälsomått för arbetsytan
- Skapa dina egna övervakningsfrågor för att fungera som anpassade hälsoindikatorer för din arbetsyta, enligt beskrivningen i Övervaka arbetsyteprestanda med hjälp av frågor, för att:
- Mäta svarstid för inmatning per tabell
- Identifiera om källan till svarstiden är samlingsagenterna eller inmatningspipelinen
- Övervaka inmatningsvolymavvikelser per tabell och resurs
- Övervaka frågeframgång per tabell, användare eller resurs
- Skapa aviseringar baserat på dina frågor
Kommentar
Du kan också använda loggfrågor för att övervaka den sekundära arbetsytan, men tänk på att loggreplikeringen utförs i batchåtgärder. Den uppmätta svarstiden kan variera och indikerar inte något hälsoproblem med den sekundära arbetsytan. Mer information finns i Granska den inaktiva arbetsytan.
Växla över till den sekundära arbetsytan
Under övergången fungerar de flesta åtgärder på samma sätt som när du använder den primära arbetsytan och regionen. Vissa åtgärder har dock något annorlunda beteende eller blockeras. Mer information finns i Begränsningar och begränsningar.
När ska jag växla över?
Du bestämmer dig för när du ska växla över till den sekundära arbetsytan och växla tillbaka till den primära arbetsytan baserat på pågående prestanda- och hälsoövervakning samt systemstandarder och krav.
Det finns flera saker att tänka på i din plan för övergång, enligt beskrivningen i följande underavsnitt.
Problemtyp och omfång
Växlingsprocessen dirigerar inmatnings- och frågebegäranden till din sekundära region, vilket vanligtvis kringgår eventuella felaktiga komponenter som orsakar svarstid eller fel i din primära region. Därför är det inte troligt att bytet hjälper om:
- Det finns ett problem mellan regioner med en underliggande resurs. Om till exempel samma resurstyper misslyckas i både dina primära och sekundära regioner.
- Du upplever ett problem som rör hantering av arbetsytor, till exempel ändring av kvarhållning av arbetsytor. Hanteringsåtgärder för arbetsytor hanteras alltid i din primära region. Under övergången blockeras hanteringsåtgärder för arbetsytor.
Problemvaraktighet
Byte är inte omedelbart. Processen för omdistribution av begäranden förlitar sig på DNS-uppdateringar, som vissa klienter tar upp inom några minuter medan andra kan ta mer tid. Därför är det bra att förstå om problemet kan lösas inom några minuter. Om det observerade problemet är konsekvent eller kontinuerligt ska du inte vänta med att växla över. Nedan följer några exempel:
Inmatning: Problem med inmatningspipelinen i din primära region kan påverka datareplikeringen till den sekundära arbetsytan. Under övergången skickas loggar i stället till inmatningspipelinen i den sekundära regionen.
Fråga: Om frågor på den primära arbetsytan misslyckas eller överskrider tidsgränsen kan aviseringar för loggsökning påverkas. I det här scenariot växlar du över till den sekundära arbetsytan för att se till att alla aviseringar utlöses korrekt.
Sekundära arbetsytedata
Loggar som matas in till din primära arbetsyta innan du aktiverar replikering kopieras inte till den sekundära arbetsytan. Om du aktiverade replikering av arbetsytor för tre timmar sedan och nu växlar över till den sekundära arbetsytan kan dina frågor bara returnera data från de senaste tre timmarna.
Innan du byter region under övergången måste den sekundära arbetsytan innehålla en användbar mängd loggar. Vi rekommenderar att du väntar minst en vecka efter att du har aktiverat replikering innan du utlöser övergången. De sju dagarna gör att tillräckligt med data kan vara tillgängliga i den sekundära regionen.
Utlösarväxling
Innan du växlar över kontrollerar du att replikeringsåtgärden för arbetsytan har slutförts. Övergången lyckas bara när den sekundära arbetsytan är korrekt konfigurerad.
