Affärskontinuitet och haveriberedskap (BCDR) för Oracle på azure virtual machines-acceleratorn för landningszoner
Den här artikeln bygger på de överväganden och rekommendationer som definieras i designområdet för Azure-landningszoner för BCDR. Enligt vägledningen ger den här artikeln designöverväganden och metodtips kring alternativ för affärskontinuitet och haveriberedskap (BCDR) som är tillgängliga för Oracle-arbetsbelastningsdistributioner på virtuella Azure-infrastrukturdatorer.
Azure tillhandahåller tjänster för att utforma arkitektur med hög tillgänglighet och motståndskraft. Den här guiden beskriver olika alternativ och metodtips för att utforma hög tillgänglighet och haveriberedskap för Oracle-databaser på azure virtual machines-acceleratorn för landningszoner. Den beskriver också hur tillhörande Azure-tjänster konfigureras för att uppnå hög tillgänglighet från slutpunkt till slutpunkt för din lösning.
Det första steget för att skapa en elastisk arkitektur för din arbetsbelastningsmiljö är att fastställa tillgänglighetskrav för din lösning med mål för återställningstid (RTO) och mål för återställningspunkter (RPO) för olika felnivåer. RTO är den maximala tid som ett program inte är tillgängligt efter en incident och RPO är den maximala mängden dataförlust under en katastrof. När du har fastställt kraven för din lösning är nästa steg att utforma din arkitektur för att tillhandahålla de etablerade nivåerna av återhämtning och tillgänglighet.
Oracle på Azure-arbetsbelastningar använder främst Data Guard, den inbyggda replikeringstekniken för Oracle-databaser (som en funktion i Enterprise Edition), för att uppfylla både hög tillgänglighet och haveriberedskapsbehov. Data Guard erbjuder tre skyddslägen: Högsta prestanda, Maximal tillgänglighet och Maximalt skydd. Valet av skyddsläge beror på arkitekturdesignen och de specifika RPO- och RTO-kraven.
Hög tillgänglighet för Oracle-arbetsbelastningar på Azure Virtual Machines-acceleratorn för landningszoner
Azure Virtual Machine-instanser som kör Oracle-arbetsbelastningar drar nytta av tillgänglighetsuppsättningsarkitekturen. Konfiguration med hög tillgänglighet ger datareplikering i nästan realtid med potentiellt snabba redundansfunktioner, men ger inte skydd för fel på Azure-datacenternivå eller regionnivå.
Välj rätt alternativ för hög tillgänglighet
Använd följande flödesschema för att välja det bästa alternativet för hög tillgänglighet för Oracle-databasen.

Hög tillgänglighet med Data Guard i läget för maximal tillgänglighet
Data Guard i läget för maximal tillgänglighet ger högsta tillgänglighet med ett löfte om noll dataförlust (RPO=0) för normala åtgärder. För högtillgänglig konfiguration av två Oracle-databasservrar som skapats i en tillgänglighetsuppsättning tillhandahåller Azure 99,95 % serviceavtal för tjänsttillgänglighet.
