Självstudie: Konfigurera SQL Data Sync mellan databaser i Azure SQL Database och SQL Server
Gäller för:![]() Azure SQL Database
Azure SQL Database
I den här självstudien lär du dig hur du konfigurerar SQL Data Sync genom att skapa en synkroniseringsgrupp som innehåller både Azure SQL Database- och SQL Server-instanser. Synkroniseringsgruppen är anpassad konfigurerad och synkroniseras enligt det schema som du anger.
Självstudien förutsätter att du har minst en viss tidigare erfarenhet av SQL Database och SQL Server.
En översikt över SQL Data Sync finns i Synkronisera data över molndatabaser och lokala databaser med SQL Data Sync.
PowerShell-exempel på hur du konfigurerar SQL Data Sync finns i Så här synkroniserar du mellan databaser i SQL Database eller mellan databaser i Azure SQL Database och SQL Server
Viktigt!
Hubbdatabasen är en synkroniseringstopologis centrala slutpunkt, där en synkroniseringsgrupp har flera databasslutpunkter. Alla andra medlemsdatabaser med slutpunkter i synkroniseringsgruppen, synkronisera med hubbdatabasen.
För närvarande stöds SQL Data Sync endast i Azure SQL Database. Hubbdatabasen måste vara en Azure SQL Database.
Azure SQL Database Hyperscale stöds bara som en medlemsdatabas, inte som en hubbdatabas .
Skapa synkroniseringsgrupp
Gå till Azure-portalen. Sök efter och välj SQL-databaser för att hitta en befintlig Azure SQL Database.
Välj den befintliga databas som du vill använda som hubbdatabas för datasynkronisering.
På resursmenyn för SQL-databasen för den valda databasen går du till Datahantering och väljer Synkronisera med andra databaser.
På sidan Synkronisera till andra databaser väljer du Ny synkroniseringsgrupp. Sidan Skapa datasynkroniseringsgrupp öppnas.
På sidan Skapa datasynkroniseringsgrupp konfigurerar du följande inställningar:
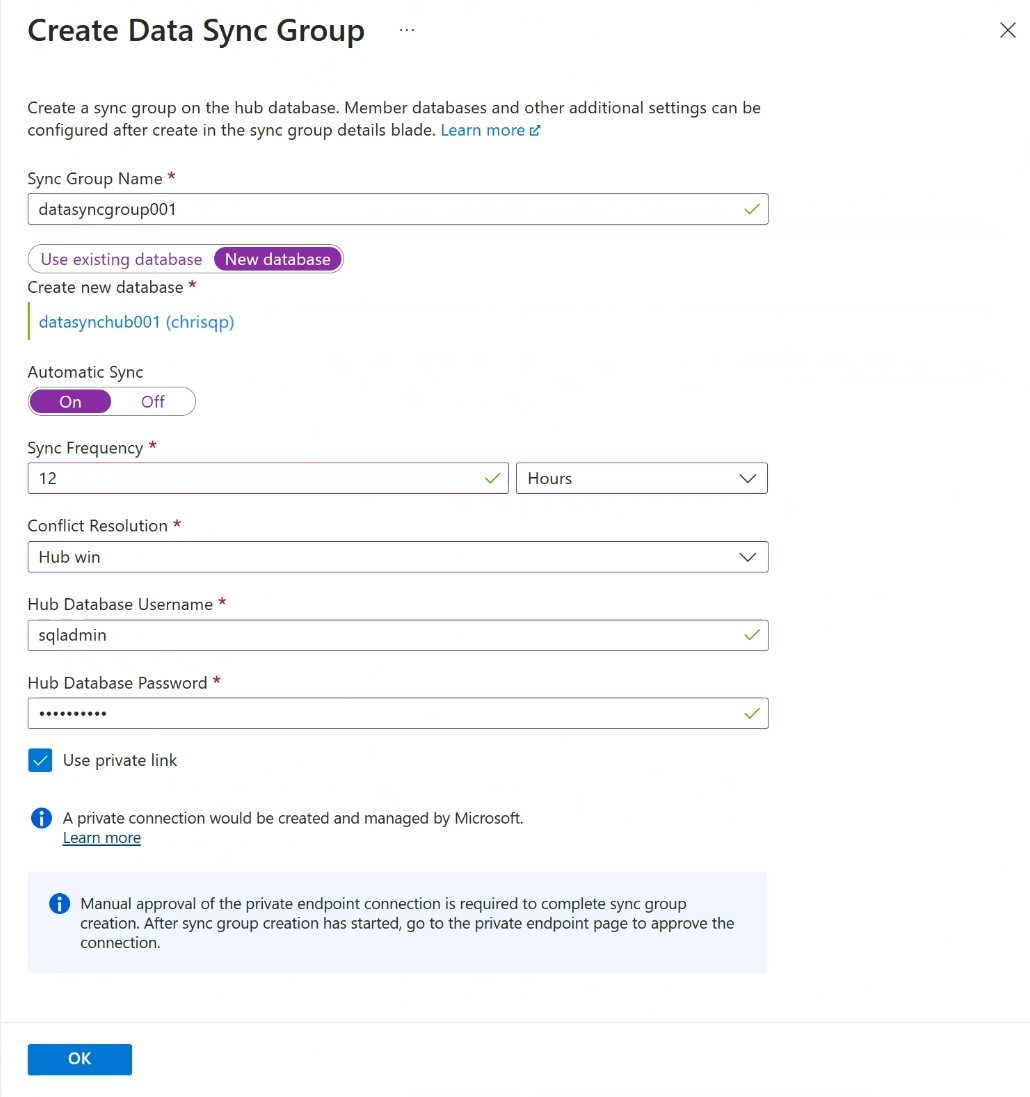
Inställningen beskrivning Namn på synkroniseringsgrupp Ange ett namn för den nya synkroniseringsgruppen. Det här namnet skiljer sig från namnet på själva databasen. Synkronisera metadatadatabas Välj att skapa en databas (rekommenderas) eller att använda en befintlig databas för att fungera som databasen för synkroniseringsmetadata.