Om du vill växla över till den sekundära arbetsytan använder du det här POST kommandot:
POST
https://management.azure.com/subscriptions/<subscription_id>/resourceGroups/<resourcegroup_name>/providers/Microsoft.OperationalInsights/locations/<secondary_region>/workspaces/<workspace_name>/failover?api-version=2023-01-01-preview
Där:
<subscription_id>: Prenumerations-ID:t som är relaterat till din arbetsyta.<resourcegroup_name>: Resursgruppen som innehåller din arbetsyteresurs.<secondary_region>: Den region som ska växlas till under övergången.<workspace_name>: Namnet på arbetsytan som ska växlas till under övergången.
Kommandot POST är en tidskrävande åtgärd som kan ta lite tid att slutföra. Ett lyckat anrop returnerar en 202 statuskod. Du kan spåra etableringstillståndet för din begäran enligt beskrivningen i Kontrollera etableringstillstånd för begäran.
Växla tillbaka till den primära arbetsytan
Återställningsprocessen avbryter omdistributionen av frågor och logginmatningsbegäranden till den sekundära arbetsytan. När du växlar tillbaka återgår Azure Monitor till routningsfrågor och logginmatningsbegäranden till din primära arbetsyta.
När du växlar över till den sekundära regionen replikerar Azure Monitor loggar från den sekundära arbetsytan till den primära arbetsytan. Om ett avbrott påverkar logginmatningsprocessen i den primära regionen kan det ta tid för Azure Monitor att slutföra inmatningen av de replikerade loggarna till din primära arbetsyta.
När ska jag växla tillbaka?
Det finns flera saker att tänka på i din plan för switchback, enligt beskrivningen i följande underavsnitt.
Loggreplikeringstillstånd
Innan du växlar tillbaka kontrollerar du att Azure Monitor har slutfört replikeringen av alla loggar som matades in under övergången till den primära regionen. Om du växlar tillbaka innan alla loggar replikeras till den primära arbetsytan kan dina frågor returnera partiella resultat tills logginmatningen har slutförts.
Du kan fråga din primära arbetsyta i Azure Portal för den inaktiva regionen enligt beskrivningen i Granska den inaktiva arbetsytan.
Primär arbetsytas hälsa
Det finns två viktiga hälsoobjekt att kontrollera inför övergången till den primära arbetsytan:
- Bekräfta att det inte finns några utestående Service Health-meddelanden för den primära arbetsytan och regionen.
- Bekräfta att din primära arbetsyta matar in loggar och bearbetar frågor som förväntat.
Exempel på hur du frågar din primära arbetsyta när den sekundära arbetsytan är aktiv och kringgår omdistributionen av begäranden till den sekundära arbetsytan finns i Granska den inaktiva arbetsytan.
Utlösaråterställning
Innan du växlar tillbaka bekräftar du hälsotillståndet för den primära arbetsytan och slutför replikeringen av loggar.
Återställningsprocessen uppdaterar dina DNS-poster. När DNS-posterna har uppdaterats kan det ta tid för alla klienter att ta emot de uppdaterade DNS-inställningarna och återuppta routningen till den primära arbetsytan.
Om du vill växla tillbaka till den primära arbetsytan använder du det här POST kommandot:
POST
https://management.azure.com/subscriptions/<subscription_id>/resourceGroups/<resourcegroup_name>/providers/Microsoft.OperationalInsights/workspaces/<workspace_name>/failback?api-version=2023-01-01-preview
Där:
<subscription_id>: Prenumerations-ID:t som är relaterat till din arbetsyta.<resourcegroup_name>: Resursgruppen som innehåller din arbetsyteresurs.<workspace_name>: Namnet på arbetsytan som ska växlas till under återställningen.
Kommandot POST är en tidskrävande åtgärd som kan ta lite tid att slutföra. Ett lyckat anrop returnerar en 202 statuskod. Du kan spåra etableringstillståndet för din begäran enligt beskrivningen i Kontrollera etableringstillstånd för begäran.
Granska den inaktiva arbetsytan
Som standard är arbetsytans aktiva region den region där du skapar arbetsytan och den inaktiva regionen är den sekundära regionen, där Azure Monitor skapar den replikerade arbetsytan.
