Sekundära repliker i hyperskala
Gäller för:![]() Azure SQL Database
Azure SQL Database
Som beskrivs i arkitekturen för distribuerade funktioner har Azure SQL Database Hyperscale två olika typer av beräkningsnoder, även kallade repliker:
- Primär: hanterar läs- och skrivåtgärder
- Sekundär: ger lässkalning, hög tillgänglighet och geo-replikering
Sekundära repliker är alltid skrivskyddade och kan ha tre olika typer:
- Replik med hög tillgänglighet
- Geo-replik
- Namngiven replik
Varje typ har en annan arkitektur, funktionsuppsättning, syfte och kostnad. Baserat på de funktioner du behöver kan du använda bara en eller till och med alla tre tillsammans. Sekundära repliker stöds av både serverlösa och etablerade beräkningsnivåer.
Replik med hög tillgänglighet
En HA-replik (hög tillgänglighet) använder samma sidservrar som den primära repliken, så ingen datakopiering krävs för att lägga till en HA-replik. HA-repliker används främst för att öka databastillgängligheten. de fungerar som frekventa väntelägen i redundanssyfte. Om den primära repliken blir otillgänglig blir redundansväxlingen till en av de befintliga HA-replikerna automatisk och snabb. Anslutningssträng behöver inte ändras. Under redundansväxlingen kan det uppstå minimal stilleståndstid på grund av att aktiva anslutningar tas bort. Som vanligt för det här scenariot rekommenderas korrekt omprövningslogik. Flera drivrutiner tillhandahåller redan en viss grad av logik för automatiskt återförsök. Om du använder .NET ger det senaste Microsoft.Data.SqlClient-biblioteket inbyggt fullständigt stöd för konfigurerbar logik för automatiska omförsök.
HA-repliker använder samma server- och databasnamn som den primära repliken. Deras servicenivåmål är också alltid samma som för den primära repliken. HA-repliker är inte synliga eller hanterbara som en fristående resurs från portalen eller från något API.
Det kan finnas noll till fyra HA-repliker. Deras antal kan ändras när en databas skapas eller när databasen har skapats, via de vanliga hanteringsslutpunkterna och verktygen (till exempel PowerShell, AZ CLI, Portal, REST API). Att skapa eller ta bort HA-repliker påverkar inte aktiva anslutningar på den primära repliken.
Anslut till en HA-replik
I Hyperskala-databaser ApplicationIntent avgör argumentet i anslutningssträng som används av klienten om anslutningen dirigeras till den skrivskyddade primära repliken eller till en skrivskyddad HA-replik. Om ApplicationIntent är inställt på ReadOnly och databasen inte har någon sekundär replik dirigeras anslutningen till den primära repliken och fungerar som standard ReadWrite .
-- Connection string with application intent
Server=tcp:<myserver>.database.windows.net;Database=<mydatabase>;ApplicationIntent=ReadOnly;User ID=<myLogin>;Password=<myPassword>;Trusted_Connection=False; Encrypt=True;
Alla HA-repliker är identiska i sin resurskapacitet. Om det finns fler än en HA-replik distribueras läs avsiktsarbetsbelastningen godtyckligt över alla tillgängliga HA-repliker. När det finns flera HA-repliker bör du tänka på att var och en kan ha olika datafördröjning när det gäller dataändringar som görs på den primära. Varje HA-replik använder samma data som den primära på samma uppsättning sidservrar. Lokala datacacheminnen på varje HA-replik återspeglar dock de ändringar som gjorts på den primära via transaktionsloggtjänsten, som vidarebefordrar loggposter från den primära repliken till HA-repliker. Beroende på vilken arbetsbelastning som bearbetas av en HA-replik kan därför tillämpningen av loggposter ske med olika hastighet, och därför kan olika repliker ha olika datasvarstid i förhållande till den primära repliken.
Namngiven replik
En namngiven replik, precis som en HA-replik, använder samma sidservrar som den primära repliken. På samma sätt som HA-repliker behövs ingen datakopiering för att lägga till en namngiven replik.