Microsoft rekommenderar att du skapar en ny, tom databas som ska användas som databas för synkroniseringsmetadata. Data Sync skapar tabeller i den här databasen och kör en frekvent arbetsbelastning. Den här databasen delas som Databasen för synkroniseringsmetadata för alla synkroniseringsgrupper i en vald region och prenumeration. Du kan inte ändra databasen eller dess namn utan att ta bort alla synkroniseringsgrupper och synkroniseringsagenter i regionen.
Om du väljer att skapa en ny databas väljer du Ny databas. Välj Konfigurera databasinställningar. På sidan SQL Database namnger och konfigurerar du en ny Azure SQL Database och väljer OK.
Om du väljer Använd befintlig databas väljer du databasen i listrutan Synkronisera metadatadatabas .Automatisk synkronisering Välj På eller Av.
Om du väljer På anger du ett tal och väljer Sekunder, Minuter, Timmar eller Dagar i avsnittet Synkroniseringsfrekvens .
Den första synkroniseringen börjar efter att den valda intervallperioden förflutit från den tidpunkt då konfigurationen sparas.Konfliktlösning Välj Hubbvinst eller Medlemsvinst.
Hubbvinst innebär att när konflikter inträffar skriver data i hubbdatabasen över motstridiga data i medlemsdatabasen.
Medlemsvinst innebär att när konflikter inträffar skriver data i medlemsdatabasen över motstridiga data i hubbdatabasen.Navdatabasens användarnamn och hubbdatabaslösenord Ange användarnamn och lösenord för serveradministratören sql-autentiserad inloggning för hubbdatabasen. Det här är serveradministratörens användarnamn och lösenord för samma logiska Azure SQL-server som du startade på. Microsoft Entra-autentisering (tidigare Azure Active Directory) stöds inte för närvarande. Använd privat länk Välj en tjänsthanterad privat slutpunkt för att upprätta en säker anslutning mellan synkroniseringstjänsten och hubbdatabasen. Välj OK och vänta tills synkroniseringsgruppen har skapats och distribuerats.
