Elastiska jobb i Azure SQL Database (förhandsversion)
Gäller för:![]() Azure SQL Database
Azure SQL Database
I den här artikeln går vi igenom funktionerna och informationen om elastiska jobb för Azure SQL Database.
- En självstudiekurs om hur du konfigurerar elastiska jobb finns i självstudien om elastiska jobb.
- Läs mer om automatiseringsbegrepp på Azure-databasplattformar.
Kommentar
Elastiska jobb finns i förhandsversion. Funktioner som för närvarande är i förhandsversion är tillgängliga under kompletterande användningsvillkor, granska för juridiska villkor som gäller för Azure-funktioner som är i förhandsversion. Azure SQL Database innehåller förhandsversioner som ger dig möjlighet att utvärdera och dela feedback med produktgruppen om funktioner innan de blir allmänt tillgängliga (GA).
Översikt över elastiska jobb
Du kan skapa och schemalägga elastiska jobb som regelbundet kan köras mot en eller flera Azure SQL-databaser för att köra Transact-SQL-frågor (T-SQL) och utföra underhållsaktiviteter.
Du kan definiera en måldatabas eller grupper av databaser där jobbet ska köras, och även definiera scheman för när jobbet ska köras. Alla datum och tider i elastiska jobb finns i UTC-tidszonen.
Ett jobb hanterar uppgiften att logga in på måldatabasen. Du definierar, underhåller och bevarar även Transact-SQL-skript som ska köras över en grupp databaser.
Alla jobb loggar status för körning och försöker automatiskt utföra åtgärderna på nytt om det uppstår fel.
När du ska använda elastiska jobb
Det finns flera scenarier när du kan använda elastisk jobbautomatisering:
- Automatisera hanteringsuppgifter och schemalägg dem så att de körs varje veckodag, efter timmar osv.
- Distribuera schemaändringar, hantering av autentiseringsuppgifter.
- Telemetriinsamling för prestandadata eller klientorganisation (kund).
- Uppdatera referensdata (information som är gemensam över alla databaser).
- Läs in data från Azure Blob Storage.
- Konfigurera jobb att köras i en samling databaser regelbundet, till exempel under lågtrafik.
- Samla in frågeresultat från en uppsättning databaser till en central tabell regelbundet.
- Frågor kan köras kontinuerligt och konfigureras för att utlösa ytterligare uppgifter som ska köras.
- Samla in data för rapportering
- Aggregera data från en samling databaser till en enda måltabell.
- Kör databearbetningsfrågor med längre körningstid över en stor uppsättning databaser, till exempel insamling av kundtelemetri. Resultaten samlas till en enskild måltabell för ytterligare analys.
- Dataförflyttning
- För anpassade utvecklade lösningar, affärsautomatisering eller annan uppgiftshantering.
- ETL-bearbetning för att extrahera/bearbeta/infoga data mellan tabeller i en databas.
Överväg elastiska jobb när du:
- Ha en uppgift som måste köras regelbundet enligt ett schema som riktar sig till en eller flera databaser.
- Ha en uppgift som måste köras en gång, men över flera databaser.
- Behöver köra jobb mot valfri kombination av databaser: en eller flera enskilda databaser, alla databaser på en server, alla databaser i en elastisk pool, med den extra flexibiliteten att inkludera eller exkludera en specifik databas. Jobb kan köras över flera servrar och flera pooler och kan även köras mot databaser i olika prenumerationer. Servrar och pooler räknas upp dynamiskt vid körning. Därför körs jobben mot alla databaser som finns i målgruppen vid tidpunkten för körningen.
- Det här är en betydande skillnad från SQL Agent, som inte dynamiskt kan räkna upp måldatabaserna, särskilt i SaaS-kundscenarier där databaser läggs till/tas bort dynamiskt.
