Anpassat tal till textcontainrar med Docker
Den anpassade tal till textcontainern transkriberar tal- eller batchljudinspelningar i realtid med mellanliggande resultat. Du kan använda en anpassad modell som du skapade i den anpassade talportalen. I den här artikeln får du lära dig hur du laddar ned, installerar och kör en anpassad tal till textcontainer.
Mer information om förutsättningar, verifiering av att en container körs, körning av flera containrar på samma värd och körning av frånkopplade containrar finns i Installera och köra Speech-containrar med Docker.
Containeravbildningar
Den anpassade tal till textcontaineravbildningen för alla versioner och nationella inställningar som stöds finns i MCR-syndikatet (Microsoft Container Registry). Den finns på lagringsplatsen azure-cognitive-services/speechservices/ och heter custom-speech-to-text.

Det fullständigt kvalificerade containeravbildningsnamnet är , mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text. Lägg antingen till en viss version eller lägg till :latest för att hämta den senaste versionen.
| Version | Sökväg |
|---|---|
| Senast | mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text:latest |
| 4.6.0 | mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text:4.6.0-amd64 |
Alla taggar, förutom latest, är i följande format och är skiftlägeskänsliga:
<major>.<minor>.<patch>-<platform>-<prerelease>
Kommentar
Och localevoice för anpassade tal till textcontainrar bestäms av den anpassade modellen som matas in av containern.
Taggarna är också tillgängliga i JSON-format för din bekvämlighet. Brödtexten innehåller containersökvägen och listan med taggar. Taggarna sorteras inte efter version, men "latest" ingår alltid i slutet av listan enligt följande kodfragment:
{
"name": "azure-cognitive-services/speechservices/custom-speech-to-text",
"tags": [
"2.10.0-amd64",
"2.11.0-amd64",
"2.12.0-amd64",
"2.12.1-amd64",
<--redacted for brevity-->
"latest"
]
}
Hämta containeravbildningen med docker pull
Du behöver kraven, inklusive nödvändig maskinvara. Se även den rekommenderade allokeringen av resurser för varje Speech-container.
Använd docker pull-kommandot för att ladda ned en containeravbildning från Microsoft Container Registry:
docker pull mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text:latest
Kommentar
Och localevoice för anpassade Speech-containrar bestäms av den anpassade modellen som matas in av containern.
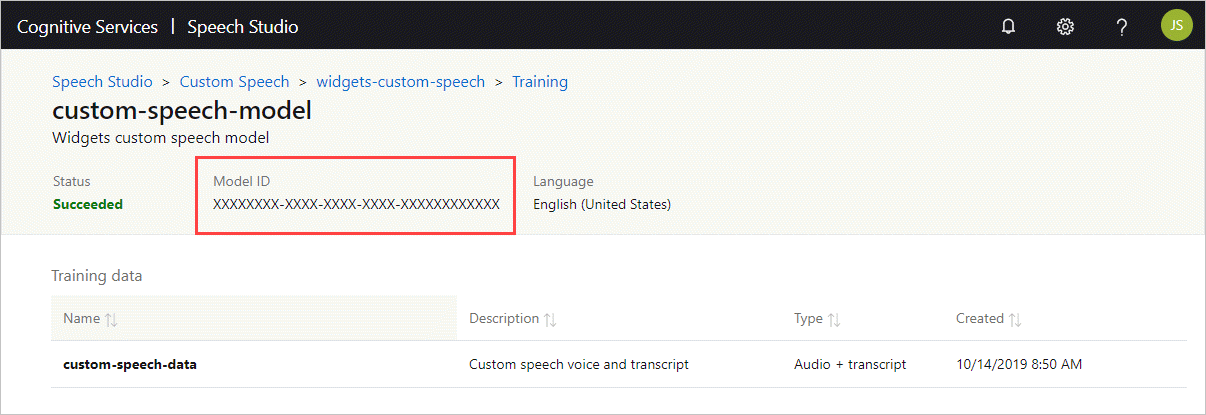
Hämta modell-ID:t
Innan du kan köra containern måste du känna till modell-ID:t för din anpassade modell eller ett basmodell-ID. När du kör containern anger du ett av modell-ID:na som ska laddas ned och användas.
Den anpassade modellen måste tränas med hjälp av Speech Studio. Information om hur du hämtar modell-ID finns i livscykeln för anpassad talmodell.