Det finns skillnader mellan HA-repliker och namngivna repliker:
- Namngivna repliker visas som vanliga (skrivskyddade) Azure SQL-databaser i portalen och i API-anrop (AZ CLI, PowerShell, T-SQL).
- Namngivna repliker kan ha ett annat databasnamn än den primära repliken och eventuellt finnas på en annan logisk server (så länge det finns i samma region som den primära repliken).
- Namngivna repliker har ett eget servicenivåmål som kan anges och ändras oberoende av den primära repliken.
- Namngivna repliker stöder upp till 30 namngivna repliker (för varje primär replik).
- Namngivna repliker stöder olika autentisering för varje namngiven replik genom att skapa olika inloggningar på logiska servrar som är värdar för namngivna repliker.
Därför erbjuder namngivna repliker flera fördelar jämfört med HA-repliker, för vad gäller skrivskyddade arbetsbelastningar:
- Användare som är anslutna till en namngiven replik drabbas inte av någon frånkoppling om den primära repliken skalas upp eller ned. Samtidigt påverkas inte användare som är anslutna till den primära repliken av namngivna repliker som skalar upp eller ned.
- Arbetsbelastningar som körs på en replik, primär eller namngiven, påverkas inte av långvariga frågor som körs på andra repliker.
Huvudmålet med namngivna repliker är att möjliggöra en mängd olika scenarier för lässkalning och att förbättra HTAP-arbetsbelastningar (Hybrid Transactional and Analytical Processing). Exempel på hur du skapar sådana lösningar finns här:
Förutom de huvudsakliga scenarier som anges ovan erbjuder namngivna repliker flexibilitet och elasticitet för att även uppfylla många andra användningsfall:
- Åtkomstisolering: du kan bevilja åtkomst till en specifik namngiven replik, men inte den primära repliken eller andra namngivna repliker.
- Arbetsbelastningsberoende servicenivåmål: eftersom en namngiven replik kan ha ett eget servicenivåmål är det möjligt att använda olika namngivna repliker för olika arbetsbelastningar och användningsfall. Till exempel kan en namngiven replik användas för att hantera Power BI-begäranden, medan en annan kan användas för att hantera data till Apache Spark för Datavetenskap uppgifter. Var och en kan ha ett oberoende servicenivåmål och skala oberoende av varandra.
- Arbetsbelastningsberoende routning: med upp till 30 namngivna repliker kan du använda namngivna repliker i grupper så att ett program kan isoleras från en annan. Till exempel kan en grupp med fyra namngivna repliker användas för att hantera begäranden som kommer från mobila program, medan en annan grupp två namngivna repliker kan användas för att hantera begäranden som kommer från ett webbprogram. Den här metoden skulle möjliggöra en detaljerad justering av prestanda och kostnader för varje grupp.
I följande exempel skapas en namngiven replik WideWorldImporters_NamedReplica för databasen WideWorldImporters. Den primära repliken använder servicenivåmål HS_Gen5_4, medan den namngivna repliken använder HS_Gen5_2. Båda använder samma logiska server contosoeast. Om du föredrar att använda REST API direkt är det här alternativet också möjligt: Databaser – Skapa en databas som namngiven replik sekundär.
I Azure-portalen bläddrar du till den databas som du vill skapa den namngivna repliken för.
På sidan SQL Database väljer du din databas, bläddrar till Datahantering, väljer Repliker och sedan Skapa replik.
