Not
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
GÄLLER FÖR: ![]() Kassandra
Kassandra
API för Cassandra i Azure Cosmos DB har blivit ett bra val för företagsarbetsbelastningar som körs på Apache Cassandra av flera skäl:
Inga omkostnader för hantering och övervakning: Det eliminerar kostnaderna för att hantera och övervaka inställningar i OS-, JVM- och YAML-filer och deras interaktioner.
Betydande kostnadsbesparingar: Du kan spara kostnader med Azure Cosmos DB, vilket inkluderar kostnaden för virtuella datorer, bandbredd och eventuella tillämpliga licenser. Du behöver inte hantera datacenter, servrar, SSD-lagring, nätverk och elkostnader.
Möjlighet att använda befintlig kod och verktyg: Azure Cosmos DB ger kompatibilitet på trådprotokollnivå med befintliga Cassandra-SDK:er och verktyg. Den här kompatibiliteten säkerställer att du kan använda din befintliga kodbas med Azure Cosmos DB för Apache Cassandra med triviala ändringar.
Det finns många sätt att migrera databasarbetsbelastningar från en plattform till en annan. Azure Databricks är ett PaaS-erbjudande (plattform som en tjänst) för Apache Spark som erbjuder ett sätt att utföra offlinemigreringar i stor skala. I den här artikeln beskrivs de steg som krävs för att migrera data från inbyggda Apache Cassandra-nyckelytor och tabeller till Azure Cosmos DB för Apache Cassandra med hjälp av Azure Databricks.
Förutsättningar
Läs grunderna för att ansluta till en Azure Cosmos DB för Apache Cassandra.
Granska de funktioner som stöds i Azure Cosmos DB för Apache Cassandra för att säkerställa kompatibilitet.
Se till att du redan har skapat tomma nyckelutrymmen och tabeller i ditt Azure Cosmos DB-målkonto för Apache Cassandra.
Etablera ett Azure Databricks-kluster
Du kan följa anvisningarna för att etablera ett Azure Databricks-kluster. Vi rekommenderar att du väljer Databricks runtime version 7.5, som stöder Spark 3.0.

Lägga till beroenden
Du måste lägga till Apache Spark Cassandra Connector-biblioteket i klustret för att ansluta till både interna slutpunkter och Azure Cosmos DB Cassandra-slutpunkter. I klustret väljer du Bibliotek>Installera ny>Maven och lägger sedan till com.datastax.spark:spark-cassandra-connector-assembly_2.12:3.0.0 i Maven-koordinater.
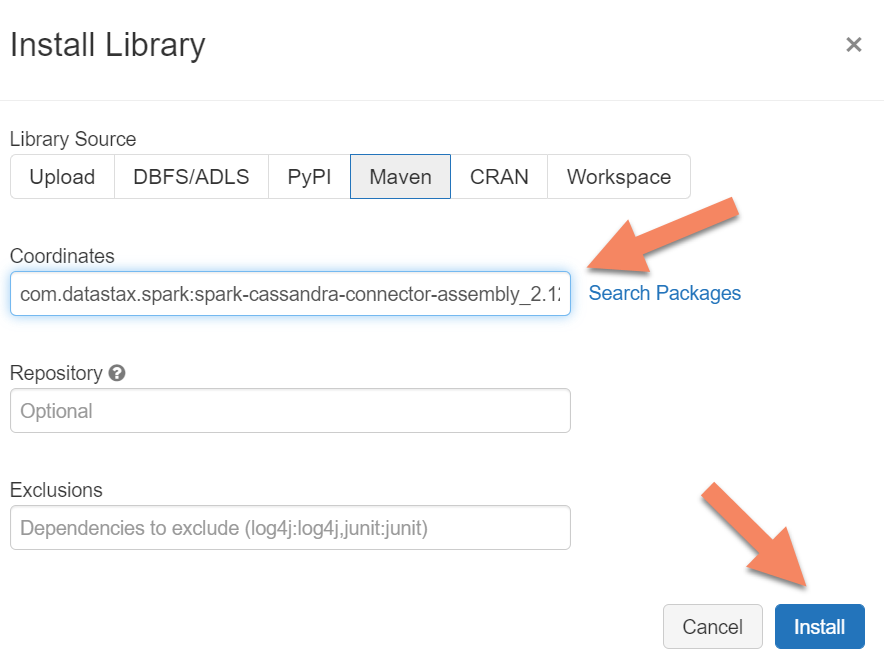
Välj Installera och starta sedan om klustret när installationen är klar.
Kommentar
Kontrollera att du startar om Databricks-klustret när Cassandra Connector-biblioteket har installerats.
Varning
Exemplen som visas i den här artikeln har testats med Spark version 3.0.1 och motsvarande Cassandra Spark Connector com.datastax.spark:spark-cassandra-connector-assembly_2.12:3.0.0. Senare versioner av Spark och/eller Cassandra-anslutningsappen kanske inte fungerar som förväntat.
