Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
gäller för:![]() Azure SQL Database
Azure SQL Database
Viktigt!
SQL Data Sync dras tillbaka den 30 september 2027. Överväg att migrera till alternativa lösningar för datareplikering/synkronisering.
Synkronisera data med SQL Server-databaser genom att installera och konfigurera Data Sync Agent för SQL Data Sync i Azure. Mer information om SQL Data Sync finns i Vad är SQL Data Sync för Azure?
SQL Data Sync stöder inte Azure SQL Managed Instance eller Azure Synapse Analytics.
Ladda ned och installera
Försiktighet
Överväg att migrera till alternativa lösningar för datareplikering/synkronisering.
Om du vill ladda ned datasynkroniseringsagenten går du till SQL Data Sync Agent. Om du vill uppgradera datasynkroniseringsagenten installerar du agenten på samma plats som den gamla agenten och åsidosätter den ursprungliga.
Installera tyst
Om du vill installera Data Sync Agent tyst från kommandotolken anger du ett kommando som liknar följande exempel. Kontrollera filnamnet för den nedladdade .msi-filen och ange dina egna värden för argumenten TARGETDIR och SERVICEACCOUNT .
Om du inte anger något värde för TARGETDIR är
C:\Program Files (x86)\Microsoft SQL Data Sync 2.0standardvärdet .Om du anger
LocalSystemsom värdet för SERVICEACCOUNT använder du SQL Server-autentisering när du konfigurerar agenten för att ansluta till SQL Server.Om du anger ett domänanvändarkonto eller ett lokalt användarkonto som värdet för SERVICEACCOUNT måste du också ange lösenordet med argumentet SERVICEPASSWORD . Till exempel
SERVICEACCOUNT="<domain>\<user>" SERVICEPASSWORD="<password>".
msiexec /i "SQLDataSyncAgent-2.0-x86-ENU.msi" TARGETDIR="C:\Program Files (x86)\Microsoft SQL Data Sync 2.0" SERVICEACCOUNT="LocalSystem" /qn
Synkronisera data med en SQL Server-databas
Information om hur du konfigurerar datasynkroniseringsagenten så att du kan synkronisera data med en eller flera SQL Server-databaser finns i Lägga till en SQL Server-databas.
Stöd för lokala SQL Server-versioner
Endast följande versioner av SQL Server lokalt kan ingå i en synkroniseringsgrupp:
- SQL Server 2008
- SQL Server 2008 R2
- SQL Server 2012
- SQL Server 2016
- SQL Server 2017 i Windows
- SQL Server 2019 i Windows
- SQL Server 2022 i Windows
Vanliga frågor och svar om Data Sync Agent
Varför behöver jag en klientagent?
SQL Data Sync-tjänsten kommunicerar med SQL Server-databaser via klientagenten. Den här säkerhetsfunktionen förhindrar direkt kommunikation med databaser bakom en brandvägg. När SQL Data Sync-tjänsten kommunicerar med agenten gör den det med hjälp av krypterade anslutningar och en unik token eller agentnyckel. SQL Server-databaserna autentiserar agenten med hjälp av anslutningssträngen och agentnyckeln. Den här designen ger en hög säkerhetsnivå för dina data.
Hur många instanser av det lokala agentgränssnittet kan köras
Endast en instans av användargränssnittet kan köras.
Hur kan jag ändra mitt tjänstkonto
När du har installerat en klientagent är det enda sättet att ändra tjänstkontot att avinstallera det och installera en ny klientagent med det nya tjänstkontot.
Hur ändrar jag min agentnyckel
En agentnyckel kan bara användas en gång av en agent. Det går inte att återanvända när du tar bort och sedan installerar om en ny agent och kan inte heller användas av flera agenter. Om du behöver skapa en ny nyckel för en befintlig agent måste du vara säker på att samma nyckel registreras med klientagenten och med SQL Data Sync-tjänsten.
Hur gör jag för att dra tillbaka en klientagent?
