Hantera filutrymme för databaser i Azure SQL Managed Instance
Gäller för:![]() Azure SQL Managed Instance
Azure SQL Managed Instance
Den här artikeln beskriver hur du övervakar och hanterar filer i databaser i Azure SQL Managed Instance. Vi granskar hur du övervakar databasens filstorlek, krymper transaktionsloggen, förstorar en transaktionsloggfil och kontrollerar tillväxten av en transaktionsloggfil.
Den här artikeln gäller för Azure SQL Managed Instance. Information om hur du hanterar storleken på transaktionsloggfiler i SQL Server finns i Hantera storleken på transaktionsloggfilen.
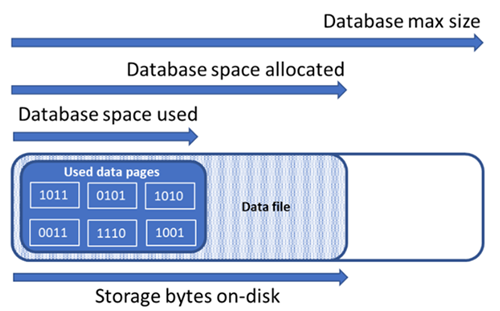
Förstå typer av lagringsutrymme för en databas
Det är viktigt att förstå följande lagringsutrymmeskvantiteter för att hantera filutrymmet i en databas.
| Databaskvantitet | Definition | Kommentarer |
|---|---|---|
| Datautrymme som används | Mängden utrymme som används för att lagra databasdata. | I allmänhet ökar utrymmet som används (minskar) vid infogningar (borttagningar). I vissa fall ändras inte det utrymme som används vid infogningar eller borttagningar beroende på mängden och mönstret för data som ingår i åtgärden och eventuell fragmentering. Om en rad tas bort från alla datasidor minskar till exempel inte nödvändigtvis utrymmet som används. |
| Allokerat datautrymme | Mängden formaterat filutrymme som görs tillgängligt för lagring av databasdata. | Mängden allokerat utrymme växer automatiskt, men minskar aldrig efter borttagningar. Det här beteendet säkerställer att framtida infogningar går snabbare eftersom utrymmet inte behöver formateras om. |
| Allokerat datautrymme men oanvänt | Skillnaden mellan mängden datautrymme som har allokerats och mängden datautrymme som används. | Den här kvantiteten representerar den maximala mängden ledigt utrymme som kan frigöras genom krympande databasdatafiler. |
| Maximal datastorlek | Den maximala mängden utrymme som kan användas för att lagra databasdata. | Mängden allokerat datautrymme kan inte bli större än den maximala datastorleken. |
Följande diagram illustrerar relationen mellan de olika typerna av lagringsutrymme för en databas.
Fråga en enskild databas om information om filutrymme
Använd följande fråga på sys.database_files för att returnera mängden allokerat databasfilutrymme och mängden oanvänt utrymme som allokerats. Enheter i frågeresultatet är i MB.
-- Connect to a user database
SELECT file_id, type_desc,
CAST(FILEPROPERTY(name, 'SpaceUsed') AS decimal(19,4)) * 8 / 1024. AS space_used_mb,
CAST(size/128.0 - CAST(FILEPROPERTY(name, 'SpaceUsed') AS int)/128.0 AS decimal(19,4)) AS space_unused_mb,
CAST(size AS decimal(19,4)) * 8 / 1024. AS space_allocated_mb,
CAST(max_size AS decimal(19,4)) * 8 / 1024. AS max_size_mb
FROM sys.database_files;
Övervaka användning av loggutrymme
Övervaka användningen av loggutrymme med hjälp av sys.dm_db_log_space_usage. Denna DMV returnerar information om mängden loggutrymme som används för närvarande och anger när transaktionsloggen behöver trunkeras.
Du kan också använda kolumnerna size, max_sizeoch för loggfilen i sys.database_files om du vill ha information om den aktuella loggfilens storlek, maximal storlek och growth autogrow-alternativet för filen.
