Så här förbättrar du din Custom Vision-modell
I den här guiden får du lära dig hur du förbättrar kvaliteten på din Custom Vision-modell. Kvaliteten på klassificeraren eller objektdetektorn beror på mängden, kvaliteten och mängden etiketterade data som du anger och hur balanserad den övergripande datamängden är. En bra modell har en balanserad träningsdatauppsättning som är representativ för vad som ska skickas till den. Processen att skapa en sådan modell är iterativ; Det är vanligt att ta några träningsrundor för att nå förväntade resultat.
Följande är ett allmänt mönster som hjälper dig att träna en mer exakt modell:
- Utbildning i första omgången
- Lägg till fler bilder och balansera data. Omskola
- Lägg till bilder med varierande bakgrund, belysning, objektstorlek, kameravinkel och stil; Omskola
- Använda nya avbildningar för att testa förutsägelse
- Ändra befintliga träningsdata enligt förutsägelseresultat
Förhindra överanpassning
Ibland lär sig en modell att göra förutsägelser baserat på godtyckliga egenskaper som dina bilder har gemensamt. Om du till exempel skapar en klassificerare för äpplen jämfört med citrus, och du har använt bilder av äpplen i händer och citrus på vita tallrikar, kan klassificeraren ge otillbörlig betydelse för händer jämfört med tallrikar, snarare än äpplen jämfört med citrus.
Åtgärda problemet genom att ge bilder olika vinklar, bakgrunder, objektstorlek, grupper och andra varianter. Följande avsnitt utökar dessa begrepp.
Datakvantitet
Antalet träningsbilder är den viktigaste faktorn för din datamängd. Vi rekommenderar att du använder minst 50 bilder per etikett som utgångspunkt. Med färre bilder finns det en högre risk för överanpassning, och även om dina prestandasiffror kan tyda på god kvalitet kan din modell kämpa med verkliga data.
Databalans
Det är också viktigt att ta hänsyn till de relativa kvantiteterna av dina träningsdata. Om du till exempel använder 500 bilder för en etikett och 50 bilder för en annan etikett blir det en obalanserad träningsdatauppsättning. Detta gör att modellen blir mer exakt när det gäller att förutsäga en etikett än en annan. Det är troligt att du får bättre resultat om du har minst ett 1:2-förhållande mellan etiketten med minst antal bilder och etiketten med flest bilder. Om etiketten med flest bilder till exempel har 500 bilder bör etiketten med minst bilder ha minst 250 bilder för träning.
Datavari variety
Se till att använda bilder som är representativa för vad som ska skickas till klassificeraren under normal användning. Annars kan din modell lära sig att göra förutsägelser baserat på godtyckliga egenskaper som dina bilder har gemensamt. Om du till exempel skapar en klassificerare för äpplen jämfört med citrus, och du har använt bilder av äpplen i händer och citrus på vita tallrikar, kan klassificeraren ge otillbörlig betydelse för händer jämfört med tallrikar, snarare än äpplen jämfört med citrus.

Åtgärda det här problemet genom att ta med en mängd olika bilder för att säkerställa att din modell kan generalisera väl. Nedan visas några sätt att göra träningsuppsättningen mer varierad:
Bakgrund: Ange bilder av objektet framför olika bakgrunder. Foton i naturliga sammanhang är bättre än foton framför neutrala bakgrunder eftersom de ger mer information för klassificeraren.

Belysning: Ge bilder med varierad belysning (dvs. tagna med blixt, hög exponering och så vidare), särskilt om de bilder som används för förutsägelse har olika belysning. Det är också användbart att använda bilder med varierande mättnad, nyans och ljusstyrka.

Objektstorlek: Ange bilder där objekten varierar i storlek och antal (till exempel ett foto av buntar bananer och en närbild av en enda banan). Olika storleksändring hjälper klassificeraren att generalisera bättre.

Kamera vinkel: Ge bilder tagna med olika kameravinklar. Alternativt, om alla dina foton måste tas med fasta kameror (till exempel övervakningskameror), se till att tilldela en annan etikett till varje regelbundet förekommande objekt för att undvika överanpassning – tolka orelaterade objekt (till exempel lyktstolpar) som nyckelfunktionen.

