Självstudie: Konfigurera en dataproduktbatch
I den här självstudien får du lära dig hur du konfigurerar dataprodukttjänster som redan har distribuerats. Använd Azure Data Factory för att integrera och samordna dina data och använda Microsoft Purview för att identifiera, hantera och styra datatillgångar.
Lär dig att:
- Skapa och distribuera nödvändiga resurser
- Tilldela roller och åtkomstbehörigheter
- Anslut resurser för dataintegrering
Den här självstudien hjälper dig att bekanta dig med de tjänster som distribueras i <DMLZ-prefix>-dev-dp001 exempeldataproduktresursgruppen. Lär dig hur Azure-tjänsterna samverkar med varandra och vilka säkerhetsåtgärder som finns på plats.
När du distribuerar de nya komponenterna kan du undersöka hur Purview ansluter tjänststyrning för att skapa en holistisk, uppdaterad karta över ditt datalandskap. Resultatet är automatiserad dataidentifiering, klassificering av känsliga data och data härkomst från slutpunkt till slutpunkt.
Förutsättningar
Innan du börjar konfigurera din dataproduktbatch måste du uppfylla följande krav:
En Azure-prenumeration. Om du inte har en Azure-prenumeration skapar du ditt kostnadsfria Azure-konto idag.
Behörigheter till Azure-prenumerationen. Om du vill konfigurera Purview och Azure Synapse Analytics för distributionen måste du ha rollen Administratör för användaråtkomst eller rollen Ägare i Azure-prenumerationen. Du anger fler rolltilldelningar för tjänster och tjänstens huvudnamn i självstudien.
Distribuerade resurser. För att slutföra självstudien måste dessa resurser redan distribueras i din Azure-prenumeration:
- Landningszon för datahantering. Mer information finns i GitHub-lagringsplatsen för datahanteringslandningszonen .
- Datalandningszon. Mer information finns i GitHub-lagringsplatsen för datalandningszonen .
- Dataproduktbatch. Mer information finns i GitHub-lagringsplatsen för dataproduktsbatch .
Microsoft Purview-konto. Kontot skapas som en del av distributionen av landningszonen för datahantering.
Lokalt installerad integrationskörning. Körningen skapas som en del av distributionen av din datalandningszon.
Kommentar
I den här självstudien refererar platshållarna till nödvändiga resurser som du distribuerar innan du påbörjar självstudien:
<DMLZ-prefix>refererar till prefixet som du angav när du skapade distributionen av landningszonen för datahantering.<DLZ-prefix>refererar till prefixet som du angav när du skapade distributionen av din datalandningszon .<DP-prefix>refererar till prefixet som du angav när du skapade batchdistributionen av dataprodukten.
Skapa Azure SQL Database-instanser
Börja den här självstudien genom att skapa två SQL Database-exempelinstanser. Du använder databaserna för att simulera CRM- och ERP-datakällor i senare avsnitt.
I azure-portalen går du till portalens globala kontroller och väljer Cloud Shell-ikonen för att öppna en Azure Cloud Shell-terminal. Välj Bash som terminaltyp.

Kör följande skript i Cloud Shell. Skriptet hittar
<DLZ-prefix>-dev-dp001resursgruppen och<DP-prefix>-dev-sqlserver001Azure SQL-servern som finns i resursgruppen. Sedan skapar skriptet de två SQL Database-instanserna på<DP-prefix>-dev-sqlserver001servern. Databaserna är ifyllda i förväg med AdventureWorks-exempeldata. Data innehåller de tabeller som du använder i den här självstudien.Se till att du ersätter platshållarvärdet för parametern
subscriptionmed ditt eget Azure-prenumerations-ID.# Azure SQL Database instances setup # Create the AdatumCRM and AdatumERP databases to simulate customer and sales data. # Use the ID for the Azure subscription you used to deployed the data product. az account set --subscription "<your-subscription-ID>" # Get the resource group for the data product. resourceGroupName=$(az group list -o tsv --query "[?contains(@.name, 'dp001')==\`true\`].name") # Get the existing Azure SQL Database server name. sqlServerName=$(az sql server list -g $resourceGroupName -o tsv --query "[?contains(@.name, 'sqlserver001')==\`true\`].name") # Create the first SQL Database instance, AdatumCRM, to create the customer's data source. az sql db create --resource-group $resourceGroupName --server $sqlServerName --name AdatumCRM --service-objective Basic --sample-name AdventureWorksLT # Create the second SQL Database instance, AdatumERP, to create the sales data source. az sql db create --resource-group $resourceGroupName --server $sqlServerName --name AdatumERP --service-objective Basic --sample-name AdventureWorksLT
När skriptet har körts har du på <DP-prefix>-dev-sqlserver001 Azure SQL-servern två nya SQL Database-instanser AdatumCRM och AdatumERP. Båda databaserna finns på basic-beräkningsnivån. Databaserna finns i samma <DLZ-prefix>-dev-dp001 resursgrupp som du använde för att distribuera dataproduktbatchen.
Konfigurera Purview för att katalogisera dataproduktbatchen
Slutför sedan stegen för att konfigurera Purview för att katalogisera dataproduktbatchen. Du börjar med att skapa ett huvudnamn för tjänsten. Sedan konfigurerar du nödvändiga resurser och tilldelar roller och åtkomstbehörigheter.
Skapa ett huvudnamn för tjänsten
I azure-portalen går du till portalens globala kontroller och väljer Cloud Shell-ikonen för att öppna en Azure Cloud Shell-terminal. Välj Bash som terminaltyp.
Ändra följande skript:
- Ersätt parameterns
subscriptionIdplatshållarvärde med ditt eget Azure-prenumerations-ID. spnameErsätt platshållarvärdet för parametern med det namn som du vill använda för tjänstens huvudnamn. Tjänstens huvudnamn måste vara unikt i prenumerationen.
När du har uppdaterat parametervärdena kör du skriptet i Cloud Shell.
# Replace the parameter values with the name you want to use for your service principal name and your Azure subscription ID. spname="<your-service-principal-name>" subscriptionId="<your-subscription-id>" # Set the scope to the subscription. scope="/subscriptions/$subscriptionId" # Create the service principal. az ad sp create-for-rbac \ --name $spname \ --role "Contributor" \ --scope $scope- Ersätt parameterns
Kontrollera JSON-utdata för ett resultat som liknar följande exempel. Anteckna eller kopiera värdena i utdata som ska användas i senare steg.
{ "appId": "<your-app-id>", "displayName": "<service-principal-display-name>", "name": "<your-service-principal-name>", "password": "<your-service-principal-password>", "tenant": "<your-tenant>" }
Konfigurera åtkomst och behörigheter för tjänstens huvudnamn
Hämta följande returnerade värden från JSON-utdata som genererades i föregående steg:
- Tjänstens huvudnamns-ID (
appId) - Tjänstens huvudnamnsnyckel (
password)
Tjänstens huvudnamn måste ha följande behörigheter:
- Rollen Storage Blob Data Reader på lagringskontona.
- Dataläsarbehörigheter för SQL Database-instanserna.
Utför följande steg för att konfigurera tjänstens huvudnamn med den roll och behörighet som krävs.
Behörigheter för Azure Storage-konto
Gå till Azure Storage-kontot i
<DLZ-prefix>devrawAzure-portalen. Välj Åtkomstkontroll (IAM) på resursmenyn.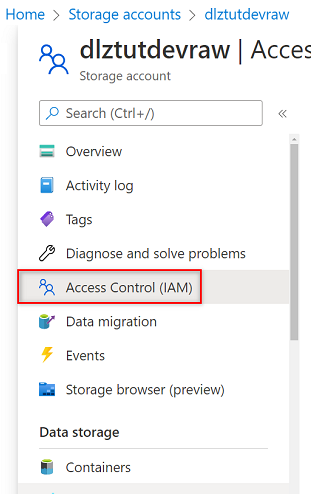
Välj Lägg till>Lägg till rolltilldelning.
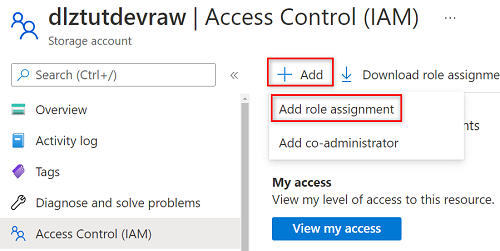
I Lägg till rolltilldelning går du till fliken Roll och söker efter och väljer Lagringsblobdataläsare. Välj sedan Nästa.
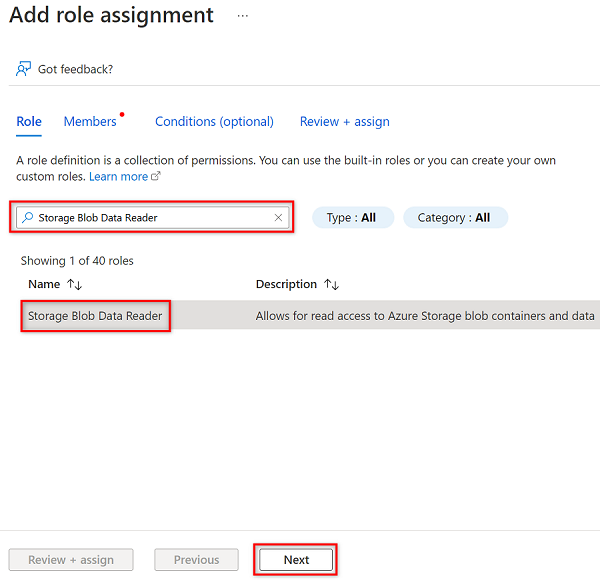
I Medlemmar väljer du Välj medlemmar.
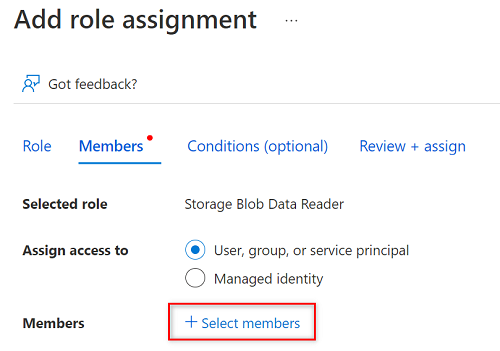
I Välj medlemmar söker du efter namnet på tjänstens huvudnamn som du skapade.

I sökresultaten väljer du tjänstens huvudnamn och väljer sedan Välj.
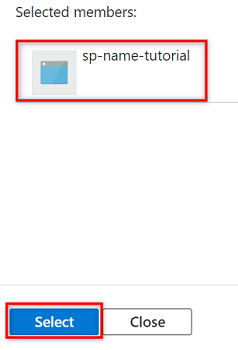
Slutför rolltilldelningen genom att välja Granska + tilldela två gånger.
Upprepa stegen i det här avsnittet för återstående lagringskonton:
<DLZ-prefix>devencur<DLZ-prefix>devwork
SQL Database-behörigheter
Om du vill ange SQL Database-behörigheter ansluter du till den virtuella Azure SQL-datorn med hjälp av frågeredigeraren. Eftersom alla resurser finns bakom en privat slutpunkt måste du först logga in på Azure-portalen med hjälp av en virtuell Azure Bastion-värddator.
I Azure-portalen ansluter du till den virtuella dator som distribueras i <DMLZ-prefix>-dev-bastion resursgruppen. Om du inte är säker på hur du ansluter till den virtuella datorn med hjälp av Bastion-värdtjänsten kan du läsa Anslut till en virtuell dator.
Om du vill lägga till tjänstens huvudnamn som användare i databasen kan du först behöva lägga till dig själv som Microsoft Entra-administratör. I steg 1 och 2 lägger du till dig själv som Microsoft Entra-administratör. I steg 3 till 5 ger du tjänstens huvudnamn behörighet till en databas. När du är inloggad på portalen från den virtuella Bastion-värddatorn söker du efter virtuella Azure SQL-datorer i Azure-portalen.
Gå till den
<DP-prefix>-dev-sqlserver001virtuella Azure SQL-datorn. I resursmenyn under Inställningar väljer du Microsoft Entra-ID.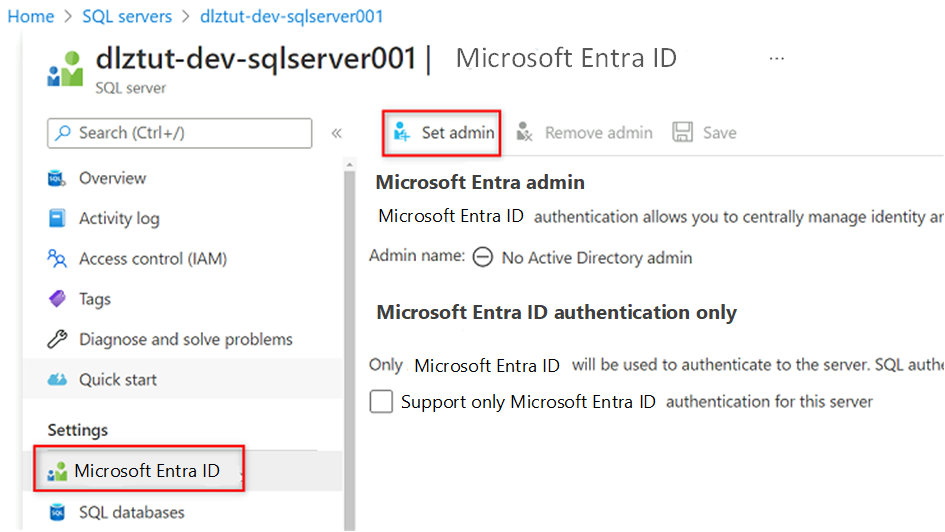
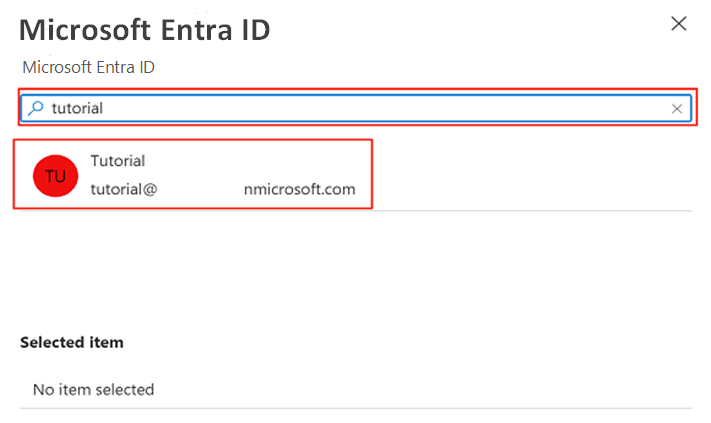
I kommandofältet väljer du Ange administratör. Sök efter och välj ditt eget konto. Välj Välj.
I resursmenyn väljer du SQL-databaser och sedan
AdatumCRMdatabasen.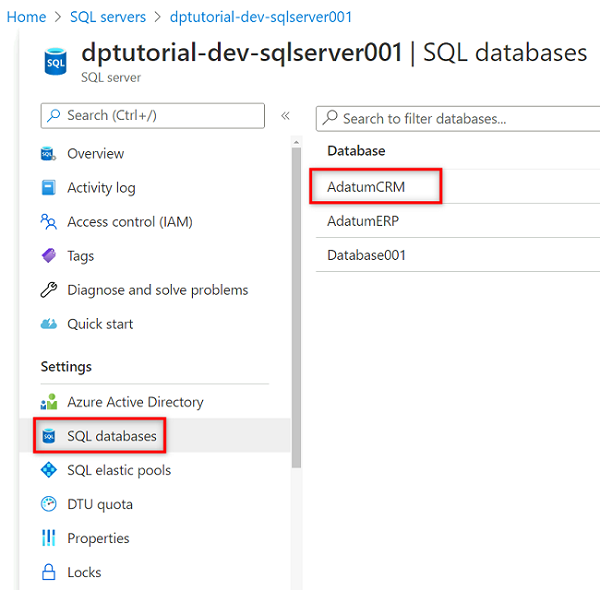
På resursmenyn AdatumCRM väljer du Frågeredigeraren (förhandsversion). Under Active Directory-autentisering väljer du knappen Fortsätt som för att logga in.
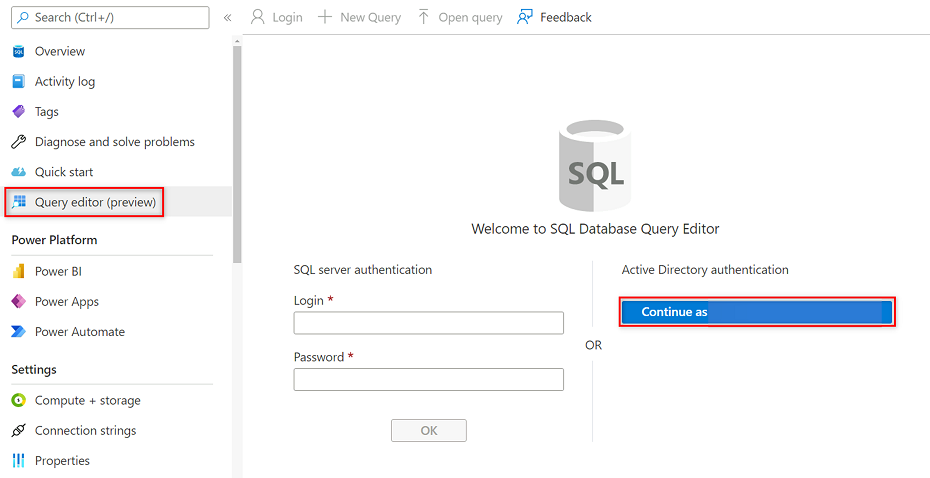
I frågeredigeraren ändrar du följande instruktioner för att ersätta
<service principal name>med namnet på tjänstens huvudnamn som du skapade (till exempelpurview-service-principal). Kör sedan -instruktionerna.CREATE USER [<service principal name>] FROM EXTERNAL PROVIDER GO EXEC sp_addrolemember 'db_datareader', [<service principal name>] GO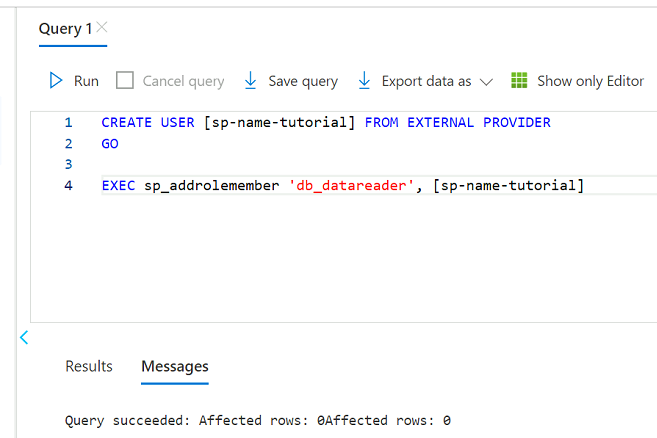
Upprepa steg 3 till 5 för AdatumERP databasen.
