Översikt över affärskontinuitet med Azure SQL Managed Instance
Gäller för:![]() Azure SQL Managed Instance
Azure SQL Managed Instance
Den här artikeln innehåller en översikt över funktionerna för affärskontinuitet och haveriberedskap i Azure SQL Managed Instance och beskriver alternativen och rekommendationerna för återställning från störande händelser som kan leda till dataförlust eller leda till att din instans och ditt program blir otillgängligt. Lär dig vad du ska göra när ett användar- eller programfel påverkar dataintegriteten, en Azure-tillgänglighetszon eller en region har ett avbrott eller om ditt program kräver underhåll.
Översikt
Affärskontinuitet i Azure SQL Managed Instance refererar till de mekanismer, principer och procedurer som gör det möjligt för ditt företag att fortsätta arbeta med avbrott genom att tillhandahålla tillgänglighet, hög tillgänglighet och haveriberedskap.
I de flesta fall hanterar SQL Managed Instance störande händelser som kan inträffa i en molnmiljö och håller dina program och affärsprocesser igång. Det finns dock några störande händelser där åtgärder kan ta lite tid, till exempel:
- Användaren tar av misstag bort eller uppdaterar en rad i en tabell.
- Den skadliga angriparen tar bort data eller tar bort en databas.
- Katastrofala naturkatastrofer drabbar ett datacenter, en tillgänglighetszon eller en region.
- Sällsynta datacenter, tillgänglighetszoner eller regionomfattande avbrott som orsakas av en konfigurationsändring, programvarufel eller maskinvarukomponentfel.
Tillgänglighet
Azure SQL Managed Instance levereras med ett kärnåterhämtnings- och tillförlitlighetslöfte som skyddar den mot programvaru- eller maskinvarufel. Databassäkerhetskopior automatiseras för att skydda dina data från skador eller oavsiktlig borttagning. Som paaS (Platform-as-a-service) tillhandahåller Tjänsten Azure SQL Managed Instance tillgänglighet som en off-the-shelf-funktion med ett branschledande serviceavtal för tillgänglighet på 99,99 %.
Hög tillgänglighet
För att uppnå hög tillgänglighet i Azure-molnmiljön aktiverar du zonredundans så att instansen använder tillgänglighetszoner för att säkerställa motståndskraft mot zonfel. Många Azure-regioner tillhandahåller tillgänglighetszoner, som är avgränsade grupper av datacenter i en region som har oberoende infrastruktur för ström, kylning och nätverk. Tillgänglighetszoner är utformade för att tillhandahålla regionala tjänster, kapacitet och hög tillgänglighet i de återstående zonerna om en zon drabbas av ett avbrott. Genom att aktivera zonredundans är instansen motståndskraftig mot zonindelade maskinvaru- och programvarufel och återställningen är transparent för program. När hög tillgänglighet är aktiverad kan Azure SQL Managed Instance-tjänsten tillhandahålla ett serviceavtal med högre tillgänglighet på 99,995 %.
Haveriberedskap
För att uppnå högre tillgänglighet och redundans mellan regioner kan du aktivera funktioner för haveriberedskap för att snabbt återställa instansen från ett katastrofalt regionalt fel. Alternativ för haveriberedskap med Azure SQL Managed Instance är:
- Redundansgrupper möjliggör kontinuerlig synkronisering mellan en primär och sekundär instans. Redundansgrupper tillhandahåller skrivskyddade och skrivskyddade lyssnarslutpunkter som förblir oförändrade, så det är inte nödvändigt att uppdatera program anslutningssträng efter redundansväxling.
- Med geo-återställning kan du återställa från ett regionalt avbrott genom att återställa från geo-replikerade säkerhetskopior när du inte kan komma åt databasen i den primära regionen genom att skapa en ny databas på en befintlig instans i någon Azure-region.