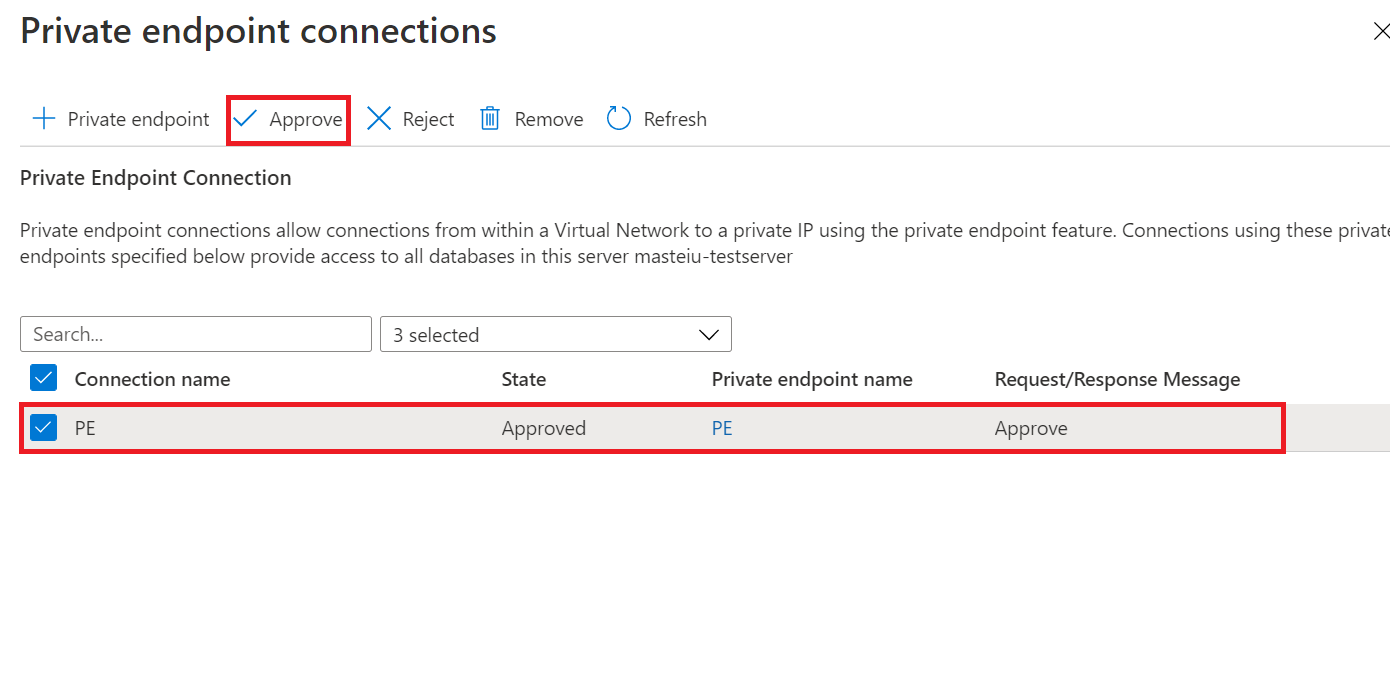
På sidan Ny synkroniseringsgrupp måste du godkänna den privata slutpunktsanslutningen om du har valt Använd privat länk. Länken i informationsmeddelandet tar dig till den privata slutpunktsanslutningen där du kan godkänna anslutningen.
Kommentar
De privata länkarna för synkroniseringsgruppen och synkroniseringsmedlemmarna måste skapas, godkännas och inaktiveras separat.
Lägga till synkroniseringsmedlemmar
När den nya synkroniseringsgruppen har skapats och distribuerats öppnar du synkroniseringsgruppen och öppnar sidan Databaser, där du väljer synkroniseringsmedlemmar .