Konfigurera nyckelvalvet
Purview läser tjänstens huvudnyckel från en instans av Azure Key Vault. Nyckelvalvet skapas i distributionen av landningszonen för datahantering. Följande steg krävs för att konfigurera nyckelvalvet:
Lägg till nyckeln för tjänstens huvudnamn i nyckelvalvet som en hemlighet.
Ge Purview MSI Secrets Reader behörigheter i nyckelvalvet.
Lägg till nyckelvalvet i Purview som en nyckelvalvsanslutning.
Skapa en autentiseringsuppgift i Purview som pekar på nyckelvalvshemligheten.
Lägga till behörigheter för att lägga till hemlighet i nyckelvalvet
Gå till Azure Key Vault-tjänsten i Azure-portalen. Sök
<DMLZ-prefix>-dev-vault001efter nyckelvalvet.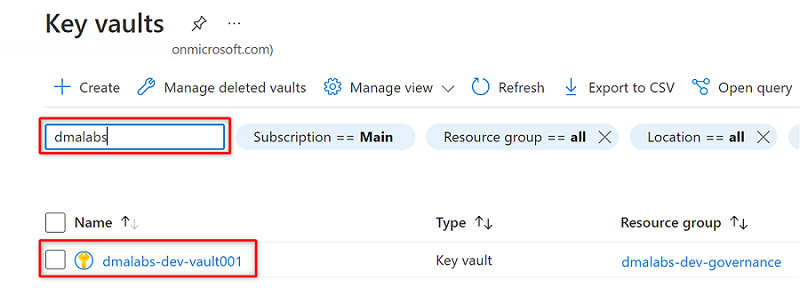
Välj Åtkomstkontroll (IAM) på resursmenyn. I kommandofältet väljer du Lägg till och sedan Lägg till rolltilldelning.
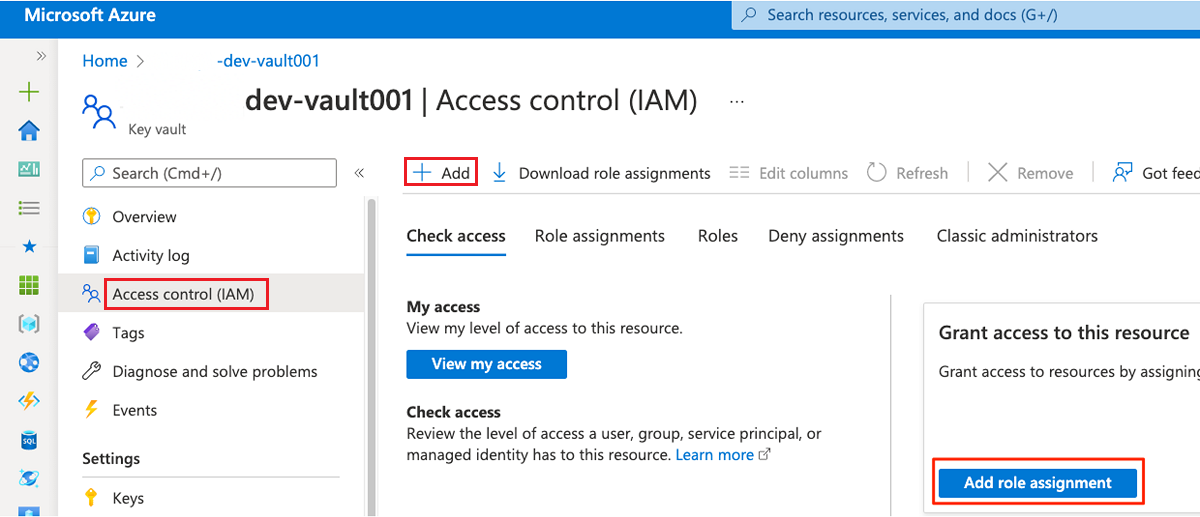
På fliken Roll söker du efter och väljer sedan Key Vault-administratör. Välj Nästa.
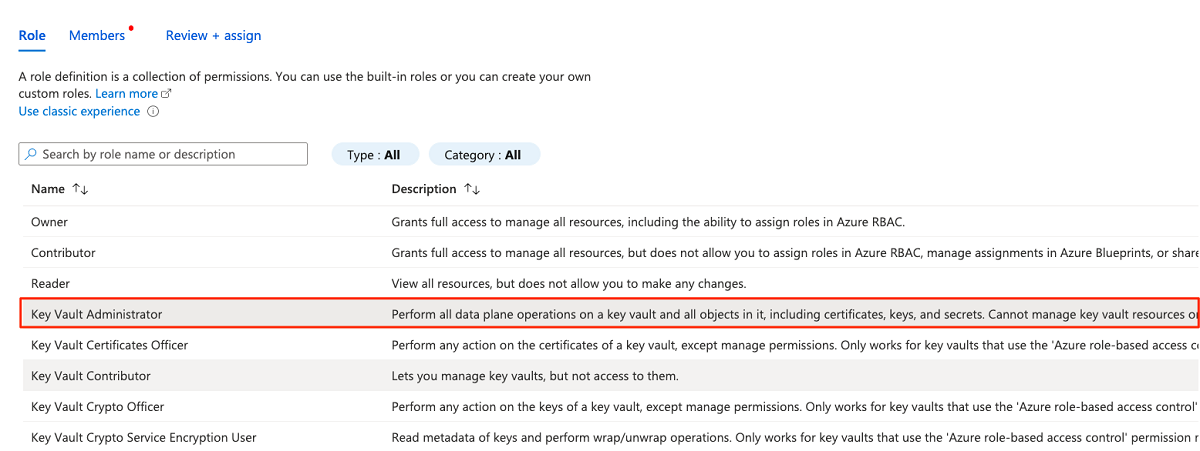
I Medlemmar väljer du Välj medlemmar för att lägga till det konto som för närvarande är inloggad.
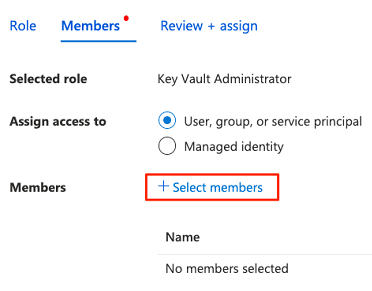
I Välj medlemmar söker du efter det konto som för närvarande är loggat in. Välj kontot och välj sedan Välj.
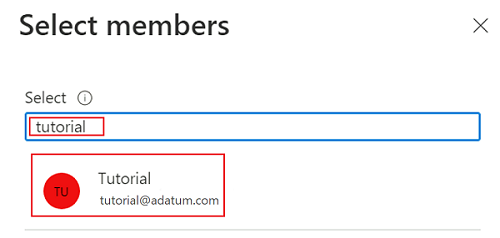
Slutför rolltilldelningsprocessen genom att välja Granska + tilldela två gånger.
Lägga till en hemlighet i nyckelvalvet
Slutför följande steg för att logga in på Azure-portalen från den virtuella Bastion-värddatorn.
<DMLZ-prefix>-dev-vault001I resursmenyn för nyckelvalvet väljer du Hemligheter. I kommandofältet väljer du Generera/importera för att skapa en ny hemlighet.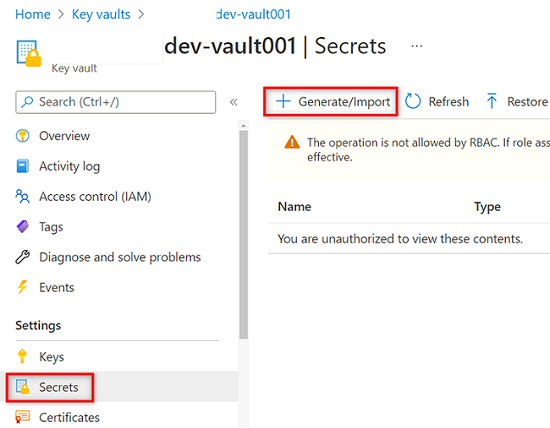
I Skapa en hemlighet väljer eller anger du följande värden:
Inställning Åtgärd Alternativ för uppladdning Välj Manuell. Namn Ange tjänstens huvudnamnshemlighet. Värde Ange lösenordet för tjänstens huvudnamn som du skapade tidigare. 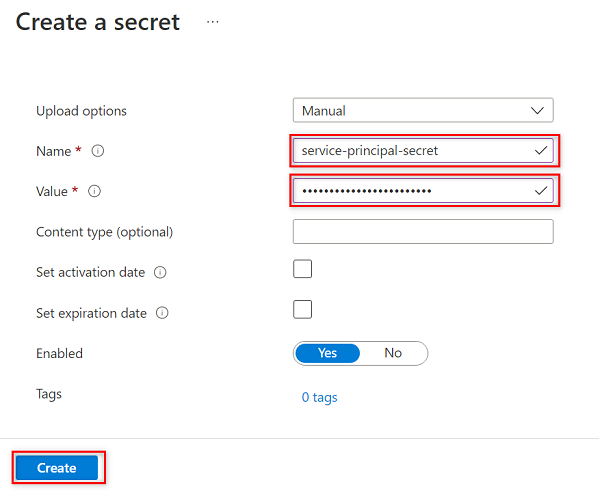
Kommentar
Det här steget skapar en hemlighet med namnet
service-principal-secreti nyckelvalvet med hjälp av lösenordsnyckeln för tjänstens huvudnamn. Purview använder hemligheten för att ansluta till och skanna datakällorna. Om du anger ett felaktigt lösenord kan du inte slutföra följande avsnitt.Välj Skapa.
Konfigurera Purview-behörigheter i nyckelvalvet
För att Purview-instansen ska kunna läsa hemligheterna som lagras i nyckelvalvet måste du tilldela Purview relevanta behörigheter i nyckelvalvet. Om du vill ange behörigheterna lägger du till purview-hanterad identitet i nyckelvalvets roll Secrets Reader.
<DMLZ-prefix>-dev-vault001I resursmenyn för nyckelvalvet väljer du Åtkomstkontroll (IAM).I kommandofältet väljer du Lägg till och sedan Lägg till rolltilldelning.
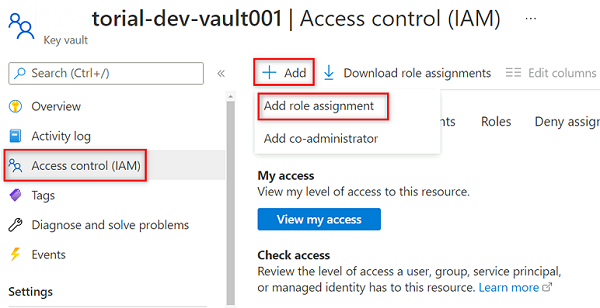
I Roll söker du efter och väljer Nyckelvalvshemlighetsanvändare. Välj Nästa.
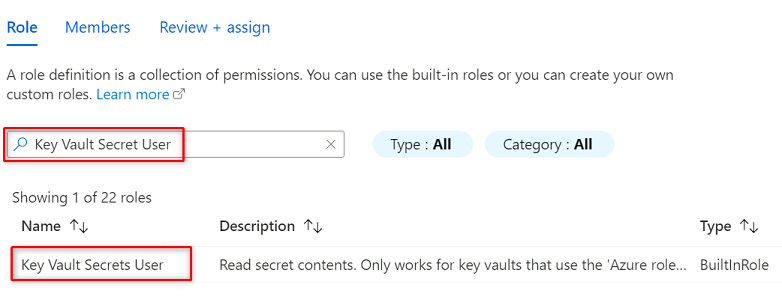
I Medlemmar väljer du Välj medlemmar.
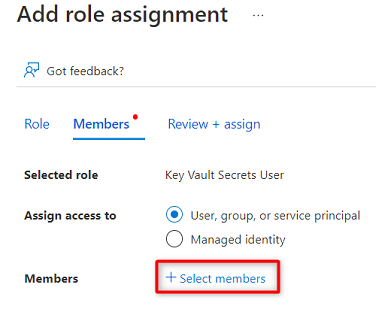
Sök efter Purview-instansen
<DMLZ-prefix>-dev-purview001. Välj instansen för att lägga till det relevanta kontot. Välj sedan Välj.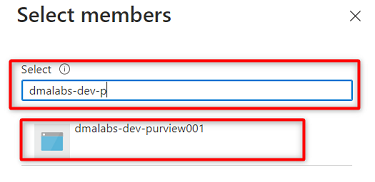
Slutför rolltilldelningsprocessen genom att välja Granska + tilldela två gånger.
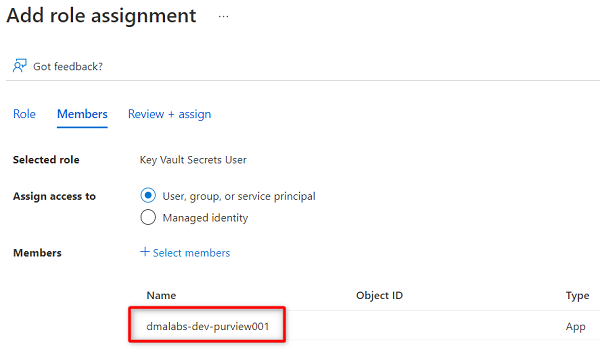
Konfigurera en key vault-anslutning i Purview
Om du vill konfigurera en key vault-anslutning till Purview måste du logga in på Azure-portalen med hjälp av en virtuell Azure Bastion-värddator.
Gå till Purview-kontot i
<DMLZ-prefix>-dev-purview001Azure-portalen. Under Komma igång går du till Öppna Microsoft Purview-styrningsportalen och väljer Öppna.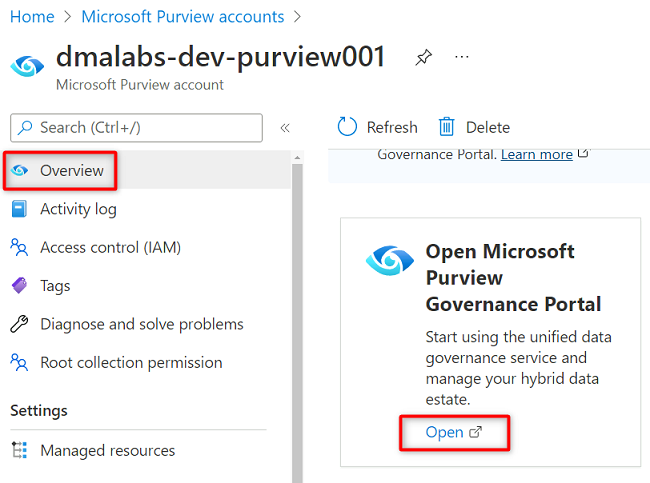
I Purview Studio väljer du Autentiseringsuppgifter för hantering>. I kommandofältet Autentiseringsuppgifter väljer du Hantera Key Vault-anslutningar och sedan Nytt.
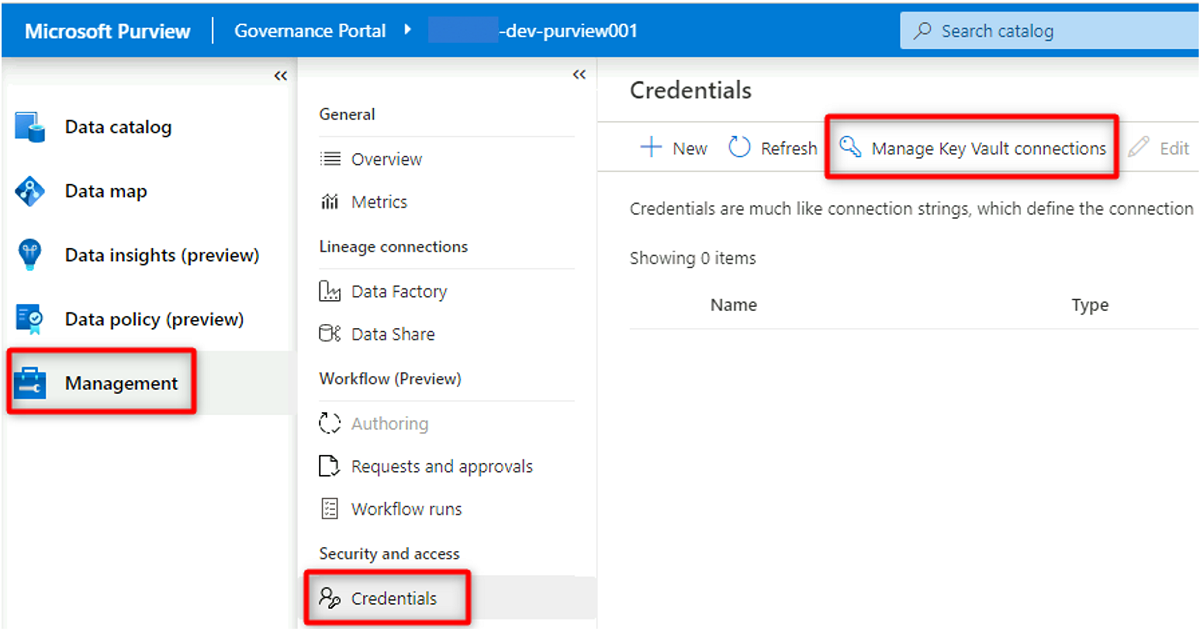
I Ny key vault-anslutning väljer eller anger du följande information:
Inställning Åtgärd Namn Ange <DMLZ-prefix-dev-vault001>. Azure-prenumeration Välj den prenumeration som är värd för nyckelvalvet. Key Vault-namn <Välj nyckelvalvet DMLZ-prefix-dev-vault001>. 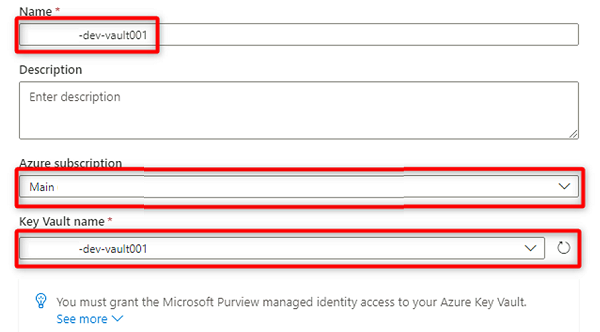
Välj Skapa.