Funktioner som ger affärskontinuitet
Det finns till exempel fyra stora potentiella avbrottsscenarier. I följande tabell visas funktioner för affärskontinuitet i SQL Managed Instance som du kan använda för att minimera ett potentiellt scenario med affärsstörningar:
| Scenario för avbrott i verksamheten | Funktion för affärskontinuitet |
|---|---|
| Lokala maskinvaru- eller programvarufel som påverkar databasnoden. | För att minska lokala maskinvaru- och programvarufel innehåller SQL Managed Instance en tillgänglighetsarkitektur som garanterar automatisk återställning från dessa fel med upp till 99,99 % tillgänglighets-SLA. |
| Skadade eller borttagna data orsakas vanligtvis av ett programfel eller ett mänskligt fel. Sådana fel är programspecifika och kan vanligtvis inte identifieras av tjänsten. | För att skydda ditt företag mot dataförlust skapar SQL Managed Instance automatiskt fullständiga databassäkerhetskopior varje vecka, differentiella databassäkerhetskopieringar var 12:e eller 24:e timme och säkerhetskopieringar av transaktionsloggar var 5–10:e minut. Som standard lagras säkerhetskopior i geo-redundant lagring i sju dagar och stöder en konfigurerbar kvarhållningsperiod för säkerhetskopiering för återställning till tidpunkt på upp till 35 dagar. Du kan återställa en borttagen databas till den punkt då den togs bort om instansen inte har tagits bort eller om du har konfigurerat långsiktig kvarhållning. |
| Sällsynt avbrott i datacenter eller tillgänglighetszoner, möjligen orsakat av en naturkatastrofhändelse, konfigurationsändring, programvarufel eller maskinvarukomponentfel. | För att minska avbrott på datacenter- eller tillgänglighetsnivå aktiverar du zonredundans för SQL Managed Instance för att använda Azure Tillgänglighetszoner och tillhandahålla redundans i flera fysiska zoner i en Azure-region. Aktivering av zonredundans säkerställer att den hanterade instansen är motståndskraftig mot zonfel med upp till 99,995 % serviceavtal med hög tillgänglighet. |
| Sällsynta regionstopp som påverkar alla tillgänglighetszoner och de datacenter som består av den, vilket kan orsakas av katastrofala naturkatastrofer. | Om du vill minimera ett regionomfattande avbrott aktiverar du haveriberedskap med något av alternativen: – Kontinuerlig datasynkronisering med redundansgrupper till repliker i en sekundär region som används för redundans. – Ställa in redundans för lagring av säkerhetskopiering till geo-redundant lagring för säkerhetskopiering så att geo-återställning används. |
Mål för återställningstid och återställningspunkter (RTO och RPO)
När du utvecklar din affärskontinuitetsplan ska du förstå den maximala godkända tiden innan programmet återställs helt efter den störande händelsen. Den tid som krävs för att ett program ska återställas helt kallas för mål för återställningstid (RTO). Förstå också den maximala perioden för de senaste datauppdateringarna (tidsintervall) som programmet kan tolerera att förlora när det återställs från en oplanerad störande händelse. Den potentiella dataförlusten kallas mål för återställningspunkt (RPO).
I följande tabell jämförs RPO och RTO för varje alternativ för affärskontinuitet:
| Alternativ för affärskontinuitet | RTO (stilleståndstid) | RPO (dataförlust) |
|---|---|---|
| Hög tillgänglighet (aktivera zonredundans) |
Vanligtvis mindre än 30 sekunder | 0 |
| Haveriberedskap (aktivera redundansgrupper) |
1 timme | 5 sekunder (beror på dataändringar före den störande händelsen som inte har replikerats) |
| Haveriberedskap (med geo-återställning) |
12 timmar | 1 timme |
Återställa en databas inom samma Azure-region
Du kan använda automatiska databassäkerhetskopior för att återställa en databas till en tidpunkt tidigare. På så sätt kan du återställa från skadade data som orsakas av mänskliga fel. Med återställning till tidpunkt (PITR) kan du skapa en ny databas till samma instans, eller en annan instans, som representerar tillståndet för data före den skadade händelsen. Återställningsåtgärden är en storlek på dataåtgärden som också beror på målinstansens aktuella arbetsbelastning. Det kan ta längre tid att återställa en mycket stor eller mycket aktiv databas. Mer information om återställningstid finns i databasens återställningstid.
