Självstudie: Synkronisera data från SQL Edge till Azure Blob Storage med hjälp av Azure Data Factory
Viktigt!
Azure SQL Edge dras tillbaka den 30 september 2025. Mer information och migreringsalternativ finns i meddelandet Om pensionering.
Kommentar
Azure SQL Edge stöder inte längre ARM64-plattformen.
Den här självstudien visar hur du använder Azure Data Factory för att inkrementellt synkronisera data till Azure Blob Storage från en tabell i en instans av Azure SQL Edge.
Innan du börjar
Om du inte redan har skapat en databas eller tabell i azure SQL Edge-distributionen använder du någon av följande metoder för att skapa en:
Använd SQL Server Management Studio eller Azure Data Studio för att ansluta till SQL Edge. Kör ett SQL-skript för att skapa databasen och tabellen.
Skapa en databas och tabell med hjälp av sqlcmd genom att ansluta direkt till SQL Edge-modulen. Mer information finns i Ansluta till databasmotorn med hjälp av sqlcmd.
Använd SQLPackage.exe för att distribuera en DAC-paketfil till SQL Edge-containern. Du kan automatisera den här processen genom att ange SqlPackage-fil-URI:n som en del av modulens önskade egenskapskonfiguration. Du kan också använda klientverktyget SqlPackage.exe direkt för att distribuera ett DAC-paket till SQL Edge.
Information om hur du laddar ned SqlPackage.exe finns i Ladda ned och installera sqlpackage. Följande är några exempelkommandon för SqlPackage.exe. Mer information finns i dokumentationen om SqlPackage.exe.
Skapa ett DAC-paket
sqlpackage /Action:Extract /SourceConnectionString:"Data Source=<Server_Name>,<port>;Initial Catalog=<DB_name>;User ID=<user>;Password=<password>" /TargetFile:<dacpac_file_name>Använda ett DAC-paket
sqlpackage /Action:Publish /Sourcefile:<dacpac_file_name> /TargetServerName:<Server_Name>,<port> /TargetDatabaseName:<DB_Name> /TargetUser:<user> /TargetPassword:<password>
Skapa en SQL-tabell och -procedur för att lagra och uppdatera vattenstämpelnivåerna
En vattenstämpeltabell används för att lagra den senaste tidsstämpeln upp till vilken data redan har synkroniserats med Azure Storage. En lagrad transact-SQL-procedur (T-SQL) används för att uppdatera vattenstämpeltabellen efter varje synkronisering.
Kör följande kommandon på SQL Edge-instansen:
CREATE TABLE [dbo].[watermarktable] (
TableName VARCHAR(255),
WatermarkValue DATETIME,
);
GO
CREATE PROCEDURE usp_write_watermark @timestamp DATETIME,
@TableName VARCHAR(50)
AS
BEGIN
UPDATE [dbo].[watermarktable]
SET [WatermarkValue] = @timestamp
WHERE [TableName] = @TableName;
END
GO
Skapa en Data Factory-pipeline
I det här avsnittet skapar du en Azure Data Factory-pipeline för att synkronisera data till Azure Blob Storage från en tabell i Azure SQL Edge.
Skapa en datafabrik med hjälp av Användargränssnittet för Data Factory
Skapa en datafabrik genom att följa anvisningarna i den här självstudien.
Skapa en Data Factory-pipeline
På sidan Kom igång i Data Factory-användargränssnittet väljer du Skapa pipeline.

På sidan Allmänt i fönstret Egenskaper för pipelinen anger du PeriodicSync som namn.
Lägg till uppslagsaktiviteten för att hämta det gamla vattenstämpelvärdet. I fönstret Aktiviteter expanderar du Allmänt och drar uppslagsaktiviteten till pipelinedesignytan. Ändra namnet på aktiviteten till OldWatermark.