I Bekräfta beviljande av åtkomst väljer du Bekräfta.
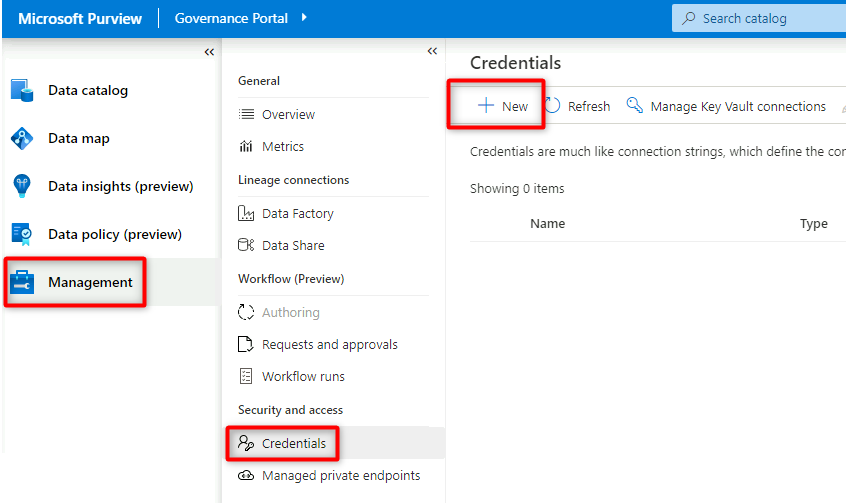
Skapa en autentiseringsuppgift i Purview
Det sista steget för att konfigurera nyckelvalv är att skapa en autentiseringsuppgift i Purview som pekar på hemligheten som du skapade i nyckelvalvet för tjänstens huvudnamn.
I Purview Studio väljer du Autentiseringsuppgifter för hantering>. I kommandofältet Autentiseringsuppgifter väljer du Nytt.
I Ny autentiseringsuppgift väljer eller anger du följande information:
Inställning Åtgärd Namn Ange purviewServicePrincipal. Autentiseringsmetod Välj Tjänstens huvudnamn. Tenant ID Värdet fylls i automatiskt. Tjänstens huvudnamn-ID Ange program-ID eller klient-ID för tjänstens huvudnamn. Key Vault-anslutning Välj den key vault-anslutning som du skapade i föregående avsnitt. Hemligt namn Ange namnet på hemligheten i nyckelvalvet (service-principal-secret). 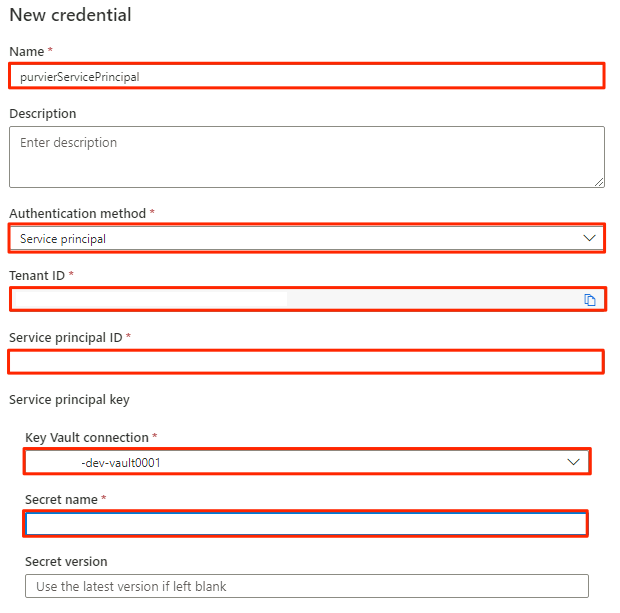
Välj Skapa.
Registrera datakällor
Nu kan Purview ansluta till tjänstens huvudnamn. Nu kan du registrera och konfigurera datakällorna.
Registrera Azure Data Lake Storage Gen2-konton
Följande steg beskriver processen för att registrera ett Azure Data Lake Storage Gen2-lagringskonto.
I Purview Studio väljer du ikonen för datakarta, väljer Källor och sedan Registrera.
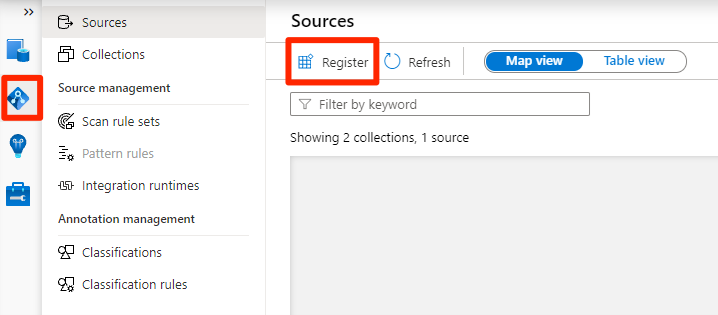
I Registrera källor väljer du Azure Data Lake Storage Gen2 och sedan Fortsätt.

I Registrera källor (Azure Data Lake Storage Gen2) väljer eller anger du följande information:
Inställning Åtgärd Namn Ange <DLZ-prefix>dldevraw. Azure-prenumeration Välj den prenumeration som är värd för lagringskontot. Namn på lagringskonto Välj relevant lagringskonto. Slutpunkt Värdet fylls i automatiskt baserat på det valda lagringskontot. Välj en samling Välj rotsamlingen. 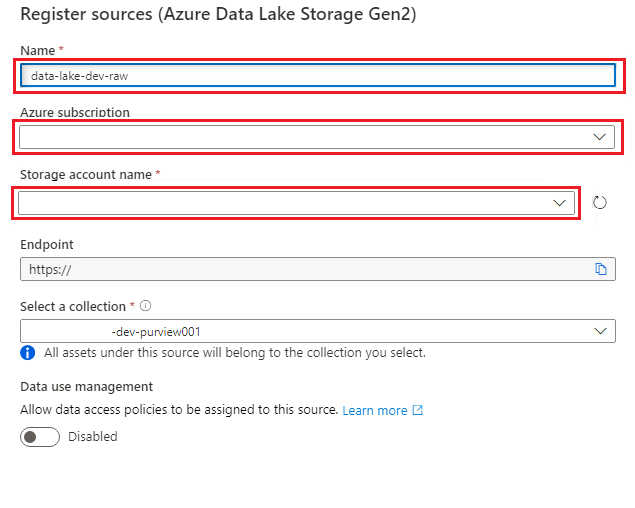
Välj Registrera för att skapa datakällan.
Upprepa följande steg för följande lagringskonton:
<DMLZ-prefix>devencur<DMLZ-prefix>devwork
Registrera SQL Database-instansen som en datakälla
I Purview Studio väljer du ikonen Datakarta, källor och sedan Registrera.
I Registrera källor väljer du Azure SQL Database och sedan Fortsätt.
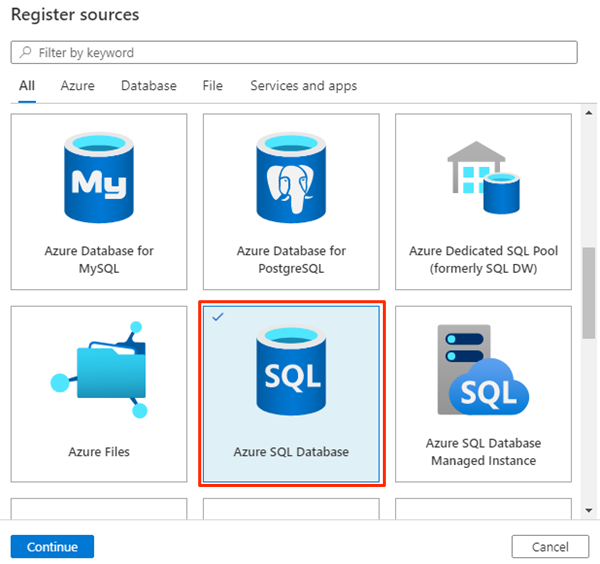
I Registrera källor (Azure SQL Database) väljer eller anger du följande information:
Inställning Åtgärd Namn Ange SQLDatabase (namnet på databasen som skapades i Skapa Azure SQL Database-instanser). Abonnemang Välj den prenumeration som är värd för databasen. Servernamn Ange <DP-prefix-dev-sqlserver001>. 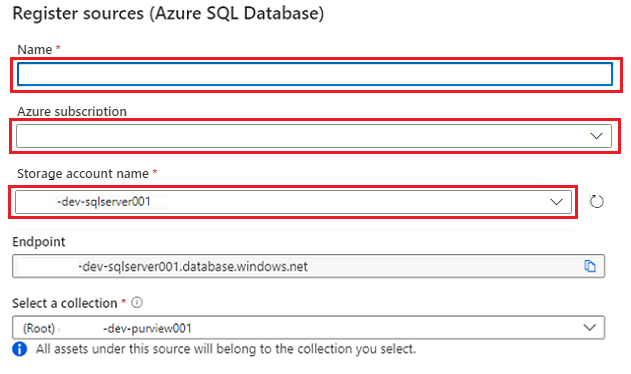
Välj Registrera.
Konfigurera genomsökningar
Konfigurera sedan genomsökningar för datakällorna.
Skanna Data Lake Storage Gen2-datakällan
Gå till datakartan i Purview Studio. I datakällan väljer du ikonen Ny genomsökning .
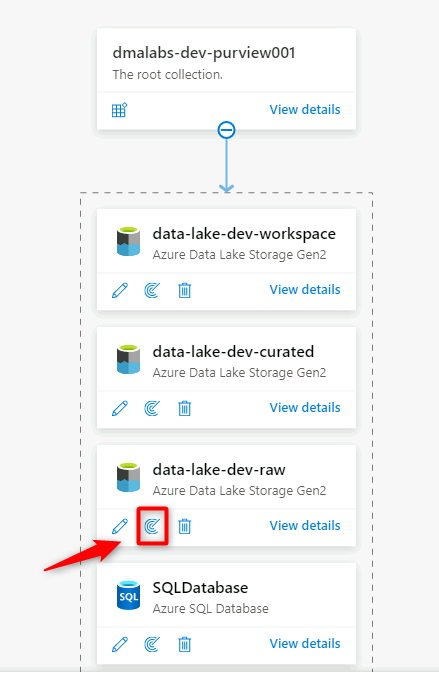
I det nya genomsökningsfönstret väljer eller anger du följande information:
Inställning Åtgärd Namn Ange Scan_<DLZ-prefix>devraw. Anslut via integrationskörning Välj den lokalt installerade integrationskörningen som distribuerades med datalandningszonen. Referens Välj tjänstens huvudnamn som du har konfigurerat för Purview. 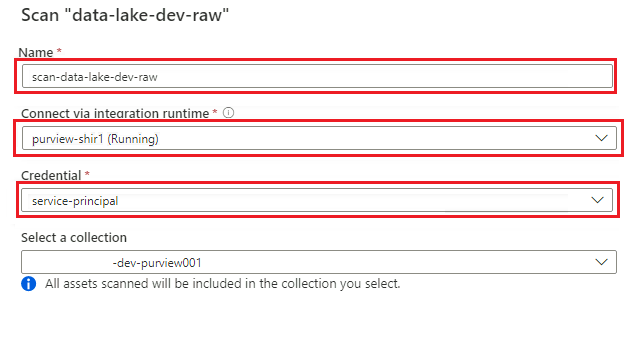
Välj Testa anslutning för att verifiera anslutningen och att behörigheter finns på plats. Välj Fortsätt.
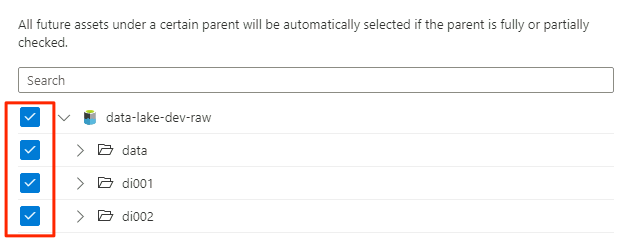
I Omfång för genomsökningen väljer du hela lagringskontot som omfång för genomsökningen och väljer sedan Fortsätt.
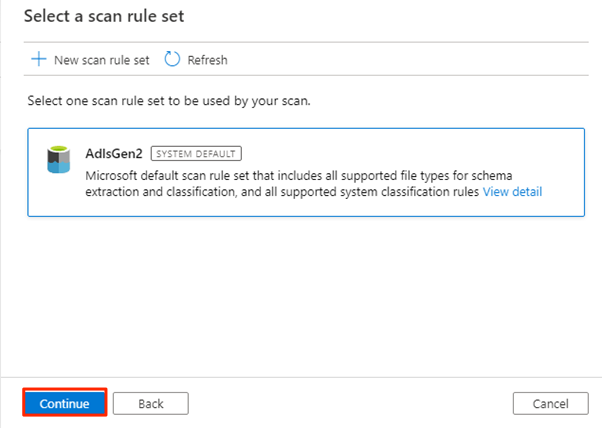
I Välj en skanningsregeluppsättning väljer du AdlsGen2 och sedan Fortsätt.
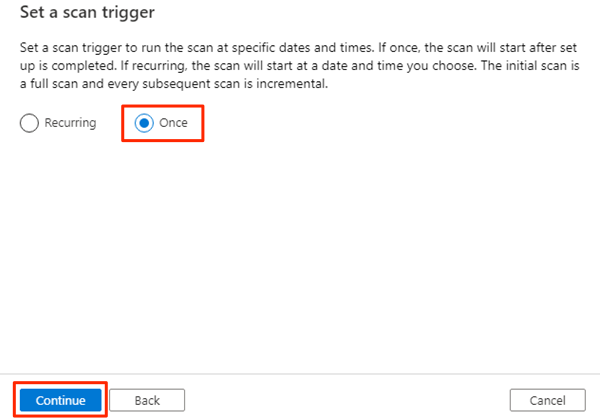
I Ange en genomsökningsutlösare väljer du En gång och väljer sedan Fortsätt.
Granska genomsökningsinställningarna i Granska genomsökningsinställningarna. Välj Spara och kör för att starta genomsökningen.
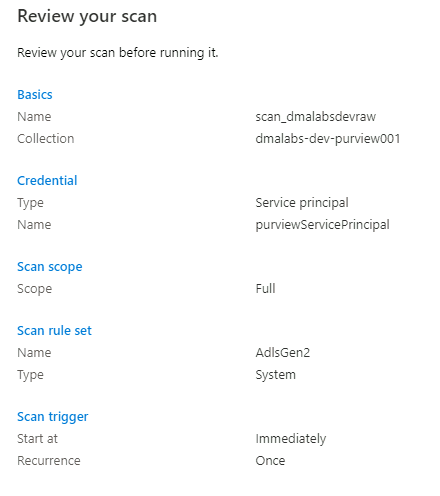
Upprepa följande steg för följande lagringskonton:
<DMLZ-prefix>devencur<DMLZ-prefix>devwork
Skanna SQL Database-datakällan
I Azure SQL Database-datakällan väljer du Ny genomsökning.
