Identifierbara typer av flaskhalsar för frågeprestanda i Azure SQL Database
Gäller för:![]() Azure SQL Database
Azure SQL Database
När du försöker åtgärda en flaskhals för frågeprestanda börjar du med att avgöra om flaskhalsen uppstår när frågan körs eller väntar. Det avgör vilken lösning du ska använda. Använd följande diagram för att förstå de faktorer som kan orsaka antingen ett körningsrelaterat problem eller ett vänterelaterat problem. Problem och lösningar som rör varje typ av problem beskrivs i den här artikeln.
Du kan använda Intelligent Insights eller SQL Server DMV:er för att identifiera dessa typer av prestandaflaskhalsar.
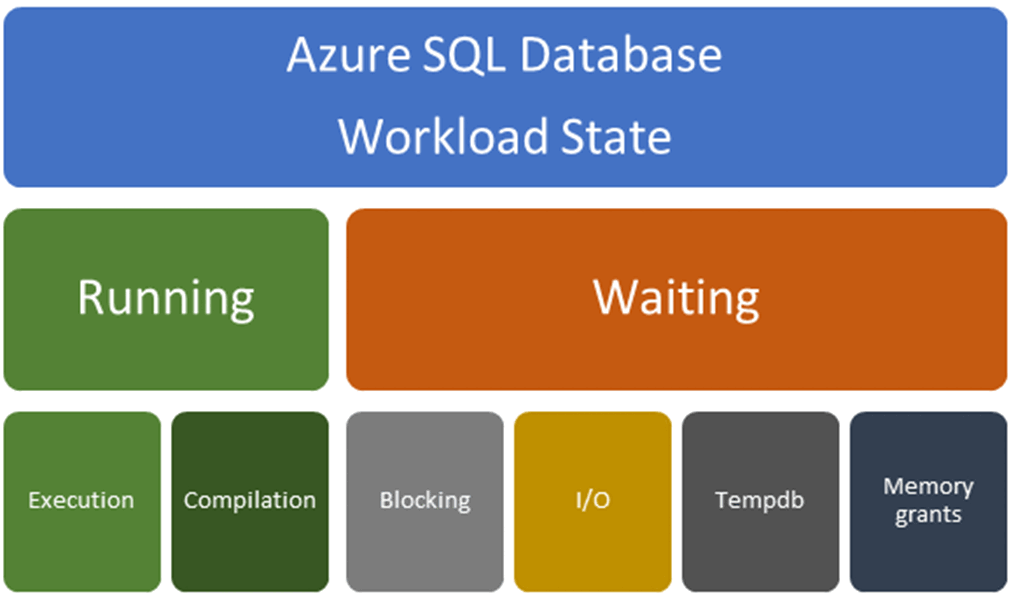
Körningsrelaterade problem: Körningsrelaterade problem är vanligtvis relaterade till kompileringsproblem som resulterar i en underoptimal frågeplan eller körningsproblem som är relaterade till otillräckliga eller överanvända resurser. Vänterelaterade problem: Vänterelaterade problem är vanligtvis relaterade till:
- Lås (blockering)
- I/O
- Konkurrens relaterad till
tempdbanvändning - Väntande minnesbidrag
Den här artikeln handlar om Azure SQL Database, se även Identifiera möjliga typer av flaskhalsar för frågeprestanda i Azure SQL Managed Instance.
Kompileringsproblem som resulterar i en suboptimal frågeplan
En suboptimal plan som genereras av SQL Query Optimizer kan vara orsaken till långsamma frågeprestanda. SQL Query Optimizer kan skapa en suboptimal plan på grund av ett index som saknas, inaktuell statistik, en felaktig uppskattning av antalet rader som ska bearbetas eller en felaktig uppskattning av det minne som krävs. Om du vet att frågan kördes snabbare tidigare eller i en annan databas jämför du de faktiska körningsplanerna för att se om de är annorlunda.
Identifiera eventuella saknade index med någon av följande metoder:
- Använd Intelligent Insights.
- Granska rekommendationerna i Database Advisor för enkla databaser och pooldatabaser i Azure SQL Database. Du kan också välja att aktivera automatiska justeringsalternativ för justering av index för Azure SQL Database.
- Index saknas i DMV:er och frågekörningsplaner. Den här artikeln visar hur du identifierar och finjusterar icke-illustrerade index med hjälp av saknade indexbegäranden.
Försök att uppdatera statistik eller återskapa index för att få en bättre plan. Aktivera automatisk plankorrigering för att automatiskt åtgärda dessa problem.