Elastiska jobbkomponenter
| Komponent | beskrivning |
|---|---|
| Elastisk jobbagent | Den Azure-resurs som du skapar för att köra och hantera jobb. |
| Jobbdatabas | En databas i Azure SQL Database som jobbagenten använder för att lagra jobbrelaterade data, jobbdefinitioner osv. |
| Jobb | Ett jobb är en arbetsprocess som består av ett eller flera jobbsteg. Jobbsteg anger vilket T-SQL-skript som ska köras samt annan information som krävs för att köra skriptet. |
| Målgrupp | Den uppsättning servrar, pooler och databaser som ska köras mot ett jobb. |
Elastisk jobbagent
En elastisk jobbagent är Azure-resursen för att skapa, köra och hantera jobb. Den elastiska jobbagenten är en Azure-resurs som du skapar i portalen (PowerShell och REST API stöds också).
För att skapa en elastisk jobbagent krävs en befintlig databas i Azure SQL Database. Agenten konfigurerar den befintliga Azure SQL Database som jobbdatabas.
Du kan starta, inaktivera eller avbryta ett jobb via Azure-portalen. Med Azure-portalen kan du också visa jobbdefinitioner och körningshistorik.
Kostnaden för den elastiska jobbagenten
Den elastiska jobbagenten är kostnadsfri för den aktuella förhandsversionen. Faktureringskort i Azure-portalen under förhandsversionen visar en uppskattning (i US-dollar) av kostnaden baserat på den valda samtidighetskapacitetsnivån. Detta är för närvarande endast för avancerade kostnadsuppskattningar.
Jobbdatabasen faktureras med samma hastighet som alla databaser i Azure SQL Database.
Elastisk jobbdatabas
Jobbdatabasen används för att definiera jobb och spåra status och historik för jobbkörningar. Jobb körs i måldatabaser. Jobbdatabasen används också för att lagra agentmetadata, loggar, resultat, jobbdefinitioner och innehåller även många användbara lagrade procedurer och andra databasobjekt för att skapa, köra och hantera jobb med hjälp av T-SQL.
För den aktuella förhandsversionen rekommenderas en befintlig databas i Azure SQL Database (S1 eller senare) för att skapa en elastisk jobbagent.
Jobbdatabasen ska vara en ren, tom, S1 eller högre tjänstmål i Azure SQL Database.
Det rekommenderade tjänstmålet för jobbdatabasen är S1 eller högre, men det optimala valet beror på dina jobbs prestandabehov: antalet jobbsteg, antalet jobbmål och hur ofta jobb körs.
Om åtgärderna mot jobbdatabasen är långsammare än förväntat övervakar du databasprestanda och resursanvändningen i jobbdatabasen under perioder av långsamhet med hjälp av Azure-portalen eller sys.dm_db_resource_stats DMV. Om användningen av en resurs, till exempel CPU, data-I/O eller loggskrivning närmar sig 100 % och korrelerar med perioder av långsamhet, bör du överväga att stegvis skala databasen till högre tjänstmål (antingen i DTU-modellen eller i modellen för virtuell kärna) tills jobbdatabasens prestanda förbättras tillräckligt.
Viktigt!
Ändra inte befintliga objekt eller skapa nya objekt i jobbdatabasen, men du kan läsa från tabellerna för rapportering och analys.
Elastiska jobb och jobbsteg
Ett jobb är en arbetsprocess som körs enligt ett schema eller som ett engångsjobb. Jobb består att ett eller flera jobbsteg.
Varje jobbsteg anger ett T-QSL-skript som ska köras, en eller flera målgrupper som T-SQL-skriptet ska köras mot samt de autentiseringsuppgifter som jobbagenten behöver för att ansluta till måldatabasen. Varje jobbsteg har anpassade principer för tidsgränser och försök på nytt, och kan valfritt ange utdataparametrar.
Elastiska jobbmål
Elastiska jobb ger möjlighet att köra ett eller flera T-SQL-skript parallellt, över ett stort antal databaser, enligt ett schema eller på begäran. Målet kan vara vilken nivå som helst av Azure SQL Database.
