Anteckning
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Datakvalitet är en hanteringsfunktion för analys i molnskala. Den finns i landningszonen för datahantering och är en viktig del av styrningen.
Överväganden för datakvalitet
Datakvalitet är ansvaret för varje individ som skapar och använder dataprodukter. Skapare bör följa globala regler och domänregler, medan konsumenter bör rapportera inkonsekvenser av data till den ägande datadomänen via en feedbackloop.
Eftersom datakvaliteten påverkar alla data som tillhandahålls till tavlan bör den börja överst i organisationen. Styrelsen bör ha insikter om kvaliteten på de data som tillhandahålls till dem.
Om du är proaktiv måste du dock ha experter på datakvalitet som kan rensa bucketar med data som kräver reparation. Undvik att skicka det här arbetet till ett centralt team och rikta istället in sig på datadomänen med specifik datakunskap för att rengöra data.
Datakvalitetsmått
Datakvalitetsmått är nyckeln till att utvärdera och öka kvaliteten på dina dataprodukter. På global nivå och domännivå måste du bestämma dina kvalitetsmått. Vi rekommenderar minst följande mått:
| Mått | Måttdefinitioner |
|---|---|
| Completeness = % total av icke-nulls + nonblanks | Mäter datatillgänglighet, fält i datauppsättningen som inte är tomma och standardvärden som har ändrats. Om en post till exempel innehåller 01/01/1900 som födelsedatum är det mycket troligt att fältet aldrig fylldes i. |
| Unikhet = % av icke-övergivna värden | Mäter distinkta värden i en viss kolumn jämfört med antalet rader i tabellen. Med tanke på fyra distinkta färgvärden (röd, blå, gul och grön) i en tabell med fem rader är fältet till exempel 80 % (eller 4/5) unikt. |
| Konsekvens = % av data som har mönster | Mäter kompatibiliteten i en viss kolumn till dess förväntade datatyp eller format. Till exempel ett e-postfält som innehåller formaterade e-postadresser eller ett namnfält med numeriska värden. |
| Giltighet = % referensmatchning | Mäter lyckad datamatchning till domänreferensuppsättningen. Med tanke på ett land/region-fält (som uppfyller taxonomivärden) i ett transaktionsregistersystem är värdet för "US of A" inte giltigt. |
| Precision = % av oförändrade värden | Mäter lyckad reproduktion av de avsedda värdena i flera system. Om en faktura till exempel specificerar en SKU och ett utökat pris som skiljer sig från den ursprungliga ordern är fakturaradsobjektet felaktigt. |
| Länkning = % av välintegrerade data | Mäter lyckad association till dess tillhörande referensinformation i ett annat system. Om en faktura till exempel specificerar en felaktig SKU eller produktbeskrivning kan fakturaradsobjektet inte länkas. |
Dataprofilering
Dataprofilering undersöker dataprodukter som är registrerade i datakatalogen och samlar in statistik och information om dessa data. Om du vill tillhandahålla sammanfattnings- och trendvyer om datakvaliteten över tid lagrar du dessa data i metadatalagringsplatsen mot dataprodukten.
Dataprofiler hjälper användarna att svara på frågor om dataprodukter, inklusive:
- Kan den användas för att lösa mitt affärsproblem?
- Överensstämmer data med vissa standarder eller mönster?
- Vilka är några av avvikelserna i datakällan?
- Vilka är de möjliga utmaningarna med att integrera dessa data i mitt program?
Användare kan visa dataproduktprofilen med hjälp av en rapporteringsinstrumentpanel på sin datamarknad.
Du kan rapportera om sådana objekt som:
- Fullständighet: Anger procentandelen data som inte är tomma eller null.
- Unikhet: Anger procentandelen data som inte dupliceras.
- Konsekvens: Anger data där dataintegriteten bibehålls.
Rekommendationer för datakvalitet
För att implementera datakvalitet måste du använda både mänsklig och beräkningskraft på följande sätt:
Använd lösningar som innehåller algoritmer, regler, dataprofilering och mått.
Använd domänexperter som kan gå in när det finns ett krav på att träna en algoritm på grund av ett stort antal fel som passerar genom beräkningslagret.