Stil: Ange bilder av olika format i samma klass (till exempel olika sorter av samma frukt). Men om du har objekt med drastiskt olika format (till exempel Musse Pigg jämfört med en verklig mus) rekommenderar vi att du märker dem som separata klasser för att bättre representera deras distinkta funktioner.

Negativa bilder (endast klassificerare)
Om du använder en bildklassificerare kan du behöva lägga till negativa exempel för att göra klassificeraren mer exakt. Negativa exempel är bilder som inte matchar någon av de andra taggarna. När du laddar upp bilderna använder du den speciella negativa etiketten på dem.
Objektdetektorer hanterar negativa prover automatiskt, eftersom alla bildområden utanför de ritade avgränsningsrutorna anses vara negativa.
Kommentar
Custom Vision-tjänsten stöder viss automatisk negativ bildhantering. Om du till exempel skapar en druva jämfört med bananklassificerare och skickar en bild av en sko för förutsägelse, bör klassificeraren bedöma bilden som nära 0 % för både druva och banan.
Å andra sidan är det troligt att modellen klassificerar negativa bilder som en märkt klass på grund av de stora likheterna i de fall där de negativa bilderna bara är en variant av de bilder som används i träning. Om du till exempel har en klassificeringsklassificerare för apelsin kontra grapefrukt, och du matar in en bild av en klementin, kan den poängsätta clementin som en apelsin eftersom många funktioner i clementin liknar apelsiner. Om dina negativa bilder är av den här typen rekommenderar vi att du skapar en eller flera ytterligare taggar (till exempel Andra) och etiketterar negativa bilder med den här taggen under träningen så att modellen bättre kan skilja mellan dessa klasser.
Ocklusion och trunkering (endast objektdetektorer)
Om du vill att objektdetektorn ska identifiera trunkerade objekt (objekt som delvis är utklippta ur bilden) eller ockluderade objekt (objekt som delvis blockeras av andra objekt i bilden) måste du inkludera träningsbilder som täcker dessa fall.
Kommentar
Problemet med objekt som occludeds av andra objekt ska inte förväxlas med Överlappningströskel, en parameter för prestanda för klassificeringsmodell. Skjutreglaget Överlappningströskel på Custom Vision-webbplatsen handlar om hur mycket en förutsagd avgränsningsruta måste överlappa med den sanna avgränsningsrutan för att anses vara korrekt.
Använda förutsägelsebilder för vidare träning
När du använder eller testar modellen genom att skicka bilder till förutsägelseslutpunkten lagrar Custom Vision-tjänsten dessa bilder. Du kan sedan använda dem för att förbättra modellen.
Om du vill visa bilder som skickats till modellen öppnar du Custom Vision-webbsidan, går till projektet och väljer fliken Förutsägelser. Standardvyn visar bilder från den aktuella iterationen. Du kan använda den nedrullningsbara menyn Iteration för att visa bilder som skickats under tidigare iterationer.