Kommentar
Om du vill uppdatera eller infoga användarnamnet och lösenordet i din hubbdatabas går du till avsnittet Hub Database på sidan Välj synkroniseringsmedlemmar .
Lägga till en databas i Azure SQL Database som medlem i en synkroniseringsgrupp
I avsnittet Välj synkroniseringsmedlemmar kan du lägga till en databas i Azure SQL Database i synkroniseringsgruppen genom att välja Lägg till en Azure Database. Sidan Konfigurera Azure Database öppnas.
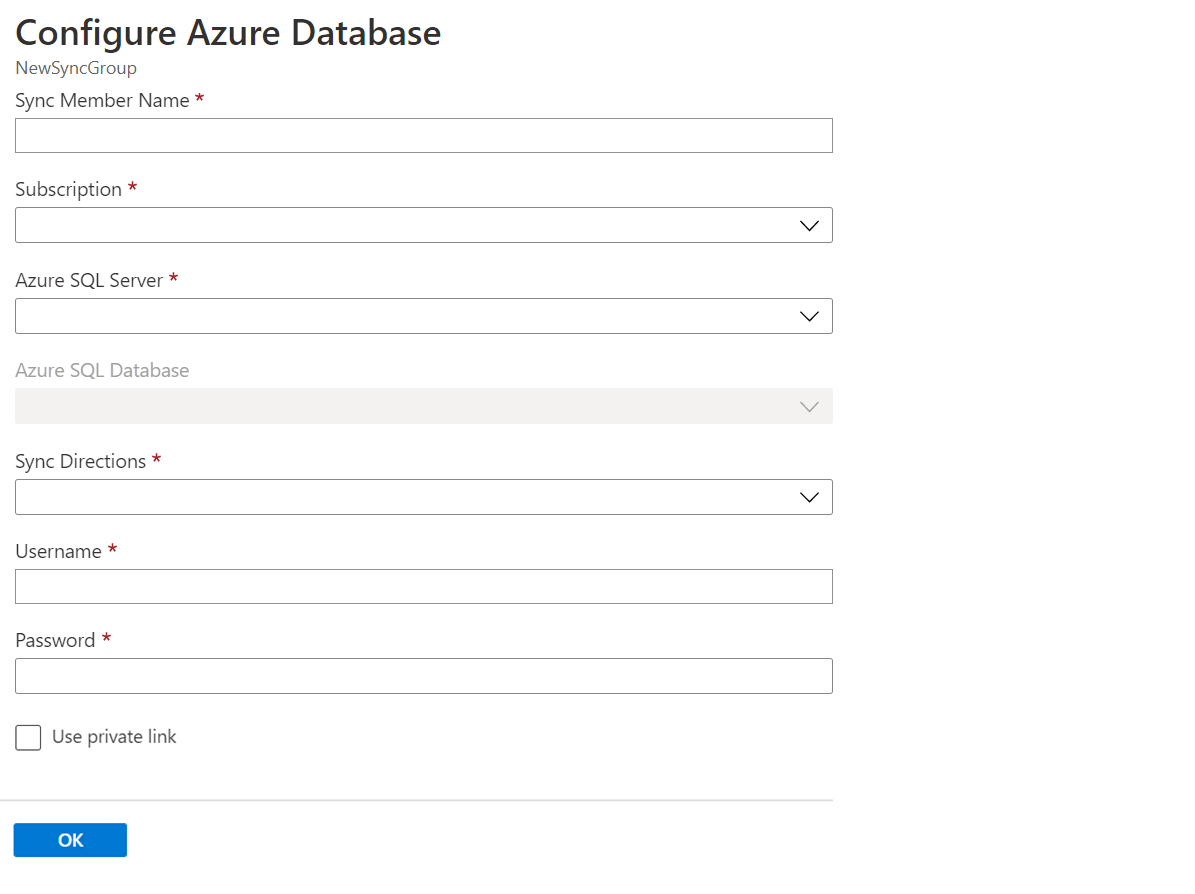
Ändra följande inställningar på sidan Konfigurera Azure SQL Database :
Inställningen beskrivning Synkronisera medlemsnamn Ange ett namn för den nya synkroniseringsmedlemmen. Det här namnet skiljer sig från själva databasnamnet. Abonnemang Välj den associerade Azure-prenumerationen i faktureringssyfte. Azure SQL Server Välj den befintliga servern. Azure SQL Database Välj den befintliga databasen i SQL Database. Synkroniseringsriktningar Synkroniseringsriktningen kan vara hubb till medlem, medlem till hubb eller båda. Välj Från hubben, till hubben eller dubbelriktad synkronisering. Mer information finns i Så här fungerar det. Användarnamn och lösenord Ange befintliga autentiseringsuppgifter för servern där medlemsdatabasen finns. Ange inte nya autentiseringsuppgifter i det här avsnittet. Använd privat länk Välj en tjänsthanterad privat slutpunkt för att upprätta en säker anslutning mellan synkroniseringstjänsten och medlemsdatabasen. Välj OK och vänta tills den nya synkroniseringsmedlemmen har skapats och distribuerats.