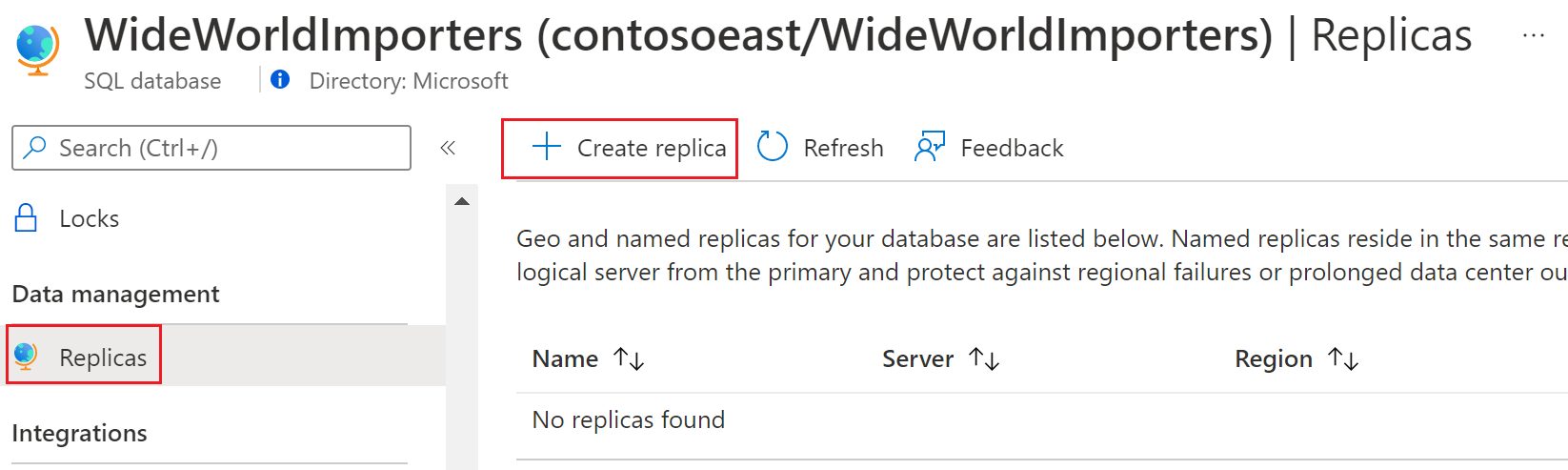
Välj Namngiven replik under Replikkonfiguration, välj eller skapa servern för den namngivna repliken, ange namnet på replikens databasnamn och konfigurera alternativen För beräkning + lagring om det behövs.