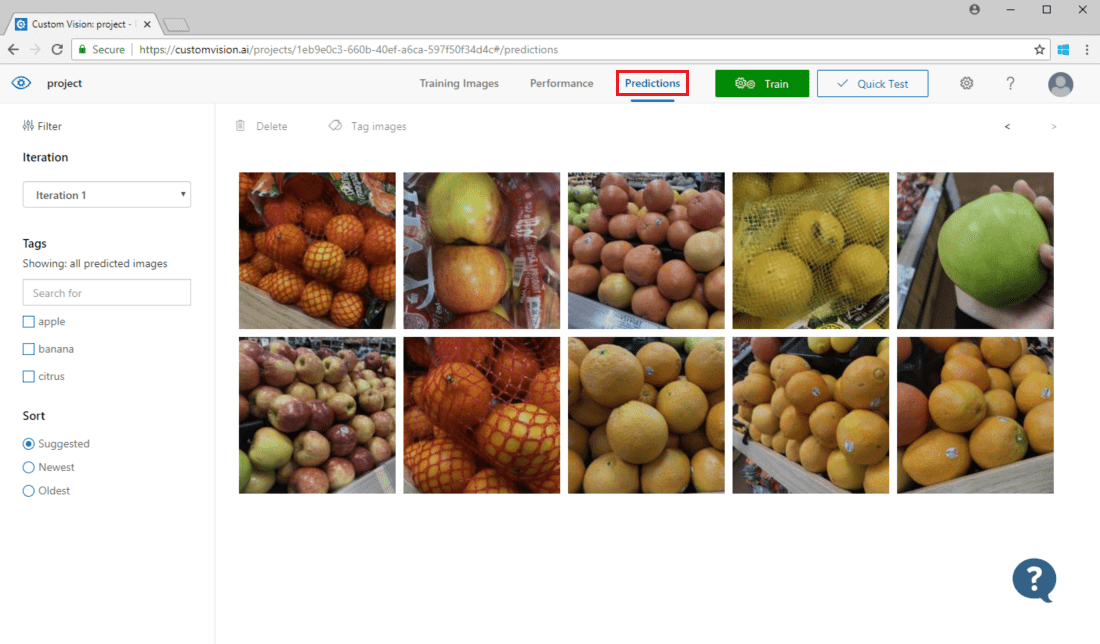
Hovra över en bild för att se taggarna som förutsagts av modellen. Bilderna sorteras så att de som kan förbättra modellen mest visas överst. Om du vill använda en annan sorteringsmetod gör du ett val i avsnittet Sortera .
Om du vill lägga till en avbildning i dina befintliga träningsdata väljer du avbildningen, anger rätt taggar och väljer Spara och stäng. Bilden tas bort från Förutsägelser och läggs till i uppsättningen träningsbilder. Du kan visa den genom att välja fliken Träningsbilder .
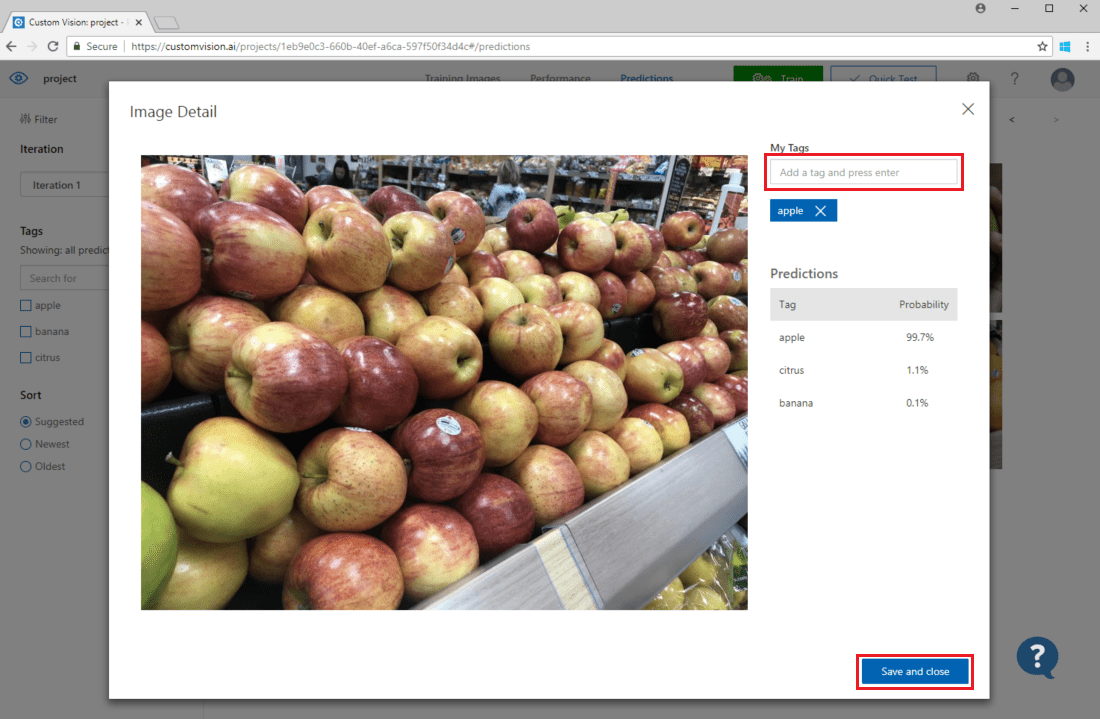
Använd sedan knappen Träna för att träna modellen igen.