Du kan köra schemalagda jobb mot valfri kombination av databaser: en eller flera enskilda databaser, alla databaser på en server, alla databaser i en elastisk pool, med den extra flexibiliteten att inkludera eller exkludera en specifik databas. Jobb kan köras över flera servrar och flera pooler och kan även köras mot databaser i olika prenumerationer. Servrar och pooler räknas upp dynamiskt vid körning. Därför körs jobben mot alla databaser som finns i målgruppen vid tidpunkten för körningen.
Följande bild visar en jobbagent som kör flera jobb över olika typer av målgrupper:
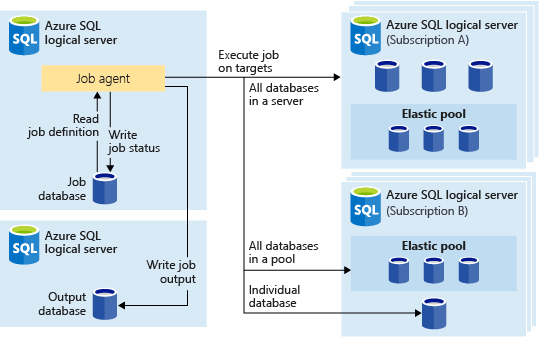
Målgrupp
En målgrupp definierar den uppsättning databaser som ett jobbsteg ska köras mot. En målgrupp kan innehålla vilket antal och vilken kombination som helst av följande:
- Logisk SQL-server – om en server anges ingår alla databaser som finns på servern vid tidpunkten för jobbkörningen i gruppen. Databasens
masterautentiseringsuppgifter måste anges så att gruppen kan räknas upp och uppdateras före jobbkörningen. Mer information om logiska servrar finns i Vad är en server i Azure SQL Database och Azure Synapse Analytics?. - Elastisk pool – om en elastisk pool anges utgör alla databaser som finns i den elastiska poolen vid tidpunkten för jobbkörningen en del av gruppen. När det gäller en server
mastermåste databasautentiseringsuppgifterna anges så att gruppen kan uppdateras före jobbkörningen. - Enskild databas – ange en eller flera enskilda databaser som ska utgöra en del av gruppen.
Dricks
Vid tidpunkten för jobbkörning omvärderar dynamisk uppräkning uppsättningen databaser i de målgrupper som inkluderar servrar eller pooler. Dynamisk uppräkning ser till att jobb körs över alla databaser som finns i servern eller poolen vid tidpunkten för jobbkörningen. Omvärdering av lista över databaser vid körning är särskilt användbart för scenarier där pool- eller servermedlemskap ändras ofta.
Pooler och enskilda databaser kan anges som inkluderade eller exkluderade från gruppen. På så sätt går det att skapa en målgrupp med valfri kombination av databaser. Till exempel kan du lägga till en server till en målgrupp men exkludera specifika databaser i den elastiska poolen (eller exkludera en hel elastisk pool).
En målgrupp kan inkludera databaser i flera prenumerationer och över flera regioner. Körningar mellan regioner har högre svarstid än körningar inom samma region.
Följande exempel visar hur olika målgruppsdefinitioner räknas upp dynamiskt när ett jobb körs för att fastställa vilka databaser jobbet ska köra:
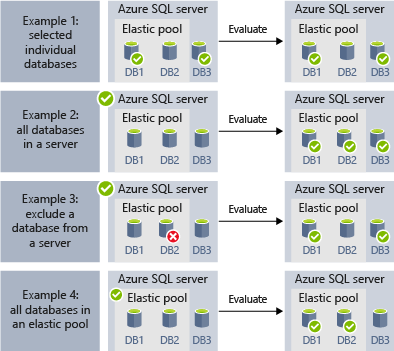
- Exempel 1 illustrerar en målgrupp som består av en lista med enskilda databaser. När ett jobbsteg körs med den här målgruppen körs åtgärden i jobbsteget i var och en av dessa databaser.
