Intelligenta program med Azure SQL Database
Gäller för:![]() Azure SQL Database
Azure SQL Database
Den här artikeln innehåller en översikt över hur du använder AI-alternativ (artificiell intelligens), till exempel OpenAI och vektorer, för att skapa intelligenta program med Azure SQL Database.
Översikt
Med stora språkmodeller (LLM) kan utvecklare skapa AI-baserade program med en välbekant användarupplevelse.
Användning av LLM:er i program ger större värde och en förbättrad användarupplevelse när modellerna kan komma åt rätt data, vid rätt tidpunkt, från programmets databas. Den här processen kallas RAG (Retrieval Augmented Generation) och Azure SQL Database har många funktioner som stöder det här nya mönstret, vilket gör det till en bra databas för att skapa intelligenta program.
Följande länkar innehåller exempelkod för olika Azure SQL Database-alternativ för att skapa intelligenta program:
| AI-alternativ | beskrivning |
|---|---|
| Azure OpenAI | Generera inbäddningar för RAG och integrera med alla modeller som stöds av Azure OpenAI. |
| Vektorer | Lär dig hur du lagrar och frågar vektorer i Azure SQL Database. |
| Azure AI Search | Använd Azure SQL Database tillsammans med Azure AI Search för att träna LLM på dina data. |
| Intelligenta program | Lär dig hur du skapar en lösning från slutpunkt till slutpunkt med hjälp av ett vanligt mönster som kan replikeras i alla scenarier. |
Nyckelbegrepp
Det här avsnittet innehåller viktiga begrepp som är viktiga för att implementera RAG med Azure SQL Database och Azure OpenAI.
Hämtning av utökad generation (RAG)
RAG är en teknik som förbättrar LLM:s förmåga att producera relevanta och informativa svar genom att hämta ytterligare data från externa källor. RAG kan till exempel köra frågor mot artiklar eller dokument som innehåller domänspecifik kunskap om användarens fråga eller fråga. LLM kan sedan använda dessa hämtade data som referens när den genererar sitt svar. Ett enkelt RAG-mönster med Azure SQL Database kan till exempel vara:
- Infoga data i en Azure SQL Database-tabell.
- Länka Azure SQL Database till Azure AI Search.
- Skapa en Azure OpenAI GPT4-modell och anslut den till Azure AI Search.
- Chatta och ställ frågor om dina data med hjälp av den tränade Azure OpenAI-modellen från ditt program och från Azure SQL Database.
RAG-mönstret, med snabb teknik, tjänar syftet att förbättra svarskvaliteten genom att erbjuda mer kontextuell information till modellen. RAG gör det möjligt för modellen att tillämpa en bredare kunskapsbas genom att införliva relevanta externa källor i genereringsprocessen, vilket resulterar i mer omfattande och välgrundade svar. Mer information om grundande LLM:er finns i Grounding LLMs – Microsoft Community Hub.
Prompts och prompt engineering
En uppmaning refererar till specifik text eller information som fungerar som en instruktion till en LLM, eller som kontextuella data som LLM kan bygga vidare på. En fråga kan ha olika former, till exempel en fråga, en instruktion eller till och med ett kodfragment.
Följande är en lista över frågor som kan användas för att generera ett svar från en LLM:
- Instruktioner: tillhandahålla direktiv till LLM
- Primärt innehåll: ger information till LLM för bearbetning
- Exempel: hjälp med att villkora modellen för en viss uppgift eller process
- Tips: dirigera LLM:s utdata i rätt riktning
- Stödinnehåll: representerar kompletterande information som LLM kan använda för att generera utdata
Processen att skapa bra frågor för ett scenario kallas prompt engineering. Mer information om frågor och metodtips för snabbteknik finns i Azure OpenAI Service.