Inspektera förutsägelser visuellt
Om du vill granska bildförutsägelser går du till fliken Träningsbilder, väljer din tidigare tränings-iteration i listrutan Iteration och kontrollerar en eller flera taggar under avsnittet Taggar. Vyn bör nu visa en röd ruta runt var och en av de bilder som modellen inte kunde förutsäga den angivna taggen för korrekt.
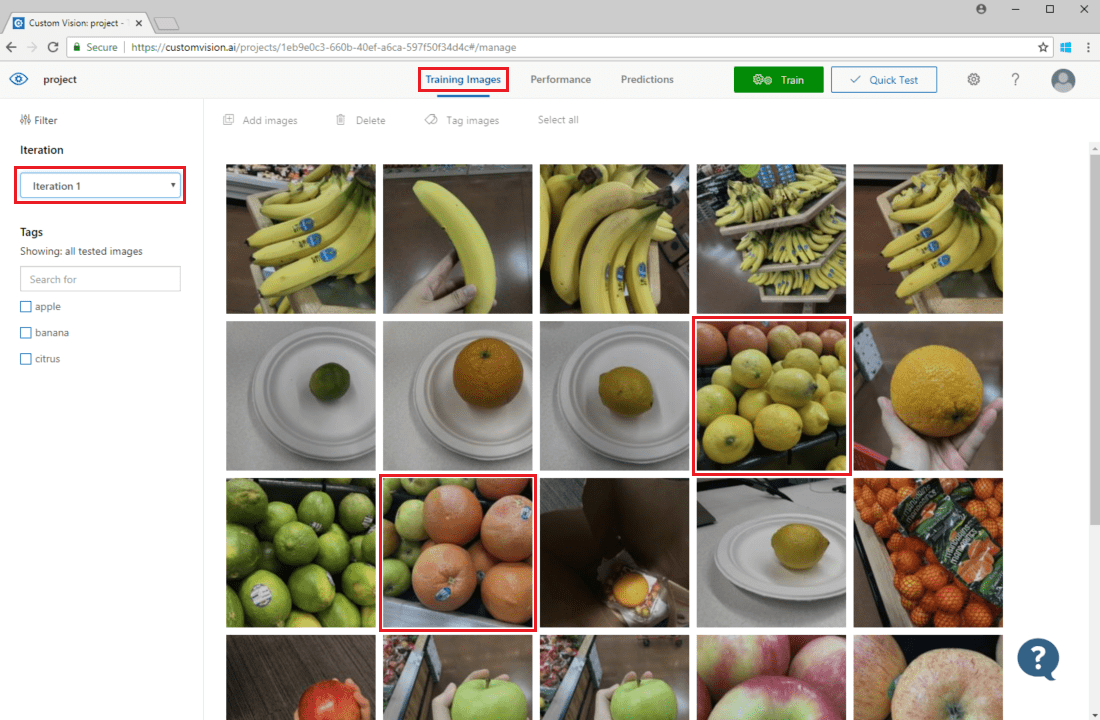
Ibland kan en visuell inspektion identifiera mönster som du sedan kan korrigera genom att lägga till fler träningsdata eller ändra befintliga träningsdata. En klassificerare för äpplen jämfört med limefrukter kan till exempel felaktigt märka alla gröna äpplen som limefrukter. Du kan sedan åtgärda det här problemet genom att lägga till och tillhandahålla träningsdata som innehåller taggade bilder av gröna äpplen.
Nästa steg
I den här guiden har du lärt dig flera tekniker för att göra din anpassade bildklassificeringsmodell eller objektidentifieringsmodell mer exakt. Lär dig sedan hur du testar bilder programmatiskt genom att skicka dem till FÖRUTSÄGELSE-API:et.