- Exempel 2 visar en målgrupp som innehåller en server som mål. När ett jobbsteg körs med den här målgruppen räknas servern upp dynamiskt för att fastställa vilken listan med databaser som för närvarande finns på servern. Åtgärden i jobbsteget körs i var och en av dessa databaser.
- Exempel 3 illustrerar en målgrupp liknande den i exempel 2, men en databas undantas uttryckligen. Åtgärden i jobbsteget körs inte i den undantagna databasen.
- Exempel 4 illustrerar en målgrupp som innehåller en elastisk pool som mål. Precis som i exempel 2 räknas poolen upp dynamiskt när jobbet körs för att fastställa listan med databaser i poolen.
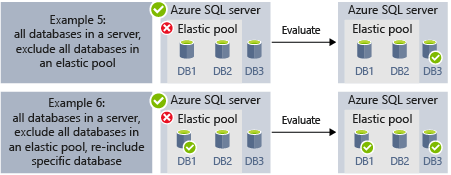
- Exempel 5 och Exempel 6 visar avancerade scenarier där servrar, elastiska pooler och databaser kan kombineras med hjälp av inkludera och exkludera regler.
Kommentar
Själva jobbdatabasen kan vara målet för ett jobb. I det här scenariot behandlas jobbdatabasen precis som andra måldatabaser. Jobbanvändaren måste skapas och beviljas tillräckliga behörigheter i jobbdatabasen, och den databasomfattande autentiseringsuppgiften för jobbanvändaren måste också finnas i jobbdatabasen, precis som för alla andra måldatabaser.
Autentisering
Välj en metod för alla mål för en elastisk jobbagent. För en enda elastisk jobbagent kan du till exempel inte konfigurera en målserver för att använda databasomfattande autentiseringsuppgifter och en annan för att använda Microsoft Entra-ID-autentisering.
Den elastiska jobbagenten kan ansluta till de servrar/databaser som anges av målgruppen via två autentiseringsalternativ:
- Använd Microsoft Entra-autentisering (tidigare Azure Active Directory) med en användartilldelad hanterad identitet (UMI).
- Använd databasomfångsbegränsade autentiseringsuppgifter. (Tidigare var detta den enda autentiseringsmetoden.)
Namnet på Azure Active Directory har ändrats till Microsoft Entra-ID från och med 2023.
Autentisering via användartilldelad hanterad identitet (UMI)
Microsoft Entra-autentisering (tidigare Azure Active Directory) via användartilldelad hanterad identitet (UMI) är det rekommenderade alternativet för att ansluta elastiska jobb till Azure SQL Database. Med stöd för Microsoft Entra-ID kan jobbagenten ansluta till måldatabaser (databaser, servrar, elastiska pooler) och utdatadatabaser med hjälp av UMI.

Du kan också aktivera Microsoft Entra-ID-autentisering på den logiska servern som innehåller den elastiska jobbdatabasen för att komma åt/fråga databasen via Microsoft Entra ID-anslutningar. Jobbagenten använder dock intern certifikatbaserad autentisering för att ansluta till sin jobbdatabas.
Du kan skapa en UMI eller använda en befintlig UMI och tilldela samma UMI till flera jobbagenter. Endast en UMI stöds per jobbagent. När en UMI har tilldelats till en jobbagent använder den jobbagenten endast den här identiteten för att ansluta och köra t-SQL-jobb i måldatabaserna. SQL-autentisering används inte mot målservern/databaserna för den jobbagenten.
UMI-namnet måste börja med en bokstav eller ett tal och med en längd mellan 3 och 128. Den kan innehålla - tecknen och _ .
Mer information om UMI i Azure SQL Database finns i Hanterade identiteter för Azure SQL, inklusive de steg som krävs och fördelarna med att använda en UMI som den logiska Azure SQL Database-serveridentiteten. Mer information finns i Använda Microsoft Entra (tidigare Azure Active Directory) för att autentisera till Azure SQL-plattformar.
Viktigt!