Token
Token är små textsegment som genereras genom att dela upp indatatexten i mindre segment. Dessa segment kan antingen vara ord eller grupper av tecken, som varierar i längd från ett enda tecken till ett helt ord. Ordet hamburger skulle till exempel delas in i token som ham, buroch ger även om ett kort och vanligt ord som skulle betraktas som pear en enda token.
I Azure OpenAI omvandlas indatatext som tillhandahålls till API:et till token (tokeniserad). Antalet token som bearbetas i varje API-begäran beror på faktorer som längden på parametrarna för indata, utdata och begäran. Mängden token som bearbetas påverkar även modellernas svarstid och dataflöde. Det finns gränser för hur många token varje modell kan ta i en enda begäran/svar från Azure OpenAI. Mer information finns i kvoter och gränser för Azure OpenAI-tjänsten.
Vektorer
Vektorer är ordnade matriser med tal (vanligtvis flyttal) som kan representera information om vissa data. En bild kan till exempel representeras som en vektor med pixelvärden, eller så kan en textsträng representeras som en vektor eller ASCII-värden. Processen för att omvandla data till en vektor kallas vektorisering.
Inbäddningar
Inbäddningar är vektorer som representerar viktiga datafunktioner. Inbäddningar lärs ofta med hjälp av en djupinlärningsmodell, och maskininlärnings- och AI-modeller använder dem som funktioner. Inbäddningar kan också fånga semantisk likhet mellan liknande begrepp. När vi till exempel genererar en inbäddning för orden person och humanförväntar vi oss att deras inbäddningar (vektorrepresentation) är liknande i värde eftersom orden också är semantiskt lika.
Azure OpenAI har modeller för att skapa inbäddningar från textdata. Tjänsten delar upp text i token och genererar inbäddningar med hjälp av modeller som förtränats av OpenAI. Mer information finns i Skapa inbäddningar med Azure OpenAI.
Vektorsökning
Vektorsökning syftar på processen att hitta alla vektorer i en datauppsättning som semantiskt liknar en specifik frågevektor. Därför söker en frågevektor för ordet human i hela ordlistan efter semantiskt liknande ord och bör hitta ordet person som en nära matchning. Den här närheten, eller avståndet, mäts med hjälp av ett likhetsmått, till exempel cosininelikhet. Ju närmare vektorer är i likhet, desto mindre är avståndet mellan dem.
Tänk dig ett scenario där du kör en fråga över miljontals dokument för att hitta de mest liknande dokumenten i dina data. Du kan skapa inbäddningar för dina data och köra frågor mot dokument med hjälp av Azure OpenAI. Sedan kan du utföra en vektorsökning för att hitta de mest liknande dokumenten från datauppsättningen. Att utföra en vektorsökning i några exempel är dock trivialt. Det blir svårt att utföra samma sökning över tusentals eller miljoner datapunkter. Det finns också kompromisser mellan omfattande sökning och ungefärliga sökmetoder för närmaste granne (ANN), inklusive svarstid, dataflöde, noggrannhet och kostnad, som alla beror på kraven för ditt program.
Eftersom Azure SQL Database-inbäddningar effektivt kan lagras och efterfrågas med hjälp av stöd för columnstore-index, vilket ger exakt närmaste grannsökning med bra prestanda, behöver du inte bestämma mellan noggrannhet och hastighet: du kan ha båda. Lagring av vektorbäddningar tillsammans med data i en integrerad lösning minimerar behovet av att hantera datasynkronisering och påskyndar din tid till marknad för UTVECKLING av AI-program.
