Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Den här handledningen leder dig genom att skapa och köra en Azure Data Factory-pipeline som kör en Azure Batch-arbetsbelastning. Ett Python-skript körs på Batch-noderna för att hämta kommaavgränsade värdeindata (CSV) från en Azure Blob Storage-container, ändra data och skriva utdata till en annan lagringscontainer. Du använder Batch Explorer för att skapa ett Batch-pool och noder, och Azure Storage Explorer för att hantera lagringsbehållare och filer.
I denna handledning får du lära dig hur du:
- Använd Batch Explorer för att skapa en Batch-pool och noder.
- Använd Storage Explorer för att skapa lagringscontainrar och ladda upp indatafiler.
- Utveckla ett Python-skript för att manipulera indata och skapa utdata.
- Skapa en Data Factory-pipeline som kör Batch-arbetsbelastningen.
- Använd Batch Explorer för att titta på utdata loggfilerna.
Prerequisites
- Ett Azure-konto med en aktiv prenumeration. Om du inte har ett, skapa ett gratis konto.
- Ett Batch-konto med ett länkat Azure Storage-konto. Du kan skapa kontona genom att använda någon av följande metoder: Azure-portalen | Azure CLI | Bicep | ARM-mall | Terraform.
- En Data Factory-instans. För att skapa dataverkstaden, följ instruktionerna i Skapa en dataverkstad.
- Batch Explorer nedladdad och installerad.
- Storage Explorer har laddats ner och installerats.
-
Python 3.8 eller senare, med azure-storage-blob-paketet installerat med hjälp av
pip. - iris.csv-inmatningsdatasetet hämtat från GitHub.
Använd Batch Explorer för att skapa en Batch-pool och noder
Använd Batch Explorer för att skapa en pool av beräkningsnoder för att köra din arbetsbelastning.
Logga in på Batch Explorer med dina Azure-referenser.
Välj ditt Batch-konto.
Välj Pools i vänstra sidofältet och välj sedan + ikonen för att lägga till en pool.
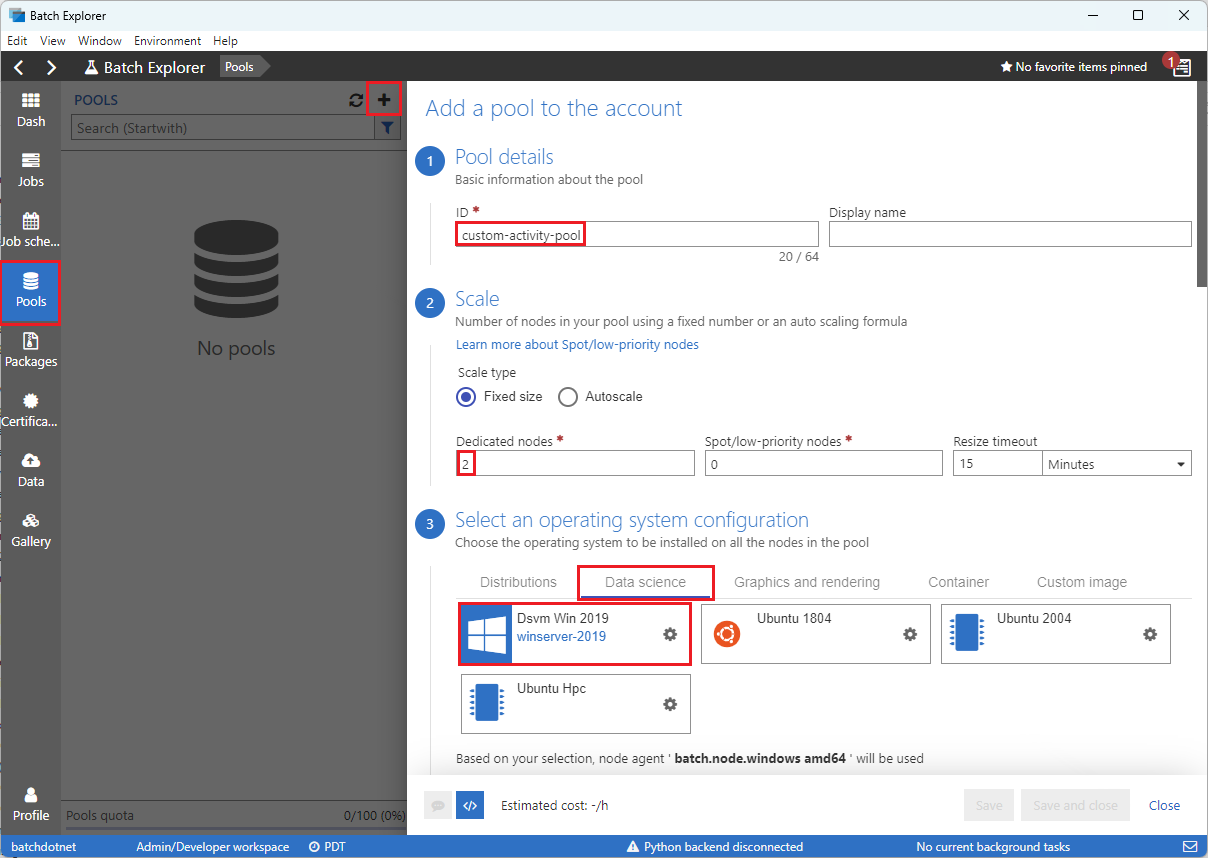
Fyll i formuläret Lägg till en pool till kontot enligt följande:
- Under ID anger du custom-activity-pool.
- Under Dedikerade noder anger du 2.
- För Välj en operativsystemkonfiguration väljer du fliken Datavetenskap och sedan Dsvm Win 2019.
- För Välj en storlek på den virtuella maskinen, välj Standard_F2s_v2.
- För Starta Uppgift, välj Lägg till en startuppgift.