Om den maximala kvarhållningsperioden för säkerhetskopiering som stöds för återställning till tidpunkt (PITR) inte är tillräcklig för ditt program, kan du utöka den genom att konfigurera en princip för långsiktig kvarhållning (LTR) för databaserna. Mer information finns i Långsiktig kvarhållning av säkerhetskopior.
Återställa en databas till en befintlig instans
Även om det är ovanligt kan ett Azure-datacenter ha ett avbrott. När ett avbrott uppstår orsakar det ett verksamhetsavbrott som kan vara några få minuter eller flera timmar.
- Ett alternativ är att vänta tills instansen är online igen när datacentrets avbrott är över. Detta fungerar för program som har råd att ha sin databas offline. Till exempel ett utvecklingsprojekt eller en kostnadsfri utvärderingsversion som du inte behöver arbeta med hela tiden. När ett datacenter har ett avbrott vet du inte hur länge avbrottet kan pågå, så det här alternativet fungerar bara om du inte behöver databasen på ett tag.
- Om du använder geo-redundant lagring (GRS) eller geo-zonredundant lagring (GZRS) är ett annat alternativ att återställa en databas till alla SQL-hanterade instanser i valfri Azure-region med geo-redundanta databassäkerhetskopior (geo-återställning). Geo-återställning använder en geo-redundant säkerhetskopia som källa och kan användas för att återställa en databas till den senaste tillgängliga tidpunkten, även om databasen eller datacentret är otillgängligt på grund av ett avbrott. Den tillgängliga säkerhetskopieringen finns i den kopplade regionen.
- Slutligen kan du snabbt återställa från ett avbrott om du har konfigurerat en geo-sekundär med hjälp av en redundansgrupp för din instans med antingen kund (rekommenderas) eller Microsoft-hanterad redundansväxling. Även om själva redundansväxlingen bara tar några sekunder tar det minst 1 timme för tjänsten att aktivera en Microsoft-hanterad geo-redundans, om den är konfigurerad. Detta är nödvändigt för att säkerställa att redundansväxlingen motiveras av driftstoppets omfattning. Redundansväxlingen kan också leda till förlust av nyligen ändrade data på grund av typen av asynkron replikering mellan de kopplade regionerna.
När du utvecklar din affärskontinuitetsplan är det viktigt att du känner till den längsta godkända tiden innan programmet är helt återställt efter en avbrottshändelse. Den tid som krävs för att programmet ska återställas helt kallas för mål för återställningstid (RTO). Du måste också förstå den maximala perioden för de senaste datauppdateringarna (tidsintervall) som programmet kan tolerera att förlora när det återställs från en oplanerad störande händelse. Den potentiella dataförlusten kallas mål för återställningspunkt (RPO).
Olika återställningsmetoder erbjuder olika nivåer av RPO och RTO. Du kan välja en specifik återställningsmetod eller använda en kombination av metoder för att uppnå fullständig programåterställning.
Använd redundansgrupper om ditt program uppfyller något av följande kriterier:
- Är verksamhetskritiskt.
- Har ett serviceavtal (SLA) som inte tillåter 12 timmar eller mer stilleståndstid.
- Stilleståndstid kan leda till ekonomisk skuld.
- Har en hög dataändringshastighet och 1 timmes dataförlust är inte acceptabelt.
- Den extra kostnaden för aktiv geo-replikering är lägre än de potentiella ekonomiska skyldigheterna och den associerade affärsförlusten.
Du kan välja att använda en kombination av databassäkerhetskopior och redundansgrupper beroende på dina programkrav.
Följande avsnitt innehåller en översikt över stegen för att återställa med hjälp av antingen databassäkerhetskopior eller redundansgrupper.
Förbereda för ett avbrott
Oavsett vilken funktion för affärskontinuitet du använder, måste du:
- Identifiera och förbereda målinstansen, inklusive nätverks-IP-brandväggsregler, inloggningar och
masterbehörigheter på databasnivå. - Fastställ hur du omdirigerar klienter och klientprogram till den nya instansen
- Dokumentera andra beroenden, till exempel granskningsinställningar och aviseringar.