När du utlöser redundansväxlar detta – den sekundära regionen aktiveras och den primära regionen blir inaktiv. Vi säger att det är inaktivt eftersom det inte är det direkta målet för logginmatning och frågebegäranden.
Det är användbart att fråga den inaktiva regionen innan du växlar mellan regioner för att kontrollera att arbetsytan i den inaktiva regionen har loggarna som du förväntar dig att se där.
Fråga inaktiv region
Om du vill köra frågor mot loggdata i den inaktiva regionen använder du det här GET-kommandot:
GET
api.loganalytics.azure.com/v1/workspaces/<workspace id>/query?query=<query>×pan=<timespan-in-ISO8601-format>&overrideWorkspaceRegion=<primary|secondary>
Om du till exempel vill köra en enkel fråga som Perf | count för den senaste dagen i den sekundära regionen använder du:
GET
api.loganalytics.azure.com/v1/workspaces/<workspace id>/query?query=Perf%20|%20count×pan=P1D&overrideWorkspaceRegion=secondary
Du kan bekräfta att Azure Monitor kör frågan i den avsedda regionen genom att kontrollera de här fälten LAQueryLogs i tabellen, som skapas när du aktiverar frågegranskning på Log Analytics-arbetsytan:
isWorkspaceInFailover: Anger om arbetsytan var i växlingsläge under frågan. Datatypen är boolesk (sant, falskt).workspaceRegion: Den region på arbetsytan som frågan riktar sig mot. Datatypen är Sträng.
Övervaka prestanda för arbetsytan med hjälp av frågor
Vi rekommenderar att du använder frågorna i det här avsnittet för att skapa aviseringsregler som meddelar dig om eventuella problem med arbetsytans hälsotillstånd eller prestanda. Beslutet att växla över kräver dock noggrant övervägande och bör inte göras automatiskt.
I frågeregeln kan du definiera ett villkor för att växla över till den sekundära arbetsytan efter ett angivet antal överträdelser. Mer information finns i Skapa eller redigera en aviseringsregel för loggsökning.
Två viktiga mått på arbetsytans prestanda är inmatningssvarstid och inmatningsvolym. I följande avsnitt beskrivs de här övervakningsalternativen.
Övervaka svarstid för inmatning från slutpunkt till slutpunkt
Svarstid för inmatning mäter den tid det tar att mata in loggar till arbetsytan. Tidsmätningen startar när den första loggade händelsen inträffar och slutar när loggen lagras på din arbetsyta. Den totala svarstiden för inmatning består av två delar:
- Agentfördröjning: Den tid som krävs av agenten för att rapportera en händelse.
- Svarstid för inmatningspipeline (serverdel): Den tid som krävs för att inmatningspipelinen ska bearbeta loggarna och skriva dem till din arbetsyta.
Olika datatyper har olika svarstid för inmatning. Du kan mäta inmatning för varje datatyp separat eller skapa en allmän fråga för alla typer och en mer detaljerad fråga för specifika typer som är av högre vikt för dig. Vi föreslår att du mäter den 90:e percentilen av inmatningssvarstiden, som är mer känslig för förändring än genomsnittet eller den 50:e percentilen (median).
I följande avsnitt visas hur du använder frågor för att kontrollera svarstiden för inmatning för din arbetsyta.
Utvärdera svarstiden för baslinjeinmatning för specifika tabeller
Börja med att fastställa baslinjesvarstiden för specifika tabeller under flera dagar.
Den här exempelfrågan skapar ett diagram över den 90:e percentilen av svarstiden för inmatning i tabellen Perf:
// Assess the ingestion latency baseline for a specific data type
Perf
| where TimeGenerated > ago(3d)
| project TimeGenerated,
IngestionDurationSeconds = (ingestion_time()-TimeGenerated)/1s
| summarize LatencyIngestion90Percentile=percentile(IngestionDurationSeconds, 90) by bin(TimeGenerated, 1h)
| render timechart
När du har kört frågan granskar du resultatet och det renderade diagrammet för att fastställa den förväntade svarstiden för tabellen.
