Anteckning
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
När du skapar en distributionsprincip anger vi något av följande distributionslägen för att definiera den strategi som ska användas när jobb distribueras till arbetare:
Resursallokeringsläge
Jobb distribueras på ett cirkulärt sätt så att varje tillgänglig arbetare får jobb i följd.
Längsta inaktiva läge
Jobb distribueras till den arbetare som används minst först. Om det finns en slips väljer vi den arbetare som har varit tillgänglig under den längre tiden. Användningen beräknas som en Load Ratio av följande algoritm:
Load Ratio = Mängd kapacitet som förbrukas av alla jobb som tilldelats till arbetaren/den totala kapaciteten för arbetaren
Exempel
Anta att varje chat jobb har konfigurerats för att förbruka en kapacitet för en arbetare. Ett nytt chattjobb placeras i kö till Jobbrouter och följande arbetare är tillgängliga för att ta jobbet:
Worker A:
Capacity = 5
ConsumedScore = 3 (Currently handling 3 chats)
LoadRatio = 3 / 5 = 0.6
LastAvailable: 5 mins ago
Worker B:
Capacity = 4
ConsumedScore = 3 (Currently handling 3 chats)
LoadRatio = 3 / 4 = 0.75
LastAvailable: 3 min ago
Worker C:
Capacity = 5
ConsumedScore = 3 (Currently handling 3 chats)
LoadRatio = 3 / 5 = 0.6
LastAvailable: 7 min ago
Worker D:
Capacity = 3
ConsumedScore = 0 (Currently idle)
LoadRatio = 0 / 4 = 0
LastAvailable: 2 min ago
Workers would be matched in order: D, C, A, B
Worker D har det lägsta belastningsförhållandet (0), så Worker D erbjuds jobbet först. Arbetare A och C är bundna med samma belastningsförhållande (0,6). Worker C har dock varit tillgängligt under en längre tid (7 minuter sedan) än Worker A (5 minuter sedan), så Worker C matchas före Arbets-A. Slutligen matchas Worker B sist eftersom Worker B har det högsta belastningsförhållandet (0,75).
Bästa arbetsläge
De arbetare som bäst kan hantera jobbet väljs först. Logiken för att rangordna arbetare kan anpassas med ett uttryck eller en Azure-funktion för att jämföra två arbetare genom att ange en bedömningsregel. Se exempel
När en bedömningsregel inte tillhandahålls använder det här distributionsläget i stället standardbedömningsmetoden, som utvärderar arbetare baserat på hur jobbets etiketter och väljare matchar med arbetarens etiketter. Algoritmerna beskrivs nedan.
Standardmatchning av etiketter
För att beräkna en poäng baserat på jobbets etiketter ökar Match Score vi med 1 för varje arbetsetikett som matchar en motsvarande etikett i jobbet och dividerar sedan med det totala antalet etiketter på jobbet. Ju fler etiketter som matchade, desto högre är en arbetares Match Score. Match Score Finalen är alltid ett värde mellan 0 och 1.
Exempel
Jobb 1:
{
"labels": {
{ "language": "english" },
{ "department": "sales" }
}
}
Arbetare A:
{
"labels": {
{ "language": "english" },
{ "department": "sales" }
}
}
Arbetare B:
{
"labels": {
{ "language": "english" }
}
}
Arbets-C:
{
"labels": {
{ "language": "english" },
{ "department": "support" }
}
}
Beräkning:
Worker A's match score = 1 (for matching english language label) + 1 (for matching department sales label) / 2 (total number of labels) = 1
Worker B's match score = 1 (for matching english language label) / 2 (total number of labels) = 0.5
Worker C's match score = 1 (for matching english language label) / 2 (total number of labels) = 0.5
Arbets-A skulle matchas först. Därefter skulle Worker B eller Worker C matchas, beroende på vem som var tillgänglig under en längre tid, eftersom matchningspoängen är lika.
Standardmatchning av arbetsväljare
Om jobbet även innehåller arbetarväljare beräknar Match Score vi baserat på arbetsväljarens LabelOperator .
Operatorer för lika/notEqual-etikett
Om arbetarväljaren LabelOperator Equal har eller NotEqualökar vi poängen med 1 för varje jobbetikett som matchar den arbetarväljaren på ett liknande sätt som Label Matching ovan.