Om du omedelbart vill ogiltigförklara eller dra tillbaka en agent återskapar du dess nyckel i portalen men skickar den inte i agentgränssnittet. Om du återskapar en nyckel ogiltigförklaras den tidigare nyckeln oavsett om motsvarande agent är online eller offline.
Hur flyttar jag en klientagent till en annan dator
Om du vill köra den lokala agenten från en annan dator än den är för närvarande och återanvända samma agent gör du följande:
- Installera agenten på önskad dator.
- Logga in på SQL Data Sync-portalen och återskapa en agentnyckel för den befintliga agenten.
- Använd den nya agentens användargränssnitt för att skicka agentnyckeln.
- Vänta medan klientagenten hämtar listan över lokala databaser som registrerades tidigare.
- Ange databasautentiseringsuppgifter för alla databaser som visas som oåtkomliga. Dessa databaser måste kunna nås från den nya datorn där agenten är installerad.
Hur tar jag bort databasen för synkroniseringsmetadata om synkroniseringsagenten fortfarande är associerad med den
Om du vill ta bort en synkroniseringsmetadatadatabas som har en synkroniseringsagent associerad med den måste du först ta bort synkroniseringsagenten. Gör följande för att ta bort agenten:
- Välj synkroniseringsdatabasen.
- Gå till sidan Synkronisera till andra databaser .
- Välj synkroniseringsagenten och välj Ta bort.
Felsöka problem med Data Sync Agent
Installation, avinstallation eller reparation av klientagenten misslyckas
Klientagenten fungerar inte när jag har avbrutit avinstallationen
Lokal synkroniseringsagentapp kan inte ansluta till den lokala synkroniseringstjänsten
Klientagentens installation, avinstallation eller reparation misslyckas
Orsak. Många scenarier kan orsaka det här felet. Titta på loggarna för att fastställa den specifika orsaken till det här felet.
Lösning. Om du vill hitta den specifika orsaken till felet genererar du och tittar på Windows Installer-loggarna. Du kan aktivera loggning i en kommandoprompt. Om den nedladdade installationsfilen till exempel är
SQLDataSyncAgent-2.0-x86-ENU.msigenererar och undersöker du loggfiler med hjälp av följande kommandorader:För installationer:
msiexec.exe /i SQLDataSyncAgent-2.0-x86-ENU.msi /l*v LocalAgentSetup.LogFör avinstallationer:
msiexec.exe /x SQLDataSyncAgent-2.0-x86-ENU.msi /l*v LocalAgentSetup.LogDu kan också aktivera loggning för alla installationer som utförs av Windows Installer. Microsoft-kunskapsbasartikeln Aktivera Windows Installer-loggning innehåller en lösning med ett klick för att aktivera loggning för Windows Installer. Den anger också loggarnas plats.
Klientagenten fungerar inte när jag har avbrutit avinstallationen
Klientagenten fungerar inte, även efter att du har avbrutit avinstallationen.
Orsak. Detta beror på att SQL Data Sync-klientagenten inte lagrar autentiseringsuppgifter.
Lösning. Du kan prova följande två lösningar:
- Använd services.msc för att ange autentiseringsuppgifterna för klientagenten igen.
- Avinstallera den här klientagenten och installera sedan en ny. Ladda ned och installera den senaste klientagenten från Download Center.
Min databas visas inte i agentlistan
När du försöker lägga till en befintlig SQL Server-databas i en synkroniseringsgrupp visas inte databasen i listan över agenter.
Dessa scenarier kan orsaka det här problemet:
Orsak. Klientagenten och synkroniseringsgruppen finns i olika datacenter.
Lösning. Klientagenten och synkroniseringsgruppen måste finnas i samma datacenter. För att konfigurera detta har du två alternativ:
- Skapa en ny agent i datacentret där synkroniseringsgruppen finns. Registrera sedan databasen med agenten.
- Ta bort den aktuella synkroniseringsgruppen. Skapa sedan om synkroniseringsgruppen i det datacenter där agenten finns.
Orsak. Klientagentens lista över databaser är inte aktuell.
Lösning. Stoppa och starta sedan om klientagenttjänsten.
