Påskynda stordataanalys i realtid med spark-anslutningsappen
Gäller för:![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance
Kommentar
Från och med sep 2020 underhålls inte den här anslutningsappen aktivt. Apache Spark-Anslut eller för SQL Server och Azure SQL är nu tillgängligt, med stöd för Python- och R-bindningar, ett enklare gränssnitt för massinfogning av data och många andra förbättringar. Vi rekommenderar starkt att du utvärderar och använder den nya anslutningsappen i stället för den här. Informationen om den gamla anslutningsappen (den här sidan) behålls endast i arkiveringssyfte.
Spark-anslutningsappen gör det möjligt för databaser i Azure SQL Database, Azure SQL Managed Instance och SQL Server att fungera som indatakälla eller utdatamottagare för Spark-jobb. Det gör att du kan använda transaktionsdata i realtid i stordataanalys och spara resultat för ad hoc-frågor eller rapportering. Jämfört med den inbyggda JDBC-anslutningsappen ger den här anslutningsappen möjlighet att massinfoga data i databasen. Den kan överträffa infogning rad för rad med 10x till 20 x snabbare prestanda. Spark-anslutningsappen stöder autentisering med Microsoft Entra ID (tidigare Azure Active Directory) för att ansluta till Azure SQL Database och Azure SQL Managed Instance, så att du kan ansluta din databas från Azure Databricks med ditt Microsoft Entra-konto. Den tillhandahåller liknande gränssnitt med den inbyggda JDBC-anslutningsappen. Det är enkelt att migrera dina befintliga Spark-jobb för att använda den här nya anslutningsappen.
Kommentar
Microsoft Entra-ID är det nya namnet för Azure Active Directory (Azure AD). Vi uppdaterar dokumentationen just nu.
Ladda ned och skapa en Spark-anslutningsapp
GitHub-lagringsplatsen för den gamla anslutningsappen som tidigare länkats till från den här sidan underhålls inte aktivt. I stället rekommenderar vi starkt att du utvärderar och använder den nya anslutningsappen.
Officiella versioner som stöds
| Komponent | Version |
|---|---|
| Apache Spark | 2.0.2 eller senare |
| Scala | 2.10 eller senare |
| Microsoft JDBC-drivrutin för SQL Server | 6.2 eller senare |
| Microsoft SQL Server | SQL Server 2008 eller senare |
| Azure SQL Database | Stöds |
| Azure SQL Managed Instance | Stöds |
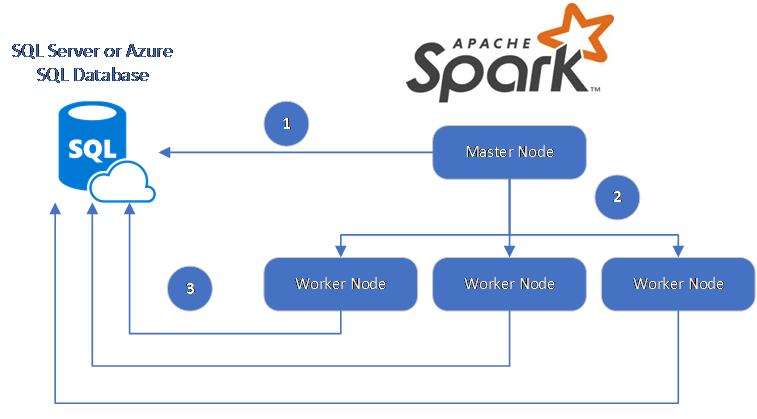
Spark-anslutningsappen använder Microsoft JDBC-drivrutinen för SQL Server för att flytta data mellan Spark-arbetsnoder och databaser:
Dataflödet är följande:
- Spark-huvudnoden ansluter till databaser i SQL Database eller SQL Server och läser in data från en specifik tabell eller med hjälp av en specifik SQL-fråga.
- Spark-huvudnoden distribuerar data till arbetsnoder för transformering.
- Noden Worker ansluter till databaser som ansluter till SQL Database och SQL Server och skriver data till databasen. Användaren kan välja att använda infogande rad för rad eller massinfogning.
Följande diagram illustrerar dataflödet.
Skapa Spark-anslutningsappen
För närvarande använder anslutningsprojektet maven. Om du vill skapa anslutningsappen utan beroenden kan du köra:
- mvn clean-paket
- Ladda ned de senaste versionerna av JAR från versionsmappen
- Inkludera SQL Database Spark JAR
Anslut och läsa data med spark-anslutningsappen
Du kan ansluta till databaser i SQL Database och SQL Server från ett Spark-jobb för att läsa eller skriva data. Du kan också köra en DML- eller DDL-fråga i databaser i SQL Database och SQL Server.