Övervaka och avisera om aktuell svarstid för inmatning
När du har upprättat svarstiden för baslinjeinmatning för en specifik tabell skapar du en varningsregel för loggsökning för tabellen baserat på ändringar i svarstid under en kort tidsperiod.
Den här frågan beräknar svarstid för inmatning under de senaste 20 minuterna:
// Track the recent ingestion latency (in seconds) of a specific table
Perf
| where TimeGenerated > ago(20m)
| extend IngestionDurationSeconds = (ingestion_time()-TimeGenerated)/1s
| summarize Ingestion90Percent_seconds=percentile(IngestionDurationSeconds, 90)
Eftersom du kan förvänta dig vissa variationer skapar du ett aviseringsregelvillkor för att kontrollera om frågan returnerar ett värde som är betydligt större än baslinjen.
Fastställa källan till svarstid för inmatning
När du märker att den totala svarstiden för inmatning ökar kan du använda frågor för att avgöra om källan till svarstiden är agenterna eller inmatningspipelinen.
Den här frågan visar den 90:e percentilsvarstiden för agenterna och pipelinen separat:
// Assess agent and pipeline (backend) latency
Perf
| where TimeGenerated > ago(1h)
| extend AgentLatencySeconds = (_TimeReceived-TimeGenerated)/1s,
PipelineLatencySeconds=(ingestion_time()-_TimeReceived)/1s
| summarize percentile(AgentLatencySeconds,90), percentile(PipelineLatencySeconds,90) by bin(TimeGenerated,5m)
| render columnchart
Kommentar
Även om diagrammet visar de 90:e percentildata som staplade kolumner, är summan av data i de två diagrammen inte lika med den totala inmatningen av den 90:e percentilen.
Övervaka inmatningsvolym
Mätning av inmatningsvolymer kan hjälpa dig att identifiera oväntade ändringar i den totala eller tabellspecifika inmatningsvolymen för din arbetsyta. Måtten för frågevolym kan hjälpa dig att identifiera prestandaproblem med logginmatning. Några användbara volymmått är:
- Total inmatningsvolym per tabell
- Konstant inmatningsvolym (stillestånd)
- Inmatningsavvikelser – toppar och dalar i inmatningsvolymen
Följande avsnitt visar hur du använder frågor för att kontrollera inmatningsvolymen för din arbetsyta.
Övervaka total inmatningsvolym per tabell
Du kan definiera en fråga för att övervaka inmatningsvolymen per tabell på din arbetsyta. Frågan kan innehålla en avisering som söker efter oväntade ändringar av total- eller tabellspecifika volymer.
Den här frågan beräknar den totala inmatningsvolymen under den senaste timmen per tabell i megabyte per sekund (MBs):
// Calculate total ingestion volume over the past hour per table
Usage
| where TimeGenerated > ago(1h)
| summarize BillableDataMB = sum(_BilledSize)/1.E6 by bin(TimeGenerated,1h), DataType
Kontrollera stillestånd för inmatning
Om du matar in loggar via agenter kan du använda agentens pulsslag för att identifiera anslutningen. Ett stillestånd kan visa ett stopp i logginmatningen till din arbetsyta. När frågedata visar ett inmatningsstopp kan du definiera ett villkor för att utlösa ett önskat svar.
Följande fråga kontrollerar agentens pulsslag för att identifiera anslutningsproblem:
// Count agent heartbeats in the last ten minutes
Heartbeat
| where TimeGenerated>ago(10m)
| count
Övervaka inmatningsavvikelser
Du kan identifiera toppar och dalar i volymdata för arbetsytans inmatning på olika sätt. Använd funktionen series_decompose_anomalies() för att extrahera avvikelser från inmatningsvolymerna som du övervakar på din arbetsyta eller skapa en egen avvikelseidentifiering för att stödja dina unika arbetsytescenarier.