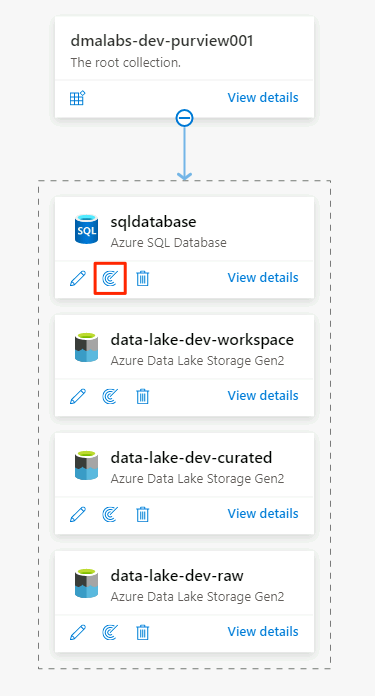
I det nya genomsökningsfönstret väljer eller anger du följande information:
Inställning Åtgärd Namn Ange Scan_Database001. Anslut via integrationskörning Välj Purview-SHIR. Databasnamn Välj databasnamnet. Referens Välj autentiseringsuppgifterna för nyckelvalvet som du skapade i Purview. Extrahering av ursprung (förhandsversion) Välj Av. 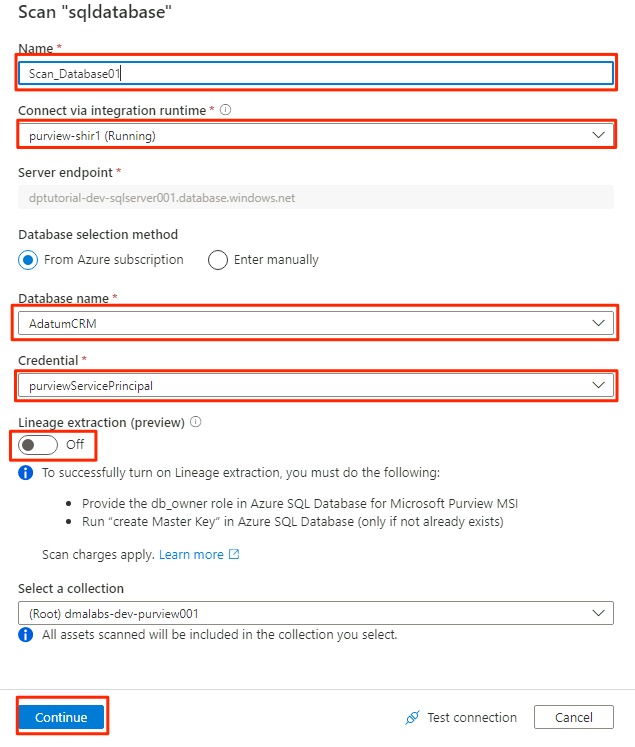
Välj Testa anslutning för att verifiera anslutningen och att behörigheter finns på plats. Välj Fortsätt.
Välj omfånget för genomsökningen. Om du vill söka igenom hela databasen använder du standardvärdet.
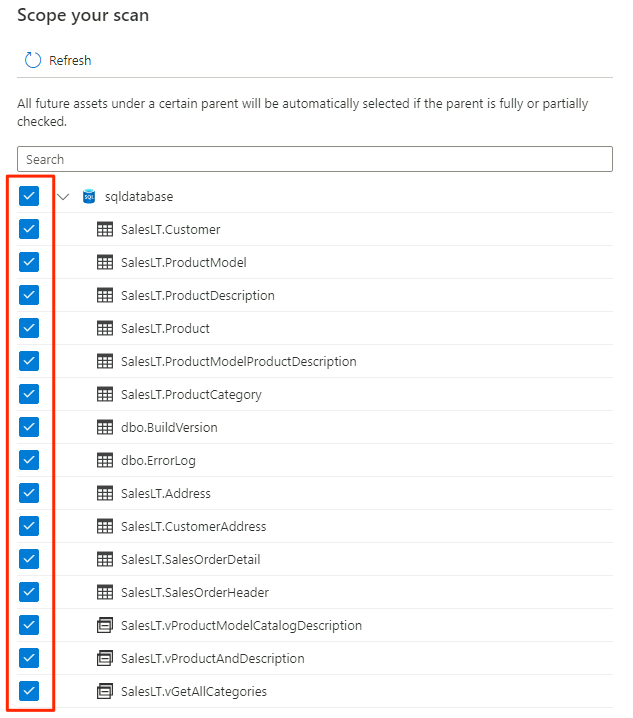
I Välj en skanningsregeluppsättning väljer du AzureSqlDatabase och väljer sedan Fortsätt.
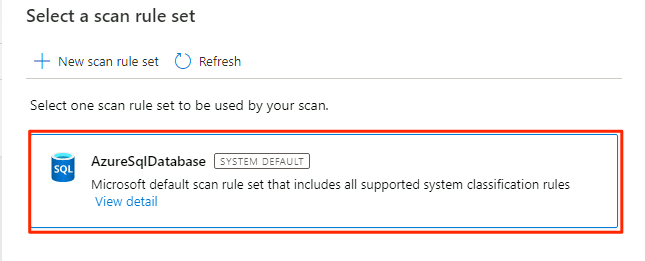
I Ange en genomsökningsutlösare väljer du En gång och väljer sedan Fortsätt.
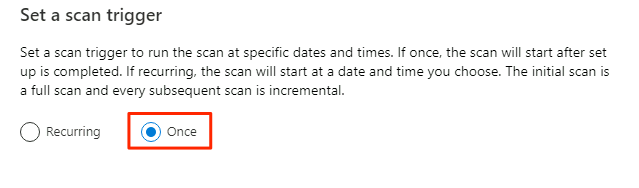
Granska genomsökningsinställningarna i Granska genomsökningsinställningarna. Välj Spara och kör för att starta genomsökningen.
Upprepa de här stegen för AdatumERP databasen.
Purview har nu konfigurerats för datastyrning för de registrerade datakällorna.
Kopiera SQL Database-data till Data Lake Storage Gen2
I följande steg använder du verktyget Kopiera data i Data Factory för att skapa en pipeline för att kopiera tabellerna från SQL Database-instanserna AdatumCRM och AdatumERP till CSV-filer i <DLZ-prefix>devraw Data Lake Storage Gen2-kontot.
Miljön är låst för offentlig åtkomst, så först måste du konfigurera privata slutpunkter. Om du vill använda de privata slutpunkterna loggar du in på Azure-portalen i din lokala webbläsare och ansluter sedan till den virtuella Bastion-värddatorn för att få åtkomst till nödvändiga Azure-tjänster.
Skapa privata slutpunkter
Så här konfigurerar du privata slutpunkter för de resurser som krävs:
<DMLZ-prefix>-dev-bastionI resursgruppen väljer du<DMLZ-prefix>-dev-vm001.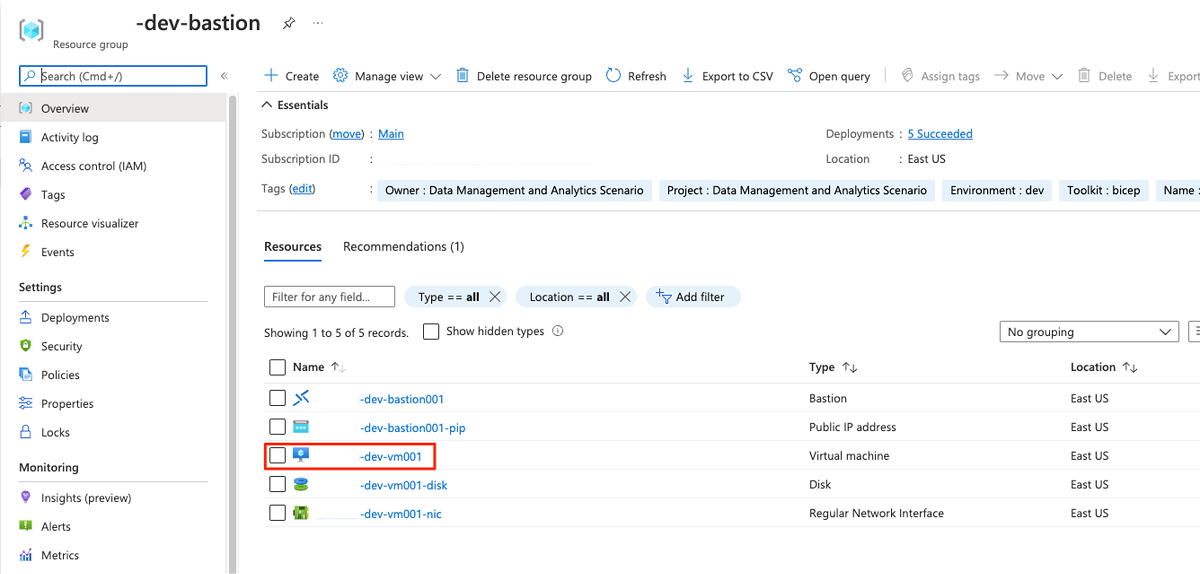
I kommandofältet väljer du Anslut och väljer Bastion.
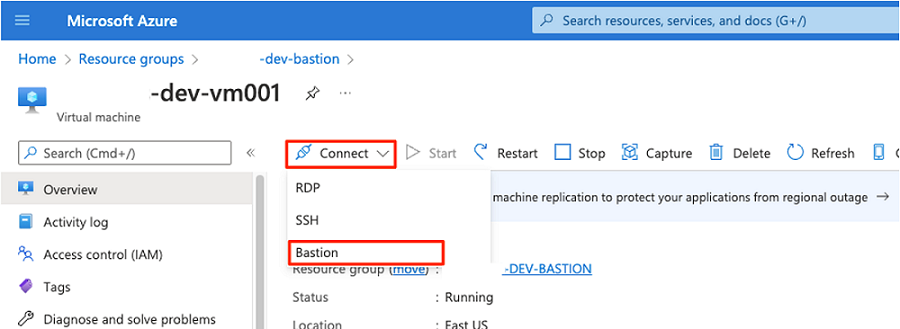
Ange användarnamnet och lösenordet för den virtuella datorn och välj sedan Anslut.
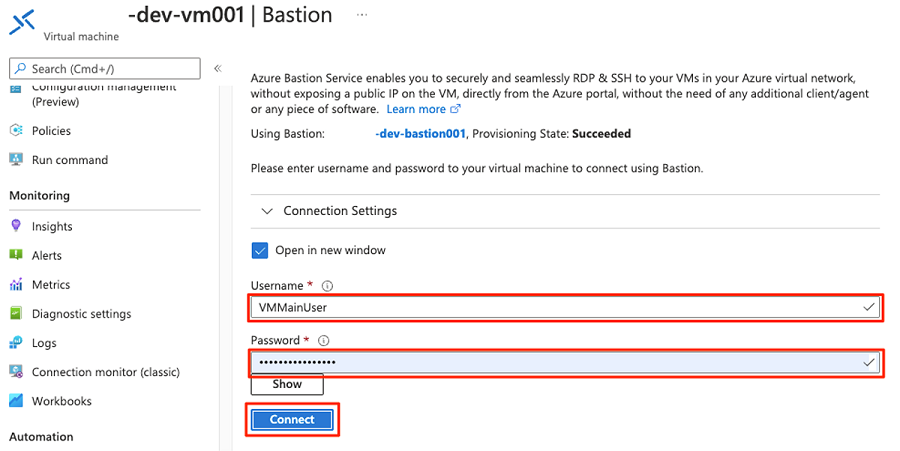
I den virtuella datorns webbläsare går du till Azure-portalen. Gå till
<DLZ-prefix>-dev-shared-integrationresursgruppen och öppna datafabriken<DLZ-prefix>-dev-integration-datafactory001.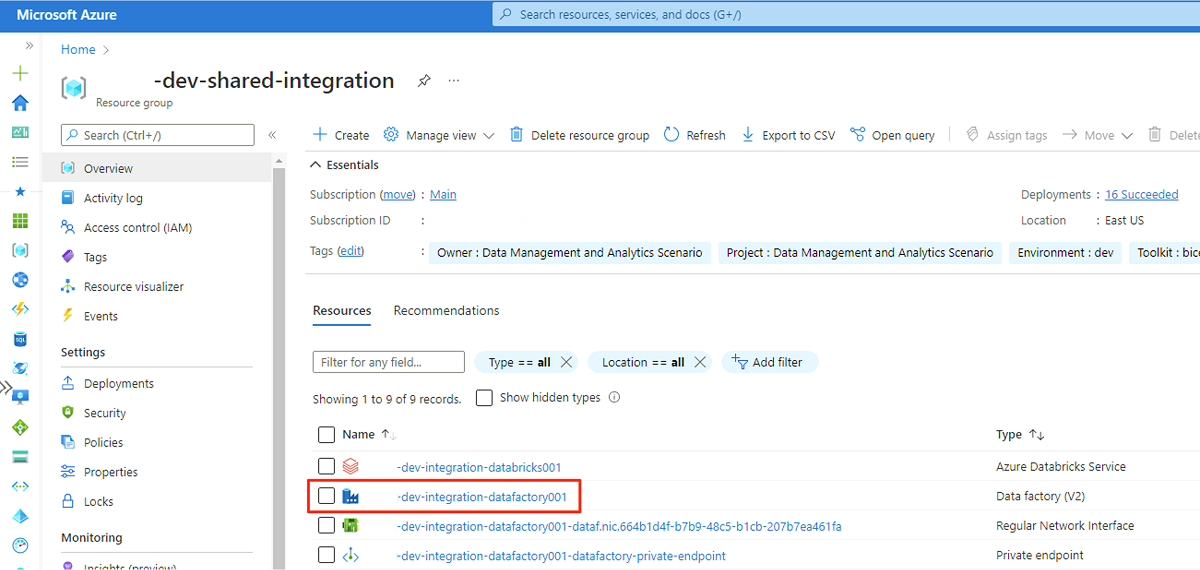
Under Komma igång går du till Öppna Azure Data Factory Studio och väljer Öppna.

I Menyn Data Factory Studio väljer du ikonen Hantera (ikonen ser ut som en fyrkantig verktygslåda med en skiftnyckel stämplad). På resursmenyn väljer du Hanterade privata slutpunkter för att skapa de privata slutpunkter som krävs för att ansluta Data Factory till andra skyddade Azure-tjänster.
Godkännande av åtkomstbegäranden för de privata slutpunkterna beskrivs i ett senare avsnitt. När du har godkänt begäranden om åtkomst till privata slutpunkter är deras godkännandestatus Godkänd, som i följande exempel på lagringskontot
<DLZ-prefix>devencur.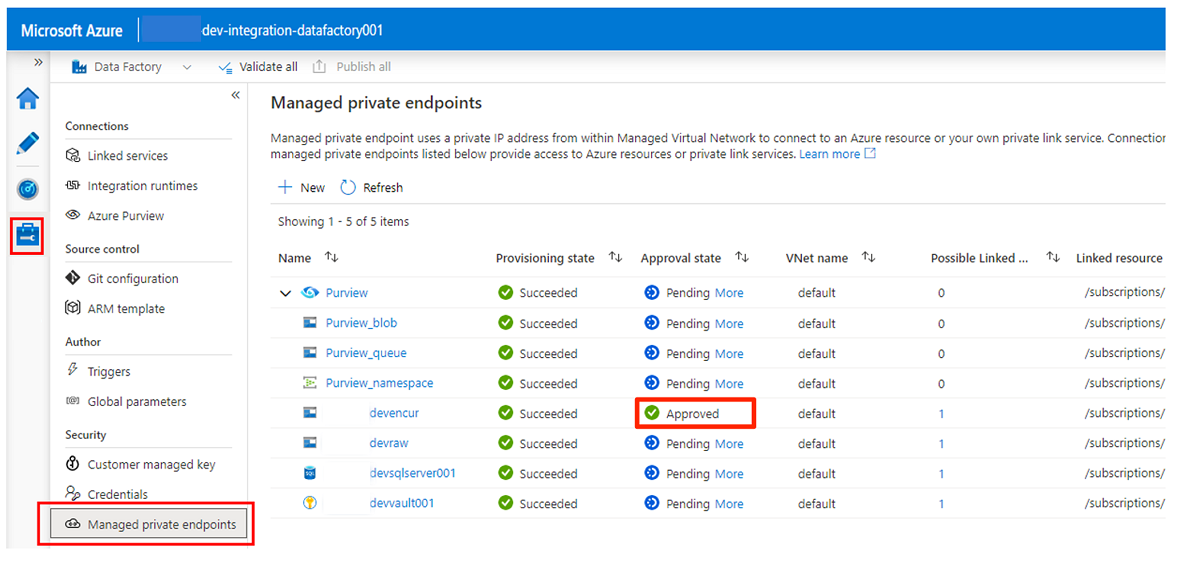
Innan du godkänner de privata slutpunktsanslutningarna väljer du Ny. Ange Azure SQL för att hitta azure SQL Database-anslutningsappen som du använder för att skapa en ny hanterad privat slutpunkt för den
<DP-prefix>-dev-sqlserver001virtuella Azure SQL-datorn. Den virtuella datorn innehåller databasernaAdatumCRMochAdatumERPsom du skapade tidigare.I Ny hanterad privat slutpunkt (Azure SQL Database) för Namn anger du data-product-dev-sqlserver001. Ange den Azure-prenumeration som du använde för att skapa resurserna. Som Servernamn väljer du
<DP-prefix>-dev-sqlserver001så att du kan ansluta till den från den här datafabriken i nästa avsnitt.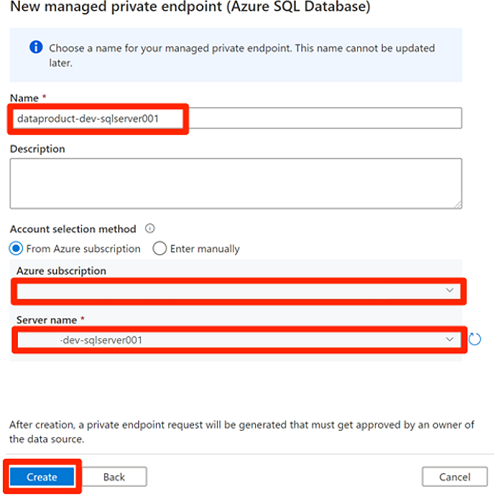



Godkänna åtkomstbegäranden för privat slutpunkt
Om du vill ge Data Factory åtkomst till de privata slutpunkterna för de tjänster som krävs har du några alternativ:
Alternativ 1: I varje tjänst som du begär åtkomst till går du till alternativet nätverksanslutningar eller privata slutpunktsanslutningar i Azure-portalen och godkänner åtkomstbegäranden till den privata slutpunkten.
Alternativ 2: Kör följande skript i Azure Cloud Shell i Bash-läge för att godkänna alla åtkomstbegäranden till de privata slutpunkter som krävs samtidigt.