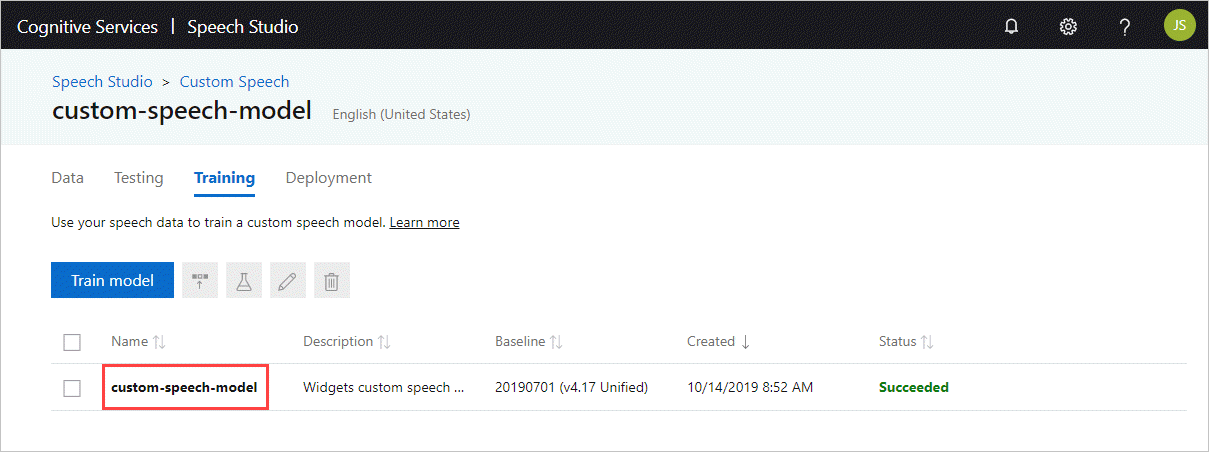
Hämta modell-ID :t som ska användas som argument till parametern ModelId för docker run kommandot.
Nedladdning av visningsmodell
Innan du kör containern kan du välja att hämta tillgänglig information om visningsmodeller och välja att ladda ned dessa modeller till din tal till textcontainer för att få mycket bättre slutliga visningsutdata. Nedladdning av visningsmodell är tillgänglig med containern custom-speech-to-text version 3.1.0 och senare.
Kommentar
Även om du använder docker run kommandot startas inte containern för tjänsten.
Du kan fråga eller ladda ned någon eller alla dessa typer av visningsmodeller: Rescoring (Rescore), Interctuation (Punct), resegmentation (Resegment) och wfstitn (Wfstitn). Annars kan du använda FullDisplay alternativet (med eller utan andra typer) för att fråga eller ladda ned alla typer av visningsmodeller.
BaseModelLocale Ange för att fråga den senaste tillgängliga visningsmodellen på målspråket. Om du inkluderar flera visningsmodelltyper returnerar kommandot de senaste tillgängliga visningsmodellerna för varje typ. Till exempel:
docker run --rm -it \
mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text \
Punct Rescore Resegment Wfstitn \ # Specify `FullDisplay` or a space-separated subset of display models
BaseModelLocale={LOCALE} \
Eula=accept \
Billing={ENDPOINT_URI} \
ApiKey={API_KEY}
DisplayLocale Ange för att ladda ned den senaste tillgängliga visningsmodellen på målspråket. När du anger DisplayLocalemåste du också ange FullDisplay eller en blankstegsavgränsad delmängd av visningsmodeller. Kommandot laddar ned den senaste tillgängliga visningsmodellen för varje angiven typ. Till exempel:
docker run --rm -it \
mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text \
Punct Rescore Resegment Wfstitn \ # Specify `FullDisplay` or a space-separated subset of display models
DisplayLocale={LOCALE} \
Eula=accept \
Billing={ENDPOINT_URI} \
ApiKey={API_KEY}
Ange en modell-ID-parameter för att ladda ned en specifik visningsmodell: Rescoring (RescoreId), Interctuation (PunctId), resegmentation (ResegmentId) eller wfstitn (WfstitnId). Det här liknar hur du laddar ned en basmodell via parametern ModelId . Om du till exempel vill ladda ned en omskolningsvisningsmodell kan du använda följande kommando med parametern RescoreId :
docker run --rm -it \
mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text \
RescoreId={RESCORE_MODEL_ID} \
Eula=accept \
Billing={ENDPOINT_URI} \
ApiKey={API_KEY}
Kommentar
Om du anger fler än en fråge- eller nedladdningsparameter prioriteras kommandot i den här ordningen: BaseModelLocale, modell-ID och sedan DisplayLocale (gäller endast för visningsmodeller).
Kör containern med docker-körning
Använd kommandot docker run för att köra containern för tjänsten.
Följande tabell representerar de olika docker run parametrarna och deras motsvarande beskrivningar:
| Parameter | Description |
|---|---|
{VOLUME_MOUNT} |
Värddatorns volymmontering, som Docker använder för att bevara den anpassade modellen. Ett exempel är c:\CustomSpeech var c:\ enheten finns på värddatorn. |
{MODEL_ID} |
Det anpassade tal- eller basmodell-ID:t. Mer information finns i Hämta modell-ID. |
{ENDPOINT_URI} |
Slutpunkten krävs för mätning och fakturering. Mer information finns i faktureringsargument. |
{API_KEY} |
API-nyckeln krävs. Mer information finns i faktureringsargument. |
När du kör den anpassade tal-till-text-containern konfigurerar du porten, minnet och PROCESSORn enligt kraven och rekommendationerna för den anpassade tal-till-textcontainern.