När du använder Microsoft Entra-ID-autentisering skapar du din jobuser användare från det Microsoft Entra-ID:t i varje måldatabas. Ge användaren de behörigheter som krävs för att köra dina jobb i varje måldatabas.
Det går inte att använda en systemtilldelad hanterad identitet (SMI).
Autentisering via databasomfattande autentiseringsuppgifter
Microsoft Entra-autentisering (tidigare Azure Active Directory) är det rekommenderade alternativet, men jobb kan konfigureras för att använda databasomfattande autentiseringsuppgifter för att ansluta till de databaser som anges av målgruppen vid körning. Före oktober 2023 var databasomfattande autentiseringsuppgifter det enda autentiseringsalternativet.
Om en målgrupp innehåller servrar eller pooler används dessa databasomfattande autentiseringsuppgifter för att ansluta till master databasen för att räkna upp tillgängliga databaser.
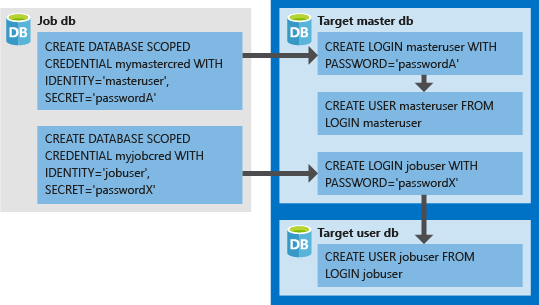
- Autentiseringsuppgifterna med databasomfattning måste skapas i jobbdatabasen.
- Alla måldatabaser måste ha en inloggning med tillräcklig behörighet för att jobbet ska slutföras (
jobuseri följande diagram). - Autentiseringsuppgifter som skapas i måldatabaser ( och för och
jobuser, i följande diagram) ska matchaIDENTITYochSECRETi de autentiseringsuppgifter som skapas i jobbdatabasenmasteruser.PASSWORDLOGIN - Autentiseringsuppgifter kan återanvändas mellan jobb och lösenorden för autentiseringsuppgifter krypteras och skyddas från användare som har skrivskyddad åtkomst till jobbobjekt.
Följande bild är utformad för att hjälpa dig att förstå hur du konfigurerar rätt jobbautentiseringsuppgifter och hur den elastiska jobbagenten ansluter med databasautentiseringsuppgifter som autentisering till inloggningar/användare i målservrar/databaser.
Kommentar
När du använder databasomfångsbegränsade autentiseringsuppgifter bör du komma ihåg att skapa användaren jobuser i varje måldatabas.
Privata slutpunkter för elastiskt jobb
Den elastiska jobbagenten stöder privata slutpunkter för elastiska jobb. När du skapar en privat slutpunkt för elastiska jobb upprättas en privat länk mellan det elastiska jobbet och målservern. Funktionen för privata slutpunkter för elastiska jobb skiljer sig från Azure Private Link.

Funktionen privata slutpunkter för elastiska jobb stöder privata anslutningar till mål-/utdataservrar, så att jobbagenten fortfarande kan nå dem även när alternativet Neka offentlig åtkomst är aktiverat. Att använda privata slutpunkter är också en möjlig lösning om du vill inaktivera alternativet "Tillåt Azure-tjänster och resurser att komma åt servern".
Privata slutpunkter för elastiska jobb stöder alla alternativ för autentisering med elastisk jobbagent.
Med funktionen för privat slutpunkt för elastiska jobb kan du välja en tjänsthanterad privat slutpunkt för att upprätta en säker anslutning mellan jobbagenten och dess mål-/utdataservrar. En tjänsthanterad privat slutpunkt är en privat IP-adress i ett specifikt virtuellt nätverk och undernät. När du väljer att använda privata slutpunkter på en av jobbagentens mål-/utdataservrar skapas en tjänsthanterad privat slutpunkt av Microsoft. Den här privata slutpunkten används sedan uteslutande av jobbagenten för att ansluta och köra jobb, eller för att skriva jobbutdata på mål-/utdatadatabaserna.