Identifiera avvikelser med hjälp av series_decompose_anomalies
Funktionen series_decompose_anomalies() identifierar avvikelser i en serie datavärden. Den här frågan beräknar volymen för inmatning per timme för varje tabell i Log Analytics-arbetsytan och använder series_decompose_anomalies() för att identifiera avvikelser:
// Calculate hourly ingestion volume per table and identify anomalies
Usage
| where TimeGenerated > ago(24h)
| project TimeGenerated, DataType, Quantity
| summarize IngestionVolumeMB=sum(Quantity) by bin(TimeGenerated, 1h), DataType
| summarize
Timestamp=make_list(TimeGenerated),
IngestionVolumeMB=make_list(IngestionVolumeMB)
by DataType
| extend series_decompose_anomalies(IngestionVolumeMB)
| mv-expand
Timestamp,
IngestionVolumeMB,
series_decompose_anomalies_IngestionVolumeMB_ad_flag,
series_decompose_anomalies_IngestionVolumeMB_ad_score,
series_decompose_anomalies_IngestionVolumeMB_baseline
| where series_decompose_anomalies_IngestionVolumeMB_ad_flag != 0
Mer information om hur du använder series_decompose_anomalies() för att identifiera avvikelser i loggdata finns i Identifiera och analysera avvikelser med hjälp av KQL-maskininlärningsfunktioner i Azure Monitor.
Skapa en egen avvikelseidentifiering
Du kan skapa en anpassad avvikelseidentifiering som stöder scenariokraven för konfigurationen av arbetsytan. Det här avsnittet innehåller ett exempel för att demonstrera processen.
Följande fråga beräknar:
- Förväntad inmatningsvolym: Per timme, per tabell (baserat på medianvärdet för medianvärden, men du kan anpassa logiken)
- Faktisk inmatningsvolym: Per timme, per tabell
För att filtrera bort obetydliga skillnader mellan den förväntade och den faktiska inmatningsvolymen tillämpar frågan två filter:
- Ändringshastighet: Över 150 % eller under 66 % av den förväntade volymen per tabell
- Ändringsvolym: Anger om den ökade eller minskade volymen är mer än 0,1 % av den månatliga volymen i tabellen
// Calculate expected vs actual hourly ingestion per table
let TimeRange=24h;
let MonthlyIngestionByType=
Usage
| where TimeGenerated > ago(30d)
| summarize MonthlyIngestionMB=sum(Quantity) by DataType;
// Calculate the expected ingestion volume by median of hourly medians
let ExpectedIngestionVolumeByType=
Usage
| where TimeGenerated > ago(TimeRange)
| project TimeGenerated, DataType, Quantity
| summarize IngestionMedian=percentile(Quantity, 50) by bin(TimeGenerated, 1h), DataType
| summarize ExpectedIngestionVolumeMB=percentile(IngestionMedian, 50) by DataType;
Usage
| where TimeGenerated > ago(TimeRange)
| project TimeGenerated, DataType, Quantity
| summarize IngestionVolumeMB=sum(Quantity) by bin(TimeGenerated, 1h), DataType
| join kind=inner (ExpectedIngestionVolumeByType) on DataType
| extend GapVolumeMB = round(IngestionVolumeMB-ExpectedIngestionVolumeMB,2)
| where GapVolumeMB != 0
| extend Trend=iff(GapVolumeMB > 0, "Up", "Down")
| extend IngestedVsExpectedAsPercent = round(IngestionVolumeMB * 100 / ExpectedIngestionVolumeMB, 2)
| join kind=inner (MonthlyIngestionByType) on DataType
| extend GapAsPercentOfMonthlyIngestion = round(abs(GapVolumeMB) * 100 / MonthlyIngestionMB, 2)
| project-away DataType1, DataType2
// Determine whether the spike/deep is substantial: over 150% or under 66% of the expected volume for this data type
| where IngestedVsExpectedAsPercent > 150 or IngestedVsExpectedAsPercent < 66
// Determine whether the gap volume is significant: over 0.1% of the total monthly ingestion volume to this workspace
| where GapAsPercentOfMonthlyIngestion > 0.1
| project
Timestamp=format_datetime(todatetime(TimeGenerated), 'yyyy-MM-dd HH:mm:ss'),
Trend,
IngestionVolumeMB,
ExpectedIngestionVolumeMB,
IngestedVsExpectedAsPercent,
GapAsPercentOfMonthlyIngestion
Övervaka lyckade och misslyckade frågor
Varje fråga returnerar en svarskod som anger lyckad eller misslyckad. När frågan misslyckas innehåller svaret även feltyperna. Ett stort antal fel kan tyda på ett problem med arbetsytans tillgänglighet eller tjänstprestanda.