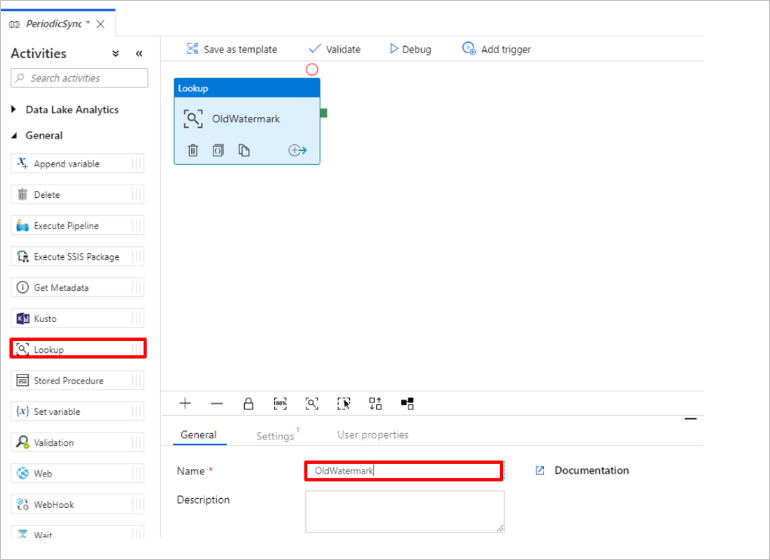
Växla till fliken Inställningar och välj Nytt för Källdatauppsättning. Nu ska du skapa en datauppsättning som representerar data i vattenstämpeltabellen. Den här tabellen innehåller den gamla vattenstämpeln som användes i den tidigare kopieringen.
I fönstret Ny datauppsättning väljer du Azure SQL Server och sedan Fortsätt.
I fönstret Ange egenskaper för datauppsättningen går du till Namn och anger WatermarkDataset.
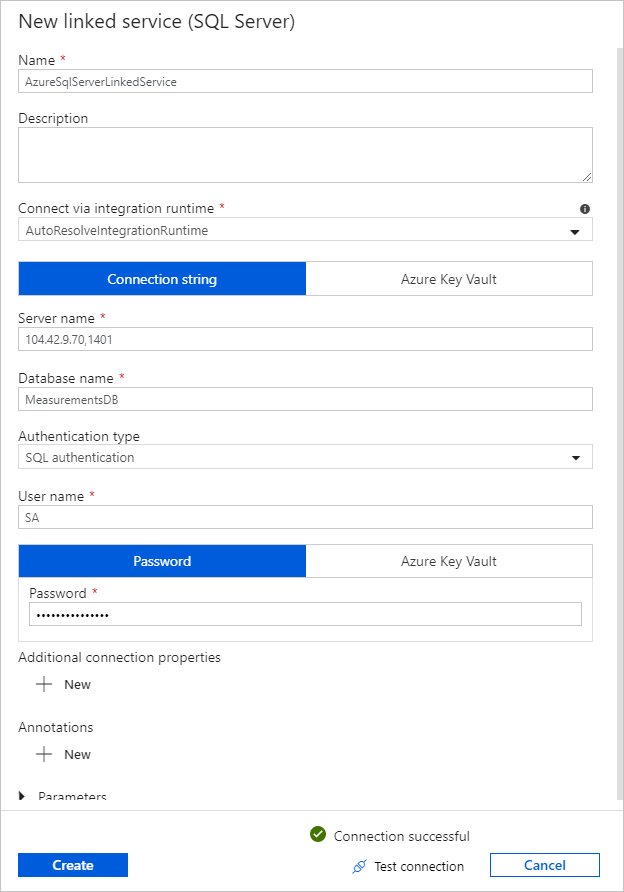
För Länkad tjänst väljer du Ny och slutför sedan följande steg:
Under Namn anger du SQLDBEdgeLinkedService.
Under Servernamn anger du din SQL Edge-serverinformation.
Välj ditt databasnamn i listan.
Ange användarnamn och lösenord.
Om du vill testa anslutningen till SQL Edge-instansen väljer du Testa anslutning.
Välj Skapa.
Välj OK.
På fliken Inställningar väljer du Redigera.
På fliken Anslutning väljer du
[dbo].[watermarktable]tabell. Om du vill förhandsgranska data i tabellen väljer du Förhandsgranska data.Växla till pipelineredigeraren genom att välja fliken pipeline överst eller genom att välja namnet på pipelinen i trädvyn till vänster. I egenskapsfönstret för uppslagsaktiviteten bekräftar du att WatermarkDataset har valts i listan Källdatauppsättning .
I fönstret Aktiviteter expanderar du Allmänt och drar en annan sökningsaktivitet till pipelinedesignytan. Ange namnet till NewWatermark på fliken Allmänt i egenskapsfönstret. Den här uppslagsaktiviteten hämtar det nya vattenstämpelvärdet från tabellen som innehåller källdata så att den kan kopieras till målet.