På startuppgiftsskärmen, under Kommandorad, ange
cmd /c "pip install azure-storage-blob pandas"och välj sedan Välj. Det här kommandot installerarazure-storage-blob-paketet på varje nod när den startar upp.
Välj Spara och stäng.

Använd Storage Explorer för att skapa blob-behållare
Använd Storage Explorer för att skapa blob-behållare för att lagra in- och utdatafiler och ladda sedan upp dina indatafiler.
- Logga in på Storage Explorer med dina Azure-autentiseringsuppgifter.
- I den vänstra sidofältet, lokalisera och expandera lagringskontot som är länkat till ditt Batch-konto.
- Högerklicka på Blob Containers, och välj Create Blob Container, eller välj Create Blob Container från Actions längst ned i sidofältet.
- Ange input i inmatningsfältet.
- Skapa en annan blob-behållare med namnet output.
- Välj input-behållaren och välj sedan Upload>Ladda upp filer i den högra panelen.
- På sidan Ladda upp filer, under Valda filer, välj ellipsen ... bredvid inmatningsfältet.
- Bläddra till platsen där din nedladdade iris.csv fil finns, välj Öppna och sedan välj Ladda upp.

Utveckla ett Python-script
Följande Python-skript laddar datasetfilen iris.csv från din Storage Explorer inmatnings-container, manipulerar data och sparar resultaten till utmatnings-containern.
Skriptet måste använda anslutningssträngen för Azure-lagringskontot som är kopplat till ditt Batch-konto. För att få anslutningssträngen:
- I Azure-portalen, sök efter och välj namnet på det lagringskonto som är kopplat till ditt Batch-konto.
- På sidan för lagringskontot, välj Åtkomstnycklar från den vänstra navigeringen under Säkerhet + nätverk.
- Under key1, välj Visa bredvid Anslutningssträng, och klicka sedan på ikonen Kopiera för att kopiera anslutningssträngen.
Klistra in anslutningssträngen i följande skript, och ersätt <storage-account-connection-string> platshållaren. Spara skriptet som en fil med namnet main.py.
Viktigt
Att avslöja kontonycklar i apparens källkod rekommenderas inte för användning i produktion. Du bör begränsa åtkomsten till autentiseringsuppgifter och hänvisa till dem i din kod genom att använda variabler eller en konfigurationsfil. Det är bäst att lagra Batch- och Storage konto-nycklar i Azure Key Vault.