Privata slutpunkter för elastiska jobb kan skapas och tillåtas via Azure-portalen. Målservrar som är anslutna via den privata länken kan finnas var som helst i Azure, även i olika geografiska områden och prenumerationer. Du måste skapa en privat slutpunkt för varje önskad målserver och jobbutdataservern för att aktivera den här kommunikationen.
En självstudiekurs om hur du konfigurerar en ny tjänsthanterad privat slutpunkt för elastiska jobb finns i Konfigurera privata slutpunkter för elastiska Azure SQL-jobb.
Krav för privata slutpunkter för elastiska jobb
- Om du vill använda en privat slutpunkt för elastiska jobb måste både jobbagenten och målservrarna/databaserna finnas i Azure (samma eller olika regioner) och i samma molntyp (till exempel både i det offentliga molnet eller i båda i myndighetsmolnet).
Microsoft.Networkresursprovidern måste registreras för värdprenumerationerna för både jobbagenten och mål-/utdataservrarna.- Privata slutpunkter för elastiska jobb skapas per mål-/utdataserver. De måste godkännas innan den elastiska jobbagenten kan använda dem. Detta kan göras via fönstret Nätverk på den logiska servern eller din föredragna klient. Den elastiska jobbagenten kommer sedan att kunna nå alla databaser under den servern med hjälp av privat anslutning.
- Anslutningen från den elastiska jobbagenten till jobbdatabasen använder inte privat slutpunkt. Själva jobbagenten använder intern certifikatbaserad autentisering för att ansluta till jobbdatabasen. En varning är om du lägger till jobbdatabasen som en målgruppsmedlem. Sedan fungerar det som ett vanligt mål som du skulle behöva konfigurera med privat slutpunkt efter behov.
Behörigheter för elastisk jobbdatabas
När jobbagenten skapas skapas ett schema, tabeller och en roll som kallas jobs_reader i jobbdatabasen. Rollen skapas med följande behörighet och är utformad för att ge administratörer bättre åtkomstkontroll för jobbövervakning. Administratörer kan ge användarna möjlighet att övervaka jobbkörning genom att lägga till dem i jobs_reader roll i jobbdatabasen.
| Rollnamn | 'jobs'-schemabehörigheter | 'jobs_internal'-schemabehörigheter |
|---|---|---|
| jobs_reader | SELECT | Ingen |
Varning
Du bör inte uppdatera interna katalogvyer i jobbdatabasen, till exempel jobs.target_group_members. Om du ändrar katalogvyerna manuellt kan jobbdatabasen skadas och orsaka fel. Dessa vyer är endast skrivskyddade för frågor. Du kan använda de lagrade procedurerna i jobbdatabasen för att lägga till/ta bort målgrupper/medlemmar, till exempel jobs.sp_add_target_group_member.
Viktigt!
Överväg säkerhetskonsekvenserna innan du beviljar förhöjd åtkomst till jobbdatabasen. En obehörig användare med behörighet att skapa eller redigera jobb kan skapa eller redigera ett jobb som använder en lagrad autentiseringsuppgift för att ansluta till en databas under den skadliga användarens kontroll, vilket kan göra det möjligt för den skadliga användaren att fastställa lösenordet för autentiseringsuppgifterna eller köra skadliga kommandon.
Övervaka elastiska jobb
Från och med oktober 2023 har den elastiska jobbagenten integrering med Azure-aviseringar för jobbstatusmeddelanden, vilket förenklar lösningen för övervakning av status och historik för jobbkörning.
Azure-portalen har också nya, ytterligare funktioner för att stödja elastiska jobb och jobbövervakning. Du kan skapa Azure Monitor-aviseringsregler med Azure-portalen, Azure CLI, PowerShell och REST API. Måttet Misslyckade elastiska jobb är en bra utgångspunkt för att övervaka och ta emot aviseringar om elastisk jobbkörning. Dessutom kan du välja att få aviseringar via en konfigurerbar åtgärd som SMS eller e-post av Azure Alert-anläggningen. Mer information finns i Skapa aviseringar för Azure SQL Database i Azure-portalen.