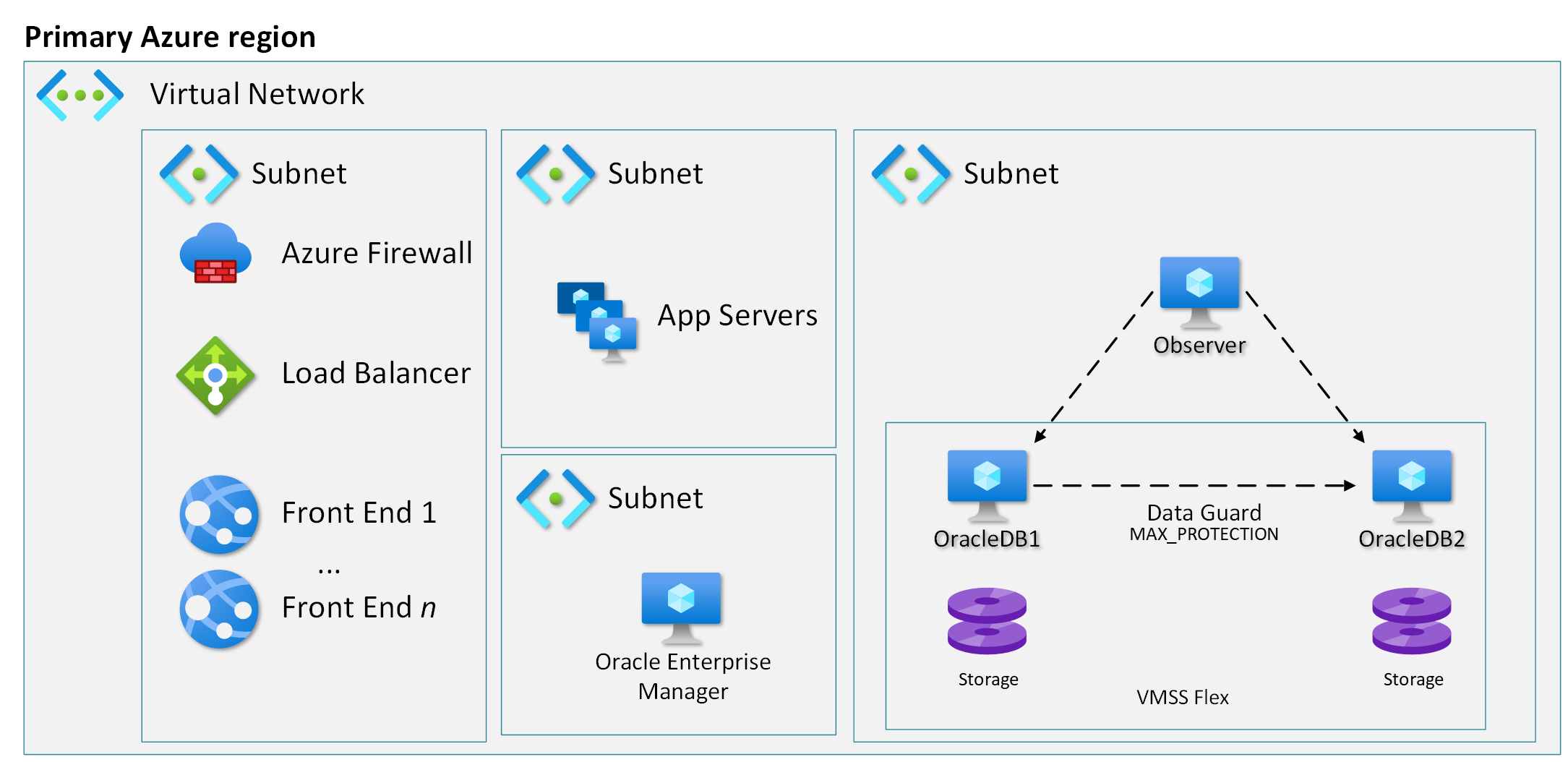
Hög tillgänglighet med Data Guard i maximalt skyddsläge
Om du alltid behöver en transaktionsmässigt konsekvent kopia av databasen kan du överväga att använda Data Guard i maximalt skyddsläge. Maximalt skyddsläge tillåter dock inte att transaktioner fortsätter när väntelägesdatabasen inte är tillgänglig. Trots att du använder tillgänglighetsuppsättningar minskas därför ditt serviceavtal till 99,9 %x99,9 %=99,8 % när du använder maximalt skyddsläge. Den här konfigurationen är mer för att säkerställa en konsekvent kopia av data i stället för att öka tillgängligheten.
Andra attribut i den här arkitekturen är samma som maximalt tillgänglighetsläge (dvs. RPO=0, RTO<=2 minuter).
Särskilda användningsöverväganden för hög tillgänglighet
I följande avsnitt beskrivs särskilda överväganden för hög tillgänglighet.