# Storage managed private endpoint approval # devencur resourceGroupName=$(az group list -o tsv --query "[?contains(@.name, '-dev-storage')==\`true\`].name") storageAcctName=$(az storage account list -g $resourceGroupName -o tsv --query "[?contains(@.name, 'devencur')==\`true\`].name") endPointConnectionName=$(az network private-endpoint-connection list -g $resourceGroupName -n $storageAcctName --type Microsoft.Storage/storageAccounts -o tsv --query "[?contains(@.properties.privateLinkServiceConnectionState.status, 'Pending')==\`true\`].name") az network private-endpoint-connection approve -g $resourceGroupName -n $endPointConnectionName --resource-name $storageAcctName --type Microsoft.Storage/storageAccounts --description "Approved" # devraw resourceGroupName=$(az group list -o tsv --query "[?contains(@.name, '-dev-storage')==\`true\`].name") storageAcctName=$(az storage account list -g $resourceGroupName -o tsv --query "[?contains(@.name, 'devraw')==\`true\`].name") endPointConnectionName=$(az network private-endpoint-connection list -g $resourceGroupName -n $storageAcctName --type Microsoft.Storage/storageAccounts -o tsv --query "[?contains(@.properties.privateLinkServiceConnectionState.status, 'Pending')==\`true\`].name") az network private-endpoint-connection approve -g $resourceGroupName -n $endPointConnectionName --resource-name $storageAcctName --type Microsoft.Storage/storageAccounts --description "Approved" # SQL Database managed private endpoint approval resourceGroupName=$(az group list -o tsv --query "[?contains(@.name, '-dev-dp001')==\`true\`].name") sqlServerName=$(az sql server list -g $resourceGroupName -o tsv --query "[?contains(@.name, 'sqlserver001')==\`true\`].name") endPointConnectionName=$(az network private-endpoint-connection list -g $resourceGroupName -n $sqlServerName --type Microsoft.Sql/servers -o tsv --query "[?contains(@.properties.privateLinkServiceConnectionState.status, 'Pending')==\`true\`].name") az network private-endpoint-connection approve -g $resourceGroupName -n $endPointConnectionName --resource-name $sqlServerName --type Microsoft.Sql/servers --description "Approved" # Key Vault private endpoint approval resourceGroupName=$(az group list -o tsv --query "[?contains(@.name, '-dev-metadata')==\`true\`].name") keyVaultName=$(az keyvault list -g $resourceGroupName -o tsv --query "[?contains(@.name, 'dev-vault001')==\`true\`].name") endPointConnectionID=$(az network private-endpoint-connection list -g $resourceGroupName -n $keyVaultName --type Microsoft.Keyvault/vaults -o tsv --query "[?contains(@.properties.privateLinkServiceConnectionState.status, 'Pending')==\`true\`].id") az network private-endpoint-connection approve -g $resourceGroupName --id $endPointConnectionID --resource-name $keyVaultName --type Microsoft.Keyvault/vaults --description "Approved" # Purview private endpoint approval resourceGroupName=$(az group list -o tsv --query "[?contains(@.name, 'dev-governance')==\`true\`].name") purviewAcctName=$(az purview account list -g $resourceGroupName -o tsv --query "[?contains(@.name, '-dev-purview001')==\`true\`].name") for epn in $(az network private-endpoint-connection list -g $resourceGroupName -n $purviewAcctName --type Microsoft.Purview/accounts -o tsv --query "[?contains(@.properties.privateLinkServiceConnectionState.status, 'Pending')==\`true\`].name") do az network private-endpoint-connection approve -g $resourceGroupName -n $epn --resource-name $purviewAcctName --type Microsoft.Purview/accounts --description "Approved" done
I följande exempel visas hur <DLZ-prefix>devraw lagringskontot hanterar privata åtkomstbegäranden för slutpunkter. I resursmenyn för lagringskontot väljer du Nätverk. I kommandofältet väljer du Privata slutpunktsanslutningar.

För vissa Azure-resurser väljer du Privata slutpunktsanslutningar på resursmenyn. Ett exempel för Azure SQL-servern visas i följande skärmbild.
Om du vill godkänna en privat slutpunktsåtkomstbegäran går du till Privata slutpunktsanslutningar, väljer den väntande åtkomstbegäran och väljer sedan Godkänn:

När du har godkänt åtkomstbegäran i varje nödvändig tjänst kan det ta några minuter innan begäran visas som Godkänd i hanterade privata slutpunkter i Data Factory Studio. Även om du väljer Uppdatera i kommandofältet kan godkännandetillståndet vara inaktuellt i några minuter.
När du är klar med godkännandet av alla åtkomstbegäranden för de tjänster som krävs i Hanterade privata slutpunkter är värdet godkännandetillstånd för alla tjänster Godkänt:
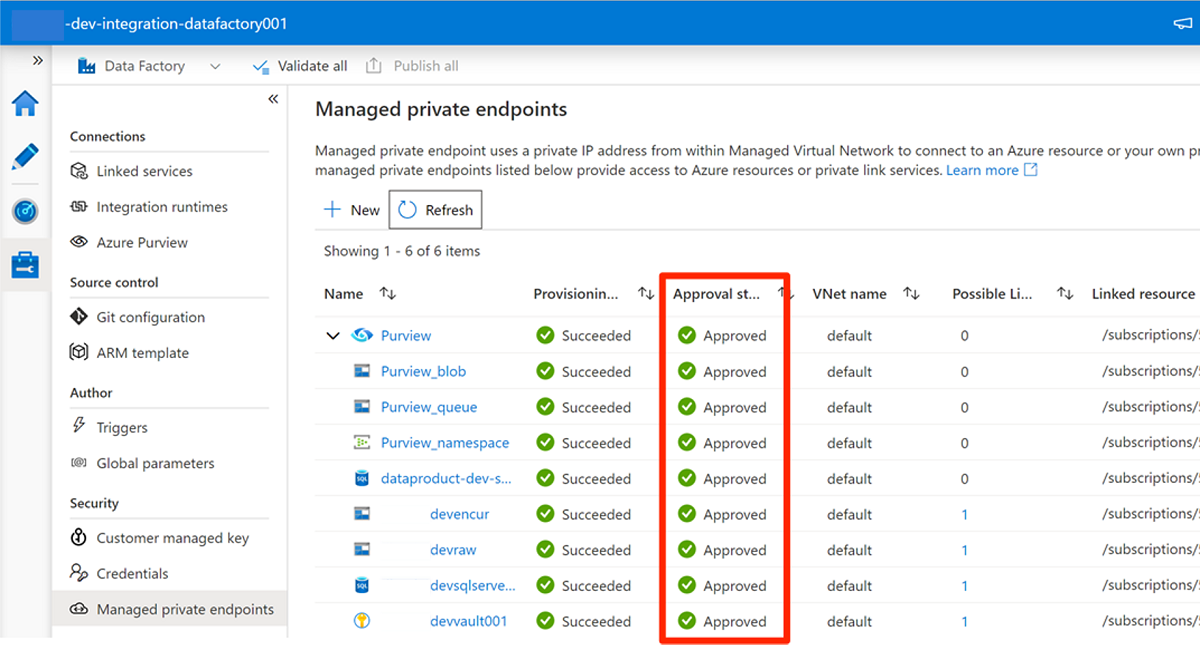
Rolltilldelningar
När du har godkänt åtkomstbegäranden för privata slutpunkter lägger du till lämpliga rollbehörigheter för Data Factory för att få åtkomst till dessa resurser:
- SQL Database-instanser
AdatumCRMochAdatumERPi<DP-prefix>-dev-sqlserver001Azure SQL-servern - Lagringskonton
<DLZ-prefix>devraw,<DLZ-prefix>devencuroch<DLZ-prefix>devwork - Purview-konto
<DMLZ-prefix>-dev-purview001
Virtuell Azure SQL-dator
Om du vill lägga till rolltilldelningar börjar du med den virtuella Azure SQL-datorn.
<DMLZ-prefix>-dev-dp001I resursgruppen går du till<DP-prefix>-dev-sqlserver001.Välj Åtkomstkontroll (IAM) på resursmenyn. I kommandofältet väljer du Lägg till lägg till>rolltilldelning.
På fliken Roll väljer du Deltagare och sedan Nästa.
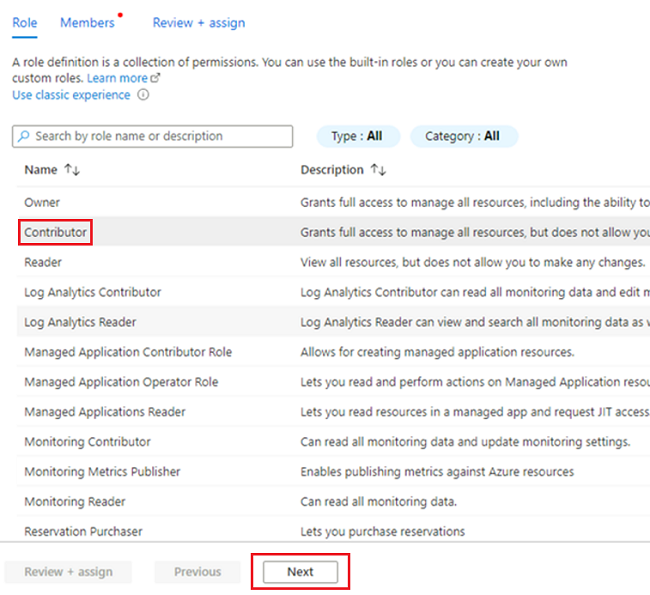
I Medlemmar för Tilldela åtkomst till väljer du Hanterad identitet. För Medlemmar väljer du Välj medlemmar.
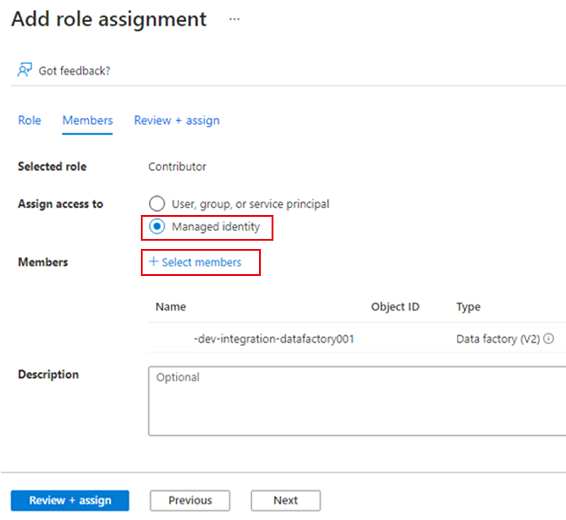
I Välj hanterade identiteter väljer du din Azure-prenumeration. För Hanterad identitet väljer du Data Factory (V2) för att se tillgängliga datafabriker. I listan över datafabriker väljer du Azure Data Factory <DLZ-prefix-dev-integration-datafactory001>. Välj Välj.
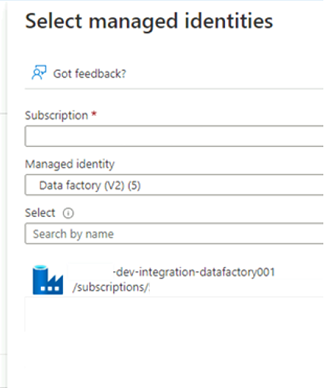
Välj Granska + Tilldela två gånger för att slutföra processen.
Lagringskonton
Tilldela sedan de nödvändiga rollerna till <DLZ-prefix>devraw, <DLZ-prefix>devencuroch <DLZ-prefix>devwork lagringskontona.
Om du vill tilldela rollerna utför du samma steg som du använde för att skapa rolltilldelningen för Azure SQL-servern. Men för rollen väljer du Storage Blob Data Contributor i stället för Deltagare.
När du har tilldelat roller för alla tre lagringskontona kan Data Factory ansluta till och komma åt lagringskontona.
Microsoft Purview
Det sista steget för att lägga till rolltilldelningar är att lägga till rollen Purview Data Curator i Microsoft Purview till datafabrikens <DLZ-prefix>-dev-integration-datafactory001 hanterade identitetskonto. Slutför följande steg så att Data Factory kan skicka tillgångsinformation för datakatalogen från flera datakällor till Purview-kontot.
I resursgruppen
<DMLZ-prefix>-dev-governancegår du till<DMLZ-prefix>-dev-purview001Purview-kontot.I Purview Studio väljer du ikonen Datakarta och sedan Samlingar.
Välj fliken Rolltilldelningar för samlingen. Under Datakuratorer lägger du till den hanterade identiteten för
<DLZ-prefix>-dev-integration-datafactory001: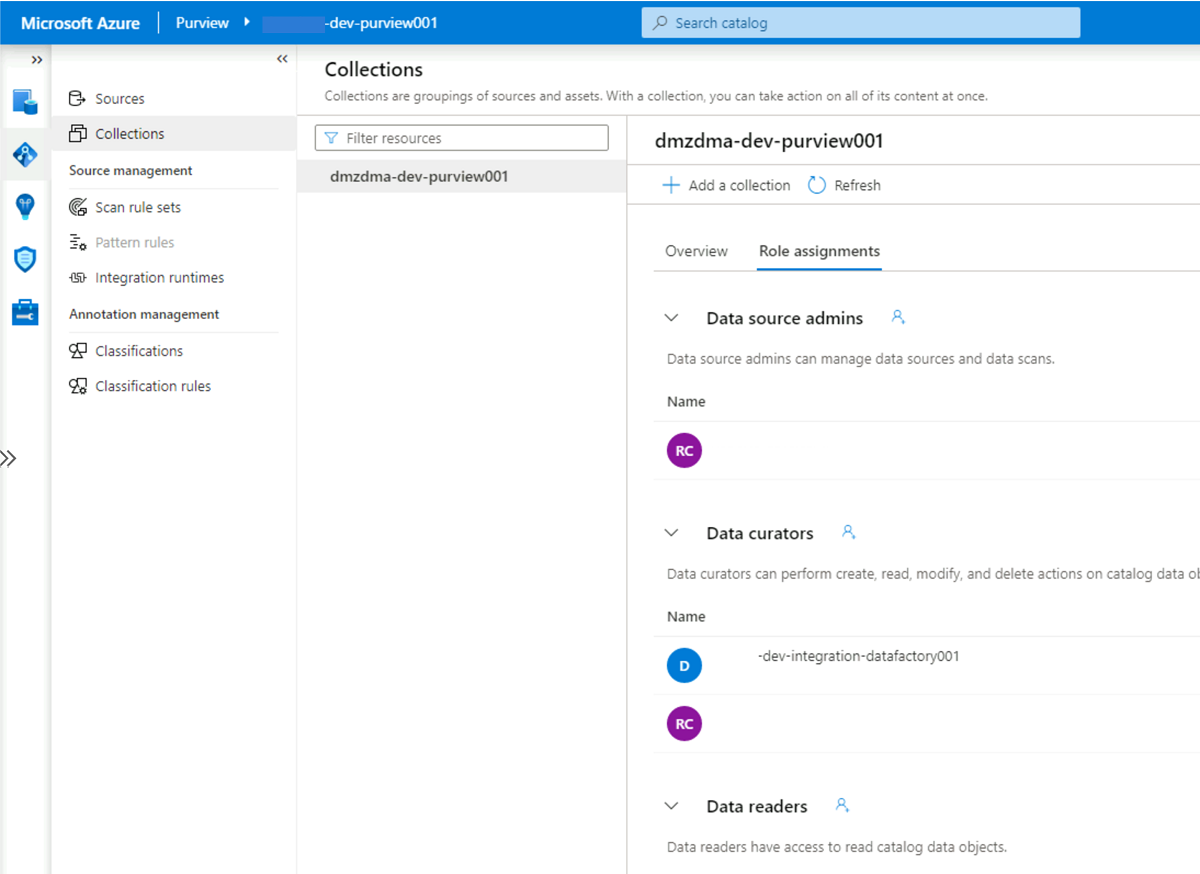
Anslut Data Factory till Purview
Behörigheterna har angetts och Purview kan nu se datafabriken. Nästa steg är att ansluta <DMLZ-prefix>-dev-purview001 till <DLZ-prefix>-dev-integration-datafactory001.
I Purview Studio väljer du ikonen Hantering och sedan Data Factory. Välj Ny för att skapa en Data Factory-anslutning.