Läsa data från Azure SQL och SQL Server
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"dbTable" -> "dbo.Clients",
"user" -> "username",
"password" -> "*********",
"connectTimeout" -> "5", //seconds
"queryTimeout" -> "5" //seconds
))
val collection = sqlContext.read.sqlDB(config)
collection.show()
Läsa data från Azure SQL och SQL Server med angiven SQL-fråga
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"queryCustom" -> "SELECT TOP 100 * FROM dbo.Clients WHERE PostalCode = 98074" //Sql query
"user" -> "username",
"password" -> "*********",
))
//Read all data in table dbo.Clients
val collection = sqlContext.read.sqlDB(config)
collection.show()
Skriva data till Azure SQL och SQL Server
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
// Aquire a DataFrame collection (val collection)
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"dbTable" -> "dbo.Clients",
"user" -> "username",
"password" -> "*********"
))
import org.apache.spark.sql.SaveMode
collection.write.mode(SaveMode.Append).sqlDB(config)
Köra DML- eller DDL-fråga i Azure SQL och SQL Server
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.query._
val query = """
|UPDATE Customers
|SET ContactName = 'Alfred Schmidt', City = 'Frankfurt'
|WHERE CustomerID = 1;
""".stripMargin
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"user" -> "username",
"password" -> "*********",
"queryCustom" -> query
))
sqlContext.sqlDBQuery(config)
Anslut från Spark med Microsoft Entra-autentisering
Du kan ansluta till SQL Database och SQL Managed Instance med Hjälp av Microsoft Entra-autentisering. Använd Microsoft Entra-autentisering för att centralt hantera identiteter för databasanvändare och som ett alternativ till SQL-autentisering.
Anslut med ActiveDirectoryPassword-autentiseringsläge
Installationskrav
Om du använder autentiseringsläget ActiveDirectoryPassword måste du ladda ned microsoft-authentication-library-for-java och dess beroenden och inkludera dem i Java-byggsökvägen.
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"user" -> "username",
"password" -> "*********",
"authentication" -> "ActiveDirectoryPassword",
"encrypt" -> "true"
))
val collection = sqlContext.read.sqlDB(config)
collection.show()
Anslut med hjälp av en åtkomsttoken
Installationskrav
Om du använder det tokenbaserade autentiseringsläget för åtkomst måste du ladda ned microsoft-authentication-library-for-java och dess beroenden och inkludera dem i Java-byggsökvägen.
Se Använda Microsoft Entra-autentisering för att lära dig hur du hämtar en åtkomsttoken till din databas i Azure SQL Database eller Azure SQL Managed Instance.
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"accessToken" -> "access_token",
"hostNameInCertificate" -> "*.database.windows.net",
"encrypt" -> "true"
))
val collection = sqlContext.read.sqlDB(config)
collection.show()
Skriva data med massinfogning
Den traditionella jdbc-anslutningsappen skriver data till databasen med hjälp av infogande rad för rad. Du kan använda Spark-anslutningsappen för att skriva data till Azure SQL och SQL Server med massinfogning. Det förbättrar avsevärt skrivprestandan vid inläsning av stora datamängder eller inläsning av data i tabeller där ett kolumnlagerindex används.
import com.microsoft.azure.sqldb.spark.bulkcopy.BulkCopyMetadata
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
/**
Add column Metadata.
If not specified, metadata is automatically added
from the destination table, which may suffer performance.
*/
var bulkCopyMetadata = new BulkCopyMetadata
bulkCopyMetadata.addColumnMetadata(1, "Title", java.sql.Types.NVARCHAR, 128, 0)
bulkCopyMetadata.addColumnMetadata(2, "FirstName", java.sql.Types.NVARCHAR, 50, 0)
bulkCopyMetadata.addColumnMetadata(3, "LastName", java.sql.Types.NVARCHAR, 50, 0)
val bulkCopyConfig = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"user" -> "username",
"password" -> "*********",
"dbTable" -> "dbo.Clients",
"bulkCopyBatchSize" -> "2500",
"bulkCopyTableLock" -> "true",
"bulkCopyTimeout" -> "600"
))
df.bulkCopyToSqlDB(bulkCopyConfig, bulkCopyMetadata)
//df.bulkCopyToSqlDB(bulkCopyConfig) if no metadata is specified.
Nästa steg
Om du inte redan har gjort det laddar du ned Spark-anslutningsappen från GitHub-lagringsplatsen azure-sqldb-spark och utforskar de ytterligare resurserna på lagringsplatsen:
Du kanske också vill granska Apache Spark SQL, DataFrames och Datasets Guide och Azure Databricks-dokumentationen.