Verifiera tidigt. Traditionella lösningar tillämpar datakvalitetskontroller efter att ha extraherat, transformerat och läst in data. Vid den här tiden har dataprodukten redan förbrukats och fel har uppstått till underordnade dataprodukter. När data matas in från källan implementerar du i stället datakvalitetskontroller nära källorna och innan nedströmsanvändare använder dataprodukterna. Om det finns batchinmatning från datasjön gör du dessa kontroller när du flyttar data från rådata till berikade.
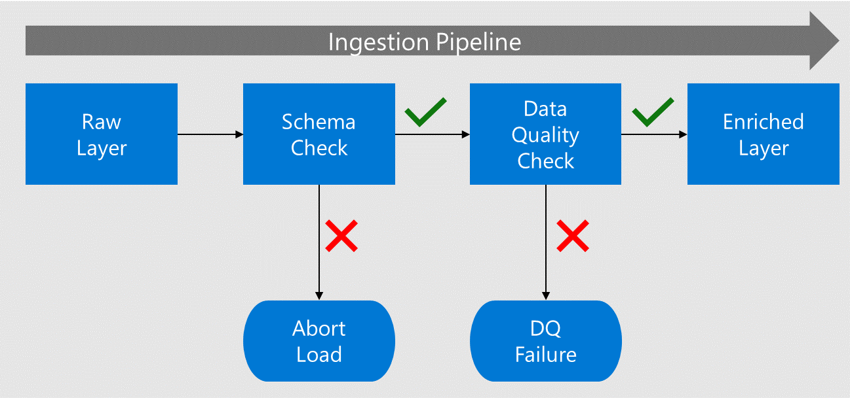
Innan data flyttas till det berikade lagret kontrolleras dess schema och kolumner mot de metadata som registrerats i datakatalogen.
Om data innehåller fel stoppas belastningen och dataprogramteamet meddelas om felet.
Om schemat och kolumnen checkar igenom läses data in i de berikade lagren med anpassade datatyper.
Innan du går över till det berikade lagret söker en datakvalitetsprocess efter kompatibilitet mot algoritmerna och reglerna.

Dricks
Definiera datakvalitetsregler på både global nivå och domännivå. På så sätt kan företaget definiera sina standarder för varje skapad dataprodukt och göra det möjligt för datadomäner att skapa ytterligare regler som är relaterade till deras domän.
Lösningar för datakvalitet
Vi rekommenderar att du utvärderar Datakvalitet i Microsoft Purview som en lösning för att utvärdera och hantera datakvalitet, vilket är avgörande för tillförlitliga AI-drivna insikter och beslutsfattande. Den innehåller:
- Regler utan kod/låg kod: Utvärdera datakvaliteten med hjälp av färdiga AI-genererade regler.
- AI-baserad dataprofilering: Rekommenderar kolumner för profilering och tillåter mänsklig inblandning för förfining.
- Bedömning av datakvalitet: Ger poäng för datatillgångar, dataprodukter och styrningsdomäner.
- Aviseringar om datakvalitet: Meddelar dataägare om kvalitetsproblem.
Mer information finns i Vad är datakvalitet.
Om din organisation bestämmer sig för att implementera Azure Databricks för att manipulera data bör du utvärdera de datakvalitetskontroller, tester, övervakning och tillämpning som den här lösningen erbjuder. Om du använder förväntningar kan du samla in datakvalitetsproblem vid inmatning innan de påverkar relaterade underordnade dataprodukter. Mer information finns i Upprätta datakvalitetsstandarder och Hantering av datakvalitet med Databricks.
Du kan också välja mellan partner, öppen källkod och anpassade alternativ för en lösning för datakvalitet.
Sammanfattning av datakvalitet
Att åtgärda datakvaliteten kan få allvarliga konsekvenser för ett företag. Det kan leda till att affärsenheter tolkar dataprodukter på olika sätt. Den här feltolkningen kan bli kostsam för verksamheten om besluten baseras på dataprodukter med lägre datakvalitet. Att åtgärda dataprodukter med attribut som saknas kan vara en dyr uppgift och kan kräva fullständiga omladdningar av data från flera perioder.
Validera datakvaliteten tidigt och sätt processer på plats för att proaktivt hantera dålig datakvalitet. En dataprodukt kan till exempel inte släppas till produktion förrän den uppnår en viss fullständighet.
Du kan använda verktyg som ett fritt val, men se till att det innehåller förväntningar (regler), datamått, profilering och möjligheten att säkra förväntningarna så att du kan implementera globala och domänbaserade förväntningar.