Lägga till en databas på en SQL Server-instans som medlem i en synkroniseringsgrupp
I avsnittet Medlemsdatabas kan du lägga till en databas i en SQL Server-instans i synkroniseringsgruppen genom att välja Lägg till en lokal databas.
Sidan Konfigurera lokal öppnas där du kan göra följande:
Välj Välj Gateway för synkroniseringsagent. Sidan Välj synkroniseringsagent öppnas.
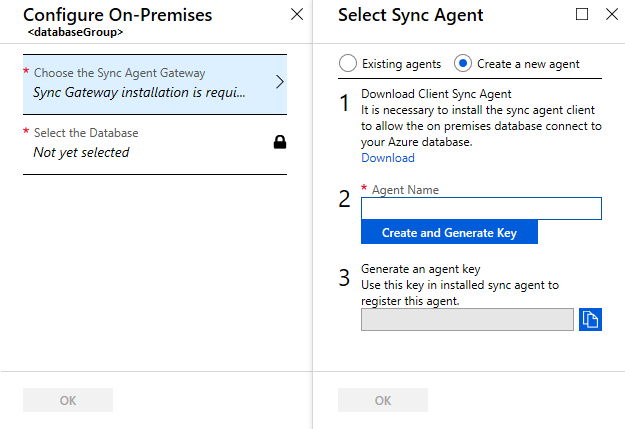
På sidan Välj synkroniseringsagent väljer du om du vill använda en befintlig agent eller skapa en agent.
Om du väljer Befintliga agenter väljer du den befintliga agenten i listan.
Om du väljer Skapa en ny agent gör du följande:
Ladda ned datasynkroniseringsagenten från den angivna länken och installera den på en annan server än där SQL Server-instansen finns. Du kan också ladda ned agenten direkt från Azure SQL Data Sync Agent. Metodtips för synkroniseringsklientagent finns i Metodtips för Azure SQL Data Sync.
Viktigt!
Du måste öppna utgående TCP-port 1433 i brandväggen för att klientagenten ska kunna kommunicera med servern.
Ange ett agentnamn.
Välj Skapa och generera nyckel och kopiera agentnyckeln till Urklipp.
Välj OK för att stänga sidan Välj synkroniseringsagent .
Leta upp och kör appen Klientsynkroniseringsagent på den server där synkroniseringsklientagenten är installerad.
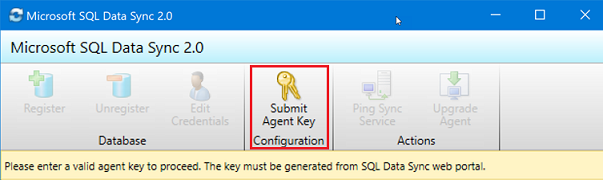
I synkroniseringsagentappen väljer du Skicka agentnyckel. Dialogrutan Synkroniseringsmetadatadatabaskonfiguration öppnas.