I egenskapsfönstret för den andra sökningsaktiviteten växlar du till fliken Inställningar och väljer Ny för att skapa en datauppsättning som pekar på källtabellen som innehåller det nya vattenstämpelvärdet.
I fönstret Ny datauppsättning väljer du SQL Edge-instans och väljer sedan Fortsätt.
I fönstret Ange egenskaper , under Namn, anger du SourceDataset. Under Länkad tjänst väljer du SQLDBEdgeLinkedService.
Under Tabell väljer du den tabell som du vill synkronisera. Du kan också ange en fråga för den här datamängden enligt beskrivningen senare i den här självstudien. Frågan har företräde framför den tabell som du anger i det här steget.
Välj OK.
Växla till pipelineredigeraren genom att välja fliken pipeline överst eller genom att välja namnet på pipelinen i trädvyn till vänster. I egenskapsfönstret för uppslagsaktiviteten bekräftar du att SourceDataset har valts i listan Källdatauppsättning .
Välj Fråga under Använd fråga. Uppdatera tabellnamnet i följande fråga och ange sedan frågan. Du väljer bara det maximala värdet
timestampför i tabellen. Se till att endast välja Första raden.SELECT MAX(timestamp) AS NewWatermarkValue FROM [TableName];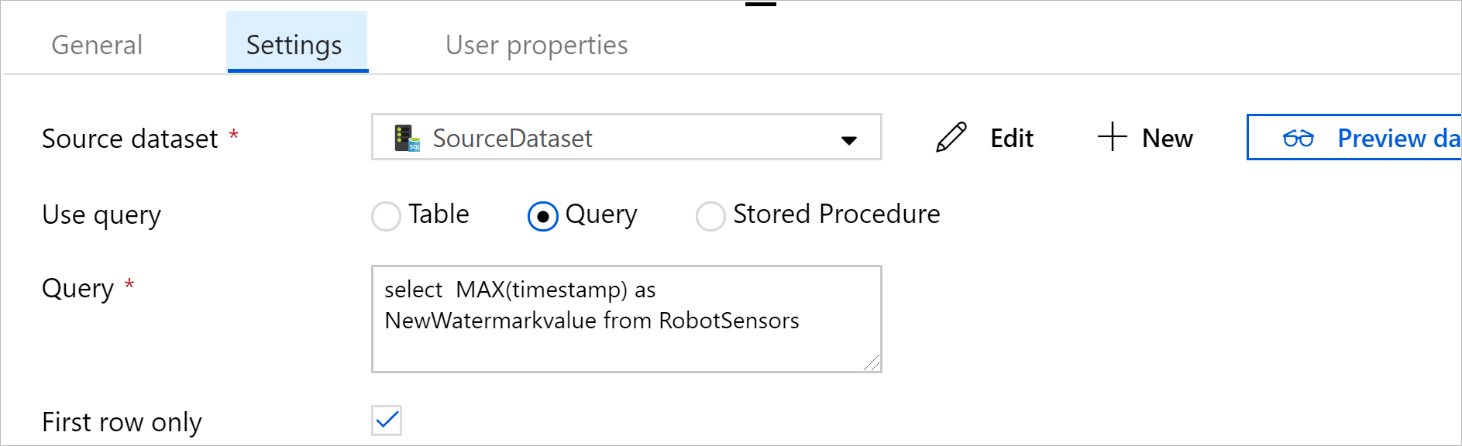
I fönstret Aktiviteter expanderar du Flytta och transformera och drar aktiviteten Kopiera från fönstret Aktiviteter till designerytan. Ange namnet på aktiviteten till IncrementalCopy.
Anslut båda sökningsaktiviteterna till kopieringsaktiviteten genom att dra den gröna knappen som är ansluten till sökningsaktiviteterna till kopieringsaktiviteten. Släpp musknappen när du ser kantfärgen på aktiviteten Kopiera ändras till blå.
Välj aktiviteten Kopiera och bekräfta att du ser egenskaperna för aktiviteten i fönstret Egenskaper.
Växla till fliken Källa i fönstret Egenskaper och slutför följande steg:
I rutan Källdatauppsättning väljer du SourceDataset.
Under Använd fråga väljer du Fråga.
Ange SQL-frågan i rutan Fråga . Här är en exempelfråga:
SELECT * FROM TemperatureSensor WHERE timestamp > '@{activity(' OldWaterMark ').output.firstRow.WatermarkValue}' AND timestamp <= '@{activity(' NewWaterMark ').output.firstRow.NewWatermarkvalue}';På fliken Mottagare väljer du Nytt under Datauppsättning för mottagare.