Om du inte förbereder dig korrekt tar det längre tid att ansluta dina program efter en redundansväxling eller databasåterställning, och kräver förmodligen även felsökning i en tid av stress – en dålig kombination.
Redundansvämna till en geo-replikerad sekundär instans
Om du använder redundansgrupper som återställningsmekanism kan du konfigurera en automatisk redundansprincip. När redundansväxlingen har initierats blir den sekundära instansen den nya primära, redo att registrera nya transaktioner och svara på frågor – med minimal dataförlust för data som ännu inte replikerats.
Kommentar
När datacentret kommer tillbaka online återansluter den gamla primära automatiskt till den nya primära för att bli den sekundära instansen. Om du behöver flytta tillbaka den primära till den ursprungliga regionen kan du initiera en planerad redundansväxling manuellt (återställning efter fel).
Utföra en geo-återställning
Om du använder automatiserade säkerhetskopior med geo-redundant lagring (standardlagringsalternativet när du skapar din instans) kan du återställa databasen med hjälp av geo-återställning. Återställning sker vanligtvis inom 12 timmar – med dataförlust på upp till en timme som bestäms av när den senaste loggsäkerhetskopian togs och replikerades. Databasen kan inte registrera några transaktioner eller svara på frågor förrän återställningen har slutförts. Observera att geo-återställning endast återställer databasen till den senaste tillgängliga tidpunkten.
Kommentar
Om datacentret är online igen innan du växlar över ditt program till den återställda databasen kan du avbryta återställningen.
Utföra åtgärder efter en redundansväxling eller återställning
Efter återställningen från endera återställningsmetod måste du utföra följande ytterligare uppgifter innan dina användare och program kan komma igång igen:
- Omdirigera klienter och klientprogram till den nya instansen och den återställda databasen.
- Se till att det finns lämpliga ip-brandväggsregler för nätverket för användare att ansluta.
- Se till att lämpliga inloggningar och
masterbehörigheter på databasnivå finns på plats (eller använd inneslutna användare). - Konfigurera granskning efter behov.