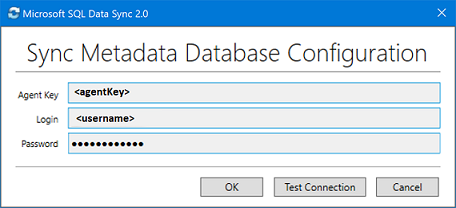
I dialogrutan Konfiguration av synkroniseringsmetadatadatabas klistrar du in agentnyckeln som kopierats från Azure-portalen. Ange även befintliga autentiseringsuppgifter för servern där databasen För synkroniseringsmetadatadatabasen finns. Välj OK och vänta tills konfigurationen är klar.
Kommentar
Om du får ett brandväggsfel skapar du en brandväggsregel i Azure för att tillåta inkommande trafik från SQL Server-datorn. Du kan skapa regeln manuellt i portalen eller i SQL Server Management Studio (SSMS). I SSMS ansluter du till hubbdatabasen i Azure genom att ange dess namn som
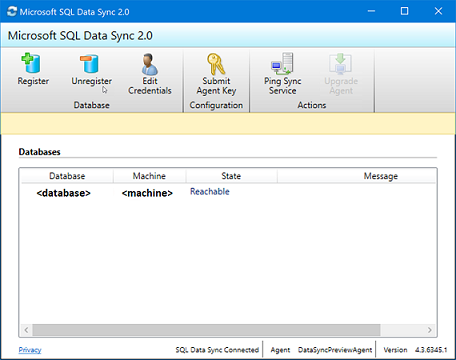
<hub_database_name>.database.windows.net.Välj Registrera för att registrera en SQL Server-databas med agenten. Dialogrutan SQL Server-konfiguration öppnas.
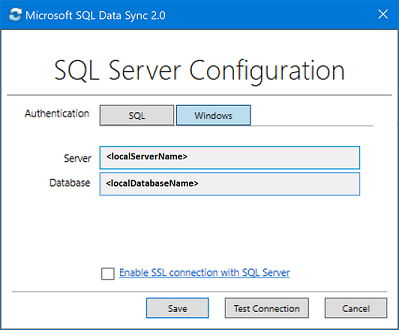
I dialogrutan SQL Server-konfiguration väljer du att ansluta med SQL Server-autentisering eller Windows-autentisering. Om du väljer SQL Server-autentisering anger du de befintliga autentiseringsuppgifterna. Ange SQL Server-namnet och namnet på den databas som du vill synkronisera och välj Testa anslutning för att testa inställningarna. Välj sedan Spara och den registrerade databasen visas i listan.
Stäng appen Klientsynkroniseringsagent.
I Azure-portalen går du till sidan Konfigurera lokalt och väljer Välj databas.
På sidan Välj databas i fältet Synkronisera medlemsnamn anger du ett namn för den nya synkroniseringsmedlemmen. Det här namnet skiljer sig från namnet på själva databasen. Välj databasen i listan. I fältet Synkroniseringsriktningar väljer du Dubbelriktad synkronisering, Till hubben eller Från hubben.
Välj OK för att stänga sidan Välj databas . Välj sedan OK för att stänga sidan Konfigurera lokal och vänta tills den nya synkroniseringsmedlemmen har skapats och distribuerats. Slutligen väljer du OK för att stänga sidan Välj synkroniseringsmedlemmar .
Kommentar
Om du vill ansluta till SQL Data Sync och den lokala agenten lägger du till ditt användarnamn i rollen DataSync_Executor. Data Sync skapar den här rollen på SQL Server-instansen.
Konfigurera synkroniseringsgrupp
När de nya medlemmarna i synkroniseringsgruppen har skapats och distribuerats går du till avsnittet Tabeller på sidan Databassynkroniseringsgrupp .