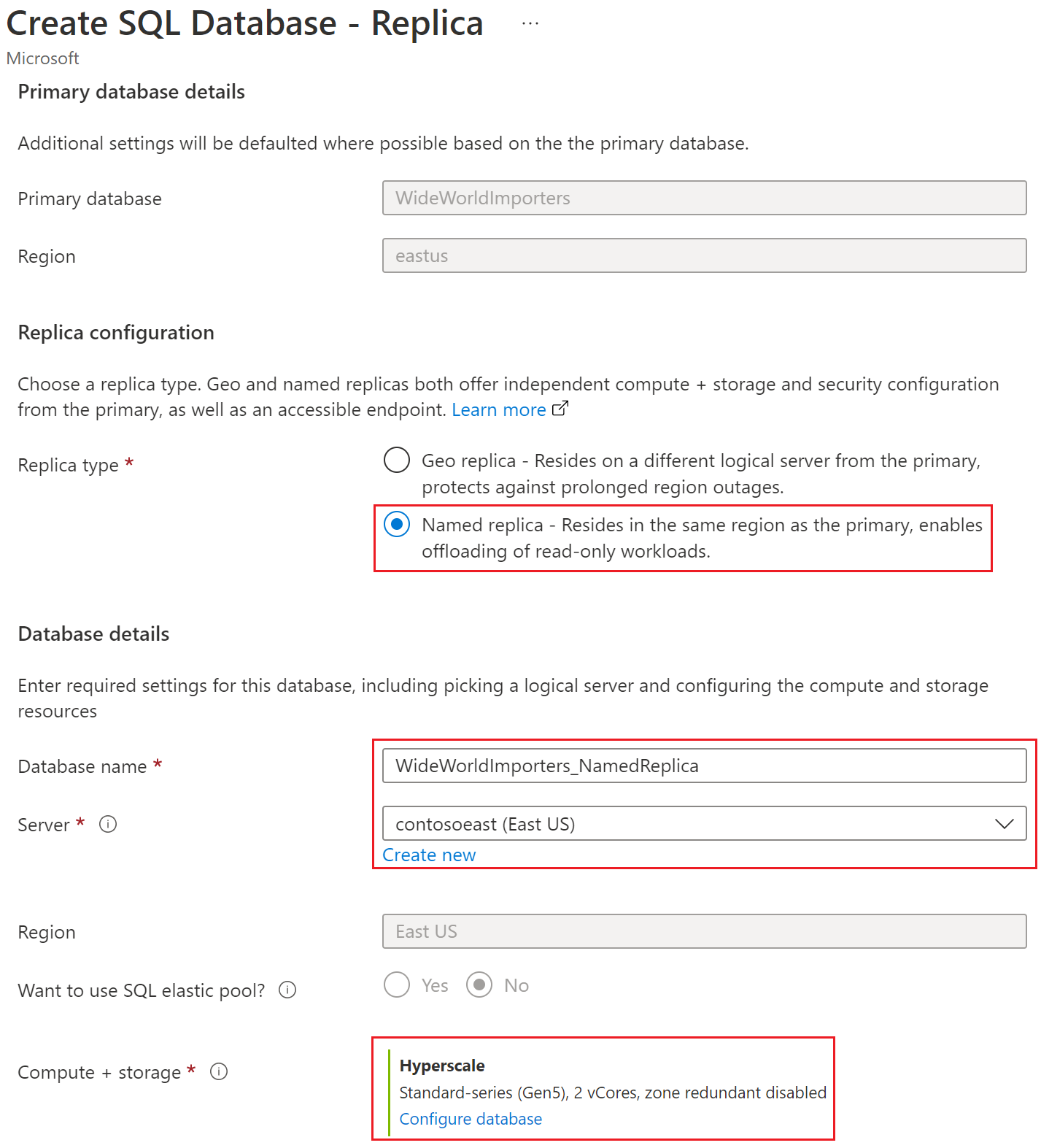
Välj Granska + skapa, granska informationen och välj sedan Skapa.
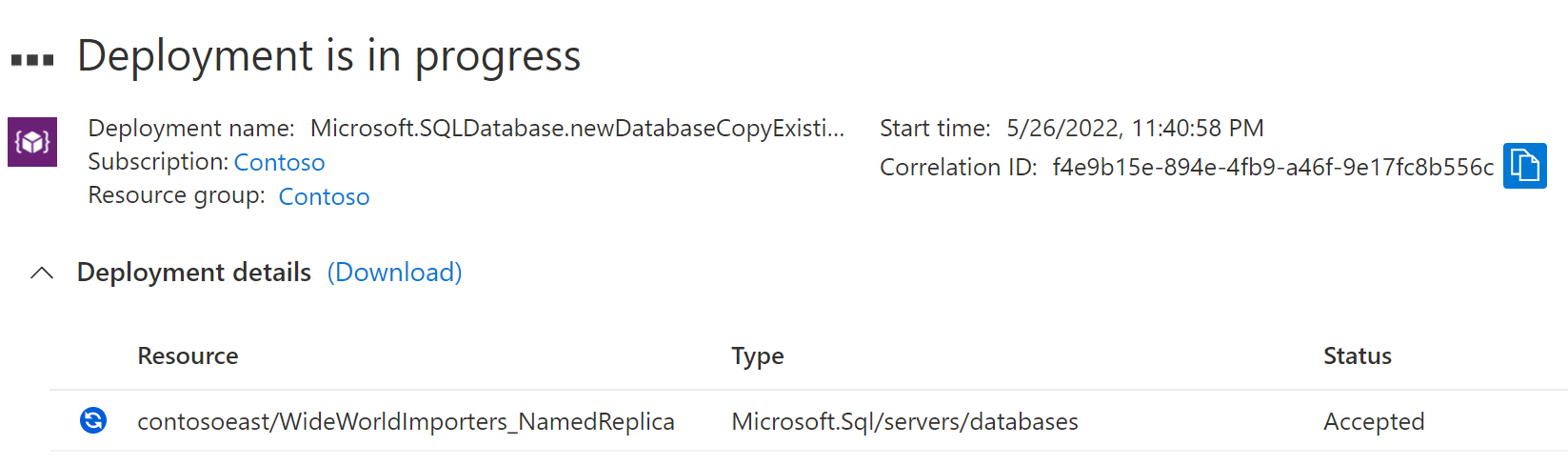
Distributionsprocessen för namngiven replik börjar.