Som ett avancerat felsökningssteg använder du Query Store-tips för att tillämpa frågetips med hjälp av Query Store, utan att göra kodändringar.
Det här exemplet på frågejustering och tips visar effekten av en suboptimal frågeplan på grund av en parametriserad fråga, hur du identifierar det här villkoret och hur du använder ett frågetips för att lösa problemet.
Prova att ändra databasens kompatibilitetsnivå och implementera intelligent frågebearbetning. SQL Query Optimizer kan generera en annan frågeplan beroende på databasens kompatibilitetsnivå. Högre kompatibilitetsnivåer ger mer intelligenta frågebearbetningsfunktioner.
- Mer information om frågebearbetning finns i Arkitekturguide för frågebearbetning.
- Information om hur du ändrar databaskompatibilitetsnivåer och läs mer om skillnaderna mellan kompatibilitetsnivåer finns i ALTER DATABASE.
- Mer information om kardinalitetsuppskattning finns i Kardinalitetsuppskattning
Åtgärda frågor med suboptimala frågekörningsplaner
I följande avsnitt beskrivs hur du löser frågor med en suboptimal frågekörningsplan.
Frågor som har problem med parameterkänslig plan (PSP)
Ett problem med parameterkänslig plan (PSP) inträffar när frågeoptimeraren genererar en frågekörningsplan som endast är optimal för ett specifikt parametervärde (eller en uppsättning värden) och den cachelagrade planen inte är optimal för parametervärden som används i efterföljande körningar. Planer som inte är optimala kan sedan orsaka problem med frågeprestanda och försämra det totala arbetsbelastningsdataflödet.
Mer information om parametersniffning och frågebearbetning finns i arkitekturguiden för frågebearbetning.
Flera lösningar kan minimera PSP-problem. Varje lösning har tillhörande kompromisser och nackdelar:
- En ny funktion som introduceras med SQL Server 2022 (16.x) är optimering av parameterkänslig plan, som försöker minimera de flesta suboptimala frågeplaner som orsakas av parameterkänslighet. Detta aktiveras med databaskompatibilitetsnivå 160 i Azure SQL Database.
- Använd frågetipset RECOMPILE vid varje frågekörning. Den här lösningen handlar om kompileringstid och ökad CPU för bättre plankvalitet. Alternativet
RECOMPILEär ofta inte möjligt för arbetsbelastningar som kräver ett högt dataflöde. - Använd frågetipset OPTION (OPTIMIZE FOR...) för att åsidosätta det faktiska parametervärdet med ett typiskt parametervärde som skapar en plan som är tillräckligt bra för de flesta parametervärdemöjligheter. Det här alternativet kräver en god förståelse av optimala parametervärden och tillhörande planegenskaper.
- Använd frågetipset OPTION (OPTIMIZE FOR UNKNOWN) för att åsidosätta det faktiska parametervärdet och i stället använda densitetsvektorgenomsnittet. Du kan också göra detta genom att samla in inkommande parametervärden i lokala variabler och sedan använda de lokala variablerna i predikaten i stället för att använda själva parametrarna. För den här korrigeringen måste den genomsnittliga densiteten vara tillräckligt bra.
- Inaktivera parametersniffning helt med hjälp av DISABLE_PARAMETER_SNIFFING frågetips.
- Använd frågetipset KEEPFIXEDPLAN för att förhindra omkompileringar i cacheminnet. Den här lösningen förutsätter att den tillräckligt bra gemensamma planen redan är den i cacheminnet. Du kan också inaktivera automatiska statistikuppdateringar för att minska risken för att den goda planen tas bort och en ny felaktig plan kompileras.
- Tvinga planen genom att uttryckligen använda frågetipset USE PLAN genom att skriva om frågan och lägga till tipset i frågetexten. Eller ange en specifik plan med hjälp av Query Store eller genom att aktivera automatisk justering.
- Ersätt den enskilda proceduren med en kapslad uppsättning procedurer som var och en kan användas baserat på villkorslogik och associerade parametervärden.
- Skapa alternativ för dynamisk strängkörning till en statisk procedurdefinition.
Om du vill använda frågetips ändrar du frågan eller använder Query Store-tips för att tillämpa tipset utan att göra kodändringar.