# Load libraries
# from azure.storage.blob import BlobClient
from azure.storage.blob import BlobServiceClient
import pandas as pd
import io
# Define parameters
connectionString = "<storage-account-connection-string>"
containerName = "output"
outputBlobName = "iris_setosa.csv"
# Establish connection with the blob storage account
blob = BlobClient.from_connection_string(conn_str=connectionString, container_name=containerName, blob_name=outputBlobName)
# Initialize the BlobServiceClient (This initializes a connection to the Azure Blob Storage, downloads the content of the 'iris.csv' file, and then loads it into a Pandas DataFrame for further processing.)
blob_service_client = BlobServiceClient.from_connection_string(conn_str=connectionString)
blob_client = blob_service_client.get_blob_client(container_name=containerName, blob_name=outputBlobName)
# Download the blob content
blob_data = blob_client.download_blob().readall()
# Load iris dataset from the task node
# df = pd.read_csv("iris.csv")
df = pd.read_csv(io.BytesIO(blob_data))
# Take a subset of the records
df = df[df['Species'] == "setosa"]
# Save the subset of the iris dataframe locally in the task node
df.to_csv(outputBlobName, index = False)
with open(outputBlobName, "rb") as data:
blob.upload_blob(data, overwrite=True)
För mer information om hur du arbetar med Azure Blob Storage, se Azure Blob Storage-dokumentationen.
Kör skriptet lokalt för att testa och validera funktionaliteten.
python main.py
Skriptet ska skapa en utdatafil med namnet iris_setosa.csv som endast innehåller de dataposter som har Species = setosa. När du har verifierat att det fungerar korrekt, ladda upp skriptfilen main.py till din Storage Explorer input-behållare.
Ställ in en Data Factory-pipeline
Skapa och validera en Data Factory-pipeline som använder ditt Python-skript.
Hämta kontoinformation
Data Factory-pipelinen använder dina Batch- och Storage-kontons namn, kontonyckelvärden och Batch-kontons slutpunkt. För att få denna information från Azure-portalen:
Från Azure-sökrutan, sök efter och välj ditt Batch-kontonnamn.
På sidan Batch-konto väljer du Nycklar i det vänstra navigeringsfältet.
På sidan Nycklar kopierar du följande värden:
- Batchkonto
- Kontoslutpunkt
- Primär åtkomstnyckel
- Lagringskontonamn
- Key1
Skapa och kör pipelinen
Om Azure Data Factory Studio inte redan körs, välj Starta studio på din Data Factory-sida i Azure-portalen.
I Data Factory Studio väljer du pennikonen Författare i det vänstra navigeringsfönstret.
Under Factory Resources, välj ikonen +, och välj sedan Pipeline.
I rutan Egenskaper till höger, ändra namnet på pipelinen till Kör Python.
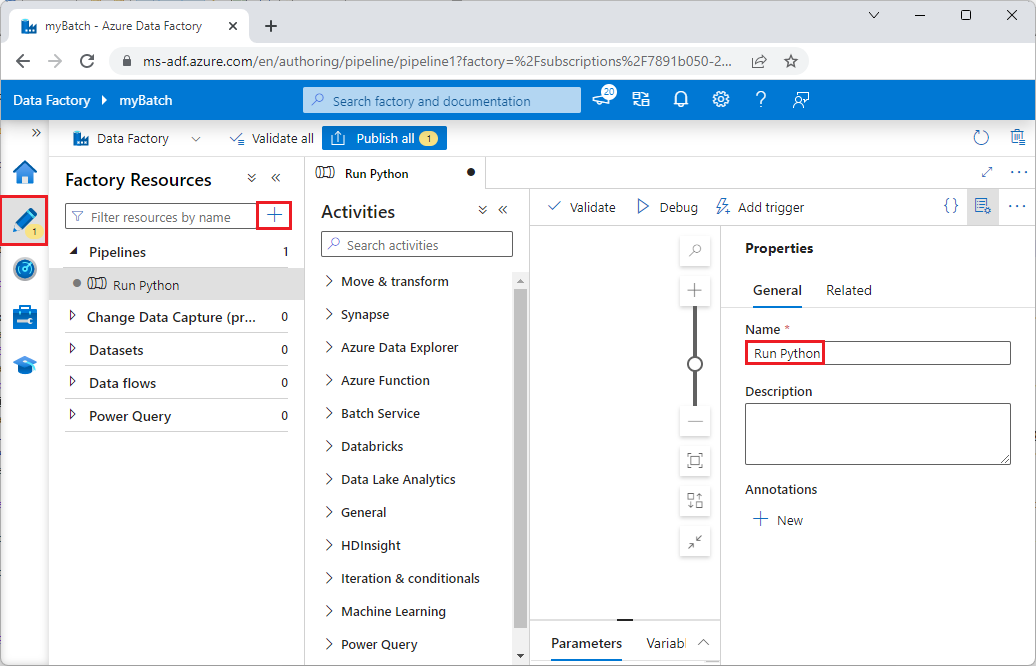
I panelen Aktiviteter, expandera Batch Service, och dra aktiviteten Anpassad till ritytan för rörledningsdesignern.