När distributionen är klar visar den namngivna repliken dess status.
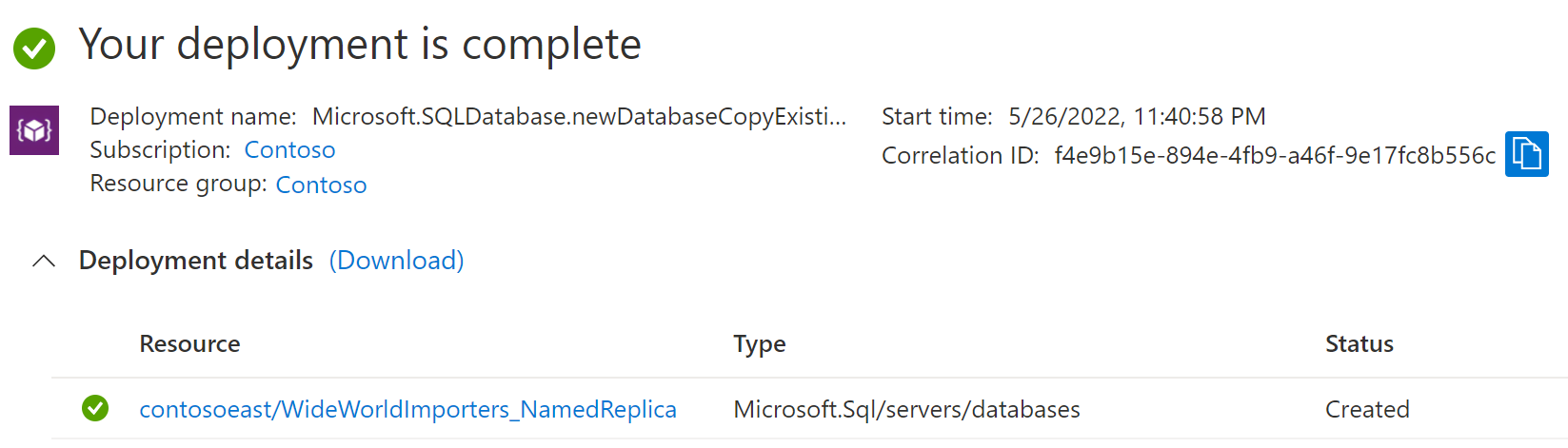
Gå tillbaka till den primära databassidan och välj sedan Repliker. Din namngivna replik visas under Namngivna repliker.
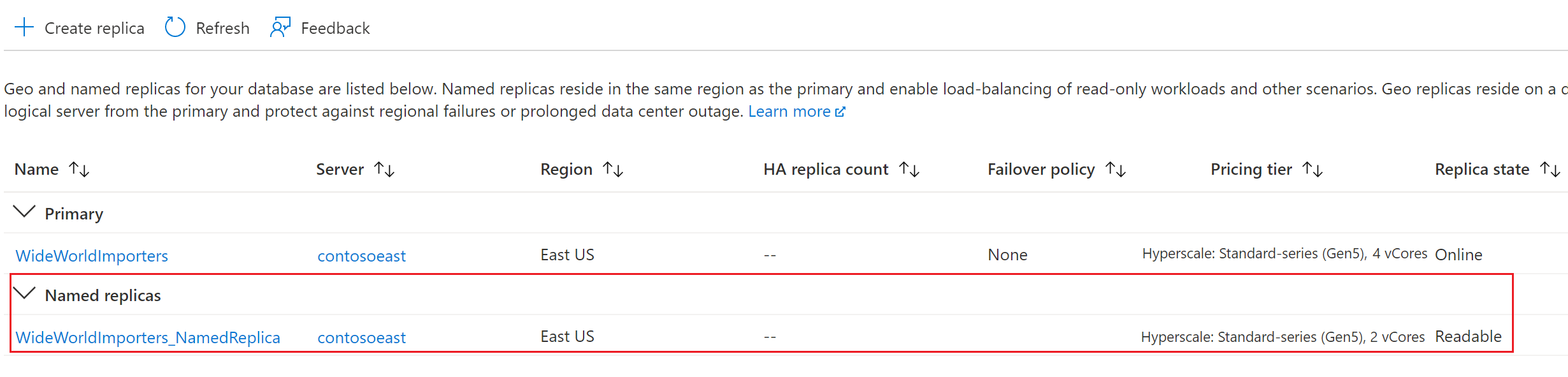
Eftersom det inte rör sig om någon dataförflyttning skapas i de flesta fall en namngiven replik om ungefär en minut. När den namngivna repliken är tillgänglig visas den från portalen eller något kommandoradsverktyg som AZ CLI eller PowerShell. En namngiven replik kan användas som en vanlig skrivskyddad databas.