Ett exempel finns i Skapa, konfigurera och hantera elastiska jobb (förhandsversion).
Jobbutdata
Resultatet av stegen i ett jobb på varje måldatabas registreras i detalj, och skriptutdata kan samlas in i en specifik tabell. Du kan ange en databas för att spara alla data som returneras från ett jobb.
Jobbhistorik
Visa historik för elastisk jobbkörning i jobbdatabasen genom att fråga tabellen jobs.job_executions. Ett systemrensningsjobb rensar körningshistorik som är äldre än 45 dagar. Om du vill ta bort historik som är mindre än 45 dagar gammal manuellt kör du den sp_purge_jobhistory lagrade proceduren i jobbdatabasen.
Jobbstatus
Du kan övervaka elastiska jobbkörningar i jobbdatabasen genom att fråga tabellen jobs.job_executions.
Bästa praxis
Tänk på följande metodtips när du arbetar med elastiska databasjobb.
Metodtips för säkerhet
- Begränsa användningen av API:er till betrodda personer.
- Autentiseringsuppgifter ska ha minsta möjliga behörigheter som krävs för att utföra jobbsteget. Mer information finns i Auktorisering och behörigheter.
- När du använder en server- och/eller poolmålgruppmedlem rekommenderar vi starkt att du skapar en separat autentiseringsuppgift med behörighet
masterför databasen för att visa/lista databaser som används för att expandera databaslistorna över servrarna och/eller poolerna före jobbkörningen.
Prestanda för elastiskt jobb
Elastiska jobb använder minimala beräkningsresurser i väntan på att långvariga jobb ska slutföras.
Beroende på storleken på målgruppen för databaser och önskad körningstid för ett jobb (antal samtidiga arbetare) kräver agenten olika mängder beräkning och prestanda för jobbdatabasen (ju fler mål och ju högre antal jobb, desto högre beräkningsmängd krävs).
Samtidiga kapacitetsnivåer
Från och med oktober 2023 har den elastiska jobbagenten flera prestandanivåer för att öka kapaciteten.
Kapacitetsökningar anger det totala antalet samtidiga måldatabaser som jobbagenten kan ansluta till och starta ett jobb. Om du vill ha fler samtidiga målanslutningar för jobbkörning uppgraderar du en jobbagentnivå från ja100-standardnivån, som har en gräns på 100 samtidiga målanslutningar.
De flesta miljöer kräver färre än 100 samtidiga jobb när som helst, så JA100 är standard.
| Elastisk jobbagentnivå | Maximalt antal samtidiga jobb |
|---|---|
| JA100 | 100 |
| JA200 | 200 |
| JA400 | 400 |
| JA800 | 800 |
Om du överskrider jobbagentens samtidighetskapacitetsnivå med jobbmål skapas köfördröjningar för vissa måldatabaser/servrar. Om du till exempel startar ett jobb med 110 mål på JA100-nivån väntar 10 jobb med att starta tills andra är klara.
Nivå- eller tjänstmålet för en elastisk jobbagent kan ändras via Azure-portalen, PowerShell eller REST-API:et för jobbagenter. Ett exempel finns i Skala jobbagenten.
Begränsa jobbpåverkan på elastiska pooler
För att säkerställa att resurser inte överbelastas när jobb körs mot databaser i en elastisk Azure SQL Database-pool kan jobb konfigureras för att begränsa antalet databaser som ett jobb kan köras mot samtidigt.
Ange antalet samtidiga databaser som ett jobb körs på genom att ange parametern för den sp_add_jobstep lagrade proceduren @max_parallelism i T-SQL.