Använda tillgänglighetszoner jämfört med tillgänglighetsuppsättningar för hög tillgänglighet
Azure-tillgänglighetszoner är Azure-datacenter i samma Azure-region som garanterat har <svarstid på 2 ms tur och retur. Även om det normalt används för haveriberedskap som beskrivs senare, är det möjligt att använda dem för hög tillgänglighet i stället för tillgänglighetsuppsättningar. Du måste dock se till att din lösning kan köras med svarstiden och dataflödet mellan de tillgänglighetszoner som du använder.
En fördel med att använda tillgänglighetszoner jämfört med tillgänglighetsuppsättningar är att ditt serviceavtal ökar från 99,95 % till 99,99 %.
Kluster för delad lagring för hög tillgänglighet
Klustertekniker för delad lagring ger unika attribut som kan hjälpa dig att uppnå dina affärsmål. En sådan teknik som du kan anpassa i Azure är Pacemaker-/Corosync-kluster (PCS) med delad lagring. Du kan använda hanterade diskar eller Azure NetApp Files som delad lagring för PCS-klusterinstanser. Att använda PCS-kluster duplicerar inte data och tillhandahåller en virtuell IP-tjänst med en statisk IP-adress/ett nätverksnamn som inte ändras mellan redundansväxlingar.
OBS! PCS-kluster är inte en Oracle-certifierad lösning. Tänk på detta när du fastställer arkitekturen för hög tillgänglighet.

Använda närhetsplaceringsgrupper
Överväg att använda närhetsplaceringsgrupper för att säkerställa minsta svarstid mellan databasservrar i samma tillgänglighetsuppsättning och mellan databasservrar och programservrar för att minimera nätverksfördröjningen.
Haveriberedskap för Oracle på Azure-arbetsbelastningar
Arkitekturen för haveriberedskap ger motståndskraft mot fel som påverkar Azures datacenter eller region eller som hindrar programfunktioner i hela regionen. I vilket fall som helst vill du flytta hela arbetsbelastningen till ett annat datacenter eller en annan region.