Mått för lagringsutrymme som visas i API:erna för Azure Resource Manager-baserade mått mäter endast storleken på använda datasidor. Exempel finns i PowerShell-get-metrics.
Storlek på krympningsloggfil
Om du vill minska den fysiska storleken på en fysisk loggfil genom att ta bort outnyttjat utrymme krymper du loggfilen. En krympning gör bara skillnad när en transaktionsloggfil innehåller outnyttjat utrymme. Om loggfilen är full, troligen på grund av öppna transaktioner, undersöker du vad som hindrar trunkering av transaktionsloggar.
Varning
Krympningsåtgärder bör inte betraktas som en vanlig underhållsåtgärd. Data och loggfiler som växer på grund av regelbundna, återkommande affärsåtgärder kräver inte krympningsåtgärder. Krympkommandon påverkar databasens prestanda när den körs och bör om möjligt köras under perioder med låg användning. Vi rekommenderar inte att du krymper datafilerna om en vanlig programarbetsbelastning gör att filerna växer till samma allokerade storlek igen.
Tänk på den potentiella negativa prestandapåverkan av krympande databasfiler. Mer information finns i Indexunderhåll efter krympning. I sällsynta fall kan krympningsåtgärder påverkas av automatiserade säkerhetskopieringar av databaser. Om det behövs kan du försöka krympa igen.
Innan du krymper transaktionsloggen bör du tänka på Faktorer som kan fördröja loggtrunkeringen. Om lagringsutrymmet krävs igen efter att en logg krympt växer transaktionsloggen igen och genom att göra det inför du prestandaomkostnader under loggtillväxtåtgärder. Mer information finns i Rekommendationer.
Du kan bara krympa en loggfil när databasen är online och minst en virtuell loggfil (VLF) är kostnadsfri. I vissa fall kanske det inte går att krympa loggen förrän efter nästa loggtrunkering.
Faktorer, till exempel en tidskrävande transaktion, kan hålla VLF:er aktiva under en längre period, kan begränsa loggkrympningen eller till och med förhindra att loggen krymper alls. Mer information finns i Faktorer som kan fördröja loggtrunkering.
Om du krymper en loggfil tas en eller flera VLF:er bort som inte innehåller någon del av den logiska loggen (dvs . inaktiva VLF:er). När du krymper en transaktionsloggfil tas inaktiva VLFs bort från slutet av loggfilen för att minska loggen till ungefär målstorleken.
Mer information om krympningsåtgärder finns i följande:
Krympa en loggfil (utan att krympa databasfiler)
Övervaka krympningshändelser för loggfiler
- Loggfilens händelseklass för automatisk krympning.
Övervaka loggutrymme
sys.database_files (Transact-SQL) (Se kolumnerna
size,max_sizeochgrowthför loggfilen eller filerna.)
Indexunderhåll efter krympning
När en krympningsåtgärd har slutförts mot datafiler kan index bli fragmenterade. Detta minskar deras prestandaoptimeringseffektivitet för vissa arbetsbelastningar, till exempel frågor som använder stora genomsökningar. Om prestandaförsämringen inträffar när krympningsåtgärden är klar bör du överväga indexunderhåll för att återskapa index. Tänk på att ombyggnad av index kräver ledigt utrymme i databasen, och därför kan det allokerade utrymmet öka, vilket motverkar effekten av krympning.
Mer information om indexunderhåll finns i Optimera indexunderhåll för att förbättra frågeprestanda och minska resursförbrukningen.
Utvärdera indexsidans densitet
Om trunkering av datafiler inte resulterade i en tillräcklig minskning av allokerat utrymme kan du välja att krympa databasdatafiler för att frigöra oanvänt utrymme från dessa filer. Men som ett valfritt men rekommenderat steg bör du först bestämma genomsnittlig sidtäthet för index i databasen. För samma mängd data slutförs krympningen snabbare om sidtätheten är hög, eftersom den måste flytta färre sidor. Om sidtätheten är låg för vissa index bör du överväga att utföra underhåll på dessa index för att öka sidtätheten innan datafilerna krymps. Detta gör också att krympning kan minska det allokerade lagringsutrymmet djupare.