Mer information om hur du löser PSP-problem finns i följande blogginlägg:
- Jag känner lukten av en parameter
- Conor jämfört med dynamiska SQL jämfört med procedurer jämfört med plankvalitet för parametriserade frågor
Kompileringsaktivitet som orsakas av felaktig parameterisering
När en fråga har literaler parameteriserar antingen databasmotorn instruktionen automatiskt eller så parameteriserar en användare uttryckligen instruktionen för att minska antalet kompileringar. Om det finns ett stort antal kompileringar för en fråga med samma mönster men olika literalvärden, kan det resultera i hög CPU-användning. Om du bara delvis parametriserar en fråga som fortsätter att innehålla literaler, parameteriserar inte databasmotorn frågan ytterligare.
Här är ett exempel på en delvis parametriserad fråga:
SELECT *
FROM t1 JOIN t2 ON t1.c1 = t2.c1
WHERE t1.c1 = @p1 AND t2.c2 = '961C3970-0E54-4E8E-82B6-5545BE897F8F';
I det här exemplet t1.c1 tar @p1, men t2.c2 fortsätter att ta GUID som literal. Om du i det här fallet ändrar värdet för c2behandlas frågan som en annan fråga och en ny kompilering sker. Om du vill minska kompileringarna i det här exemplet skulle du även parametrisera GUID:t.
Följande fråga visar antalet frågor per frågehash för att avgöra om en fråga är korrekt parametriserad:
SELECT TOP 10
q.query_hash
, count (distinct p.query_id ) AS number_of_distinct_query_ids
, min(qt.query_sql_text) AS sampled_query_text
FROM sys.query_store_query_text AS qt
JOIN sys.query_store_query AS q
ON qt.query_text_id = q.query_text_id
JOIN sys.query_store_plan AS p
ON q.query_id = p.query_id
JOIN sys.query_store_runtime_stats AS rs
ON rs.plan_id = p.plan_id
JOIN sys.query_store_runtime_stats_interval AS rsi
ON rsi.runtime_stats_interval_id = rs.runtime_stats_interval_id
WHERE
rsi.start_time >= DATEADD(hour, -2, GETUTCDATE())
AND query_parameterization_type_desc IN ('User', 'None')
GROUP BY q.query_hash
ORDER BY count (distinct p.query_id) DESC;
Faktorer som påverkar ändringar i frågeplanen
En omkompilering av en frågekörningsplan kan resultera i en genererad frågeplan som skiljer sig från den ursprungliga cachelagrade planen. En befintlig ursprunglig plan kan omkompileras automatiskt av olika skäl:
- Ändringar i schemat refereras av frågan
- Dataändringar i tabellerna refereras av frågan
- Alternativ för frågekontext har ändrats
En kompilerad plan kan matas ut från cachen av olika skäl, till exempel:
- Instansen startas om
- Ändringar i databasomfattningskonfiguration
- Minnesbelastning
- Explicita begäranden om att rensa cacheminnet
Om du använder ett RECOMPILE-tips cachelagras ingen plan.
En omkompilering (eller ny kompilering efter cacheavhysning) kan fortfarande resultera i genereringen av en frågekörningsplan som är identisk med originalet. När planen ändras från den tidigare eller ursprungliga planen är dessa förklaringar sannolikt:
Ändrad fysisk design: Till exempel täcker nyligen skapade index mer effektivt kraven för en fråga. De nya indexen kan användas på en ny kompilering om frågeoptimeraren beslutar att det är mer optimalt att använda det nya indexet än att använda datastrukturen som ursprungligen valdes för den första versionen av frågekörningen. Eventuella fysiska ändringar av de refererade objekten kan resultera i ett nytt planval vid kompileringstillfället.
Skillnader mellan serverresurser: När en plan i ett system skiljer sig från planen i ett annat system kan resurstillgänglighet, till exempel antalet tillgängliga processorer, påverka vilken plan som genereras. Om ett system till exempel har fler processorer kan en parallell plan väljas. Mer information om parallellitet i Azure SQL Database finns i Konfigurera maxgraden av parallellitet (MAXDOP) i Azure SQL Database.
Annan statistik: Den statistik som är associerad med de refererade objekten kan ha ändrats eller skilja sig väsentligt från det ursprungliga systemets statistik. Om statistiken ändras och en omkompilering sker använder frågeoptimeraren statistiken från och med när de ändrades. Den reviderade statistikens datadistributioner och frekvenser kan skilja sig från den ursprungliga kompileringsstatistikens. Dessa ändringar används för att skapa kardinalitetsuppskattningar. (Kardinalitetsuppskattningar är antalet rader som förväntas flöda genom det logiska frågeträdet.) Ändringar i kardinalitetsuppskattningar kan leda till att du väljer olika fysiska operatorer och associerade operationsordningar. Även mindre ändringar i statistik kan resultera i en ändrad frågekörningsplan.