Som tidigare nämnts bör haveriberedskapsarkitekturen baseras på dina lösningskrav enligt RTO och RPO. Eftersom haveriberedskapsarkitekturen är byggd för exceptionella fel är redundansprocessen manuell i stället för design med hög tillgänglighet. Generellt bör du ha mer avslappnade krav för RTO och RPO, vilket kan möjliggöra mer kostnadseffektiv design.
Det här dokumentet fokuserar på scenarier där både primära och sekundära servrar finns i Azure. Det är också möjligt att ha en primär server lokalt och sekundär server på Azure i haveriberedskapssyfte. Läs mer om det här scenariot i Haveriberedskap för en Oracle Database 12c-databas i en Azure-miljö.
Välj rätt alternativ för haveriberedskap
Använd följande flödesschema för att bestämma det bästa haveriberedskapsalternativet för Oracle-databasen.
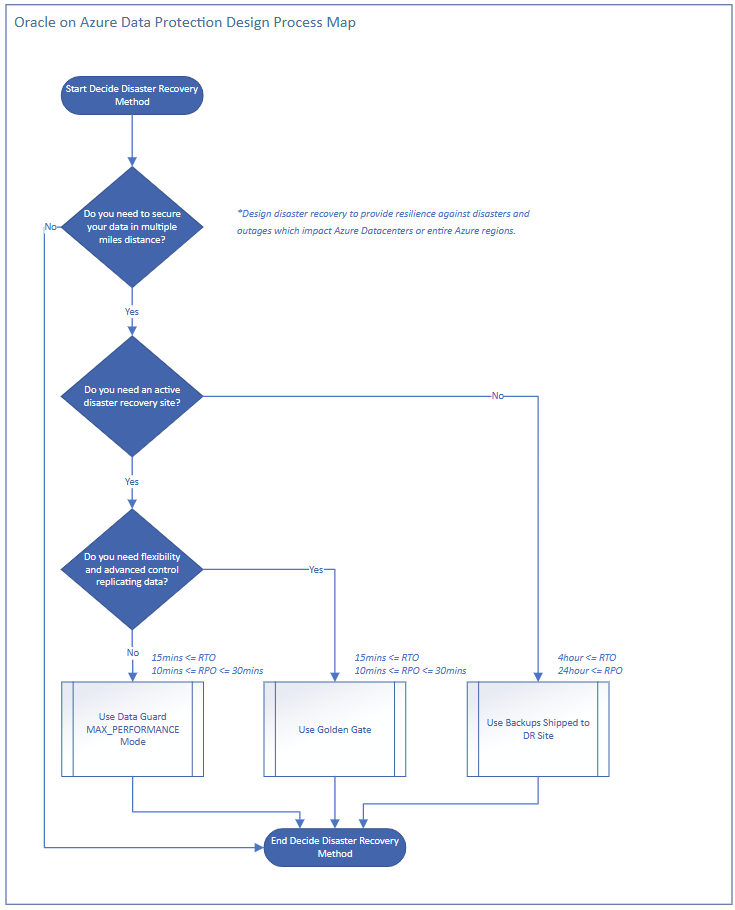
Haveriberedskap med Data Guard
Data Guard kan användas för att replikera data till din haveriberedskapsplats. Den platsen kan vara en annan tillgänglighetszon i samma region eller vara en annan region beroende på dina krav för dataskydd. Det är också beroende av den tillgänglighetszonstruktur som tillhandahålls på din produktionsplats. Att använda Oracle Data Guard i ett haveriberedskapsscenario liknar det scenario med hög tillgänglighet som beskrevs tidigare med några viktiga skillnader.
- När du redundansväxlar till en sekundär replik i ett scenario med hög tillgänglighet skickar du Azure Load Balancer för att omdirigera begäranden till en ny primär replik.
- När du redundansväxlar till haveriberedskapsplatsen redundansväxlar du hela lösningen till den nya platsen.
Om haveriberedskapsplatsen finns i en annan region måste du utforma den för redundansväxlingen beroende på dina krav.
Svarstiden mellan Azure-datacenter som är långt ifrån varandra och svarstiden mellan regioner eller datacenter är högre än svarstiden i samma datacenter. Därför är den minst komplexa och billigaste rekommendationen att använda Data Guard i maximalt prestandaläge för haveriberedskap. Om maximalt prestandaläge är för riskabelt är det möjligt att använda maximalt tillgänglighetsläge med FarSync-mekanismen. Användning av en FarSync-instans utlöser dock Active Data Guard-licensiering i både primära miljöer och väntelägesmiljöer. Mer detaljerad information finns i licensinformationen.