Använd följande fråga för att fastställa siddensitet för alla index i databasen. Siddensitet rapporteras i avg_page_space_used_in_percent kolumnen.
SELECT OBJECT_SCHEMA_NAME(ips.object_id) AS schema_name,
OBJECT_NAME(ips.object_id) AS object_name,
i.name AS index_name,
i.type_desc AS index_type,
ips.avg_page_space_used_in_percent,
ips.avg_fragmentation_in_percent,
ips.page_count,
ips.alloc_unit_type_desc,
ips.ghost_record_count
FROM sys.dm_db_index_physical_stats(DB_ID(), default, default, default, 'SAMPLED') AS ips
INNER JOIN sys.indexes AS i
ON ips.object_id = i.object_id
AND
ips.index_id = i.index_id
ORDER BY page_count DESC;
Om det finns index med högt sidantal som har en sidtäthet som är lägre än 60–70 %, bör du överväga att återskapa eller omorganisera dessa index innan du krymper datafilerna.
Kommentar
För större databaser kan det ta lång tid (timmar) att slutföra frågan för att fastställa siddensiteten. Dessutom kräver återskapande eller omorganisering av stora index också betydande tids- och resursanvändning. Det finns en kompromiss mellan att spendera extra tid på att öka sidtätheten å ena sidan och minska krympningstiden och uppnå högre utrymmesbesparingar på en annan.
Om det finns flera index med låg sidtäthet kan du återskapa dem parallellt på flera databassessioner för att påskynda processen. Kontrollera dock att du inte närmar dig databasresursgränserna genom att göra det och lämna tillräckligt med resursutrymme för programarbetsbelastningar som kan köras. Övervaka resursförbrukningen (CPU, data-I/O, logg-I/O) i Azure-portalen eller använd vyn sys.dm_db_resource_stats och starta ytterligare parallella återskapanden endast om resursanvändningen för var och en av dessa dimensioner fortfarande är betydligt lägre än 100 %. Om processor-, data-I/O- eller logg-I/O-användningen är 100 %, kan du skala upp databasen för att få fler CPU-kärnor och öka I/O-dataflödet. Detta kan möjliggöra ytterligare parallella återskapanden för att slutföra processen snabbare.
Exempel på återskapningskommando för index
Följande är ett exempelkommando för att återskapa ett index och öka dess siddensitet med hjälp av ALTER INDEX-instruktionen:
ALTER INDEX [index_name] ON [schema_name].[table_name]
REBUILD WITH (FILLFACTOR = 100, MAXDOP = 8,
ONLINE = ON (WAIT_AT_LOW_PRIORITY (MAX_DURATION = 5 MINUTES, ABORT_AFTER_WAIT = NONE)),
RESUMABLE = ON);
Det här kommandot initierar en online- och återupptagningsbar indexåterbyggnad. På så sätt kan samtidiga arbetsbelastningar fortsätta att använda tabellen medan återskapande pågår och du kan återuppta återskapa om den avbryts av någon anledning. Den här typen av återskapande är dock långsammare än en offline-återskapande, vilket blockerar åtkomsten till tabellen. Om inga andra arbetsbelastningar behöver komma åt tabellen under återskapande anger du ONLINE alternativen och RESUMABLE till OFF och tar bort WAIT_AT_LOW_PRIORITY satsen.
Mer information om indexunderhåll finns i Optimera indexunderhåll för att förbättra frågeprestanda och minska resursförbrukningen.
Krymp flera datafiler
Som tidigare nämnts är krympning med dataförflyttning en tidskrävande process. Om databasen har flera datafiler kan du påskynda processen genom att krympa flera datafiler parallellt. Du gör detta genom att öppna flera databassessioner och använda DBCC SHRINKFILE på varje session med ett annat file_id värde. Se till att du har tillräckligt med resursutrymme (CPU, data-I/O, logg-I/O) innan du startar varje nytt parallellt krympningskommando.