I fönstret Nya Data Factory-anslutningar anger du din Azure-prenumeration och väljer datafabriken
<DLZ-prefix>-dev-integration-datafactory001. Välj OK.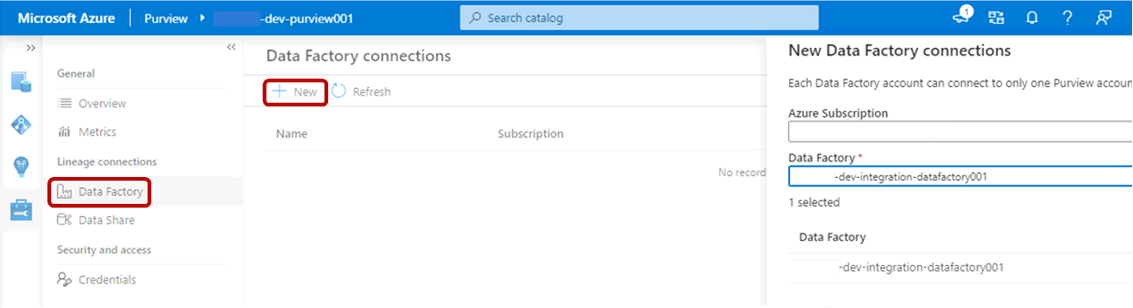
I Data Factory Studio-instansen
<DLZ-prefix>-dev-integration-datafactory001, under Hantera>Azure Purview, uppdaterar du Azure Purview-kontot.Integreringen
Data Lineage - Pipelinevisar nu den gröna Anslut ikonen.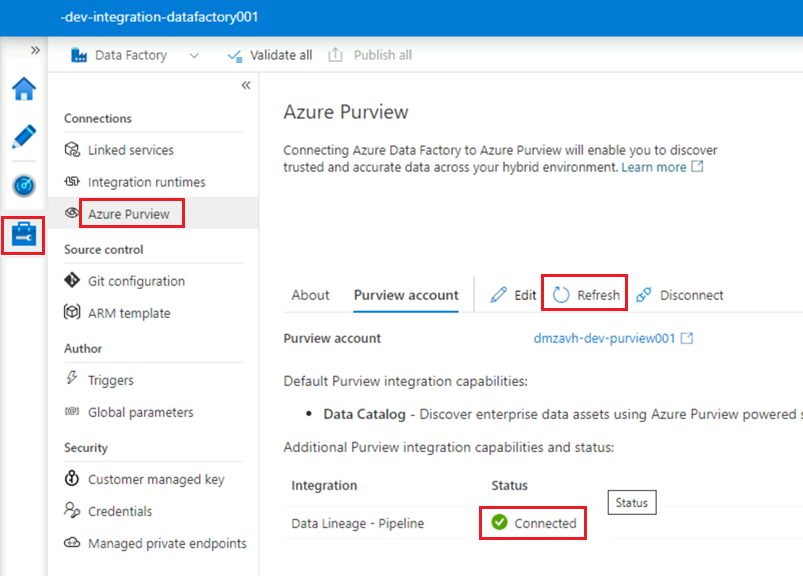

Skapa en ETL-pipeline
Nu när den <DLZ-prefix>-dev-integration-datafactory001 har nödvändiga åtkomstbehörigheter skapar du en kopieringsaktivitet i Data Factory för att flytta data från SQL Database-instanser till det <DLZ-prefix>devraw råa lagringskontot.
Använda verktyget Kopiera data med AdatumCRM
Den här processen extraherar kunddata från SQL Database-instansen AdatumCRM och kopierar dem till Data Lake Storage Gen2-lagring.
I Data Factory Studio väljer du ikonen Författare och sedan Fabriksresurser. Välj plustecknet (+) och välj Verktyget Kopiera data.
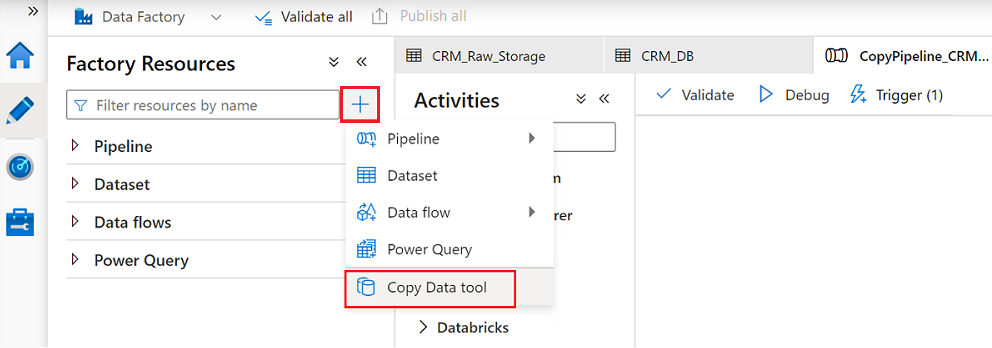
Slutför varje steg i guiden Kopiera data:
Om du vill skapa en utlösare för att köra pipelinen var 24:e timme väljer du Schema.
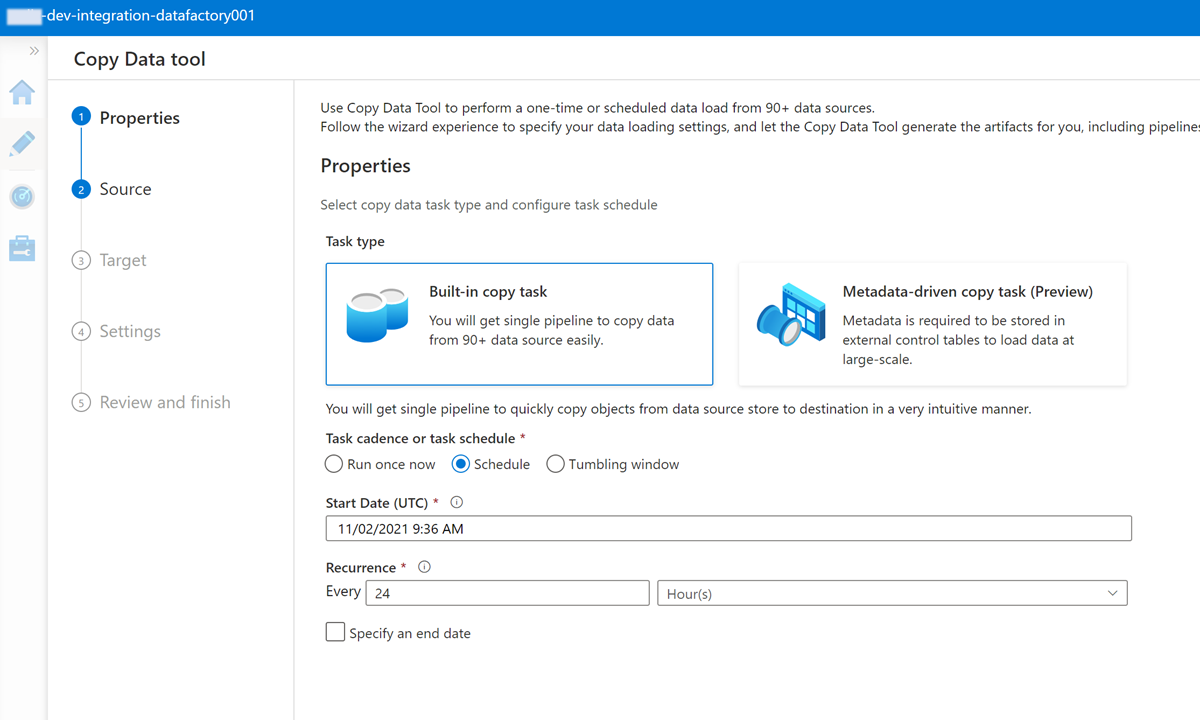
Om du vill skapa en länkad tjänst för att ansluta den här datafabriken
AdatumCRMtill SQL Database-instansen<DP-prefix>-dev-sqlserver001på servern (källa) väljer du Ny Anslut ion.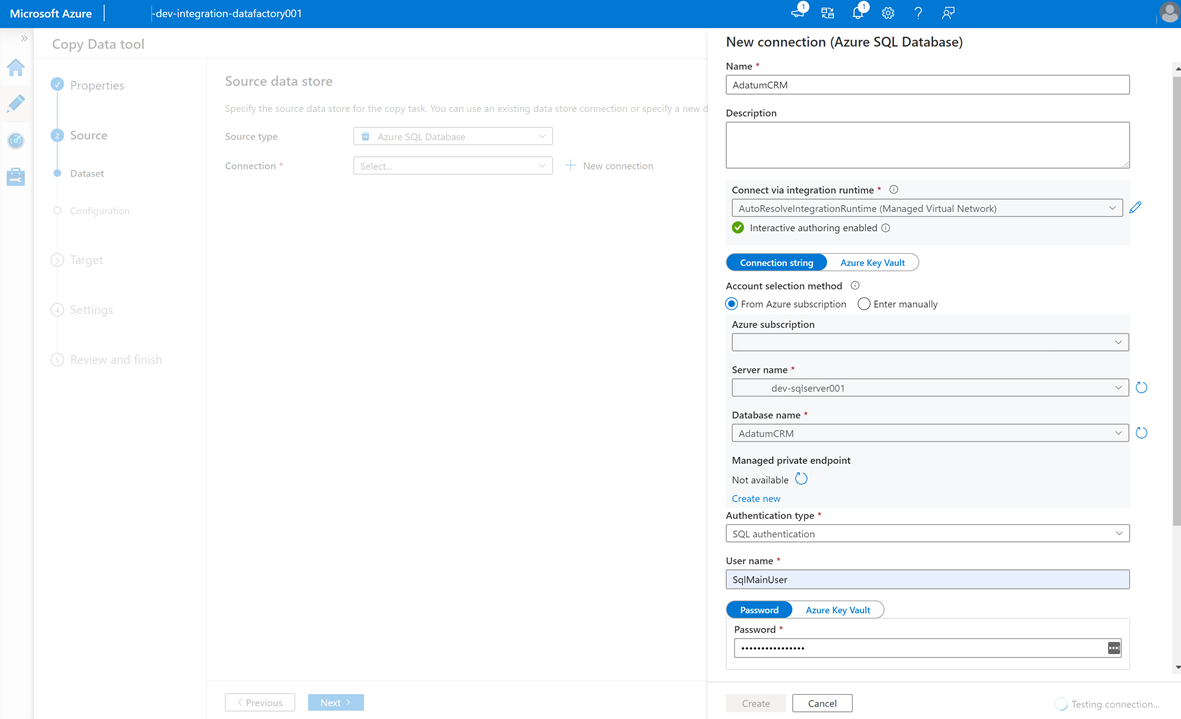
Kommentar
Om det uppstår fel vid anslutning till eller åtkomst till data i SQL Database-instanserna eller lagringskontona granskar du dina behörigheter i Azure-prenumerationen. Kontrollera att datafabriken har nödvändiga autentiseringsuppgifter och åtkomstbehörigheter till alla problematiska resurser.
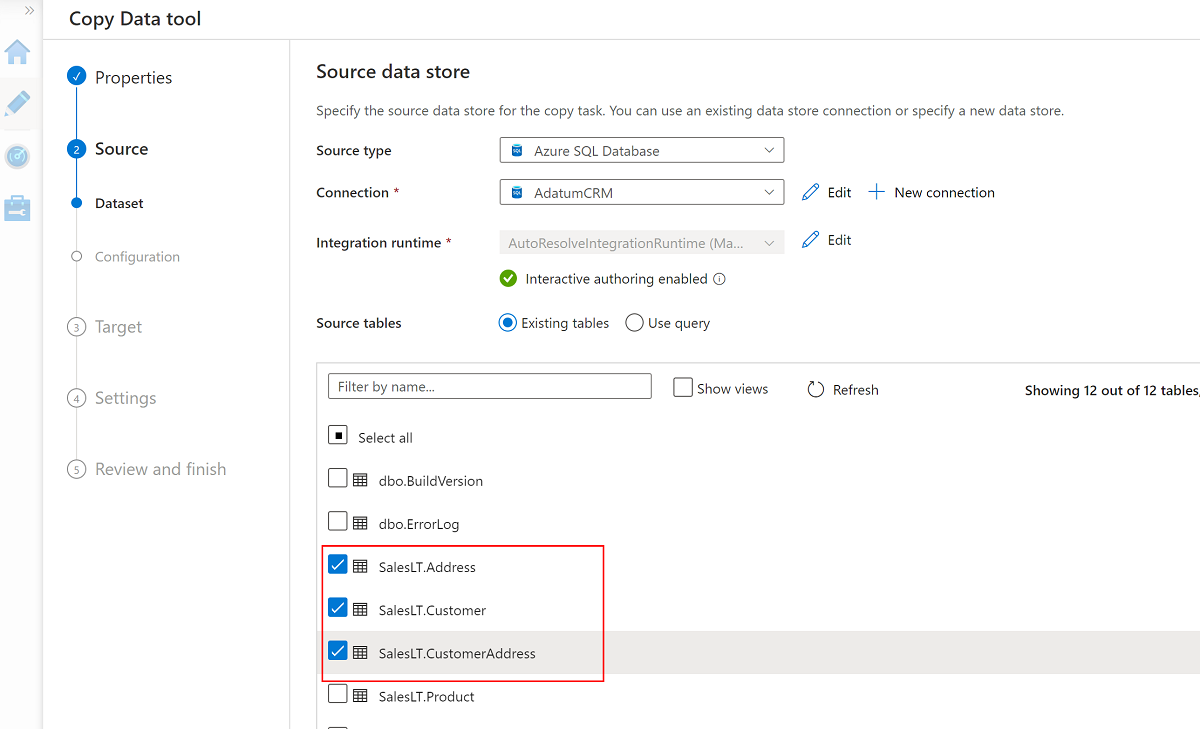
Välj dessa tre tabeller:
SalesLT.AddressSalesLT.CustomerSalesLT.CustomerAddress
Skapa en ny länkad tjänst för att få åtkomst till
<DLZ-prefix>devrawAzure Data Lake Storage Gen2-lagringen (mål).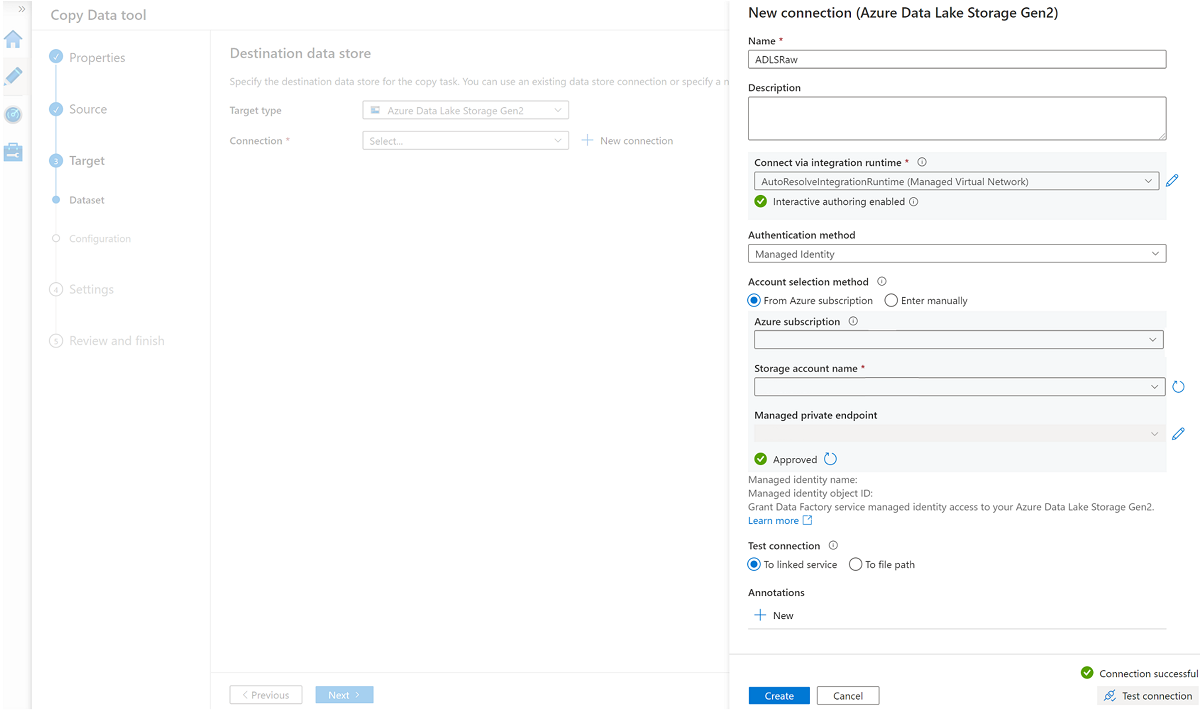
Bläddra bland mapparna i lagringen
<DLZ-prefix>devrawoch välj Data som mål.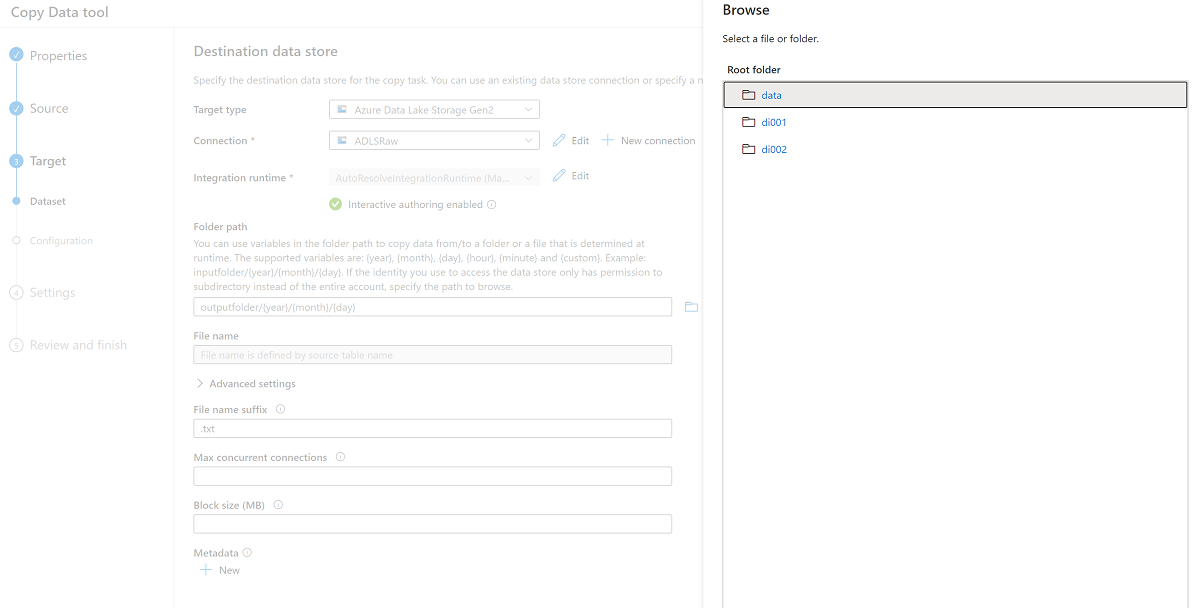
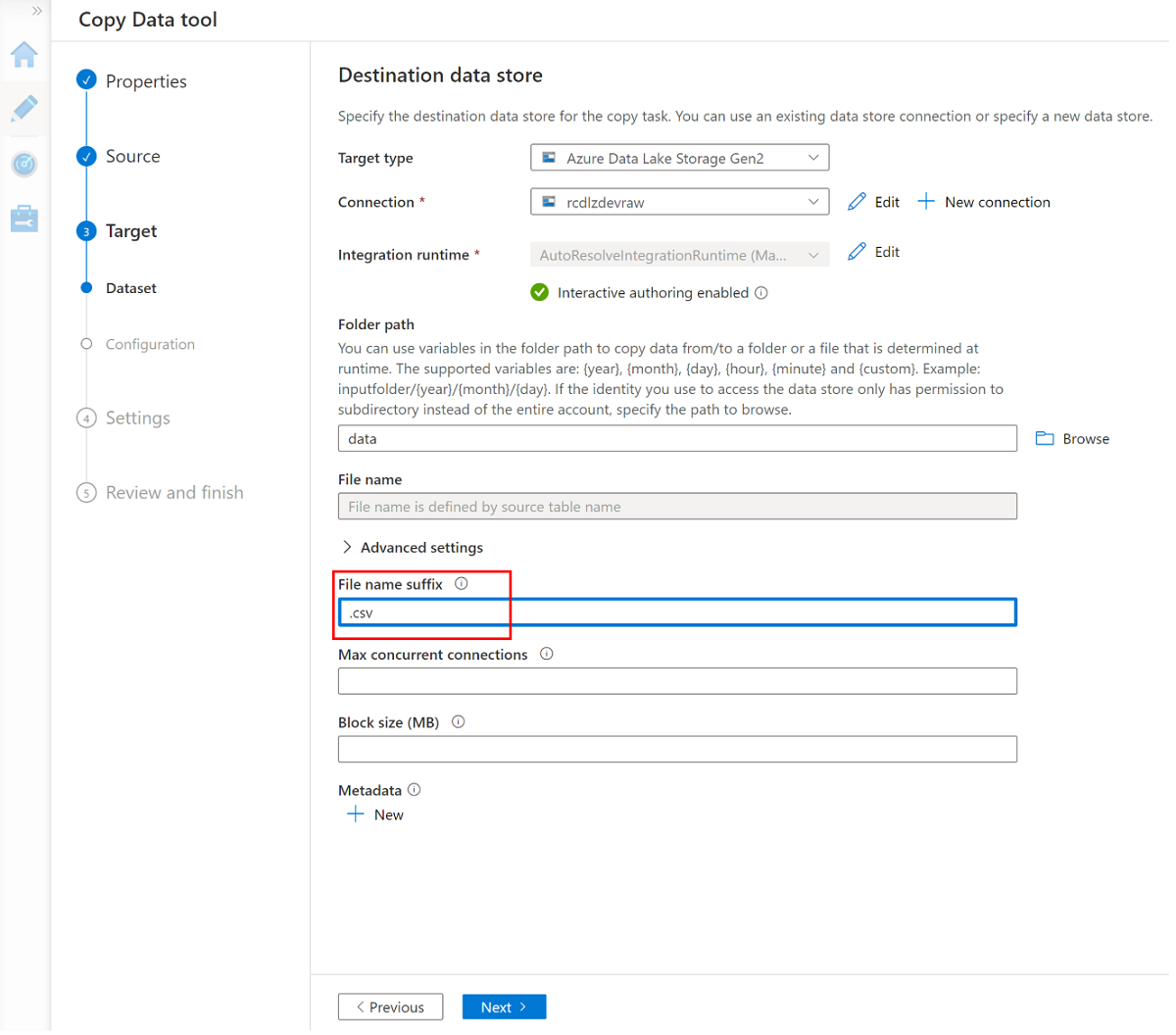
Ändra filnamnssuffixet till .csv och använd de andra standardalternativen.