När du skickar data mellan Azure-regioner eller datacenter står du dessutom inför utgående kostnader för data (t.ex. gör om loggar) som skickas till en haveriberedskapsplats. Om du inte behöver replikera alla data i databasen kan du bara replikera partiella data efter behov med hjälp av Golden Gate-baserad replikering och spara på utgående kostnader.
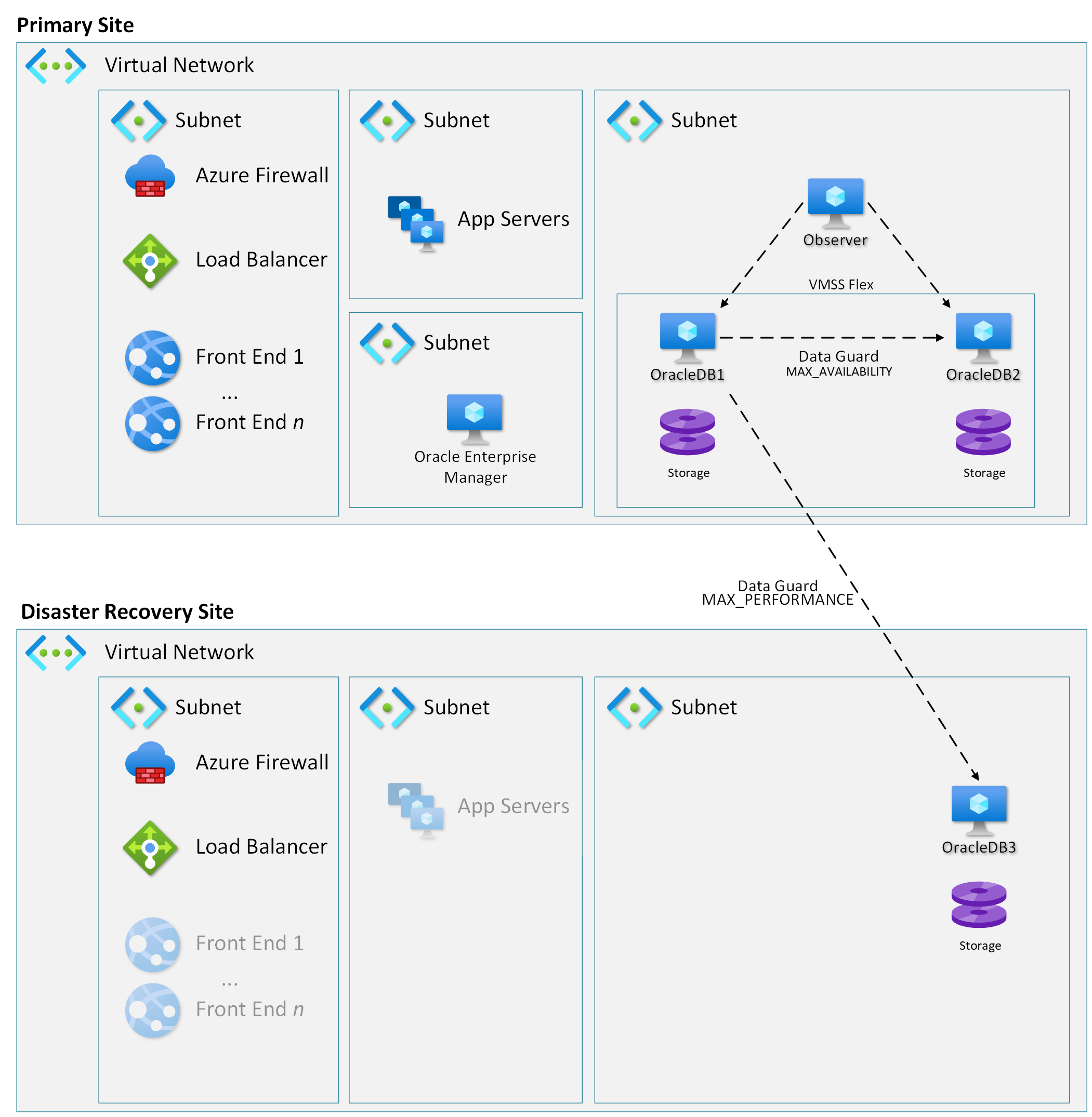
En stegvis konfiguration av Data Guard i Azure finns i Implementera Oracle Data Guard på en virtuell Azure Linux-dator .
Haveriberedskap med Golden Gate
Golden Gate är en logisk replikeringsprogramvara som möjliggör replikering i realtid, filtrering och omvandling av data från en källdatabas till en måldatabas eller mellan flera primära databaser. Den här funktionen säkerställer att ändringar i källdatabasen replikeras nära realtid, vilket gör det möjligt för måldatabasen att vara uppdaterad med de senaste data.
Golden Gate kan användas för att replikera data från en primär databas till sekundär i en konfiguration för haveriberedskap. Golden Gate kan vara mer praktiskt till exempel när inte alla data om dina data behöver skyddas. Med Golden Gate kan du selektivt replikera tabeller och till och med filtrera bort tabellrader under replikeringen för att undvika replikering av onödiga data.
En stegvis guide om hur du implementerar Golden Gate i Azure finns i Implementera Oracle Golden Gate på en virtuell Azure Linux-dator.
Haveriberedskap med hjälp av säkerhetskopiering
Säkerhetskopiering och återställning har varit en traditionell metod för haveriberedskapsarkitektur. Det finns två huvudkomponenter för att använda säkerhetskopiering som en haveriberedskapsmetod för Oracle-databaser i Azure:
Se till att data är uppdaterade på haveriberedskapsplatsen genom att extrahera och flytta säkerhetskopiering av data från databasen.