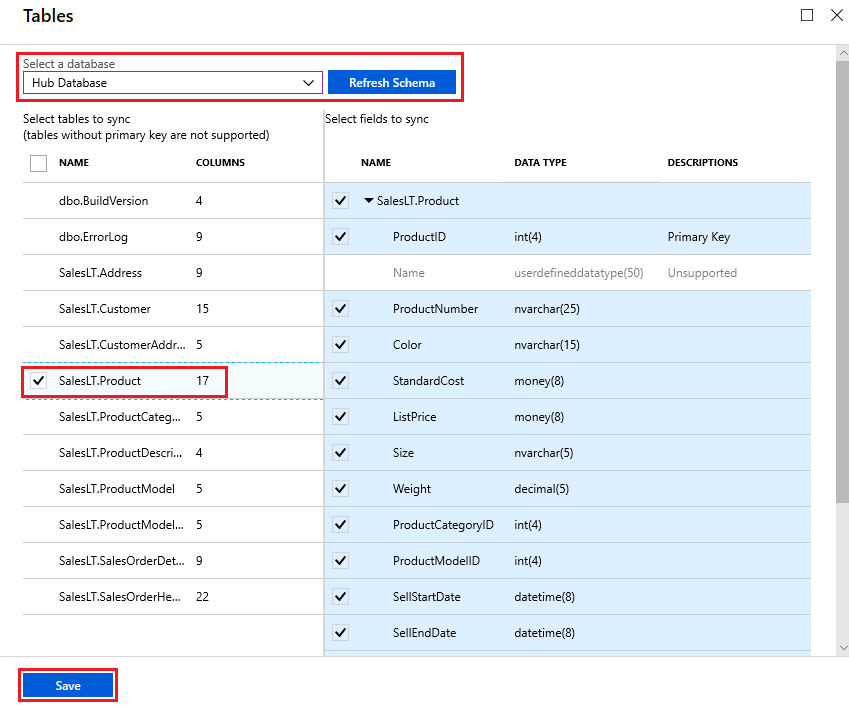
På sidan Tabeller väljer du en databas i listan över medlemmar i synkroniseringsgruppen och väljer Uppdatera schema. Förvänta dig några minuters fördröjning i uppdateringsschemat, fördröjningen kan vara några minuter längre om du använder privat länk.
I listan väljer du de tabeller som du vill synkronisera. Som standard är alla kolumner markerade, så inaktivera kryssrutan för de kolumner som du inte vill synkronisera. Se till att lämna primärnyckelkolumnen markerad.
Välj Spara.
Som standard synkroniseras inte databaser förrän de har schemalagts eller körts manuellt. Om du vill köra en manuell synkronisering går du till databasen i SQL Database i Azure-portalen, väljer Synkronisera till andra databaser och väljer synkroniseringsgruppen. Sidan Datasynkronisering öppnas. Välj synkronisera.
Vanliga frågor
Det här avsnittet besvarar vanliga frågor om Azure SQL Data Sync-tjänsten.
Skapar SQL Data Sync tabeller fullständigt?
Om tabeller i synkroniseringsschemat saknas i destinationsdatabasen skapar SQL Data Sync dem med de kolumner du har valt. Detta resulterar dock inte i ett fullständigt återgivningsschema av följande skäl:
- Endast de kolumner som du väljer skapas i måltabellen. Kolumner som inte valts ignoreras.
- Endast markerade kolumnindex skapas i måltabellen. Index för kolumner som inte valts ignoreras.
- Index för kolumner av XML-typ skapas inte.
- CHECK-begränsningar skapas inte.
- Utlösare för källtabellerna skapas inte.
- Vyer och lagrade procedurer skapas inte.
På grund av dessa begränsningar rekommenderar vi följande:
- I produktionsmiljöer bör du skapa schemat för fullständig exakthet själv.
- När du experimenterar med tjänsten kan du använda funktionen för automatisk etablering.
Varför visas tabeller som jag inte har skapat?
Data Sync skapar ytterligare tabeller i databasen för ändringsspårning. Ta inte bort dessa eller så slutar Data Sync att fungera.
Konvergerar mina data efter en synkronisering?