Den lokala agenten laddar endast ned listan över associerade databaser vid den första överföringen av agentnyckeln. Den laddar inte ned listan över associerade databaser vid efterföljande agentnyckelöverföringar. Databaser som registreras under en agentflytt visas inte i den ursprungliga agentinstansen.
Klientagenten startar inte (fel 1069)
Du upptäcker att agenten inte körs på en dator som är värd för SQL Server. När du försöker starta agenten manuellt visas en dialogruta med meddelandet "Fel 1069: Tjänsten startades inte på grund av ett inloggningsfel".
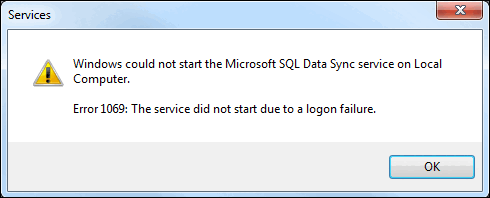
Orsak. En sannolik orsak till det här felet är att lösenordet på den lokala servern har ändrats sedan du skapade agenten och agentlösenordet.
Lösning. Uppdatera agentens lösenord till ditt aktuella serverlösenord:
- Leta upp SQL Data Sync-klientagenttjänsten.
a. Välj start.
b) Ange services.msc i sökrutan.
c. Välj Tjänster bland sökresultaten.
d. I fönstret Tjänster bläddrar du till posten för SQL Data Sync Agent. - Högerklicka på SQL Data Sync Agent och välj Stoppa.
- Högerklicka på SQL Data Sync Agent och välj Egenskaper.
- I Egenskaper för SQL Data Sync Agent väljer du fliken Inloggning.
- I rutan Lösenord anger du ditt lösenord.
- I rutan Bekräfta lösenord anger du lösenordet igen.
- Tryck på Tillämpa och välj sedan OK.
- I fönstret Tjänster högerklickar du på SQL Data Sync Agent-tjänsten och väljer Starta.
- Stäng fönstret Tjänster.
- Leta upp SQL Data Sync-klientagenttjänsten.
Jag kan inte skicka agentnyckeln
När du har skapat eller återskapat en nyckel för en agent försöker du skicka nyckeln via programmet SqlAzureDataSyncAgent. Det går inte att slutföra inlämningen.
Förkunskapskrav. Kontrollera följande förutsättningar innan du fortsätter:
Windows-tjänsten SQL Data Sync körs.
Tjänstkontot för Windows-tjänsten SQL Data Sync har nätverksåtkomst.
Utgående port 1433 är öppen i din lokala brandväggsregel.
Den lokala ip-adressen läggs till i server- eller databasbrandväggsregeln för databasen för synkroniseringsmetadata.
Orsak. Agentnyckeln identifierar varje lokal agent unikt. Nyckeln måste uppfylla två villkor:
- Klientagentnyckeln på SQL Data Sync-servern och den lokala datorn måste vara identiska.
- Klientagentnyckeln kan bara användas en gång.
Lösning. Om agenten inte fungerar beror det på att ett eller båda av dessa villkor inte uppfylls. Så här får du agenten att fungera igen:
- Generera en ny nyckel.
- Applicera den nya nyckeln på agenten.
Så här tillämpar du den nya nyckeln på agenten:
- Gå till installationskatalogen för agenten i Utforskaren. Standardinstallationskatalogen är C:\Program Files (x86)\Microsoft SQL Data Sync.
- Dubbelklicka på underkatalogen bin.
- Öppna programmet SqlAzureDataSyncAgent.
- Välj Skicka agentnyckel.
- I det angivna området, klistra in nyckeln från urklipp.
- Välj OK.
- Stäng programmet.
Klientagenten kan inte tas bort från portalen om dess associerade lokala databas inte kan nås
Om en lokal slutpunkt (dvs. en databas) som är registrerad med en SQL Data Sync-klientagent inte kan nås, kan klientagenten inte tas bort.