Exempel
Jobb 2:
{
"workerSelectors": [
{ "key": "department", "labelOperator": "equals", "value": "billing" },
{ "key": "segment", "labelOperator": "notEquals", "department": "vip" }
]
}
Arbets-D:
{
"labels": {
{ "department": "billing" },
{ "segment": "vip" }
}
}
Arbetare E:
{
"labels": {
{ "department": "billing" }
}
}
Arbetare F:
{
"labels": {
{ "department": "sales" },
{ "segment": "new" }
}
}
Beräkning:
Worker D's match score = 1 (for matching department selector) / 2 (total number of worker selectors) = 0.5
Worker E's match score = 1 (for matching department selector) + 1 (for matching segment not equal to vip) / 2 (total number of worker selectors) = 1
Worker F's match score = 1 (for segment not equal to vip) / 2 (total number of labels) = 0.5
Arbets-E skulle matchas först. Därefter skulle Worker D eller Worker F matchas, beroende på vem som var tillgänglig under en längre tid, eftersom matchningspoängen är lika.
Andra etikettoperatorer
För arbetarväljare som använder operatorer som jämför med storlek (GreaterThanLessThan///GreaterThanEqualLessThanEqual) ökar vi arbetarens med ett belopp som beräknas Match Score med hjälp av logistikfunktionen (se bild 1). Beräkningen baseras på hur mycket arbetarens etikettvärde överskrider arbetarväljarens värde eller ett mindre belopp om det inte överskrider arbetarväljarens värde. Ju fler arbetarväljarvärden som arbetaren överskrider, och ju större grad den gör det, desto högre blir en arbetares poäng.
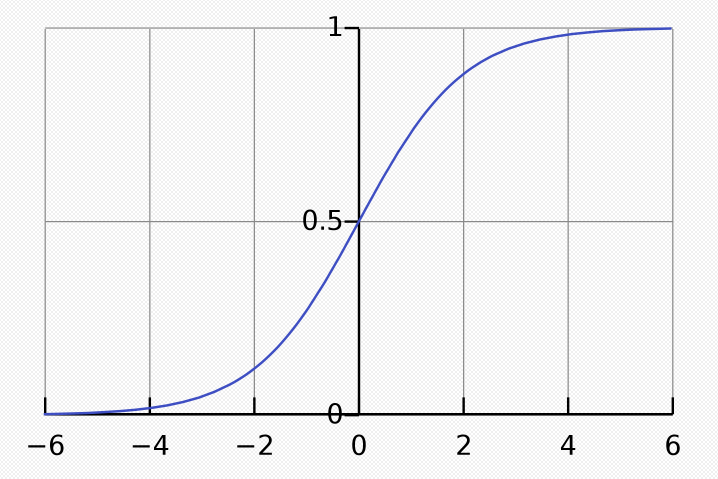
Bild 1. Logistisk funktion
Följande funktion används för Operatorerna GreaterThan eller GreaterThanEqual:
MatchScore(x) = 1 / (1 + e^(-x)) where x = (labelValue - selectorValue) / selectorValue
Följande funktion används för LessThan- eller LessThanEqual-operatorer:
MatchScore(x) = 1 / (1 + e^(-x)) where x = (selectorValue - labelValue) / selectorValue
Exempel
Jobb 3:
{
"workerSelectors": [
{ "key": "language", "operator": "equals", "value": "french" },
{ "key": "sales", "operator": "greaterThanEqual", "value": 10 },
{ "key": "cost", "operator": "lessThanEqual", "value": 10 }
]
}
Arbetare G:
{
"labels": {
{ "language": "french" },
{ "sales": 10 },
{ "cost": 10 }
}
}
Arbetar H:
{
"labels": {
{ "language": "french" },
{ "sales": 15 },
{ "cost": 10 }
}
}
Arbetare I:
{
"labels": {
{ "language": "french" },
{ "sales": 10 },
{ "cost": 9 }
}
}
Beräkning:
Worker G's match score = (1 + 1 / (1 + e^-((10 - 10) / 10)) + 1 / (1 + e^-((10 - 10) / 10))) / 3 = 0.667
Worker H's match score = (1 + 1 / (1 + e^-((15 - 10) / 10)) + 1 / (1 + e^-((10 - 10) / 10))) / 3 = 0.707
Worker I's match score = (1 + 1 / (1 + e^-((10 - 10) / 10)) + 1 / (1 + e^-((10 - 9) / 10))) / 3 = 0.675
Alla tre arbetarna matchar arbetsväljarna på jobbet och är berättigade att arbeta med det. Vi kan dock se att Worker H överskrider "försäljnings"-arbetarväljarens värde med en marginal på 5. Under tiden överskrider arbets-I bara värdet för kostnadsarbetare med en marginal på 1. Arbets-G överskrider inte något av arbetarväljarens värden alls. Därför skulle Worker H matchas först, följt av Worker I och slutligen Worker G skulle matchas sist.