Den här frågan räknar hur många frågor som returnerade en serverfelkod:
// Count query errors
LAQueryLogs
| where ResponseCode>=500 and ResponseCode<600
| count
Villkor och begränsningar
Replikering av Log Analytics-arbetsytor som är länkade till ett dedikerat kluster stöds för närvarande inte.
Rensningsåtgärden, som tar bort poster från en arbetsyta, tar bort relevanta poster från både den primära och den sekundära arbetsytan. Om en av arbetsyteinstanserna inte är tillgänglig misslyckas rensningsåtgärden.
Replikering av aviseringsregler mellan regioner stöds för närvarande inte. Eftersom Azure Monitor stöder frågor mot den inaktiva regionen fortsätter frågebaserade aviseringar att fungera när du växlar mellan regioner om inte aviseringstjänsten i den aktiva regionen inte fungerar korrekt eller om aviseringsreglerna inte är tillgängliga.
När du aktiverar replikering för arbetsytor som interagerar med Sentinel kan det ta upp till 12 dagar att helt replikera Watchlist- och Threat Intelligence-data till den sekundära arbetsytan.
Under övergången stöds inte hanteringsåtgärder för arbetsytor, inklusive:
- Ändra kvarhållning av arbetsytor, prisnivå, dagligt tak och så vidare
- Ändra nätverksinställningar
- Ändra schema via nya anpassade loggar eller ansluta plattformsloggar från nya resursprovidrar, till exempel skicka diagnostikloggar från en ny resurstyp
Funktionen för lösningsmål för den äldre Log Analytics-agenten stöds inte under övergången. Under övergången matas därför lösningsdata in från alla agenter.
Redundansväxlingen uppdaterar DNS-posterna (Domain Name System) för att omdirigera alla inmatningsbegäranden till den sekundära regionen för bearbetning. Vissa HTTP-klienter har "klibbiga anslutningar" och kan ta längre tid att hämta DNS-uppdaterade DNS. Under övergången kan dessa klienter försöka mata in loggar via den primära regionen under en tid. Du kanske matar in loggar till din primära arbetsyta med hjälp av olika klienter, inklusive den äldre Log Analytics-agenten, Azure Monitor Agent, kod (med hjälp av API:et för logginmatning eller det äldre API:et för HTTP-datainsamling) och andra tjänster, till exempel Sentinel.
Dessa funktioner stöds för närvarande inte eller stöds endast delvis:
Funktion Support Tilläggstabellplaner Stöds ej. Azure Monitor replikerar inte data i tabeller med hjälploggplanen till den sekundära arbetsytan. Därför skyddas dessa data inte mot dataförlust i händelse av ett regionalt fel och är inte tillgängliga när du växlar över till den sekundära arbetsytan. Sökjobb, Återställ Stöds delvis – Sökjobb och återställningsåtgärder skapar tabeller och fyller dem med sökresultat eller återställda data. När du har aktiverat replikering av arbetsytor replikeras nya tabeller som skapats för dessa åtgärder till den sekundära arbetsytan. Tabeller som fylls i innan du aktiverar replikering replikeras inte. Om dessa åtgärder pågår när du växlar över är resultatet oväntat. Det kan slutföras men inte replikeras, eller så kan det misslyckas, beroende på arbetsytans hälsa och den exakta tidpunkten. Application Insights via Log Analytics-arbetsytor Stöds inte VM-insikter Stöds inte Containerinsikter Stöds inte Privata länkar Stöds inte under redundansväxling