Identifiera det talade språket automatiskt med modellen för språkidentifiering
Viktigt!
På grund av azure Media Services-tillbakadragandemeddelandet meddelar Azure AI Video Indexer att funktionsjusteringar för Azure AI Video Indexer har justerats. Mer information om vad detta innebär för ditt Azure AI Video Indexer-konto finns i Ändringar som rör tillbakadragning av Azure Media Service (AMS). Se guiden Förbereda för AMS-pensionering: VI-uppdatering och migrering.
Azure AI Video Indexer stöder automatisk språkidentifiering (LID), vilket är processen att automatiskt identifiera det talade språket från ljudinnehåll. Mediefilen transkriberas på det dominerande identifierade språket.
Se listan över språk som stöds av Azure AI Video Indexer på språk som stöds.
Läs avsnittet Riktlinjer och begränsningar .
Välja automatisk språkidentifiering vid indexering
När du indexerar eller indexerar om en video med hjälp av API:et auto detect väljer du alternativet i parametern sourceLanguage .
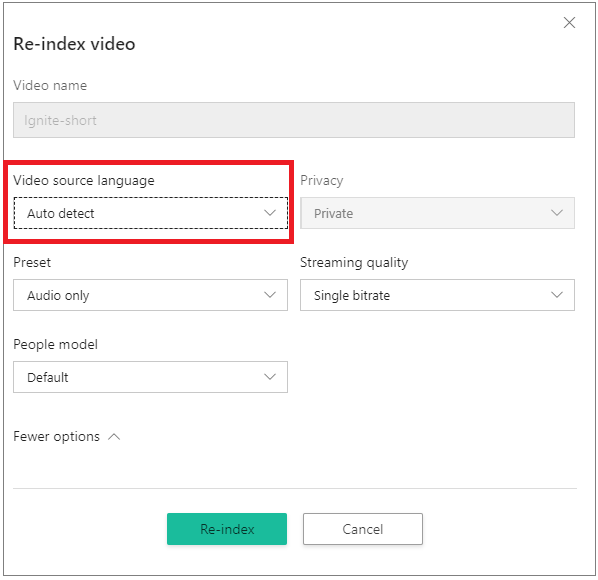
När du använder portalen går du till dina kontovideor på startsidan för Azure AI Video Indexer och hovra över namnet på videon som du vill indexera om. I det högra nedre hörnet väljer du knappen Omindexering . I dialogrutan Omindexering av video väljer du Automatisk identifiering i listrutan Videokällans språk.
Modell-utdata
Azure AI Video Indexer transkriberar videon enligt det mest sannolika språket om konfidensen för det språket är > 0.6. Om språket inte kan identifieras med förtroende förutsätter det att det talade språket är engelska.
Modelldominerande språk är tillgängligt i insights JSON som sourceLanguage attribut (under root/videos/insights). En motsvarande konfidenspoäng är också tillgänglig under attributet sourceLanguageConfidence .
"insights": {
"version": "1.0.0.0",
"duration": "0:05:30.902",
"sourceLanguage": "fr-FR",
"language": "fr-FR",
"transcript": [...],
. . .
"sourceLanguageConfidence": 0.8563
}
Riktlinjer och begränsningar
Automatisk språkidentifiering (LID) stöder följande språk:
Se listan över språk som stöds av Azure AI Video Indexer på språk som stöds.
- Om ljudet innehåller andra språk än listan som stöds är resultatet oväntat.
- Om Azure AI Video Indexer inte kan identifiera språket med tillräckligt hög konfidens (större än 0,6) är reservspråket engelska.
- För närvarande finns det inte stöd för filer med blandat språkljud. Om ljudet innehåller blandade språk är resultatet oväntat.
- Ljud av låg kvalitet kan påverka modellresultatet.
- Modellen kräver minst en minuts tal i ljudet.
- Modellen är utformad för att känna igen ett spontant konversationstal (inte röstkommandon, sång och så vidare).
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för