Se till att distributionen är uppdaterad på haveriberedskapsplatsen. Du uppdaterar platsen genom att replikera samma distribution av alla nätverkskomponenter, programservrar och konfiguration till haveriberedskapsplatsen.
När det gäller att replikera data med hjälp av säkerhetskopiering har du flera olika alternativ som du kan utforska enligt beskrivningen i Säkerhetskopieringsstrategier för Oracle Databases i Azure.
Överväg att använda någon av följande metoder för att underhålla haveriberedskapsplatsen:
- En metod är att du inte underhåller någon fysisk distribution på haveriberedskapsplatsen, vilket undviker underhållsarbete och kostnader för den. Du kan använda metoder för infrastruktur som kod (IaC) och teknik för platstillförlitlighet för att utveckla och underhålla en lagringsplats som kan replikera distributionen som konfiguration med ett klick vid tidpunkten för redundansväxlingen till en haveriberedskapsplats. Den här metoden optimerar kostnaden eftersom den inte använder några fysiska resurser förrän vid redundansväxlingen.
Viktigt!
Du måste se till att lösningens RTO-krav kan uppfyllas om du skapar hela distributionen från grunden under redundansväxlingen. Rutinmässig simulering och testning av haveriberedskapsscenario krävs för att säkerställa att distributionskoden inte bryts.
- En annan metod är att distribuera och underhålla en skalad version av produktionsmiljön. En version som kan fungera korrekt för en liten arbetsbelastning och som potentiellt kan skalas upp efter behov under redundansväxlingen för att fungera för produktionsbelastning. Det här alternativet är den metod som används mest, särskilt för komplexa distributioner där du inte vill ta risken att skapa hela miljön eller när du vill redundansväxla snabbt för att ge en lägre RTO.
En tredje metod är att distribuera och underhålla hela lösningen på haveriberedskapsplatsen för de snabbaste RTO- och redundanstiderna på bekostnad av en potentiell fördubbling av kostnaden.
Särskilda överväganden för haveriberedskap
I följande avsnitt beskrivs särskilda överväganden för haveriberedskap.
Använda FarSync
Oracle Data Guard Far Sync hjälper inte till med funktionerna för hög tillgänglighet, men du kan uppnå ingen replikering av dataförlustskyddsfunktioner för Oracle Databases. Om din arbetsbelastning kräver noll dataförlust när det primära misslyckas kan du läsa Oracle-referensarkitekturer i Azure för mer information om hur du använder Far Sync på Azure.
Välj rätt datareplikeringsteknik
Förutom inbyggda tekniker som beskrivs i det här dokumentet kan du använda alla tekniker som underlättar datareplikering mellan två Oracle-databaser för att upprätthålla en replik med hög tillgänglighet och en haveriberedskapsreplik för dina Oracle-databaser i Azure. Det är viktigt att den teknik du väljer uppfyller dina lösningskrav i dessa pelare.
Svarstid: Hur lång tid det tar att replikera en uppdatering från primära till sekundärfiler för hög tillgänglighet och haveriberedskap bör uppfylla dina lösningskrav.
Bandbredd: Mängden och kostnaden för bandbredd som du behöver för att replikera data till sekundärfiler för hög tillgänglighet och haveriberedskap bör anges. Azure tillhandahåller redan en infrastruktur för höghastighetsnätverk mellan tillgänglighetszoner. När du överväger replikering till andra Azure-regioner för haveriberedskap bör du överväga hur mycket bandbredd som kan uppnås samt utgående kostnader för data som lämnar Azure-datacentret.
Effekt: Mängden påverkan replikering medför för transaktioner på den primära databasen bör uppfylla dina lösningskrav.
Dataförlust: Mängden dataförlust som förväntas vid ett plötsligt fel i den primära databasen bör uppfylla dina lösningskrav.