Ändrad databaskompatibilitetsnivå eller kardinalitetsuppskattningsversion: Ändringar på databaskompatibilitetsnivån kan aktivera nya strategier och funktioner som kan resultera i en annan frågekörningsplan. Utöver databaskompatibilitetsnivån kan en inaktiverad eller aktiverad spårningsflagga 4199 eller ett ändrat tillstånd för den databasomfattande konfigurationen QUERY_OPTIMIZER_HOTFIXES också påverka val av frågekörningsplan vid kompileringstillfället. Spårningsflaggor 9481 (force legacy CE) och 2312 (force default CE) påverkar också planen.
Problem med resursbegränsningar
Långsamma frågeprestanda som inte är relaterade till suboptimala frågeplaner och saknade index är vanligtvis relaterade till otillräckliga eller överanvända resurser. Om frågeplanen är optimal kan frågan (och databasen) nå resursgränserna för databasen eller den elastiska poolen. Ett exempel kan vara överskjutande loggskrivningsdataflöde för tjänstnivån.
Identifiera resursproblem med hjälp av Azure-portalen: Information om resursbegränsningar är problemet finns i RESURSövervakning i SQL Database. Information om enskilda databaser och elastiska pooler finns i Prestandarekommendationer för Database Advisor och Query Performance Insights.
Identifiera resursgränser med hjälp av Intelligent Insights
Identifiera resursproblem med DMV :er:
- Den sys.dm_db_resource_stats DMV returnerar cpu-, I/O- och minnesförbrukning för databasen. Det finns en rad för varje intervall på 15 sekunder, även om det inte finns någon aktivitet i databasen. Historiska data bevaras i en timme.
- sys.resource_stats DMV returnerar CPU-användning och lagringsdata för Azure SQL Database. Data samlas in och aggregeras i femminutersintervall.
- Många enskilda frågor som kumulativt förbrukar hög CPU
Om du identifierar problemet som otillräcklig resurs kan du uppgradera resurser för att öka databasens kapacitet för att absorbera cpu-kraven. Mer information finns i Skala resurser för en enskild databas i Azure SQL Database och Skala elastiska poolresurser i Azure SQL Database.
Prestandaproblem som orsakas av ökad arbetsbelastning
En ökning av programtrafik och arbetsbelastningsvolym kan orsaka ökad CPU-användning. Men du måste vara noga med att korrekt diagnostisera det här problemet. När du ser ett problem med hög CPU svarar du på dessa frågor för att avgöra om ökningen orsakas av ändringar i arbetsbelastningsvolymen:
Är frågorna från programmet orsaken till problemet med hög CPU?
För de vanligaste CPU-förbrukningsfrågorna som du kan identifiera:
- Var flera körningsplaner associerade med samma fråga? I så fall, varför?
- Var körningstiderna konsekventa för frågor med samma körningsplan? Ökade antalet körningar? I så fall orsakar arbetsbelastningsökningen troligen prestandaproblem.
Sammanfattningsvis är prestandaproblemet sannolikt relaterat till en ökning av arbetsbelastningen om frågekörningsplanen inte har körts på ett annat sätt men cpu-användningen ökade tillsammans med körningsantalet.
Det är inte alltid lätt att identifiera en arbetsbelastningsvolymändring som driver ett CPU-problem. Tänk på följande faktorer:
Ändrad resursanvändning: Tänk dig till exempel ett scenario där CPU-användningen ökade till 80 procent under en längre tidsperiod. Enbart cpu-användning innebär inte att arbetsbelastningsvolymen har ändrats. Regressioner i frågekörningsplanen och ändringar i datadistributionen kan också bidra till mer resursanvändning även om programmet kör samma arbetsbelastning.
Utseendet på en ny fråga: Ett program kan köra en ny uppsättning frågor vid olika tidpunkter.
En ökning eller minskning av antalet begäranden: Det här scenariot är det mest uppenbara måttet på en arbetsbelastning. Antalet frågor motsvarar inte alltid mer resursanvändning. Det här måttet är dock fortfarande en viktig signal, förutsatt att andra faktorer är oförändrade.
Använd Intelligent Insights för att identifiera ökningar av arbetsbelastningar och planera regressioner.