Nedanför design duken, på Allmänt fliken, ange testPipeline under Namn.
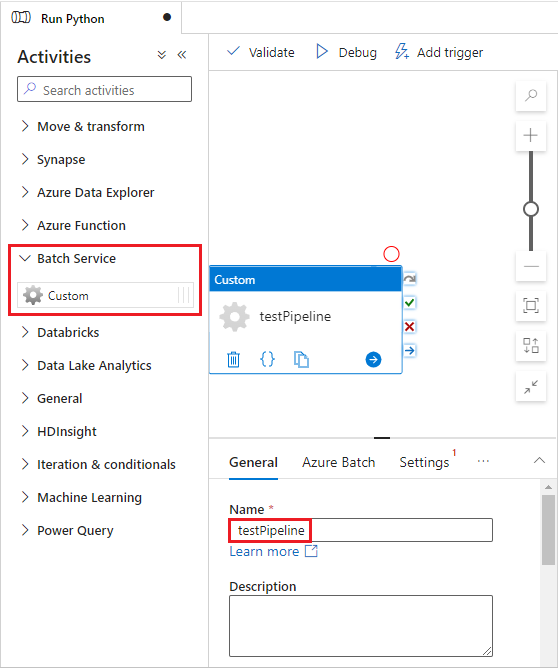
Välj fliken Azure Batch och välj sedan Nytt.
Fyll i formuläret Ny länkad tjänst enligt följande:
- Namn: Ange ett namn för den länkade tjänsten, till exempel AzureBatch1.
- Åtkomstnyckel: Ange den primära åtkomstnyckel som du kopierade från ditt Batch-konto.
- Kontonamn: Ange ditt Batch-kontonamn.
-
Batch-URL: Ange det kontoändpunkt du kopierade från ditt Batch-konto, till exempel
https://batchdotnet.eastus.batch.azure.com. - Poolnamn: Ange custom-activity-pool, den pool du skapade i Batch Explorer.
- Lagringskontots länkade tjänstnamn: Välj Nytt. På nästa skärm, ange ett Namn för den länkade lagringstjänsten, till exempel AzureBlobStorage1, välj din Azure-prenumeration och länkade lagringskonto, och välj sedan Skapa.
Längst ner på skärmen för Batch Ny länkad tjänst, välj Testa anslutning. När anslutningen är lyckad, välj Skapa.