- Konfigurera aviseringar efter behov.
Kommentar
Om du använder en redundansgrupp och ansluter till instansen med läs-och-skriv-lyssnaren sker omdirigeringen efter redundansväxlingen automatiskt och transparent till programmet.
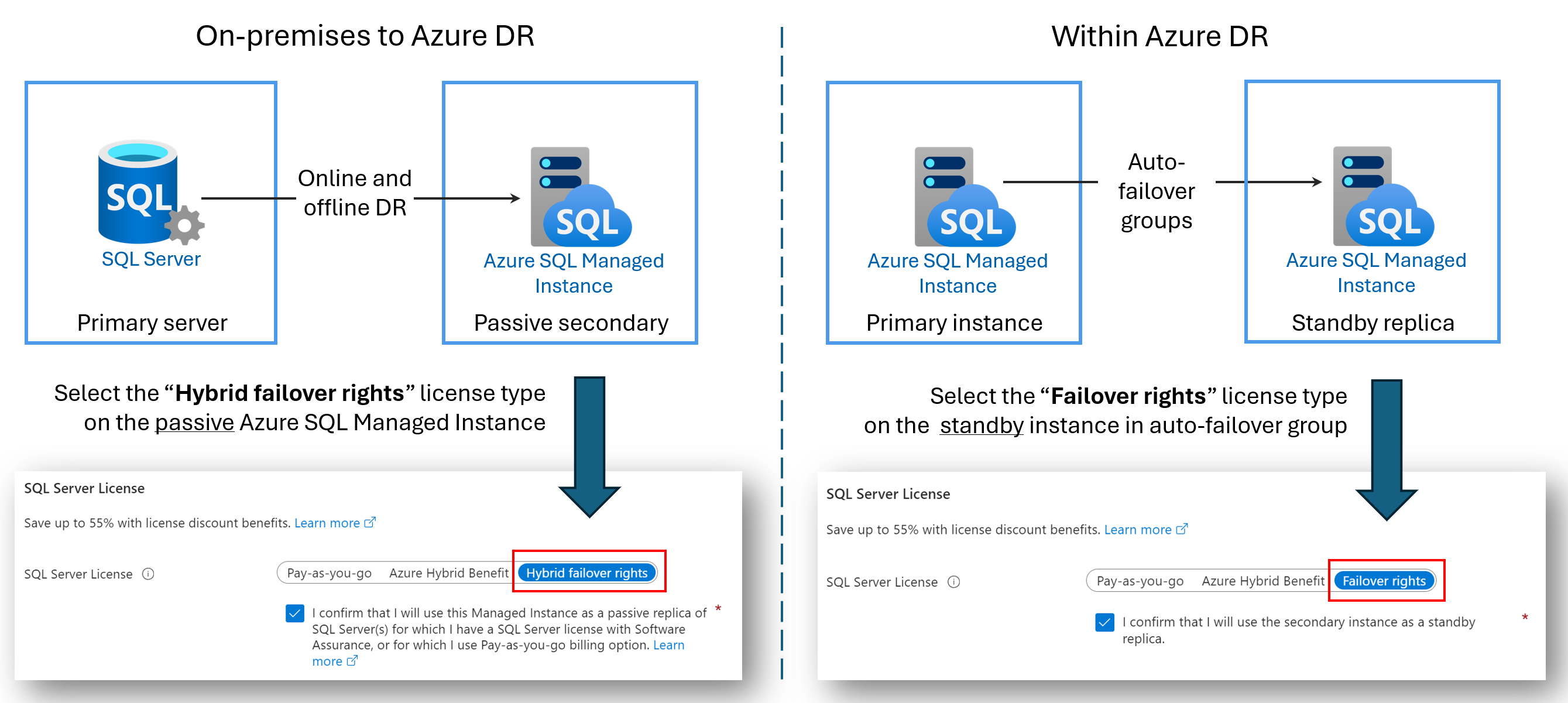
Licensfria DR-repliker
Du kan spara på licenskostnader genom att konfigurera en sekundär Azure SQL Managed Instance för endast haveriberedskap (DR). Den här fördelen är tillgänglig om du använder en redundansgrupp mellan två SQL-hanterade instanser eller om du har konfigurerat en hybridlänk mellan SQL Server och Azure SQL Managed Instance. Så länge den sekundära instansen inte har några läs- eller skrivarbetsbelastningar på den och endast är ett passivt DR-vänteläge debiteras du inte för de licensieringskostnader för virtuella kärnor som används av den sekundära instansen.
När du anger en sekundär instans för endast haveriberedskap och inga läs- eller skrivarbetsbelastningar körs på instansen, ger Microsoft dig det antal virtuella kärnor som är licensierade till den primära instansen utan extra kostnad under redundansrättsförmånen. Du debiteras fortfarande för den beräkning och lagring som den sekundära instansen använder. Exakta villkor för hybrid redundansrättsförmånen finns i SQL Server-licensvillkoren online i avsnittet "SQL Server – Redundansrättigheter" .
Namnet på förmånen beror på ditt scenario:
- Hybridredundansrättigheter för en passiv replik: När du konfigurerar en länk mellan SQL Server och Azure SQL Managed Instance kan du använda hybrid redundansrättsförmånen för att spara på licensieringskostnader för virtuella kärnor för den passiva sekundära repliken.
- Redundansrättigheter för en väntelägesreplik: När du konfigurerar en redundansgrupp mellan två hanterade instanser kan du använda rättighetsförmånen redundans för att spara på licensieringskostnader för virtuella kärnor för den sekundära reservrepliken.
Följande diagram visar fördelarna för varje scenario:
Nästa steg
Mer information om funktioner för affärskontinuitet finns i Automatiserade säkerhetskopieringar och redundansgrupper. I händelse av en katastrof kan du läsa återställa en databas.