Idempotent-skript
Ett elastiskt jobbs T-SQL-skript måste vara idempotent. Idempotent innebär att om skriptet lyckas, och det körs igen, inträffar samma resultat. Ett skript kan misslyckas på grund av tillfälliga nätverksproblem. I så fall försöker jobbet automatiskt köra skriptet på nytt ett förinställt antal gånger innan det ger upp. Ett idempotent-skript har samma resultat även om det har körts två gånger (eller mer).
En enkel metod är att testa om ett objekt finns innan det skapas. Följande är ett hypotetiskt exempel:
IF NOT EXISTS (SELECT * FROM sys.objects WHERE [name] = N'some_object')
print 'Object does not exist'
-- Create the object
ELSE
print 'Object exists'
-- If it exists, drop the object before recreating it.
På liknande sätt måste ett skript kunna lyckas köra genom att logiskt testa och motverka eventuella tillstånd som det hittar.
Begränsningar
Det här är de aktuella begränsningarna för tjänsten elastiska jobb. Vi arbetar aktivt med att ta bort så många av dessa begränsningar som möjligt.
| Problem | beskrivning |
|---|---|
| Den elastiska jobbagenten måste återskapas och startas i den nya regionen efter en redundansväxling/flytt till en ny Azure-region. | Tjänsten elastiska jobb lagrar alla jobbagenter och jobbmetadata i jobbdatabasen. Vid redundansväxling eller flytt av Azure-resurser till en ny Azure-region flyttas även jobbdatabasen, jobbagenten och jobbmetadata till den nya Azure-regionen. Den elastiska jobbagenten är dock bara en beräkningsresurs och måste uttryckligen återskapas och startas i den nya regionen innan jobben börjar köras igen i den nya regionen. När den elastiska jobbagenten har startats återupptas körningen av jobb i den nya regionen enligt det tidigare definierade jobbschemat. |
| Överdrivna granskningsloggar från jobbdatabasen | Den elastiska jobbagenten arbetar genom att ständigt söka efter nya jobb och andra CRUD-åtgärder i jobbdatabasen. Om granskning är aktiverat på servern som rymmer en jobbdatabas kan ett stort antal granskningsloggar genereras av jobbdatabasen. Detta kan minimeras genom att filtrera bort dessa granskningsloggar med hjälp av Set-AzSqlServerAudit kommandot med ett predikatuttryck.Till exempel: Set-AzSqlServerAudit -ResourceGroupName "ResourceGroup01" -ServerName "Server01" -BlobStorageTargetState Enabled -StorageAccountResourceId "/subscriptions/7fe3301d-31d3-4668-af5e-211a890ba6e3/resourceGroups/resourcegroup01/providers/Microsoft.Storage/storageAccounts/mystorage" -PredicateExpression "database_principal_name <> '##MS_JobAccount##'"Det här kommandot filtrerar bara bort jobbagenten till jobbdatabasens granskningsloggar, inte jobbagenten till måldatabasens granskningsloggar. |
| Användning av en Hyperskala-databas som jobbdatabas | Det går inte att använda en Hyperskala-databas som en jobbdatabas . Elastiska jobb kan dock rikta in sig på Hyperskala-databaser på samma sätt som andra databaser i Azure SQL Database. |
| Serverlösa databaser och automatisk pausning med elastiska jobb. | Automatisk pausning av aktiverad serverlös databas stöds inte som en jobbdatabas. Serverlösa databaser som omfattas av elastiska jobb stöder automatisk pausning och återupptas av jobbanslutningar. |
| Exportera en jobbdatabas till en BACPAC-fil | Export av en jobbdatabas till en BACPAC-fil stöds inte. Om SQL Server som innehåller en jobbdatabas måste exporteras bör jobbdatabasen tas bort först innan servern exporteras. |
Relaterat innehåll
- Skapa, konfigurera och hantera elastiska jobb (förhandsversion)
- Automatisera hanteringsuppgifter i Azure SQL
- Skapa och hantera elastiska jobb med hjälp av PowerShell (förhandsversion)
- Skapa och hantera elastiska jobb med hjälp av T-SQL (förhandsversion)