Inte nödvändigtvis. Ta en synkroniseringsgrupp med en hubb och tre ekrar (A, B och C) där synkroniseringar är Hub to A, Hub to B och Hub to C. Om en ändring görs i databas A efter hubben till A-synkronisering skrivs inte ändringen till databas B eller databas C förrän nästa synkroniseringsaktivitet.
Hur gör jag för att hämta schemaändringar i en synkroniseringsgrupp?
Skapa och sprida alla schemaändringar manuellt.
- Replikera schemaändringarna manuellt till hubben och till alla synkroniseringsmedlemmar.
- Uppdatera synkroniseringsschemat.
För att lägga till nya tabeller och kolumner:
Nya tabeller och kolumner påverkar inte den aktuella synkroniseringen och datasynkronisering ignorerar dem förrän de läggs till i synkroniseringsschemat. När du lägger till nya databasobjekt följer du sekvensen:
- Lägg till nya tabeller eller kolumner i hubben och till alla synkroniseringsmedlemmar.
- Lägg till nya tabeller eller kolumner i synkroniseringsschemat.
- Börja infoga värden i de nya tabellerna och kolumnerna.
Så här ändrar du datatypen för en kolumn:
När du ändrar datatypen för en befintlig kolumn fortsätter Data Sync att fungera så länge de nya värdena passar den ursprungliga datatypen som definierats i synkroniseringsschemat. Om du till exempel ändrar typen i källdatabasen från int till bigint fortsätter Data Sync att fungera tills du infogar ett värde som är för stort för int-datatypen. För att slutföra ändringen replikerar du schemaändringen manuellt till hubben och till alla synkroniseringsmedlemmar och uppdaterar sedan synkroniseringsschemat.
Hur kan jag exportera och importera en databas med Data Sync?
När du har exporterat en databas som en .bacpac fil och importerat filen för att skapa en databas gör du följande för att använda Data Sync i den nya databasen:
- Rensa datasynkroniseringsobjekten och ytterligare tabeller i den nya databasen med hjälp av Data Sync complete cleanup.sql. Skriptet tar bort alla nödvändiga Data Sync-objekt från databasen.
- Återskapa synkroniseringsgruppen med den nya databasen. Om du inte längre behöver den gamla synkroniseringsgruppen tar du bort den.
Var hittar jag information om klientagenten?
Vanliga frågor och svar om klientagenten finns i Vanliga frågor och svar om agenten.
Är det nödvändigt att godkänna länken manuellt innan jag kan börja använda den?
Ja. Du måste godkänna den tjänsthanterade privata slutpunkten manuellt på sidan Privata slutpunktsanslutningar i Azure-portalen under distributionen av synkroniseringsgruppen eller med hjälp av PowerShell.
Varför får jag ett brandväggsfel när synkroniseringsjobbet etablerar min Azure-databas?
Detta kan inträffa eftersom Azure-resurser inte har behörighet att komma åt servern. Det finns två lösningar:
- Kontrollera att brandväggen i Azure-databasen har angett Tillåt Att Azure-tjänster och resurser får åtkomst till den här servern till Ja. Mer information finns i Azure SQL Database- och nätverksåtkomstkontroller.
- Konfigurera en privat länk för Data Sync, som skiljer sig från en Azure Private Link. Private Link är ett sätt att skapa synkroniseringsgrupper med säker anslutning med databaser som sitter bakom en brandvägg. SQL Data Sync Private Link är Microsoft-hanterad slutpunkt och skapar internt ett undernät i det befintliga virtuella nätverket, så du behöver inte skapa ett annat virtuellt nätverk eller undernät.
Nästa steg
Gratulerar! Du har skapat en synkroniseringsgrupp som innehåller både en Azure SQL-databas och en SQL Server-databas.
Mer information om SQL Data Sync finns i:
- Vad är SQL Data Sync för Azure?
- Data Sync Agent för Azure SQL Data Sync
- Metodtips och Felsöka problem med Azure SQL Data Sync
- Övervaka SQL Data Sync med Azure Monitor-loggar
- Uppdatera synkroniseringsschemat med Transact-SQL eller PowerShell
Mer information om SQL Database finns i:
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för