Här är ett exempelkommando docker run med platshållarvärden. Du måste ange VOLUME_MOUNTvärdena , MODEL_ID, ENDPOINT_URIoch API_KEY :
docker run --rm -it -p 5000:5000 --memory 8g --cpus 4 \
-v {VOLUME_MOUNT}:/usr/local/models \
mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text \
ModelId={MODEL_ID} \
Eula=accept \
Billing={ENDPOINT_URI} \
ApiKey={API_KEY}
Det här kommandot:
- Kör en anpassad tal-till-text-container från containeravbildningen.
- Allokerar 4 CPU-kärnor och 8 GB minne.
- Läser in den anpassade tal-till-text-modellen från volyminmatningsmonteringen, till exempel C:\CustomSpeech.
- Exponerar TCP-port 5000 och allokerar en pseudo-TTY för containern.
- Laddar ned modellen med tanke
ModelIdpå (om den inte hittas på volymmonteringen). - Om den anpassade modellen tidigare laddades
ModelIdned ignoreras den. - Tar automatiskt bort containern när den har avslutats. Containeravbildningen är fortfarande tillgänglig på värddatorn.
Mer information om docker run med Speech-containrar finns i Installera och köra Speech-containrar med Docker.
Använda containern
Talcontainrar tillhandahåller websocketbaserade frågeslutpunkts-API:er som nås via Speech SDK och Speech CLI. Som standard använder Speech SDK och Speech CLI den offentliga Speech-tjänsten. Om du vill använda containern måste du ändra initieringsmetoden.
Viktigt!
När du använder Speech-tjänsten med containrar måste du använda värdautentisering. Om du konfigurerar nyckeln och regionen går begäranden till den offentliga Speech-tjänsten. Resultat från Speech-tjänsten kanske inte är vad du förväntar dig. Begäranden från frånkopplade containrar misslyckas.
I stället för att använda den här initieringskonfigurationen för Azure-molnet:
var config = SpeechConfig.FromSubscription(...);
Använd den här konfigurationen med containervärden:
var config = SpeechConfig.FromHost(
new Uri("ws://localhost:5000"));
I stället för att använda den här initieringskonfigurationen för Azure-molnet:
auto speechConfig = SpeechConfig::FromSubscription(...);
Använd den här konfigurationen med containervärden:
auto speechConfig = SpeechConfig::FromHost("ws://localhost:5000");
I stället för att använda den här initieringskonfigurationen för Azure-molnet:
speechConfig, err := speech.NewSpeechConfigFromSubscription(...)
Använd den här konfigurationen med containervärden:
speechConfig, err := speech.NewSpeechConfigFromHost("ws://localhost:5000")
I stället för att använda den här initieringskonfigurationen för Azure-molnet:
SpeechConfig speechConfig = SpeechConfig.fromSubscription(...);
Använd den här konfigurationen med containervärden:
SpeechConfig speechConfig = SpeechConfig.fromHost("ws://localhost:5000");
I stället för att använda den här initieringskonfigurationen för Azure-molnet:
const speechConfig = sdk.SpeechConfig.fromSubscription(...);
Använd den här konfigurationen med containervärden:
const speechConfig = sdk.SpeechConfig.fromHost("ws://localhost:5000");
I stället för att använda den här initieringskonfigurationen för Azure-molnet:
SPXSpeechConfiguration *speechConfig = [[SPXSpeechConfiguration alloc] initWithSubscription:...];
Använd den här konfigurationen med containervärden:
SPXSpeechConfiguration *speechConfig = [[SPXSpeechConfiguration alloc] initWithHost:"ws://localhost:5000"];
I stället för att använda den här initieringskonfigurationen för Azure-molnet:
let speechConfig = SPXSpeechConfiguration(subscription: "", region: "");
Använd den här konfigurationen med containervärden:
let speechConfig = SPXSpeechConfiguration(host: "ws://localhost:5000");
I stället för att använda den här initieringskonfigurationen för Azure-molnet:
speech_config = speechsdk.SpeechConfig(
subscription=speech_key, region=service_region)
Använd den här konfigurationen med containerslutpunkten:
speech_config = speechsdk.SpeechConfig(
host="ws://localhost:5000")
När du använder Speech CLI i en container inkluderar du alternativet --host ws://localhost:5000/ . Du måste också ange --key none för att säkerställa att CLI inte försöker använda en Talnyckel för autentisering. Information om hur du konfigurerar Speech CLI finns i Komma igång med Azure AI Speech CLI.
Prova snabbstarten tal till text med värdautentisering i stället för nyckel och region.
Nästa steg
- Se översikten över Speech-containrar
- Granska konfigurera containrar för konfigurationsinställningar
- Använda fler Azure AI-containrar