Följande exempelkommando krymper datafilen med file_id 4 och försöker minska den allokerade storleken till 52 000 MB genom att flytta sidor i filen:
DBCC SHRINKFILE (4, 52000);
Om du vill minska det allokerade utrymmet för filen så mycket som möjligt kör du -instruktionen utan att ange målstorleken:
DBCC SHRINKFILE (4);
Om en arbetsbelastning körs samtidigt med krympning kan den börja använda lagringsutrymmet som frigörs genom krympning innan krympningen slutförs och trunkerar filen. I det här fallet kan krympning inte minska allokerat utrymme till det angivna målet.
Du kan minimera detta genom att krympa varje fil i mindre steg. Det innebär att du i DBCC SHRINKFILE kommandot anger det mål som är något mindre än det aktuella allokerade utrymmet för filen. Om till exempel allokerat utrymme för fil med file_id 4 är 200 000 MB och du vill minska det till 100 000 MB, kan du först ange målet till 170 000 MB:
DBCC SHRINKFILE (4, 170000);
När det här kommandot har slutförts har den trunkerat filen och minskat dess allokerade storlek till 170 000 MB. Du kan sedan upprepa det här kommandot och först ange målet till 140 000 MB, sedan till 110 000 MB osv., tills filen krymps till önskad storlek. Om kommandot slutförs men filen inte trunkeras använder du mindre steg, till exempel 15 000 MB i stället för 30 000 MB.
Om du vill övervaka krympningsstatus för alla samtidiga krympningssessioner kan du använda följande fråga:
SELECT command,
percent_complete,
status,
wait_resource,
session_id,
wait_type,
blocking_session_id,
cpu_time,
reads,
CAST(((DATEDIFF(s,start_time, GETDATE()))/3600) AS varchar) + ' hour(s), '
+ CAST((DATEDIFF(s,start_time, GETDATE())%3600)/60 AS varchar) + 'min, '
+ CAST((DATEDIFF(s,start_time, GETDATE())%60) AS varchar) + ' sec' AS running_time
FROM sys.dm_exec_requests AS r
LEFT JOIN sys.databases AS d
ON r.database_id = d.database_id
WHERE r.command IN ('DbccSpaceReclaim','DbccFilesCompact','DbccLOBCompact','DBCC');
Kommentar
Krympningsförloppet kan vara icke-linjärt och värdet i percent_complete kolumnen kan förbli praktiskt taget oförändrat under långa tidsperioder, även om krympningen fortfarande pågår.
När krympningen har slutförts för alla datafiler använder du frågan om utrymmesanvändning för att fastställa den resulterande minskningen av allokerad lagringsstorlek. Om det fortfarande finns en stor skillnad mellan använt utrymme och allokerat utrymme kan du återskapa index. Detta kan tillfälligt öka allokerat utrymme ytterligare, men krympande datafiler igen efter återskapande av index bör resultera i en djupare minskning av allokerat utrymme.
Förstora en loggfil
I Azure SQL Managed Instance lägger du till utrymme i en loggfil genom att förstora den befintliga loggfilen (om diskutrymme tillåter det). Det går inte att lägga till en loggfil i databasen. En transaktionsloggfil räcker om inte loggutrymmet håller på att ta slut och diskutrymmet börjar också ta slut på den volym som innehåller loggfilen.
Om du vill förstora loggfilen använder du instruktionens MODIFY FILEALTER DATABASE sats och anger syntaxen SIZE och MAXSIZE . Mer information finns i Alternativ för ALTER DATABASE (Transact-SQL) File och Filegroup.
Mer information finns i Rekommendationer.