Kommentar
Vanliga frågor och svar om hyperskala med namngivna repliker finns i Vanliga frågor och svar om Azure SQL Database Hyperscale-namngivna repliker.
Anslut till en namngiven replik
Om du vill ansluta till en namngiven replik måste du använda anslutningssträng för den namngivna repliken och referera till dess server- och databasnamn. Du behöver inte ange alternativet "ApplicationIntent=ReadOnly" eftersom namngivna repliker alltid är skrivskyddade.
Precis som för HA-repliker, även om de primära replikerna, HA och namngivna repliker delar samma data på samma uppsättning sidservrar, hålls datacacheminnen på varje namngiven replik synkroniserade med den primära via transaktionsloggtjänsten, som vidarebefordrar loggposter från den primära till namngivna replikerna. Beroende på vilken arbetsbelastning som bearbetas av en namngiven replik kan därför tillämpningen av loggposterna ske med olika hastighet, och därför kan olika repliker ha olika datasvarstid i förhållande till den primära repliken.
Ändra en namngiven replik
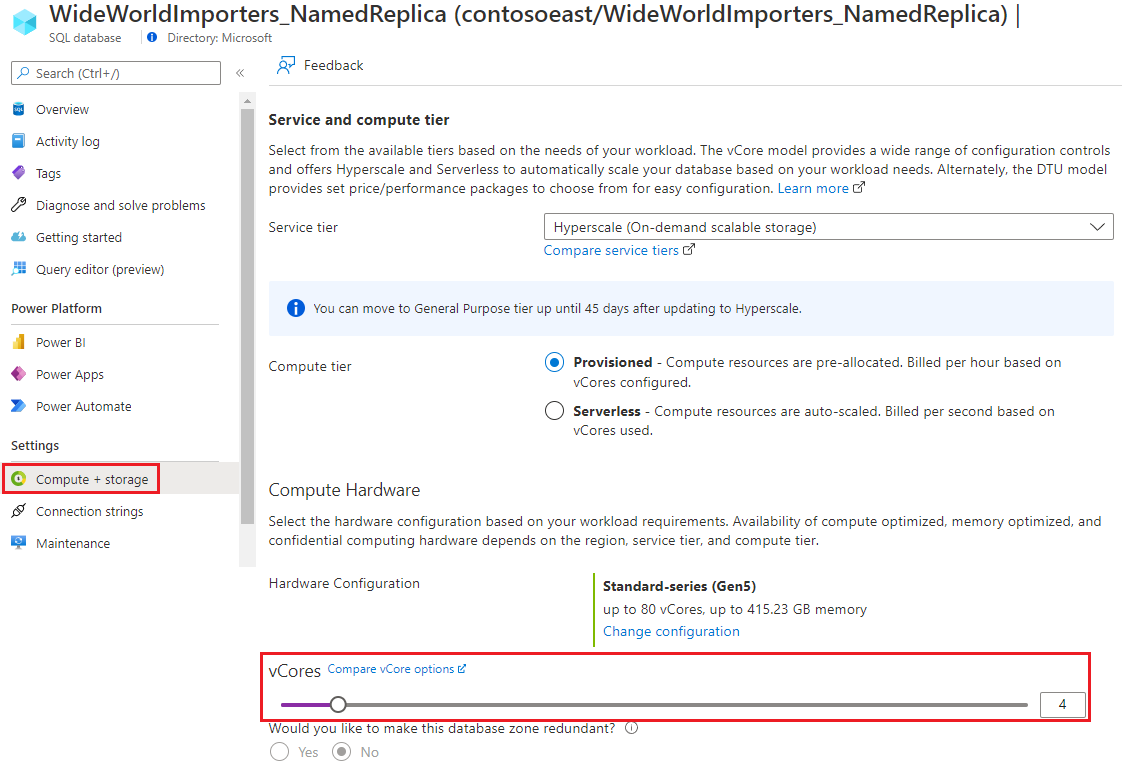
Du kan definiera servicenivåmålet för en namngiven replik när du skapar den ALTER DATABASE , via kommandot eller på något annat sätt som stöds (Portal, AZ CLI, PowerShell, REST API). Om du behöver ändra servicenivåmålet när den namngivna repliken har skapats kan du göra det med kommandot ALTER DATABASE ... MODIFY på den namngivna repliken. Om till exempel WideWorldImporters_NamedReplica är den namngivna repliken av WideWorldImporters databasen kan du göra det enligt nedan.