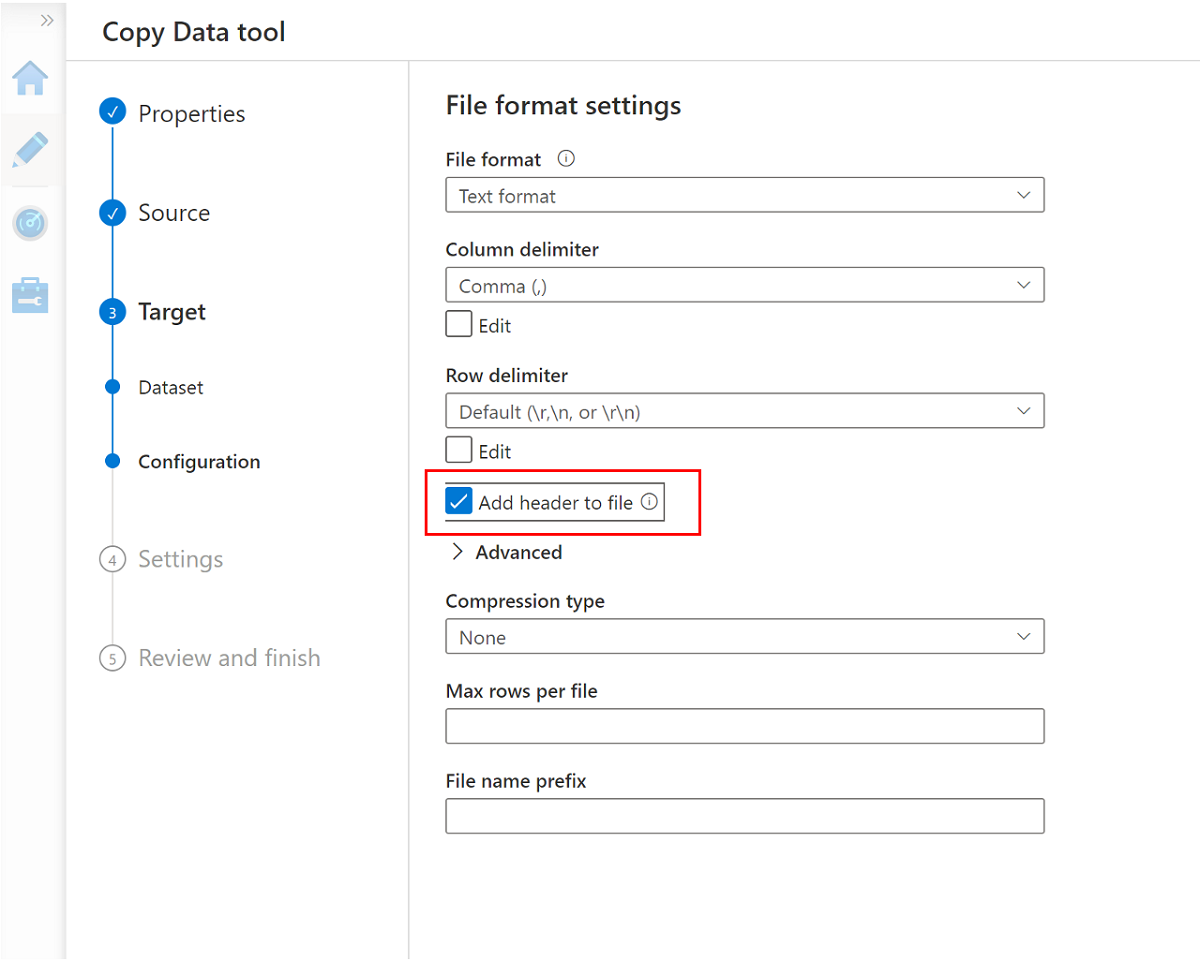
Gå till nästa fönster och välj Lägg till rubrik i filen.
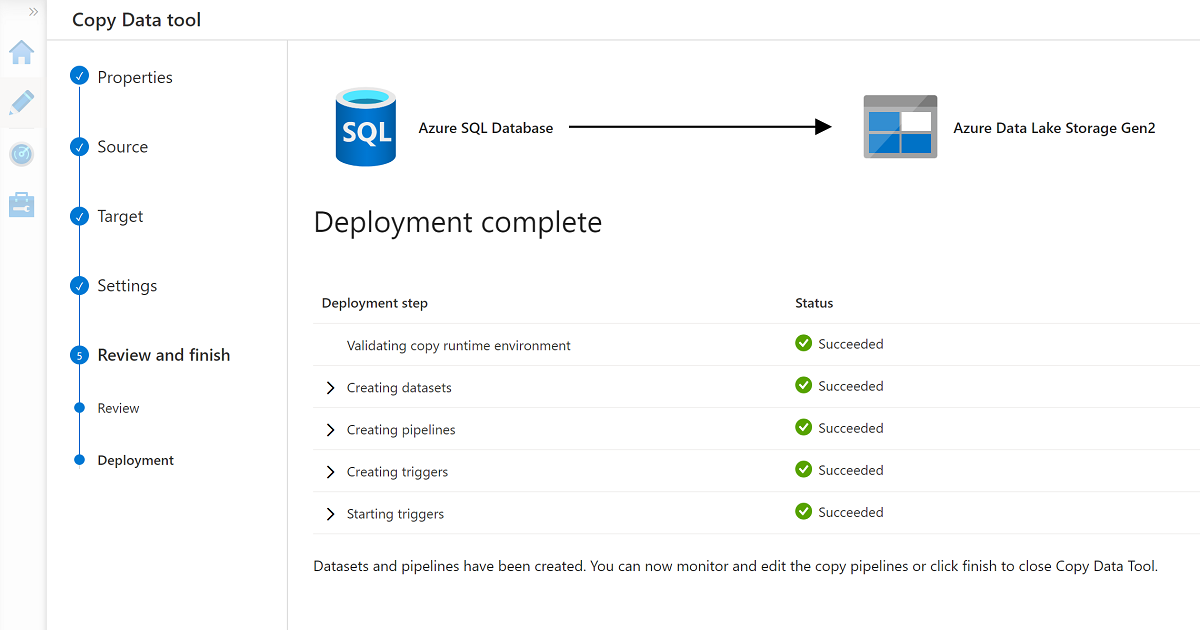
När du är klar med guiden ser fönstret Distribution färdigt ut ungefär som i det här exemplet:




Den nya pipelinen visas i Pipelines.
Köra pipelinen
Den här processen skapar tre .csv filer i mappen Data\CRM , en för var och en av de valda tabellerna AdatumCRM i databasen.
Byt namn på pipelinen
CopyPipeline_CRM_to_Raw.Byt namn på datauppsättningarna
CRM_Raw_StorageochCRM_DB.I kommandofältet Fabriksresurser väljer du Publicera alla.
Välj pipelinen
CopyPipeline_CRM_to_Rawoch välj Utlösa i pipelinekommandofältet för att kopiera de tre tabellerna från SQL Database till Data Lake Storage Gen2.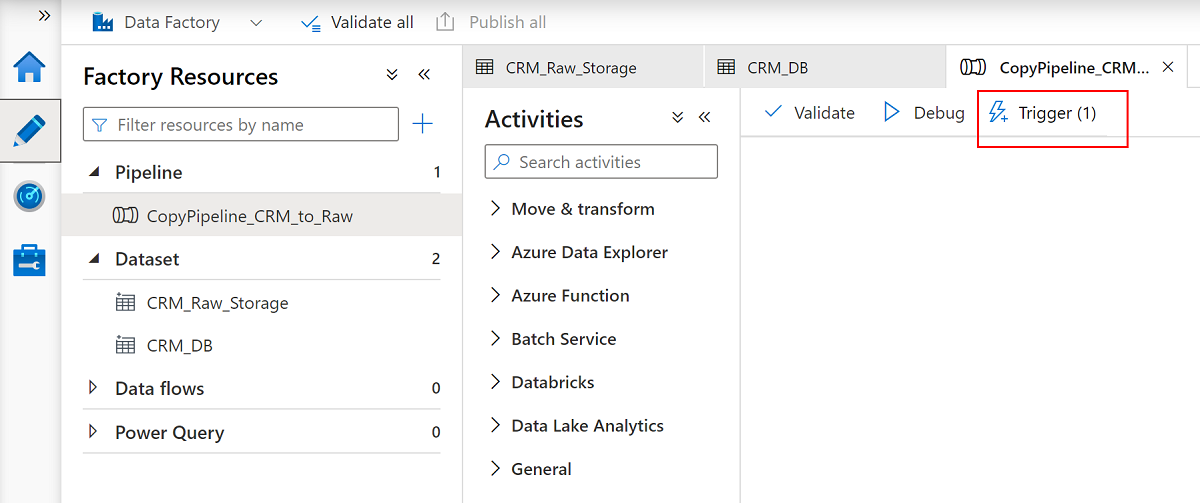
Använda verktyget Kopiera data med AdatumERP
Extrahera sedan data från AdatumERP databasen. Data representerar försäljningsdata som kommer från ERP-systemet.
Skapa en ny pipeline i Data Factory Studio med verktyget Kopiera data. Den här gången skickar du försäljningsdata från
AdatumERPtill<DLZ-prefix>devrawlagringskontots datamapp, på samma sätt som du gjorde med CRM-data. Utför samma steg, men användAdatumERPdatabasen som källa.Skapa schemat som ska utlösas varje timme.
Skapa en länkad tjänst till SQL Database-instansen
AdatumERP.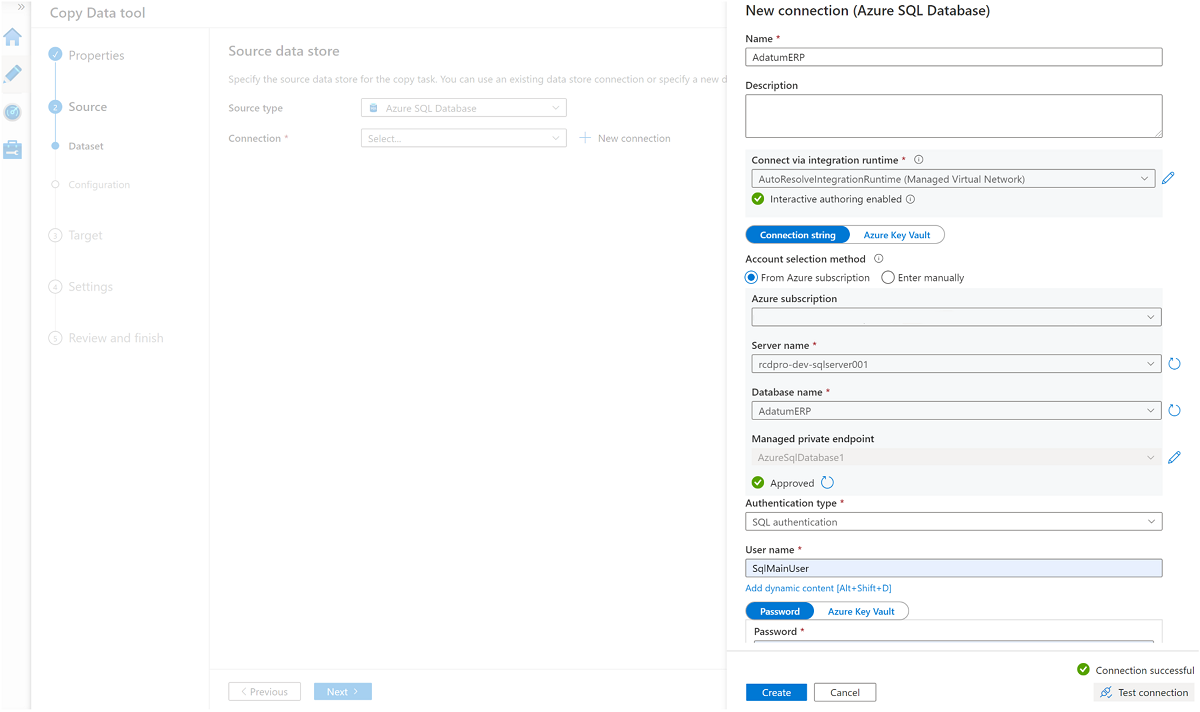
Välj dessa sju tabeller:
SalesLT.ProductSalesLT.ProductCategorySalesLT.ProductDescriptionSalesLT.ProductModelSalesLT.ProductModelProductDescriptionSalesLT.SalesOrderDetailSalesLT.SalesOrderHeader
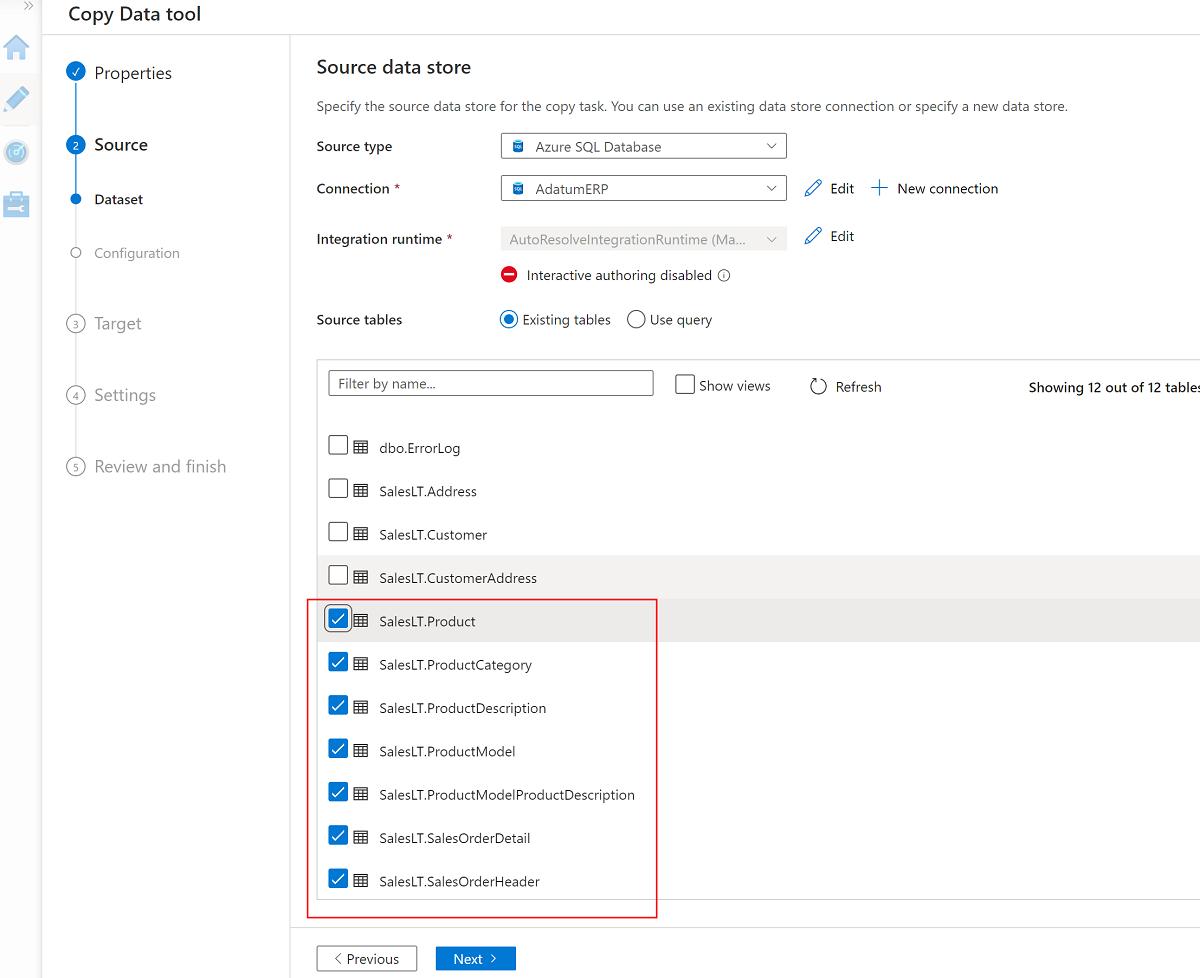
Använd den befintliga länkade tjänsten till lagringskontot
<DLZ-prefix>devrawoch ange filnamnstillägget till .csv.