Kontrollera transaktionsloggfilens tillväxt
Använd alternativsatsen ALTER DATABASE (Transact-SQL) för att hantera tillväxten av en transaktionsloggfil. Notera följande:
- Om du vill ändra den aktuella filstorleken i KB-, MB-, GB- och TB-enheter använder du alternativet
SIZE. - Om du vill ändra tillväxtökningen använder du alternativet
FILEGROWTH. Värdet 0 anger att automatisk tillväxt är inställd på av och att inget ytterligare utrymme tillåts. - Om du vill styra den maximala storleken på en loggfil i KB-, MB-, GB- och TB-enheter eller för att ange tillväxt till OBEGRÄNSAD använder du
MAXSIZEalternativet .
Rekommendationer
Följande är några allmänna rekommendationer när du arbetar med transaktionsloggfiler:
Den automatiska tillväxtökningen (automatisk ökning) av transaktionsloggen
FILEGROWTH, som anges av alternativet, måste vara tillräckligt stor för att ligga före arbetsbelastningstransaktionernas behov. Ökning av filtillväxt i en loggfil bör vara tillräckligt stor för att undvika frekvent expansion. En bra pekare för att storleksanpassa en transaktionslogg är att övervaka mängden logg som upptas under:- Den tid som krävs för att köra en fullständig säkerhetskopia, eftersom loggsäkerhetskopior inte kan ske förrän den har slutförts.
- Den tid som krävs för de största indexunderhållsåtgärderna.
- Den tid som krävs för att köra den största batchen i en databas.
När du ställer in autogrow för data och loggfiler med alternativet
FILEGROWTHkan det vara att föredra att ange den isizestället förpercentage, för att ge bättre kontroll över tillväxtkvoten, eftersom procentandelen är en ständigt växande mängd.- I Azure SQL Managed Instance kan omedelbar initiering av filer gynna transaktionsloggens tillväxthändelser på upp till 64 MB. Standardökningen för automatisk tillväxt för nya databaser är 64 MB. Händelser som är större än 64 MB kan inte dra nytta av omedelbar filinitiering.
- Vi rekommenderar att du inte anger
FILEGROWTHalternativvärdet över 1 024 MB för transaktionsloggar.
En liten automatisk ökning kan generera för många små VLF:er och kan minska prestanda. Information om hur du fastställer den optimala VLF-distributionen för den aktuella transaktionsloggstorleken för alla databaser i en viss instans och de tillväxtökningar som krävs för att uppnå den nödvändiga storleken finns i det här skriptet för att analysera och åtgärda VLF:er som tillhandahålls av SQL Tiger Team.
Ett stort autogrowth-steg kan orsaka två problem:
- En stor automatisk ökning kan göra att databasen pausas medan det nya utrymmet allokeras, vilket kan orsaka tidsgränser för frågor.
- Ett stort autogrowth-steg kan generera för få och stora VLF:er och kan också påverka prestanda. Information om hur du fastställer den optimala VLF-distributionen för den aktuella transaktionsloggstorleken för alla databaser i en viss instans och de tillväxtökningar som krävs för att uppnå den nödvändiga storleken finns i det här skriptet för att analysera och åtgärda VLF:er som tillhandahålls av SQL Tiger Team.
Även om autogrow är aktiverat kan du få ett meddelande om att transaktionsloggen är full, om den inte kan växa tillräckligt snabbt för att uppfylla behoven i din fråga. Mer information om hur du ändrar tillväxtökningen finns i ALTER DATABASE -fil- och filgruppsalternativ (Transact-SQL).
Loggfiler kan ställas in för att krympa automatiskt. Detta rekommenderas dock inte och auto_shrink-databasegenskapenär inställd på FALSE som standard. Om auto_shrink är inställt på TRUE minskar automatisk krympning endast storleken på en fil när mer än 25 procent av dess utrymme inte används.
- Filen krymps antingen till den storlek där endast 25 procent av filen är outnyttjat utrymme eller till den ursprungliga storleken på filen, beroende på vilket som är större.
- Information om hur du ändrar inställningen för egenskapen auto_shrink finns i Visa eller ändra egenskaperna för en databas och ÄNDRA DATABASUPPSÄTTNINGsalternativ (Transact-SQL).
Nästa steg
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för