Total ägandekostnad: Kostnaden för anskaffning (en replikeringslösning från tredje part) och mängden arbete som krävs för att konfigurera och underhålla replikeringslösningen bör också betraktas och verifieras så att den uppfyller lösningskraven.
Optimera redundansinstans
När du använder Data Guard i hög tillgänglighet eller högskyddsläge är det också möjligt att konfigurera för automatisk redundans så att den sekundära servern tas upp automatiskt när den primära servern misslyckas. Genom att konfigurera programservrar i enlighet med detta kan du se till att programavbrottstiden är nära noll under redundansväxlingen.
Eftersom databasen ska fungera på samma sätt efter redundansväxlingen i den här implementeringen måste en sekundär server konfigureras med samma PROCESSOR-, minnes- och I/O-kapacitet som den primära servern. I så fall skulle du behöva ha en hög kapacitet med en sekundär server som skulle öka dina Azure-kostnader och Oracle-databaslicenskostnader. Den sekundära servern bearbetar inte användarbegäranden för det mesta.
Azure tillhandahåller redan 99,9 % tillgänglighet för virtuella datorer i en tillgänglighetszon enligt vad som anges i serviceavtal på tjänstnivå för virtuella datorer (SLA). När du underhåller en sekundär replik av databasen i samma tillgänglighetszon, en annan tillgänglighetszon eller en annan region med hjälp av datareplikeringsteknik, är det möjligt att optimera den sekundära kapaciteten.
Med den här metoden konfigureras de sekundära databaserna med den kapacitet de behöver för att hålla sig uppdaterade. När ett fel inträffar ändras den sekundära databasen så att den får samma kapacitet som den ursprungliga primära databasen. Den här åtgärden utförs bara vid fel, så under normal drift betalar du bara för en bråkdel av kostnaden för den ursprungliga servern. Eftersom den primära databasen inte fungerar just nu behöver du inte andra Oracle-databaslicenser.
Den kapacitet som krävs för att använda sekundär databas som replikeringsmål beror på vilken replikeringsteknik du använder. I huvudsak består arbetsbelastningen på ett transaktionellt OLTP-system mestadels av läsbegäranden. Till exempel är 90%-10% eller 95%-5% läs-skriv-ransoner vanliga i OLTP-programmet. Datareplikering replikerar i princip resultatet av att skriva begäranden i källdatabasen. Med den här konfigurationen är det rimligt att förvänta sig att den sekundära databasen fungerar med den 1/10:e (om 90%-10 % läs-och skrivförhållande) eller till och med 1/10 kapacitet för den primära databasen.
Vi rekommenderar också att du automatiserar redundansprocedurer för att säkerställa företagsstandarder under redundansväxlingen. Samma process kan utvecklas för att inkludera serverändringsåtgärder som effektiviserar processen från slutpunkt till slutpunkt.
Nätverkstopologi för tjänstskydd och dataskydd
För att uppnå hög tillgänglighet och haveriberedskap krävs ett ekonomiskt och affärsbeslut som balanserar återställningstiden (RTO) och den potentiella dataförlusten (RPO) mot andra Oracle-licensiering, underhåll av virtuella datorer och kostnader för dataöverföring som ska implementeras. Att vara värd för en arbetsbelastning på en enskild virtuell Azure-dator ger grundläggande skydd för vanliga maskinvarufel och ger den minst kostsamma lösningen. Eftersom ett fel på en enskild virtuell dator sannolikt orsakar avbrott och dataförlust bör produktionsmiljöerna innehålla en sekundär Oracle-databas som finns på en separat virtuell dator med Oracle Data Guard. Konfigurera dataskyddet korrekt för datareplikering med en eller flera av följande arkitekturer, beroende på dina krav.
- Optimal RTO och RPO. Om du vill minimera svarstiden lägger du till en sekundär Oracle-databas på en separat virtuell dator i samma tillgänglighetszon och inom en närhetsplaceringsgrupp som den primära databasen.
- Dataskydd från ett datacenterfel. Om du placerar den sekundära virtuella datorn i en andra databas ökar dataskyddet om ett helt datacenter misslyckas. Svarstiden mellan den primära och sekundära databasen kan vara så mycket som 2 ms, vilket kan påverka prestanda, RTO och RPO.