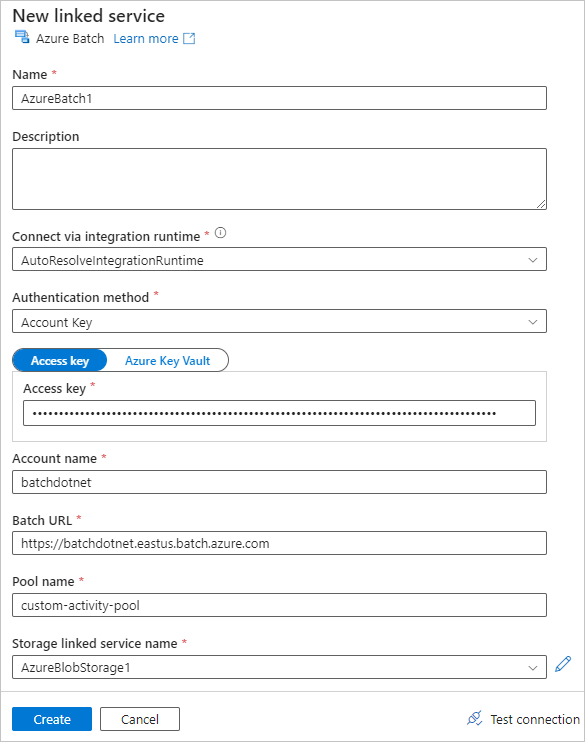
Välj fliken Inställningar och ange eller välj följande inställningar:
-
Command: Ange
cmd /C python main.py. - Resursansluten tjänst: Välj den anslutna lagringstjänsten du skapade, såsom AzureBlobStorage1, och testa anslutningen för att säkerställa att den är lyckad.
- Mappsökväg: Välj mappikonen och välj sedan inmatningsbehållaren och välj OK. Filerna från den här mappen laddas ner från containern till poolnoderna innan Python-skriptet körs.
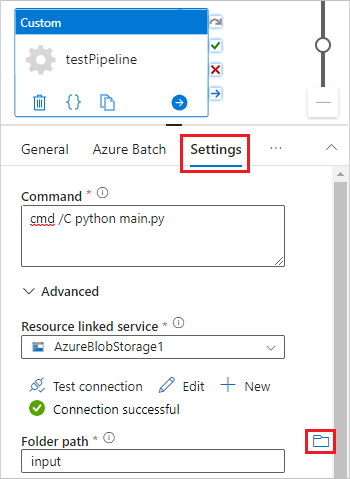
-
Command: Ange
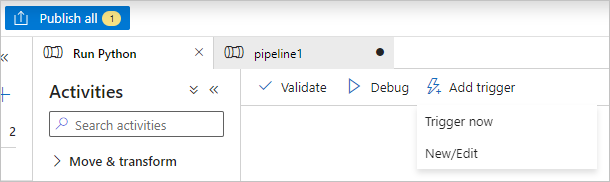
Välj Validera på verktygsfältet för pipeline för att validera pipelinen.
Välj Debug för att testa pipelinen och säkerställa att den fungerar korrekt.
Välj Publicera alla för att publicera pipelinen.
Välj Lägg till trigger, och välj sedan Trigga nu för att köra pipelinen, eller Ny/Redigera för att schemalägga den.

Använd Batch Explorer för att visa loggfiler
Om körning av din pipeline genererar varningar eller fel kan du använda Batch Explorer för att titta på stdout.txt och stderr.txt utdatafilerna för mer information.
- I Batch Explorer väljer du Jobb från sidofältet till vänster.
- Välj adfv2-custom-activity-pool-jobbet.
- Välj en uppgift som hade en felaktig utgångskod.
- Visa filerna stdout.txt och stderr.txt för att undersöka och diagnostisera problemet.
Rensa resurser
Batchkonton, jobb och uppgifter är gratis, men beräkningsnoder medför kostnader även när de inte kör jobb. Det är bäst att allokera nodpooler endast vid behov, och ta bort poolerna när du är klar med dem. Att ta bort pooler tar bort alla uppgiftsresultat på noderna, samt noderna själva.
Inmatnings- och utmatningsfiler förblir i lagringskontot och kan medföra kostnader. När du inte längre behöver filerna kan du ta bort filerna eller behållarna. När du inte längre behöver ditt Batch-konto eller det kopplade lagringskontot kan du ta bort dem.
Nästa steg
I den här självstudien får du lära dig att använda ett Python-skript med Batch Explorer, Storage Explorer samt Data Factory för att köra en Batch-arbetsbelastning. Mer information om Data Factory finns i Vad är Azure Data Factory?