Metodtips för att använda Avvikelseidentifiering univariate API
Viktigt!
Från och med den 20 september 2023 kan du inte skapa nya Avvikelseidentifiering resurser. Tjänsten Avvikelseidentifiering dras tillbaka den 1 oktober 2026.
AVVIKELSEIDENTIFIERING-API:et är en tillståndslös tjänst för avvikelseidentifiering. Noggrannheten och prestandan för resultaten kan påverkas av:
- Hur dina tidsseriedata förbereds.
- De Avvikelseidentifiering API-parametrar som användes.
- Antalet datapunkter i din API-begäran.
Använd den här artikeln om du vill veta mer om metodtips för att använda API:et för att få bästa resultat för dina data.
När du ska använda batch (hela) eller senaste (senaste) punktavvikelseidentifiering
Med Avvikelseidentifiering-API:ets slutpunkt för batchidentifiering kan du identifiera avvikelser genom hela tidsseriedata. I det här identifieringsläget skapas en enda statistisk modell och tillämpas på varje punkt i datauppsättningen. Om din tidsserie har nedanstående egenskaper rekommenderar vi att du använder batchidentifiering för att förhandsgranska dina data i ett API-anrop.
- En säsongsserie med tillfälliga avvikelser.
- En platt trendtidsserie med tillfälliga toppar/dalar.
Vi rekommenderar inte att du använder batchavvikelseidentifiering för dataövervakning i realtid eller använder dem på tidsseriedata som inte har ovanstående egenskaper.
Batchidentifiering skapar och tillämpar endast en modell, identifieringen för varje punkt görs i kontexten för hela serien. Om tidsseriedatatrenderna ökar och minskar utan säsongsvariationer kan vissa ändringspunkter (datadippar och toppar) missas av modellen. På samma sätt kan vissa ändringspunkter som är mindre betydande än de som senare i datauppsättningen inte räknas som tillräckligt betydande för att införlivas i modellen.
Batchidentifieringen går långsammare än att identifiera avvikelsestatusen för den senaste punkten vid dataövervakning i realtid på grund av antalet punkter som analyseras.
För dataövervakning i realtid rekommenderar vi att du bara identifierar avvikelsestatusen för din senaste datapunkt. Genom att kontinuerligt tillämpa den senaste punktidentifieringen kan övervakning av strömmande data göras mer effektivt och korrekt.
I exemplet nedan beskrivs hur dessa identifieringslägen kan påverka prestanda. Den första bilden visar resultatet av att kontinuerligt identifiera den senaste avvikelsestatusen längs 28 tidigare sedda datapunkter. De röda punkterna är avvikelser.

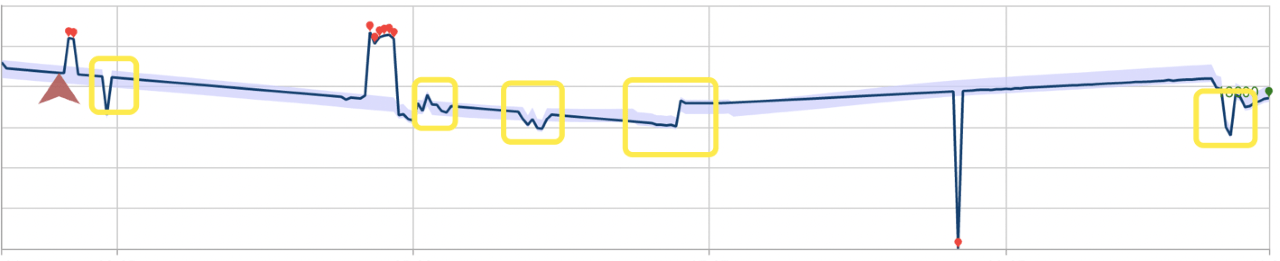
Nedan visas samma datauppsättning med batchavvikelseidentifiering. Modellen som skapats för åtgärden har ignorerat flera avvikelser, markerade med rektanglar.
Dataförberedelse
AVVIKELSEIDENTIFIERING-API:et accepterar tidsseriedata som är formaterade till ett JSON-begärandeobjekt. En tidsserie kan vara numeriska data som registreras över tid i sekventiell ordning. Du kan skicka windows för dina tidsseriedata till Avvikelseidentifiering API-slutpunkten för att förbättra API:ets prestanda. Det minsta antalet datapunkter som du kan skicka är 12 och maxvärdet är 8 640 poäng. Kornighet definieras som den hastighet som dina data samplas med.
Datapunkter som skickas till Avvikelseidentifiering-API:et måste ha en giltig UTC-tidsstämpel (Coordinated Universal Time) och ett numeriskt värde.
{
"granularity": "daily",
"series": [
{
"timestamp": "2018-03-01T00:00:00Z",
"value": 32858923
},
{
"timestamp": "2018-03-02T00:00:00Z",
"value": 29615278
},
]
}
Om dina data samplas med ett tidsintervall som inte är standard kan du ange dem genom att lägga till customInterval attributet i din begäran. Om serien till exempel samplas var femte minut kan du lägga till följande i din JSON-begäran:
{
"granularity" : "minutely",
"customInterval" : 5
}
Datapunkter saknas
Saknade datapunkter är vanliga i jämnt fördelade tidsseriedatauppsättningar, särskilt datamängder med fin kornighet (ett litet samplingsintervall. Exempel på data som samplas med några minuters mellanrum). Mindre än 10 % av det förväntade antalet punkter i dina data bör inte ha en negativ inverkan på identifieringsresultatet. Överväg att fylla luckor i dina data baserat på dess egenskaper som att ersätta datapunkter från en tidigare period, linjär interpolation eller ett glidande medelvärde.
Aggregera distribuerade data
AVVIKELSEIDENTIFIERING-API:et fungerar bäst i en jämnt distribuerad tidsserie. Om dina data distribueras slumpmässigt bör du aggregera dem med en tidsenhet, till exempel per minut, timme eller dag.
Avvikelseidentifiering för data med säsongsmönster
Om du vet att dina tidsseriedata har ett säsongsmönster (ett som inträffar med jämna mellanrum) kan du förbättra noggrannheten och API-svarstiden.
Om du anger en period när du skapar din JSON-begäran kan svarstiden för avvikelseidentifiering minskas med upp till 50 %. period är ett heltal som anger ungefär hur många datapunkter som tidsserierna tar för att upprepa ett mönster. Till exempel skulle en tidsserie med en datapunkt per dag ha en period som 7, och en tidsserie med en punkt per timme (med samma veckomönster) skulle ha en period på 7*24. Om du är osäker på dina datas mönster behöver du inte ange den här parametern.
För bästa resultat anger du fyra period"värde av datapunkt, plus ytterligare en. Till exempel bör timdata med ett veckomönster enligt beskrivningen ovan tillhandahålla 673 datapunkter i begärandetexten (7 * 24 * 4 + 1).
Samplingsdata för realtidsövervakning
Om dina strömmande data samplas med ett kort intervall (till exempel sekunder eller minuter) kan det rekommenderade antalet datapunkter överskrida Avvikelseidentifiering API:s maximala antal tillåtna (8 640 datapunkter). Om dina data visar ett stabilt säsongsmönster bör du överväga att skicka ett exempel på dina tidsseriedata med ett större tidsintervall, till exempel timmar. Sampling av dina data på det här sättet kan också avsevärt förbättra API-svarstiden.