Öppna den namngivna replikdatabassidan och välj sedan Beräkning + lagring. Uppdatera de virtuella kärnorna.
Ta bort en namngiven replik
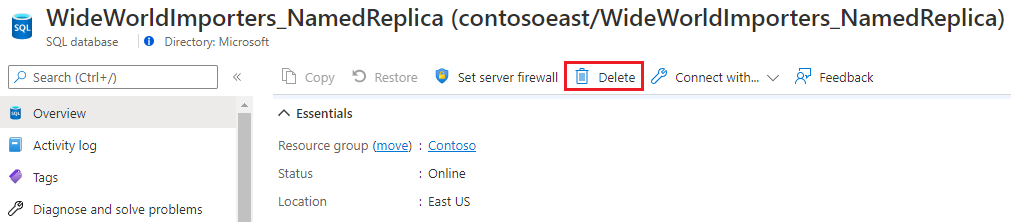
Om du vill ta bort en namngiven replik släpper du den precis som en vanlig databas.
Öppna den namngivna replikdatabassidan och välj Delete alternativet.
Viktigt!
Namngivna repliker tas bort automatiskt när den primära repliken som de har skapats från tas bort.
Kända problem
Delvis felaktiga data som returneras från sys.databases
Radvärden som returneras från sys.databases, för namngivna repliker, i andra kolumner än name och database_id, kan vara inkonsekventa och felaktiga. Kolumnen för en namngiven compatibility_level replik kan till exempel rapporteras som 140 även om den primära databasen som den namngivna repliken har skapats från är inställd på 150. En lösning är när det är möjligt att hämta samma data med hjälp av DATABASEPROPERTYEX() funktionen, som returnerar rätt data.
Geo-replik
Med aktiv geo-replikering kan du skapa en läsbar sekundär replik av den primära Hyperskala-databasen i samma eller i en annan Azure-region. Geo-repliker måste skapas på en annan logisk server. Databasnamnet för en geo-replik matchar alltid databasnamnet för den primära.
När du skapar en geo-replik kopieras alla data från den primära till en annan uppsättning sidservrar. En geo-replik delar inte sidservrar med den primära, även om de finns i samma region. Den här arkitekturen tillhandahåller nödvändig redundans för geo-redundans.
Geo-repliker används för att underhålla en transaktionsmässigt konsekvent kopia av databasen via asynkron replikering. Om en geo-replik finns i en annan Azure-region kan den användas för haveriberedskap vid haveri eller avbrott i den primära regionen. Geo-repliker kan också användas för geografiska utskalningsscenarier för läsning. Från och med oktober 2022 stöds databaskopiering från en geo-sekundär hyperskalareplik.
Geo-replikering för Hyperskala-databasen har följande aktuella begränsningar:
- Endast en geo-replik kan skapas (i samma eller en annan region).
- Återställning till tidpunkt för geo-repliken stöds inte.
- Det går inte att skapa geo-replikering av en geo-replik (kallas även "geo-repliklänkning").