Azure OpenAI
Inbäddning är processen för att representera den verkliga världen som data. Text, bilder eller ljud kan konverteras till inbäddningar. Azure OpenAI-modeller kan omvandla verklig information till inbäddningar. Modellerna är tillgängliga som REST-slutpunkter och kan därför enkelt användas från Azure SQL Database med hjälp av den sp_invoke_external_rest_endpoint systemlagrade proceduren:
DECLARE @retval INT, @response NVARCHAR(MAX);
DECLARE @payload NVARCHAR(MAX);
SET @payload = JSON_OBJECT('input': @text);
EXEC @retval = sp_invoke_external_rest_endpoint @url = 'https://<openai-url>/openai/deployments/<model-name>/embeddings?api-version=2023-03-15-preview',
@method = 'POST',
@credential = [https://<openai-url>/openai/deployments/<model-name>],
@payload = @payload,
@response = @response OUTPUT;
SELECT CAST([key] AS INT) AS [vector_value_id],
CAST([value] AS FLOAT) AS [vector_value]
FROM OPENJSON(JSON_QUERY(@response, '$.result.data[0].embedding'));
Att använda ett anrop till en REST-tjänst för att hämta inbäddningar är bara ett av de integreringsalternativ som du har när du arbetar med SQL Database och OpenAI. Du kan låta någon av de tillgängliga modellerna komma åt data som lagras i Azure SQL Database för att skapa lösningar där användarna kan interagera med data, till exempel följande exempel.
Ytterligare exempel på hur du använder SQL Database och OpenAI finns i följande artiklar:
- Generera avbildningar med Azure OpenAI Service (DALL-E) och Azure SQL Database
- Använda OpenAI REST-slutpunkter med Azure SQL Database
Vektorer
Även om Azure SQL Database inte har någon intern vektortyp är en vektor inget annat än en ordnad tupplar, och relationsdatabaser är bra på att hantera tupplar. Du kan se en tuppeln som den formella termen för en rad i en tabell.
Azure SQL Database stöder även columnstore-index och körning av batchläge. En vektorbaserad metod används för bearbetning i batchläge, vilket innebär att varje kolumn i en batch har en egen minnesplats där den lagras som en vektor. Detta möjliggör snabbare och effektivare bearbetning av data i batchar.
Följande är ett exempel på hur en vektor kan lagras i SQL Database:
CREATE TABLE [dbo].[wikipedia_articles_embeddings_titles_vector]
(
[article_id] [int] NOT NULL,
[vector_value_id] [int] NOT NULL,
[vector_value] [float] NOT NULL
)
GO
CREATE CLUSTERED COLUMNSTORE INDEX ixc
ON dbo.wikipedia_articles_embeddings_titles_vector
ORDER (article_id);
GO
Ett exempel som använder en gemensam delmängd av Wikipedia-artiklar med inbäddningar som redan genererats med OpenAI finns i Vector similarity search with Azure SQL Database and OpenAI (Vektorlikhetssökning med Azure SQL Database och OpenAI).
Ett annat alternativ för att använda Vector Search i Azure SQL Database är integrering med Azure AI med hjälp av de integrerade vektoriseringsfunktionerna: Vektorsökning med Azure SQL Database och Azure AI Search
Azure AI Search
Implementera RAG-mönster med Azure SQL Database och Azure AI Search. Du kan köra chattmodeller som stöds på data som lagras i Azure SQL Database utan att behöva träna eller finjustera modeller tack vare integreringen av Azure AI Search med Azure OpenAI och Azure SQL Database. Genom att köra modeller på dina data kan du chatta ovanpå och analysera dina data med större noggrannhet och hastighet.