Skapa Scala Notebook för migrering
Skapa en Scala Notebook i Databricks. Ersätt dina cassandra-konfigurationer för källa och mål med motsvarande autentiseringsuppgifter samt käll- och målnyckelområden och tabeller. Kör sedan följande kod:
import com.datastax.spark.connector._
import com.datastax.spark.connector.cql._
import org.apache.spark.SparkContext
// source cassandra configs
val nativeCassandra = Map(
"spark.cassandra.connection.host" -> "<Source Cassandra Host>",
"spark.cassandra.connection.port" -> "9042",
"spark.cassandra.auth.username" -> "<USERNAME>",
"spark.cassandra.auth.password" -> "<PASSWORD>",
"spark.cassandra.connection.ssl.enabled" -> "false",
"keyspace" -> "<KEYSPACE>",
"table" -> "<TABLE>"
)
//target cassandra configs
val cosmosCassandra = Map(
"spark.cassandra.connection.host" -> "<USERNAME>.cassandra.cosmos.azure.com",
"spark.cassandra.connection.port" -> "10350",
"spark.cassandra.auth.username" -> "<USERNAME>",
"spark.cassandra.auth.password" -> "<PASSWORD>",
"spark.cassandra.connection.ssl.enabled" -> "true",
"keyspace" -> "<KEYSPACE>",
"table" -> "<TABLE>",
//throughput related settings below - tweak these depending on data volumes.
"spark.cassandra.output.batch.size.rows"-> "1",
"spark.cassandra.output.concurrent.writes" -> "1000",
//"spark.cassandra.connection.remoteConnectionsPerExecutor" -> "1", // Spark 3.x
"spark.cassandra.connection.connections_per_executor_max"-> "1", // Spark 2.x
"spark.cassandra.concurrent.reads" -> "512",
"spark.cassandra.output.batch.grouping.buffer.size" -> "1000",
"spark.cassandra.connection.keep_alive_ms" -> "600000000"
)
//Read from native Cassandra
val DFfromNativeCassandra = sqlContext
.read
.format("org.apache.spark.sql.cassandra")
.options(nativeCassandra)
.load
//Write to CosmosCassandra
DFfromNativeCassandra
.write
.format("org.apache.spark.sql.cassandra")
.options(cosmosCassandra)
.mode(SaveMode.Append) // only required for Spark 3.x
.save
Kommentar
Värdena spark.cassandra.output.batch.size.rows och spark.cassandra.output.concurrent.writes och antalet arbetare i Spark-klustret är viktiga konfigurationer att justera för att undvika hastighetsbegränsning. Hastighetsbegränsning sker när begäranden till Azure Cosmos DB överskrider etablerat dataflöde eller enheter för begäranden (RU:er). Du kan behöva justera de här inställningarna, beroende på antalet utförare i Spark-klustret och eventuellt storleken (och därmed RU-kostnaden) för varje post som skrivs till måltabellerna.
Felsöka
Hastighetsbegränsning (429-fel)
Du kan se felkoden 429 eller feltexten "begärandefrekvensen är stor" även om du har minskat inställningarna till deras minimivärden. Följande scenarier kan orsaka hastighetsbegränsning:
Dataflödet som allokeras till tabellen är mindre än 6 000 enheter för begäran. Även vid minsta inställningar kan Spark skriva med en hastighet av cirka 6 000 enheter för begäran eller mer. Om du har etablerat en tabell i ett nyckelområde med delat dataflöde är det möjligt att den här tabellen har färre än 6 000 RU:er tillgängliga vid körning.
Kontrollera att tabellen som du migrerar till har minst 6 000 RU:er tillgängliga när du kör migreringen. Om det behövs allokerar du dedikerade enheter för begäranden till den tabellen.
Överdriven dataförskjutning med stor datavolym. Om du har en stor mängd data att migrera till en viss tabell men har en betydande snedställning i data (dvs. ett stort antal poster som skrivs för samma partitionsnyckelvärde), kan du fortfarande uppleva hastighetsbegränsning även om du har flera enheter för begäranden etablerade i tabellen. Enheter för begärande delas lika mellan fysiska partitioner, och stora datasnedvridningar kan orsaka en flaskhals med begäranden till en enda partition.
I det här scenariot minskar du till minimala dataflödesinställningar i Spark och tvingar migreringen att köras långsamt. Det här scenariot kan vara vanligare när du migrerar referens- eller kontrolltabeller, där åtkomsten är mindre frekvent och snedställning kan vara hög. Men om det finns en betydande skevhet i någon annan typ av tabell kanske du vill granska datamodellen för att undvika problem med frekvent partition för din arbetsbelastning under åtgärder med stabilt tillstånd.