- Parallellitet: Överdriven parallellitet kan försämra andra samtidiga arbetsbelastningsprestanda genom att svälta andra frågor om processor- och arbetstrådsresurser. Mer information om parallellitet i Azure SQL Database finns i Konfigurera maxgraden av parallellitet (MAXDOP) i Azure SQL Database.
Vänterelaterade problem
När du har eliminerat en suboptimal plan och vänterelaterade problem som är relaterade till körningsproblem är prestandaproblemet vanligtvis att frågorna förmodligen väntar på någon resurs. Problem relaterade till väntetider kan orsakas av följande:
Blockering:
Det är möjligt att en fråga upprätthåller ett lås på objekt i databasen medan andra försöker komma åt samma objekt. Du kan identifiera blockeringsfrågor med hjälp av DMV:er eller Intelligent Insights. Mer information finns i Förstå och lösa blockeringsproblem i Azure SQL Database.
I/O-problem
Frågor kanske väntar på att sidorna ska skrivas till data- eller loggfilerna. I det här fallet kontrollerar du väntestatistiken för
INSTANCE_LOG_RATE_GOVERNOR,WRITE_LOGellerPAGEIOLATCH_*i DMV:en. Läs mer om att identifiera problem med I/O-prestanda med hjälp av DMV:er.Tempdb-problem
Om arbetsbelastningen använder temporära tabeller eller om det finns
tempdb-tömningar i planerna kan frågorna ha problem medtempdb-dataflödet. Om du vill undersöka vidare hittar du mer information i Identifiera tempdb-problem.Minnesrelaterade problem
Om arbetsbelastningen inte har tillräckligt med minne kan den förväntade sidlivslängden minska eller så kan frågorna få mindre minne än de behöver. I vissa fall kan inbyggd intelligens i Frågeoptimeraren åtgärda minnesrelaterade problem. Läs mer om att identifiera problem med minnestilldelning med hjälp av DMV:er. Mer information och exempelfrågor finns i Felsöka minnesfel med Azure SQL Database. Om det uppstår minnesfel kan du läsa sys.dm_os_out_of_memory_events.
Metoder för att visa de vanligaste väntekategorierna
Dessa metoder används ofta för att visa de vanligaste kategorierna av väntetyper:
- Använd Intelligent Insights för att identifiera frågor med prestandaförsämring på grund av ökade väntetider
- Använd Query Store för att hitta väntestatistik för varje fråga över tid. I Query Store kombineras väntetyper i väntekategorier. Du hittar mappningen av väntekategorier för väntetyper i sys.query_store_wait_stats.
- Använd sys.dm_db_wait_stats för att returnera information om alla väntetider som påträffas av trådar som kördes under en frågeåtgärd. Du kan använda den här aggregerade vyn för att diagnostisera prestandaproblem med Azure SQL Database och även med specifika frågor och batchar. Frågor kan vänta på resurser, kövänte eller externa väntetider.
- Använd sys.dm_os_waiting_tasks för att returnera information om kön med uppgifter som väntar på en viss resurs.
I scenarier med hög CPU kanske frågelagrings- och väntestatistiken inte återspeglar CPU-användningen om:
- Frågor med hög CPU-användning körs fortfarande.
- Frågorna med hög CPU-användning kördes när en redundansväxling inträffade.
DMV:er som spårar Query Store- och väntestatistik visar resultat för endast slutförda och tidsgränserade frågor. De visar inte data för att köra instruktioner för närvarande förrän -uttrycken har slutförts. Använd den dynamiska hanteringsvyn sys.dm_exec_requests för att spåra frågor som körs och den associerade arbetstiden.
Nästa steg
- Konfigurera den maximala graden av parallellitet (MAXDOP) i Azure SQL Database
- Förstå och lösa blockeringsproblem i Azure SQL Database i Azure SQL Database
- Diagnostisera och felsöka hög CPU-användning i Azure SQL Database
- Översikt över övervakning och justering av SQL Database
- Övervaka Prestanda för Microsoft Azure SQL Database med dynamiska hanteringsvyer
- Justera icke-illustrerade index med indexförslag som saknas
- Resurshantering i Azure SQL Database
- Resursbegränsningar för enskilda databaser med hjälp av vCore-inköpsmodellen
- Resursbegränsningar för elastiska pooler med hjälp av vCore-inköpsmodellen
- Resursbegränsningar för enskilda databaser med hjälp av inköpsmodellen DTU
- Resursbegränsningar för elastiska pooler med hjälp av DTU-inköpsmodellen
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för