- Azure OpenAI för dina data
- Hämtning av utökad generation (RAG) i Azure AI Search
- Vektorsökning med Azure SQL Database och Azure AI Search
Intelligenta program
Azure SQL Database kan användas för att skapa intelligenta program som innehåller AI-funktioner, till exempel rekommenderare och RAG (Retrieval Augmented Generation) som följande diagram visar:
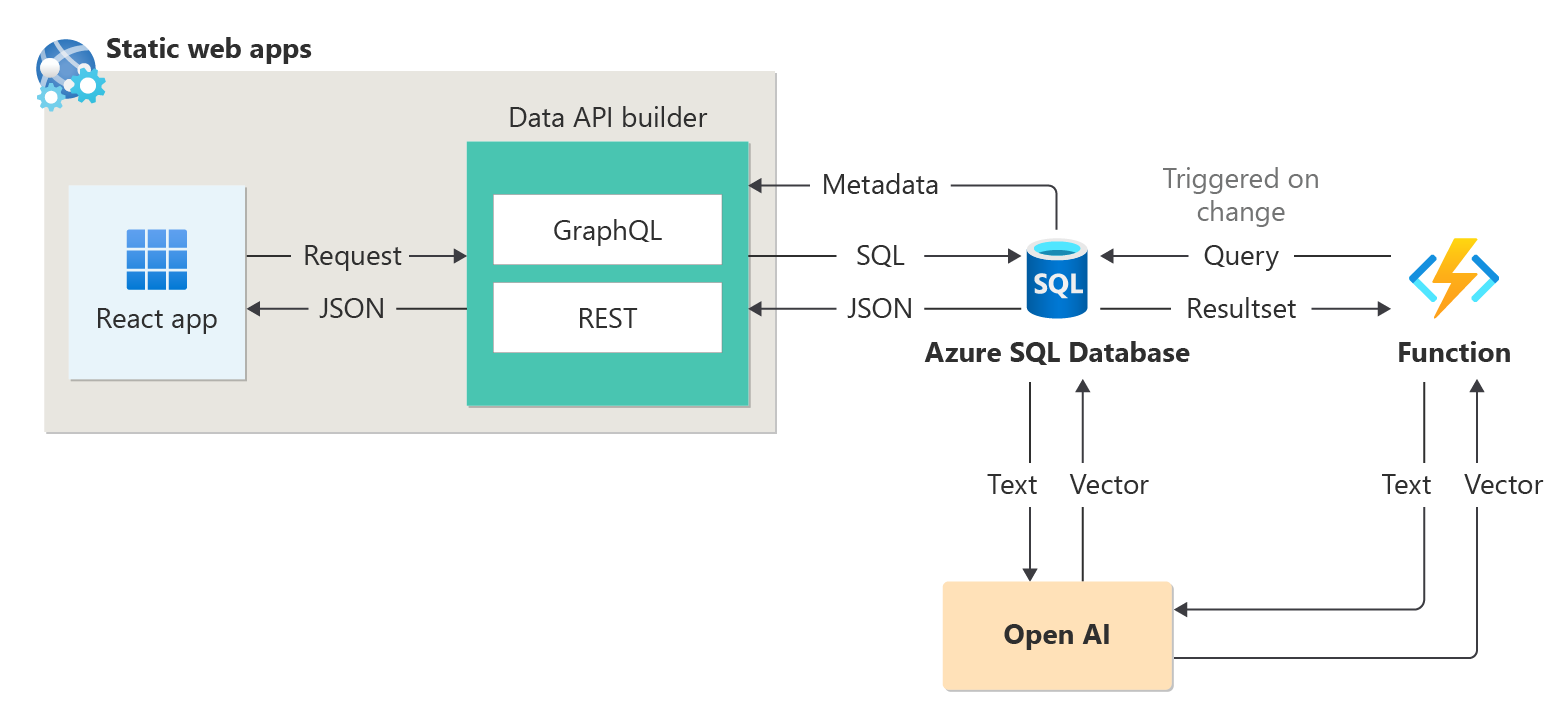
Ett exempel från slutpunkt till slutpunkt för att skapa en rekommenderare med sessionssammandrag som en exempeldatauppsättning finns i How I built a session recommender in 1 hour using Open AI (Hur jag skapade en sessionsrekommendator på 1 timme med Open AI).
LangChain-integrering
LangChain är ett välkänt ramverk för att utveckla program som drivs av språkmodeller.
Ett exempel som visar hur LangChain kan användas för att skapa en chattrobot på dina egna data finns i Skapa din egen DB Copilot för Azure SQL med Azure OpenAI GPT-4.
Relaterat innehåll
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för