I den här självstudien är datalagret för mottagare ett Azure Blob Storage-datalager. Välj Azure Blob Storage och välj sedan Fortsätt i fönstret Ny datauppsättning .
I fönstret Välj format väljer du formatet för dina data och väljer sedan Fortsätt.
I fönstret Ange egenskaper under Namn anger du SinkDataset. Under Länkad tjänst väljer du Ny. Nu ska du skapa en anslutning (en länkad tjänst) till Azure Blob Storage.
I fönstret Ny länkad tjänst (Azure Blob Storage) utför du följande steg:
I rutan Namn anger du AzureStorageLinkedService.
Under Lagringskontonamn väljer du Azure Storage-kontot för din Azure-prenumeration.
Testa anslutningen och välj sedan Slutför.
I fönstret Ange egenskaper bekräftar du att AzureStorageLinkedService har valts under Länkad tjänst. Välj Skapa och OK.
På fliken Mottagare väljer du Redigera.
Gå till fliken Anslutning i SinkDataset och slutför följande steg:
Under Filsökväg anger du
asdedatasync/incrementalcopy, därasdedatasyncär namnet på blobcontainern ochincrementalcopyär mappnamnet. Skapa containern om den inte finns eller använd namnet på en befintlig. Azure Data Factory skapar automatiskt utdatamappenincrementalcopyom den inte finns. Du kan också använda knappen Bläddra för Filsökväg för att navigera till en mapp i en blobcontainer.För fildelen av filsökvägen väljer du Lägg till dynamiskt innehåll [Alt+P] och anger
@CONCAT('Incremental-', pipeline().RunId, '.txt')sedan i fönstret som öppnas. Välj Slutför. Filnamnet genereras dynamiskt av uttrycket. Varje pipelinekörning har ett unikt ID. Kopieringsaktiviteten använder körnings-ID för att generera filnamnet.
Växla till pipelineredigeraren genom att välja fliken pipeline överst eller genom att välja namnet på pipelinen i trädvyn till vänster.
I fönstret Aktiviteter expanderar du Allmänt och drar aktiviteten Lagrad procedur från fönstret Aktiviteter till pipelinedesignytan. Anslut de gröna (lyckade) utdata från aktiviteten Kopiera till aktiviteten Lagrad procedur.
Välj Lagrad proceduraktivitet i pipelinedesignern och ändra namnet till
SPtoUpdateWatermarkActivity.Växla till fliken SQL-konto och välj *QLDBEdgeLinkedService under Länkad tjänst.
Växla till fliken Lagrad procedur och slutför följande steg:
Under Namn på lagrad procedur väljer du
[dbo].[usp_write_watermark].Om du vill ange värden för parametrarna för lagrad procedur väljer du Importera parameter och anger följande värden för parametrarna:
Namn Typ Värde LastModifiedTime Datum/tid @{activity('NewWaterMark').output.firstRow.NewWatermarkvalue}TableName String @{activity('OldWaterMark').output.firstRow.TableName}Om du vill verifiera pipelineinställningarna väljer du Verifiera i verktygsfältet. Kontrollera att det inte finns några verifieringsfel. Om du vill stänga fönstret PipelineVerifieringsrapport väljer du >>.
Publicera entiteterna (länkade tjänster, datauppsättningar och pipelines) till Azure Data Factory-tjänsten genom att välja knappen Publicera alla . Vänta tills du ser ett meddelande som bekräftar att publiceringsåtgärden har slutförts.
Utlösa en pipeline baserat på ett schema
I verktygsfältet pipeline väljer du Lägg till utlösare, ny /redigera och sedan Ny.
Ge utlösaren namnet HourlySync. Under Typ väljer du Schema. Ange Upprepning till var 1 timme.
Välj OK.
Välj Publicera alla.
Välj Utlös nu.
Växla till fliken Övervaka till vänster. Du kan se status för den pipelinekörning som utlöstes av den manuella utlösaren. Om du vill uppdatera listan väljer du Refresh (Uppdatera).
## Relaterat innehåll
- Azure Data Factory-pipelinen i den här självstudien kopierar data från en tabell på en SQL Edge-instans till en plats i Azure Blob Storage en gång i timmen. Mer information om hur du använder Data Factory i andra scenarier finns i de här självstudierna.