Orsak. Det går inte att ta bort den lokala agenten eftersom den oåtkomliga databasen fortfarande är registrerad hos agenten. När du försöker ta bort agenten försöker borttagningsprocessen nå databasen, vilket misslyckas.
Lösning. Använd "force delete" för att ta bort den oåtkomliga databasen.
Anmärkning
Om synkroniseringsmetadatatabeller finns kvar efter en "force delete" använder du deprovisioningutil.exe för att rensa dem.
Appen Lokala Synk-Agenten kan inte ansluta till den lokala synkroniseringstjänsten
Lösning. Prova följande steg:
- Avsluta appen.
- Öppna panelen Komponenttjänster.
a. I sökrutan i aktivitetsfältet anger du services.msc.
b) Dubbelklicka på Tjänster i sökresultaten. - Stoppa SQL Data Sync-tjänsten.
- Starta om SQL Data Sync-tjänsten.
- Öppna appen igen.
Kör datasynkroniseringsagenten från kommandotolken
Du kan köra följande datasynkroniseringsagentkommandon från kommandotolken:
Pinga tjänsten
Användning
SqlDataSyncAgentCommand.exe -action pingsyncservice
Exempel
SqlDataSyncAgentCommand.exe -action "pingsyncservice"
Visa registrerade databaser
Användning
SqlDataSyncAgentCommand.exe -action displayregistereddatabases
Exempel
SqlDataSyncAgentCommand.exe -action "displayregistereddatabases"
Skicka agentnyckeln
Användning
Usage: SqlDataSyncAgentCommand.exe -action submitagentkey -agentkey [agent key] -username [user name] -password [password]
Exempel
SqlDataSyncAgentCommand.exe -action submitagentkey -agentkey [agent key generated from portal, PowerShell, or API] -username [user name to sync metadata database] -password [user name to sync metadata database]
Registrera en databas
Användning
SqlDataSyncAgentCommand.exe -action registerdatabase -servername [on-premisesdatabase server name] -databasename [on-premisesdatabase name] -username [domain\\username] -password [password] -authentication [sql or windows] -encryption [true or false]
Exempel
SqlDataSyncAgentCommand.exe -action "registerdatabase" -serverName localhost -databaseName testdb -authentication sql -username <user name> -password <password> -encryption true
SqlDataSyncAgentCommand.exe -action "registerdatabase" -serverName localhost -databaseName testdb -authentication windows -encryption true
Avregistrera en databas
När du använder det här kommandot för att avregistrera en databas avetableras databasen helt. Om databasen deltar i andra synkroniseringsgrupper bryter den här åtgärden de andra synkroniseringsgrupperna.
Användning
SqlDataSyncAgentCommand.exe -action unregisterdatabase -servername [on-premisesdatabase server name] -databasename [on-premisesdatabase name]
Exempel
SqlDataSyncAgentCommand.exe -action "unregisterdatabase" -serverName localhost -databaseName testdb
Uppdatera autentiseringsuppgifter
Användning
SqlDataSyncAgentCommand.exe -action updatecredential -servername [on-premisesdatabase server name] -databasename [on-premisesdatabase name] -username [domain\\username] -password [password] -authentication [sql or windows] -encryption [true or false]
Exempel
SqlDataSyncAgentCommand.exe -action "updatecredential" -serverName localhost -databaseName testdb -authentication sql -username <user name> -password <password> -encryption true
SqlDataSyncAgentCommand.exe -action "updatecredential" -serverName localhost -databaseName testdb -authentication windows -encryption true
Relaterat innehåll
Mer information om SQL Data Sync finns i följande artiklar:
- Översikt – Synkronisera data över flera molndatabaser och lokala databaser med SQL Data Sync i Azure
- Konfigurera datasynkronisering
- I portalen – Självstudie: Konfigurera SQL Data Sync för att synkronisera data mellan Azure SQL Database och SQL Server
- Med hjälp av PowerShell
- Metodtips – Metodtips för Azure SQL Data Sync
- Övervaka – Övervaka SQL Data Sync med Azure Monitor-loggar
- Felsökning – Felsöka problem med Azure SQL Data Sync