Välj Lägg till rubrik i filen.
Slutför guiden igen och byt namn på pipelinen
CopyPipeline_ERP_to_DevRaw. Välj sedan Publicera alla i kommandofältet. Kör slutligen utlösaren på den här nyligen skapade pipelinen för att kopiera de sju valda tabellerna från SQL Database till Data Lake Storage Gen2.

När du är klar med de här stegen finns 10 CSV-filer i Data Lake Storage Gen2-lagringen <DLZ-prefix>devraw . I nästa avsnitt kurerar du filerna i <DLZ-prefix>devencur Data Lake Storage Gen2-lagringen.
Kurera data i Data Lake Storage Gen2
När du är klar med att skapa de 10 CSV-filerna i den råa <DLZ-prefix>devraw Data Lake Storage Gen2-lagringen omvandlar du filerna efter behov när du kopierar dem till den kuraterade <DLZ-prefix>devencur Data Lake Storage Gen2-lagringen.
Fortsätt att använda Azure Data Factory för att skapa dessa nya pipelines för att samordna dataflytt.
Kurera CRM till kunddata
Skapa ett dataflöde som hämtar CSV-filerna i mappen Data\CRM i <DLZ-prefix>devraw. Transformera filerna och kopiera transformerade filer i .parquet-filformat till mappen Data\Customer i <DLZ-prefix>devencur.
I Azure Data Factory går du till datafabriken och väljer Orchestrate.
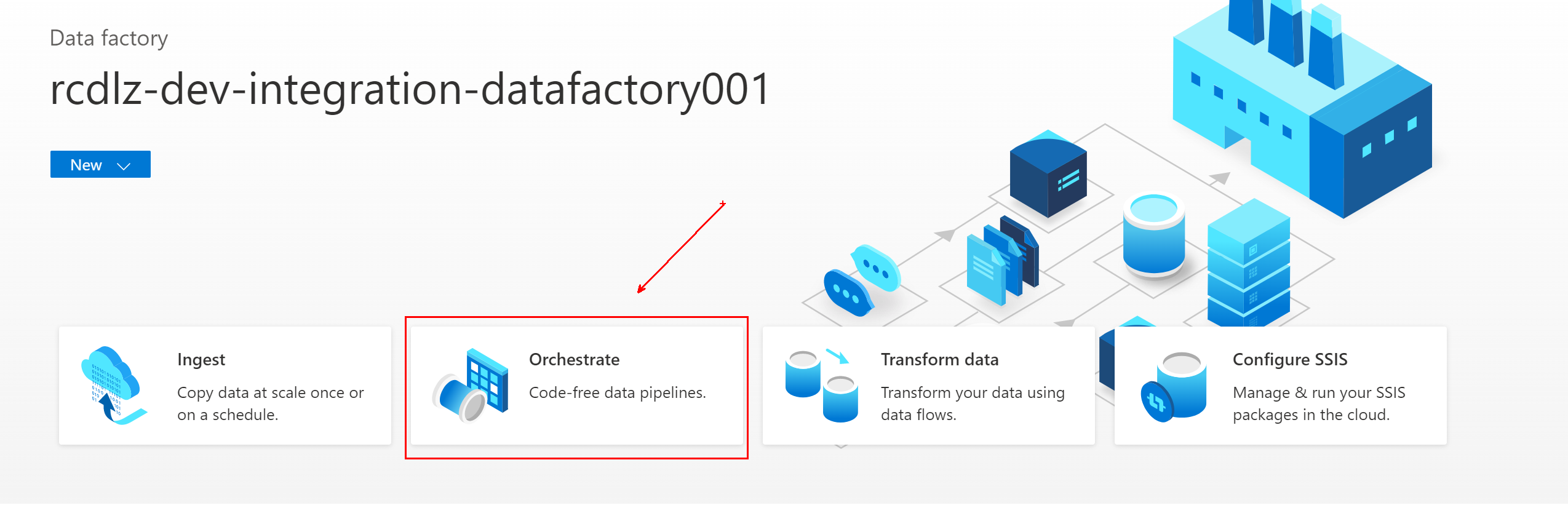
I Allmänt namnger du pipelinen
Pipeline_transform_CRM.I fönstret Aktiviteter expanderar du Flytta och transformera. Dra dataflödesaktiviteten och släpp den i pipelinearbetsytan.
I Lägga till Dataflöde väljer du Skapa nytt dataflöde och namnger dataflödet
CRM_to_Customer. Välj Slutför.Kommentar
I kommandofältet på pipelinearbetsytan aktiverar du Felsökning av dataflöde. I felsökningsläge kan du interaktivt testa omvandlingslogik mot ett Live Apache Spark-kluster. Det tar 5 till 7 minuter att värma upp dataflödeskluster. Vi rekommenderar att du aktiverar felsökning innan du påbörjar dataflödesutvecklingen.

När du är klar med att välja alternativen i
CRM_to_Customerdataflödet ser pipelinenPipeline_transform_CRMut ungefär som i det här exemplet: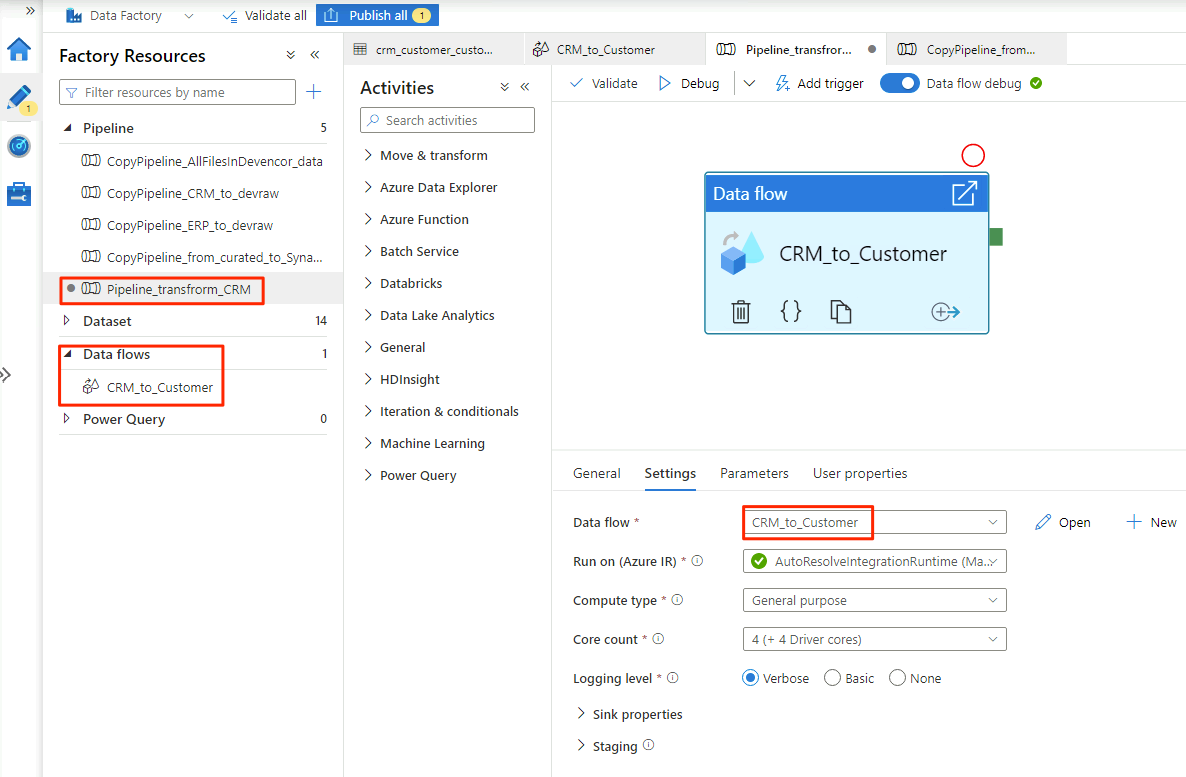
Dataflödet ser ut så här:
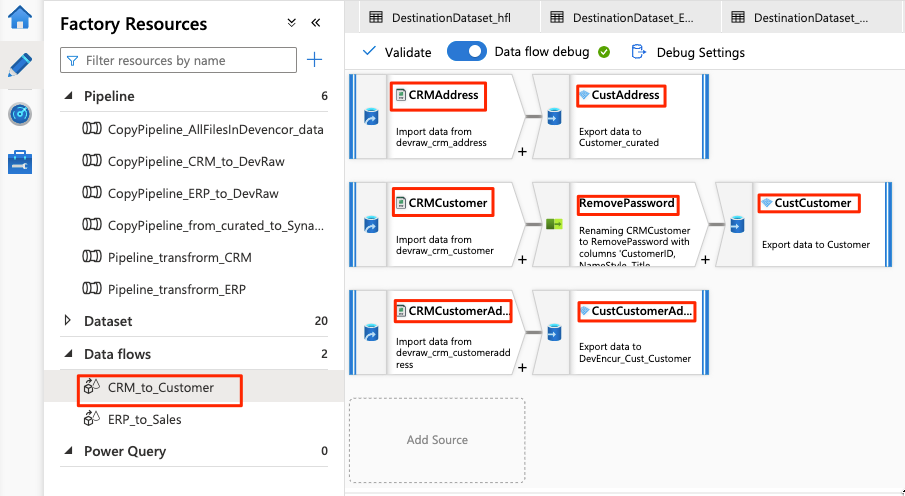
Ändra sedan de här inställningarna i dataflödet för
CRMAddresskällan:Skapa en ny datauppsättning från Data Lake Storage Gen2. Använd formatet DelimitedText. Ge datamängden
DevRaw_CRM_Addressnamnet .Anslut den länkade tjänsten till
<DLZ-prefix>devraw.Data\CRM\SalesLTAddress.csvVälj filen som källa.
Ändra de här inställningarna i dataflödet för den kopplade
CustAddressmottagaren:Skapa en ny datauppsättning med namnet
DevEncur_Cust_Address.Välj mappen Data\Customer i
<DLZ-prefix>devencursom mottagare.Under Inställningar\Output to single file (Utdata till en enda fil) konverterar du filen till Address.parquet.
För resten av dataflödeskonfigurationen använder du informationen i följande tabeller för varje komponent. Observera att CRMAddress och CustAddress är de två första raderna. Använd dem som exempel för de andra objekten.
Ett objekt som inte finns i någon av följande tabeller är RemovePasswords schemamodifieraren. Föregående skärmbild visar att det här objektet går mellan CRMCustomer och CustCustomer. Om du vill lägga till den här schemamodifieraren går du till Välj inställningar och tar bort PasswordHash och PasswordSalt.
CRMCustomer returnerar ett schema med 15 kolumner från .crv-filen. CustCustomer skriver bara 13 kolumner efter att schemamodifieraren tar bort de två lösenordskolumnerna.
Den fullständiga tabellen
| Name | Object type | Namn på datauppsättning | Datalager | Formattyp | Länkad tjänst | Filen eller mappen |
|---|---|---|---|---|---|---|
CRMAddress |
source | DevRaw_CRM_Address |
Azure Data Lake Storage Gen2 | Avgränsadtext | devraw |
Data\CRM\SalesLTAddress.csv |
CustAddress |
Diskbänken | DevEncur_Cust_Address |
Azure Data Lake Storage Gen2 | Parquet | devencur |
Data\Customer\Address.parquet |
CRMCustomer |
source | DevRaw_CRM_Customer |
Azure Data Lake Storage Gen2 | Avgränsadtext | devraw |
Data\CRM\SalesLTCustomer.csv |
CustCustomer |
Diskbänken | DevEncur_Cust_Customer |
Azure Data Lake Storage Gen2 | Parquet | devencur |
Data\Customer\Customer.parquet |
CRMCustomerAddress |
source | DevRaw_CRM_CustomerAddress |
Azure Data Lake Storage Gen2 | Avgränsadtext | devraw |
Data\CRM\SalesLTCustomerAddress.csv |
CustCustomerAddress |
Diskbänken | DevEncur_Cust_CustomerAddress |
Azure Data Lake Storage Gen2 | Parquet | devencur |
Data\Customer\CustomerAddress.parquet |
Tabellen ERP till försäljning
Upprepa nu liknande steg för att skapa en Pipeline_transform_ERP pipeline, skapa ett ERP_to_Sales dataflöde för att transformera .csv-filerna i mappen Data\ERP i <DLZ-prefix>devrawoch kopiera de transformerade filerna till mappen Data\Sales i <DLZ-prefix>devencur.
I följande tabell hittar du de objekt som ska skapas i ERP_to_Sales dataflödet och de inställningar som du behöver ändra för varje objekt. Varje .csv fil mappas till en .parquet-mottagare .
| Name | Object type | Namn på datauppsättning | Datalager | Formattyp | Länkad tjänst | Filen eller mappen |
|---|---|---|---|---|---|---|
ERPProduct |
source | DevRaw_ERP_Product |
Azure Data Lake Storage Gen2 | Avgränsadtext | devraw |
Data\ERP\SalesLTProduct.csv |
SalesProduct |
Diskbänken | DevEncur_Sales_Product |
Azure Data Lake Storage Gen2 | Parquet | devencur |
Data\Sales\Product.parquet |
ERPProductCategory |
source | DevRaw_ERP_ProductCategory |
Azure Data Lake Storage Gen2 | Avgränsadtext | devraw |
Data\ERP\SalesLTProductCategory.csv |
SalesProductCategory |
Diskbänken | DevEncur_Sales_ProductCategory |
Azure Data Lake Storage Gen2 | Parquet | devencur |
Data\Sales\ProductCategory.parquet |
ERPProductDescription |
source | DevRaw_ERP_ProductDescription |
Azure Data Lake Storage Gen2 | Avgränsadtext | devraw |
Data\ERP\SalesLTProductDescription.csv |
SalesProductDescription |
Diskbänken | DevEncur_Sales_ProductDescription |
Azure Data Lake Storage Gen2 | Parquet | devencur |
Data\Sales\ProductDescription.parquet |
ERPProductModel |
source | DevRaw_ERP_ProductModel |
Azure Data Lake Storage Gen2 | Avgränsadtext | devraw |
Data\ERP\SalesLTProductModel.csv |
SalesProductModel |
Diskbänken | DevEncur_Sales_ProductModel |
Azure Data Lake Storage Gen2 | Parquet | devencur |
Data\Sales\ProductModel.parquet |
ERPProductModelProductDescription |
source | DevRaw_ERP_ProductModelProductDescription |
Azure Data Lake Storage Gen2 | Avgränsadtext | devraw |
Data\ERP\SalesLTProductModelProductDescription.csv |
SalesProductModelProductDescription |
Diskbänken | DevEncur_Sales_ProductModelProductDescription |
Azure Data Lake Storage Gen2 | Parquet | devencur |
Data\Sales\ProductModelProductDescription.parquet |
ERPProductSalesOrderDetail |
source | DevRaw_ERP_ProductSalesOrderDetail |
Azure Data Lake Storage Gen2 | Avgränsadtext | devraw |
Data\ERP\SalesLTProductSalesOrderDetail.csv |
SalesProductSalesOrderDetail |
Diskbänken | DevEncur_Sales_ProductSalesOrderDetail |
Azure Data Lake Storage Gen2 | Parquet | devencur |
Data\Sales\ProductSalesOrderDetail.parquet |
ERPProductSalesOrderHeader |
source | DevRaw_ERP_ProductSalesOrderHeader |
Azure Data Lake Storage Gen2 | Avgränsadtext | devraw |
Data\ERP\SalesLTProductSalesOrderHeader.csv |
SalesProductSalesOrderHeader |
Diskbänken | DevEncur_Sales_ProductSalesOrderHeader |
Azure Data Lake Storage Gen2 | Parquet | devencur |
Data\Sales\ProductSalesOrderHeader.parquet |
Nästa steg
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för