- Dataskydd mot ett regionalt fel. För att utöka skyddet för att förhindra dataförlust från ett regionalt Azure-fel kan den sekundära databasen placeras i en annan region. Eftersom svarstiden mellan regioner kan vara mellan 30 ms och 300 ms kan påverkan på produktionsarbetsbelastningen och RTO och RPO öka. Beräkna den här svarstiden i förväg.
Affärskontinuitet kräver en integrerad metod som omfattar alla komponenter i arbetsbelastningen. Nätverksinfrastruktur är en primär komponent för alla arbetsbelastningar i Azure och måste anpassas till arkitekturen för hög tillgänglighet och haveriberedskap.
- Oracle Data Guard ger hög tillgänglighet och (i de flesta fall) ger tillräckligt stöd för vanliga fel. När virtuella datorer placeras i tillgänglighetsuppsättningar bör alla virtuella datorer och tjänster i en enda lösning finnas i samma tillgänglighetszon för att minska nätverksfördröjningen. Av samma anledning bör tjänsterna också dela samma virtuella nätverk.
- För annat skydd kan virtuella datorer placeras strategiskt i separata tillgänglighetszoner i stället för en enda tillgänglighetszon. Den här metoden kan förhindra avbrott under ett datacenterfel.
- För extremt skydd kan en sekundär databas placeras i en annan Azure-region med kontinuerliga uppdateringar som tillämpas med Oracle Data Guard med hjälp av global peering för virtuella nätverk. Det här skyddet gör att datauppdateringar kan tillämpas på den sekundära regionen privat via Microsofts stamnät. Resurser kommunicerar direkt, utan gatewayer, extra hopp eller överföring via det offentliga Internet. Det här nätverksalternativet tillåter en anslutning med hög bandbredd och låg svarstid mellan peer-kopplade virtuella nätverk i olika regioner. Du kan använda global peering för virtuella nätverk för att ansluta din primära plats till haveriberedskapsplatsen i en annan region via ett höghastighetsnätverk.
Sammanfattning av återhämtning mot olika feltyper
| Felscenario | Oracle på Azure HA/DR Scenario | RPO/RTO |
|---|---|---|
| Fel med enskild komponent (värd, rack, kylning, nätverk, ström) | Data Guard med två noder i samma tillgänglighetsuppsättning i samma datacenter. – Skyddar mot fel med en enskild instans. – Orsakar stilleståndstid om hela datacentret är nere. |
RPO=0 RTO<=2 min – Använda Observer för snabb redundans – Använda MAX_AVAILABILITY eller MAX_PROTECTION läge för Data Guard. |
| Data Center-fel | Data Guard med två noder i separata tillgänglighetszoner. – Skyddar mot fel i datacenter. – Orsakar stilleståndstid om hela regionen är nere. – Kräver mer redundanskonfiguration för att appservrar ska kunna hantera nätverksfördröjning. |
RPO<=5 min RTO<=5 min – Använda MAX_PERFORMANCE läge för Data Guard RPO=0 RTO<=5 min – Använda MAX_AVAILABILITY läge för Data Guard |
| Regionfel | Data Guard med två noder i separata Azure-regioner: – Skyddar mot regionala fel – Kräver mer redundanskonfiguration för att appservrar ska kunna hantera nätverksfördröjning. |
RPO>=10 min RTO>=15 min – Använda MAX_PERFORMANCE läge för Data Guard. |
| Säkerhetskopior som levereras till en annan Azure-region: - Skyddar mot regionala fel. – Kräver att hela Azure-miljön konfigureras i målregionen under redundansväxlingen. |
RPO>=24 timmar RTO>=4 timmar |
Nästa steg
Lär dig mer om designöverväganden för Oracle på azure virtual machines-acceleratorsäkerhet i ett scenario i företagsskala.
Se Säkerhetsriktlinjer för Oracle på Azure Virtual Machines-acceleratorn för landningszoner.
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för